一、概述
聊天机器人的基本功能是系统根据用户当前的输入语句,生成相应的语句并输出给用户,用户和聊天机器人之间的一问一答构成了一个utterance,多个utterance就构成了一段对话。目前流行的聊天机器人都是基于Transformer的架构来做的,在这之前也有使用RNN网络来构建聊天机器人的例子,譬如PyTorch框架提供给我们的“Chatbot Tutorial”(Chatbot Tutorial — PyTorch Tutorials 2.0.0+cu117 documentation)。本文使用前面用于语言翻译的Transformer模型来构建一个简单的聊天机器人,并与“Chatbot Tutorial”示例提供的基于RNN的GRU模型构建的聊天机器人进行对比测试,基于Transformer构建的聊天机器人同样使用“Chatbot Tutorial”示例中提到的语料进行训练。
二、训练数据准备
首先从PyTorch提供的chatbot turorial中下载训练语料“Cornell Movie-Dialogs Corpus.”,这是一个基于电影对话的语料,处理后包括以下文件:
原始的对话数据文件是utterances.jsonl,以下是内容示例,一个utterance包含一问一答:

首先需要对这些原始对话数据进行格式化处理:

每一行代表一个utterance,以”\t”作为分隔符,前半部分可以看成是用户输入的语句,后半部分看成是聊天机器人的输出语句。从这个语料库格式化处理后得到的可用于训练的utterances总共有22万左右,这里抽取其中的少量数据作为测试集,剩下的大部分数据都作为训练集来使用。
接下来需要构建词典,如果都是英文对话,使用一个词典就可以了:

如果按照one hot编码的方式把训练集中所有语句的单词都拿出来构建词典,会造成词典过于庞大而影响性能,所以这里采用按照数据集中的词汇出现频率进行统计,只在词典中保留必要的词汇,另外为了防止预测时给出的词汇是词典中不存在的,需要添加UNK(unkown)标记,另外也需要加入PAD对不够长度的句子进行补齐:

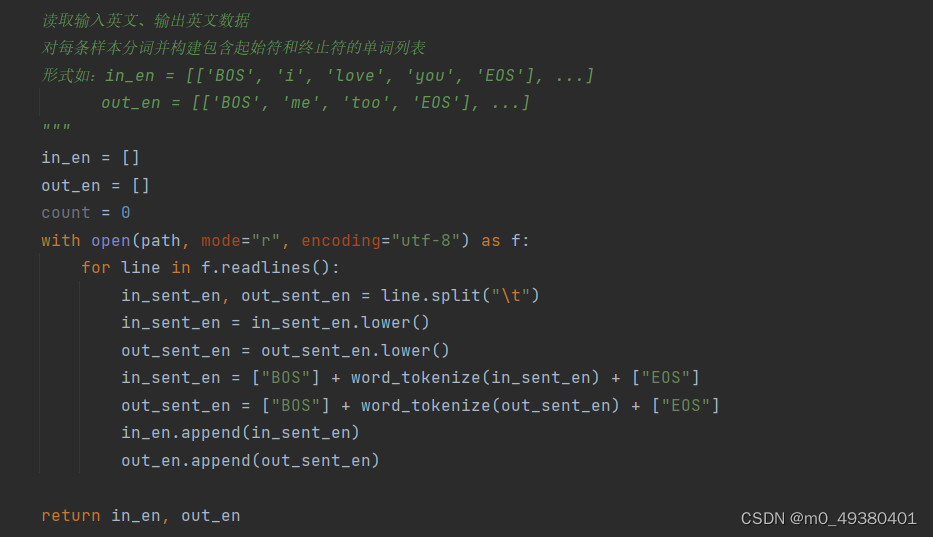
加载数据时对于英文语句的单词切分使用了工具包nltk.tokenize:
三、模型构建
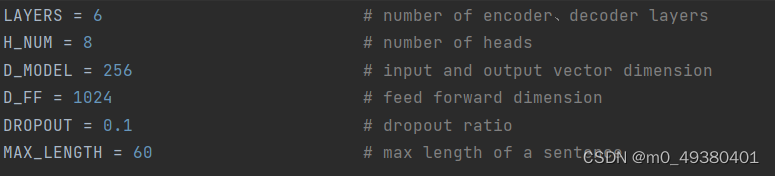
对于基于Transformer的这个聊天机器人,使用的还是前面博文提到的用于语言翻译的这个Transformer模型,只是使用了上面提到的基于电影对话的语料来训练模型,以下是这个模型的超参配置:
对于PyTorch框架提供的聊天机器人示例,使用的是基于RNN的GRU的Seq2Seq的模型,以下是这个模型的超参配置,这里的注意力计算方法为“dot”,另外注意这里的输入语句最大长度被限制在了10,GRU是基于RNN的变体,对于长句的处理能力有限:
![]()

在基于GRU构建的聊天机器人这个示例中,使用了注意力机制,相当于GRU模型的一个外挂,这个注意力机制与Transformer使用的注意力机制是有区别的,以下是关于这个称之为“Luong attention”的注意力机制的架构图:
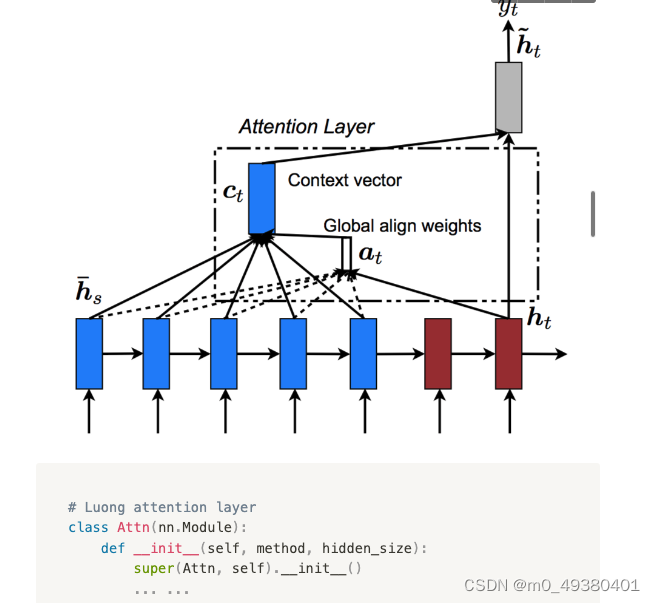
在这个RNN的decoder部分,我们可以看到decoder是如何在每一步预测下一个单词时进行注意力计算的:
- 通过一个单向的GRU模型获取单步的output及hidden
- 把这个output与encoder的所有outputs(也就是输入语句经过encoder处理后得到的outputs)进行点积计算
- 点积计算结果进行矩阵转置处理,然后调用softmax函数转换为0到1之间的概率,即注意力权重
- 把上面得到的注意力权重通过方法bmm再次与encoder的outputs进行批量矩阵相乘,得到的结果称为“加权和”的context向量
- 把这个context与上面decoder单步计算得到的output进行拼接(cat函数),得到基于context的input
- 把这个基于context的input传入tanh函数得到一个output,基于它调用softmax来预测下一个单词
以下是decoder的forward关于使用注意力来预测单词的逻辑代码:
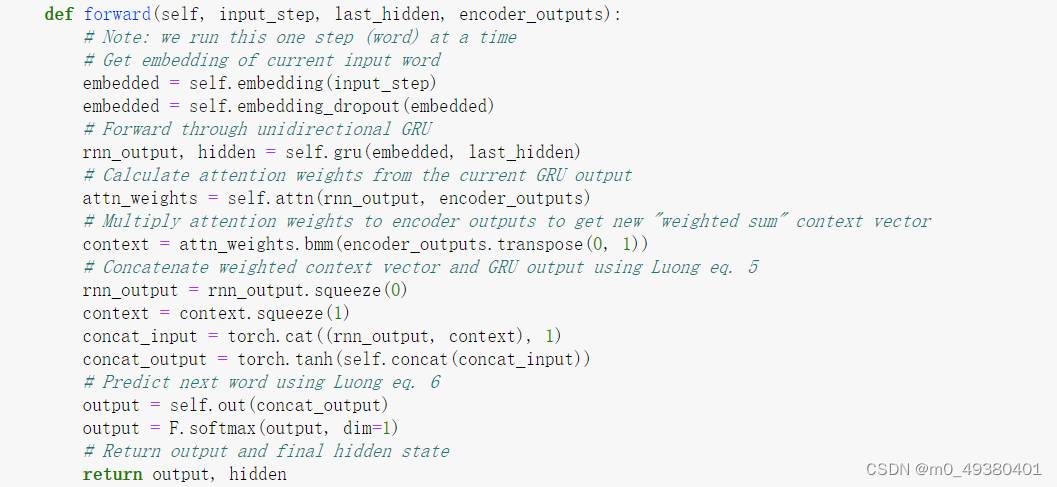
以下是这个RNN中使用到的注意力机制的计算逻辑代码,: