原文:OpenCV 3.x with Python By Example
协议:CC BY-NC-SA 4.0
译者:飞龙
本文来自【ApacheCN 计算机视觉 译文集】,采用译后编辑(MTPE)流程来尽可能提升效率。
当别人说你没有底线的时候,你最好真的没有;当别人说你做过某些事的时候,你也最好真的做过。
一、将几何变换应用于图像
在本章中,我们将学习如何将冷酷的几何效果应用于图像。 在开始之前,我们需要安装 OpenCV-Python。 我们将解释如何编译和安装必要的库,以遵循本书中的每个示例。
在本章结束时,您将了解:
- 如何安装 OpenCV-Python
- 如何读取,显示和保存图像
- 如何转换为多个色彩空间
- 如何应用几何变换,例如平移,旋转,
和缩放 - 如何使用仿射和投影变换将有趣的几何效果应用于照片
安装 OpenCV-Python
在本节中,我们说明如何在多个平台上使用 Python 2.7 安装 OpenCV3.X。 如果需要,OpenCV 3.X 还支持使用 Python 3.X,它将与本书中的示例完全兼容。 建议使用 Linux,因为本书中的示例已在该 OS 上进行了测试。
Windows
为了启动并运行 OpenCV-Python,我们需要执行以下步骤:
- 安装 Python:确保您的计算机上安装了 Python2.7.x。 如果没有它,则可以从以下位置进行安装。
- 安装 NumPy:NumPy 是使用 Python 进行数值计算的出色包。 它非常强大,并具有多种功能。 OpenCV-Python 与 NumPy 配合良好,在本书中我们将大量使用此包。 您可以从以下位置安装最新版本。
我们需要将所有这些包安装在它们的默认位置。 安装 Python 和 NumPy 之后,我们需要确保它们能正常工作。 打开 Python shell 并输入以下内容:
>>> import numpy
如果安装顺利,则不会出现任何错误。 确认后,您可以继续从以下位置下载最新的 OpenCV 版本。
下载完成后,双击以安装它。 我们需要进行一些更改,如下所示:
- 导航到
opencv/build/python/2.7/。 - 您将看到一个名为
cv2.pyd的文件。 将此文件复制到C:/Python27/lib/site-packages。
你们都准备好了! 让我们确保 OpenCV 正常运行。 打开 Python shell 并输入以下内容:
>>> import cv2
如果您没有看到任何错误,那就很好了! 现在您可以使用 OpenCV-Python 了。
MacOSX
要安装 OpenCV-Python,我们将使用 Homebrew。 Homebrew 是 MacOSX 的出色包管理器,当您在 MacOSX 上安装各种库和工具时,它会派上用场。如果没有 Homebrew,则可以通过在终端中运行以下命令来安装它:
$ ruby -e "$(curl -fsSL
https://raw.githubusercontent.com/Homebrew/install/master/install)"
即使 OS X 带有内置的 Python,我们也需要使用 Homebrew 安装 Python 以使我们的生活更轻松。 这个版本称为 Brewed Python。 安装 Homebrew 之后,下一步就是安装酿造的 Python。 打开终端,然后键入以下内容:
$ brew install python
这也将自动安装。 PIP 是一个包管理工具,用于在 Python 中安装包,我们将使用它来安装其他包。 让我们确保酿造的 Python 正常工作。 转到终端并输入以下内容:
$ which python
您应该会在终端上看到/usr/local/bin/python。 这意味着我们正在使用酿造的 Python,而不是内置的系统 Python。 现在,我们已经安装了酝酿的 Python,我们可以继续添加存储库homebrew/science,它是 OpenCV 所在的位置。 打开终端并运行以下命令:
$ brew tap homebrew/science
确保已安装 NumPy 包。 如果没有,请在终端中运行以下命令:
$ pip install numpy
现在,我们准备安装 OpenCV。 继续并从终端运行以下命令:
$ brew install opencv --with-tbb --with-opengl
现在已在您的计算机上安装了 OpenCV,您可以在/usr/local/Cellar/opencv/3.1.0/上找到它。 您暂时无法使用它。 我们需要告诉 Python 在哪里可以找到我们的 OpenCV 包。 让我们通过符号链接 OpenCV 文件来做到这一点。 从终端运行以下命令(请仔细检查您实际上使用的是正确版本,因为它们可能略有不同):
$ cd /Library/Python/2.7/site-packages/
$ ln -s /usr/local/Cellar/opencv/3.1.0/lib/python2.7/site-packages/cv.py
cv.py
$ ln -s /usr/local/Cellar/opencv/3.1.0/lib/python2.7/site-packages/cv2.so
cv2.so
你们都准备好了! 让我们看看它是否正确安装。 打开 Python shell 并输入以下内容:
> import cv2
如果安装顺利,您将看不到任何错误消息。 现在您可以在 Python 中使用 OpenCV 了。
如果要在虚拟环境中使用 OpenCV,可以遵循“虚拟环境”部分中的说明,对 MacOSX 的每个命令进行少量更改。
Linux(Ubuntu)
首先,我们需要安装操作系统要求:
[compiler] $ sudo apt-get install build-essential
[required] $ sudo apt-get install cmake git libgtk2.0-dev pkg-config
libavcodec-dev libavformat-dev libswscale-dev git
libgstreamer0.10-dev libv4l-dev
[optional] $ sudo apt-get install python-dev python-numpy libtbb2
libtbb-dev libjpeg-dev libpng-dev libtiff-dev libjasper-dev
libdc1394-22-dev
安装完操作系统要求后,我们需要下载并编译最新版本的 OpenCV 以及几个受支持的标志,以使我们能够实现以下代码示例。 在这里,我们将安装版本 3.3.0:
$ mkdir ~/opencv
$ git clone -b 3.3.0 https://github.com/opencv/opencv.git opencv
$ cd opencv
$ git clone https://github.com/opencv/opencv_contrib.git opencv_contrib
$ mkdir release
$ cd release
$ cmake -D CMAKE_BUILD_TYPE=RELEASE -D CMAKE_INSTALL_PREFIX=/usr/local -D INSTALL_PYTHON_EXAMPLES=ON -D INSTALL_C_EXAMPLES=OFF -D OPENCV_EXTRA_MODULES_PATH=~/opencv/opencv_contrib/modules -D BUILD_PYTHON_SUPPORT=ON -D WITH_XINE=ON -D WITH_OPENGL=ON -D WITH_TBB=ON -D WITH_EIGEN=ON -D BUILD_EXAMPLES=ON -D BUILD_NEW_PYTHON_SUPPORT=ON -D WITH_V4L=ON -D BUILD_EXAMPLES=ON ../
$ make -j4 ; echo 'Running in 4 jobs'
$ sudo make install
如果您使用的是 Python 3,则将-D和标志放在一起,如以下命令所示:
cmake -DCMAKE_BUILD_TYPE=RELEASE....
虚拟环境
如果您使用虚拟环境使测试环境与操作系统的其余部分完全分开,则可以按照以下教程安装名为 virtualenvwrapper 的工具。
要使 OpenCV 在此 Virtualenv 上运行,我们需要安装 NumPy 包:
$(virtual_env) pip install numpy
按照前面的所有步骤,只需在cmake的编译中添加以下三个标志(请注意,正在重新定义标志CMAKE_INSTALL_PREFIX):
$(<env_name>) > cmake ...
-D CMAKE_INSTALL_PREFIX=~/.virtualenvs/<env_name> \
-D PYTHON_EXECUTABLE=~/.virtualenvs/<env_name>/bin/python
-D PYTHON_PACKAGES_PATH=~/.virtualenvs/<env_name>/lib/python<version>/site-packages ...
确保安装正确。 打开 Python shell 并输入以下内容:
> import cv2
如果没有看到任何错误,那就很好了。
故障排除
如果找不到cv2库,请标识该库的编译位置。 它应该位于/usr/local/lib/python2.7/site-packages/cv2.so处。 如果是这种情况,请确保您的 Python 版本与已存储的一个包匹配,否则只需将其移至 Python 的site-packages文件夹中,包括 Virtualenv 的文件夹即可。
在执行cmake命令期间,尝试加入-DMAKE …和其余-D行。 此外,如果在编译过程中执行失败,则操作系统初始要求中可能缺少某些库。 确保已全部安装。
您可以在以下网站上找到有关如何在 Linux 上安装最新版本的 OpenCV 的官方教程。
如果您尝试使用 Python 3 进行编译,并且未安装cv2.so,请确保已安装操作系统依赖项 Python 3 和 NumPy。
OpenCV 文档
OpenCV 的官方文档位于这个页面。 共有三个文档类别:Doxygen,Sphinx 和 Javadoc。
为了更好地理解如何使用本书中使用的每个函数,我们建议您打开其中一个文档页面,并研究示例中使用的每种 OpenCV 库方法的不同用法。 作为建议,Doxygen 文档提供了有关 OpenCV 使用的更准确和扩展的信息。
读取,显示和保存图像
让我们看看如何在 OpenCV-Python 中加载图像。 创建一个名为first_program.py的文件,然后在您喜欢的代码编辑器中将其打开。 在当前文件夹中创建一个名为images的文件夹,并确保该文件夹中有一个名为input.jpg的图像。
完成后,将以下行添加到该 Python 文件中:
import cv2
img = cv2.imread(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/opencv-3x-py-example/img/input.jpg')
cv2.imshow('Input image', img)
cv2.waitKey()
如果运行上述程序,则会在新窗口中显示图像。
刚刚发生了什么?
让我们逐行地理解前面的代码。 在第一行中,我们将导入 OpenCV 库。 对于代码中将要使用的所有函数,我们都需要它。 在第二行中,我们正在读取图像并将其存储在变量中。 OpenCV 使用 NumPy 数据结构存储图像。 您可以通过http://www.numpy.org了解有关 NumPy 的更多信息。
因此,如果打开 Python shell 并键入以下内容,您将在终端上看到打印的数据类型:
> import cv2
> img = cv2.imread(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/opencv-3x-py-example/img/input.jpg')
> type(img)
<type 'numpy.ndarray'>
在下一行中,我们在新窗口中显示图像。 cv2.imshow中的第一个参数是窗口的名称。 第二个参数是您要显示的图像。
您一定想知道为什么我们在这里有最后一行。 函数cv2.waitKey()在 OpenCV 中用于键盘绑定。 它以数字作为参数,该数字表示时间(以毫秒为单位)。 基本上,我们使用此函数等待指定的持续时间,直到遇到键盘事件为止。 该程序此时停止,并等待您按任意键继续。 如果我们不传递任何参数,或者我们将其作为参数传递,则此函数将无限期地等待键盘事件。
最后一条语句cv2.waitKey(n)执行之前步骤中加载的图像的渲染。 它需要一个数字来表示渲染时间(以毫秒为单位)。 基本上,我们使用此函数等待指定的时间,直到遇到键盘事件。 该程序此时停止,并等待您按任意键继续。 如果我们不传递任何参数,或者如果传递 0 作为参数,则此函数将无限期地等待键盘事件。
加载和保存图像
OpenCV 提供了多种加载图像的方法。 假设我们要以灰度模式加载彩色图像,可以使用以下代码来实现:
import cv2
gray_img = cv2.imread('images/input.jpg', cv2.IMREAD_GRAYSCALE)
cv2.imshow('Grayscale', gray_img)
cv2.waitKey()
在这里,我们将 ImreadFlag 用作cv2.IMREAD_GRAYSCALE,并以灰度模式加载图像,尽管您可以在官方文档中找到更多读取模式。
您可以在新窗口中看到显示的图像。 这是输入图像:

以下是相应的灰度图像:

我们也可以将该图像另存为文件:
cv2.imwrite('images/output.jpg', gray_img)
这会将灰度图像保存为名为output.jpg的输出文件。 确保您对在 OpenCV 中阅读,显示和保存图像感到满意,因为在本书学习过程中我们将做很多事情。
更改图像格式
我们也可以将此图像另存为文件,并将原始图像格式更改为 PNG:
import cv2
img = cv2.imread('images/input.jpg')
cv2.imwrite('images/output.png', img, [cv2.IMWRITE_PNG_COMPRESSION])
imwrite()方法会将灰度图像保存为名为output.png的输出文件。 这是在IMWRITE标志和cv2.IMWRITE_PNG_COMPRESSION的帮助下使用 PNG 压缩完成的。 IMWRITE标志允许输出图像更改格式,甚至图像质量。
图像色彩空间
在计算机视觉和图像处理中,色彩空间是指组织色彩的特定方式。 颜色空间实际上是颜色模型和映射函数两件事的组合。 我们需要颜色模型的原因是因为它有助于我们使用元组表示像素值。 映射函数将颜色模型映射到可以表示的所有可能颜色的集合。
有许多有用的不同颜色空间。 一些较流行的颜色空间是 RGB,YUV,HSV,Lab 等。 不同的色彩空间提供不同的优势。 我们只需要选择适合给定问题的色彩空间即可。 我们来看几个色彩空间,看看它们提供了什么信息:
- RGB:可能是最受欢迎的色彩空间。 它代表红色,绿色和蓝色。 在此颜色空间中,每种颜色都表示为红色,绿色和蓝色的加权组合。 因此,每个像素值都表示为三个数字的元组,分别对应于红色,绿色和蓝色。 每个值的范围是 0 到 255。
- YUV:尽管 RGB 在许多方面都有好处,但对于许多现实生活中的应用而言,RGB 往往非常有限。 人们开始考虑将强度信息与颜色信息分开的不同方法。 因此,他们提出了 YUV 颜色空间。 Y 表示亮度或强度,U/V 通道表示颜色信息。 这在许多应用中效果很好,因为人类视觉系统感知到的强度信息与颜色信息大不相同。
- HSV:事实证明,即使 YUV 对于某些应用仍然不够好。 因此人们开始思考人类如何看待色彩,然后他们想到了 HSV 色彩空间。 HSV 代表色相,饱和度和值。 这是一个圆柱系统,其中我们将颜色的三个最主要的属性分开,并使用不同的通道表示它们。 这与人类视觉系统如何理解颜色密切相关。 这使我们在处理图像方面具有很大的灵活性。
转换色彩空间
考虑到所有颜色空间,OpenCV 中提供了大约 190 个转换选项。 如果要查看所有可用标志的列表,请转到 Python shell 并键入以下内容:
import cv2
print([x for x in dir(cv2) if x.startswith('COLOR_')])
您将看到 OpenCV 中可用于从一种颜色空间转换为另一种颜色空间的选项列表。 我们几乎可以将任何颜色空间转换为任何其他颜色空间。 让我们看看如何将彩色图像转换为灰度图像:
import cv2
img = cv2.imread(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/opencv-3x-py-example/img/input.jpg', cv2.IMREAD_COLOR)
gray_img = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY)
cv2.imshow('Grayscale image', gray_img)
cv2.waitKey()
刚刚发生了什么?
我们使用cvtColor函数转换色彩空间。 第一个参数是输入图像,第二个参数指定颜色空间转换。
分割图像通道
您可以使用以下标志转换为 YUV:
yuv_img = cv2.cvtColor(img, cv2.COLOR_BGR2YUV)
该图像将类似于以下内容:

这可能看起来像原始图像的降级版本,但事实并非如此。 让我们分离出三个通道:
# Alternative 1
y,u,v = cv2.split(yuv_img)
cv2.imshow('Y channel', y)
cv2.imshow('U channel', u)
cv2.imshow('V channel', v)
cv2.waitKey()
# Alternative 2 (Faster)
cv2.imshow('Y channel', yuv_img[:, :, 0])
cv2.imshow('U channel', yuv_img[:, :, 1])
cv2.imshow('V channel', yuv_img[:, :, 2])
cv2.waitKey()
由于yuv_img是 NumPy(提供维选择运算符),因此我们可以通过切片将其分离出来。 如果看yuv_img.shape,您会看到它是一个 3D 数组。 因此,运行前面的代码后,您将看到三个不同的图像。 以下是 Y 通道:

通道基本上是灰度图像。 接下来是 U 通道:

最后,V 通道:

正如我们在这里看到的,通道与灰度图像相同。 它代表强度值,通道代表颜色信息。
合并图像通道
现在,我们将读取图像,将其分成单独的通道,然后合并它们,以了解如何从不同的组合中获得不同的效果:
img = cv2.imread(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/opencv-3x-py-example/img/input.jpg', cv2.IMREAD_COLOR)
g,b,r = cv2.split(img)
gbr_img = cv2.merge((g,b,r))
rbr_img = cv2.merge((r,b,r))
cv2.imshow('Original', img)
cv2.imshow('GRB', gbr_img)
cv2.imshow('RBR', rbr_img)
cv2.waitKey()
在这里,我们可以看到如何重组通道以获得不同的颜色强度:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FxU5CVza-1681870901084)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/opencv-3x-py-example/img/f534b9e0-d766-44b1-a851-870b190373a3.png)]
在此示例中,红色通道使用了两次,因此红色更加强烈:

这应该为您提供有关如何在色彩空间之间进行转换的基本概念。 您可以在更多的色彩空间中玩耍,以查看图像的外观。 在随后的章节中,我们将讨论相关的色彩空间以及它们何时出现。
图像平移
在本节中,我们将讨论图像移位。 假设我们要在参照系内移动图像。 在计算机视觉术语中,这称为平移。 让我们继续前进,看看我们如何做到这一点:
import cv2
import numpy as np
img = cv2.imread('images/input.jpg')
num_rows, num_cols = img.shape[:2]
translation_matrix = np.float32([ [1,0,70], [0,1,110] ])
img_translation = cv2.warpAffine(img, translation_matrix, (num_cols, num_rows), cv2.INTER_LINEAR)
cv2.imshow('Translation', img_translation)
cv2.waitKey()
如果运行前面的代码,您将看到类似以下内容:

刚刚发生了什么?
要了解前面的代码,我们需要了解扭曲的工作原理。 平移基本上意味着我们通过添加/减去x和y坐标来移动图像。 为此,我们需要创建一个转换矩阵,如下所示:
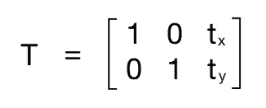
在此,t[x]和t[y]值是x和y平移值; 也就是说,图像将向右移动x个单位,向下移动y个单位。 因此,一旦创建了这样的矩阵,就可以使用函数warpAffine将其应用于图像。 warpAffine中的第三个参数指的是结果图像中的行数和列数。 如下所示,它通过了InterpolationFlags,它定义了插值方法的组合。
由于行数和列数与原始图像相同,因此最终图像将被裁剪。 原因是当我们应用转换矩阵时,输出中没有足够的空间。 为了避免裁剪,我们可以执行以下操作:
img_translation = cv2.warpAffine(img, translation_matrix,
(num_cols + 70, num_rows + 110))
如果将程序中的相应行替换为前一行,则会看到下图:
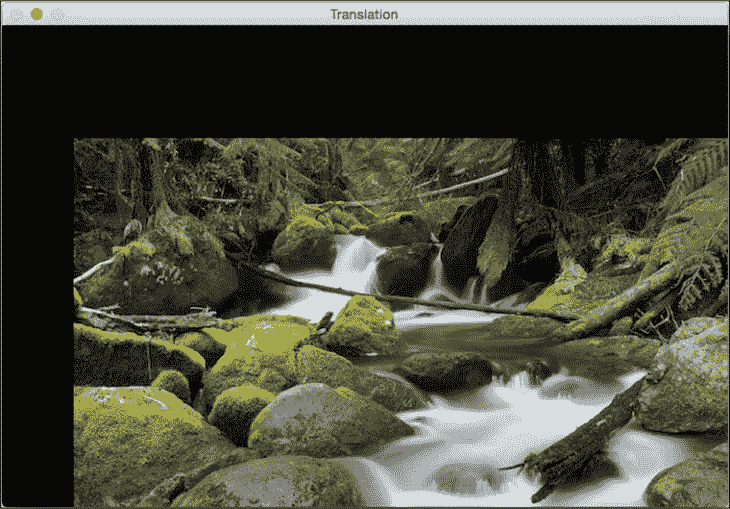
假设您要将图像移到更大图像帧的中间; 我们可以通过执行以下操作来做到这一点:
import cv2
import numpy as np
img = cv2.imread('images/input.jpg')
num_rows, num_cols = img.shape[:2]
translation_matrix = np.float32([ [1,0,70], [0,1,110] ])
img_translation = cv2.warpAffine(img, translation_matrix, (num_cols + 70, num_rows + 110))
translation_matrix = np.float32([ [1,0,-30], [0,1,-50] ])
img_translation = cv2.warpAffine(img_translation, translation_matrix, (num_cols + 70 + 30, num_rows + 110 + 50))
cv2.imshow('Translation', img_translation)
cv2.waitKey()
如果运行前面的代码,您将看到类似以下的图像:
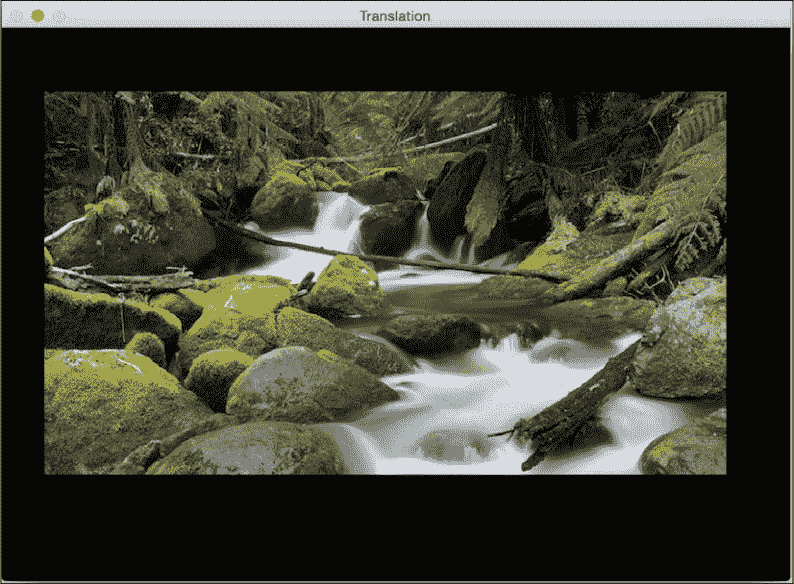
此外,还有另外两个参数borderMode和borderValue,这些参数使您可以使用像素外推法填充平移的空白边界:
import cv2
import numpy as np
img = cv2.imread(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/opencv-3x-py-example/img/input.jpg')
num_rows, num_cols = img.shape[:2]
translation_matrix = np.float32([ [1,0,70], [0,1,110] ])
img_translation = cv2.warpAffine(img, translation_matrix, (num_cols, num_rows), cv2.INTER_LINEAR, cv2.BORDER_WRAP, 1)
cv2.imshow('Translation', img_translation)
cv2.waitKey()

图像旋转
在本节中,我们将看到如何将给定图像旋转一定角度。 我们可以使用以下代码来做到这一点:
import cv2
import numpy as np
img = cv2.imread('images/input.jpg')num_rows, num_cols = img.shape[:2]
rotation_matrix = cv2.getRotationMatrix2D((num_cols/2, num_rows/2), 30, 0.7)
img_rotation = cv2.warpAffine(img, rotation_matrix, (num_cols, num_rows))
cv2.imshow('Rotation', img_rotation)
cv2.waitKey()
如果运行前面的代码,您将看到如下图像:

刚刚发生了什么?
使用getRotationMatrix2D,我们可以将图像围绕其旋转的中心点指定为第一个参数,然后指定旋转角度(以度为单位),最后指定图像的缩放比例。 我们使用 0.7 将图像缩小 30%,使其适合框架。
为了理解这一点,让我们看看我们如何数学地处理旋转。 旋转也是一种变换形式,我们可以使用以下变换矩阵来实现:
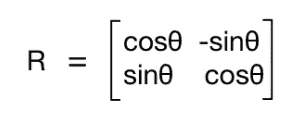
在此,θ是逆时针方向的旋转角度。 OpenCV 通过getRotationMatrix2D函数可以更好地控制此矩阵的创建。 我们可以指定围绕图像旋转的点,旋转角度(以度为单位)和图像的缩放因子。 一旦有了转换矩阵,就可以使用warpAffine函数将此矩阵应用于任何图像。
从上图中可以看到,图像内容超出范围并被裁剪。 为了防止这种情况,我们需要在输出图像中提供足够的空间。
让我们继续使用前面讨论的平移函数:
import cv2
import numpy as np
img = cv2.imread('images/input.jpg')
num_rows, num_cols = img.shape[:2]
translation_matrix = np.float32([ [1,0,int(0.5*num_cols)], [0,1,int(0.5*num_rows)] ])
rotation_matrix = cv2.getRotationMatrix2D((num_cols, num_rows), 30, 1)
img_translation = cv2.warpAffine(img, translation_matrix, (2*num_cols, 2*num_rows))
img_rotation = cv2.warpAffine(img_translation, rotation_matrix, (num_cols*2, num_rows*2))
cv2.imshow('Rotation', img_rotation)
cv2.waitKey()
如果运行前面的代码,我们将看到类似以下内容:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DQOsgHFr-1681870901086)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/opencv-3x-py-example/img/d75f3928-9e56-4732-a57a-3f001a921bf4.png)]
图像缩放
在本节中,我们将讨论调整图像的大小。 这是计算机视觉中最常见的操作之一。 我们可以使用缩放因子来调整图像的大小,也可以将其调整为特定的大小。 让我们看看如何做到这一点:
import cv2
img = cv2.imread('images/input.jpg')
img_scaled = cv2.resize(img,None,fx=1.2, fy=1.2, interpolation = cv2.INTER_LINEAR)
cv2.imshow('Scaling - Linear Interpolation', img_scaled)
img_scaled = cv2.resize(img,None,fx=1.2, fy=1.2, interpolation = cv2.INTER_CUBIC)
cv2.imshow('Scaling - Cubic Interpolation', img_scaled)
img_scaled = cv2.resize(img,(450, 400), interpolation = cv2.INTER_AREA)
cv2.imshow('Scaling - Skewed Size', img_scaled)
cv2.waitKey()
刚刚发生了什么?
每当我们调整图像大小时,都有多种方法可以填充像素值。 放大图像时,需要在像素位置之间填充像素值。 在缩小图像时,我们需要获得最佳的代表值。 当我们按非整数值缩放时,我们需要适当地插值,以便保持图像的质量。 有多种插值方法。 如果要放大图像,则最好使用线性或三次插值。 如果要缩小图像,则最好使用基于区域的插值。 三次插值在计算上更复杂,因此比线性插值要慢。 但是,最终图像的质量会更高。
OpenCV 提供了一个称为调整大小的函数来实现图像缩放。 如果未指定大小(通过使用None),则它将期望x和y缩放因子。 在我们的示例中,图像将放大 1.2 倍。 如果使用三次插值进行相同的放大,则可以看到质量有所提高,如下图所示。 以下屏幕截图显示了线性插值的形式:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0Pxk5ggw-1681870901086)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/opencv-3x-py-example/img/7d905530-6480-4d33-9d28-dea78be81288.png)]
这是对应的三次插值:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4a6d9fj5-1681870901087)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/opencv-3x-py-example/img/c0772825-4f0b-483f-af34-92c65a651d90.png)]
如果我们想将其调整为特定大小,可以使用最后一个调整大小实例中显示的格式。 我们基本上可以倾斜图像并将其调整为所需的大小。 输出将类似于以下内容:

仿射变换
在本节中,我们将讨论 2D 图像的各种广义几何变换。 在最后两节中,我们已经大量使用了warpAffine函数,现在是时候了解下面发生的事情了。
在讨论仿射变换之前,让我们了解什么是欧几里得变换。 欧几里德变换是保留长度和角度量度的一种几何变换。 如果我们采用几何形状并对其进行欧几里德变换,则该形状将保持不变。 它看起来可能旋转,移位等等,但是基本结构不会改变。 因此,从技术上讲,线将保留为线,平面将保留为平面,正方形将保留为正方形,圆形将保留为圆形。
回到仿射变换,可以说它们是欧几里得变换的概括。 在仿射变换的范围内,线将保留为线,但正方形可能会变成矩形或平行四边形。 基本上,仿射变换不会保留长度和角度。
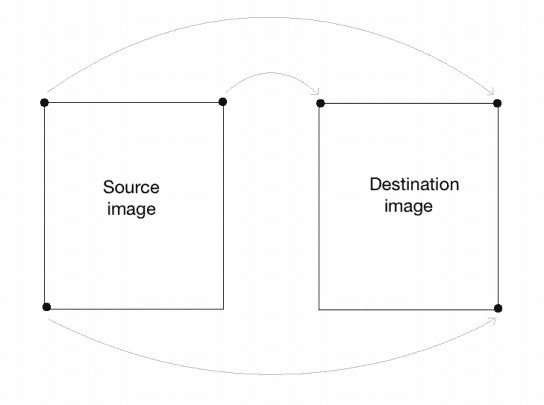
为了构建通用仿射变换矩阵,我们需要定义控制点。 一旦有了这些控制点,就需要确定我们希望将它们映射到何处。 在这种特殊情况下,我们需要的是源图像中的三个点,以及输出图像中的三个点。 让我们看看如何将图像转换为类似平行四边形的图像:
import cv2
import numpy as np
img = cv2.imread('images/input.jpg')
rows, cols = img.shape[:2]
src_points = np.float32([[0,0], [cols-1,0], [0,rows-1]])
dst_points = np.float32([[0,0], [int(0.6*(cols-1)),0], [int(0.4*(cols-1)),rows-1]])
affine_matrix = cv2.getAffineTransform(src_points, dst_points)
img_output = cv2.warpAffine(img, affine_matrix, (cols,rows))
cv2.imshow('Input', img)
cv2.imshow('Output', img_output)
cv2.waitKey()
刚刚发生了什么?
如前所述,我们正在定义控制点。 我们只需要三个点就可以得到仿射变换矩阵。 我们希望将src_points中的三个点映射到dst_points中的相应点。 我们正在映射点,如下图所示:
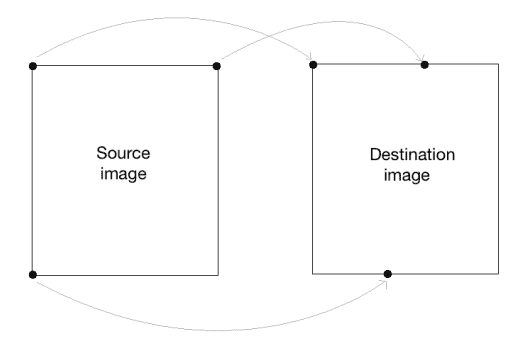
为了获得转换矩阵,我们在 OpenCV 中有一个函数。 有了仿射变换矩阵后,就可以使用该函数将该矩阵应用于输入图像。
以下是输入图像:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8fARNGPS-1681870901087)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/opencv-3x-py-example/img/4ab715df-96bb-4a15-abe9-48318f8f8a2e.png)]
如果运行前面的代码,则输出将类似于以下内容:
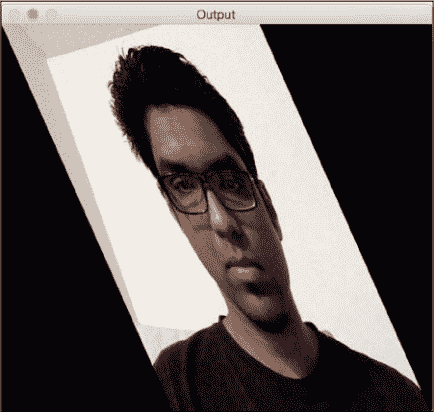
我们还可以获取输入图像的镜像。 我们只需要通过以下方式更改控制点:
src_points = np.float32([[0,0], [cols-1,0], [0,rows-1]])
dst_points = np.float32([[cols-1,0], [0,0], [cols-1,rows-1]])
在这里,映射看起来像这样:
如果用这两行替换仿射变换代码中的相应行,则会得到以下结果:

投影变换
仿射转换很不错,但是有一定的限制。 另一方面,投射性的转换给了我们更多的自由。 为了理解投影变换,我们需要了解投影几何如何工作。 我们基本上描述了当视角改变时图像会发生什么。 例如,如果您正站在一张纸上画有正方形的前面,它将看起来像一个正方形。
现在,如果您开始倾斜那张纸,则正方形将开始越来越像梯形。 投影变换使我们能够以一种很好的数学方式捕获这种动态。 这些变换既不保留大小也不保留角度,但确实保留了入射和交叉比率。
您可以在这个页面和这个页面上了解更多有关发生率和交叉比率的信息。
现在我们知道了投影变换是什么,让我们看看是否可以在此处提取更多信息。 可以说,给定平面上的任何两个图像都是由单应性相关的。 只要它们在同一平面上,我们就可以将任何东西转换成其他东西。 这具有许多实际应用,例如增强现实,图像校正,图像配准或两个图像之间的相机运动计算。 一旦从估计的单应性矩阵中提取了摄像机的旋转和平移,此信息即可用于导航,或将 3D 对象的模型插入图像或视频。 这样,它们将以正确的透视图进行渲染,看起来它们就像是原始场景的一部分。
让我们继续前进,看看如何做到这一点:
import cv2
import numpy as np
img = cv2.imread('images/input.jpg')
rows, cols = img.shape[:2]
src_points = np.float32([[0,0], [cols-1,0], [0,rows-1], [cols-1,rows-1]])
dst_points = np.float32([[0,0], [cols-1,0], [int(0.33*cols),rows-1], [int(0.66*cols),rows-1]])
projective_matrix = cv2.getPerspectiveTransform(src_points, dst_points)
img_output = cv2.warpPerspective(img, projective_matrix, (cols,rows))
cv2.imshow('Input', img)
cv2.imshow('Output', img_output)
cv2.waitKey()
如果运行前面的代码,您将看到有趣的输出,例如以下屏幕截图:
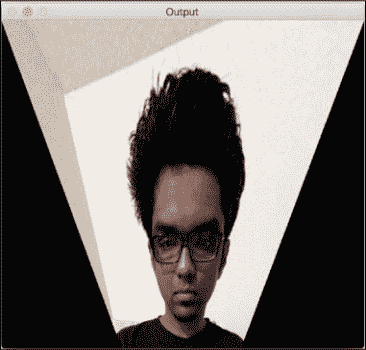
刚刚发生了什么?
我们可以在源图像中选择四个控制点,并将它们映射到目标图像。 转换后,平行线将不会保持平行线。 我们使用一个名为getPerspectiveTransform的函数来获取变换矩阵。
让我们使用投影变换应用几个有趣的效果,然后看它们的外观。 我们需要做的就是更改控制点以获得不同的效果。
这是一个例子:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WR205U58-1681870901088)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/opencv-3x-py-example/img/b3c69a1b-29f5-40b4-9b7b-07e0b1748918.png)]
控制点如下:
src_points = np.float32([[0,0], [0,rows-1], [cols/2,0],[cols/2,rows-1]])
dst_points = np.float32([[0,100], [0,rows-101], [cols/2,0],[cols/2,rows-1]])
作为练习,您应该在平面上映射前面的点,并查看如何映射这些点(就像我们前面讨论仿射变换时所做的一样)。 您将对映射系统有一个很好的了解,并且可以创建自己的控制点。 如果要在y轴上获得相同的效果,可以应用以前的变换。
图像变形
让我们对图像有更多的乐趣,看看还能实现什么。 投影变换非常灵活,但是它们仍然对我们如何变换点施加了一些限制。 如果我们想做完全随机的事情怎么办? 我们需要更多的控制权,对不对? 碰巧我们也可以做到这一点。 我们只需要创建自己的映射即可,这并不困难。 以下是通过图像变形可以实现的一些效果:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mQG1ZVoK-1681870901088)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/opencv-3x-py-example/img/05a0eb65-3ec5-49e2-bd9d-981d0829dc6d.png)]
这是创建这些效果的代码:
import cv2
import numpy as np
import math
img = cv2.imread('images/input.jpg', cv2.IMREAD_GRAYSCALE)
rows, cols = img.shape
#####################
# Vertical wave
img_output = np.zeros(img.shape, dtype=img.dtype)
for i in range(rows):
for j in range(cols):
offset_x = int(25.0 * math.sin(2 * 3.14 * i / 180))
offset_y = 0
if j+offset_x < rows:
img_output[i,j] = img[i,(j+offset_x)%cols]
else:
img_output[i,j] = 0
cv2.imshow('Input', img)
cv2.imshow('Vertical wave', img_output)
#####################
# Horizontal wave
img_output = np.zeros(img.shape, dtype=img.dtype)
for i in range(rows):
for j in range(cols):
offset_x = 0
offset_y = int(16.0 * math.sin(2 * 3.14 * j / 150))
if i+offset_y < rows:
img_output[i,j] = img[(i+offset_y)%rows,j]
else:
img_output[i,j] = 0
cv2.imshow('Horizontal wave', img_output)
#####################
# Both horizontal and vertical
img_output = np.zeros(img.shape, dtype=img.dtype)
for i in range(rows):
for j in range(cols):
offset_x = int(20.0 * math.sin(2 * 3.14 * i / 150))
offset_y = int(20.0 * math.cos(2 * 3.14 * j / 150))
if i+offset_y < rows and j+offset_x < cols:
img_output[i,j] = img[(i+offset_y)%rows,(j+offset_x)%cols]
else:
img_output[i,j] = 0
cv2.imshow('Multidirectional wave', img_output)
#####################
# Concave effect
img_output = np.zeros(img.shape, dtype=img.dtype)
for i in range(rows):
for j in range(cols):
offset_x = int(128.0 * math.sin(2 * 3.14 * i / (2*cols)))
offset_y = 0
if j+offset_x < cols:
img_output[i,j] = img[i,(j+offset_x)%cols]
else:
img_output[i,j] = 0
cv2.imshow('Concave', img_output)
cv2.waitKey()
总结
在本章中,我们学习了如何在各种平台上安装 OpenCV-Python。 我们讨论了如何读取,显示和保存图像。 我们讨论了各种颜色空间的重要性,以及如何将其转换为多个颜色空间,拆分和合并它们。 我们学习了如何将几何变换应用于图像,并了解了如何使用这些变换来实现炫酷的几何效果。 我们讨论了转换矩阵的基本表示形式,以及如何根据需要制定不同类型的转换。 我们学习了如何根据所需的几何变换选择控制点。 我们讨论了投影变换,并学习了如何使用图像变形来实现任何给定的几何效果。
在下一章中,我们将讨论边缘检测和图像过滤。 我们可以使用图像过滤器来应用许多视觉效果,并且底层结构为我们提供了许多以创造性方式操作图像的自由。
二、检测边缘并应用图像过滤器
在本章中,我们将了解如何将酷炫的视觉效果应用于图像。 我们将学习如何使用基本的图像处理运算符,讨论边缘检测,以及如何使用图像过滤器将各种效果应用于照片。
在本章结束时,您将了解:
- 什么是 2D 卷积以及如何使用
- 如何模糊图像
- 如何检测图像边缘
- 如何将运动模糊应用于图像
- 如何锐化和浮雕图像
- 如何腐蚀和扩大图像
- 如何创建晕影过滤器
- 如何增强图像对比度
2D 卷积
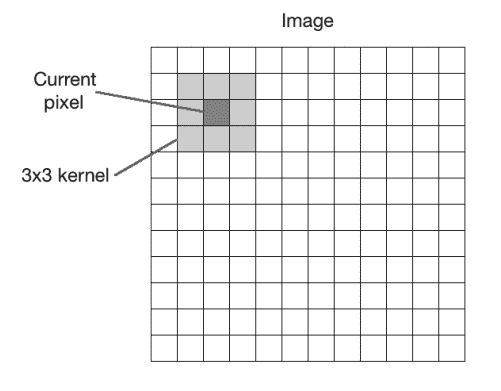
卷积是图像处理中的基本操作。 我们基本上将数学运算符应用于每个像素,并以某种方式更改其值。 为了应用该数学运算符,我们使用另一个称为核的矩阵。 核的大小通常比输入图像小得多。 对于图像中的每个像素,我们将核放在顶部,以使核的中心与所考虑的像素重合。 然后,我们将核矩阵中的每个值与图像中的相应值相乘,然后将其求和。 这是将应用于输出图像中该位置的新值。
在这里,核称为图像过滤器,而将此核应用于给定图像的过程称为图像过滤。 将核应用于图像后获得的输出称为滤波图像。 根据核中的值,它执行不同的功能,例如模糊,检测边缘等。 下图应帮助您可视化图像过滤操作:
让我们从最简单的情况开始,即身份核。 这个核并没有真正改变输入图像。 如果我们考虑一个3x3身份核,它看起来类似于以下内容:

模糊化
模糊是指对邻域内的像素值求平均。 这也称为低通过滤器。 低通过滤器是允许低频并阻止高频的过滤器。 现在,我们想到的下一个问题是:频率在图像中意味着什么? 嗯,在这种情况下,频率是指像素值的变化率。 因此,可以说尖锐的边缘将是高频内容,因为像素值在该区域中快速变化。 按照这种逻辑,平原区域将是低频内容。 按照这个定义,低通过滤器将尝试平滑边缘。
构造低通过滤器的一种简单方法是均匀地平均像素附近的值。 我们可以根据要平滑图像的程度来选择核的大小,并且相应地会有不同的效果。 如果您选择更大的尺寸,那么您将在更大的区域进行平均。 这趋于增加平滑效果。 让我们看一下3x3低通过滤器核的样子:
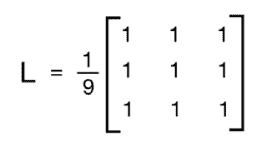
我们将矩阵除以 9,因为我们希望这些值的总和为 1。 这称为归一化,这一点很重要,因为我们不想人为地增加该像素位置的强度值。 因此,您应该在将核应用于图像之前对其进行规范化。 规范化是一个非常重要的概念,它在多种情况下都可以使用,因此您应该在线阅读一些教程以很好地了解它。
这是将低通过滤器应用于图像的代码:
import cv2
import numpy as np
img = cv2.imread('images/input.jpg')
rows, cols = img.shape[:2]
kernel_identity = np.array([[0,0,0], [0,1,0], [0,0,0]])
kernel_3x3 = np.ones((3,3), np.float32) / 9.0 # Divide by 9 to normalize the kernel
kernel_5x5 = np.ones((5,5), np.float32) / 25.0 # Divide by 25 to normalize the kernel
cv2.imshow('Original', img)
# value -1 is to maintain source image depth
output = cv2.filter2D(img, -1, kernel_identity) cv2.imshow('Identity filter', output)
output = cv2.filter2D(img, -1, kernel_3x3)
cv2.imshow('3x3 filter', output)
output = cv2.filter2D(img, -1, kernel_5x5)
cv2.imshow('5x5 filter', output)
cv2.waitKey(0)
如果运行前面的代码,您将看到类似以下内容:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-aRYH5vJm-1681870901090)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/opencv-3x-py-example/img/f6a39ae5-b981-419d-8326-ca3e8c690e63.png)]
核大小与模糊
在前面的代码中,我们在代码中生成了kernel_identity,kernel_3x3和kernel_5x5不同的核。 我们使用filter2D函数将这些核应用于输入图像。 如果仔细查看图像,您会发现随着我们增加核大小,它们会变得越来越模糊。 其原因是因为当我们增加核大小时,我们在更大的区域进行平均。 这往往具有较大的模糊效果。
另一种执行此操作的方法是使用 OpenCV 函数blur。 如果您不想自己生成核,则可以直接使用此函数。 我们可以使用以下代码行来调用它:
output = cv2.blur(img, (3,3))
这会将3x3核应用于输入,并直接为您提供输出。
运动模糊
当我们应用运动模糊效果时,看起来就像是您沿特定方向移动时捕获的图片。 例如,您可以使图像看起来像是从行驶中的汽车上捕获的。
输入和输出图像将类似于以下图像:

以下是实现这种运动模糊效果的代码:
import cv2
import numpy as np
img = cv2.imread('images/input.jpg')
cv2.imshow('Original', img)
size = 15
# generating the kernel
kernel_motion_blur = np.zeros((size, size))
kernel_motion_blur[int((size-1)/2), :] = np.ones(size)
kernel_motion_blur = kernel_motion_blur / size
# applying the kernel to the input image
output = cv2.filter2D(img, -1, kernel_motion_blur)
cv2.imshow('Motion Blur', output)
cv2.waitKey(0)
底层原理
我们正在照常读取图像。 然后,我们正在构建运动blur核。 运动模糊核会在特定方向上平均像素值。 就像定向低通过滤器。 3x3水平运动模糊核看起来像这样:
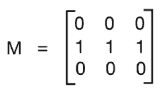
这将使图像在水平方向上模糊。 您可以选择任何方向,它将相应地起作用。 模糊的数量将取决于核的大小。 因此,如果要使图像模糊,只需为核选择更大的尺寸即可。 为了看到全部效果,我们在前面的代码中采用了15x15核。 然后,我们使用filter2D将此核应用于输入图像,以获得运动模糊的输出。
锐化
应用锐化过滤器将锐化图像中的边缘。 当我们要增强不够清晰的图像边缘时,此过滤器非常有用。 以下是一些图像,可让您大致了解图像锐化过程的外观:

如上图所示,锐化程度取决于我们使用的核类型。 我们在这里可以自由定制核,每个核都会给您一种不同的锐化方法。 要像在上一张图片的右上角图像中那样锐化图像,我们将使用这样的核:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kEdYmXcD-1681870901092)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/opencv-3x-py-example/img/32e9bc1f-b7ac-4bc8-b7b8-c113c5cd3985.png)]
如果要进行过度锐化,如左下图所示,我们将使用以下核:
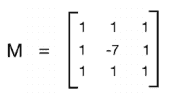
但是,这两个核的问题在于输出图像看起来是人为增强的。 如果我们希望图像看起来更自然,可以使用边缘增强过滤器。 基本概念保持不变,但是我们使用近似的高斯核来构建此过滤器。 当我们增强边缘时,它将帮助我们平滑图像,从而使图像看起来更自然。
这是实现上述屏幕快照中所应用效果的代码:
import cv2
import numpy as np
img = cv2.imread('images/input.jpg')
cv2.imshow('Original', img)
# generating the kernels
kernel_sharpen_1 = np.array([[-1,-1,-1], [-1,9,-1], [-1,-1,-1]])
kernel_sharpen_2 = np.array([[1,1,1], [1,-7,1], [1,1,1]])
kernel_sharpen_3 = np.array([[-1,-1,-1,-1,-1],
[-1,2,2,2,-1],
[-1,2,8,2,-1],
[-1,2,2,2,-1],
[-1,-1,-1,-1,-1]]) / 8.0
# applying different kernels to the input image
output_1 = cv2.filter2D(img, -1, kernel_sharpen_1)
output_2 = cv2.filter2D(img, -1, kernel_sharpen_2)
output_3 = cv2.filter2D(img, -1, kernel_sharpen_3)
cv2.imshow('Sharpening', output_1)
cv2.imshow('Excessive Sharpening', output_2)
cv2.imshow('Edge Enhancement', output_3)
cv2.waitKey(0)
如果您注意到,在前面的代码中,我们没有将前两个核除以归一化因子。 这样做的原因是核内部的值总和为 1,因此我们将矩阵隐式除以 1。
了解模式
您一定已经在图像过滤代码示例中注意到了一种常见模式。 我们构建一个核,然后使用filter2D获得所需的输出。 这也正是此代码示例中发生的事情! 您可以使用核中的值,看看是否可以获得不同的视觉效果。 确保在应用核之前对核进行了标准化,否则图像将显得太亮,因为您是在人为地增加图像中的像素值。
浮雕
浮雕过滤器将拍摄图像并将其转换为浮雕图像。 我们基本上会获取每个像素,然后将其替换为阴影或高光。 假设我们正在处理图像中相对较平坦的区域。 在这里,我们需要用纯灰色代替它,因为那里没有太多信息。 如果在特定区域有很多对比度,我们将根据浮雕的方向将其替换为白色像素(高光)或深色像素(阴影)。
它将是这样的:

让我们看一下代码,看看如何做到这一点:
import cv2
import numpy as np
img_emboss_input = cv2.imread('images/input.jpg')
# generating the kernels
kernel_emboss_1 = np.array([[0,-1,-1],
[1,0,-1],
[1,1,0]])
kernel_emboss_2 = np.array([[-1,-1,0],
[-1,0,1],
[0,1,1]])
kernel_emboss_3 = np.array([[1,0,0],
[0,0,0],
[0,0,-1]])
# converting the image to grayscale
gray_img = cv2.cvtColor(img_emboss_input,cv2.COLOR_BGR2GRAY)
# applying the kernels to the grayscale image and adding the offset to produce the shadow
output_1 = cv2.filter2D(gray_img, -1, kernel_emboss_1) + 128
output_2 = cv2.filter2D(gray_img, -1, kernel_emboss_2) + 128
output_3 = cv2.filter2D(gray_img, -1, kernel_emboss_3) + 128
cv2.imshow('Input', img_emboss_input)
cv2.imshow('Embossing - South West', output_1)
cv2.imshow('Embossing - South East', output_2)
cv2.imshow('Embossing - North West', output_3)
cv2.waitKey(0)
如果运行前面的代码,您将看到输出图像已浮雕。 从前面的核可以看到,我们只是将当前像素值替换为特定方向上相邻像素值的差。 通过将图像中的所有像素值都偏移128来实现浮雕效果。 此操作将高光/阴影效果添加到图片。
边缘检测
边缘检测的过程涉及检测图像中的尖锐边缘,并生成二进制图像作为输出。 通常,我们在黑色背景上绘制白线以指示这些边缘。 我们可以将边缘检测视为高通滤波操作。 高通过滤器允许高频内容通过并阻止低频内容。 如前所述,边缘是高频内容。 在边缘检测中,我们要保留这些边缘并丢弃其他所有内容。 因此,我们应该构建一个等效于高通过滤器的核。
让我们从一个称为Sobel过滤器的简单边缘检测过滤器开始。 由于边缘会同时出现在水平和垂直方向,因此Sobel过滤器由以下两个核组成:

左侧的核检测水平边缘,右侧的核检测垂直边缘。 OpenCV 提供了直接将Sobel过滤器应用于给定图像的函数。 这是使用 Sobel 过滤器检测边缘的代码:
import cv2
import numpy as np
img = cv2.imread('images/input_shapes.png', cv2.IMREAD_GRAYSCALE)
rows, cols = img.shape
# It is used depth of cv2.CV_64F.
sobel_horizontal = cv2.Sobel(img, cv2.CV_64F, 1, 0, ksize=5)
# Kernel size can be: 1,3,5 or 7.
sobel_vertical = cv2.Sobel(img, cv2.CV_64F, 0, 1, ksize=5)
cv2.imshow('Original', img)
cv2.imshow('Sobel horizontal', sobel_horizontal)
cv2.imshow('Sobel vertical', sobel_vertical)
cv2.waitKey(0)
对于 8 位输入图像,这将导致截断的导数,因此可以使用深度值cv2.CV_16U代替。 如果边缘定义不明确,可以调整核的值,将其设置为较小可获得较薄的边缘,而对于相反的目的则为较大。
输出将类似于以下内容:

在上图中,中间的图像是水平边缘检测器的输出,而右边的图像是垂直边缘检测器。 正如我们在这里看到的,Sobel过滤器可以检测水平或垂直方向上的边缘,并且不能为我们提供所有边缘的整体视图。 为了克服这个问题,我们可以使用Laplacian过滤器。 使用此过滤器的优点是它在两个方向上都使用了双导数。 您可以使用以下行来调用该函数:
laplacian = cv2.Laplacian(img, cv2.CV_64F)
输出将类似于以下屏幕截图:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4FxDK6cj-1681870901093)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/opencv-3x-py-example/img/e7458f9f-6cc7-477c-8541-fd9b16c44ae2.png)]
即使Laplacian核在这种情况下也能很好地工作,但它并不总是能很好地工作。 如下面的屏幕快照所示,这会在输出中引起很多噪声。 这是Canny边缘检测器派上用场的地方:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Aj0OFvzR-1681870901094)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/opencv-3x-py-example/img/f51ac394-4b50-4ca2-80f0-5914928cc8d4.png)]
正如我们在前面的图像中看到的,Laplacian核会产生一个嘈杂的输出,这并不是完全有用的。 为了克服这个问题,我们使用了Canny边缘检测器。 要使用Canny边缘检测器,我们可以使用以下函数:
canny = cv2.Canny(img, 50, 240)
如我们所见,Canny边缘检测器的质量要好得多。 它使用两个数字作为参数来指示阈值。 第二个参数称为低阈值值,第三个参数称为高阈值值。 如果梯度值超出高阈值,则将其标记为强边缘。 Canny边缘检测器从此点开始跟踪边缘,并继续进行处理,直到梯度值降至低阈值以下。 随着增加这些阈值,较弱的边缘将被忽略。 输出图像将更清晰,更稀疏。 您可以尝试使用阈值,并查看增加或减小阈值会发生什么。 总体表述很深。 您可以通过以下网址了解更多信息。
侵蚀和膨胀
侵蚀和膨胀是形态图像处理操作。 形态图像处理基本上涉及修改图像中的几何结构。 这些操作主要是为二进制图像定义的,但是我们也可以在灰度图像上使用它们。 侵蚀基本上剥夺了结构中最外面的像素层,而膨胀使结构增加了额外的像素层。
让我们看看这些操作是什么样的:

以下是实现此目的的代码:
import cv2
import numpy as np
img = cv2.imread('images/input.jpg', 0)
kernel = np.ones((5,5), np.uint8)
img_erosion = cv2.erode(img, kernel, iterations=1)
img_dilation = cv2.dilate(img, kernel, iterations=1)
cv2.imshow('Input', img)
cv2.imshow('Erosion', img_erosion)
cv2.imshow('Dilation', img_dilation)
cv2.waitKey(0)
事后思考
OpenCV 提供直接腐蚀和扩大图像的函数。 它们分别称为腐蚀和膨胀。 值得注意的是这两个函数中的第三个参数。 迭代次数将确定您要腐蚀/扩大给定图像的数量。 它基本上将操作顺序地应用于所得图像。 您可以拍摄样本图像,并使用此参数来查看结果。
创建晕影过滤器
使用我们拥有的所有信息,让我们看看是否可以创建一个漂亮的小插图过滤器。 输出将类似于以下内容:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4qbcpG00-1681870901095)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/opencv-3x-py-example/img/5103d772-52a4-4ba9-9052-2de6a7fdb88e.png)]
这是实现此效果的代码:
import cv2
import numpy as np
img = cv2.imread('images/input.jpg')
rows, cols = img.shape[:2]
# generating vignette mask using Gaussian kernels
kernel_x = cv2.getGaussianKernel(cols,200)
kernel_y = cv2.getGaussianKernel(rows,200)
kernel = kernel_y * kernel_x.T
mask = 255 * kernel / np.linalg.norm(kernel)
output = np.copy(img)
# applying the mask to each channel in the input image
for i in range(3):
output[:,:,i] = output[:,:,i] * mask
cv2.imshow('Original', img)
cv2.imshow('Vignette', output)
cv2.waitKey(0)
到底发生了什么?
晕影过滤器基本上将亮度聚焦在图像的特定部分上,而其他部分则显得褪色。 为了实现这一点,我们需要使用高斯核过滤掉图像中的每个通道。 OpenCV 提供了执行此操作的函数,称为getGaussianKernel。 我们需要构建一个 2D 核,其大小与图像的大小匹配。 函数的第二个参数getGaussianKernel很有趣。 它是高斯的标准差,它控制明亮的中心区域的半径。 您可以试用此参数,并查看它如何影响输出。
构建 2D 核后,需要通过标准化该核并按比例放大来构建遮罩,如以下行所示:
mask = 255 * kernel / np.linalg.norm(kernel)
这是重要的一步,因为如果您不按比例放大图像,图像将看起来很黑。 发生这种情况是因为在将遮罩叠加在输入图像上之后,所有像素值都将接近于零。 此后,我们遍历所有颜色通道并将遮罩应用于每个通道。
我们如何转移焦点?
现在,我们知道如何创建聚焦于图像中心的小插图过滤器。 假设我们要实现相同的晕影效果,但我们要关注图像中的其他区域,如下图所示:

我们需要做的是建立一个更大的高斯核,并确保该峰与兴趣区域重合。 以下是实现此目的的代码:
import cv2
import numpy as np
img = cv2.imread('images/input.jpg')
rows, cols = img.shape[:2]
# generating vignette mask using Gaussian kernels
kernel_x = cv2.getGaussianKernel(int(1.5*cols),200)
kernel_y = cv2.getGaussianKernel(int(1.5*rows),200)
kernel = kernel_y * kernel_x.T
mask = 255 * kernel / np.linalg.norm(kernel)
mask = mask[int(0.5*rows):, int(0.5*cols):]
output = np.copy(img)
# applying the mask to each channel in the input image
for i in range(3):
output[:,:,i] = output[:,:,i] * mask
cv2.imshow('Input', img)
cv2.imshow('Vignette with shifted focus', output)
cv2.waitKey(0)
增强图像的对比度
每当我们在弱光条件下拍摄图像时,图像就会变暗。 当您在晚上或昏暗的房间中拍摄图像时,通常会发生这种情况。 您一定已经多次看到这种情况! 发生这种情况的原因是,当我们在这种条件下捕获图像时,像素值趋于集中在零附近。 发生这种情况时,人眼无法清晰看到图像中的许多细节。 人眼喜欢对比度,因此我们需要调整对比度以使图像看起来既美观又令人愉悦。 许多相机和照片应用已经隐式地执行了此操作。 我们使用称为直方图均衡的过程来实现这一目标。
举个例子,这是对比度增强前后的样子:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KF1TATov-1681870901095)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/opencv-3x-py-example/img/c81ff785-75d5-4d34-bb7a-949c6ea9dc94.png)]
如我们在这里看到的,左侧的输入图像确实很暗。 为了解决这个问题,我们需要调整像素值,以使它们分布在整个值范围内,即介于 0-255 之间。
以下是用于调整像素值的代码:
import cv2
import numpy as np
img = cv2.imread('images/input.jpg', 0)
# equalize the histogram of the input image
histeq = cv2.equalizeHist(img)
cv2.imshow('Input', img)
cv2.imshow('Histogram equalized', histeq)
cv2.waitKey(0)
直方图均衡化适用于灰度图像。 OpenCV 提供了equalizeHist函数来实现此效果。 就像我们在这里看到的那样,代码非常简单,我们读取图像并均衡其直方图以归一化亮度并增加图像的对比度。
我们如何处理彩色图像?
既然我们知道如何均衡灰度图像的直方图,您可能想知道如何处理彩色图像。 直方图均衡化是一个非线性过程。 因此,我们不能仅将 RGB 图像中的三个通道分离出来,分别对直方图进行均衡,然后再将它们组合以形成输出图像。 直方图均衡化的概念仅适用于图像中的强度值。 因此,我们必须确保在进行此操作时不要修改颜色信息。
为了处理彩色图像的直方图均衡化,我们需要将其转换为色彩空间,其中强度与色彩信息分开。 YUV 是这种颜色空间的一个很好的例子,因为 YUV 模型根据一个亮度(Y)和两个色度(UV)成分。 一旦将其转换为 YUV,我们只需要均衡 Y 通道并将其与其他两个通道组合即可获得输出图像。
以下是其外观的示例:

这是实现彩色图像直方图均衡的代码:
import cv2
import numpy as np
img = cv2.imread('images/input.jpg')
img_yuv = cv2.cvtColor(img, cv2.COLOR_BGR2YUV)
# equalize the histogram of the Y channel
img_yuv[:,:,0] = cv2.equalizeHist(img_yuv[:,:,0])
# convert the YUV image back to RGB format
img_output = cv2.cvtColor(img_yuv, cv2.COLOR_YUV2BGR)
cv2.imshow('Color input image', img)
cv2.imshow('Histogram equalized', img_output)
cv2.waitKey(0)
总结
在本章中,我们学习了如何使用图像过滤器将酷炫的视觉效果应用于图像。 我们讨论了基本的图像处理运算符,以及如何使用它们来构建各种东西。 我们学习了如何使用各种方法检测边缘。 我们了解了 2D 卷积的重要性以及如何在不同的场景中使用它。 我们讨论了如何使图像平滑,运动模糊,锐化,浮雕,腐蚀和扩大图像。 我们学习了如何创建晕影过滤器,以及如何更改焦点区域。 我们讨论了对比度增强以及如何使用直方图均衡来实现它。
在下一章中,我们将讨论如何对给定图像进行卡通化。
三、卡通化图像
在本章中,我们将学习如何将图像转换为卡通图像。 我们将学习如何在实时视频流中访问网络摄像头并进行键盘/鼠标输入。 我们还将学习一些高级图像过滤器,并了解如何使用它们来对输入视频进行卡通化。
在本章结束时,您将了解:
- 如何访问网络摄像头
- 如何在实时视频流中进行键盘和鼠标输入
- 如何创建一个交互式应用
- 如何使用高级图像过滤器
- 如何将图像卡通化
访问网络摄像头
我们可以使用网络摄像头的实时视频流构建非常有趣的应用。 OpenCV 提供了一个视频捕获对象,该对象可以处理与网络摄像头的打开和关闭有关的所有事情。 我们需要做的就是创建该对象并保持从中读取帧。
以下代码将打开网络摄像机,捕获帧,将它们按比例缩小 2 倍,然后在窗口中显示它们。 您可以按Esc键退出:
import cv2
cap = cv2.VideoCapture(0)
# Check if the webcam is opened correctly
if not cap.isOpened():
raise IOError("Cannot open webcam")
while True:
ret, frame = cap.read()
frame = cv2.resize(frame, None, fx=0.5, fy=0.5, interpolation=cv2.INTER_AREA)
cv2.imshow('Input', frame)
c = cv2.waitKey(1)
if c == 27:
break
cap.release()
cv2.destroyAllWindows()
底层原理
如我们在前面的代码中看到的,我们使用 OpenCV 的VideoCapture函数创建视频捕获对象上限。 创建完毕后,我们将开始无限循环并不断从网络摄像头读取帧,直到遇到键盘中断为止。
在while循环的第一行中,我们有以下行:
ret, frame = cap.read()
此处,ret是由read函数返回的布尔值,它指示是否成功捕获了帧。 如果正确捕获了帧,则将其存储在变量frame中。 该循环将一直运行,直到我们按Esc键。 因此,我们继续在以下行中检查键盘中断:
if c == 27:
众所周知,Esc的 ASCII 值为 27。一旦遇到它,我们就会中断循环并释放视频捕获对象。 cap.release()行很重要,因为它可以正常释放网络摄像头资源,以便其他应用可以使用它。
扩展捕获选项
在前面讨论的代码中,cv2.VideoCapture(0)使用自动检测到的读取器实现定义了默认连接的网络摄像头的使用,但是有多个选项涉及如何从网络摄像头读取图像。
在撰写本书时,版本 OpenCV 3.3.0 没有正确的方法列出可用的网络摄像头,因此在运行此代码时连接多个网络摄像头的情况下, 必须增加VideoCapture 的索引值,直到使用所需的索引值为止。
如果有多个可用阅读器实现,例如cv2.CAP_FFMPEG和cv2.CAP_IMAGES,或以cv2.CAP_*开头的所有东西,也可以强制实现特定的阅读器。 例如,您可以在网络摄像头索引 1 上使用QuickTime阅读器:
cap = cv2.VideoCapture(1 + cv2.CAP_QT) // Webcam index 1 + reader implementation QuickTime
键盘输入
现在我们知道了如何从网络摄像头捕获实时视频流,让我们看看如何使用键盘与显示视频流的窗口进行交互:
import cv2
def print_howto():
print("""
Change color space of the
input video stream using keyboard controls. The control keys are:
1\. Grayscale - press 'g'
2\. YUV - press 'y'
3\. HSV - press 'h'
""")
if __name__=='__main__':
print_howto()
cap = cv2.VideoCapture(0)
# Check if the webcam is opened correctly
if not cap.isOpened():
raise IOError("Cannot open webcam")
cur_mode = None
while True:
# Read the current frame from webcam
ret, frame = cap.read()
# Resize the captured image
frame = cv2.resize(frame, None, fx=0.5, fy=0.5, interpolation=cv2.INTER_AREA)
c = cv2.waitKey(1)
if c == 27:
break
# Update cur_mode only in case it is different and key was pressed
# In case a key was not pressed during the iteration result is -1 or 255, depending
# on library versions
if c != -1 and c != 255 and c != cur_mode:
cur_mode = c
if cur_mode == ord('g'):
output = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
elif cur_mode == ord('y'):
output = cv2.cvtColor(frame, cv2.COLOR_BGR2YUV)
elif cur_mode == ord('h'):
output = cv2.cvtColor(frame, cv2.COLOR_BGR2HSV)
else:
output = frame
cv2.imshow('Webcam', output)
cap.release()
cv2.destroyAllWindows()
与应用交互
该程序将显示输入视频流,并等待键盘输入更改色彩空间。 如果运行先前的程序,则将看到一个窗口,显示来自网络摄像头的输入视频流。 如果按G,您将看到输入流的色彩空间已转换为灰度。 如果按Y,则输入流将转换为 YUV 色彩空间。 同样,如果按H,您将看到图像正在转换为 HSV 色彩空间。
众所周知,我们使用函数waitKey()来监听键盘事件。 当我们遇到不同的按键时,我们将采取适当的措施。 我们使用函数ord()的原因是因为waitKey()返回键盘输入的 ASCII 值。 因此,我们需要在检查字符值之前将其转换为 ASCII 形式。
鼠标输入
在本节中,我们将看到如何使用鼠标与显示窗口进行交互。 让我们从简单的事情开始。 我们将编写一个程序,该程序将检测检测到鼠标单击的象限。 一旦检测到它,我们将突出显示该象限:
import cv2
import numpy as np
def detect_quadrant(event, x, y, flags, param):
if event == cv2.EVENT_LBUTTONDOWN:
if x > width/2:
if y > height/2:
point_top_left = (int(width/2), int(height/2))
point_bottom_right = (width-1, height-1)
else:
point_top_left = (int(width/2), 0)
point_bottom_right = (width-1, int(height/2))
else:
if y > height/2:
point_top_left = (0, int(height/2))
point_bottom_right = (int(width/2), height-1)
else:
point_top_left = (0, 0)
point_bottom_right = (int(width/2), int(height/2))
img = param["img"]
# Repaint all in white again
cv2.rectangle(img, (0,0), (width-1,height-1), (255,255,255), -1)
# Paint green quadrant
cv2.rectangle(img, point_top_left, point_bottom_right, (0,100,0), -1)
if __name__=='__main__':
width, height = 640, 480
img = 255 * np.ones((height, width, 3), dtype=np.uint8)
cv2.namedWindow('Input window')
cv2.setMouseCallback('Input window', detect_quadrant, {"img": img})
while True:
cv2.imshow('Input window', img)
c = cv2.waitKey(1)
if c == 27:
break
cv2.destroyAllWindows()
输出将如下图所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-glso529M-1681870901096)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/opencv-3x-py-example/img/8d044011-30d0-458c-8b16-aa0f977345a6.png)]
到底发生了什么?
让我们从该程序的main函数开始。 我们创建一个白色图像,我们将使用鼠标在其上单击。 然后,我们创建一个命名窗口并将MouseCallback函数绑定到该窗口。 MouseCallback函数基本上是检测到鼠标事件时将调用的函数。 鼠标事件有很多种,例如单击,双击,拖动等等。 在我们的例子中,我们只想检测鼠标单击。 在detect_quadrant函数中,我们检查第一个输入参数事件以查看执行了什么操作。 OpenCV 提供了一组预定义的事件,我们可以使用特定的关键字来调用它们。 如果要查看所有鼠标事件的列表,可以转到 Python shell 并键入以下内容:
>>> import cv2
>>> print([x for x in dir(cv2) if x.startswith('EVENT')])
detect_quadrant函数中的第二个和第三个参数提供了鼠标单击事件的X和Y坐标。 一旦知道了这些坐标,就可以很容易地确定其所在的象限。使用此信息,我们就可以继续使用cv2.rectangle()绘制具有指定颜色的矩形。 这是一个非常方便的函数,它使用左上角和右下角在具有指定颜色的图像上绘制矩形。
与实时视频流交互
让我们看看如何使用鼠标与网络摄像头中的实时视频流进行交互。 我们可以使用鼠标选择一个区域,然后对该区域应用负片效果,如下图所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kSfqSPZW-1681870901096)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/opencv-3x-py-example/img/128bc65d-3feb-4daa-9749-08e99c53d776.png)]
在以下程序中,我们将从网络摄像头捕获视频流,用鼠标选择一个兴趣区域,然后应用此效果:
import cv2
import numpy as np
def update_pts(params, x, y):
global x_init, y_init
params["top_left_pt"] = (min(x_init, x), min(y_init, y))
params["bottom_right_pt"] = (max(x_init, x), max(y_init, y))
img[y_init:y, x_init:x] = 255 - img[y_init:y, x_init:x]
def draw_rectangle(event, x, y, flags, params):
global x_init, y_init, drawing
# First click initialize the init rectangle point
if event == cv2.EVENT_LBUTTONDOWN:
drawing = True
x_init, y_init = x, y
# Meanwhile mouse button is pressed, update diagonal rectangle point
elif event == cv2.EVENT_MOUSEMOVE and drawing:
update_pts(params, x, y)
# Once mouse botton is release
elif event == cv2.EVENT_LBUTTONUP:
drawing = False
update_pts(params, x, y)
if __name__=='__main__':
drawing = False
event_params = {"top_left_pt": (-1, -1), "bottom_right_pt": (-1, -1)}
cap = cv2.VideoCapture(0)
# Check if the webcam is opened correctly
if not cap.isOpened():
raise IOError("Cannot open webcam")
cv2.namedWindow('Webcam')
# Bind draw_rectangle function to every mouse event
cv2.setMouseCallback('Webcam', draw_rectangle, event_params)
while True:
ret, frame = cap.read()
img = cv2.resize(frame, None, fx=0.5, fy=0.5, interpolation=cv2.INTER_AREA)
(x0,y0), (x1,y1) = event_params["top_left_pt"], event_params["bottom_right_pt"]
img[y0:y1, x0:x1] = 255 - img[y0:y1, x0:x1]
cv2.imshow('Webcam', img)
c = cv2.waitKey(1)
if c == 27:
break
cap.release()
cv2.destroyAllWindows()
如果运行上述程序,则会看到一个显示视频流的窗口。 您可以使用鼠标在窗口上绘制一个矩形,然后您会看到该区域被转换为负片。
我们是怎么做的?
正如我们在程序的main函数中看到的那样,我们初始化了一个视频捕获对象。 然后,在下面的行中将函数draw_rectangle与MouseCallback函数绑定:
cv2.setMouseCallback('Webcam', draw_rectangle, event_params)
然后,我们开始无限循环并开始捕获视频流。 让我们看看函数draw_rectangle中发生了什么; 每当我们使用鼠标绘制矩形时,我们基本上必须检测三种类型的鼠标事件:鼠标单击,鼠标移动和鼠标按钮释放。 这正是我们在此函数中所做的。 每当我们检测到鼠标单击事件时,我们都会初始化矩形的左上角。 当我们移动鼠标时,我们通过将当前位置保持为矩形的右下角来选择兴趣区域,并在通过引用传递的对象作为第三个参数(event_params)处对其进行更新。
一旦有了兴趣区域,我们只需反转像素即可应用负片效果。 我们从 255 中减去当前像素值,这给了我们想要的效果。 当鼠标移动停止并且检测到按下按钮事件时,我们将停止更新矩形的右下位置。 我们只是一直显示该图像,直到检测到另一个鼠标单击事件为止。
卡通化图像
现在,我们知道了如何处理网络摄像头和键盘/鼠标输入,让我们继续前进,看看如何将图片转换为卡通图像。 我们可以将图像转换为草图或彩色卡通图像。
以下是草图的示例:

如果将卡通化效果应用于彩色图像,它将看起来像下一个图像:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IEzfzqIb-1681870901097)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/opencv-3x-py-example/img/f111d98c-4918-4fe3-b010-ee6a28e48c33.png)]
让我们看看如何实现这一目标:
import cv2
import numpy as np
def print_howto():
print("""
Change cartoonizing mode of image:
1\. Cartoonize without Color - press 's'
2\. Cartoonize with Color - press 'c'
""")
def cartoonize_image(img, ksize=5, sketch_mode=False):
num_repetitions, sigma_color, sigma_space, ds_factor = 10, 5, 7, 4
# Convert image to grayscale
img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# Apply median filter to the grayscale image
img_gray = cv2.medianBlur(img_gray, 7)
# Detect edges in the image and threshold it
edges = cv2.Laplacian(img_gray, cv2.CV_8U, ksize=ksize)
ret, mask = cv2.threshold(edges, 100, 255, cv2.THRESH_BINARY_INV)
# 'mask' is the sketch of the image
if sketch_mode:
return cv2.cvtColor(mask, cv2.COLOR_GRAY2BGR)
# Resize the image to a smaller size for faster computation
img_small = cv2.resize(img, None, fx=1.0/ds_factor, fy=1.0/ds_factor, interpolation=cv2.INTER_AREA)
# Apply bilateral filter the image multiple times
for i in range(num_repetitions):
img_small = cv2.bilateralFilter(img_small, ksize, sigma_color, sigma_space)
img_output = cv2.resize(img_small, None, fx=ds_factor, fy=ds_factor, interpolation=cv2.INTER_LINEAR)
dst = np.zeros(img_gray.shape)
# Add the thick boundary lines to the image using 'AND' operator
dst = cv2.bitwise_and(img_output, img_output, mask=mask)
return dst
if __name__=='__main__':
print_howto()
cap = cv2.VideoCapture(0)
cur_mode = None
while True:
ret, frame = cap.read()
frame = cv2.resize(frame, None, fx=0.5, fy=0.5, interpolation=cv2.INTER_AREA)
c = cv2.waitKey(1)
if c == 27:
break
if c != -1 and c != 255 and c != cur_mode:
cur_mode = c
if cur_mode == ord('s'):
cv2.imshow('Cartoonize', cartoonize_image(frame, ksize=5, sketch_mode=True))
elif cur_mode == ord('c'):
cv2.imshow('Cartoonize', cartoonize_image(frame, ksize=5, sketch_mode=False))
else:
cv2.imshow('Cartoonize', frame)
cap.release()
cv2.destroyAllWindows()
解构代码
当您运行上述程序时,您将看到一个窗口,其中包含来自网络摄像头的视频流。 如果按S,视频流将变为草图模式,并且您将看到其铅笔状的轮廓。 如果按C,您将看到输入流的彩色卡通版。 如果按任何其他键,它将返回到正常模式。
让我们看一下cartoonize_image函数,看看我们是如何做到的。 首先,我们将图像转换为灰度图像,然后通过中值过滤器进行处理。 中值过滤器非常擅长去除盐和胡椒粉的噪音。 当您在图像中看到孤立的黑色或白色像素时,就是这种噪声。 它在网络摄像头和移动相机中很常见,因此我们需要将其过滤掉,然后再继续进行。 举个例子,看下面的图片:
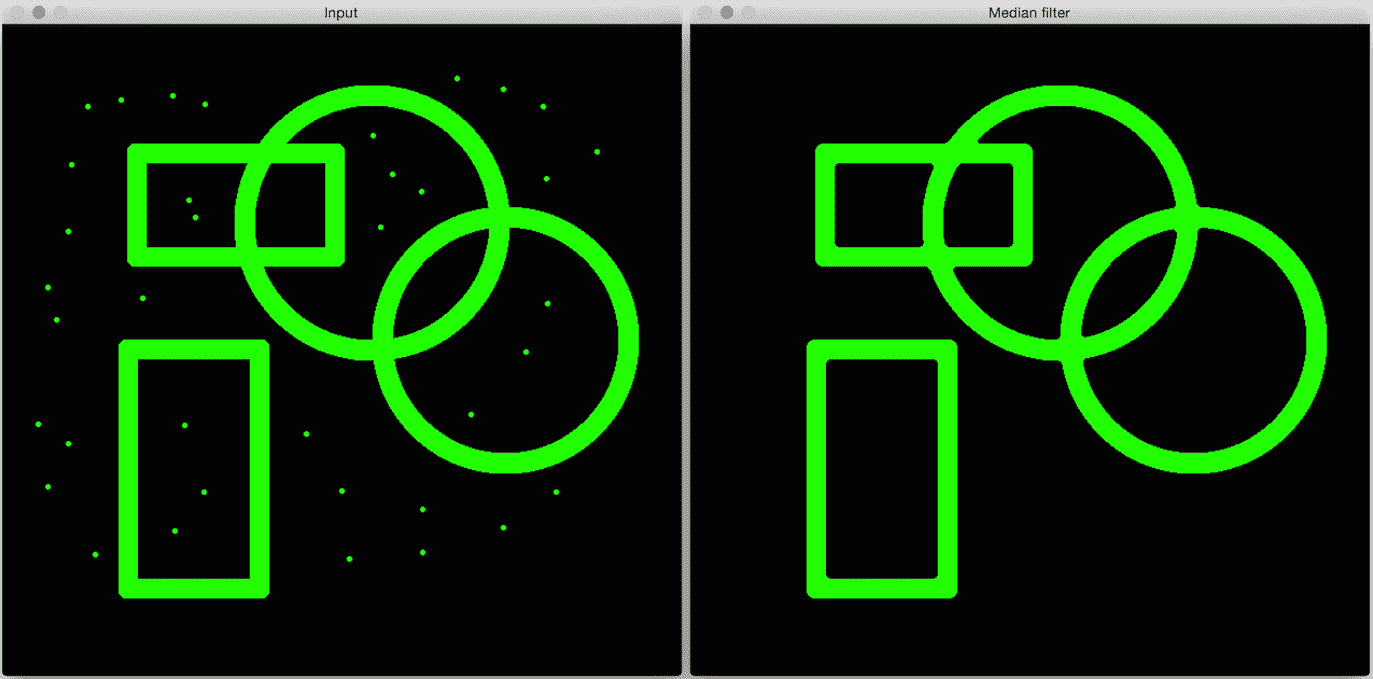
正如我们在输入图像中看到的,有很多孤立的绿色像素。 它们降低了图像的质量,我们需要摆脱它们。 这是中值过滤器派上用场的地方。 我们仅查看每个像素周围的NxN邻域,然后选择这些数字的中值。 由于在这种情况下,孤立的像素具有较高的值,因此取中间值将摆脱这些值,并使图像平滑。 正如您在输出图像中看到的那样,中值过滤器消除了所有这些孤立的像素,并且图像看起来很干净。 以下是此代码:
import cv2
import numpy as np
img = cv2.imread('images/input.jpg')
output = cv2.medianBlur(img, ksize=7)
cv2.imshow('Input', img)
cv2.imshow('Median filter', output)
cv2.waitKey()
该代码非常简单。 我们仅使用medianBlur函数将中值过滤器应用于输入图像。 此函数中的第二个参数指定我们正在使用的核的大小。 核的大小与我们需要考虑的邻域大小有关。 您可以试用此参数,并查看它如何影响输出。 请记住,可能的值只是奇数:1、3、5、7,依此类推。
回到cartoonize_image,我们继续检测灰度图像上的边缘。 我们需要知道边缘在哪里,以便创建铅笔线效果。 一旦检测到边缘,就对它们进行阈值处理,以使事物在字面上和隐喻上都变成黑白!
在下一步中,我们检查草图模式是否已启用。 如果是这样,那么我们只需将其转换为彩色图像并返回即可。 如果我们希望线变粗怎么办? 假设我们想看到类似下图的内容:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Dl4FHYIN-1681870901097)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/opencv-3x-py-example/img/a54e99ea-d3dd-4fa5-a1fd-795bcb8231d4.png)]
如您所见,线条比以前更粗。 为此,将if代码块替换为以下代码:
if sketch_mode:
img_sketch = cv2.cvtColor(mask, cv2.COLOR_GRAY2BGR)
kernel = np.ones((3,3), np.uint8)
img_eroded = cv2.erode(img_sketch, kernel, iterations=1)
return cv2.medianBlur(img_eroded, ksize=5)
我们在这里将erode函数与3x3核一起使用。 之所以要使用此选项,是因为它使我们有机会使用线图的粗细。 现在,您可能会问:如果我们要增加某些物体的厚度,我们是否应该使用膨胀? 好吧,这种推理是正确的,但是这里有一个小小的转折。 请注意,前景为黑色,背景为白色。 侵蚀和膨胀将白色像素视为前景,将黑色像素视为背景。 因此,如果要增加黑色前景的厚度,则需要使用腐蚀。 施加腐蚀后,我们仅使用中值过滤器清除噪声并获得最终输出。
在下一步中,我们将使用双边过滤来平滑图像。 双边滤波是一个有趣的概念,它的性能比高斯过滤器好得多。 关于双边过滤的好处是它可以保留边缘,而高斯过滤器则可以使所有内容均等地平滑。 为了进行比较和对比,让我们看下面的输入图像:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wqcw0sSA-1681870901097)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/opencv-3x-py-example/img/2a5b18d0-51af-4be7-a191-aa2e14a99004.png)]
让我们将高斯过滤器应用于上一张图片:

现在,让我们将双边过滤器应用于输入图像:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zwPkDmLl-1681870901098)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/opencv-3x-py-example/img/97343da8-7065-459c-81e7-203afb916283.png)]
如您所见,如果使用双边过滤器,质量会更好。 图像看起来很平滑,边缘看起来也很清晰! 实现此目的的代码如下:
import cv2
import numpy as np
img = cv2.imread('images/input.jpg')
img_gaussian = cv2.GaussianBlur(img, (13,13), 0) # Gaussian Kernel Size 13x13
img_bilateral = cv2.bilateralFilter(img, 13, 70, 50)
cv2.imshow('Input', img)
cv2.imshow('Gaussian filter', img_gaussian)
cv2.imshow('Bilateral filter', img_bilateral)
cv2.waitKey()
如果仔细观察两个输出,可以看到高斯滤波图像的边缘看起来模糊。 通常,我们只想平滑图像中的粗糙区域并保持边缘完整。 这是双边过滤器派上用场的地方。 高斯过滤器仅查看紧邻区域,并使用由GaussianBlur方法应用的高斯核对像素值求平均。 双边过滤器通过仅对强度彼此相似的那些像素求平均,将这一概念提升到了一个新的水平。 它还使用颜色邻域度量标准来查看它是否可以替换强度相似的当前像素。 如果您看一下函数调用:
img_small = cv2.bilateralFilter(img_small, size, sigma_color,
sigma_space)
这里的最后两个参数指定颜色和空间邻域。 这就是在双边过滤器的输出中边缘看起来清晰的原因。 我们在图像上多次运行此过滤器以使其平滑化,使其看起来像卡通漫画。 然后,我们将铅笔状的遮罩叠加在此彩色图像的顶部,以创建类似卡通的效果。
总结
在本章中,我们学习了如何访问网络摄像头。 我们讨论了在实时视频流中如何获取键盘和鼠标输入。 我们使用此知识来创建交互式应用。 我们讨论了中值和双边过滤器,并讨论了双边过滤器相对于高斯过滤器的优势。 我们使用所有这些原理将输入图像转换为素描图像,然后将其卡通化。
在下一章中,我们将学习如何在静态图像以及实时视频中检测不同的身体部位。
四、检测和跟踪不同的身体部位
在本章中,我们将学习如何在实时视频流中检测和跟踪不同的身体部位。 我们将首先讨论面部检测管道以及它是如何从头开始构建的。 我们将学习如何使用此框架来检测和跟踪其他身体部位,例如眼睛,耳朵和嘴巴。
在本章结束时,您将了解:
- 如何使用 Haar 级联
- 什么是完整的图像
- 什么是自适应增强
- 如何在实时视频流中检测和跟踪面部
- 如何在实时视频流中检测和跟踪眼睛
- 如何将太阳镜自动覆盖在人的脸上
- 如何检测眼睛,耳朵和嘴巴
- 如何使用形状分析检测瞳孔
使用 Haar 级联检测对象
当我们说 Haar 级联时,实际上是在谈论基于 Haar 特征的级联分类器。 要了解这意味着什么,我们需要退后一步,并首先了解为什么需要这样做。 早在 2001 年,Paul Viola 和 Michael Jones 在他们的开创性论文中提出了一种非常有效的对象检测方法。 它已成为机器学习领域的主要标志之一。
在他们的论文中,他们描述了一种机器学习技术,其中使用了增强的简单分类器级联来获得表现非常好的整体分类器。 这样,我们就可以避免构建单个复杂分类器以实现高精度的过程。 之所以如此令人惊讶,是因为构建一个强大的单步分类器是一个计算量大的过程。 此外,我们需要大量的训练数据来建立这样的分类器。 该模型最终变得复杂,并且表现可能达不到要求。
假设我们要检测像菠萝这样的物体。 为了解决这个问题,我们需要构建一个机器学习系统,该系统将学习菠萝的外观。 它应该能够告诉我们未知图像是否包含菠萝。 为了实现这样的目标,我们需要训练我们的系统。 在机器学习领域,我们有很多方法可以训练系统。 这很像训练狗,只是它不会帮您拿到球! 为了训练我们的系统,我们拍摄了很多菠萝和非菠萝图像,然后将它们输入到系统中。 在此,将菠萝图像称为正图像,将非菠萝图像称为负图像。
就训练而言,有很多路线可供选择。 但是所有传统技术都是计算密集型的,并且会导致模型复杂。 我们不能使用这些模型来构建实时系统。 因此,我们需要保持分类器简单。 但是,如果我们保持分类器简单,那么它将是不准确的。 速度和准确率之间的权衡在机器学习中很常见。 通过构建一组简单的分类器,然后将它们级联在一起以形成一个健壮的统一分类器,我们克服了这个问题。 为了确保整体分类器运行良好,我们需要在层叠步骤中发挥创意。 这是 Viola-Jones 方法如此有效的主要原因之一。
谈到人脸检测这个话题,让我们看看如何训练一个系统来检测人脸。 如果要构建机器学习系统,则首先需要从所有图像中提取特征。 在我们的案例中,机器学习算法将使用这些特征来学习人脸。 我们使用 Haar 特征来构建特征向量。 Haar 特征是整个图像上补丁的简单求和和差异。 我们以多种图像尺寸执行此操作,以确保我们的系统缩放不变。
如果您好奇,可以通过以下网址了解有关该公式的更多信息
提取这些特征后,我们将其传递给一系列的分类器。 我们只检查所有不同的矩形子区域,并继续丢弃其中没有人脸的区域。 这样,我们可以快速得出最终答案,以查看给定的矩形是否包含面。
什么是完整图片?
如果要计算 Haar 特征,则必须计算图像中许多不同矩形区域的总和。 如果要有效地构建特征集,则需要在多个尺度上计算这些总和。 这是一个非常昂贵的过程! 如果我们要构建一个实时系统,我们就不能花费那么多的周期来计算这些和。 因此,我们使用了积分图像:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Fr1TQlDs-1681870901098)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/opencv-3x-py-example/img/4af4f723-49da-4a71-95e1-065dc78a2750.png)]
要计算图像中任何矩形的总和,我们不需要遍历该矩形区域中的所有元素。 假设AP表示矩形中由左上角的点和图像中的点P作为两个对角相对的角所形成的所有元素的总和。 因此,现在,如果要计算矩形 ABCD 的面积,可以使用以下公式:
矩形 ABCD 的面积 = AC - (AB + AD - AA)
我们为什么要关心这个特定公式? 如前所述,提取 Haar 特征包括以多个比例计算图像中大量矩形的面积。 这些计算中有很多是重复的,整个过程非常缓慢。 实际上,它是如此之慢,以至于我们无力实时运行任何东西。 这就是我们使用这种秘籍的原因! 这种方法的好处是我们不必重新计算任何东西。 该方程式右侧面积的所有值均已可用。 因此,我们仅使用它们来计算任何给定矩形的面积并提取特征。
检测和追踪人脸
OpenCV 提供了一个不错的人脸检测框架。 我们只需要加载级联文件并使用它来检测图像中的面部。 让我们看看如何做到这一点:
import cv2
import numpy as np
face_cascade = cv2.CascadeClassifier('./cascade_files/haarcascade_frontalface_alt.xml')
cap = cv2.VideoCapture(0)
scaling_factor = 0.5
while True:
ret, frame = cap.read()
frame = cv2.resize(frame, None, fx=scaling_factor,
fy=scaling_factor, interpolation=cv2.INTER_AREA)
face_rects = face_cascade.detectMultiScale(frame, scaleFactor=1.3, minNeighbors=3)
for (x,y,w,h) in face_rects:
cv2.rectangle(frame, (x,y), (x+w,y+h), (0,255,0), 3)
cv2.imshow('Face Detector', frame)
c = cv2.waitKey(1)
if c == 27:
break
cap.release()
cv2.destroyAllWindows()
如果运行前面的代码,结果将类似于下图:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xi0ZWbIF-1681870901098)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/opencv-3x-py-example/img/3fe5f7e6-753d-4cad-b3ea-f82ae50af1f9.png)]
更好地了解它
我们需要一个可用于检测图像中人脸的分类器模型。 OpenCV 提供了可用于此目的的 XML 文件。 我们使用函数CascadeClassifier加载 XML 文件。 一旦我们开始从网络摄像头捕获输入帧并使用detectMultiScale函数获取当前图像中所有面部的边界框,以防万一帧没有以灰度传递,则将在该方法内部运行,因为需要灰度帧来处理检测。 此函数中的第二个参数指定缩放因子的跳跃,例如,如果我们找不到当前缩放比例的图像,则在我们的示例中,下一个要检查的尺寸将比当前尺寸大 1.3 倍。 最后一个参数是一个阈值,用于指定保留当前矩形所需的最小相邻矩形数。 万一人脸识别无法按预期工作时,可以使用它来提高人脸检测器的鲁棒性,降低阈值以获得更好的识别。 如果图像由于处理检测而有些延迟,请将缩放帧的大小减小 0.4 或 0.3。
人脸上的乐趣
现在我们知道了如何检测和跟踪脸部,让我们一起玩一些乐趣。 当我们从摄像头捕获视频流时,我们可以在脸部上方覆盖有趣的遮罩。 它看起来像下图:

如果您是汉尼拔的粉丝,可以尝试以下方法:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-iio61mrF-1681870901099)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/opencv-3x-py-example/img/b21edc36-ecf7-4a8f-8ecc-21a9f895f042.png)]
让我们看一下代码,看看如何在输入视频流中将头骨遮罩覆盖在面部顶部:
import cv2
import numpy as np
face_cascade = cv2.CascadeClassifier('./cascade_files/haarcascade_frontalface_alt.xml')
face_mask = cv2.imread(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/opencv-3x-py-example/img/mask_hannibal.png')
h_mask, w_mask = face_mask.shape[:2]
if face_cascade.empty():
raise IOError('Unable to load the face cascade classifier xml file')
cap = cv2.VideoCapture(0)
scaling_factor = 0.5
while True:
ret, frame = cap.read()
frame = cv2.resize(frame, None, fx=scaling_factor, fy=scaling_factor, interpolation=cv2.INTER_AREA)
face_rects = face_cascade.detectMultiScale(frame, scaleFactor=1.3, minNeighbors=3)
for (x,y,w,h) in face_rects:
if h <= 0 or w <= 0: pass
# Adjust the height and weight parameters depending on the sizes and the locations.
# You need to play around with these to make sure you get it right.
h, w = int(1.0*h), int(1.0*w)
y -= int(-0.2*h)
x = int(x)
# Extract the region of interest from the image
frame_roi = frame[y:y+h, x:x+w]
face_mask_small = cv2.resize(face_mask, (w, h), interpolation=cv2.INTER_AREA)
# Convert color image to grayscale and threshold it
gray_mask = cv2.cvtColor(face_mask_small, cv2.COLOR_BGR2GRAY)
ret, mask = cv2.threshold(gray_mask, 180, 255, cv2.THRESH_BINARY_INV)
# Create an inverse mask
mask_inv = cv2.bitwise_not(mask)
try:
# Use the mask to extract the face mask region of interest
masked_face = cv2.bitwise_and(face_mask_small, face_mask_small, mask=mask)
# Use the inverse mask to get the remaining part of the image
masked_frame = cv2.bitwise_and(frame_roi, frame_roi, mask=mask_inv)
except cv2.error as e:
print('Ignoring arithmentic exceptions: '+ str(e))
# add the two images to get the final output
frame[y:y+h, x:x+w] = cv2.add(masked_face, masked_frame)
cv2.imshow('Face Detector', frame)
c = cv2.waitKey(1)
if c == 27:
break
cap.release()
cv2.destroyAllWindows()
底层原理
像以前一样,我们首先加载面部级联分类器 XML 文件。 人脸检测步骤照常工作。 我们开始无限循环,并持续检测每一帧中的人脸。 一旦知道人脸在哪里,就需要稍微修改坐标以确保遮罩正确适合。 该操作过程是主观的,并且取决于所讨论的掩模。 不同的遮罩需要不同程度的调整,以使其看起来更自然。 我们在以下行中从输入帧中提取兴趣区域:
frame_roi = frame[y:y+h, x:x+w]
现在我们有了所需的关注区域,我们需要在此之上覆盖遮罩。 因此,我们调整输入遮罩的大小以确保它适合此兴趣区域。 输入掩码具有白色背景。 因此,如果我们仅将其覆盖在兴趣区域的顶部,由于白色背景,它看起来将不自然。 我们只需要覆盖头骨遮罩像素即可; 其余区域应该是透明的。
因此,在下一步中,我们通过对头骨图像进行阈值处理来创建遮罩。 由于背景是白色,因此我们对图像进行阈值处理,以使强度值大于 180 的任何像素变为零,其他所有值变为 255。就感兴趣的帧区域而言,我们需要将这个遮罩区域的所有东西涂黑。 我们可以通过简单地使用刚创建的遮罩的逆来实现。 一旦我们获得了头骨图像的遮罩版本和感兴趣的输入区域,我们就将它们加起来以获得最终图像。
从重叠图像中删除 Alpha 通道
由于使用了重叠图像,我们应该记住,可能会在黑色像素上构建一层,这会对我们的代码结果产生不良影响。 为了避免该问题,以下代码从叠加图像中删除了 Alpha 通道层,因此使我们可以在本章中的示例代码上获得良好的效果:
import numpy as np
import cv2
def remove_alpha_channel(source, background_color):
source_img = cv2.cvtColor(source[:,:,:3], cv2.COLOR_BGR2GRAY)
source_mask = source[:,:,3] * (1 / 255.0)
bg_part = (255 * (1 / 255.0)) * (1.0 - source_mask)
weight = (source_img * (1 / 255.0)) * (source_mask)
dest = np.uint8(cv2.addWeighted(bg_part, 255.0, weight, 255.0, 0.0))
return dest
orig_img = cv2.imread(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/opencv-3x-py-example/img/overlay_source.png', cv2.IMREAD_UNCHANGED)
dest_img = remove_alpha_channel(orig_img)
cv2.imwrite('images/overlay_dest.png', dest_img, [cv2.IMWRITE_PNG_COMPRESSION])
检测眼睛
现在我们了解了如何检测脸部,我们也可以将概念推广到检测其他身体部位。 重要的是要了解 Viola-Jones 框架可以应用于任何对象。 准确率和鲁棒性将取决于对象的唯一性。 例如,人脸具有非常独特的特征,因此很容易将我们的系统训练成健壮的。 另一方面,毛巾,衣服或书本之类的物体太普通,并且没有明显的特征,因此要构建坚固的检测器会更加困难。
让我们看看如何构建眼睛检测器:
import cv2
import numpy as np
face_cascade = cv2.CascadeClassifier('./cascade_files/haarcascade_frontalface_alt.xml')
eye_cascade = cv2.CascadeClassifier('./cascade_files/haarcascade_eye.xml')
if face_cascade.empty():
raise IOError('Unable to load the face cascade classifier xml file')
if eye_cascade.empty():
raise IOError('Unable to load the eye cascade classifier xml file')
cap = cv2.VideoCapture(0)
ds_factor = 0.5
while True:
ret, frame = cap.read()
frame = cv2.resize(frame, None, fx=ds_factor, fy=ds_factor, interpolation=cv2.INTER_AREA)
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
faces = face_cascade.detectMultiScale(gray, scaleFactor=1.3, minNeighbors=1)
for (x,y,w,h) in faces:
roi_gray = gray[y:y+h, x:x+w]
roi_color = frame[y:y+h, x:x+w]
eyes = eye_cascade.detectMultiScale(roi_gray)
for (x_eye,y_eye,w_eye,h_eye) in eyes:
center = (int(x_eye + 0.5*w_eye), int(y_eye + 0.5*h_eye))
radius = int(0.3 * (w_eye + h_eye))
color = (0, 255, 0)
thickness = 3
cv2.circle(roi_color, center, radius, color, thickness)
cv2.imshow('Eye Detector', frame)
c = cv2.waitKey(1)
if c == 27:
break
cap.release()
cv2.destroyAllWindows()
如果运行此程序,输出将类似于下图:

事后思考
如果您注意到,该程序看起来与人脸检测程序非常相似。 除了加载人脸检测级联分类器外,我们还加载了眼睛检测级联分类器。 从技术上讲,我们不需要使用面部检测器。 但是我们知道眼睛总是在别人的脸上。 我们使用此信息并仅在感兴趣的相关区域(即脸部)中搜索眼睛。 我们首先检测人脸,然后在该子图像上运行眼睛检测器。 这样,它更快,更高效。
有趣的眼睛
现在,我们知道了如何检测图像中的眼睛,让我们看看我们是否可以对此做一些有趣的事情。 我们可以执行以下屏幕快照中所示的操作:

让我们看一下代码,看看如何做这样的事情:
import cv2
import numpy as np
face_cascade = cv2.CascadeClassifier('./cascade_files/haarcascade_frontalface_alt.xml')
eye_cascade = cv2.CascadeClassifier('./cascade_files/haarcascade_eye.xml')
if face_cascade.empty():
raise IOError('Unable to load the face cascade classifier xml file')
if eye_cascade.empty():
raise IOError('Unable to load the eye cascade classifier xml file')
cap = cv2.VideoCapture(0)
sunglasses_img = cv2.imread('images/sunglasses.png')
while True:
ret, frame = cap.read()
frame = cv2.resize(frame, None, fx=0.5, fy=0.5, interpolation=cv2.INTER_AREA)
vh, vw = frame.shape[:2]
vh, vw = int(vh), int(vw)
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
faces = face_cascade.detectMultiScale(gray, scaleFactor=1.3, minNeighbors=1)
centers = []
for (x,y,w,h) in faces:
roi_gray = gray[y:y+h, x:x+w]
roi_color = frame[y:y+h, x:x+w]
eyes = eye_cascade.detectMultiScale(roi_gray)
for (x_eye,y_eye,w_eye,h_eye) in eyes:
centers.append((x + int(x_eye + 0.5*w_eye), y + int(y_eye + 0.5*h_eye)))
if len(centers) > 1: # if detects both eyes
h, w = sunglasses_img.shape[:2]
# Extract the region of interest from the image
eye_distance = abs(centers[1][0] - centers[0][0])
# Overlay sunglasses; the factor 2.12 is customizable depending on the size of the face
sunglasses_width = 2.12 * eye_distance
scaling_factor = sunglasses_width / w
print(scaling_factor, eye_distance)
overlay_sunglasses = cv2.resize(sunglasses_img, None, fx=scaling_factor, fy=scaling_factor, interpolation=cv2.INTER_AREA)
x = centers[0][0] if centers[0][0] < centers[1][0] else centers[1][0]
# customizable X and Y locations; depends on the size of the face
x -= int(0.26*overlay_sunglasses.shape[1])
y += int(0.26*overlay_sunglasses.shape[0])
h, w = overlay_sunglasses.shape[:2]
h, w = int(h), int(w)
frame_roi = frame[y:y+h, x:x+w]
# Convert color image to grayscale and threshold it
gray_overlay_sunglassess = cv2.cvtColor(overlay_sunglasses, cv2.COLOR_BGR2GRAY)
ret, mask = cv2.threshold(gray_overlay_sunglassess, 180, 255, cv2.THRESH_BINARY_INV)
# Create an inverse mask
mask_inv = cv2.bitwise_not(mask)
try:
# Use the mask to extract the face mask region of interest
masked_face = cv2.bitwise_and(overlay_sunglasses, overlay_sunglasses, mask=mask)
# Use the inverse mask to get the remaining part of the image
masked_frame = cv2.bitwise_and(frame_roi, frame_roi, mask=mask_inv)
except cv2.error as e:
print('Ignoring arithmentic exceptions: '+ str(e))
#raise e
# add the two images to get the final output
frame[y:y+h, x:x+w] = cv2.add(masked_face, masked_frame)
else:
print('Eyes not detected')
cv2.imshow('Eye Detector', frame)
c = cv2.waitKey(1)
if c == 27:
break
cap.release()
cv2.destroyAllWindows()
放置太阳镜
就像我们之前所做的一样,我们加载图像并检测眼睛。 一旦检测到眼睛,便会调整太阳镜图像的大小以适合当前的关注区域。 为了创建兴趣区域,我们考虑了眼睛之间的距离。 我们相应地调整图像的大小,然后继续创建遮罩。 这类似于我们之前对骷髅面罩所做的操作。 太阳镜在脸上的位置是主观的,因此如果您想使用另一副太阳镜,则必须调整权重。
检测耳朵
通过使用 Haar 级联分类器文件,下面的代码将再次识别每只耳朵,并在检测到它们时将它们突出显示。 您会注意到,需要两个不同的分类器,因为每个耳朵的坐标将被反转:
import cv2
import numpy as np
left_ear_cascade = cv2.CascadeClassifier('./cascade_files/haarcascade_mcs_leftear.xml')
right_ear_cascade = cv2.CascadeClassifier('./cascade_files/haarcascade_mcs_rightear.xml')
if left_ear_cascade.empty():
raise IOError('Unable to load the left ear cascade classifier xml file')
if right_ear_cascade.empty():
raise IOError('Unable to load the right ear cascade classifier xml file')
cap = cv2.VideoCapture(0)
scaling_factor = 0.5
while True:
ret, frame = cap.read()
frame = cv2.resize(frame, None, fx=scaling_factor, fy=scaling_factor, interpolation=cv2.INTER_AREA)
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
left_ear = left_ear_cascade.detectMultiScale(gray, scaleFactor=1.3, minNeighbors=3)
right_ear = right_ear_cascade.detectMultiScale(gray, scaleFactor=1.3, minNeighbors=3)
for (x,y,w,h) in left_ear:
cv2.rectangle(frame, (x,y), (x+w,y+h), (0,255,0), 3)
for (x,y,w,h) in right_ear:
cv2.rectangle(frame, (x,y), (x+w,y+h), (255,0,0), 3)
cv2.imshow('Ear Detector', frame)
c = cv2.waitKey(1)
if c == 27:
break
cap.release()
cv2.destroyAllWindows()
如果在图像上运行前面的代码,则应该看到类似以下屏幕截图的内容:

检测嘴巴
这次,使用 Haar 分类器,我们将从输入视频流中提取嘴巴位置,在该代码下面的代码中,我们将使用这些坐标在脸上放置小胡子:
import cv2
import numpy as np
mouth_cascade = cv2.CascadeClassifier('./cascade_files/haarcascade_mcs_mouth.xml')
if mouth_cascade.empty():
raise IOError('Unable to load the mouth cascade classifier xml file')
cap = cv2.VideoCapture(0)
ds_factor = 0.5
while True:
ret, frame = cap.read()
frame = cv2.resize(frame, None, fx=ds_factor, fy=ds_factor, interpolation=cv2.INTER_AREA)
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
mouth_rects = mouth_cascade.detectMultiScale(gray, scaleFactor=1.7, minNeighbors=11)
for (x,y,w,h) in mouth_rects:
y = int(y - 0.15*h)
cv2.rectangle(frame, (x,y), (x+w,y+h), (0,255,0), 3)
break
cv2.imshow('Mouth Detector', frame)
c = cv2.waitKey(1)
if c == 27:
break
cap.release()
cv2.destroyAllWindows()
下图显示了输出结果:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cRwpWM4v-1681870901100)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/opencv-3x-py-example/img/6e16a772-32d0-41a2-8297-ec3331f3500e.png)]
覆盖胡须
让我们在上面盖上胡须:
import cv2
import numpy as np
mouth_cascade = cv2.CascadeClassifier('./cascade_files/haarcascade_mcs_mouth.xml')
moustache_mask = cv2.imread(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/opencv-3x-py-example/img/moustache.png')
h_mask, w_mask = moustache_mask.shape[:2]
if mouth_cascade.empty():
raise IOError('Unable to load the mouth cascade classifier xml file')
cap = cv2.VideoCapture(0)
scaling_factor = 0.5
while True:
ret, frame = cap.read()
frame = cv2.resize(frame, None, fx=scaling_factor, fy=scaling_factor, interpolation=cv2.INTER_AREA)
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
mouth_rects = mouth_cascade.detectMultiScale(gray, 1.3, 5)
if len(mouth_rects) > 0:
(x,y,w,h) = mouth_rects[0]
h, w = int(0.6*h), int(1.2*w)
x -= int(0.05*w)
y -= int(0.55*h)
frame_roi = frame[y:y+h, x:x+w]
moustache_mask_small = cv2.resize(moustache_mask, (w, h), interpolation=cv2.INTER_AREA)
gray_mask = cv2.cvtColor(moustache_mask_small, cv2.COLOR_BGR2GRAY)
ret, mask = cv2.threshold(gray_mask, 50, 255, cv2.THRESH_BINARY_INV)
mask_inv = cv2.bitwise_not(mask)
masked_mouth = cv2.bitwise_and(moustache_mask_small, moustache_mask_small, mask=mask)
masked_frame = cv2.bitwise_and(frame_roi, frame_roi, mask=mask_inv)
frame[y:y+h, x:x+w] = cv2.add(masked_mouth, masked_frame)
cv2.imshow('Moustache', frame)
c = cv2.waitKey(1)
if c == 27:
break
cap.release()
cv2.destroyAllWindows()
看起来是这样的:

检测瞳孔
我们将在这里采取不同的方法。 瞳孔太普通了,无法采用 Haar 级联方法。 我们还将了解如何根据事物的形状检测事物。 以下是输出结果:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rbyUAvnM-1681870901100)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/opencv-3x-py-example/img/b8f774da-6486-4c95-8603-150606b61ce5.png)]
让我们看看如何构建瞳孔检测器:
import math
import cv2
eye_cascade = cv2.CascadeClassifier('./cascade_files/haarcascade_eye.xml')
if eye_cascade.empty():
raise IOError('Unable to load the eye cascade classifier xml file')
cap = cv2.VideoCapture(0)
ds_factor = 0.5
ret, frame = cap.read()
contours = []
while True:
ret, frame = cap.read()
frame = cv2.resize(frame, None, fx=ds_factor, fy=ds_factor, interpolation=cv2.INTER_AREA)
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
eyes = eye_cascade.detectMultiScale(gray, scaleFactor=1.3, minNeighbors=1)
for (x_eye, y_eye, w_eye, h_eye) in eyes:
pupil_frame = gray[y_eye:y_eye + h_eye, x_eye:x_eye + w_eye]
ret, thresh = cv2.threshold(pupil_frame, 80, 255, cv2.THRESH_BINARY)
cv2.imshow("threshold", thresh)
im2, contours, hierarchy = cv2.findContours(thresh, cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)
print(contours)
for contour in contours:
area = cv2.contourArea(contour)
rect = cv2.boundingRect(contour)
x, y, w, h = rect
radius = 0.15 * (w + h)
area_condition = (100 <= area <= 200)
symmetry_condition = (abs(1 - float(w)/float(h)) <= 0.2)
fill_condition = (abs(1 - (area / (math.pi * math.pow(radius, 2.0)))) <= 0.4)
cv2.circle(frame, (int(x_eye + x + radius), int(y_eye + y + radius)), int(1.3 * radius), (0, 180, 0), -1)
cv2.imshow('Pupil Detector', frame)
c = cv2.waitKey(1)
if c == 27:
break
cap.release()
cv2.destroyAllWindows()
如果运行此程序,您将看到如前所示的输出。
解构代码
如前所述,我们不会使用 Haar 级联来检测学生。 如果我们不能使用预先训练的分类器,那么我们将如何检测学生? 好吧,我们可以使用形状分析来检测瞳孔。 我们知道瞳孔是圆形的,因此我们可以使用此信息在图像中检测到它们。 我们反转输入图像,然后将其转换为灰度图像,如以下行所示:
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
正如我们在这里看到的,我们可以使用波浪号运算符反转图像。 在我们的情况下,将图像反转非常有用,因为瞳孔是黑色的,而黑色对应于较低的像素值。 然后,我们对图像进行阈值处理,以确保只有黑白像素。 现在,我们必须找出所有形状的边界。 OpenCV 提供了一个很好的函数来实现这一目标,即findContours。 我们将在接下来的章节中讨论更多有关此的内容。 但就目前而言,我们所需要知道的是,此函数返回在图像中找到的所有形状的边界集。
下一步是识别瞳孔的形状,并丢弃其余的瞳孔。 我们将使用圆的某些属性对此形状进行归零。 让我们考虑边界矩形的宽高比。 如果形状是圆形,则该比率将为 1。 我们可以使用boundingRect函数来获取边界矩形的坐标。 让我们考虑一下这种形状的面积。 如果我们粗略计算此形状的半径并使用公式计算圆的面积,则它应接近此轮廓的面积。 我们可以使用contourArea函数来计算图像中任何轮廓的面积。 因此,我们可以使用这些条件并过滤出形状。 完成此操作后,图像中剩下两个瞳孔。 我们可以通过将搜索区域限制在面部或眼睛来进一步完善它。 由于您知道如何检测面部和眼睛,因此可以尝试一下,看看是否可以将其用于实时视频流。
如果您想玩另一种身体检测,只需转到以下链接以找到差异分类器。
总结
在本章中,我们讨论了 Haar 级联和积分图像。 我们了解了人脸检测管道的构建方式。 我们学习了如何在实时视频流中检测和跟踪面部。 我们讨论了如何使用面部检测管道来检测身体的各个部位,例如眼睛,耳朵,鼻子和嘴巴。 我们学习了如何使用身体部位检测的结果在输入图像的顶部覆盖遮罩。 我们使用形状分析的原理来检测学生。
在下一章中,我们将讨论特征检测以及如何将其用于理解图像内容。
五、从图像中提取特征
在本章中,我们将学习如何检测图像中的显着点,也称为关键点。 我们将讨论为什么这些关键点很重要,以及如何使用它们来理解图像内容。 我们将讨论可用于检测这些关键点的不同技术,并了解如何从给定图像中提取特征。
在本章结束时,您将了解以下内容:
- 关键点是什么,我们为什么要关心它们?
- 如何检测关键点
- 如何将关键点用于图像内容分析
- 检测关键点的不同技术
- 如何构建特征提取器
我们为什么要关心关键点?
图像内容分析是指理解图像内容的过程,以便我们可以据此采取一些措施。 让我们退后一步,谈谈人类是如何做到的。 我们的大脑是一个非常强大的机器,可以非常快速地完成复杂的事情。 当我们观察事物时,我们的大脑会根据该图像的有趣的方面自动创建足迹。 在本章中,我们将讨论有趣的方法。
目前,一个有趣的方面是该地区与众不同的地方。 如果我们将一个点称为有趣的点,那么在它的邻域中不应有另一个点满足约束条件。 让我们考虑下图:

现在,闭上你的眼睛,并尝试形象化这张图片。 您看到特定的东西了吗? 您可以回忆一下图像左半部分的内容吗? 并不是的! 这样做的原因是图像没有任何有趣的信息。 当我们的大脑看着这样的东西时,没有什么需要注意的,因此它会四处游荡! 让我们看一下下图:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cAA9y5lU-1681870901101)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/opencv-3x-py-example/img/f75b18a5-0ebb-4284-8b9e-8e1bb74b9300.jpg)]
现在,闭上你的眼睛,并尝试形象化这张图片。 您会看到回忆很生动,并且还记得有关此图像的许多细节。 原因是图像中有很多有趣的区域。 人眼对高频内容比低频内容更敏感。 这就是为什么我们倾向于比第一幅图像更好地收集第二幅图像的原因。 为了进一步说明这一点,让我们看一下下图:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nJiXdbr5-1681870901101)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/opencv-3x-py-example/img/4d36fa1b-83e6-4f0d-93c8-01ff066990dd.jpg)]
如果您注意到,即使它不在图像中心,您的视线也会立即移到电视遥控器上。 我们会自动趋向于图像中的有趣区域,因为这是所有信息所在的位置。 这是我们的大脑需要存储的内容,以便以后进行重新收集。
在构建对象识别系统时,我们需要检测这些有趣的区域,以创建图像的签名。 这些有趣的区域以关键点为特征。 这就是为什么关键点检测在许多现代计算机视觉系统中至关重要的原因。
关键点是什么?
现在我们知道关键点是指图像中有趣的区域,下面让我们更深入地进行研究。 关键点是什么? 这些要点在哪里? 当我们说有趣时,表示该区域正在发生某些事情。 如果该区域是统一的,那就不是很有趣。 例如,角点很有趣,因为强度在两个不同方向上急剧变化。 每个角都是两个边相交的唯一点。 如果查看前面的图像,您会发现有趣的区域并没有完全由有趣的内容组成。 如果仔细观察,我们仍然可以看到繁忙区域中的平原区域。 例如,考虑以下图像:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3w474Cds-1681870901101)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/opencv-3x-py-example/img/43262bcc-6ff8-45ab-a980-8dbe3030ec6f.png)]
如果您查看前面的对象,则有趣区域的内部部分不有趣:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Z6e3veYU-1681870901102)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/opencv-3x-py-example/img/32044b8b-e47b-4867-9eab-33079ca8c5d7.png)]
因此,如果要表征该对象,则需要确保选择了有趣的点。 现在,我们如何定义有趣点? 我们可以说没有什么不有趣的事情可能是一个有趣的观点吗? 让我们考虑以下示例:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-sTzBPPLE-1681870901102)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/opencv-3x-py-example/img/27350a15-0e27-4955-96d7-37e2ece5cbbf.png)]
现在,我们可以看到该图像沿边缘有很多高频内容。 但是我们不能称整个边缘为有趣的。 重要的是要理解有趣的不一定涉及颜色或强度值。 只要是不同的,它可以是任何东西。 我们需要隔离它们附近唯一的点。 沿边缘的点相对于它们的邻居不是唯一的。 那么,既然我们知道我们在寻找什么,我们如何挑选一个有趣的观点?
桌子的一角呢? 那很有趣,对不对? 就其邻居而言,它是独一无二的,我们附近没有类似的东西。 现在,可以选择这一点作为我们的关键点之一。 我们利用这些关键点来表征特定的图像。
在进行图像分析时,我们需要先将图像转换为数字形式,然后才能得出结论。 这些关键点使用数字形式表示,然后使用这些关键点的组合来创建图像签名。 我们希望该图像签名以最好的方式表示给定的图像。
检测角点
由于我们知道角点很有趣,因此让我们看一下如何检测它们。 在计算机视觉中,有一种流行的角点检测技术,称为哈里斯角点检测器。 我们基本上基于灰度图像的偏导数构造一个2x2矩阵,然后分析获得的特征值。 特征值是一组特殊的标量,与一组线性方程组相关联,这些方程组通过属于一起的像素群集提供有关图像的分段信息。 在这种情况下,我们使用它们来检测角点。 这实际上是对实际算法的过度简化,但涵盖了要点。 因此,如果您想了解基本的数学细节,可以在这个页面上查看 Harris 和 Stephens 的原始论文。角点是两个特征值都将具有较大值的点。
让我们考虑下图:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-flshCZlH-1681870901102)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/opencv-3x-py-example/img/8c474e59-9760-47d5-8302-f4730ed516ca.png)]
如果在此图像上运行哈里斯角点探测器,您将看到类似以下内容:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-I6UDBFge-1681870901102)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/opencv-3x-py-example/img/3ac56702-c2ad-433d-b92b-eb33cd578456.png)]
如您所见,所有黑点均对应于图像中的角。 您可能会注意到未检测到盒子底部的角。 原因是角点不够尖锐。 您可以在角点检测器中调整阈值以识别这些角点。 执行此操作的代码如下:
import cv2
import numpy as np
img = cv2.imread(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/opencv-3x-py-example/img/box.png')
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
gray = np.float32(gray)
# To detect only sharp corners
dst = cv2.cornerHarris(gray, blockSize=4, ksize=5, k=0.04)
# Result is dilated for marking the corners
dst = cv2.dilate(dst, None)
# Threshold for an optimal value, it may vary depending on the image
img[dst > 0.01*dst.max()] = [0,0,0]
cv2.imshow('Harris Corners(only sharp)',img)
# to detect soft corners
dst = cv2.cornerHarris(gray, blockSize=14, ksize=5, k=0.04)
dst = cv2.dilate(dst, None)
img[dst > 0.01*dst.max()] = [0,0,0]
cv2.imshow('Harris Corners(also soft)',img)
cv2.waitKey()
良好的跟踪特征
在许多情况下,Harris Corner Detector 的表现都不错,但在某些方面却漏了。 在哈里斯和斯蒂芬斯撰写原始论文大约六年后,史和托马西想出了一个更好的角检测器。 您可以在这里阅读原始论文。 J. Shi 和 C.Tomasi 使用了不同的评分函数来提高整体质量。 使用这种方法,我们可以找到给定图像中的 N 个最强角。 当我们不想使用每个角来从图像中提取信息时,这非常有用。
如果将 Shi-Tomasi 角点检测器应用于之前显示的图像,则会看到类似以下内容:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OXGLH2kD-1681870901103)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/opencv-3x-py-example/img/b6714991-e7ad-44ea-800f-41d30a7ff89f.png)]
以下是代码:
import cv2
import numpy as np
img = cv2.imread('images/box.png')
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
corners = cv2.goodFeaturesToTrack(gray, maxCorners=7, qualityLevel=0.05, minDistance=25)
corners = np.float32(corners)
for item in corners:
x, y = item[0]
cv2.circle(img, (x,y), 5, 255, -1)
cv2.imshow("Top 'k' features", img)
cv2.waitKey()
尺度不变特征变换(SIFT)
即使边角特征很有趣,它们也不足以表征真正有趣的部分。 当我们谈论图像内容分析时,我们希望图像签名对于诸如比例尺,旋转和照明之类的东西不变。 人类在这些事情上非常擅长。 即使我给您看的苹果颠倒的图像变暗,您仍然会识别它。 如果我向您展示该图像的放大版本,您仍会识别它。 我们希望我们的图像识别系统能够做到这一点。
让我们考虑角点特征。 如果放大图像,角点可能不再是角点,如下所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-egCFZVYP-1681870901103)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/opencv-3x-py-example/img/236f839e-d683-41f5-9b6c-a34ed2db6d20.png)]
在第二种情况下,检测器将不会拾取该角。 并且,由于它是在原始图像中拾取的,因此第二张图像将与第一张图像不匹配。 它基本上是相同的图像,但是基于角点特征的方法将完全错过它。 这意味着角点检测器并非完全不变。 这就是为什么我们需要一种更好的方法来表征图像的原因。
SIFT 是整个计算机视觉领域中最受欢迎的算法之一。 您可以在这个页面上阅读 David Lowe 的原始论文。 我们可以使用该算法提取关键点并构建相应的特征描述符。 在线上有很多好的文档,因此我们将简短地讨论。 为了确定潜在的关键点,SIFT 通过对图像进行下采样并获取高斯差来构建金字塔。 这意味着我们在每个级别上运行一个高斯过滤器,并利用差值在金字塔中构建连续的级别。 为了查看当前点是否为关键点,它会查看相邻点以及金字塔相邻级别中同一位置的像素。 如果是最大值,则将当前点作为关键点。 这样可以确保我们将关键点保持不变。
现在我们知道了 SIFT 如何实现尺度不变性,让我们看看它如何实现旋转不变性。 一旦我们确定了关键点,便为每个关键点分配了方向。 我们采用每个关键点附近的邻域,并计算梯度大小和方向。 这使我们对关键点的方向有所了解。 如果我们有此信息,即使旋转该关键点,也可以将其与另一个图像中的同一点进行匹配。 由于我们知道方向,因此我们可以在进行比较之前将这些关键点归一化。
一旦获得所有这些信息,我们如何量化它? 我们需要将其转换为一组数字,以便可以对其进行某种匹配。 为此,我们只需要围绕每个关键点设置16x16的邻域,并将其划分为 16 个大小为4x4的块。 对于每个块,我们使用八个面元计算方向直方图。 因此,我们有一个与每个块相关联的长度为 8 的向量,这意味着该邻域由大小为 128(8x16)的向量表示。 这是将要使用的最终关键点描述符。 如果从图像中提取N个关键点,则每个长度为 128 的N个描述符。N个描述符的数组表征了给定的图像。
考虑下图:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BpLaiBYQ-1681870901103)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/opencv-3x-py-example/img/8a4e8485-1a88-46e6-a19f-dc3d9e35c2d7.jpg)]
如果使用 SIFT 提取关键点位置,您将看到类似以下的内容,其中圆圈的大小指示关键点的强度,圆圈内的线指示方向:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SYvEnsIL-1681870901103)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/opencv-3x-py-example/img/ea2dea58-dd20-448a-9ceb-13d5d7968ea0.png)]
在查看代码之前,重要的是要知道 SIFT 已获得专利,并且不能免费商业使用。 以下是执行此操作的代码:
import cv2
import numpy as np
input_image = cv2.imread('images/fishing_house.jpg')
gray_image = cv2.cvtColor(input_image, cv2.COLOR_BGR2GRAY)
# For version opencv < 3.0.0, use cv2.SIFT()
sift = cv2.xfeatures2d.SIFT_create()
keypoints = sift.detect(gray_image, None)
cv2.drawKeypoints(input_image, keypoints, input_image, \
flags = cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS)
cv2.imshow('SIFT features', input_image)
cv2.waitKey()
我们还可以计算描述符。 OpenCV 让我们分开进行操作,或者我们可以通过使用以下步骤在同一步骤中组合检测和计算部分:
keypoints, descriptors = sift.detectAndCompute(gray_image, None)
加速的强大特征(SURF)
即使 SIFT 很好且有用,但它的计算量很大。 这意味着它很慢,如果使用 SIFT,我们将很难实现实时系统。 我们需要一个快速且具有 SIFT 所有优点的系统。 如果您还记得,SIFT 使用高斯差分来构建金字塔,并且此过程很慢。 因此,为克服此问题,SURF 使用简单的盒式过滤器来近似高斯。 好消息是,这确实很容易计算,而且速度相当快。 SURF 上有很多在线文档。 因此,您可以遍历它以了解他们如何构造描述符。 您也可以在这个页面上参考原始论文。 重要的是要知道 SURF 也已获得专利,并且不能免费用于商业用途。
如果在较早的图像上运行 SURF 关键点检测器,您将看到类似以下内容:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bL8LznAh-1681870901104)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/opencv-3x-py-example/img/8b2e2cb9-f3cc-4e98-8dfa-ad3ee9a90519.png)]
这是代码:
import cv2
import numpy as np
input_image = cv2.imread('images/fishing_house.jpg')
gray_image = cv2.cvtColor(input_image, cv2.COLOR_BGR2GRAY)
# For version opencv < 3.0.0, use cv2.SURF()
surf = cv2.xfeatures2d.SURF_create()
# This threshold controls the number of keypoints
surf.setHessianThreshold(15000)
keypoints, descriptors = surf.detectAndCompute(gray_image, None)
cv2.drawKeypoints(input_image, keypoints, input_image, color=(0,255,0),\ flags=cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS)
cv2.imshow('SURF features', input_image)
cv2.waitKey()
来自加速段测试的特征(FAST)
尽管 SURF 比 SIFT 快,但是对于实时系统而言,它还不够快,尤其是在存在资源限制的情况下。 当您在移动设备上构建实时应用时,您将无法享受使用 SURF 进行实时计算的奢华。 我们需要的是真正快速且计算便宜的东西。 因此,罗斯滕(Rosten)和德拉蒙德(Drummond)提出了 FAST。 顾名思义,它真的很快!
他们没有进行所有昂贵的计算,而是提出了一种高速测试来快速确定当前点是否是潜在的关键点。 我们需要注意,FAST 仅用于关键点检测。 一旦检测到关键点,就需要使用 SIFT 或 SURF 来计算描述符。 考虑下图:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-tmOHm6JY-1681870901104)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/opencv-3x-py-example/img/5062275d-7f88-4047-9178-aae0a41478ca.png)]
如果我们在此图像上运行 FAST 关键点检测器,您将看到类似以下内容:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-glUk23a1-1681870901104)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/opencv-3x-py-example/img/92906d68-6c10-4b84-a8cd-378fe765df0b.png)]
如果我们清理它并抑制不重要的关键点,它将看起来像这样:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XTYolpFO-1681870901104)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/opencv-3x-py-example/img/4121bff1-f5d4-4040-a308-0997f9c28f46.png)]
以下是此代码:
import cv2
import numpy as np
input_image = cv2.imread('images/tool.png')
gray_image = cv2.cvtColor(input_image, cv2.COLOR_BGR2GRAY)
# Version under opencv 3.0.0 cv2.FastFeatureDetector()
fast = cv2.FastFeatureDetector_create()
# Detect keypoints
keypoints = fast.detect(gray_image, None)
print("Number of keypoints with non max suppression:", len(keypoints))
# Draw keypoints on top of the input image
img_keypoints_with_nonmax=input_image.copy()
cv2.drawKeypoints(input_image, keypoints, img_keypoints_with_nonmax, color=(0,255,0), \ flags=cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS)
cv2.imshow('FAST keypoints - with non max suppression', img_keypoints_with_nonmax)
# Disable nonmaxSuppression
fast.setNonmaxSuppression(False)
# Detect keypoints again
keypoints = fast.detect(gray_image, None)
print("Total Keypoints without nonmaxSuppression:", len(keypoints))
# Draw keypoints on top of the input image
img_keypoints_without_nonmax=input_image.copy()
cv2.drawKeypoints(input_image, keypoints, img_keypoints_without_nonmax, color=(0,255,0), \ flags=cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS)
cv2.imshow('FAST keypoints - without non max suppression', img_keypoints_without_nonmax)
cv2.waitKey()
二进制鲁棒的独立基本特征(BRIEF)
即使我们有 FAST 来快速检测关键点,我们仍然必须使用 SIFT 或 SURF 来计算描述符。 我们还需要一种快速计算描述符的方法。 这就是 BRIEF 出现的地方。 摘要是一种提取特征描述符的方法。 它不能单独检测关键点,因此我们需要将其与关键点检测器结合使用。 BRIEF 的好处是它紧凑且快速。
考虑下图:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-sn3aUZ6w-1681870901105)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/opencv-3x-py-example/img/41adb87d-ecca-4bfd-bdf1-dbc82d96a1b6.jpg)]
BRIEF 获取输入关键点的列表并输出更新的列表。 因此,如果在此图像上运行“摘要”,您将看到类似以下内容:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jAvLJYK7-1681870901105)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/opencv-3x-py-example/img/f860bc36-6fe5-42df-9191-ff74f0f23d2a.png)]
以下是代码:
import cv2
import numpy as np
input_image = cv2.imread('images/house.jpg')
gray_image = cv2.cvtColor(input_image, cv2.COLOR_BGR2GRAY)
# Initiate FAST detector
fast = cv2.FastFeatureDetector_create()
# Initiate BRIEF extractor, before opencv 3.0.0 use cv2.DescriptorExtractor_create("BRIEF")
brief = cv2.xfeatures2d.BriefDescriptorExtractor_create()
# find the keypoints with STAR
keypoints = fast.detect(gray_image, None)
# compute the descriptors with BRIEF
keypoints, descriptors = brief.compute(gray_image, keypoints)
cv2.drawKeypoints(input_image, keypoints, input_image, color=(0,255,0))
cv2.imshow('BRIEF keypoints', input_image)
cv2.waitKey()
定向快速旋转 BRIEF(ORB)
因此,现在我们已经达到了到目前为止讨论的所有组合中的最佳组合。 该算法来自 OpenCV 实验室。 它是快速,强大且开源的! SIFT 和 SURF 算法均已获得专利,您不能将其用于商业目的; 这就是为什么 ORB 在许多方面都很好的原因。
如果在前面显示的图像之一上运行 ORB 关键点提取器,您将看到类似以下内容:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-O2mP6bs3-1681870901105)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/opencv-3x-py-example/img/f6c967ca-3614-4018-b781-b6a061e1b6ba.png)]
这是代码:
import cv2
import numpy as np
input_image = cv2.imread('images/fishing_house.jpg')
gray_image = cv2.cvtColor(input_image, cv2.COLOR_BGR2GRAY)
# Initiate ORB object, before opencv 3.0.0 use cv2.ORB()
orb = cv2.ORB_create()
# find the keypoints with ORB
keypoints = orb.detect(gray_image, None)
# compute the descriptors with ORB
keypoints, descriptors = orb.compute(gray_image, keypoints)
# draw only the location of the keypoints without size or orientation
cv2.drawKeypoints(input_image, keypoints, input_image, color=(0,255,0))
cv2.imshow('ORB keypoints', input_image)
cv2.waitKey()
总结
在本章中,我们了解了关键点的重要性以及为什么需要它们。 我们讨论了用于检测关键点和计算特征描述符的各种算法。 我们将在各种情况下的所有后续章节中使用这些算法。 关键点概念对于计算机视觉至关重要,并且在许多现代系统中都扮演着重要角色。
在下一章中,我们将讨论如何将同一场景的多个图像拼接在一起以创建全景图像。






![【PWN刷题wp】[BJDCTF 2020]babystack](https://img-blog.csdnimg.cn/1ab107b013584c0c973b5251a57fb9f0.png)