版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
大数据系列文章目录
官方网址:https://flink.apache.org/
学习资料:https://flink-learning.org.cn/

目录
- 数据输出Data Sinks
- 基于本地集合的sink
- 基于文件的sink
- Flink的广播变量
- Flink Accumulators & Counters
- 未使用累加器
- 使用累加器
- Flink Broadcast和Accumulators的区别
- Flink的分布式缓存
数据输出Data Sinks
flink在批处理中常见的sink
- 基于本地集合的sink(Collection-based-sink)
- 基于文件的sink(File-based-sink)
基于本地集合的sink
目标
数据可以输出到:Stdout,Stderr,采集为本地集合
package batch.sink;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.DataSource;
import java.util.List;
/**
* @author lwh
* @date 2023/4/14
* @description 基于本地集合的sink,数据可以输出到:Stdout,Stderr,采集为本地集合
**/
public class LocalOutputDemo {
public static void main(String[] args) throws Exception {
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
DataSource<Long> source = env.generateSequence(1, 10);
// Local print
source.print();
System.out.println("-----------");
// Print to Local Stderr
source.printToErr();
System.out.println("-----------");
// Collect to local collection
List<Long> collect = source.collect();
System.out.println(collect);
}
}
基于文件的sink
- 文件协议:flink支持多种存储设备上的文件,包括本地文件,hdfs文件等。
- 文件类型:flink支持多种文件的存储格式,包括text文件,CSV文件等。
package batch.sink;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.core.fs.FileSystem;
/**
* @author lwh
* @date 2023/4/14
* @description 基于文件的sink
**/
public class FileOutputDemo {
public static void main(String[] args) throws Exception {
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
DataSource<Long> source = env.generateSequence(1, 10);
// 1. Sink to local file
source.writeAsText("data/output/1", FileSystem.WriteMode.OVERWRITE);
// 2. Sink to HDFS file, 注意需要有HDFS的写入权限, 在idea中运行是以windows系统的本地用户名作为用户操作的
source.writeAsText("hdfs://node1:8020/output/idea1", FileSystem.WriteMode.OVERWRITE).setParallelism(1);
// 因为没有print,所以需要手动启动这个Flink任务.
env.execute();
}
}
Flink的广播变量
Flink支持广播变量,就是将数据广播到具体的taskmanager上,数据存储在内存中,这样可以减缓大量的shuffle操作。
比如在数据join阶段,不可避免的就是大量的shuffle操作,我们可以把其中一个dataSet广播出去,一直加载到taskManager的内存中,可以直接在内存中拿数据,避免了大量的shuffle,导致集群性能下降。
广播变量创建后,它可以运行在集群中的任何function上,而不需要多次传递给集群节点。另外需要记住,不应该修改广播变量,这样才能确保每个节点获取到的值都是一致的。
一句话解释,可以理解为是一个公共的共享变量,我们可以把一个dataset 数据集广播出去,然后不同的task在节点上都能够获取到,这个数据在每个节点上只会存在一份。如果不使用broadcast,则在每个节点中的每个task中都需要拷贝一份dataset数据集,比较浪费内存(也就是一个节点中可能会存在多份dataset数据)。
注意:因为广播变量是要把dataset广播到内存中,所以广播的数据量不能太大,否则会出现OOM这样的问题
- Broadcast:Broadcast是通过withBroadcastSet(dataset,string)来注册的
- Access:通过getRuntimeContext().getBroadcastVariable(String)访问广播变量
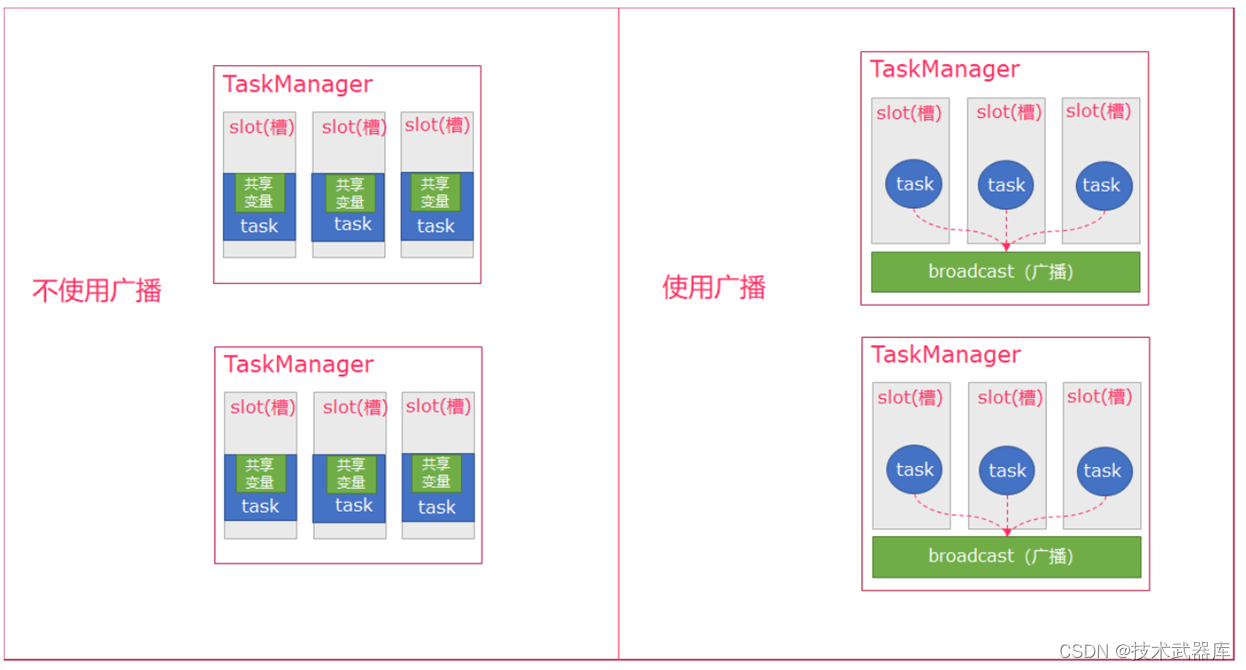
- 可以理解广播就是一个公共的共享变量
- 将一个数据集广播后,不同的Task都可以在节点上获取到
- 每个节点 只存一份
- 如果不使用广播,每一个Task都会拷贝一份数据集,造成内存资源浪费
用法
在需要使用广播的操作后,使用 withBroadcastSet 创建广播
在操作中,使用getRuntimeContext.getBroadcastVariable [广播数据类型] ( 广播名 )获取广播变量
示例
创建一个 学生 数据集,包含以下数据
|学生ID | 姓名 |
|------|------|
List((1, "张三"), (2, "李四"), (3, "王五"))
将该数据,发布到广播。
再创建一个 成绩 数据集,
|学生ID | 学科 | 成绩 |
|------|------|-----|
List( (1, "语文", 50),(2, "数学", 70), (3, "英文", 86))
请通过广播获取到学生姓名,将数据转换为
List( ("张三", "语文", 50),("李四", "数学", 70), ("王五", "英文", 86))
步骤
- 获取批处理运行环境
- 分别创建两个数据集
- 使用 RichMapFunction 对 成绩数据集进行map转换
- 在数据集调用 map 方法后,调用 withBroadcastSet 将 学生数据集创建广播
- 实现 RichMapFunction
1、将成绩数据(学生ID,学科,成绩) -> (学生姓名,学科,成绩)
2、重写 open 方法中,获取广播数据
3、在 map 方法中使用广播进行转换 - 打印测试
package batch.broadcast;
import org.apache.commons.collections.map.HashedMap;
import org.apache.flink.api.common.functions.RichMapFunction;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.operators.MapOperator;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.configuration.Configuration;
import java.util.List;
import java.util.Map;
/**
* @author lwh
* @date 2023/4/14
* @description 演示广播变量
**/
public class BroadcastDemo {
public static void main(String[] args) throws Exception {
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// 准备学生信息数据集
DataSource<Tuple2<Integer, String>> studentInfoDataSet = env.fromElements(
Tuple2.of(1, "王大锤"),
Tuple2.of(2, "潇潇"),
Tuple2.of(3, "甜甜")
);
// 准备分数信息数据集
DataSource<Tuple3<Integer, String, Integer>> scoreInfoDataSet = env.fromElements(
Tuple3.of(1, "数据结构", 99),
Tuple3.of(2, "英语", 100),
Tuple3.of(3, "C++", 96),
Tuple3.of(5, "Java", 97),
Tuple3.of(3, "Scala", 100)
);
// 关联操作用到广播变量技术
// 在map方法中计算的时候, 带上withBroadcastSet, 就表明可以在map中访问广播变量
// 需要用RichMapFunction实现, 是因为需要用到Rich的获取RuntimeContext的功能
// 可以从RuntimeContext中获取到广播变量
// Rich类型功能有2:
// 1. 带有open和close
// 2. 可以访问到RuntimeContext
MapOperator<Tuple3<Integer, String, Integer>, Tuple3<String, String, Integer>> result = scoreInfoDataSet.map(new RichMapFunction<Tuple3<Integer, String, Integer>, Tuple3<String, String, Integer>>() {
private Map<Integer, String> map = new HashedMap();
@Override
// open在类被实例化的时候 执行一次
public void open(Configuration parameters) throws Exception {
// 需要在实例化的时候, 获取到广播变量的值
// 通过RuntimeContext的getBroadcastVariable取到广播变量的值
List<Tuple2<Integer, String>> student = getRuntimeContext().getBroadcastVariable("student");
// 将list组装成map 方便通过id get到名字
for (Tuple2<Integer, String> tuple : student) {
map.put(tuple.f0, tuple.f1);
}
}
@Override
// close在类被销毁的时候 执行一次
public void close() throws Exception {
super.close();
}
@Override
public Tuple3<String, String, Integer> map(Tuple3<Integer, String, Integer> value) throws Exception {
Integer id = value.f0;
String name = map.getOrDefault(id, "未知的学生姓名");
return Tuple3.of(name, value.f1, value.f2);
}
}).withBroadcastSet(studentInfoDataSet, "student");
// withBroadcastSet中参数2是设置广播变量的名字的, 如果你用多个广播变量, 一定要注意名字不一样, 不然就会产生问题
result.print();
}
}
// 有一个 10个G的数据集, 我要广播出去, 广播变量扛得住吗?
// 内存有限, 对于大体积的数据, 可以使用分布式缓存技术来优化
/*
将数据广播到每一个机器的硬盘上, 那么当读取的时候 或者说多次读取的时候就会有优化:
1. 首次读取没有加速, 二次 三次使用的话, 直接从硬盘读 ( 非分布式缓存, 需要从HDFS读, HDFS读涉及到 磁盘读出来 网络发出去), 省略了一次网络发送的IO
2. 缓存到本地硬盘上, 可以被Linux系统的 Buffer和Cache所优化 (不是100%起作用, 需要内存有空闲)
Buffer和Cache是Linux操作系统的磁盘优化项, 可以在内存中缓存最近的```热数据```, 当你使用热数据的时候, 其实是从内存中取出去的.
*/
Flink Accumulators & Counters
Accumulator即累加器,与Mapreduce counter的应用场景差不多,都能很好地观察task在运行期间的数据变化
可以在Flink job任务中的算子函数中操作累加器,但是只能在任务执行结束之后才能获得累加器的最终结果。
Flink现在有以下内置累加器。每个累加器都实现了Accumulator接口。
- IntCounter
- LongCounter
- DoubleCounter
步骤
- 创建累加器
private IntCounter numLines = new IntCounter();
- 注册累加器
getRuntimeContext().addAccumulator("num-lines", this.numLines);
- 使用累加器
this.numLines.add(1);
- 获取累加器的结果
myJobExecutionResult.getAccumulatorResult("num-lines")
未使用累加器
package batch.accumulators;
import org.apache.flink.api.common.functions.RichMapFunction;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.operators.MapOperator;
import org.apache.flink.core.fs.FileSystem;
/**
* @author lwh
* @date 2023/4/14
* @description 演示未使用累加器
**/
public class AccumulatorsDemo1 {
public static void main(String[] args) throws Exception {
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
DataSource<Long> source = env.generateSequence(1, 10);
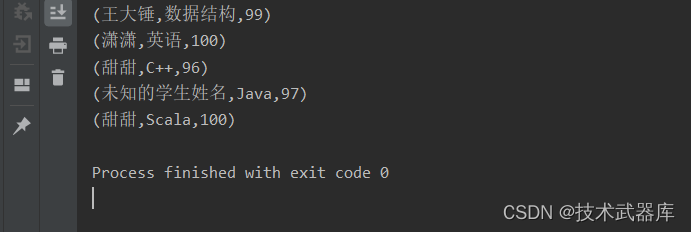
MapOperator<Long, Long> map = source.map(new RichMapFunction<Long, Long>() {
Long counter = 0L;
@Override
public Long map(Long value) throws Exception {
counter += 1L;
System.out.println("Thread id: " + getRuntimeContext().getIndexOfThisSubtask() + ",counter: " + counter);
return value;
}
});
map.writeAsText("data/output/accumulators", FileSystem.WriteMode.OVERWRITE);
env.execute();
}
}
使用累加器
package batch.accumulators;
import org.apache.flink.api.common.JobExecutionResult;
import org.apache.flink.api.common.accumulators.IntCounter;
import org.apache.flink.api.common.functions.RichMapFunction;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.operators.MapOperator;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.core.fs.FileSystem;
/**
* @author lwh
* @date 2023/4/14
* @description 演示使用累加器
**/
public class AccumulatorsDemo2 {
public static void main(String[] args) throws Exception {
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
DataSource<Long> source = env.generateSequence(1, 10);
/*
累加器使用为4步:
1. 创建累加器
2. 注册累加器
3. 使用累加器
4. 获得累加器的结果
*/
MapOperator<Long, Long> map = source.map(new RichMapFunction<Long, Long>() {
// 1. 创建累加器
IntCounter counter = new IntCounter();
// 2. 在open方法中注册累加器
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
// 注册
getRuntimeContext().addAccumulator("sum", counter);
}
@Override
public Long map(Long value) throws Exception {
// 3. 使用累加器
counter.add(1);
System.out.println("Thread id: " + getRuntimeContext().getIndexOfThisSubtask() + ",counter: " + counter.getLocalValue());
return value;
}
});
map.writeAsText("data/output/accumulators", FileSystem.WriteMode.OVERWRITE);
JobExecutionResult jobExecutionResult = env.execute();
// 4. 从执行结果中获取累加器的最终值
int sum = jobExecutionResult.getAccumulatorResult("sum");
System.out.println("Finally Accumulator result is: " + sum);
}
}
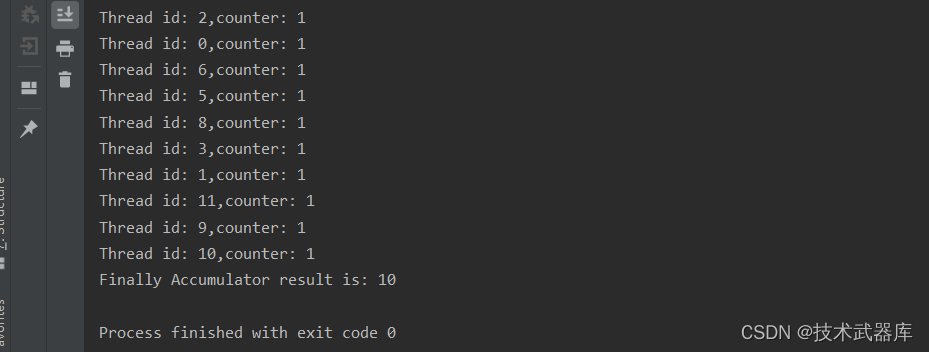
可见,每一个线程本地中累加后结果确实都是1
但是经过累加器集合后,最终结果不会变化
Flink Broadcast和Accumulators的区别
- Broadcast(广播变量)允许程序员将一个只读的变量缓存在每台机器上,而不用在任务之间传递变量。广播变量可以进行共享,但是不可以进行修改
- Accumulators(累加器)是可以在不同任务中对同一个变量进行累加操作(简单的说就是由Flink为我们实现线程安全)(对于分布式系统来说,不仅仅累加的各个Task会跨Slot,甚至会跨机器进行累加,所以,传统的累加不可用,需要用Flink提供的累加器才可以的哦)。
Flink的分布式缓存
Flink提供了一个类似于Hadoop的分布式缓存,让并行运行实例的函数可以在本地访问。这个功能可以被使用来分享外部静态的数据,例如:机器学习的逻辑回归模型等!
缓存的使用流程:
使用ExecutionEnvironment实例对本地的或者远程的文件(例如:HDFS上的文件),为缓存文件指定一个名字注册该缓存文件!当程序执行时候,Flink会自动将复制文件或者目录到所有worker节点的本地文件系统中,函数可以根据名字去该节点的本地文件系统中检索该文件!
和广播变量的区别:
- 广播变量广播的是程序中的变量(DataSet)数据,分布式缓存广播的是文件
- 广播变量将数据广播到各个TaskManager的内存中,分布式缓存广播到各个TaskManager的本地
用法
使用Flink运行时环境的 registerCachedFile 注册一个分布式缓存
在操作中,使用 getRuntimeContext.getDistributedCache.getFile ( 文件名 )获取分布式缓存
示例
创建一个 成绩 数据集
List( (1, "语文", 50),(2, "数学", 70), (3, "英文", 86))
请通过分布式缓存获取到学生姓名,将数据转换为
List( ("张三", "语文", 50),("李四", "数学", 70), ("王五", "英文", 86))
测试数据
1,王大锤
2,潇潇
3,甜甜
操作步骤
- 将 distribute_cache_student 文件上传到HDFS / 目录下
- 获取批处理运行环境
- 创建成绩数据集
- 对成绩数据集进行map转换,将(学生ID, 学科, 分数)转换为(学生姓名,学科,分数)
1、RichMapFunction 的 open 方法中,获取分布式缓存数据
2、在 map 方法中进行转换 - 实现 open 方法
1、使用 getRuntimeContext.getDistributedCache.getFile 获取分布式缓存文件
2、使用 Scala.fromFile 读取文件,并获取行
3、将文本转换为元组(学生ID,学生姓名),再转换为List - 实现 map 方法
1、从分布式缓存中根据学生ID过滤出来学生
2、获取学生姓名
3、构建最终结果元组 - 打印测试
package batch.distributed_cache;
import org.apache.commons.collections.map.HashedMap;
import org.apache.flink.api.common.functions.RichMapFunction;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.operators.MapOperator;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.configuration.Configuration;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileReader;
import java.util.Map;
/**
* @author lwh
* @date 2023/4/14
* @description 分布式缓存
**/
public class DistributedCacheDemo {
public static void main(String[] args) throws Exception {
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// 准备分数信息数据集
DataSource<Tuple3<Integer, String, Integer>> scoreInfoDataSet = env.fromElements(
Tuple3.of(1, "数据结构", 99),
Tuple3.of(2, "英语", 100),
Tuple3.of(3, "C++", 96),
Tuple3.of(5, "Java", 97),
Tuple3.of(3, "Scala", 100)
);
// 1. env注册分布式缓存 参数1是被广播文件的路径, 参数2是名称
env.registerCachedFile("data/input/distributed_student.txt", "student");
// 2. 在算子中应用分布式缓存数据即可
MapOperator<Tuple3<Integer, String, Integer>, Tuple3<String, String, Integer>> result = scoreInfoDataSet.map(new RichMapFunction<Tuple3<Integer, String, Integer>, Tuple3<String, String, Integer>>() {
private Map<Integer, String> map = new HashedMap();
@Override
public void open(Configuration parameters) throws Exception {
// 通过RuntimeContext来获取到分布式缓存的```文件```, getFile参数是分布式缓存的名称
File file = getRuntimeContext().getDistributedCache().getFile("student");
// 应用 读文件的逻辑读取数据即可
BufferedReader bufferedReader = new BufferedReader(new FileReader(file));
String line = "";
while ((line = bufferedReader.readLine()) != null) {
String[] arr = line.split(",");
map.put(Integer.parseInt(arr[0]), arr[1]);
}
}
@Override
public Tuple3<String, String, Integer> map(Tuple3<Integer, String, Integer> value) throws Exception {
int id = value.f0;
String name = map.getOrDefault(id, "未知的学生姓名");
return Tuple3.of(name, value.f1, value.f2);
}
});
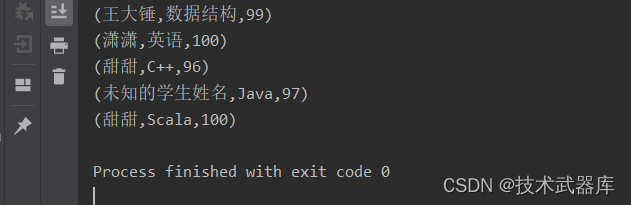
result.print();
}
}


![[使用指南]在使用MyEclipse时如何添加 更新插件](https://img-blog.csdnimg.cn/img_convert/e69fc51e7150b710d51301f387481383.png)