背景
今天出现了一个bug,在数据库中我们将订单表中的order_no从之前的bigint(20)改成varchar(20)后,原有的代码逻辑在进行时查询时,之前是以Long类型传参查询的。
select * from order_main where order_no=16541913435669023
debug时的时候发现这条sql语句查询出来两条数据,另外一条毫不相关的订单也被查出来了。 但是同样的sql我们放到数据库中时确是只能查到一条数据。
select * from order_main where order_no='16541913435669023'

仔细观察后发现,得到正确结果的Sql,是加了引号的,代码中的sql是没有加引号的数字类型。
根源
mysql5.7 查询varchar类型的数据时,不加引号,触发隐式转换导致的查询结果错误。
dev.mysql.com/doc/refman/…

源码解释
堆栈调用关系如下所示:
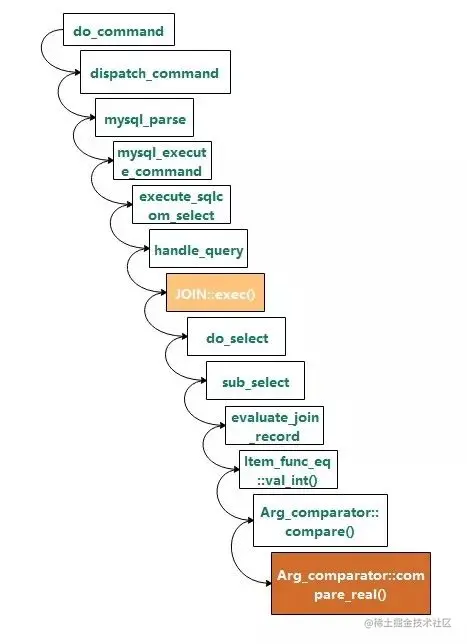
其中JOIN::exec()是执行的入口,Arg_comparator::compare_real()是进行等值判断的函数,其定义如下
int Arg_comparator::compare_real()
{
/*
Fix yet another manifestation of Bug#2338. 'Volatile' will instruct
gcc to flush double values out of 80-bit Intel FPU registers before
performing the comparison.
*/
volatile double val1, val2;
val1= (*a)->val_real();
if (!(*a)->null_value)
{
val2= (*b)->val_real();
if (!(*b)->null_value)
{
if (set_null)
owner->null_value= 0;
if (val1 < val2) return -1;
if (val1 == val2) return 0;
return 1;
}
}
if (set_null)
owner->null_value= 1;
return -1;
}
比较步骤如下图所示,逐行读取t1表的id列放入val1,而常量204027026112927603存在于cache中,类型为double类型(2.0402702611292762E+17),所以到这里传值给val2后val2=2.0402702611292762E+17。

当扫描到第一行时,204027026112927605转成doule的值为2.0402702611292762e17,等式成立,判定为符合条件的行,继续往下扫描,同理204027026112927603也同样符合

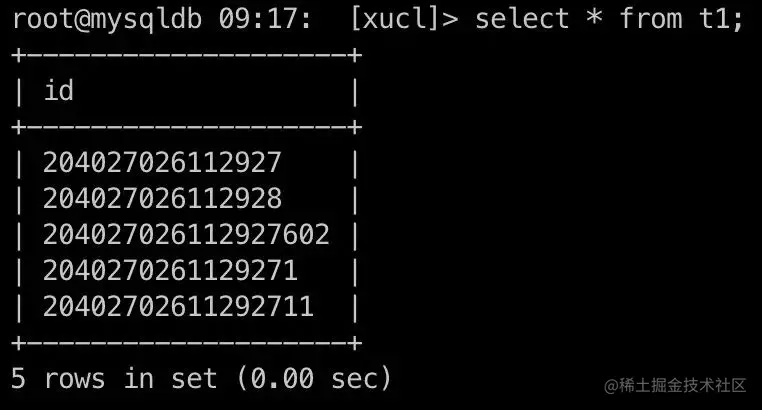
如何检测string类型的数字转成doule类型是否溢出呢?这里经过测试,当数字超过16位以后,转成double类型就已经不准确了,例如20402702611292711会表示成20402702611292712(如图中val1)

MySQL string转成double的定义函数如下:
{
char buf[DTOA_BUFF_SIZE];
double res;
DBUG_ASSERT(end != NULL && ((str != NULL && *end != NULL) ||
(str == NULL && *end == NULL)) &&
error != NULL);
res= my_strtod_int(str, end, error, buf, sizeof(buf));
return (*error == 0) ? res : (res < 0 ? -DBL_MAX : DBL_MAX);
}
真正转换函数my_strtod_int位置在dtoa.c(太复杂了,简单贴个注释吧)
/*
strtod for IEEE--arithmetic machines.
This strtod returns a nearest machine number to the input decimal
string (or sets errno to EOVERFLOW). Ties are broken by the IEEE round-even
rule.
Inspired loosely by William D. Clinger's paper "How to Read Floating
Point Numbers Accurately" [Proc. ACM SIGPLAN '90, pp. 92-101].
Modifications:
1. We only require IEEE (not IEEE double-extended).
2. We get by with floating-point arithmetic in a case that
Clinger missed -- when we're computing d * 10^n
for a small integer d and the integer n is not too
much larger than 22 (the maximum integer k for which
we can represent 10^k exactly), we may be able to
compute (d*10^k) * 10^(e-k) with just one roundoff.
3. Rather than a bit-at-a-time adjustment of the binary
result in the hard case, we use floating-point
arithmetic to determine the adjustment to within
one bit; only in really hard cases do we need to
compute a second residual.
4. Because of 3., we don't need a large table of powers of 10
for ten-to-e (just some small tables, e.g. of 10^k
for 0 <= k <= 22).
*/
既然是这样,我们测试下没有溢出的案例
root@mysqldb 23:30: [xucl]> select * from t1 where id=2040270261129276;
+------------------+
| id |
+------------------+
| 2040270261129276 |
+------------------+
1 row in set (0.00 sec)
root@mysqldb 23:30: [xucl]> select * from t1 where id=101;
+------+
| id |
+------+
| 101 |
+------+
1 row in set (0.00 sec)
结果符合预期,而在本例中,正确的写法应当是
root@mysqldb 22:19: [xucl]> select * from t1 where id='204027026112927603';
+--------------------+
| id |
+--------------------+
| 204027026112927603 |
+--------------------+
1 row in set (0.01 sec)
结论
- 避免发生隐式类型转换,隐式转换的类型主要有字段类型不一致、in参数包含多个类型、字符集类型或校对规则不一致等
- 隐式类型转换可能导致无法使用索引、查询结果不准确等,因此在使用时必须仔细甄别
- 数字类型的建议在字段定义时就定义为int或者bigint,表关联时关联字段必须保持类型、字符集、校对规则都一致
本篇文章如有帮助到您,请给「翎野君」点个赞,感谢您的支持。






![[算法总结] 关于字符串类型题你应该知道这些?精心汇总!!](https://img-blog.csdnimg.cn/34e3437a43c345ed80015fa335ad0826.png#pic_center)