目录
开发环境
数据描述
功能需求
数据准备
分析数据
HBase
HIive
统计查询
开发环境
Hadoop+Hive+Spark+HBase
启动Hadoop:start-all.sh
启动zookeeper:zkServer.sh start
启动Hive:
nohup hiveserver2 1>/dev/null 2>&1 &
beeline -u jdbc:hive2://192.168.152.192:10000
启动Hbase:
start-hbase.sh
hbase shell
启动Spark:spark-shell
数据描述
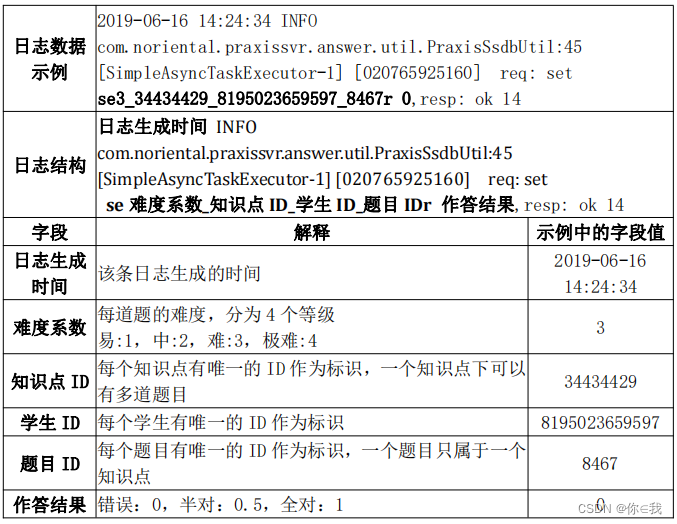
这是一份来自于某在线考试系统的学员答题批改日志,日志中记录了日志生成时间,题目 难度系数,题目所属的知识点 ID,做题的学生 ID,题目 ID 以及作答批改结果。日志的结构如下:
功能需求
数据准备
请在 HDFS 中创建目录/app/data/exam,并将 answer_question.log 传到该目录。
hdfs dfs -mkdir -p /app/data/exam
hdfs dfs -put ./nswer_question.log /app/data/exam
分析数据
在 Spark-Shell 中,加载 HDFS 文件系统 answer_question.log 文件,并使用 RDD 完成 以下分析,也可使用 Spark 的其他方法完成数据分析。
①提取日志中的知识点 ID,学生 ID,题目 ID,作答结果 4 个字段的值
val aq=sc.textFile("/app/data/exam/nswer_question.log")
//方法一
aq.map(x=>{val ar=x.split("_");(ar(1),ar(2),ar(3).split('r')(0),ar(3)
.split("\\s")(1).split(",")(0))})
.foreach(println)
//方法二
aq.map(x=>x.split("\\s+")).map(x=>(x(8).split("_"),x(9)))
.map(x=>(x._1(1),x._1(2),x._1(3).dropRight(1),x._2.split(",")(0)))
.foreach(println)
②将提取后的知识点 ID,学生 ID,题目 ID,作答结果字段的值以文件的形式保存到 HDFS的/app/data/result 目录下。一行保留一条数据,字段间以“\t”分割。(提示:元组可使用 tuple.productIterator.mkString("\t")组合字符串文件格式)如下所示。
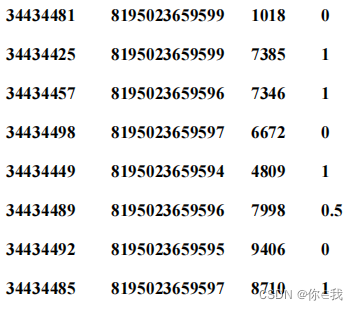
aq.map(x=>x.split("\\s+")).map(x=>(x(8).split("_"),x(9)))
.map(x=>(x._1(1),x._1(2),x._1(3).dropRight(1),x._2.split(",")(0))
.productIterator.mkString("\t")).saveAsTextFile("/app/data/result")
HBase
在 HBase 中创建命名空间(namespace)exam,在该命名空间下创建 analysis 表,使用 学生 ID 作为 RowKey,该表下有 2 个列族 accuracy、question。accuracy 列族用于保存 学 员 答 题 正 确 率 统 计 数 据 ( 总 分 accuracy:total_score , 答 题 的 试 题 数 accuracy:question_count,正确率 accuracy:accuracy);question 列族用于分类保存学 员正确,错 误和半对的题目 id (正确 question:right,错误 question:error,半对question:half)
hbase(main):001:0> create 'exam:analysis','accuracy','question'HIive
请在 Hive 中创建数据库 exam,在该数据库中创建外部表 ex_exam_record 指向 /app/data/result 下 Spark 处理后的日志数据 ;创建外部表 ex_exam_anlysis 映射至 HBase中的 analysis 表的 accuracy 列族;创建外部表 ex_exam_question 映射至 HBase 中的analysis 表的 question 列族
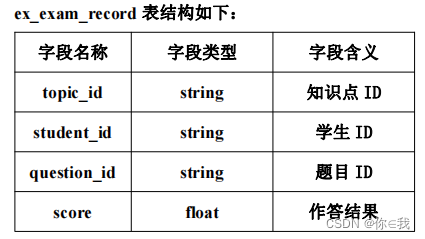
ex_exam_anlysis 表结构如下:
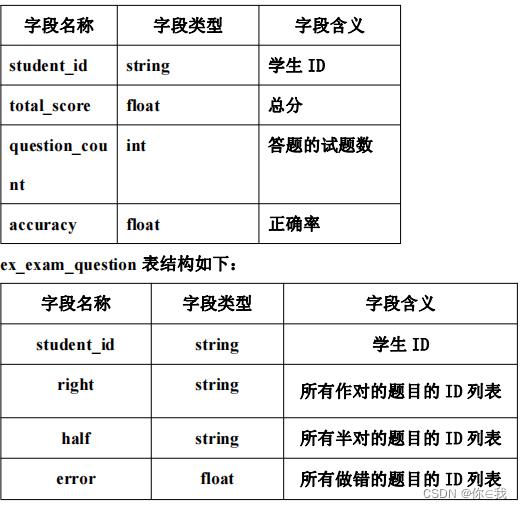
ex_exam_record 表
create external table ex_exam_record
(
topic_id string,
student_id string,
question_id string,
score float
)
row format delimited fields terminated by "\t"
stored as textfile location "/app/data/result";ex_exam_anlysis 表
create external table ex_exam_anlysis
(
student_id string,
total_score float,
question_count int,
accuracy float
) stored by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
with serdeproperties ("hbase.columns.mapping" =
":key,accuracy:total_score,accuracy:question_count,accuracy:accuracy")
tblproperties ("hbase.table.name" = "exam:analysis");
ex_exam_question 表
create external table ex_exam_question
(
student_id string,
`right` string,
half string,
error float
) stored by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
with serdeproperties ("hbase.columns.mapping" =
":key,question:`right` ,question:half,question:error")
tblproperties ("hbase.table.name" = "exam:analysis");统计查询
使用 ex_exam_record 表中的数据统计每个学员总分、答题的试题数和正确率,并保存 到 ex_exam_anlysis 表中,其中正确率的计算方法如下: 正确率=总分/答题的试题数
insert into ex_exam_anlysis
select student_id,
sum(score) total_score ,
count(question_id) question_count,
-- sum(score)/count(question_id) accuracy,
-- round(sum(score) / count(question_id), 2) as accuracy,
cast((sum(score)/count(question_id)) as decimal(5,2)) as accuracy2
from ex_exam_record group by student_id;使用 ex_exam_record 表中的数据统计每个作对,做错,半对的题目列表。
①题目 id 以逗号分割,并保存到 ex_exam_question 表中。
方法一:
insert into ex_exam_question
select t1.student_id, t1.`right`, t3.half, t2.error
from (
(select student_id, concat_ws(",", collect_set(question_id)) as `right`
from ex_exam_record1
where score = 1
group by student_id) as t1
left join
(select student_id, concat_ws(",", collect_set(question_id)) as error
from ex_exam_record1
where score = 0
group by student_id) as t2 on t1.student_id = t2.student_id
left join
(select student_id, concat_ws(",", collect_set(question_id)) as half
from ex_exam_record1
where score = 0.5
group by student_id) t3 on t1.student_id = t2.student_id);方法二:
with `right` as (select student_id, concat_ws(",", collect_set(question_id)) as `right`
from ex_exam_record1
where score = 1
group by student_id),
halt as (select student_id, concat_ws(",", collect_set(question_id)) as half
from ex_exam_record1
where score = 0.5
group by student_id),
error as (select student_id, concat_ws(",", collect_set(question_id)) as error
from ex_exam_record1
where score = 0
group by student_id)
insert
into ex_exam_question
select `right`.student_id, `right`, half, error
from `right`
left join halt on `right`.student_id = halt.student_id
left join error on `right`.student_id = error.student_id②完成统计后,在 HBase Shell 中遍历 exam:analysis 表并只显示 question 列族中的数据,
如下图所示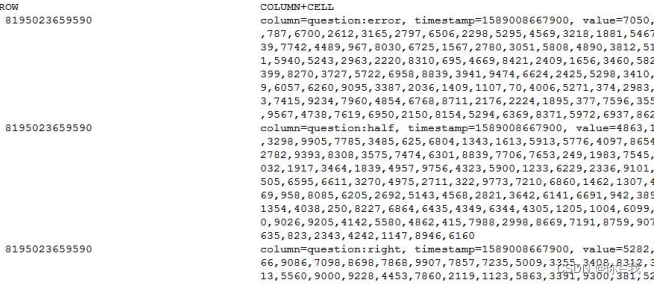
hbase(main):014:0> scan 'exam:analysis',{COLUMNS=>'question'}




![[算法总结] 关于字符串类型题你应该知道这些?精心汇总!!](https://img-blog.csdnimg.cn/34e3437a43c345ed80015fa335ad0826.png#pic_center)