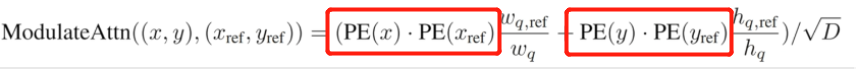原文:Learning OpenCV 4 Computer Vision with Python 3
协议:CC BY-NC-SA 4.0
译者:飞龙
本文来自【ApacheCN 计算机视觉 译文集】,采用译后编辑(MTPE)流程来尽可能提升效率。
当别人说你没有底线的时候,你最好真的没有;当别人说你做过某些事的时候,你也最好真的做过。
六、检索图像并将图像描述符用于搜索
与人眼和大脑相似,OpenCV 可以检测图像的主要特征并将其提取到所谓的图像描述符中。 然后可以将这些特征用作数据库,从而启用基于图像的搜索。 此外,我们可以使用关键点将图像拼接在一起并组成更大的图像。 (请考虑将许多图片组合在一起以形成 360° 全景图。)
本章将向您展示如何使用 OpenCV 检测图像的特征,并利用它们来匹配和搜索图像。 在本章中,我们将拍摄样本图像并检测其主要特征,然后尝试查找与样本图像匹配的另一幅图像的区域。 我们还将发现样本图像与另一幅图像的匹配区域之间的单应性或空间关系。
更具体地说,我们将介绍以下任务:
- 使用以下任何一种算法检测关键点并提取关键点周围的局部描述符:Harris 角,SIFT,SURF 或 ORB
- 使用暴力算法或 FLANN 算法匹配关键点
- 使用 KNN 和比率测试过滤掉不良匹配
- 查找两组匹配的关键点之间的单应性
- 搜索一组图像以确定哪个包含与参考图像最匹配的图像
我们将通过构建概念验证法证应用来结束本章。 给定纹身的参考图像,我们将搜索一组人的图像,以找到具有匹配纹身的人。
技术要求
本章使用 Python,OpenCV 和 NumPy。 关于 OpenCV,我们使用可选的opencv_contrib模块,其中包括用于关键点检测和匹配的其他算法。 要启用 SIFT 和 SURF 算法(已获得专利,并非为商业用途免费提供),我们必须在 CMake 中为opencv_contrib模块配置OPENCV_ENABLE_NONFREE标志。 有关安装说明,请参阅第 1 章,“设置 OpenCV”。 另外,如果尚未安装 Matplotlib,请通过运行$ pip install matplotlib(或$ pip3 install matplotlib(取决于您的环境))进行安装。
本章的完整代码可以在本书的 GitHub 存储库的chapter06文件夹中找到。 样本图像可在images文件夹中找到。
了解特征检测和匹配的类型
许多算法可用于检测和描述特征,我们将在本节中探讨其中的几种。 OpenCV 中最常用的特征检测和描述符提取算法如下:
- Harris:此算法对于检测角点很有用。
- SIFT:此算法对于检测斑点很有用。
- SURF:此算法可用于检测斑点。
- FAST:此算法对于检测角点很有用。
- BRIEF:此算法可用于检测斑点。
- ORB:该算法代表定向 FAST 和旋转 BRIEF。 对于检测角点和斑点的组合很有用。
可以使用以下方法执行匹配功能:
- 暴力匹配
- 基于 FLANN 的匹配
然后可以使用单应性进行空间验证。
我们刚刚介绍了许多新的术语和算法。 现在,我们将介绍它们的基本定义。
定义特征
到底有什么特征? 为什么图像的特定区域可以分类为特征,而其他区域则不能分类为特征? 从广义上讲,特征是图像中唯一或易于识别的兴趣区域。 角落和纹理细节密度高的区域是好的特征,而重复很多的图案和低密度区域(例如蓝天)则不是。 边缘是很好的特征,因为它们倾向于划分图像的两个区域。 斑点(图像的区域与其周围区域也大不相同)也是一个有趣的特征。
大多数特征检测算法都围绕角,边和斑点的识别,其中一些算法还关注脊的概念,您可以将其概念化为细长对象的对称轴。 (例如,考虑识别图像中的道路。)
有些算法更擅长识别和提取某种类型的特征,因此了解您的输入图像很重要,这样您就可以利用 OpenCV 传送带中最好的工具。
使用哈里斯检测角点
让我们开始使用哈里斯角点检测算法查找角点。 我们将通过示例来实现。 如果您在本书之外继续学习 OpenCV,您会发现棋盘格是计算机视觉分析的常见主题,部分原因是棋盘格模式适合于多种类型的特征检测,部分原因是国际象棋是一种流行的消遣方式,特别是在俄罗斯,许多 OpenCV 开发人员居住的地方。
这是我们的棋盘和棋子的示例图像:

OpenCV 具有称为cv2.cornerHarris的便捷函数,该函数可检测图像中的角。 在下面的基本示例中,我们可以看到此函数在起作用:
import cv2
img = cv2.imread('https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/learn-opencv4-cv-py3/img/chess_board.png')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
dst = cv2.cornerHarris(gray, 2, 23, 0.04)
img[dst > 0.01 * dst.max()] = [0, 0, 255]
cv2.imshow('corners', img)
cv2.waitKey()
让我们分析一下代码。 在常规导入之后,我们加载棋盘图像并将其转换为灰度。 然后,我们调用cornerHarris函数:
dst = cv2.cornerHarris(gray, 2, 23, 0.04)
这里最重要的参数是第三个参数,它定义了 Sobel 算子的孔径或核大小。 Sobel 运算符通过测量邻域中像素值之间的水平和垂直差异来检测边缘,并使用核进行此操作。 cv2.cornerHarris函数使用 Sobel 运算符,其光圈由该参数定义。 用简单的英语来说,这些参数定义了敏感角检测的程度。 它必须在 3 到 31 之间,并且是一个奇数值。 在3值低(高度敏感)的情况下,棋盘黑色正方形中的所有对角线在接触正方形的边界时都会注册为角。 对于23较高(较不敏感)的值,将仅将每个正方形的角检测为角。
cv2.cornerHarris返回浮点格式的图像。 该图像中的每个值代表源图像中相应像素的分数。 中等或高分表示该像素可能是一个角。 相反,我们可以将得分最低的像素视为非角。 考虑以下行:
img[dst > 0.01 * dst.max()] = [0, 0, 255]
在这里,我们选择分数至少为最高分数的 1% 的像素,并在原始图像中将这些像素着色为红色。 结果如下:

大! 几乎所有检测到的角都标记为红色。 标记的点几乎包括棋盘正方形的所有角。
如果在cv2.cornerHarris中调整第二个参数,我们将看到较小的区域(对于较小的参数值)或较大的区域(对于较大的参数值)将被检测为角点。 此参数称为块大小。
检测 DoG 特征并提取 SIFT 描述符
先前使用cv2.cornerHarris的技术非常适合检测角点,并且由于角点就是角点而具有明显的优势。 即使旋转图像,也会检测到它们。 但是,如果我们将图像缩放为较小或较大的尺寸,则图像的某些部分可能会丢失甚至获得角点质量。
例如,在 F1 意大利大奖赛赛道图像中查看以下角点检测:
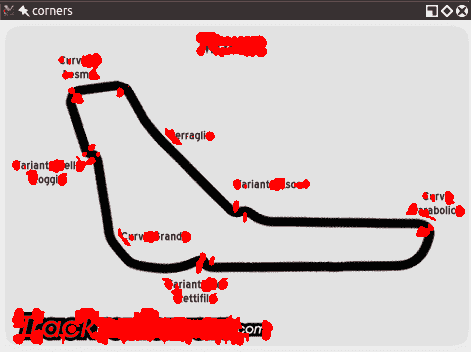
以下是使用同一图像的较小版本的角点检测结果:
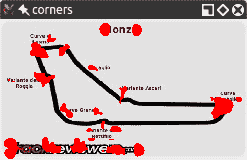
您会注意到角落更加凝结了。 但是,即使我们获得了一些优势,我们也失去了一些优势! 特别是,让我们研究一下瓦里安特·阿斯卡里弯锥,它看起来像是从西北向东南一直延伸的那部分赛道尽头的弯弯曲曲。 在较大的图像版本中,双折弯的入口和顶点均被检测为角。 在较小的图像中,无法像这样检测到顶点。 如果我们进一步缩小图像,从某种程度上说,我们也将失去通往那个弯道的入口。
特征的丧失引发了一个问题。 我们需要一种无论图像大小如何都可以工作的算法。 输入比例不变特征变换(SIFT)。 尽管这个名称听起来有些神秘,但现在我们知道我们要解决的问题,这实际上是有道理的。 我们需要一个函数(一个变换)来检测特征(一个特征变换),并且不会根据图像的缩放比例输出不同的结果(缩放不变的特征变换)。 请注意,SIFT 不会检测关键点(这是通过高斯差异(DoG 来完成的);而是通过特征向量描述了围绕它们的区域。
对 DoG 的快速介绍是有序的。 之前,在第 3 章“使用 OpenCV 处理图像”中,我们讨论了低通过滤器和模糊操作,特别是cv2.GaussianBlur()函数。 DoG 是对同一图像应用不同的高斯过滤器的结果。 以前,我们将这种类型的技术应用于边缘检测,这里的想法是相同的。 DoG 操作的最终结果包含兴趣区域(关键点),然后将通过 SIFT 描述这些区域。
让我们看看下图中的 DoG 和 SIFT 的行为,图中充满了角落和特征:

在这里,瓦雷泽(Varese)的美丽全景(位于意大利伦巴第)作为计算机视觉的主题而声名 new 起。 这是生成此已处理图像的代码:
import cv2
img = cv2.imread('https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/learn-opencv4-cv-py3/img/varese.jpg')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
sift = cv2.xfeatures2d.SIFT_create()
keypoints, descriptors = sift.detectAndCompute(gray, None)
cv2.drawKeypoints(img, keypoints, img, (51, 163, 236),
cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS)
cv2.imshow('sift_keypoints', img)
cv2.waitKey()
在常规导入后,我们加载要处理的图像。 然后,我们将图像转换为灰度。 到目前为止,您可能已经收集到 OpenCV 中的许多方法都希望将灰度图像作为输入。 下一步是创建 SIFT 检测对象并计算灰度图像的特征和描述符:
sift = cv2.xfeatures2d.SIFT_create()
keypoints, descriptors = sift.detectAndCompute(gray, None)
在幕后,这些简单的代码行执行了一个复杂的过程。 我们创建一个cv2.SIFT对象,该对象使用 DoG 来检测关键点,然后为每个关键点的周围区域计算特征向量。 就像detectAndCompute方法的名称清楚地表明的那样,执行了两个主要操作:特征检测和描述符的计算。 该操作的返回值是一个元组,其中包含一个关键点列表和另一个关键点描述符的列表。
最后,我们通过使用cv2.drawKeypoints函数在其上绘制关键点,然后使用常规的cv2.imshow函数来显示该图像来处理该图像。 作为其参数之一,cv2.drawKeypoints函数接受一个标志,该标志指定我们想要的可视化类型。 在这里,我们指定cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINT以绘制每个关键点的比例和方向的可视化。
关键点剖析
每个关键点都是cv2.KeyPoint类的实例,该类具有以下属性:
pt(点)属性包含图像中关键点的x和y坐标。size属性指示特征的直径。angle属性指示特征的方向,如先前处理的图像中的径向线所示。response属性指示关键点的强度。 SIFT 将某些特征归类为比其他特征更强,并且response是您要检查以评估特征强度的属性。octave属性指示图像金字塔中找到特征的层。 让我们简要回顾一下图像金字塔的概念,我们在“概念化 Haar 级联”部分的第 5 章,“检测和识别人脸”中进行了讨论。 SIFT 算法以与人脸检测算法相似的方式运行,因为它迭代地处理相同的图像,但是在每次迭代时都会更改输入。 特别地,图像的比例尺是在算法的每次迭代(octave)时都会变化的参数。 因此,octave属性与检测到关键点的图像比例有关。- 最后,
class_id属性可用于将自定义标识符分配给一个关键点或一组关键点。
检测快速 Hessian 特征并提取 SURF 描述符
计算机视觉是计算机科学中一个相对较年轻的分支,因此许多著名的算法和技术只是最近才发明的。 实际上,SIFT 才 21 岁,由 David Lowe 于 1999 年出版。
SURF 是一种特征检测算法,由 Herbert Bay 于 2006 年发布。 SURF 比 SIFT 快几倍,并且部分受其启发。
请注意,SIFT 和 SURF 都是专利算法,因此,仅在使用OPENCV_ENABLE_NONFREE CMake 标志的opencv_contrib构建中可用。
理解 SURF 是如何在后台运行的,与本书没有特别的关系,因为我们可以在应用中使用它并充分利用它。 重要的是要理解的是cv2.SURF是一个 OpenCV 类,它使用 Fast Hessian 算法执行关键点检测并使用 SURF 执行描述符提取,就像cv2.SIFT类使用 DoG 执行关键点检测并使用 SIFT 执行描述符提取。
同样,好消息是 OpenCV 为其所有受支持的特征检测和描述符提取算法提供了标准化的 API。 因此,仅需很小的更改,我们就可以使我们先前的代码示例适应于使用 SURF 而不是 SIFT。 这是修改后的代码,其中的更改以粗体显示:
import cv2
img = cv2.imread('https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/learn-opencv4-cv-py3/img/varese.jpg')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
surf = cv2.xfeatures2d.SURF_create(8000)
keypoints, descriptor = surf.detectAndCompute(gray, None)
cv2.drawKeypoints(img, keypoints, img, (51, 163, 236),
cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS)
cv2.imshow('surf_keypoints', img)
cv2.waitKey()
cv2.xfeatures2d.SURF_create的参数是 Fast Hessian 算法的阈值。 通过增加阈值,我们可以减少将保留的特征数量。 阈值为8000,我们得到以下结果:

尝试调整阈值以查看其如何影响结果。 作为练习,您可能希望使用控制阈值的滑块构建 GUI 应用。 这样,用户可以调整阈值并查看特征数量以反比例的方式增加和减少。 我们在第 4 章,“深度估计和分段”中使用滑块构建了 GUI 应用,在“使用普通摄像机的深度估计”中,因此您可能需要回到并参考该部分作为指导。
接下来,我们将检查 FAST 角点检测器,BRIEF 关键点描述符和 ORB(将 FAST 和 BRIEF 一起使用)。
将 ORB 与 FAST 特征和 BRIEF 描述符一起使用
如果 SIFT 年龄较小,而 SURF 年龄较小,则 ORB 处于婴儿期。 ORB 于 2011 年首次发布,是 SIFT 和 SURF 的快速替代方案。
该算法已发表在论文《ORB:SIFT 或 SURF 的有效替代品》中,可通过 PDF 格式在这个页面中找到。
ORB 混合了 FAST 关键点检测器和 BRIEF 关键点描述符中使用的技术,因此值得快速了解 FAST 和 BRIEF。 然后,我们将讨论暴力匹配-一种用于特征匹配的算法-并查看特征匹配的示例。
FAST
来自加速段测试的特征(FAST)算法通过分析 16 个像素的圆形邻域来工作。 它将邻近区域中的每个像素标记为比特定阈值更亮或更暗,该特定阈值是相对于圆心定义的。 如果邻域包含多个标记为亮或暗的连续像素,则认为该邻域是一个角。
FAST 还使用高速测试,有时仅检查 2 或 4 个像素(而不是 16 个像素)就可以确定邻域不是角点。要了解该测试的工作原理,请看下面的图表 OpenCV 文档:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pL0QgaQu-1681871605260)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/learn-opencv4-cv-py3/img/1f5bcf2b-743f-4078-8588-2bd024ed2d36.png)]
在这里,我们可以看到两个不同放大倍数的 16 像素邻域。 位置 1、5、9 和 13 处的像素对应于圆形邻域边缘处的四个基点。 如果邻域是一个角,我们希望在这四个像素中,三个或恰好一个比阈值亮。 (另一种说法是,正好一个或正好三个都比阈值暗。)如果正好两个都比阈值亮,那么我们有一个边缘,而不是一个角。 如果其中恰好有四个或恰好零个比阈值亮,那么我们有一个相对统一的邻域,既不是角点也不是边缘。
FAST 是一种聪明的算法,但并非没有缺点,为了弥补这些缺点,分析图像的开发人员可以实现机器学习方法,以便将一组图像(与给定应用相关)馈送到算法中,以便优化类似阈值的参数。 无论开发人员直接指定参数还是为机器学习方法提供训练集,FAST 都是一种对开发人员的输入敏感的算法,可能比 SIFT 更为敏感。
BRIEF
另一方面,二进制鲁棒独立基本特征(BRIEF)不是特征检测算法,而是描述符。 让我们更深入地了解描述符是什么的概念,然后看一下 BRIEF。
当我们先前使用 SIFT 和 SURF 分析图像时,整个过程的核心是对detectAndCompute函数的调用。 该函数执行两个不同的步骤-检测和计算-并且它们返回两个不同的结果,并以元组为单位。
检测的结果是一组关键点。 计算的结果是这些关键点的一组描述符。 这意味着 OpenCV 的cv2.SIFT和cv2.SURF类实现用于检测和描述的算法。 但是请记住,原始的 SIFT 和 SURF 不是特征检测算法。 OpenCV 的cv2.SIFT实现了 DoG 特征检测和 SIFT 描述,而 OpenCV 的cv2.SURF实现了快速黑森特征检测和 SURF 描述。
关键点描述符是图像的表示形式,可以用作特征匹配的网关,因为您可以比较两个图像的关键点描述符并找到共同点。
BRIEF 是当前可用的最快的描述符之一。 BRIEF 背后的理论非常复杂,但可以说 BRIEF 采用了一系列优化,使其成为特征匹配的很好选择。
暴力匹配
暴力匹配器是描述符匹配器,它比较两组关键点描述符并生成结果,该结果是匹配项列表。 之所以称为暴力是因为该算法几乎没有优化。 对于第一组中的每个关键点描述符,匹配器将与第二组中的每个关键点描述符进行比较。 每次比较都会产生一个距离值,并且可以根据最小距离选择最佳匹配。
更一般而言,在计算中,术语暴力与优先使用所有可能组合(例如,所有可能的字符组合以破解已知长度的密码)的方法相关联。 相反,优先考虑速度的算法可能会跳过某些可能性,并尝试采用一条捷径来解决似乎最合理的解决方案。
OpenCV 提供了cv2.BFMatcher类,该类支持多种用于暴力特征匹配的方法。
在两个图像中匹配徽标
现在我们对 FAST 和 BRIEF 有了一个大致的了解,我们可以理解为什么 ORB 背后的团队(由 Ethan Rublee,Vincent Rabaud,Kurt Konolige 和 Gary R. Bradski 组成)选择这两种算法作为 ORB 的基础。
在他们的论文中,作者旨在实现以下结果:
- 在 FAST 中添加了快速准确的定位组件
- 定向 BRIEF 特征的有效计算
- 定向 BRIEF 特征的方差和相关性分析
- 一种在旋转不变性下解相关简短特征的学习方法,从而在最近邻应用中获得更好的表现
要点很明确:ORB 旨在优化和加速操作,包括非常重要的步骤,即以旋转感知的方式使用 BRIEF,以便即使在训练图像与旋转图像有很大不同的情况下,也可以改善匹配度。 查询图片。
不过,在这个阶段,也许您已经掌握了足够的理论,并且想深入了解某些特征匹配,所以让我们看一些代码。 以下脚本尝试将徽标中的特征与包含徽标的照片中的特征进行匹配:
import cv2
from matplotlib import pyplot as plt
# Load the images.
img0 = cv2.imread('https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/learn-opencv4-cv-py3/img/nasa_logo.png',
cv2.IMREAD_GRAYSCALE)
img1 = cv2.imread('https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/learn-opencv4-cv-py3/img/kennedy_space_center.jpg',
cv2.IMREAD_GRAYSCALE)
# Perform ORB feature detection and description.
orb = cv2.ORB_create()
kp0, des0 = orb.detectAndCompute(img0, None)
kp1, des1 = orb.detectAndCompute(img1, None)
# Perform brute-force matching.
bf = cv2.BFMatcher(cv2.NORM_HAMMING, crossCheck=True)
matches = bf.match(des0, des1)
# Sort the matches by distance.
matches = sorted(matches, key=lambda x:x.distance)
# Draw the best 25 matches.
img_matches = cv2.drawMatches(
img0, kp0, img1, kp1, matches[:25], img1,
flags=cv2.DRAW_MATCHES_FLAGS_NOT_DRAW_SINGLE_POINTS)
# Show the matches.
plt.imshow(img_matches)
plt.show()
让我们逐步检查该代码。 常规导入后,我们以灰度格式加载两个图像(查询图像和场景)。 这是查询图像,它是 NASA 徽标:

这是肯尼迪航天中心的现场照片:

现在,我们继续创建 ORB 特征检测器和描述符:
# Perform ORB feature detection and description.
orb = cv2.ORB_create()
kp0, des0 = orb.detectAndCompute(img0, None)
kp1, des1 = orb.detectAndCompute(img1, None)
以与 SIFT 和 SURF 相似的方式,我们检测并计算两个图像的关键点和描述符。
从这里开始,概念非常简单:遍历描述符并确定它们是否匹配,然后计算该匹配的质量(距离)并对匹配进行排序,以便我们可以显示顶部的n确实可以匹配两个图像上的特征,因此具有一定的可信度。 cv2.BFMatcher为我们做到这一点:
# Perform brute-force matching.
bf = cv2.BFMatcher(cv2.NORM_HAMMING, crossCheck=True)
matches = bf.match(des0, des1)
# Sort the matches by distance.
matches = sorted(matches, key=lambda x:x.distance)
在这个阶段,我们已经拥有了所需的所有信息,但是作为计算机视觉爱好者,我们非常重视视觉表示数据,因此让我们在matplotlib图表中绘制这些匹配项:
# Draw the best 25 matches.
img_matches = cv2.drawMatches(
img0, kp0, img1, kp1, matches[:25], img1,
flags=cv2.DRAW_MATCHES_FLAGS_NOT_DRAW_SINGLE_POINTS)
# Show the matches.
plt.imshow(img_matches)
plt.show()
Python 的切片语法非常强大。 如果matches列表包含少于 25 个条目,则matches[:25]切片命令将毫无问题地运行,并为我们提供一个包含与原始元素一样多的元素的列表。
结果如下:
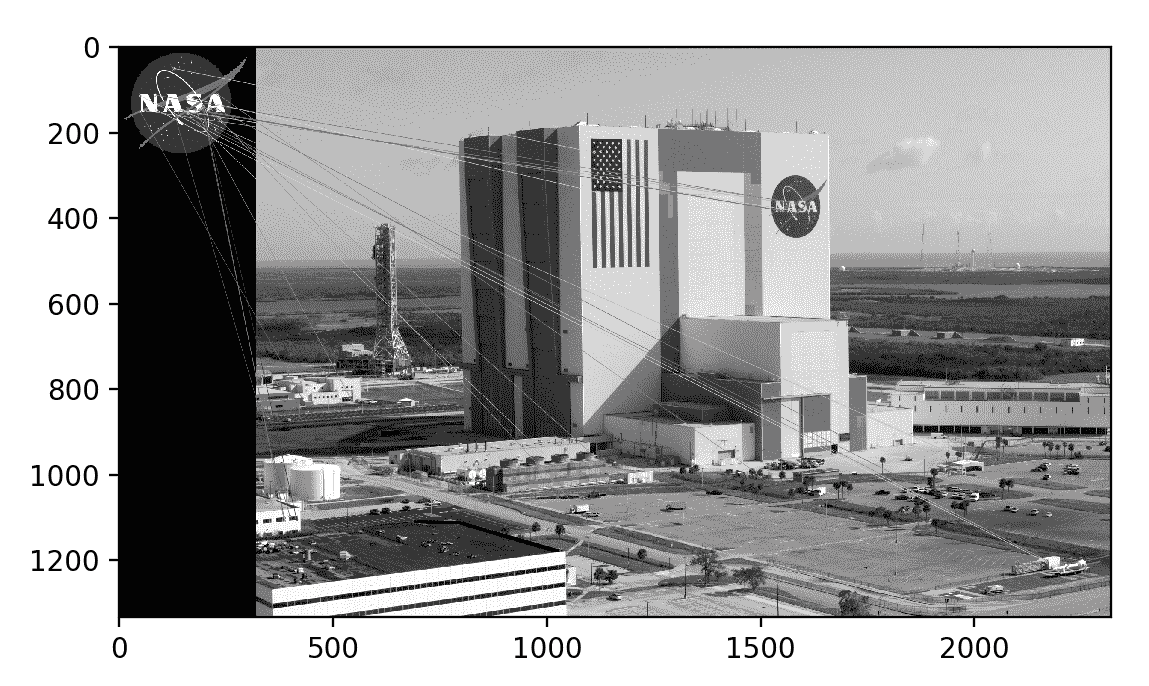
您可能会认为这是令人失望的结果。 确实,我们可以看到大多数匹配项都是错误的匹配项。 不幸的是,这是很典型的。 为了改善结果,我们需要应用其他技术来滤除不良匹配。 接下来,我们将注意力转移到此任务上。
使用 K 最近邻和比率测试过滤匹配
想象一下,一大批著名的哲学家要您对有关生命,宇宙和一切至关重要的问题进行辩论。 您在每个哲学家轮流讲话时会仔细听。 最后,当所有哲学家用尽了所有论点之后,您便会回顾自己的笔记并意识到以下两点:
- 每个哲学家都不同意
- 没有一个哲学家比其他哲学家更具说服力
从您的第一个观察中,您可以推断出最多一个哲学家是正确的; 但是,所有哲学家都有可能犯错。 然后,从第二个观察中,您开始担心自己有可能选择错误的哲学家,即使其中一位哲学家是正确的。 不管您怎么看,这些人都让您陷入僵局。 您称其为平局,说辩论中最重要的问题仍未解决。
我们可以将判断哲学家辩论的假想问题与排除不良关键点匹配的实际问题进行比较。
首先,我们假设查询图像中的每个关键点在场景中最多只有一个正确的匹配项。 暗示地,如果我们的查询图像是 NASA 徽标,则我们假设另一幅图像-场景-最多包含一个 NASA 徽标。 假设查询关键点最多只有一个正确或良好的匹配项,所以当我们考虑所有可能的匹配项时,我们主要观察到错误的匹配项。 因此,暴力匹配器会为每个可能的匹配计算一个距离得分,可以使我们对不良匹配的距离得分有很多观察。 我们期望良好的比赛比许多不良的比赛具有更好的(较低)距离得分,因此不良比赛的得分可以帮助我们选择良好比赛的门槛。 这样的阈值不一定能在不同的查询关键点或不同的场景之间很好地概括,但至少在个案的基础上可以帮助我们。
现在,让我们考虑一种改进的暴力匹配算法的实现,该算法以我们描述的方式自适应地选择距离阈值。 在上一节的代码示例中,我们使用cv2.BFMatcher类的match方法来获取包含每个查询关键点的单个最佳(最小距离)匹配的列表。 这样,我们就丢弃了所有可能更差的比赛的距离得分的信息,这是我们采用自适应方法所需的信息。 幸运的是,cv2.BFMatcher还提供了knnMatch方法,该方法接受参数k,该参数指定我们要为每个查询关键点保留的最佳(最小距离)匹配的最大数目。 (在某些情况下,我们得到的匹配数可能少于最大值)。KNN 代表 K 最近邻。
我们将使用knnMatch方法为每个查询关键点请求两个最佳匹配的列表。 基于我们的假设,即每个查询关键点最多具有一个正确的匹配项,因此我们确信第二好的匹配项是错误的。 我们将次优匹配的距离得分乘以小于 1 的值以获得阈值。
然后,仅当其远处分数小于阈值时,我们才将最佳匹配视为良好匹配。 这种方法称为比率测试,最早由 SIFT 算法的作者 David Lowe 提出。 他在论文《比例不变关键点中的独特图像特征》中描述了比率测试,可从这个页面。 具体来说,在“对象识别”的应用部分中,他指出:
“匹配正确的可能性可以通过计算从最近邻到第二次邻居的距离之比来确定。”
我们可以像上一节代码示例中一样的方式加载图像,检测关键点并计算 ORB 描述符。 然后,我们可以使用以下两行代码执行暴力 KNN 匹配:
# Perform brute-force KNN matching.
bf = cv2.BFMatcher(cv2.NORM_HAMMING, crossCheck=False)
pairs_of_matches = bf.knnMatch(des0, des1, k=2)
knnMatch返回列表列表; 每个内部列表至少包含一个匹配项,并且不超过k个匹配项,从最佳(最短距离)到最差排序。 以下代码行根据最佳匹配的距离得分对外部列表进行排序:
# Sort the pairs of matches by distance.
pairs_of_matches = sorted(pairs_of_matches, key=lambda x:x[0].distance)
让我们画出前 25 个最佳比赛,以及knnMatch可能与之配对的次佳比赛。 我们无法使用cv2.drawMatches函数,因为它仅接受一维匹配项列表; 相反,我们必须使用cv2.drawMatchesKnn。 以下代码用于选择,绘制和显示匹配项:
# Draw the 25 best pairs of matches.
img_pairs_of_matches = cv2.drawMatchesKnn(
img0, kp0, img1, kp1, pairs_of_matches[:25], img1,
flags=cv2.DRAW_MATCHES_FLAGS_NOT_DRAW_SINGLE_POINTS)
# Show the pairs of matches.
plt.imshow(img_pairs_of_matches)
plt.show()
到目前为止,我们还没有过滤掉任何不正确的比赛-实际上,我们故意包括了第二好的比赛,我们认为这是糟糕的-因此结果看起来很混乱。 这里是:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wj2LNaAt-1681871605261)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/learn-opencv4-cv-py3/img/7000bd41-2787-4857-a612-7881cafcdcba.png)]
现在,让我们应用比率测试。 我们将阈值设置为第二好的比赛的距离得分的 0.8 倍。 如果knnMatch无法提供次佳的比赛,我们仍然会拒绝最佳比赛,因为我们无法应用测试。 以下代码适用于这些条件,并为我们提供了通过测试的最佳匹配项列表:
# Apply the ratio test.
matches = [x[0] for x in pairs_of_matches
if len(x) > 1 and x[0].distance < 0.8 * x[1].distance]
应用了比率测试之后,现在我们仅处理最佳匹配(而不是最佳匹配和次佳匹配对),因此我们可以使用cv2.drawMatches而不是cv2.drawMatchesKnn来绘制它们。 同样,我们将从列表中选择前 25 个匹配项。 以下代码用于选择,绘制和显示匹配项:
# Draw the best 25 matches.
img_matches = cv2.drawMatches(
img0, kp0, img1, kp1, matches[:25], img1,
flags=cv2.DRAW_MATCHES_FLAGS_NOT_DRAW_SINGLE_POINTS)
# Show the matches.
plt.imshow(img_matches)
plt.show()
在这里,我们可以看到通过比率测试的匹配项:

将输出图像与上一节中的图像进行比较,我们可以看到 KNN 和比率测试使我们能够过滤掉许多不良匹配项。 其余比赛并不完美,但几乎所有比赛都指向正确的区域-肯尼迪航天中心侧面的 NASA 徽标。
我们已经有了良好的开端。 接下来,我们将使用名为 FLANN 的更快的匹配器替换暴力匹配器。 之后,我们将学习如何用单应性来描述一组匹配项-即二维变换矩阵,该矩阵表示匹配对象的位置,旋转,比例和其他几何特征。
使用 FLANN 的匹配
FLANN 代表用于近似最近邻的快速库。 根据许可的 2 条款 BSD 许可,这是一个开源库。 FLANN 的官方互联网主页是这个页面。 以下是该网站的报价:
“FLANN 是一个用于在高维空间中执行快速近似最近邻搜索的库。它包含我们发现最适合最近邻搜索的算法集合,以及一个根据数据集自动选择最佳算法和最佳参数的系统
FLANN 用 C++ 编写,并且包含以下语言的绑定:C,MATLAB 和 Python。”
换句话说,FLANN 有一个很大的工具箱,它知道如何为工作选择正确的工具,并且会说几种语言。 这些功能使资料库快速便捷。 实际上,FLANN 的作者声称,对于许多数据集而言,它比其他最近邻搜索软件快 10 倍。
作为独立的库,可以在 GitHub 上找到 FLANN。 但是,我们将 FLANN 用作 OpenCV 的一部分,因为 OpenCV 为此提供了一个方便的包装器。
为了开始我们的 FLANN 匹配的实际示例,让我们导入 NumPy,OpenCV 和 Matplotlib,并从文件中加载两个图像。 以下是相关代码:
import numpy as np
import cv2
from matplotlib import pyplot as plt
img0 = cv2.imread('https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/learn-opencv4-cv-py3/img/gauguin_entre_les_lys.jpg',
cv2.IMREAD_GRAYSCALE)
img1 = cv2.imread('https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/learn-opencv4-cv-py3/img/gauguin_paintings.png',
cv2.IMREAD_GRAYSCALE)
这是我们的脚本正在加载的第一张图像-查询图像:

此艺术品是保罗·高更(Paul Gauguin)在 1889 年绘制的《Entre les lys》(在百合花中)。我们将在包含高更的多幅作品的较大图像中搜索匹配的关键点, 本书的一位作者绘制的一些杂乱无章的形状。 这是更大的图像:
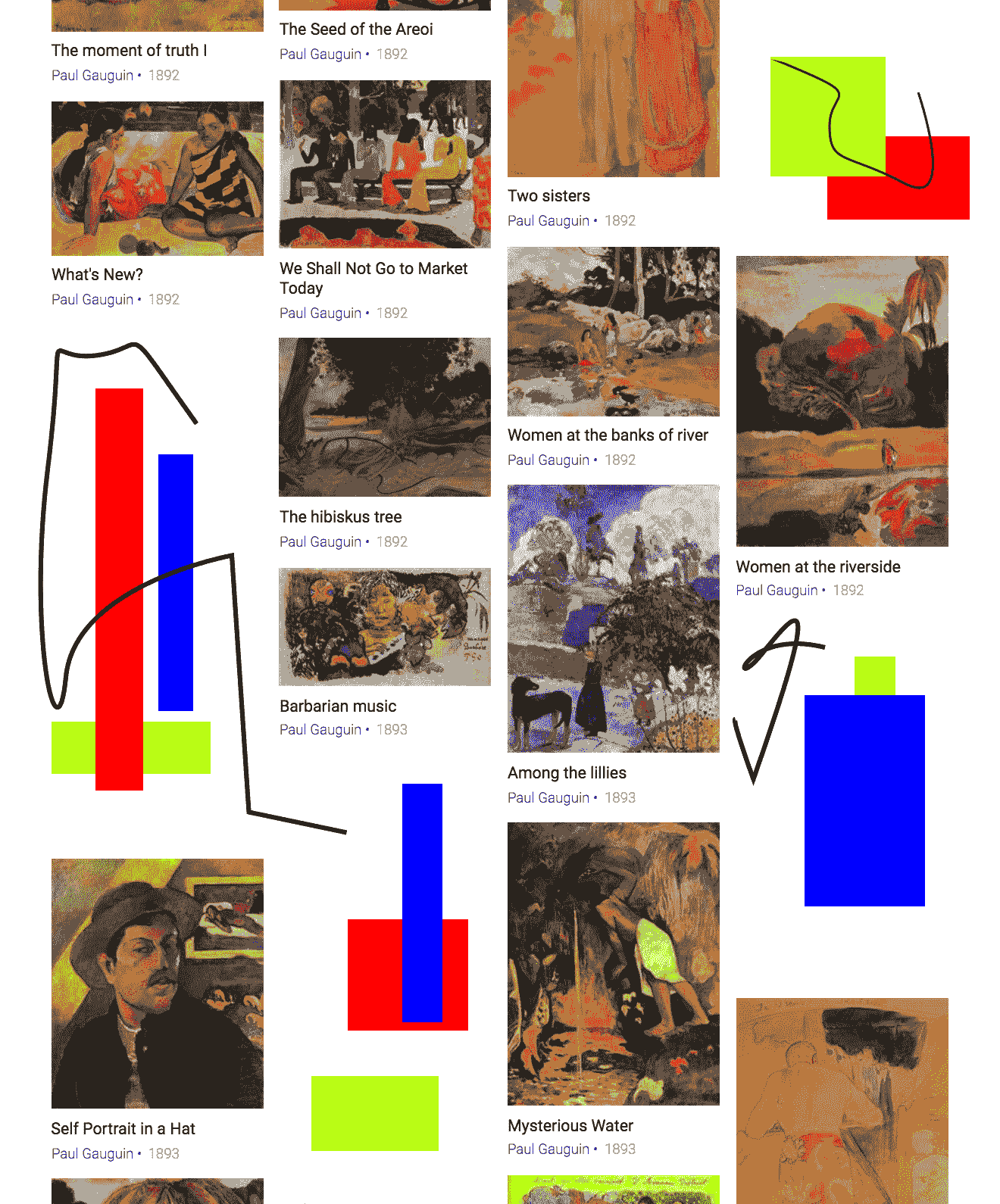
在较大的图像中,《Entre les lys》出现在第三列第三行中。 查询图像和较大图像的对应区域不相同; 他们以略微不同的颜色和不同的比例描绘了《Entre les lys》。 但是,对于我们的匹配器来说,这应该是一个简单的例子。
让我们检测必要的关键点并使用cv2.SIFT类提取特征:
# Perform SIFT feature detection and description.
sift = cv2.xfeatures2d.SIFT_create()
kp0, des0 = sift.detectAndCompute(img0, None)
kp1, des1 = sift.detectAndCompute(img1, None)
到目前为止,该代码应该看起来很熟悉,因为我们已经在本章的几个部分中专门介绍了 SIFT 和其他描述符。 在前面的示例中,我们将描述符提供给cv2.BFMatcher以进行暴力匹配。 这次,我们将改为使用cv2.FlannBasedMatcher。 以下代码使用自定义参数执行基于 FLANN 的匹配:
# Define FLANN-based matching parameters.
FLANN_INDEX_KDTREE = 1
index_params = dict(algorithm=FLANN_INDEX_KDTREE, trees=5)
search_params = dict(checks=50)
# Perform FLANN-based matching.
flann = cv2.FlannBasedMatcher(index_params, search_params)
matches = flann.knnMatch(des0, des1, k=2)
在这里,我们可以看到 FLANN 匹配器采用两个参数:indexParams对象和searchParams对象。 这些参数在 Python 中以字典的形式(在 C++ 中以结构的形式)传递,确定了索引的行为以及搜索对象,FLANN 在内部使用这些对象来计算匹配项。 我们选择的参数在精度和处理速度之间取得合理的平衡。 具体来说,我们使用核密度树(kd-tree)索引算法,其中有五棵树,FLANN 可以并行处理。 (FLANN 文档建议在一棵不提供并行性的树和 16 棵树之间(如果系统可以利用它,则可以提供高度的并行性)。)
我们正在对每棵树执行 50 次检查或遍历。 数量更多的支票可以提供更高的准确率,但计算成本更高。
在执行基于 FLANN 的匹配后,我们使用系数为 0.7 的 Lowe 比率测试。 为了演示不同的编码风格,我们将使用比率测试的结果与上一节代码示例中的结果稍有不同。 以前,我们组装了一个仅包含良好匹配项的新列表。 这次,我们将组装一个名为mask_matches的列表,其中每个元素都是长度为k的子列表(与传递给knnMatch的k相同)。 如果匹配良好,则将子列表的相应元素设置为1; 否则,我们将其设置为0。
例如,如果我们有mask_matches = [[0, 0], [1, 0]],则意味着我们有两个匹配的关键点; 对于第一个关键点,最佳匹配和次佳匹配都不好,而对于第二个关键点,最佳匹配很好,但次佳匹配不好。 记住,我们假设所有次佳的比赛都是不好的。 我们使用以下代码进行比率测试并构建遮罩:
# Prepare an empty mask to draw good matches.
mask_matches = [[0, 0] for i in range(len(matches))]
# Populate the mask based on David G. Lowe's ratio test.
for i, (m, n) in enumerate(matches):
if m.distance < 0.7 * n.distance:
mask_matches[i]=[1, 0]
现在,是时候绘制并显示良好的匹配。 我们可以将mask_matches列表作为可选参数传递给cv2.drawMatchesKnn,如以下代码段中的粗体所示:
# Draw the matches that passed the ratio test.
img_matches = cv2.drawMatchesKnn(
img0, kp0, img1, kp1, matches, None,
matchColor=(0, 255, 0), singlePointColor=(255, 0, 0),
matchesMask=mask_matches, flags=0)
# Show the matches.
plt.imshow(img_matches)
plt.show()
cv2.drawMatchesKnn仅在遮罩中绘制我们标记为良好的匹配项(值为1)。 让我们揭晓结果。 我们的脚本对基于 FLANN 的匹配产生以下可视化效果:
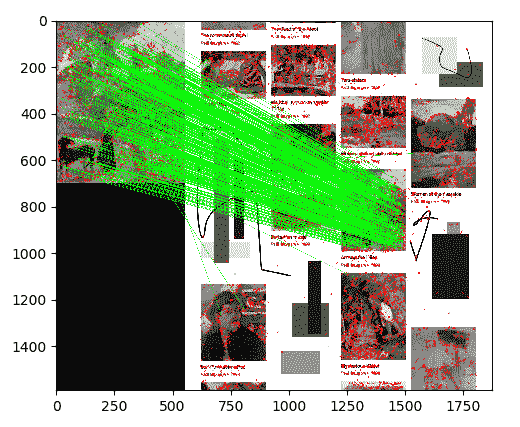
这是令人鼓舞的情况:看来几乎所有比赛都在正确的位置。 接下来,让我们尝试将这种类型的结果简化为更简洁的几何表示法-单应性法-它可以描述整个匹配对象的姿态,而不是一堆断开的匹配点的姿态。
通过基于 FLANN 的匹配执行单应性
首先,什么是单应性? 让我们从互联网上阅读一个定义:
“两个图形之间的关系,使得一个图形的任意一点对应一个图形,而另一图形又对应一个图形,反之亦然。因此,在圆上滚动的切线将圆的两个固定切线切成同形的两组点。”
如果您-像本书的作者一样-不是前面定义的明智者,您可能会发现以下解释更清楚:单应性是一种条件,即当一个图是另一个图的透视变形时,两个图会互相发现 。
首先,让我们看一下我们要实现的目标,以便我们可以完全理解单应性。 然后,我们将遍历代码。
假设我们要搜索以下纹身:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WyhGIxSS-1681871605262)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/learn-opencv4-cv-py3/img/24caa145-7d5e-49c4-b72d-4d4c2b682a17.png)]
尽管存在旋转差异,但作为人类,我们可以轻松地在下图中找到纹身:
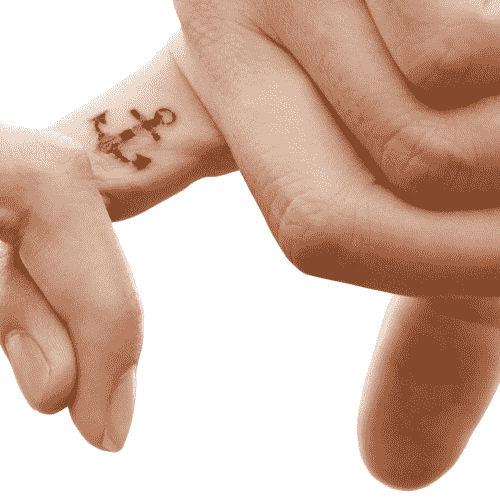
作为计算机视觉中的一项练习,我们想编写一个脚本,以产生以下关键点匹配和单应性的可视化效果:
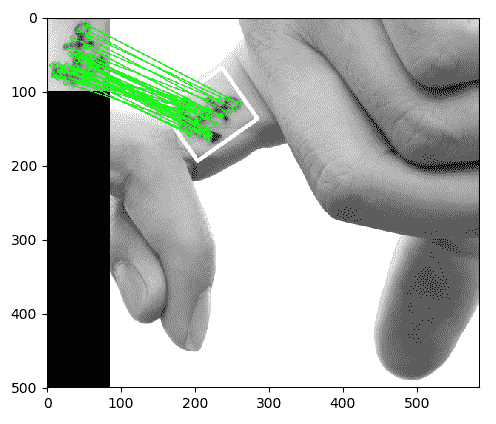
如前面的屏幕快照所示,我们在第一幅图像中拍摄了对象,在第二幅图像中正确地识别了该对象,在关键点之间绘制了匹配线,甚至绘制了一个白色边框,显示了第二幅图像中对象相对于第一张图片的视角的变形。
您可能已经正确地猜到了脚本的实现是通过导入库,读取灰度格式的图像,检测特征以及计算 SIFT 描述符开始的。 我们在前面的示例中做了所有这些操作,因此在此将其省略。 让我们看一下接下来的操作:
- 我们通过组装通过 Lowe 比率测试的匹配项列表来进行操作,如以下代码所示:
# Find all the good matches as per Lowe's ratio test.
good_matches = []
for m, n in matches:
if m.distance < 0.7 * n.distance:
good_matches.append(m)
- 从技术上讲,我们可以通过最少四个匹配来计算单应性。 但是,如果这四个匹配项中的任何一个有缺陷,都会降低结果的准确率。 更实用的最小值是
10。 给定额外的匹配项,单应性查找算法可以丢弃一些离群值,以产生与匹配项的实质子集非常契合的结果。 因此,我们继续检查我们是否至少有10个良好匹配项:
MIN_NUM_GOOD_MATCHES = 10
if len(good_matches) >= MIN_NUM_GOOD_MATCHES:
- 如果满足此条件,我们将查找匹配的关键点的 2D 坐标,并将这些坐标放置在两个浮点坐标对列表中。 一个列表包含查询图像中的关键点坐标,而另一个列表包含场景中匹配的关键点坐标:
src_pts = np.float32(
[kp0[m.queryIdx].pt for m in good_matches]).reshape(-1, 1, 2)
dst_pts = np.float32(
[kp1[m.trainIdx].pt for m in good_matches]).reshape(-1, 1, 2)
- 现在,我们找到单应性:
M, mask = cv2.findHomography(src_pts, dst_pts, cv2.RANSAC, 5.0)
mask_matches = mask.ravel().tolist()
请注意,我们创建了一个mask_matches列表,该列表将在比赛的最终绘图中使用,以便仅在单应图中的点才会绘制出匹配线。
- 在这一阶段,我们必须执行透视变换,该变换将查询图像的矩形角投影到场景中,以便绘制边框:
h, w = img0.shape
src_corners = np.float32(
[[0, 0], [0, h-1], [w-1, h-1], [w-1, 0]]).reshape(-1, 1, 2)
dst_corners = cv2.perspectiveTransform(src_corners, M)
dst_corners = dst_corners.astype(np.int32)
# Draw the bounds of the matched region based on the homography.
num_corners = len(dst_corners)
for i in range(num_corners):
x0, y0 = dst_corners[i][0]
if i == num_corners - 1:
next_i = 0
else:
next_i = i + 1
x1, y1 = dst_corners[next_i][0]
cv2.line(img1, (x0, y0), (x1, y1), 255, 3, cv2.LINE_AA)
然后,按照前面的示例,我们继续绘制关键点并显示可视化效果。
示例应用–纹身取证
让我们以一个真实的(或者也许是幻想的)例子作为本章的结尾。 假设您正在哥谭法医部门工作,并且需要识别纹身。 您拥有罪犯纹身的原始图片(也许是在闭路电视录像中捕获的),但您不知道该人的身份。 但是,您拥有一个纹身数据库,该数据库以纹身所属的人的名字为索引。
让我们将此任务分为两个部分:
- 通过将图像描述符保存到文件来构建数据库
- 加载数据库并扫描查询图像的描述符和数据库中的描述符之间的匹配项
我们将在接下来的两个小节中介绍这些任务。
将图像描述符保存到文件
我们要做的第一件事是将图像描述符保存到外部文件中。 这样,我们不必每次想要扫描两个图像以进行匹配时都重新创建描述符。
就我们的示例而言,让我们扫描文件夹中的图像并创建相应的描述符文件,以便我们可以随时使用它们以供将来搜索。 为了创建描述符,我们将使用本章已经使用过多次的过程:即加载图像,创建特征检测器,检测特征并计算描述符。 要将描述符保存到文件中,我们将使用方便的 NumPy 数组方法save,该方法以优化的方式将数组数据转储到文件中。
Python 标准库中的pickle模块提供了更多通用的序列化功能,该功能支持任何 Python 对象,而不仅仅是 NumPy 数组。 但是,NumPy 的数组序列化是数字数据的不错选择。
让我们将脚本分解为函数。 主要函数将命名为create_descriptors(复数,描述符),它将遍历给定文件夹中的文件。 对于每个文件,create_descriptors将调用一个名为create_descriptor的帮助器函数(单数,描述符),该函数将为给定的图像文件计算并保存我们的描述符。 让我们开始吧:
- 首先,这是
create_descriptors的实现:
import os
import numpy as np
import cv2
def create_descriptors(folder):
feature_detector = cv2.xfeatures2d.SIFT_create()
files = []
for (dirpath, dirnames, filenames) in os.walk(folder):
files.extend(filenames)
for f in files:
create_descriptor(folder, f, feature_detector)
请注意,create_descriptors创建了特征检测器,因为我们只需要执行一次,而不是每次加载文件时都执行一次。 辅助函数create_descriptor接收特征检测器作为参数。
- 现在,让我们看一下后一个函数的实现:
def create_descriptor(folder, image_path, feature_detector):
if not image_path.endswith('png'):
print('skipping %s' % image_path)
return
print('reading %s' % image_path)
img = cv2.imread(os.path.join(folder, image_path),
cv2.IMREAD_GRAYSCALE)
keypoints, descriptors = feature_detector.detectAndCompute(
img, None)
descriptor_file = image_path.replace('png', 'npy')
np.save(os.path.join(folder, descriptor_file), descriptors)
请注意,我们将描述符文件与图像保存在同一文件夹中。 此外,我们假设图像文件具有png扩展名。 为了使脚本更加鲁棒,可以对其进行修改,使其支持其他图像文件扩展名,例如jpg。 如果文件具有意外扩展名,我们将其跳过,因为它可能是描述符文件(来自脚本的先前运行)或其他一些非映像文件。
- 我们已经完成了函数。 为了完成脚本,我们将使用文件夹名称作为参数来调用
create_descriptors:
folder = 'tattoos'
create_descriptors(folder)
当我们运行此脚本时,它将以 NumPy 的数组文件格式生成必要的描述符文件,文件扩展名为npy。 这些文件构成我们的纹身描述符数据库,按名称索引。 (每个文件名都是一个人的名字。)接下来,我们将编写一个单独的脚本,以便可以对该数据库运行查询。
扫描描述符
现在,我们已将描述符保存到文件中,我们只需要对每组描述符进行匹配,以确定哪一组与我们的查询图像最匹配。
这是我们将执行的过程:
- 加载查询图像(
query.png)。 - 扫描包含描述符文件的文件夹。 打印描述符文件的名称。
- 为查询图像创建 SIFT 描述符。
- 对于每个描述符文件,加载 SIFT 描述符并查找基于 FLANN 的匹配项。 根据比率测试过滤匹配项。 打印此人的姓名和匹配数。 如果匹配数超过任意阈值,请打印此人是可疑人员。 (请记住,我们正在调查犯罪。)
- 打印主要嫌疑人的名字(匹配次数最多的人)。
让我们考虑一下实现:
- 首先,以下代码块加载查询图像:
import os
import numpy as np
import cv2
# Read the query image.
folder = 'tattoos'
query = cv2.imread(os.path.join(folder, 'query.png'),
cv2.IMREAD_GRAYSCALE)
- 我们继续组装并打印描述符文件列表:
# create files, images, descriptors globals
files = []
images = []
descriptors = []
for (dirpath, dirnames, filenames) in os.walk(folder):
files.extend(filenames)
for f in files:
if f.endswith('npy') and f != 'query.npy':
descriptors.append(f)
print(descriptors)
- 我们设置了典型的
cv2.SIFT和cv2.FlannBasedMatcher对象,并生成了查询图像的描述符:
# Create the SIFT detector.
sift = cv2.xfeatures2d.SIFT_create()
# Perform SIFT feature detection and description on the
# query image.
query_kp, query_ds = sift.detectAndCompute(query, None)
# Define FLANN-based matching parameters.
FLANN_INDEX_KDTREE = 1
index_params = dict(algorithm=FLANN_INDEX_KDTREE, trees=5)
search_params = dict(checks=50)
# Create the FLANN matcher.
flann = cv2.FlannBasedMatcher(index_params, search_params)
- 现在,我们搜索嫌疑犯,我们将其定义为查询纹身至少具有 10 个良好匹配项的人。 我们的搜索需要遍历描述符文件,加载描述符,执行基于 FLANN 的匹配以及根据比率测试过滤匹配。 我们为每个人(每个描述符文件)打印结果:
# Define the minimum number of good matches for a suspect.
MIN_NUM_GOOD_MATCHES = 10
greatest_num_good_matches = 0
prime_suspect = None
print('>> Initiating picture scan...')
for d in descriptors:
print('--------- analyzing %s for matches ------------' % d)
matches = flann.knnMatch(
query_ds, np.load(os.path.join(folder, d)), k=2)
good_matches = []
for m, n in matches:
if m.distance < 0.7 * n.distance:
good_matches.append(m)
num_good_matches = len(good_matches)
name = d.replace('.npy', '').upper()
if num_good_matches >= MIN_NUM_GOOD_MATCHES:
print('%s is a suspect! (%d matches)' % \
(name, num_good_matches))
if num_good_matches > greatest_num_good_matches:
greatest_num_good_matches = num_good_matches
prime_suspect = name
else:
print('%s is NOT a suspect. (%d matches)' % \
(name, num_good_matches))
请注意np.load方法的使用,该方法会将指定的NPY文件加载到 NumPy 数组中。
- 最后,我们打印主要嫌疑人的姓名(如果找到嫌疑人,则为):
if prime_suspect is not None:
print('Prime suspect is %s.' % prime_suspect)
else:
print('There is no suspect.')
运行前面的脚本将产生以下输出:
>> Initiating picture scan...
--------- analyzing anchor-woman.npy for matches ------------
ANCHOR-WOMAN is NOT a suspect. (2 matches)
--------- analyzing anchor-man.npy for matches ------------
ANCHOR-MAN is a suspect! (44 matches)
--------- analyzing lady-featherly.npy for matches ------------
LADY-FEATHERLY is NOT a suspect. (2 matches)
--------- analyzing steel-arm.npy for matches ------------
STEEL-ARM is NOT a suspect. (0 matches)
--------- analyzing circus-woman.npy for matches ------------
CIRCUS-WOMAN is NOT a suspect. (1 matches)
Prime suspect is ANCHOR-MAN.
如果需要,我们可以像上一节中那样以图形方式表示比赛和单应性。
总结
在本章中,我们学习了有关检测关键点,计算关键点描述符,匹配这些描述符,滤除不匹配项以及查找两组匹配的关键点之间的单应性的方法。 我们探索了 OpenCV 中可以用于完成这些任务的多种算法,并将这些算法应用于各种图像和用例。
如果我们将关键点的新知识与有关相机和透视图的其他知识相结合,则可以跟踪 3D 空间中的对象。 这将是第 9 章,“相机模型和增强现实”的主题。 如果您特别想达到第三个维度,则可以跳到该章。
相反,如果您认为下一步的逻辑步骤是完善对对象检测,识别和跟踪的二维解决方案的了解,则可以按顺序继续进行第 7 章,“构建自定义对象检测器”,然后是第 8 章,“跟踪对象”。 最好了解 2D 和 3D 的组合技术,以便为给定的应用选择一种提供正确的输出种类和正确的计算速度的方法。
七、建立自定义对象检测器
本章将深入研究对象检测的概念,这是计算机视觉中最常见的挑战之一。 在本书中走到这一步,您也许想知道什么时候可以在街头实践计算机视觉。 您是否梦想建立一个检测汽车和人员的系统? 好吧,实际上,您离目标不算太远。
在前面的章节中,我们已经研究了对象检测和识别的一些特定情况。 在第 5 章,“检测和识别人脸”中,我们专注于直立的正面人脸;在第 6 章,“检索图像并使用图像描述符进行搜索”中,我们研究了具有角点或斑点状特征的物体。 现在,在本章中,我们将探索具有良好泛化或外推能力的算法,从某种意义上说,它们可以应对给定对象类别中存在的现实世界的多样性。 例如,不同的汽车具有不同的设计,并且人们可能会根据所穿的衣服而呈现出不同的形状。
具体来说,我们将追求以下目标:
- 了解另一种特征描述符:定向梯度描述符直方图(HOG)。
- 了解非最大抑制,也称为非最大抑制(NMS),这有助于我们从重叠的检测窗口集中选择最佳。
- 对支持向量机(SVM)有较高的了解。 这些通用分类器基于有监督的机器学习,类似于线性回归。
- 使用基于 HOG 描述符的预训练分类器检测人员。
- 训练词袋(BoW)分类器以检测汽车。 对于此示例,我们将使用图像金字塔,滑动窗口和 NMS 的自定义实现,以便我们可以更好地了解这些技术的内部工作原理。
本章中的大多数技术都不是互斥的。 相反,它们作为检测器的组件一起工作。 在本章结束时,您将知道如何训练和使用在大街上有实际应用的分类器!
技术要求
本章使用 Python,OpenCV 和 NumPy。 请参考第 1 章,“设置 OpenCV”,以获得安装说明。
可在本书的 GitHub 存储库中找到本章的完整代码, 在chapter07文件夹中。 样本图像可以在images文件夹的存储库中找到。
了解 HOG 描述符
HOG 是一种特征描述符,因此它与尺度不变特征变换(SIFT),加速鲁棒特征(SURF)和定向 FAST 和旋转 BRIEF(ORB),我们在第 6 章“检索图像和使用图像描述符进行搜索”中介绍了此方法。 像其他特征描述符一样,HOG 能够传递对于特征匹配以及对象检测和识别至关重要的信息类型。 最常见的是,HOG 用于对象检测。 Navneet Dalal 和 Bill Triggs 在他们的论文《面向人类检测的梯度梯度直方图》(INRIA,2005)上普及了该算法,尤其是将其用作人体检测器。
HOG 的内部机制确实很聪明; 将图像分为多个单元,并为每个单元计算一组梯度。 每个梯度描述了给定方向上像素强度的变化。 这些梯度一起形成了单元格的直方图表示。 当我们在第 5 章,“检测和识别人脸”中使用局部二进制模式直方图(LBPH)研究人脸识别时,遇到了类似的方法。
在深入探讨 HOG 的工作原理的技术细节之前,让我们先看一下 HOG 如何看待世界。
可视化 HOG
Carl Vondrick,Aditya Khosla,Hamed Pirsiavash,Tomasz Malisiewicz 和 Antonio Torralba 开发了一种称为 HOGgles(HOG 护目镜)的 HOG 可视化技术。 有关 HOGgles 的摘要以及代码和出版物的链接,请参见 Carl Vondrick 的 MIT 网页。 作为他们的测试图像之一,Vondrick 等。 使用以下卡车图片:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-De09rAly-1681871605263)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/learn-opencv4-cv-py3/img/60775b41-94f8-43dc-8580-9a9c8b23131f.png)]
Vondrick 等。 基于 Dalal 和 Triggs 早期论文的方法,产生了 HOG 描述符的以下可视化:

然后,应用 HOGgles,Vondrick 等。 反转特征描述算法,以按照 HOG 的角度重建卡车的图像,如下所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NqdwchDL-1681871605263)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/learn-opencv4-cv-py3/img/acdf5184-82af-4777-83cd-e2733c306775.png)]
在这两种可视化中,您都可以看到 HOG 已将图像分为多个单元格,并且可以轻松识别出车轮和车辆的主要结构。 在第一个可视化中,每个单元格计算出的梯度显示为一组纵横交错的线,有时看起来像是细长的星星; 恒星的长轴代表更强的梯度。 在第二个可视化中,将梯度显示为沿单元格中各个轴的亮度平滑过渡。
现在,让我们进一步考虑 HOG 的工作方式,以及它对物体检测解决方案的贡献。
使用 HOG 描述图像区域
对于每个 HOG 单元,直方图包含的箱子数量等于梯度的数量,换句话说,就是 HOG 考虑的轴方向的数量。 在计算了所有单元的直方图之后,HOG 处理直方图组以生成更高级别的描述符。 具体而言,将单元分为更大的区域,称为块。 这些块可以由任意数量的单元组成,但是 Dalal 和 Triggs 发现2x2单元块在进行人员检测时产生了最佳结果。 创建一个块范围的向量,以便可以对其进行归一化,以补偿照明和阴影的局部变化。 (单个单元的区域太小而无法检测到这种变化。)这种归一化提高了基于 HOG 的检测器相对于光照条件变化的鲁棒性。
像其他探测器一样,基于 HOG 的探测器也需要应对物体位置和比例的变化。 通过在图像上移动固定大小的滑动窗口,可以满足在各种位置进行搜索的需求。 通过将图像缩放到各种大小,从而形成所谓的图像金字塔,可以解决在各种尺度下进行搜索的需求。 我们先前在第 5 章,“检测和识别人脸”中,特别是在“概念化 Haar 级联”部分中研究了这些技术。 但是,让我们详细说明一个困难:如何处理重叠窗口中的多个检测。
假设我们正在使用滑动窗口对图像执行人物检测。 我们以很小的步幅滑动窗口,一次仅滑动几个像素,因此我们希望它可以多次框住任何给定的人。 假设重叠的检测确实是一个人,我们不想报告多个位置,而只是报告一个我们认为正确的位置。 换句话说,即使在给定位置的检测具有良好的置信度得分,如果重叠检测具有更好的的置信度得分,我们可能会拒绝它; 因此,从一组重叠的检测中,我们将选择最佳置信度得分的检测。
这就是 NMS 发挥作用的地方。 给定一组重叠区域,我们可以抑制(或拒绝)分类器未针对其产生最大得分的所有区域。
了解 NMS
NMS 的概念听起来很简单。 从一组重叠的解决方案中,只需选择最佳方案即可! 但是,实现比您最初想象的要复杂。 还记得图像金字塔吗? 重叠检测可以不同的比例发生。 我们必须收集所有的正面检测结果,并在检查重叠之前将其范围重新转换为通用比例。 NMS 的典型实现采用以下方法:
- 构造图像金字塔。
- 使用滑动窗口方法扫描金字塔的每个级别,以进行物体检测。 对于每个产生正面检测的窗口(超过某个任意置信度阈值),请将窗口转换回原始图像的比例。 将窗口及其置信度得分添加到正面检测列表中。
- 按降序的置信度得分对正面检测列表进行排序,以便最佳检测在列表中排在第一位。
- 对于每个窗口,在正面检测列表中,
W,删除所有与W明显重叠的所有后续窗口。 我们只剩下满足 NMS 标准的正面检测列表。
除 NMS 之外,过滤正面检测结果的另一种方法是消除任何子窗口。 当我们说子窗口(或子区域)时,是指完全包含在另一个窗口(或区域)内的窗口(或图像中的区域)。 要检查子窗口,我们只需要比较各种窗口矩形的角坐标。 我们将在第一个实际示例中采用这种简单方法,即“使用 HOG 描述符的人脸检测”部分。 可以选择将 NMS 和子窗口抑制合并在一起。
其中几个步骤是迭代的,因此我们面临着一个有趣的优化问题。 Tomasz Malisiewicz 在这个页面提供了 MATLAB 中的快速示例实现。 Adrian Rosebrock 在这个页面提供了此示例实现的一部分到 Python。 我们将在本章稍后的“在场景中检测汽车”部分的基础上,基于后一个示例。
现在,我们如何确定窗口的置信度得分? 我们需要一个分类系统来确定是否存在某个特征,以及该分类的置信度得分。 这就是 SVM 发挥作用的地方。
了解 SVM
在不讨论 SVM 如何工作的细节的情况下,让我们尝试了解它在机器学习和计算机视觉的背景下可以帮助我们完成哪些工作。 给定带标签的训练数据,SVM 会通过找到最佳超平面来学习对相同类型的数据进行分类,用最简单的英语来说,该超平面是用最大可能的余量划分不同标签数据的平面。 为了帮助我们理解,让我们考虑下图,该图由 Zach Weinberg 在“知识共享署名-相同方式共享 3.0 无端口许可”下提供:
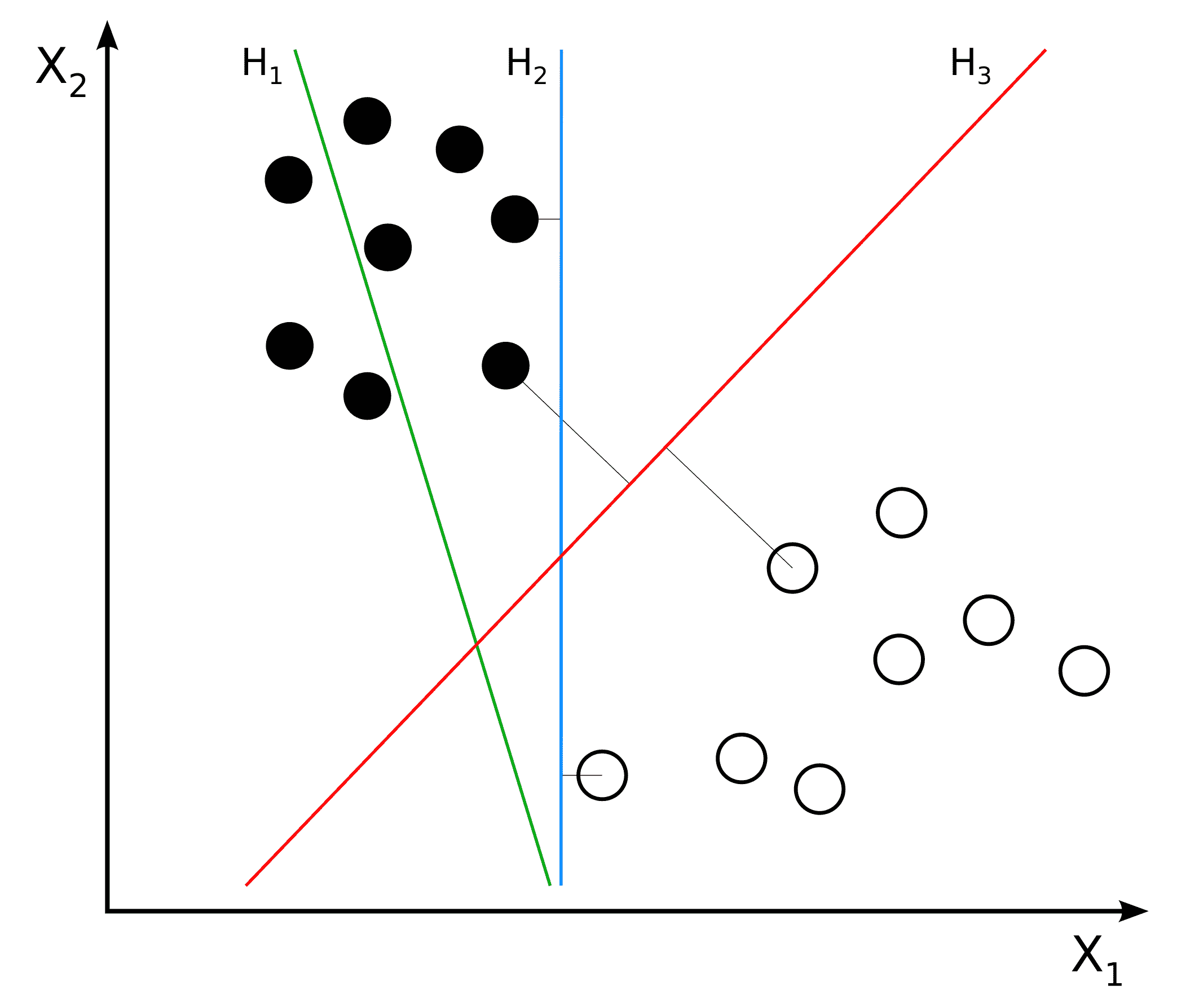
超平面H1(显示为绿线)不划分两类(黑点与白点)。 超平面H2(显示为蓝线)和H3(显示为红线)都划分了类别。 但是,只有超平面H3将类别划分为最大余量。
假设我们正在训练 SVM 作为人员检测器。 我们有两类,人和非人。 作为训练样本,我们提供了包含或不包含人的各种窗口的 HOG 描述符的向量。 这些窗口可能来自各种图像。 SVM 通过找到最佳的超平面来学习,该平面将多维 HOG 描述符空间最大程度地分为人(在超平面的一侧)和非人(在另一侧)。 此后,当我们为训练后的 SVM 提供任何图像中任何其他窗口的 HOG 描述符向量时,SVM 可以判断该窗口是否包含人。 SVM 甚至可以给我们一个与向量到最佳超平面的距离有关的置信度值。
SVM 模型自 1960 年代初就出现了。 但是,此后它就得到了改进,现代 SVM 实现的基础可以在 Corinna Cortes 和 Vladimir Vapnik 的论文《支持向量网络》(《机器学习》,1995 年)中找到 。 可从这个页面获得。
现在,我们对可以组合以构成对象检测器的关键组件有了概念上的理解,我们可以开始看一些示例。 我们将从 OpenCV 的现成对象检测器之一开始,然后我们将继续设计和训练我们自己的自定义对象检测器。
使用 HOG 描述符检测人
OpenCV 带有称为cv2.HOGDescriptor的类,该类能够执行人员检测。 该接口与我们在第 5 章,“检测和识别人脸”中使用的cv2.CascadeClassifier类相似。 但是,与cv2.CascadeClassifier不同,cv2.HOGDescriptor有时会返回嵌套的检测矩形。 换句话说,cv2.HOGDescriptor可能告诉我们它检测到一个人的边界矩形完全位于另一个人的边界矩形内部。 这种情况确实是可能的。 例如,一个孩子可能站在成人的前面,而孩子的边界矩形可能完全在成人的边界矩形内。 但是,在典型情况下,嵌套检测可能是错误,因此cv2.HOGDescriptor通常与代码一起使用,以过滤掉任何嵌套检测。
让我们通过执行测试来确定一个矩形是否嵌套在另一个矩形中来开始示例脚本。 为此,我们将连接一个函数is_inside(i, o),其中i是可能的内部矩形,o是可能的外部矩形。 如果i在o内部,则函数将返回True; 否则,将返回False。 这是脚本的开始:
import cv2
def is_inside(i, o):
ix, iy, iw, ih = i
ox, oy, ow, oh = o
return ix > ox and ix + iw < ox + ow and \
iy > oy and iy + ih < oy + oh
现在,我们创建cv2.HOGDescriptor的实例,并指定它使用 OpenCV 内置的默认人员检测器,方法是运行以下代码:
hog = cv2.HOGDescriptor()
hog.setSVMDetector(cv2.HOGDescriptor_getDefaultPeopleDetector())
请注意,我们使用setSVMDetector方法指定了人员检测器。 希望根据本章前面的内容,这是有道理的。 SVM 是分类器,因此 SVM 的选择决定了我们的cv2.HOGDescriptor将检测到的对象类型。
现在,我们继续加载图像(在这种情况下,是一张在干草地上工作的妇女的老照片),并尝试通过运行以下代码来检测图像中的人:
img = cv2.imread('https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/learn-opencv4-cv-py3/img/haying.jpg')
found_rects, found_weights = hog.detectMultiScale(
img, winStride=(4, 4), scale=1.02, finalThreshold=1.9)
请注意,cv2.HOGDescriptor具有detectMultiScale方法,该方法返回两个列表:
- 检测到的对象(在这种情况下,检测到的人)的包围矩形的列表。
- 检测到的物体的权重或置信度得分列表。 值越高,表示检测结果正确的可信度越高。
detectMultiScale接受几个可选参数,包括:
winStride:此元组定义了滑动窗口在连续检测尝试之间移动的x和y距离。 HOG 在重叠的窗口中效果很好,因此相对于窗口大小,步幅可能较小。 较小的值将以较高的计算成本产生更多的检测结果。 默认的步幅没有重叠。 它与窗口大小相同,对于默认人物检测器为(64, 128)。scale:此比例因子应用于图像金字塔的连续级别之间。 较小的值将以较高的计算成本产生更多的检测结果。 该值必须大于1.0。 默认值为1.5。finalThreshold:此值确定我们的检测标准有多严格。 较小的值不太严格,导致更多的检测。 默认值为2.0。
现在,我们可以过滤检测结果以删除嵌套的矩形。 为了确定矩形是否为嵌套矩形,我们可能需要将其与其他所有矩形进行比较。 请注意在以下嵌套循环中使用我们的is_inside函数:
found_rects_filtered = []
found_weights_filtered = []
for ri, r in enumerate(found_rects):
for qi, q in enumerate(found_rects):
if ri != qi and is_inside(r, q):
break
else:
found_rects_filtered.append(r)
found_weights_filtered.append(found_weights[ri])
最后,让我们绘制其余的矩形和权重以突出显示检测到的人,然后如下所示并显示此可视化效果:
for ri, r in enumerate(found_rects_filtered):
x, y, w, h = r
cv2.rectangle(img, (x, y), (x + w, y + h), (0, 255, 255), 2)
text = '%.2f' % found_weights_filtered[ri]
cv2.putText(img, text, (x, y - 20),
cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 255), 2)
cv2.imshow('Women in Hayfield Detected', img)
cv2.imwrite('./women_in_hayfield_detected.jpg', img)
cv2.waitKey(0)
如果您自己运行脚本,则图像中的人周围会看到矩形。 结果如下:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-883w3iWY-1681871605264)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/learn-opencv4-cv-py3/img/fbf9ccc9-f411-44ef-b0d7-0ab759c64250.png)]
这张照片是彩色摄影的先驱 Sergey Prokudin-Gorsky(1863-1944)作品的另一个例子。 在这里,场景是 1909 年俄罗斯西北部 Leushinskii 修道院的一块田地。
在距离相机最近的六位女性中,有五位被成功检测到。 同时,背景中的一个塔被错误地检测为人。 在许多实际应用中,可以通过分析视频中的一系列帧来改善人员检测结果。 例如,假设我们正在观看 Leushinskii 修道院干草地的监视视频,而不是一张照片。 我们应该能够添加代码来确定该塔不能为人,因为它不会移动。 同样,我们应该能够在其他框架中检测到其他人,并跟踪每个人在框架之间的移动。 我们将在第 8 章,“跟踪对象”中研究人员跟踪问题。
同时,让我们继续研究另一种检测器,我们可以训练该检测器来检测给定类别的对象。
创建和训练对象检测器
使用训练有素的检测器使构建快速原型变得容易,我们都非常感谢 OpenCV 开发人员提供了诸如人脸检测和人物检测之类的有用功能。 但是,无论您是业余爱好者还是计算机视觉专业人员,都不太可能只与人和面孔打交道。
此外,如果您像本书的作者一样,您会想知道“人检测器”是如何首先创建的,以及是否可以改进它。 此外,您可能还想知道是否可以将相同的概念应用于检测从汽车到地精的各种物体。
的确,在行业中,您可能不得不处理检测非常具体的对象的问题,例如车牌,书皮或任何对您的雇主或客户最重要的东西。
因此,问题是,我们如何提出自己的分类器?
有许多流行的方法。 在本章的其余部分中,我们将看到一个答案在于 SVM 和 BoW 技术。
我们已经讨论过 SVM 和 HOG。 现在让我们仔细看看 BoW。
了解 BoW
BoW 是最初不用于计算机视觉的概念; 相反,我们在计算机视觉的背景下使用了该概念的演进版本。 让我们首先讨论一下它的基本版本,正如您可能已经猜到的那样,它最初属于语言分析和信息检索领域。
在计算机视觉的背景下,有时 BoW 被称为视觉词袋(BoVW)。 但是,我们将仅使用术语 BoW,因为这是 OpenCV 使用的术语。
BoW 是一种技术,通过它我们可以为一系列文档中的每个单词分配权重或计数; 然后,我们用这些计数的向量表示这些文档。 让我们来看一个示例,如下所示:
- 文档 1:我喜欢 OpenCV,也喜欢 Python。
- 文档 2:我喜欢 C++ 和 Python。
- 文档 3:我不喜欢洋蓟。
这三个文档使我们能够使用以下值构建字典-也称为码本或词汇表-如下所示:
{
I: 4,
like: 4,
OpenCV: 1,
and: 2,
Python: 2,
C++: 1,
don't: 1,
artichokes: 1
}
我们有八个条目。 现在让我们使用八项向量表示原始文档。 每个向量都包含代表给定文档的字典中所有单词计数的值。 前三个句子的向量表示如下:
[2, 2, 1, 1, 1, 0, 0, 0]
[1, 1, 0, 1, 1, 1, 0, 0]
[1, 1, 0, 0, 0, 0, 1, 1]
这些向量可以概念化为文档的直方图表示形式,也可以概念化为可用于训练分类器的描述符向量。 例如,基于这样的表示,文档可以分类为垃圾邮件或非垃圾邮件。 实际上,垃圾邮件过滤是 BoW 的许多实际应用之一。
既然我们已经掌握了 BoW 的基本概念,那么让我们看一下它如何应用于计算机视觉世界。
将 BoW 应用于计算机视觉
现在,我们已经熟悉了特征和描述符的概念。 我们使用了诸如 SIFT 和 SURF 之类的算法从图像特征中提取描述符,以便我们可以在另一幅图像中匹配这些特征。
最近,我们还熟悉了另一种基于密码本或字典的描述符。 我们知道一个 SVM,该模型可以接受标记的描述符向量作为训练数据,可以找到描述符空间按给定类别的最佳划分,并可以预测新数据的类别。
有了这些知识,我们可以采用以下方法来构建分类器:
- 取得图像的样本数据集。
- 对于数据集中的每个图像,提取描述符(使用 SIFT,SURF,ORB 或类似算法)。
- 将每个描述符向量添加到 BoW 训练器中。
- 将描述符聚类为
k聚类,其中心(质心)是我们的视觉单词。 最后一点听起来可能有些晦涩,但是我们将在下一部分中进一步探讨。
在此过程的最后,我们准备了一个视觉单词词典可供使用。 可以想象,庞大的数据集将使我们的词典中的视觉单词更加丰富。 到现在为止,单词越多越好!
训练完分类器后,我们应该继续对其进行测试。 好消息是测试过程在概念上与前面概述的训练过程非常相似。 给定一个测试图像,我们可以通过计算描述符到质心的距离的直方图来提取描述符并量化它们(或降低其维数)。 基于此,我们可以尝试识别视觉单词,并将其定位在图像中。
这就是本章的要点,在这里,您已经对更深入的实践示例产生了浓厚的兴趣,并且非常喜欢编码。 但是,在继续之前,让我们快速但必要地探讨k-均值聚类的理论,以便您可以完全理解视觉单词的创建方式。 从而,您将更好地了解使用 BoW 和 SVM 进行对象检测的过程。
K 均值聚类
k-均值聚类是一种量化方法,通过此方法,我们分析了大量向量,以找到少量聚类。 给定一个数据集,k代表该数据集将被划分为的群集数。 术语均值是指平均值或平均值的数学概念; 当以视觉方式表示时,群集的均值是其质心或群集中点的几何中心。
聚类是指将数据集中的点分组为聚类的过程。
OpenCV 提供了一个名为cv2.BOWKMeansTrainer的类,我们将使用它来帮助训练我们的分类器。 如您所料,OpenCV 文档提供了此类的以下摘要:
“基于 kmeans 的类,使用词袋方法来训练视觉词汇。”
在进行了长期的理论介绍之后,我们可以看一个示例,然后开始训练我们的自定义分类器。
检测汽车
要训练任何种类的分类器,我们必须首先创建或获取训练数据集。 我们将训练汽车探测器,因此我们的数据集必须包含代表汽车的正样本,以及代表检测器在寻找汽车时可能遇到的其他(非汽车)事物的负样本。 例如,如果检测器旨在搜索街道上的汽车,则路边,人行横道,行人或自行车的图片可能比土星环的图片更具代表性。 除了表示预期的主题外,理想情况下,训练样本还应表示我们的特定相机和算法看到主题的方式。
最终,在本章中,我们打算使用固定大小的滑动窗口,因此,重要的是,我们的训练样本必须符合固定大小,并且要对正样本进行严格裁剪以构架没有太多背景的汽车。
在一定程度上,我们希望随着我们不断添加良好的训练图像,分类器的准确率将会提高。 另一方面,较大的数据集会使训练变慢,并且可能过度训练分类器,从而无法推断超出训练集的分类器。 在本节的后面,我们将以一种允许我们轻松修改训练图像的数量的方式编写代码,以便通过实验找到合适的尺寸。
如果我们自己完成所有的工作,那么组装汽车图像数据集将是一项耗时的工作(尽管这完全是可行的)。 为了避免重新发明轮子或整个汽车,我们可以利用现成的数据集,例如:
- 用于车辆检测的 UIUC 图像数据库
- 斯坦福汽车数据集
让我们在示例中使用 UIUC 数据集。 获取此数据集并在脚本中使用它涉及几个步骤,因此让我们一一遍解它们,如下所示:
- 从这个页面下载 UIUC 数据集。 将其解压缩到某个文件夹,我们将其称为
<project_path>。 现在,解压缩的数据应该位于<project_path>/CarData处。 具体来说,我们将使用<project_path>/CarData/TrainImages和<project_path>/CarData/TestImages中的某些图像。 - 同样在
<project_path>中,我们创建一个名为detect_car_bow_svm.py的 Python 脚本。 要开始执行脚本,请编写以下代码以检查CarData子文件夹是否存在:
import cv2
import numpy as np
import os
if not os.path.isdir('CarData'):
print(
'CarData folder not found. Please download and unzip '
'http://l2r.cs.uiuc.edu/~cogcomp/Data/Car/CarData.tar.gz '
'into the same folder as this script.')
exit(1)
如果您可以运行此脚本并且不打印任何内容,则表示所有内容均位于正确的位置。
- 接下来,让我们在脚本中定义以下常量:
BOW_NUM_TRAINING_SAMPLES_PER_CLASS = 10
SVM_NUM_TRAINING_SAMPLES_PER_CLASS = 100
请注意,我们的分类器将使用两个训练阶段:一个阶段用于 BoW 词汇表,它将使用多个图像作为样本,而另一个阶段则用于 SVM,它将使用多个 BoW 描述符向量作为样本。 我们随意地为每个阶段定义了不同数量的训练样本。 在每个阶段,我们还可以为两个类别(汽车和非汽车)定义不同数量的训练样本,但是,我们将使用相同的数量。
- 我们将使用
cv2.SIFT提取描述符,并使用cv2.FlannBasedMatcher匹配这些描述符。 让我们用以下代码初始化这些算法:
sift = cv2.xfeatures2d.SIFT_create()
FLANN_INDEX_KDTREE = 1
index_params = dict(algorithm=FLANN_INDEX_KDTREE, trees=5)
search_params = {}
flann = cv2.FlannBasedMatcher(index_params, search_params)
请注意,我们已经按照与第 6 章“图像检索和使用图像描述符的搜索”相同的方式,初始化了 SIFT 和用于近似最近邻的 FAST 库(FLANN)。但是,这一次,描述符匹配不是我们的最终目标。 相反,它将成为 BoW 特征的一部分。
- OpenCV 提供了一个名为
cv2.BOWKMeansTrainer的类来训练 BoW 词汇表,以及一个名为cv2.BOWImgDescriptorExtractor的类来将某种较低级的描述符(在我们的示例中为 SIFT 描述符)转换为 BoW 描述符。 让我们用以下代码初始化这些对象:
bow_kmeans_trainer = cv2.BOWKMeansTrainer(40)
bow_extractor = cv2.BOWImgDescriptorExtractor(sift, flann)
初始化cv2.BOWKMeansTrainer时,必须指定群集数-在我们的示例中为 40。在初始化cv2.BOWImgDescriptorExtractor时,必须指定描述符提取器和描述符匹配器-在我们的示例中为我们之前创建的cv2.SIFT和cv2.FlannBasedMatcher对象。
- 为了训练 BoW 词汇,我们将提供各种汽车和非汽车图像的 SIFT 描述符样本。 我们将从
CarData/TrainImages子文件夹中加载图像,该图像包含名称为pos-x.pgm的正(汽车)图像和名称为诸如pos-x.pgm的负(非汽车)图像。neg-x.pgm,其中x是从1开始的数字。 让我们编写以下实用函数,以返回到第i个正负训练图像的路径,其中i是一个以0开头的数字:
def get_pos_and_neg_paths(i):
pos_path = 'CarData/Trainhttps://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/learn-opencv4-cv-py3/img/pos-%d.pgm' % (i+1)
neg_path = 'CarData/Trainhttps://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/learn-opencv4-cv-py3/img/neg-%d.pgm' % (i+1)
return pos_path, neg_path
在本节的稍后部分,当我们需要获取大量训练样本时,我们将使用i的变化值循环调用前面的函数。
- 对于训练样本的每条路径,我们将需要加载图像,提取 SIFT 描述符,并将描述符添加到 BoW 词汇表训练器中。 让我们编写另一个工具函数来精确地做到这一点,如下所示:
def add_sample(path):
img = cv2.imread(path, cv2.IMREAD_GRAYSCALE)
keypoints, descriptors = sift.detectAndCompute(img, None)
if descriptors is not None:
bow_kmeans_trainer.add(descriptors)
如果在图像中未找到特征,则keypoints和descriptors变量将为None。
- 在此阶段,我们拥有开始训练 BoW 词汇表所需的一切。 让我们为每个类读取一些图像(汽车作为肯定类,非汽车作为否定类),并将它们添加到训练集中,如下所示:
for i in range(BOW_NUM_TRAINING_SAMPLES_PER_CLASS):
pos_path, neg_path = get_pos_and_neg_paths(i)
add_sample(pos_path)
add_sample(neg_path)
- 现在我们已经组装了训练集,我们将调用词汇训练器的
cluster方法,该方法执行k-均值分类并返回词汇表。 我们将把这个词汇分配给 BoW 描述符提取器,如下所示:
voc = bow_kmeans_trainer.cluster()
bow_extractor.setVocabulary(voc)
请记住,之前我们用 SIFT 描述符提取器和 FLANN 匹配器初始化了 BoW 描述符提取器。 现在,我们还为 BoW 描述符提取器提供了一个词汇,并使用 SIFT 描述符样本进行了训练。 在这个阶段,我们的 BoW 描述符提取器具有从高斯(DoG)特征中提取 BoW 描述符所需的一切。
请记住,cv2.SIFT检测 DoG 特征并提取 SIFT 描述符,正如我们在第 6 章,“检索图像并使用图像描述符”讨论的那样,特别是在“检测 DoG 特征和提取 SIFT 描述符”部分。
- 接下来,我们将声明另一个效用函数,该函数获取图像并返回 BoW 描述符提取器计算出的描述符向量。 这涉及提取图像的 DoG 特征,并根据 DoG 特征计算 BoW 描述符向量,如下所示:
def extract_bow_descriptors(img):
features = sift.detect(img)
return bow_extractor.compute(img, features)
- 我们准备组装另一种训练集,其中包含 BoW 描述符的样本。 让我们创建两个数组来容纳训练数据和标签,并用 BoW 描述符提取器生成的描述符填充它们。 我们将每个描述符向量标记为 1(正样本)和 -1(负样本),如以下代码块所示:
training_data = []
training_labels = []
for i in range(SVM_NUM_TRAINING_SAMPLES_PER_CLASS):
pos_path, neg_path = get_pos_and_neg_paths(i)
pos_img = cv2.imread(pos_path, cv2.IMREAD_GRAYSCALE)
pos_descriptors = extract_bow_descriptors(pos_img)
if pos_descriptors is not None:
training_data.extend(pos_descriptors)
training_labels.append(1)
neg_img = cv2.imread(neg_path, cv2.IMREAD_GRAYSCALE)
neg_descriptors = extract_bow_descriptors(neg_img)
if neg_descriptors is not None:
training_data.extend(neg_descriptors)
training_labels.append(-1)
如果您希望训练一个分类器来区分多个肯定类,则可以简单地添加带有其他标签的其他描述符。 例如,我们可以训练一个分类器,该分类器将标签 1 用于汽车,将 2 用于人,将 -1 用于背景。 不需要具有否定类或背景类,但如果没有,则分类器将假定一切都属于肯定类之一。
- OpenCV 提供了一个名为
cv2.ml_SVM的类,表示一个 SVM。 让我们创建一个 SVM,并使用我们先前组装的数据和标签对其进行训练,如下所示:
svm = cv2.ml.SVM_create()
svm.train(np.array(training_data), cv2.ml.ROW_SAMPLE,
np.array(training_labels))
请注意,在将训练数据和标签从列表转换为 NumPy 数组之前,必须将它们传递给cv2.ml_SVM的train方法。
- 最后,我们准备通过对一些不属于训练集的图像进行分类来测试 SVM。 我们将遍历测试图像的路径列表。 对于每个路径,我们将加载图像,提取 BoW 描述符,并获得 SVM 的预测或分类结果,它们将是 1.0(汽车)或 -1.0(非汽车),具体取决于我们之前使用的训练标签。 我们将在图像上绘制文本以显示分类结果,并在窗口中显示图像。 显示所有图像后,我们将等待用户按下任意键,然后脚本将结束。 所有这些都是通过以下代码块实现的:
for test_img_path in ['CarData/Testhttps://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/learn-opencv4-cv-py3/img/test-0.pgm',
'CarData/Testhttps://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/learn-opencv4-cv-py3/img/test-1.pgm',
'https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/learn-opencv4-cv-py3/img/car.jpg',
'https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/learn-opencv4-cv-py3/img/haying.jpg',
'https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/learn-opencv4-cv-py3/img/statue.jpg',
'https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/learn-opencv4-cv-py3/img/woodcutters.jpg']:
img = cv2.imread(test_img_path)
gray_img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
descriptors = extract_bow_descriptors(gray_img)
prediction = svm.predict(descriptors)
if prediction[1][0][0] == 1.0:
text = 'car'
color = (0, 255, 0)
else:
text = 'not car'
color = (0, 0, 255)
cv2.putText(img, text, (10, 30), cv2.FONT_HERSHEY_SIMPLEX, 1,
color, 2, cv2.LINE_AA)
cv2.imshow(test_img_path, img)
cv2.waitKey(0)
保存并运行脚本。 您应该看到六个具有各种分类结果的窗口。 这是真实正面结果之一的屏幕截图:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GufSBKuv-1681871605264)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/learn-opencv4-cv-py3/img/22bf292d-e1bc-4c9b-8202-e4b54d563cba.png)]
下一个屏幕截图显示了真正的负面结果之一:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BgdG4RWA-1681871605264)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/learn-opencv4-cv-py3/img/25d85e70-bd2b-49b6-b798-24a415207279.png)]
在我们的简单测试中的六张图像中,只有以下一张被错误分类:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Cy01WNg3-1681871605264)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/learn-opencv4-cv-py3/img/d163362d-ad5c-48be-b854-7b7053063b2c.png)]
尝试调整训练样本的数量,并尝试在更多图像上测试分类器,以查看可获得的结果。
让我们总结一下到目前为止所做的事情。 我们使用了 SIFT,BoW 和 SVM 的混合来训练分类器,以区分两个类别:汽车和非汽车。 我们已将此分类器应用于整个图像。 下一步的逻辑步骤是应用滑动窗口技术,以便我们可以将分类结果缩小到图像的特定区域。
将 SVM 与滑动窗口结合
通过将我们的 SVM 分类器与滑动窗口技术和图像金字塔相结合,我们可以实现以下改进:
- 检测图像中相同种类的多个对象。
- 确定图像中每个检测到的对象的位置和大小。
我们将采用以下方法:
- 拍摄图像的一个区域,对其进行分类,然后将该窗口向右移动一个预定义的步长。 当我们到达图像的最右端时,将
x坐标重置为 0,向下移动一步,然后重复整个过程。 - 在每个步骤中,请使用经过 BoW 训练的 SVM 执行分类。
- 根据 SVM,跟踪所有检测为正例的窗口。
- 在对整个图像中的每个窗口进行分类之后,将图像按比例缩小,然后重复使用滑动窗口的整个过程。 因此,我们正在使用图像金字塔。 继续重新缩放和分类,直到达到最小大小。
到此过程结束时,我们已经收集了有关图像内容的重要信息。 但是,存在一个问题:我们很可能已经发现了许多重叠的块,每个块都有很高的置信度。 也就是说,图像可以包含被多次检测的一个物体。 如果我们报告了这些检测结果,那么我们的报告将具有很大的误导性,因此我们将使用 NMS 筛选结果。
有关更新,您可能希望参考本章前面的“了解 NMS”部分。
接下来,让我们看一下如何修改和扩展前面的脚本,以实现我们刚刚描述的方法。
在场景中检测汽车
现在,我们已经准备好通过创建汽车检测脚本来应用到目前为止学到的所有概念,该脚本可以扫描图像并在汽车周围绘制矩形。 通过复制先前的脚本detect_car_bow_svm.py,创建一个新的 Python 脚本detect_car_bow_svm_sliding_window.py。 (我们之前在“检测汽车”部分中介绍了detect_car_bow_svm.py的实现。)新脚本的大部分实现将保持不变,因为我们仍然希望以几乎相同的方式训练 BoW 描述符提取器和 SVM 像我们以前一样。 但是,训练完成后,我们将以新的方式处理测试图像。 除了将每个图像整体分类之外,我们将每个图像分解为金字塔层和窗口,我们将每个窗口分类,然后将 NMS 应用于产生正面检测结果的窗口列表。
对于 NMS,我们将依靠 Malisiewicz 和 Rosebrock 的实现,如本章前面的“了解 NMS”部分中所述。 您可以在本书的 GitHub 存储库中找到其实现的略微修改的副本,尤其是在chapter7/non_max_suppression.py的 Python 脚本中。 该脚本提供具有以下签名的函数:
def non_max_suppression_fast(boxes, overlapThresh):
作为其第一个参数,该函数采用一个 NumPy 数组,其中包含矩形坐标和分数。 如果我们有N个矩形,则此数组的形状为Nx5。 对于索引为i的给定矩形,数组中的值具有以下含义:
boxes[i][0]是最左侧的x坐标。boxes[i][1]是最高的y坐标。boxes[i][2]是最右边的x坐标。boxes[i][3]是最底端的y坐标。boxes[i][4]是分数,其中分数越高表示矩形是正确的检测结果的可信度越高。
作为第二个参数,该函数采用一个阈值,该阈值表示矩形之间重叠的最大比例。 如果两个矩形的重叠比例大于此比例,则得分较低的矩形将被滤除。 最终,该函数将返回剩余矩形的数组。
现在,让我们将注意力转向对detect_car_bow_svm_sliding_window.py脚本的修改,如下所示:
- 首先,我们要为 NMS 函数添加一个新的
import语句,如以下代码中的粗体所示:
import cv2
import numpy as np
import os
from non_max_suppression import non_max_suppression_fast as nms
- 让我们在脚本开头附近定义一些其他参数,如粗体所示:
BOW_NUM_TRAINING_SAMPLES_PER_CLASS = 10
SVM_NUM_TRAINING_SAMPLES_PER_CLASS = 100
SVM_SCORE_THRESHOLD = 1.8
NMS_OVERLAP_THRESHOLD = 0.15
我们将使用SVM_SCORE_THRESHOLD作为阈值来区分正窗口和负窗口。 我们将在本节稍后部分看到如何获得分数。 我们将使用NMS_OVERLAP_THRESHOLD作为 NMS 步骤中重叠的最大可接受比例。 在这里,我们任意选择了 15%,因此我们将剔除重叠超过此比例的窗口。 在试验 SVM 时,您可以根据自己的喜好调整这些参数,直到找到在应用中产生最佳结果的值。
- 我们将
k-均值群集的数量从40减少到12(根据实验任意选择的数量),如下所示:
bow_kmeans_trainer = cv2.BOWKMeansTrainer(12)
- 我们还将调整 SVM 的参数,如下所示:
svm = cv2.ml.SVM_create()
svm.setType(cv2.ml.SVM_C_SVC)
svm.setC(50)
svm.train(np.array(training_data), cv2.ml.ROW_SAMPLE,
np.array(training_labels))
通过对 SVM 的先前更改,我们指定了分类器的严格性或严重性级别。 随着C参数的值增加,误报的风险减少,但误报的风险增加。 在我们的应用中,假正例将是当其确实是非汽车时被检测为汽车的窗口,而假负例将是当它的实际汽车时被检测为非汽车的窗口。
在训练 SVM 的代码之后,我们想添加两个辅助函数。 基于滑动窗口技术,其中一个将生成图像金字塔的级别,而另一个将生成关注区域。 除了添加这些辅助函数外,我们还需要以不同的方式处理测试图像,以利用滑动窗口和 NMS。 以下步骤介绍了更改:
- 首先,让我们看一下处理图像金字塔的辅助函数。 以下代码块显示了此函数:
def pyramid(img, scale_factor=1.25, min_size=(200, 80),
max_size=(600, 600)):
h, w = img.shape
min_w, min_h = min_size
max_w, max_h = max_size
while w >= min_w and h >= min_h:
if w <= max_w and h <= max_h:
yield img
w /= scale_factor
h /= scale_factor
img = cv2.resize(img, (int(w), int(h)),
interpolation=cv2.INTER_AREA)
前面的函数获取图像并生成一系列调整大小的版本。 该系列受最大和最小图像尺寸的限制。
您会注意到,调整大小的图像不是通过return关键字返回的,而是通过yield关键字返回的。 这是因为此函数是所谓的生成器。 它产生一系列图像,我们可以轻松地在循环中使用它们。 如果您不熟悉生成器,请查看这个页面上的官方 Python Wiki。
- 接下来是基于滑动窗口技术生成兴趣区域的函数。 以下代码块显示了此函数:
def sliding_window(img, step=20, window_size=(100, 40)):
img_h, img_w = img.shape
window_w, window_h = window_size
for y in range(0, img_w, step):
for x in range(0, img_h, step):
roi = img[y:y+window_h, x:x+window_w]
roi_h, roi_w = roi.shape
if roi_w == window_w and roi_h == window_h:
yield (x, y, roi)
同样,这是一个生成器。 尽管有点嵌套,但是该机制非常简单:给定图像,返回左上角坐标和代表下一个窗口的子图像。 连续的窗口从左到右以任意大小的步长移动,直到我们到达一行的末尾;从顶部到底部,直到我们到达图像的末尾。
- 现在,让我们考虑对测试图像的处理。 与先前版本的脚本一样,我们循环浏览一系列路径以测试图像,以便加载和处理每个图像。 循环的开始保持不变。 对于上下文,这里是:
for test_img_path in ['CarData/Testhttps://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/learn-opencv4-cv-py3/img/test-0.pgm',
'CarData/Testhttps://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/learn-opencv4-cv-py3/img/test-1.pgm',
'https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/learn-opencv4-cv-py3/img/car.jpg',
'https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/learn-opencv4-cv-py3/img/haying.jpg',
'https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/learn-opencv4-cv-py3/img/statue.jpg',
'https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/learn-opencv4-cv-py3/img/woodcutters.jpg']:
img = cv2.imread(test_img_path)
gray_img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
- 对于每个测试图像,我们迭代金字塔级别,对于每个金字塔级别,我们迭代滑动窗口位置。 对于每个窗口或兴趣区域(ROI),我们提取 BoW 描述符并使用 SVM 对它们进行分类。 如果分类产生的正例结果通过了一定的置信度阈值,则将矩形的角坐标和置信度得分添加到正面检测列表中。 从上一个代码块继续,我们继续使用以下代码处理给定的测试图像:
pos_rects = []
for resized in pyramid(gray_img):
for x, y, roi in sliding_window(resized):
descriptors = extract_bow_descriptors(roi)
if descriptors is None:
continue
prediction = svm.predict(descriptors)
if prediction[1][0][0] == 1.0:
raw_prediction = svm.predict(
descriptors,
flags=cv2.ml.STAT_MODEL_RAW_OUTPUT)
score = -raw_prediction[1][0][0]
if score > SVM_SCORE_THRESHOLD:
h, w = roi.shape
scale = gray_img.shape[0] / \
float(resized.shape[0])
pos_rects.append([int(x * scale),
int(y * scale),
int((x+w) * scale),
int((y+h) * scale),
score])
让我们注意一下前面代码中的两个复杂性,如下所示:
到目前为止,我们已经在各种规模和位置进行了汽车检测; 结果,我们有了一个检测到的汽车矩形的列表,包括坐标和分数。 我们期望在此矩形列表内有很多重叠。
- 现在,让我们调用 NMS 函数,以便在重叠的情况下挑选得分最高的矩形,如下所示:
pos_rects = nms(np.array(pos_rects), NMS_OVERLAP_THRESHOLD)
请注意,我们已经将矩形坐标和分数列表转换为 NumPy 数组,这是该函数期望的格式。
在此阶段,我们有一系列检测到的汽车矩形及其得分,并且我们确保了这些是我们可以选择的最佳非重叠检测(在模型的参数范围内)。
- 现在,通过在代码中添加以下内部循环来绘制矩形及其分数:
for x0, y0, x1, y1, score in pos_rects:
cv2.rectangle(img, (int(x0), int(y0)), (int(x1), int(y1)),
(0, 255, 255), 2)
text = '%.2f' % score
cv2.putText(img, text, (int(x0), int(y0) - 20),
cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 255), 2)
与该脚本的先前版本一样,外部循环的主体通过显示当前的测试图像(包括我们在其上绘制的标注)来结束。 循环遍历所有测试图像后,我们等待用户按下任意键; 然后,程序结束,如下所示:
cv2.imshow(test_img_path, img)
cv2.waitKey(0)
让我们运行修改后的脚本,看看它能如何回答永恒的问题:杜德,我的车在哪里?
以下屏幕截图显示了成功的检测:

我们的另一个测试图像中有两辆车。 碰巧的是,成功检测到一辆汽车,而另一辆则未成功,如以下屏幕截图所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-I3RfrsE1-1681871605265)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/learn-opencv4-cv-py3/img/c81bc1e1-7f9f-4b98-baee-dd4b97c3e530.png)]
有时,其中具有许多特征的背景区域被错误地检测为汽车。 这是一个例子:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ttYiwkez-1681871605265)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/learn-opencv4-cv-py3/img/32aeb7bf-d325-4e18-bc1e-c6201d7769a9.png)]
请记住,在此示例脚本中,我们的训练集很小。 具有更大背景的更大训练集可以改善结果。 另外,请记住,图像金字塔和滑动窗口会产生大量的 ROI。 考虑这一点时,我们应该意识到检测器的误报率实际上很低。 如果我们要对视频的帧执行检测,则可以通过过滤掉仅出现在单个帧或几个帧中而不是一系列任意的最小长度的检测,来进一步降低误报率。
随意尝试上述脚本的参数和训练集。 当您准备就绪时,让我们用一些结束语来结束本章。
保存和加载经过训练的 SVM
关于 SVM 的最后一条建议是:您不需要每次使用探测器时都对它进行训练–实际上,由于训练速度很慢,因此您应该避免这样做。 您可以使用以下代码将经过训练的 SVM 模型保存到 XML 文件:
svm = cv2.ml.SVM_create()
svm.train(np.array(training_data), cv2.ml.ROW_SAMPLE,
np.array(training_labels))
svm.save('my_svm.xml')
随后,您可以使用以下代码重新加载经过训练的 SVM:
svm = cv2.ml.SVM_create()
svm.load('my_svm.xml')
通常,您可能有一个脚本用于训练和保存 SVM 模型,而其他脚本则可以加载和使用它来解决各种检测问题。
总结
在本章中,我们涵盖了广泛的概念和技术,包括 HOG,BoW,SVM,图像金字塔,滑动窗口和 NMS。 我们了解到这些技术在对象检测以及其他领域中都有应用。 我们编写了一个脚本,该脚本结合了 BoW,SVM,图像金字塔,滑动窗口和 NMS 等大多数技术,并且通过训练和测试自定义检测器,在机器学习中获得了实践经验。 最后,我们证明了我们可以检测到汽车!
我们的新知识构成下一章的基础,在下一章中,我们将对视频中的帧序列利用对象检测和分类技术。 我们将学习如何跟踪对象并保留有关它们的信息-这是许多实际应用中的重要目标。
八、追踪对象
在本章中,我们将从对象跟踪的广泛主题中探索一系列技术,这是在电影或来自摄像机的视频馈送中定位运动对象的过程。 实时对象跟踪是许多计算机视觉应用中的关键任务,例如监视,感知用户界面,增强现实,基于对象的视频压缩和驾驶员辅助。
跟踪对象可以通过多种方式来完成,而最佳技术则很大程度上取决于手头的任务。 在研究此主题时,我们将采取以下路线:
- 根据当前帧和代表背景的帧之间的差异检测运动对象。 首先,我们将尝试这种方法的简单实现。 然后,我们将使用 OpenCV 的更高级算法的实现,即高斯混合(MOG)和 K 最近邻(KNN)背景减法器。 我们还将考虑如何修改脚本以使用 OpenCV 支持的任何其他背景减法器,例如 Godbehere-Matsukawa-Goldberg(GMG)背景减法器。
- 根据对象的颜色直方图跟踪移动的对象。 这种方法涉及直方图反投影,这是计算各个图像区域和直方图之间相似度的过程。 换句话说,直方图用作我们期望对象外观的模板。 我们将使用称为 MeanShift 和 CamShift 的跟踪算法,这些算法对直方图反投影的结果进行运算。
- 使用卡尔曼过滤器查找对象运动的趋势,并预测对象下一步的移动方向。
- 回顾 OpenCV 支持面向对象编程(OOP)范式的方式,并考虑这与函数式编程(FP)范例有何不同。
- 实现结合了 KNN 背景减法,MeanShift 和卡尔曼滤波的行人跟踪器。
如果您已按顺序阅读本书,那么到本章结束时,您将了解许多以 2D 形式描述,检测,分类和跟踪对象的方法。 届时,您应该准备在第 9 章,“摄像机模型和增强现实”中进行 3D 跟踪。
技术要求
本章使用 Python,OpenCV 和 NumPy。 有关安装说明,请参阅第 1 章,“设置 OpenCV”。
可在本书的 GitHub 存储库中找到本章的完整代码和示例视频,位于chapter08文件夹中。
通过背景减法检测运动物体
要跟踪视频中的任何内容,首先,我们必须确定视频帧中与移动对象相对应的区域。 许多运动检测技术都基于背景减法的简单概念。 例如,假设我们有一台固定的摄像机来观看也基本上静止的场景。 除此之外,假设相机的曝光和场景中的照明条件是稳定的,以使帧的亮度变化不大。 在这些条件下,我们可以轻松捕获代表背景的参考图像,换句话说,就是场景的静止部分。 然后,无论何时摄像机捕获新帧,我们都可以从参考图像中减去该帧,并取该差的绝对值,以便获得该帧中每个像素位置的运动测量值。 如果帧的任何区域与参考图像有很大不同,我们可以得出结论,给定区域是运动对象。
背景减法技术通常具有以下局限性:
- 摄像机的任何运动,曝光变化或照明条件的变化都可能导致整个场景中的像素值立即发生变化。 因此,整个背景模型(或参考图像)已过时。
- 如果某个对象进入场景,然后在该场景中停留很长一段时间,那么一部分背景模型可能会过时。 例如,假设我们的场景是走廊。 有人进入走廊,将海报放在墙上,然后将海报留在那里。 实际上,海报实际上只是固定背景的另一部分。 但是,它不是我们参考图像的一部分,因此我们的背景模型已经过时了。
这些问题表明需要基于一系列新帧动态更新背景模型。 先进的背景减法技术试图以多种方式解决这一需求。
另一个普遍的限制是阴影和固体对象可能以类似方式影响背景减法器。 例如,由于我们无法将物体与其阴影区分开来,因此我们可能无法获得运动物体的大小和形状的准确图片。 但是,先进的背景减法技术确实尝试使用各种方法来区分阴影区域和实体对象。
背景减法器通常还有另一个局限性:它们无法对其检测到的运动类型提供细粒度的控制。 例如,如果场景显示地铁车在其轨道上行驶时不断晃动,则此重复动作将影响背景减法器。 出于实际目的,我们可以将地铁的振动视为半静止背景下的正常变化。 我们甚至可能知道这些振动的频率。 但是,背景减法器不会嵌入有关运动频率的任何信息,因此它没有提供方便或精确的方法来滤除此类可预测的运动。 为了弥补这些缺点,我们可以应用预处理步骤,例如模糊参考图像,也可以模糊每个新帧。 以这种方式,尽管以不太直观,有效或精确的方式抑制了某些频率。
分析运动频率超出了本书的范围。 但是,有关在计算机视觉环境中对此主题的介绍,请参阅 Joseph Howse 的书《写给秘密特工的 OpenCV 4》(Packt Publishing,2019),特别是第 7 章“用运动放大相机观看心跳”。
现在,我们已经对背景减法进行了概述,并了解了背景减法面临的一些障碍,让我们研究一下背景减法的实现效果如何。 我们将从一个简单但不鲁棒的实现开始,我们可以编写几行代码,然后发展到 OpenCV 为我们提供的更复杂的替代方案。
实现基本的背景减法器
为了实现基本的背景减法器,让我们采用以下方法:
- 开始从相机捕获帧。
- 丢弃九帧,以便相机有时间适当调整其自动曝光以适合场景中的照明条件。
- 拍摄第 10 帧,将其转换为灰度,对其进行模糊处理,然后将此模糊图像用作背景的参考图像。
- 对于每个后续帧,请对该帧进行模糊处理,然后将其转换为灰度,然后计算该模糊帧与背景参考图像之间的绝对差。 对差异图像执行阈值化,平滑和轮廓检测。 绘制并显示主要轮廓的边界框。
高斯模糊的使用应该使我们的背景减法器不易受到小振动以及数字噪声的影响。 形态学操作也提供了这些好处。
要模糊图像,我们将使用高斯模糊算法,该算法最初在第 3 章“使用 OpenCV 处理图像”中,特别是在“HPF 和 LPF”部分中讨论过。 为了使阈值图像平滑,我们将使用形态学侵蚀和膨胀,我们最初在第 4 章,“深度估计和分割”中讨论过,特别是在“使用分水岭算法进行图像分割”部分中。 轮廓检测和边界框也是我们在第 3 章“使用 OpenCV 处理图像”,特别是在“轮廓检测”部分中介绍的主题。
将前面的列表扩展为更小的步骤,我们可以考虑在八个顺序的代码块中执行脚本:
- 让我们开始导入 OpenCV 并为
blur,erode和dilate操作定义核的大小:
import cv2
BLUR_RADIUS = 21
erode_kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (5, 5))
dilate_kernel = cv2.getStructuringElement(
cv2.MORPH_ELLIPSE, (9, 9))
- 现在,让我们尝试从相机捕获 10 帧:
cap = cv2.VideoCapture(0)
# Capture several frames to allow the camera's autoexposure to adjust.
for i in range(10):
success, frame = cap.read()
if not success:
exit(1)
- 如果我们无法捕获 10 帧,则退出。 否则,我们将第 10 帧转换为灰度并对其进行模糊处理:
gray_background = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
gray_background = cv2.GaussianBlur(gray_background,
(BLUR_RADIUS, BLUR_RADIUS), 0)
- 在这一阶段,我们有背景的参考图像。 现在,让我们继续捕获更多帧,以检测运动。 我们对每一帧的处理都是从灰度转换和高斯模糊运算开始的:
success, frame = cap.read()
while success:
gray_frame = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
gray_frame = cv2.GaussianBlur(gray_frame,
(BLUR_RADIUS, BLUR_RADIUS), 0)
- 现在,我们可以将当前帧的模糊灰度版本与背景图像的模糊灰度版本进行比较。 具体来说,我们将使用 OpenCV 的
cv2.absdiff函数查找这两个图像之间差异的绝对值(或大小)。 然后,我们将应用阈值以获得纯黑白图像,并应用形态学操作来平滑阈值图像。 以下是相关代码:
diff = cv2.absdiff(gray_background, gray_frame)
_, thresh = cv2.threshold(diff, 40, 255, cv2.THRESH_BINARY)
cv2.erode(thresh, erode_kernel, thresh, iterations=2)
cv2.dilate(thresh, dilate_kernel, thresh, iterations=2)
- 在这一点上,如果我们的技术运行良好,则在有运动物体的任何地方,我们的阈值图像都应包含白色斑点。 现在,我们要查找白色斑点的轮廓并在其周围绘制边界框。 作为过滤掉可能不是真实物体的细微变化的另一种方法,我们将基于轮廓的面积应用阈值。 如果轮廓线太小,我们可以得出结论,它不是真正的运动物体。 (当然,“定义太小”可能会因相机的分辨率和应用而异;在某些情况下,您可能根本不希望进行此测试。)以下代码用于检测轮廓和绘制边界框:
_, contours, hier = cv2.findContours(thresh, cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
for c in contours:
if cv2.contourArea(c) > 4000:
x, y, w, h = cv2.boundingRect(c)
cv2.rectangle(frame, (x, y), (x+w, y+h), (255, 255, 0), 2)
- 现在,让我们用边界矩形显示差异图像,阈值图像和检测结果:
cv2.imshow('diff', diff)
cv2.imshow('thresh', thresh)
cv2.imshow('detection', frame)
- 我们将继续读取帧,直到用户按下
Esc键退出为止:
k = cv2.waitKey(1)
if k == 27: # Escape
break
success, frame = cap.read()
在那里,您便拥有了一个基本的运动检测器,它可以在移动物体周围绘制矩形。 最终结果是这样的:
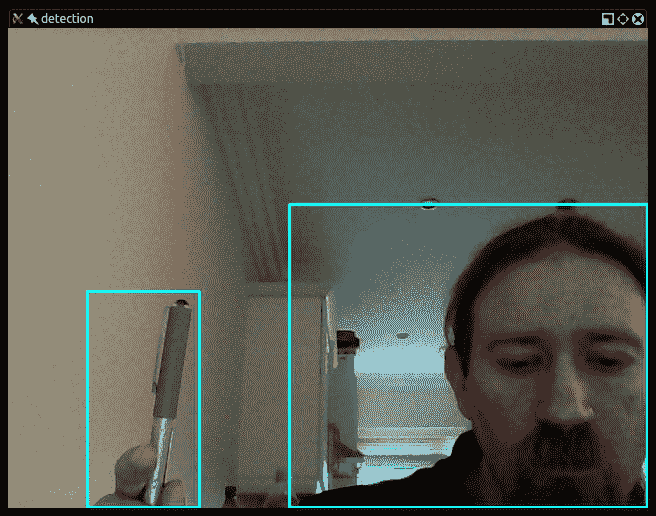
为了使用此脚本获得良好的效果,请确保在初始化背景图像之后,您(和其他移动物体)才进入摄像机的视野。
对于这种简单的技术,此结果很有希望。 但是,我们的脚本不努力动态地更新背景图像,因此如果相机移动或照明发生变化,它将很快过时。 因此,我们应该继续使用更加灵活和智能的背景减法器。 幸运的是,OpenCV 提供了几个现成的背景减法器供我们使用。 我们将从实现 MOG 算法的算法开始。
使用 MOG 背景减法器
OpenCV 提供了一个名为cv2.BackgroundSubtractor的类,该类具有实现各种背景减法算法的各种子类。
您可能还记得,我们之前在第 4 章,“深度估计和分段”中,特别是在“GrabCut 算法的前景检测”部分中,使用了 OpenCV 的 GrabCut 算法来执行前景/背景分割。 像cv2.grabCut一样,cv2.BackgroundSubtractor的各种子类实现也可以产生一个掩码,该掩码将不同的值分配给图像的不同段。 具体来说,背景减法器可以将前景段标记为白色(即 255 的 8 位灰度值),将背景段标记为黑色(0),将阴影段标记为灰色(127)。 此外,与 GrabCut 不同的是,背景减法器会随着时间的推移更新前景/背景模型,通常是通过将机器学习应用于一系列帧来实现的。 许多背景减法器是根据统计聚类技术命名的,它们是基于它们的机器学习方法的。 因此,我们将首先查看基于 MOG 聚类技术的背景减法器。
OpenCV 具有 MOG 背景减法器的两种实现。 也许不足为奇,它们被命名为cv2.BackgroundSubtractorMOG和cv2.BackgroundSubtractorMOG2。 后者是更新的实现,它增加了对阴影检测的支持,因此我们将使用它。
首先,让我们以上一节中的基本背景减除脚本为基础。 我们将对其进行以下修改:
- 用 MOG 背景减法器替换我们的基本背景减法模型。
- 作为输入,请使用视频文件而不是摄像机。
- 取消使用高斯模糊。
- 调整阈值,形态和轮廓分析步骤中使用的参数。
这些修改会影响几行代码,这些代码分散在整个脚本中。 在脚本顶部附近,让我们初始化 MOG 背景减法器并修改形态核的大小,如以下代码块中的粗体所示:
import cv2
bg_subtractor = cv2.createBackgroundSubtractorMOG2(detectShadows=True)
erode_kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (3, 3))
dilate_kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (7, 7))
请注意,OpenCV 提供了cv2.createBackgroundSubtractorMOG2函数来创建cv2.BackgroundSubtractorMOG2的实例。 该函数接受参数detectShadows,我们将其设置为True,这样阴影区域将被标记为此类,而不标记为前景的一部分。
其余更改(包括使用 MOG 背景减法器获取前景/阴影/背景遮罩)在以下代码块中以粗体标记:
cap = cv2.VideoCapture('hallway.mpg')
success, frame = cap.read()
while success:
fg_mask = bg_subtractor.apply(frame)
_, thresh = cv2.threshold(fg_mask, 244, 255, cv2.THRESH_BINARY)
cv2.erode(thresh, erode_kernel, thresh, iterations=2)
cv2.dilate(thresh, dilate_kernel, thresh, iterations=2)
contours, hier = cv2.findContours(thresh, cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
for c in contours:
if cv2.contourArea(c) > 1000:
x, y, w, h = cv2.boundingRect(c)
cv2.rectangle(frame, (x, y), (x+w, y+h), (255, 255, 0), 2)
cv2.imshow('mog', fg_mask)
cv2.imshow('thresh', thresh)
cv2.imshow('detection', frame)
k = cv2.waitKey(30)
if k == 27: # Escape
break
success, frame = cap.read()
当我们将帧传递给背景减法器的apply方法时,减法器更新其背景的内部模型,然后返回掩码。 如前所述,对于前景段,遮罩为白色(255),对于阴影段为灰色(127),对于背景段为黑色(0)。 出于我们的目的,我们将阴影视为背景,因此我们向遮罩应用了接近白色的阈值(244)。
以下屏幕截图显示了来自 MOG 检测器的遮罩(左上图),该遮罩的阈值和变形版本(右上图)以及检测结果(下图):
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QUQV5lQO-1681871605265)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/learn-opencv4-cv-py3/img/5411968e-4189-41af-a28e-c5e765213a91.png)]
为了进行比较,如果通过设置detectShadows=False禁用阴影检测,我们将获得诸如以下屏幕截图的结果:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8jkC7kzS-1681871605266)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/learn-opencv4-cv-py3/img/30a0bf8d-cccb-4419-9d29-bc9301a530c3.png)]
由于抛光的地板和墙壁,该场景不仅包含阴影,还包含反射。 启用阴影检测后,我们可以使用阈值去除遮罩中的阴影和反射,从而使我们在大厅中的人周围有一个准确的检测矩形。 但是,当禁用阴影检测时,我们可以进行两种检测,这两种检测都可以说是不准确的。 一种检测覆盖了该人,他的阴影以及他在地板上的反射。 第二次检测覆盖了该人在墙上的反射。 这些可以说是不准确的检测结果,因为人的阴影和反射并不是真正的移动物体,即使它们是移动物体的视觉伪像。
到目前为止,我们已经看到,背景减法脚本可以非常简洁,并且进行一些小改动就可以大大改变算法和结果,无论是好是坏。 以同样的方式继续进行下去,让我们看看我们如何轻松修改代码以使用 OpenCV 的另一种高级背景减法器来查找另一种运动对象。
使用 KNN 背景减法器
通过仅在 MOG 背景减法脚本中修改五行代码,我们可以使用不同的背景减法算法,不同的形态参数以及不同的视频作为输入。 借助 OpenCV 提供的高级接口,即使是这些简单的更改,也使我们能够成功处理各种后台扣除任务。
只需将cv2.createBackgroundSubtractorMOG2替换为cv2.createBackgroundSubtractorKNN,我们就可以使用基于 KNN 聚类而非 MOG 聚类的背景减法器:
bg_subtractor = cv2.createBackgroundSubtractorKNN(detectShadows=True)
请注意,尽管算法有所变化,但仍支持detectShadows参数。 此外,apply方法仍然受支持,因此我们在脚本的后面不需要更改与使用背景减法器有关的任何内容。
请记住,cv2.createBackgroundSubtractorMOG2返回cv2.BackgroundSubtractorMOG2类的新实例。 同样,cv2.createBackgroundSubtractorKNN返回cv2.BackgroundSubtractorKNN类的新实例。 这两个类都是cv2.BackgroundSubtractor的子类,它定义了apply之类的常用方法。
进行以下更改后,我们可以使用形态核,这些核稍微更适合水平拉长的物体(在本例中为汽车),并且可以使用交通视频作为输入:
erode_kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (7, 5))
dilate_kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (17, 11))
cap = cv2.VideoCapture('traffic.flv')
为了反映算法的变化,让我们将遮罩窗口的标题从'mog'更改为'knn':
cv2.imshow('knn', fg_mask)
以下屏幕截图显示了运动检测的结果:
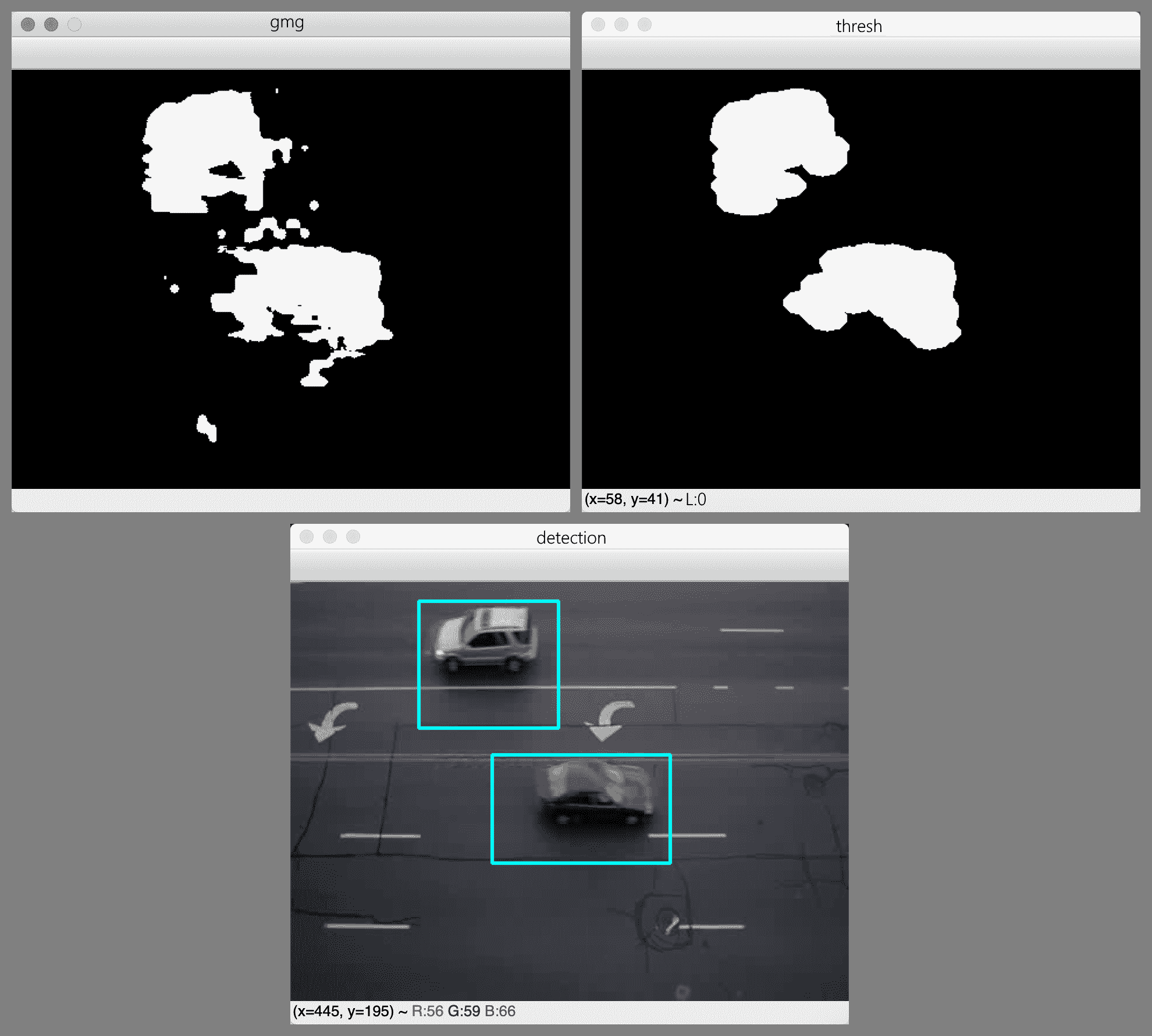
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9HpmDCBV-1681871605266)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/learn-opencv4-cv-py3/img/b4d2bfd1-89bd-4265-bf9c-6dfc41bd3a50.png)]
KNN 背景减法器及其在对象和阴影之间进行区分的功能在这里效果很好。 所有汽车都被单独检测到; 即使有些汽车彼此靠近,也没有将它们合并为一个检测。 对于五分之三的汽车,检测矩形是准确的。 对于视频帧左下角的深色汽车,背景减法器无法完全区分汽车的后部和沥青。 对于框架顶部中央部分的白色汽车,背景减法器无法将汽车及其阴影与道路上的白色标记完全区分开。 尽管如此,总的来说,这是一个有用的检测结果,可以使我们计算每个车道上行驶的汽车数量。
如我们所见,脚本上的一些简单变体可以产生非常不同的背景减法结果。 让我们考虑如何进一步探索这一观察。
使用 GMG 和其他背景减法器
您可以自由尝试对我们的背景减法脚本进行自己的修改。 如果已经通过可选的opencv_contrib模块获得了 OpenCV,如第 1 章,“设置 OpenCV”中所述,则cv2.bgsegm模块中还可以使用几个背景减法器 。 可以使用以下函数创建它们:
cv2.bgsegm.createBackgroundSubtractorCNTcv2.bgsegm.createBackgroundSubtractorGMGcv2.bgsegm.createBackgroundSubtractorGSOCcv2.bgsegm.createBackgroundSubtractorLSBPcv2.bgsegm.createBackgroundSubtractorMOGcv2.bgsegm.createSyntheticSequenceGenerator
这些函数不支持detectShadows参数,它们创建不支持阴影检测的背景减法器。 但是,所有背景减法器都支持apply方法。
作为如何修改背景减法样本以使用前面列表中的cv2.bgsegm减法器之一的示例,让我们使用 GMG 背景减法器。 在以下代码块中,相关的修改以粗体突出显示:
import cv2
bg_subtractor = cv2.bgsegm.createBackgroundSubtractorGMG()
erode_kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (13, 9))
dilate_kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (17, 11))
cap = cv2.VideoCapture('traffic.flv')
success, frame = cap.read()
while success:
fg_mask = bg_subtractor.apply(frame)
_, thresh = cv2.threshold(fg_mask, 244, 255, cv2.THRESH_BINARY)
cv2.erode(thresh, erode_kernel, thresh, iterations=2)
cv2.dilate(thresh, dilate_kernel, thresh, iterations=2)
contours, hier = cv2.findContours(thresh, cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
for c in contours:
if cv2.contourArea(c) > 1000:
x, y, w, h = cv2.boundingRect(c)
cv2.rectangle(frame, (x, y), (x+w, y+h), (255, 255, 0), 2)
cv2.imshow('gmg', fg_mask)
cv2.imshow('thresh', thresh)
cv2.imshow('detection', frame)
k = cv2.waitKey(30)
if k == 27: # Escape
break
success, frame = cap.read()
请注意,这些修改类似于我们在上一节“使用 KNN 背景减法器”中看到的修改。 我们只需要使用一个不同的函数来创建 GMG 减法器,就可以将形态核的大小调整为更适合该算法的值,然后将其中一个窗口标题更改为'gmg'。
GMG 算法以其作者 Andrew B. Godbehere,Akihiro Matsukawa 和 Ken Goldberg 的名字命名。 他们在论文《在可变照明条件下对观众进行视觉跟踪以进行响应式音频艺术装置》(ACC,2012)中进行了描述,该论文可从这个页面。 GMG 背景减法器在开始生成带有白色(对象)区域的遮罩之前,需要花费一些帧来初始化自身。
与 KNN 背景减法器相比,GMG 背景减法器在我们的交通示例视频中产生的效果更差。 部分原因是 OpenCV 的 GMG 实现无法区分阴影和固体物体,因此检测矩形在汽车的阴影或反射方向上拉长。 这是输出示例:
在完成背景减法器的实验后,让我们继续研究其他跟踪技术,这些技术依赖于我们要跟踪的对象的模板而不是背景的模板。
使用 MeanShift 和 CamShift 跟踪彩色物体
我们已经看到,背景减法可以成为检测运动物体的有效技术。 但是,我们知道它有一些固有的局限性。 值得注意的是,它假定可以基于过去的帧来预测当前背景。 这个假设是脆弱的。 例如,如果照相机移动,则整个背景模型可能突然过时。 因此,在鲁棒的跟踪系统中,重要的是建立某种前景对象模型,而不仅仅是背景模型。
我们已经在第 5 章,“检测和识别人脸”,第 6 章,“检索图像和使用图像描述符进行搜索”中和第 7 章,“构建自定义对象检测器”。 对于物体检测,我们偏爱可以处理一类物体内大量变化的算法,因此我们的汽车检测器不太会检测其形状或颜色。 对于跟踪的对象,我们的需求有所不同。 如果要跟踪汽车,则我们希望场景中的每辆汽车都具有不同的模型,以免红色汽车和蓝色汽车混淆。 我们想分别跟踪每辆车的运动。
一旦检测到移动物体(通过背景减法或其他方式),我们便要以与其他移动物体不同的方式描述该物体。 这样,即使物体与另一个运动物体交叉,我们也可以继续识别和跟踪物体。 颜色直方图可以用作足够独特的描述。 本质上,对象的颜色直方图是对对象中像素颜色的概率分布的估计。 例如,直方图可以指示对象中的每个像素都是蓝色的可能性为 10%。 直方图基于在参考图像的对象区域中观察到的实际颜色。 例如,参考图像可以是我们首先在其中检测到运动对象的视频帧。
与其他描述对象的方式相比,颜色直方图具有一些在运动跟踪方面特别吸引人的属性。 直方图用作直接将像素值映射到概率的查找表,因此它使我们能够以较低的计算成本将每个像素用作特征。 这样,我们可以实时地以非常精细的空间分辨率执行跟踪。 为了找到我们正在跟踪的对象的最可能位置,我们只需要根据直方图找到像素值映射到最大概率的兴趣区域。
自然地,这种方法被具有醒目的名称:MeanShift 的算法所利用。 对于视频中的每个帧,MeanShift 算法通过基于当前跟踪矩形中的概率值计算质心,将矩形的中心移至该质心,基于新矩形中的值重新计算质心,再次移动矩形来进行迭代跟踪 , 等等。 此过程一直持续到收敛达到(意味着质心停止移动或几乎停止移动)或直到达到最大迭代次数为止。 本质上,MeanShift 是一种聚类算法,其应用扩展到了计算机视觉之外。 该算法首先由 K.Fukunaga 和 L.Hostetler 在题为《密度函数梯度的估计及其在模式识别》(IEEE,1975)中的应用中进行了描述。 IEEE 订户可以通过这个页面获得该论文。
在研究示例脚本之前,让我们考虑一下要通过 MeanShift 实现的跟踪结果的类型,并让我们进一步了解 OpenCV 与颜色直方图有关的功能。
规划我们的 MeanShift 示例
对于 MeanShift 的首次演示,我们不关心移动物体的初始检测方法。 我们将采用幼稚的方法,该方法只是选择第一个视频帧的中心部分作为我们感兴趣的初始区域。 (用户必须确保感兴趣的对象最初位于视频的中心。)我们将计算该感兴趣的初始区域的直方图。 然后,在随后的帧中,我们将使用此直方图和 MeanShift 算法来跟踪对象。
在视觉上,MeanShift 演示将类似于我们先前编写的许多对象检测示例。 对于每一帧,我们将在跟踪矩形周围绘制一个蓝色轮廓,如下所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pBdguvpU-1681871605266)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/learn-opencv4-cv-py3/img/b0f74533-c63a-4920-a3b2-0e356475435c.png)]
在此,玩具电话具有淡紫色,在场景中的任何其他对象中都不存在。 因此,电话具有独特的直方图,因此易于跟踪。 接下来,让我们考虑如何计算直方图,然后将其用作概率查找表。
计算和反投影颜色直方图
为了计算颜色直方图,OpenCV 提供了一个称为cv2.calcHist的函数。 要将直方图用作查找表,OpenCV 提供了另一个名为cv2.calcBackProject的函数。 后者的操作称为直方图反投影,它将基于给定的直方图将给定的图像转换为概率图。 让我们首先可视化这两个函数的输出,然后检查它们的参数。
直方图可以使用任何颜色模型,例如蓝绿红(BGR),色相饱和度值(HSV)或灰度。 (有关颜色模型的介绍,请参阅第 3 章,“用 OpenCV 处理图像”,特别是“在不同颜色模型之间转换图像”部分。) ,我们将仅使用 HSV 颜色模型的色相(H)通道的直方图。 下图是色调直方图的可视化:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-llKrjLo7-1681871605266)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/learn-opencv4-cv-py3/img/3ad27b78-a3e1-4cb0-9de6-b79a7d05df29.png)]
该直方图可视化是来自名为 DPEx 的图像查看应用输出的示例。
在此图的x轴上,有色相,在y轴上,有色相的估计概率,换句话说,就是图像中具有给定的色调的像素比例。 如果您正在阅读本书的电子书版本,则将看到该图根据色相进行了颜色编码。 从左到右,绘图通过色轮的色调进行:红色,黄色,绿色,青色,蓝色,洋红色,最后回到红色。 这个特殊的直方图似乎代表了一个带有很多黄色的物体。
OpenCV 表示 H 值,范围从 0 到 179。某些其他系统使用的范围是 0 到 359(如圆的度数)或 0 到 255。
由于纯黑色和纯白色像素没有有意义的色相,因此在解释色相直方图时需要格外小心。 但是,它们的色相通常表示为 0(红色)。
当我们使用cv2.calcHist生成色调直方图时,它将返回一个在概念上与前面的图相似的一维数组。 或者,根据我们提供的参数,我们可以使用cv2.calcHist生成另一个通道或两个通道的直方图。 在后一种情况下,cv2.calcHist将返回 2D 数组。
有了直方图后,我们可以将直方图反向投影到任何图像上。 cv2.calcBackProject产生 8 位灰度图像格式的反投影,其像素值的范围可能为 0(表示低概率)到 255(表示高概率),具体取决于我们如何缩放这些值。 例如,考虑以下两张照片,分别显示背投和 MeanShift 跟踪结果的可视化:

在这里,我们正在跟踪一个主要颜色为黄色,红色和棕色的小物体。 在实际上是对象一部分的区域中,背投影最亮。 在其他类似颜色的区域中,背投投影也有些明亮,例如约瑟夫·霍斯(Joseph Howse)的棕色胡须,他的眼镜的黄框以及背景中海报之一的红色边框。
现在我们已经可视化了cv2.calcHist和cv2.calcBackProject的输出,让我们检查这些函数接受的参数。
了解cv2.calcHist的参数
cv2.calcHist函数具有以下签名:
calcHist(images, channels, mask, histSize, ranges[, hist[,
accumulate]]) -> hist
下表包含参数的说明(改编自 OpenCV 官方文档):
| 参数 | 说明 |
|---|---|
images | 此参数是一个或多个源图像的列表。 它们都应具有相同的位深度(8 位,16 位或 32 位)和相同的大小。 |
channels | 此参数是用于计算直方图的通道索引的列表。 例如,channels=[0]表示仅使用第一个通道(即索引为0的通道)来计算直方图。 |
mask | 此参数是掩码。 如果为None,则不执行任何屏蔽操作; 图像的每个区域都用于直方图计算中。 如果不是None,则它必须是与images中每个图像大小相同的 8 位数组。 遮罩的非零元素标记应在直方图计算中使用的图像区域。 |
histSize | 此参数是每个通道要使用的直方图箱数的列表。 histSize列表的长度必须与channels列表的长度相同。 例如,如果channels=[0]和histSize=[180],则直方图对于第一个通道具有 180 个箱子(并且未使用任何其他通道)。 |
ranges | 此参数是一个列表,该列表指定每个通道要使用的值的范围(包括下限和排除上限)。 ranges列表的长度必须是channels列表的长度的两倍。 例如,如果channels=[0],histSize=[180]和ranges=[0, 180],则直方图的第一个通道具有 180 个箱子,这些箱子基于 0 到 179 范围内的值; 换句话说,每个仓位只有一个输入值。 |
hist | 此可选参数是输出直方图。 如果它是None(默认值),则将返回一个新数组作为输出直方图。 |
accumulate | 此可选参数是accumulate标志。 默认情况下为False。 如果是True,则不会清除hist的原始内容; 而是将新的直方图添加到hist的原始内容中。 使用此功能,您可以从多个图像列表中计算单个直方图,或者随时间更新直方图。 |
在我们的样本中,我们将像这样计算兴趣区域的色相直方图:
roi_hist = cv2.calcHist([hsv_roi], [0], mask, [180], [0, 180])
接下来,让我们考虑cv2.calcBackProject的参数。
了解cv2.calcBackProject的参数
cv2.calcBackProject函数具有以下签名:
calcBackProject(images, channels, hist, ranges,
scale[, dst]) -> dst
下表包含参数的说明(改编自 OpenCV 官方文档):
| 参数 | 说明 |
|---|---|
images | 此参数是一个或多个源图像的列表。 它们都应具有相同的位深度(8 位,16 位或 32 位)和相同的大小。 |
channels | 此参数必须与calcHist中使用的channels参数相同。 |
hist | 此参数是直方图。 |
ranges | 此参数必须与calcHist中使用的ranges参数相同。 |
scale | 此参数是比例因子。 反投影乘以该比例因子。 |
dst | 此可选参数是输出反投影。 如果它是None(默认值),将返回一个新数组作为反投影。 |
在我们的示例中,我们将使用类似于以下行的代码将色相直方图反向投影到 HSV 图像上:
back_proj = cv2.calcBackProject([hsv], [0], roi_hist, [0, 180], 1)
在详细研究了cv2.calcHist和cv2.calcBackProject函数之后,现在让我们在使用 MeanShift 进行跟踪的脚本中将它们付诸实践。
实现 MeanShift 示例
让我们依次研究一下 MeanShift 示例的实现:
- 像我们的基本背景减除示例一样,MeanShift 示例从捕获(并丢弃)相机的几帧开始,以便自动曝光可以调整:
import cv2
cap = cv2.VideoCapture(0)
# Capture several frames to allow the camera's autoexposure to
# adjust.
for i in range(10):
success, frame = cap.read()
if not success:
exit(1)
- 到第 10 帧,我们假设曝光良好; 因此,我们可以提取兴趣区域的准确直方图。 以下代码定义了兴趣区域(ROI)的边界:
# Define an initial tracking window in the center of the frame.
frame_h, frame_w = frame.shape[:2]
w = frame_w//8
h = frame_h//8
x = frame_w//2 - w//2
y = frame_h//2 - h//2
track_window = (x, y, w, h)
- 然后,以下代码选择 ROI 的像素并将其转换为 HSV 颜色空间:
roi = frame[y:y+h, x:x+w]
hsv_roi = cv2.cvtColor(roi, cv2.COLOR_BGR2HSV)
- 接下来,我们计算 ROI 的色相直方图:
mask = None
roi_hist = cv2.calcHist([hsv_roi], [0], mask, [180], [0, 180])
- 在计算直方图之后,我们将值归一化为 0 到 255 之间的范围:
cv2.normalize(roi_hist, roi_hist, 0, 255, cv2.NORM_MINMAX)
- 请记住,MeanShift 在达到收敛之前执行了许多迭代。 但是,这种融合并不能保证。 因此,OpenCV 允许我们指定所谓的终止标准。 让我们定义终止条件如下:
# Define the termination criteria:
# 10 iterations or convergence within 1-pixel radius.
term_crit = \
(cv2.TERM_CRITERIA_COUNT | cv2.TERM_CRITERIA_FPS, 10, 1)
基于这些标准,MeanShift 将在 10 次迭代后(计数标准)或当位移不再大于 1 个像素(ε标准)时停止计算质心偏移。 标志(cv2.TERM_CRITERIA_COUNT | cv2.TERM_CRITERIA_EPS)的组合表示我们正在使用这两个条件。
- 现在我们已经计算出直方图并定义了 MeanShift 的终止条件,让我们开始通常的循环,在该循环中我们从相机捕获并处理帧。 对于每一帧,我们要做的第一件事就是将其转换为 HSV 颜色空间:
success, frame = cap.read()
while success:
hsv = cv2.cvtColor(frame, cv2.COLOR_BGR2HSV)
- 现在我们有了 HSV 图像,我们可以执行期待已久的直方图反投影操作:
back_proj = cv2.calcBackProject(
[hsv], [0], roi_hist, [0, 180], 1)
- 反投影,跟踪窗口和终止条件可以传递给
cv2.meanShift,这是 OpenCV 对 MeanShift 算法的实现。 这是函数调用:
# Perform tracking with MeanShift.
num_iters, track_window = cv2.meanShift(
back_proj, track_window, term_crit)
请注意,MeanShift 返回其运行的迭代次数,以及找到的新跟踪窗口。 (可选)我们可以将迭代次数与终止条件进行比较,以确定结果是否收敛。 (如果实际的迭代次数小于最大值,则结果必须收敛。)
- 最后,我们绘制并显示更新的跟踪矩形:
# Draw the tracking window.
x, y, w, h = track_window
cv2.rectangle(
frame, (x, y), (x+w, y+h), (255, 0, 0), 2)
cv2.imshow('back-projection', back_proj)
cv2.imshow('meanshift', frame)
那就是整个例子。 如果运行该程序,它将在“计算和反投影颜色直方图”部分中产生与我们之前看到的屏幕截图类似的输出。
到目前为止,您应该对颜色直方图,反投影和 MeanShift 的工作原理有所了解。 但是,前面的程序(通常是 MeanShift)有一个局限性:窗口的大小不会随被跟踪帧中对象的大小而改变。
OpenCV 项目的创始人之一加里·布拉德斯基(Gary Bradski)于 1988 年发表了一篇论文,以提高 MeanShift 的准确率。 他描述了一种称为连续自适应 MeanShift(CAMShift 或 CamShift)的新算法,该算法与 MeanShift 非常相似,但在 MeanShift 时也可以调整跟踪窗口的大小来达到收敛。 接下来,让我们看一下 CamShift 的示例。
使用 CamShift
尽管 CamShift 是比 MeanShift 更复杂的算法,但 OpenCV 为这两种算法提供了非常相似的接口。 主要区别在于对cv2.CamShift的调用将返回一个具有特定旋转的矩形,该旋转随被跟踪对象的旋转而变化。 只需对前面的 MeanShift 示例进行一些修改,我们就可以使用 CamShift 并绘制一个旋转的跟踪矩形。 在以下摘录中,所有必需的更改均以粗体突出显示:
import cv2
import numpy as np
# ... Initialize the tracking window and histogram as previously ...
success, frame = cap.read()
while success:
# Perform back-projection of the HSV histogram onto the frame.
hsv = cv2.cvtColor(frame, cv2.COLOR_BGR2HSV)
back_proj = cv2.calcBackProject([hsv], [0], roi_hist, [0, 180], 1)
# Perform tracking with CamShift.
rotated_rect, track_window = cv2.CamShift(
back_proj, track_window, term_crit)
# Draw the tracking window.
box_points = cv2.boxPoints(rotated_rect)
box_points = np.int0(box_points)
cv2.polylines(frame, [box_points], True, (255, 0, 0), 2)
cv2.imshow('back-projection', back_proj)
cv2.imshow('camshift', frame)
k = cv2.waitKey(1)
if k == 27: # Escape
break
success, frame = cap.read()
cv2.CamShift的参数未更改; 它们与我们先前示例中的cv2.meanShift的参数具有相同的含义和相同的值。
我们使用cv2.boxPoints函数查找旋转的跟踪矩形的顶点。 然后,我们使用cv2.polylines函数绘制连接这些顶点的线。 以下屏幕截图显示了结果:

到目前为止,您应该熟悉两种跟踪技术。 第一个家庭使用背景减法。 第二种使用直方图反向投影,并结合了 MeanShift 或 CamShift。 现在,让我们认识一下卡尔曼过滤器,它代表了第三族; 它找到趋势,或者换句话说,根据过去的运动预测未来的运动。
使用卡尔曼过滤器查找运动趋势
卡尔曼过滤器是 Rudolf 卡尔曼在 1950 年代后期主要(但并非唯一)开发的算法。 它已经在许多领域中找到了实际应用,特别是从核潜艇到飞机的各种车辆的导航系统。
卡尔曼过滤器对嘈杂的输入数据流进行递归操作,以产生基础系统状态的统计最优估计。 在计算机视觉的背景下,卡尔曼过滤器可以使跟踪对象位置的估计变得平滑。
让我们考虑一个简单的例子。 想一想桌上的一个红色小球,想象一下您有一台照相机对准了现场。 您将球标识为要跟踪的对象,然后用手指轻拂它。 球将根据运动定律开始在桌子上滚动。
如果球在特定方向上以每秒 1 米的速度滚动,则很容易估计一秒钟后球将在哪里:它将在 1 米外。 卡尔曼过滤器应用诸如此类的定律,以基于在先前帧中收集的跟踪结果来预测对象在当前视频帧中的位置。 卡尔曼过滤器本身并没有收集这些跟踪结果,而是基于从另一种算法(例如 MeanShift)得出的跟踪结果来更新其对象运动模型。 自然,卡尔曼过滤器无法预测作用在球上的新力(例如与躺在桌上的铅笔的碰撞),但是它可以根据新的跟踪结果在事后更新其运动模型。 通过使用卡尔曼过滤器,我们可以获得比仅跟踪结果更稳定,更符合运动规律的估计。
了解预测和更新阶段
从前面的描述中,我们得出卡尔曼过滤器的算法具有两个阶段:
- 预测:在第一阶段,卡尔曼过滤器使用直到当前时间点为止计算出的协方差来估计对象的新位置。
- 更新:在第二阶段,卡尔曼过滤器记录对象的位置并为下一个计算周期调整协方差。
用 OpenCV 的术语来说,更新阶段是校正。 因此,OpenCV 通过以下方法提供cv2.KalmanFilter类:
predict([, control]) -> retval
correct(measurement) -> retval
为了平滑跟踪对象,我们将调用predict方法估计对象的位置,然后使用correct方法指示卡尔曼过滤器根据另一种算法的新跟踪结果调整其计算,例如 MeanShift。 但是,在将卡尔曼过滤器与计算机视觉算法结合使用之前,让我们检查一下它如何与来自简单运动传感器的位置数据一起执行。
跟踪鼠标光标
运动传感器在用户界面中已经很长时间了。 计算机的鼠标会感觉到自己相对于桌子等表面的运动。 鼠标是真实的物理对象,因此应用运动定律来预测鼠标坐标的变化是合理的。 我们将作为卡尔曼过滤器的演示来进行此操作。
我们的演示将实现以下操作序列:
- 首先初始化一个黑色图像和一个卡尔曼过滤器。 在窗口中显示黑色图像。
- 每次窗口应用处理输入事件时,请使用卡尔曼过滤器来预测鼠标的位置。 然后,根据实际的鼠标坐标校正卡尔曼过滤器的模型。 在黑色图像的顶部,从旧的预测位置到新的预测位置绘制一条红线,然后从旧的实际位置到新的实际位置绘制一条绿线。 在窗口中显示图形。
- 当用户按下
Esc键时,退出并将图形保存到文件中。
要开始执行脚本,以下代码将初始化一个800 x 800黑色图像:
import cv2
import numpy as np
# Create a black image.
img = np.zeros((800, 800, 3), np.uint8)
现在,让我们初始化卡尔曼过滤器:
# Initialize the Kalman filter.
kalman = cv2.KalmanFilter(4, 2)
kalman.measurementMatrix = np.array(
[[1, 0, 0, 0],
[0, 1, 0, 0]], np.float32)
kalman.transitionMatrix = np.array(
[[1, 0, 1, 0],
[0, 1, 0, 1],
[0, 0, 1, 0],
[0, 0, 0, 1]], np.float32)
kalman.processNoiseCov = np.array(
[[1, 0, 0, 0],
[0, 1, 0, 0],
[0, 0, 1, 0],
[0, 0, 0, 1]], np.float32) * 0.03
基于前面的初始化,我们的卡尔曼过滤器将跟踪 2D 对象的位置和速度。 我们将在第 9 章,“相机模型和增强现实”中更深入地研究卡尔曼过滤器的初始化过程,在其中我们将跟踪 3D 对象的位置,速度,加速度,旋转 ,角速度和角加速度。 现在,让我们仅注意cv2.KalmanFilter(4, 2)中的两个参数。 第一个参数是由卡尔曼过滤器跟踪(或预测)的变量数,在这种情况下为4:x位置,y位置,x速度,以及y速度。 第二个参数是作为测量提供给卡尔曼过滤器的变量的数量,在这种情况下,2:x位置和y位置。 我们还初始化了几个矩阵,这些矩阵描述了所有这些变量之间的关系。
初始化图像和卡尔曼过滤器后,我们还必须声明变量以保存实际(测量)和预测的鼠标坐标。 最初,我们没有坐标,因此我们将None分配给以下变量:
last_measurement = None
last_prediction = None
然后,我们声明一个处理鼠标移动的回调函数。 此函数将更新卡尔曼过滤器的状态,并绘制未过滤鼠标移动和卡尔曼过滤鼠标移动的可视化。 第一次收到鼠标坐标时,我们将初始化卡尔曼过滤器的状态,以便其初始预测与实际的初始鼠标坐标相同。 (如果不这样做,则卡尔曼过滤器将假定鼠标的初始位置为(0, 0)。)随后,每当我们收到新的鼠标坐标时,我们都会用当前测量值校正卡尔曼过滤器,计算卡尔曼预测值,然后, 最后,画两条线:从最后一次测量到当前测量的绿线,以及从最后一次预测到当前预测的红线。 这是回调函数的实现:
def on_mouse_moved(event, x, y, flags, param):
global img, kalman, last_measurement, last_prediction
measurement = np.array([[x], [y]], np.float32)
if last_measurement is None:
# This is the first measurement.
# Update the Kalman filter's state to match the measurement.
kalman.statePre = np.array(
[[x], [y], [0], [0]], np.float32)
kalman.statePost = np.array(
[[x], [y], [0], [0]], np.float32)
prediction = measurement
else:
kalman.correct(measurement)
prediction = kalman.predict() # Gets a reference, not a copy
# Trace the path of the measurement in green.
cv2.line(img, (last_measurement[0], last_measurement[1]),
(measurement[0], measurement[1]), (0, 255, 0))
# Trace the path of the prediction in red.
cv2.line(img, (last_prediction[0], last_prediction[1]),
(prediction[0], prediction[1]), (0, 0, 255))
last_prediction = prediction.copy()
last_measurement = measurement
下一步是初始化窗口并将回调函数传递给cv2.setMouseCallback函数:
cv2.namedWindow('kalman_tracker')
cv2.setMouseCallback('kalman_tracker', on_mouse_moved)
由于大多数程序的逻辑都在鼠标回调中,因此主循环的实现很简单。 我们只是不断地显示更新的图像,直到用户按下Esc键:
while True:
cv2.imshow('kalman_tracker', img)
k = cv2.waitKey(1)
if k == 27: # Escape
cv2.imwrite('kalman.png', img)
break
运行该程序并四处移动鼠标。 如果您突然高速转弯,您会发现预测线(红色)的曲线比测量线(绿色)的曲线宽。 这是因为预测是跟踪到那时鼠标移动的动量。 这是一个示例结果:

前面的图也许会给我们启发下一个示例应用的灵感,我们在其中跟踪行人。
跟踪行人
到目前为止,我们已经熟悉了运动检测,对象检测和对象跟踪的概念。 您可能急于在现实生活中充分利用这些新知识。 让我们通过监视摄像机中的视频跟踪行人来做到这一点。
您可以在samples/data/vtest.avi的 OpenCV 存储库中找到监视视频。 该视频的副本位于chapter08/pedestrians.avi这本书的 GitHub 存储库中。
让我们制定一个计划,然后实现该应用!
规划应用流程
该应用将遵循以下逻辑:
- 从视频文件捕获帧。
- 使用前 20 帧填充背景减法器的历史记录。
- 基于背景减法,使用第 21 帧识别移动的前景对象。 我们将把它们当作行人。 为每个行人分配一个 ID 和一个初始跟踪窗口,然后计算直方图。
- 对于每个后续帧,使用卡尔曼过滤器和 MeanShift 跟踪每个行人。
如果这是一个实际应用,则可能会存储每个行人穿过场景的路线的记录,以便用户稍后进行分析。 但是,这种类型的记录保存超出了本示例的范围。
此外,在实际应用中,您将确保识别出新的行人进入现场。 但是,现在,我们将集中精力仅跟踪视频开始附近场景中的那些对象。
您可以在本书的 GitHub 存储库中的chapter08/track_pedestrians.py找到该应用的代码。 在检查实现之前,让我们简要地讨论一下编程范例以及它们与我们对 OpenCV 的使用之间的关系。
比较面向对象和函数式范式
尽管大多数程序员对 OOP 都不熟悉(或不停地工作),但多年以来,另一种称为 FP 的范例一直在偏爱纯数学基础的程序员中获得支持。
塞缪尔·豪斯(Samuel Howse)的作品展示了具有纯数学基础的编程语言规范。 您可以在这个页面以及他的论文《NummSquared:正式方法》。
FP 将程序视为对数学函数的评估,允许函数返回函数,并允许函数作为函数中的参数。 FP 的优势不仅在于它可以做什么,还在于它可以避免或旨在避免的事情:例如,副作用和状态变化。 如果 FP 主题引起了人们的兴趣,请确保您看一下 Haskell,Clojure 或元语言(ML)之类的语言。
那么,编程方面的副作用是什么? 如果函数产生任何在其本地范围之外可以访问的更改(返回值除外),则该函数具有副作用。 Python 和许多其他语言一样,容易受到副作用的影响,因为它使您可以访问成员变量和全局变量-有时,这种访问可能是偶然的!
在非纯粹函数式的语言中,即使我们反复向其传递相同的参数,其输出也会发生变化。 例如,如果函数将对象作为参数,并且计算依赖于该对象的内部状态,则该函数将根据对象状态的变化返回不同的结果。 这在使用诸如 Python 和 C++ 之类的 OOP 中很常见。
那么,为什么要离题呢? 好吧,这是一个很好的时机,考虑我们自己的样本和 OpenCV 中使用的范例,以及它们与纯数学方法的区别。 在本书中,我们经常使用全局变量或带有成员变量的面向对象的类。 下一个程序是 OOP 的另一个示例。 OpenCV 也包含许多具有副作用的函数和许多面向对象的类。
例如,任何 OpenCV 绘图函数,例如cv2.rectangle或cv2.circle,都会修改我们作为参数传递给它的图像。 这种方法违反了 FP 的基本原则之一:避免副作用和状态变化。
作为简短的练习,让我们将cv2.rectangle包装在另一个 Python 函数中以 FP 样式执行绘图,而没有任何副作用。 以下实现依赖于复制输入图像,而不是修改原始图像:
def draw_rect(img, top_left, bottom_right, color,
thickness, fill=cv2.LINE_AA):
new_img = img.copy()
cv2.rectangle(new_img, top_left, bottom_right, color,
thickness, fill)
return new_img
这种方法-尽管由于copy操作而在计算上更加昂贵-但允许以下代码运行而没有副作用:
frame = camera.read()
frame_with_rect = draw_rect(
frame, (0, 0), (10, 10), (0, 255, 0), 1)
在这里,frame和frame_with_rect是对包含不同值的两个不同 NumPy 数组的引用。 如果我们使用cv2.rectangle而不是受 FP 启发的draw_rect包装器,则frame和frame_with_rect将被引用到一个相同的 NumPy 数组(在原始图像顶部包含一个矩形图) )。
总结一下这一题外话,请注意,各种编程语言和范例都可以成功地应用于计算机视觉问题。 了解多种语言和范例非常有用,这样您就可以为给定的工作选择正确的工具。
现在,让我们回到程序,探索监视应用的实现,跟踪视频中的移动对象。
实现Pedestrian类
卡尔曼过滤器的性质为创建Pedestrian类提供了主要原理。 卡尔曼过滤器可以基于历史观察来预测对象的位置,并且可以基于实际数据来校正预测,但是它只能对一个对象执行此操作。 因此,每个跟踪对象需要一个卡尔曼过滤器。
每个Pedestrian对象都将充当卡尔曼过滤器,彩色直方图(在对象的首次检测时计算并用作后续帧的参考)的支架,以及一个跟踪窗口,MeanShift 算法将使用该跟踪窗口。 此外,每个行人都有一个 ID,我们将显示该 ID,以便我们可以轻松地区分所有被跟踪的行人。 让我们依次完成该类的实现:
- 作为参数,
Pedestrian类的构造器采用 ID,HSV 格式的初始帧和初始跟踪窗口作为参数。 这是该类及其构造器的声明:
import cv2
import numpy as np
class Pedestrian():
"""A tracked pedestrian with a state including an ID, tracking
window, histogram, and Kalman filter.
"""
def __init__(self, id, hsv_frame, track_window):
- 为了开始构造器的实现,我们为 ID,跟踪窗口和 MeanShift 算法的终止条件定义变量:
self.id = id
self.track_window = track_window
self.term_crit = \
(cv2.TERM_CRITERIA_COUNT | cv2.TERM_CRITERIA_EPS, 10, 1)
- 我们通过在初始 HSV 图像中创建兴趣区域的标准化色相直方图来进行操作:
# Initialize the histogram.
x, y, w, h = track_window
roi = hsv_frame[y:y+h, x:x+w]
roi_hist = cv2.calcHist([roi], [0], None, [16], [0, 180])
self.roi_hist = cv2.normalize(roi_hist, roi_hist, 0, 255,
cv2.NORM_MINMAX)
- 然后,我们初始化卡尔曼过滤器:
# Initialize the Kalman filter.
self.kalman = cv2.KalmanFilter(4, 2)
self.kalman.measurementMatrix = np.array(
[[1, 0, 0, 0],
[0, 1, 0, 0]], np.float32)
self.kalman.transitionMatrix = np.array(
[[1, 0, 1, 0],
[0, 1, 0, 1],
[0, 0, 1, 0],
[0, 0, 0, 1]], np.float32)
self.kalman.processNoiseCov = np.array(
[[1, 0, 0, 0],
[0, 1, 0, 0],
[0, 0, 1, 0],
[0, 0, 0, 1]], np.float32) * 0.03
cx = x+w/2
cy = y+h/2
self.kalman.statePre = np.array(
[[cx], [cy], [0], [0]], np.float32)
self.kalman.statePost = np.array(
[[cx], [cy], [0], [0]], np.float32)
就像在我们的鼠标跟踪示例中一样,我们正在配置卡尔曼过滤器来预测 2D 点的运动。 作为初始点,我们使用初始跟踪窗口的中心。 这样就完成了构造器的实现。
Pedestrian类还具有update方法,我们将每帧调用一次。 作为参数,update方法采用 BGR 框架(在绘制跟踪结果的可视化时使用)和同一框架的 HSV 版本(用于直方图反投影)。update方法的实现从熟悉的直方图反投影和 MeanShift 代码开始,如以下几行所示:
def update(self, frame, hsv_frame):
back_proj = cv2.calcBackProject(
[hsv_frame], [0], self.roi_hist, [0, 180], 1)
ret, self.track_window = cv2.meanShift(
back_proj, self.track_window, self.term_crit)
x, y, w, h = self.track_window
center = np.array([x+w/2, y+h/2], np.float32)
- 请注意,我们要提取跟踪窗口的中心坐标,因为我们要对其进行卡尔曼滤波。 我们将继续执行此操作,然后更新跟踪窗口,使其以校正后的坐标为中心:
prediction = self.kalman.predict()
estimate = self.kalman.correct(center)
center_offset = estimate[:,0][:2] - center
self.track_window = (x + int(center_offset[0]),
y + int(center_offset[1]), w, h)
x, y, w, h = self.track_window
- 为了总结
update方法,我们将卡尔曼过滤器的预测绘制为蓝色圆圈,将校正后的跟踪窗口绘制为青色矩形,并将行人的 ID 绘制为矩形上方的蓝色文本:
# Draw the predicted center position as a circle.
cv2.circle(frame, (int(prediction[0]), int(prediction[1])),
4, (255, 0, 0), -1)
# Draw the corrected tracking window as a rectangle.
cv2.rectangle(frame, (x,y), (x+w, y+h), (255, 255, 0), 2)
# Draw the ID above the rectangle.
cv2.putText(frame, 'ID: %d' % self.id, (x, y-5),
cv2.FONT_HERSHEY_SIMPLEX, 0.6, (255, 0, 0),
1, cv2.LINE_AA)
这就是我们需要与单个行人关联的所有特征和数据。 接下来,我们需要实现一个程序,该程序提供创建和更新Pedestrian对象所需的视频帧。
实现main函数
现在我们有了Pedestrian类来维护有关每个行人跟踪的数据,让我们实现程序的main函数。 我们将依次查看实现的各个部分:
- 我们首先加载视频文件,初始化背景减法器,然后设置背景减法器的历史记录长度(即影响背景模型的帧数):
def main():
cap = cv2.VideoCapture('pedestrians.avi')
# Create the KNN background subtractor.
bg_subtractor = cv2.createBackgroundSubtractorKNN()
history_length = 20
bg_subtractor.setHistory(history_length)
- 然后,我们定义形态核:
erode_kernel = cv2.getStructuringElement(
cv2.MORPH_ELLIPSE, (3, 3))
dilate_kernel = cv2.getStructuringElement(
cv2.MORPH_ELLIPSE, (8, 3))
- 我们定义了一个名为
pedestrians的列表,该列表最初是空的。 稍后,我们将Pedestrian对象添加到此列表中。 我们还设置了一个帧计数器,用于确定是否经过了足够的帧以填充背景减法器的历史记录。 以下是变量的相关定义:
pedestrians = []
num_history_frames_populated = 0
- 现在,我们开始循环。 在每次迭代的开始,我们尝试读取视频帧。 如果失败(例如,在视频文件的末尾),则退出循环:
while True:
grabbed, frame = cap.read()
if (grabbed is False):
break
- 继续循环的主体,我们根据新捕获的帧更新背景减法器。 如果背景减法器的历史记录尚未满,我们将继续循环的下一个迭代。 以下是相关代码:
# Apply the KNN background subtractor.
fg_mask = bg_subtractor.apply(frame)
# Let the background subtractor build up a history.
if num_history_frames_populated < history_length:
num_history_frames_populated += 1
continue
- 一旦背景减法器的历史记录已满,我们将对每个新捕获的帧进行更多处理。 具体来说,我们采用与本章前面的背景减法器相同的方法:对前景遮罩执行阈值化,腐蚀和扩张; 然后我们检测轮廓,这些轮廓可能是移动的对象:
# Create the thresholded image.
_, thresh = cv2.threshold(fg_mask, 127, 255,
cv2.THRESH_BINARY)
cv2.erode(thresh, erode_kernel, thresh, iterations=2)
cv2.dilate(thresh, dilate_kernel, thresh, iterations=2)
# Detect contours in the thresholded image.
contours, hier = cv2.findContours(
thresh, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
- 我们还将帧转换为 HSV 格式,因为我们打算将这种格式的直方图用于 MeanShift。 下面的代码行执行转换:
hsv_frame = cv2.cvtColor(frame, cv2.COLOR_BGR2HSV)
- 一旦有了轮廓和框架的 HSV 版本,我们就可以检测和跟踪移动的对象了。 我们为每个轮廓找到并绘制一个边界矩形,该矩形足够大以适合行人。 而且,如果尚未填充
pedestrians列表,我们现在可以通过基于每个边界矩形(以及 HSV 图像的相应区域)添加一个新的Pedestrian对象来进行填充。 这是按照我们刚刚描述的方式处理轮廓的子循环:
# Draw rectangles around large contours.
# Also, if no pedestrians are being tracked yet, create some.
should_initialize_pedestrians = len(pedestrians) == 0
id = 0
for c in contours:
if cv2.contourArea(c) > 500:
(x, y, w, h) = cv2.boundingRect(c)
cv2.rectangle(frame, (x, y), (x+w, y+h),
(0, 255, 0), 1)
if should_initialize_pedestrians:
pedestrians.append(
Pedestrian(id, frame, hsv_frame,
(x, y, w, h)))
id += 1
- 现在,我们有了我们要跟踪的行人的列表。 我们将每个
Pedestrian对象的update方法都调用,将原始 BGR 帧(用于绘图)和 HSV 帧(用于借助 MeanShift 进行跟踪)传递给该方法。 请记住,每个Pedestrian对象都负责绘制自己的信息(文本,跟踪矩形和卡尔曼过滤器的预测)。 这是更新pedestrians列表的子循环:
# Update the tracking of each pedestrian.
for pedestrian in pedestrians:
pedestrian.update(frame, hsv_frame)
- 最后,我们在一个窗口中显示跟踪结果,并允许用户随时按
Esc键退出程序:
cv2.imshow('Pedestrians Tracked', frame)
k = cv2.waitKey(110)
if k == 27: # Escape
break
if __name__ == "__main__":
main()
在那里,您可以找到:MeanShift 与卡尔曼过滤器协同工作,以跟踪移动的对象。 一切顺利,您应该可以通过以下方式看到跟踪结果:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LMbaTOwF-1681871605267)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/learn-opencv4-cv-py3/img/818b8345-0248-4fc9-b694-f3c626f0e44e.png)]
在此裁剪的屏幕截图中,带有细边框的绿色矩形是检测到的轮廓,带有粗边框的青色矩形是经过卡尔曼校正的 MeanShift 跟踪矩形,而蓝点是由卡尔曼过滤器预测的中心位置。
像往常一样,随时尝试使用脚本。 您可能需要调整参数,尝试使用 MOG 背景减法器代替 KNN,或尝试使用 CamShift 代替 MeanShift。 这些更改应该只影响几行代码。 完成后,接下来,我们将考虑可能对脚本的结构产生更大影响的其他可能的修改。
考虑下一步
可以根据特定应用的需求以各种方式扩展和改进前面的程序。 请考虑以下示例:
- 如果卡尔曼过滤器预测行人的位置在框架之外,则可以从
pedestrians列表中删除Pedestrian对象(从而销毁Pedestrian对象)。 - 您可以检查每个检测到的移动对象是否对应于
pedestrians列表中的现有Pedestrian实例,如果不存在,则向列表中添加一个新对象,以便在后续帧中对其进行跟踪。 - 您可以训练支持向量机(SVM)并将其用于分类每个运动对象。 使用这些方法,您可以确定运动对象是否是您要跟踪的对象。 例如,一条狗可能会进入场景,但是您的应用可能只需要跟踪人类。 有关训练 SVM 的更多信息,请参阅第 7 章,“构建自定义对象检测器”。
无论您有什么需要,本章都希望为您提供构建满足您要求的 2D 跟踪应用所需的知识。
总结
本章介绍了视频分析,尤其是选择了一些有用的跟踪对象技术。
我们首先通过计算帧差异的基本运动检测技术来学习背景减法。 然后,我们继续使用 OpenCV 的cv2.BackgroundSubtractor类中实现的更复杂和有效的背景减法算法-MOG 和 KNN。
然后,我们继续探索 MeanShift 和 CamShift 跟踪算法。 在此过程中,我们讨论了颜色直方图和反投影。 我们还熟悉卡尔曼过滤器及其在平滑跟踪算法结果中的作用。 最后,我们将所有知识汇总到一个示例监视应用中,该应用能够跟踪视频中的行人(或其他移动物体)。
到目前为止,我们在 OpenCV,计算机视觉和机器学习方面的基础正在巩固。 在本书的其余两章中,我们可以期待几个高级主题。 我们将在第 9 章,“相机模型和增强现实”中扩展对 3D 空间的跟踪知识。 然后,我们将讨论人工神经网络(ANN),并在第 10 章“使用 OpenCV 的神经网络”中介绍,从而更深入地研究人工智能。
九、相机模型和增强现实
如果您喜欢几何图形,摄影或 3D 图形,那么本章的主题尤其适合您。 我们将学习 3D 空间和 2D 投影之间的关系。 我们将根据相机和镜头的基本光学参数对这种关系进行建模。 最后,我们将相同的关系应用于在精确的透视投影中绘制 3D 形状的任务。 在所有这些过程中,我们将整合我们之前在图像匹配和对象跟踪方面的知识,以便跟踪其真实世界对象的 3D 运动,该对象的 2D 投影由相机实时捕获。
在实践上,我们将构建一个增强现实应用,该应用使用有关相机,对象和运动的信息,以便将 3D 图形实时叠加在被跟踪对象的顶部。 为此,我们将克服以下技术挑战:
- 建模相机和镜头的参数
- 使用 2D 和 3D 关键点建模 3D 对象
- 通过匹配的关键点来检测对象
- 使用
cv2.solvePnPRansac函数查找对象的 3D 姿势 - 使用卡尔曼过滤器平滑 3D 姿势
- 在对象上方绘制图形
在本章的过程中,如果您继续构建自己的增强现实引擎或任何其他依赖 3D 跟踪的系统(例如机器人导航系统),则将获得对您有用的技能。
技术要求
本章使用 Python,OpenCV 和 NumPy。 请返回第 1 章,“设置 OpenCV”,了解安装说明。
本章的完整代码和示例视频可以在本书的 GitHub 存储库中找到,位于chapter09文件夹中。
本章代码包含摘自 Joseph Howse(本书作者之一)称为“可视化不可见”的开源演示项目的摘录。 要了解有关此项目的更多信息,请访问这个页面中的资源库。
了解 3D 图像跟踪和增强现实
我们已经在第 6 章,“检索图像并使用图像描述符搜索”中解决了图像匹配问题。 此外,我们在第 8 章,“跟踪对象”中解决了涉及连续跟踪的问题。 因此,尽管我们尚未解决任何 3D 跟踪问题,但我们熟悉图像跟踪系统的许多组件。
那么,3D 跟踪到底是什么? 嗯,这是一个不断更新 3D 空间中对象姿态估计值的过程,通常使用六个变量:三个变量来表示对象的 3D 平移(即位置),以及其他三个变量代表其 3D 旋转。
3D 跟踪的一个更专业的术语是 6DOF 跟踪 –也就是说,使用 6 个自由度的跟踪,即我们刚才提到的 6 个变量。
有 3 种方式将 3D 旋转表示为三个变量。 在其他地方,您可能会遇到各种各样的欧拉角表示形式,它们以围绕x,y和z的三个单独的 2D 旋转来描述 3D 旋转。 ]轴按特定顺序排列。 OpenCV 不使用欧拉角来表示 3D 旋转。 相反,它使用称为 Rodrigues 旋转向量的表示形式。 具体来说,OpenCV 使用以下六个变量来表示 6DOF 姿态:
t[x]:这是对象沿x轴的平移。t[y]:这是对象沿y轴的平移。t[z]:这是对象沿z轴的平移。r[x]:这是对象 Rodrigues 旋转向量的第一个元素。r[y]:这是对象 Rodrigues 旋转向量的第二个元素。r[z]:这是对象 Rodrigues 旋转向量的第三个元素。
不幸的是,在 Rodrigues 表示中,没有简单的方法来解释r[x],r[y]和r[z]彼此分开。 总之,它们作为向量r编码旋转轴和围绕该轴的旋转角。 具体来说,以下公式定义了r向量之间的关系; 角度θ,归一化的轴向量,r̂; 和3 x 3旋转矩阵R:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ts3o06xK-1681871605268)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/learn-opencv4-cv-py3/img/195c32cf-e876-419e-bd2e-db6f9f92cbf3.png)]
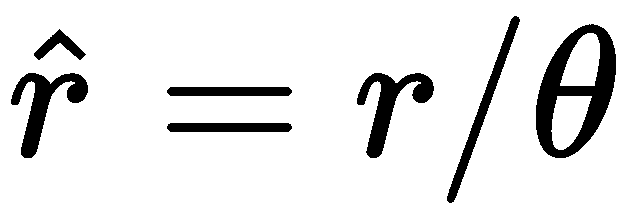
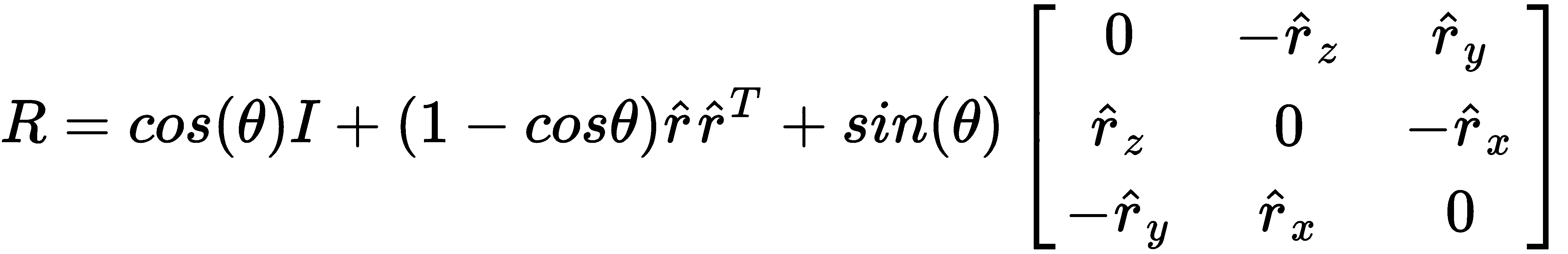
作为 OpenCV 程序员,我们没有义务直接计算或解释任何这些变量。 OpenCV 提供了将 Rodrigues 旋转向量作为返回值的函数,我们可以将此旋转向量作为参数传递给其他 OpenCV 函数-无需自己操纵其内容。
出于我们的目的(实际上,对于计算机视觉中的许多问题),相机是 3D 坐标系的原点。 因此,在任何给定的帧中,摄像机的当前t[x],t[y],t[z],r[x],r[y]和r[z]值均定义为 0。我们将努力跟踪相对于相机当前姿势的其他对象。
当然,为了便于讲授,我们将可视化 3D 跟踪结果。 这将我们带入增强现实(AR)的领域。 广义上讲,AR 是一种持续跟踪现实世界对象之间的关系并将这些关系应用于虚拟对象的过程,以这种方式,用户可以将虚拟对象视为固定在现实世界中的某物上。 通常,视觉 AR 基于 3D 空间和透视投影的关系。 确实,我们的情况很典型。 我们希望通过在框架中跟踪的对象上方绘制一些 3D 图形的投影来可视化 3D 跟踪结果。
稍后,我们将回到透视投影的概念。 同时,让我们概述一下 3D 图像跟踪和可视 AR 的一组典型步骤:
- 定义相机和镜头的参数。 我们将在本章中介绍该主题。
- 初始化我们将用于稳定 6DOF 跟踪结果的卡尔曼过滤器。 有关卡尔曼滤波的更多信息,请参考第 8 章,“跟踪对象”。
- 选择一个参考图像,代表我们要跟踪的对象的表面。 对于我们的演示,对象将是一个平面,例如一张打印图像的纸。
- 创建一个 3D 点列表,代表对象的顶点。 坐标可以是任何单位,例如米,毫米或任意单位。 例如,您可以任意定义 1 个单位以等于对象的高度。
- 从参考图像中提取特征描述符。 对于 3D 跟踪应用,ORB 是描述符的一种流行选择,因为它甚至可以在智能手机等适度的硬件上实时进行计算。 我们的演示将使用 ORB。 有关 ORB 的更多信息,请参考第 6 章,“检索图像并使用图像描述符搜索”。
- 使用与“步骤 4”中相同的映射,将特征描述符从像素坐标转换为 3D 坐标。
- 开始从相机捕获帧。 对于每个帧,执行以下步骤:
- 提取特征描述符,并尝试在参考图像和框架之间找到良好的匹配。 我们的演示将使用基于 FLANN 的匹配和比率测试。 有关这些用于匹配描述符的方法的更多信息,请参考第 6 章,“检索图像并使用图像描述符搜索”。
- 如果找到的匹配次数不足,请继续下一帧。 否则,请继续执行其余步骤。
在继续演示代码之前,让我们进一步讨论此概述的两个方面:第一,相机和镜头的参数;第二,相机和镜头的参数。 第二,神秘函数cv2.solvePnPRansac的作用。
了解相机和镜头参数
通常,当我们捕获图像时,至少涉及三个对象:
- 主题是我们要在图像中捕获的东西。 通常,它是一个反射光的对象,我们希望该对象在图像中聚焦(清晰)。
- 透镜透射光,并将所有来自焦平面的反射光聚焦到像平面上。 焦平面是包括主体(如先前定义)的圆形空间切片。 图像平面是一个圆形的空间切片,其中包含图像传感器(稍后定义)。 通常,这些平面垂直于镜头的主轴(长度方向)。 镜头具有光学中心,这是来自焦平面的入射光在聚光回像平面之前会聚的点。 焦距(即,光学中心与焦平面之间的距离)根据光学中心与像平面之间的距离而变化。 如果我们将光学中心移近图像平面,则焦距会增加; 相反,如果我们将光学中心移离图像平面更远,则焦距会减小(通常,在相机系统中,通过简单地前后移动镜头的机制来调整焦点)。 焦距定义为当焦距为无穷远时光学中心与像平面之间的距离。
- 图像传感器是一种感光表面,可在模拟介质(例如胶片)或数字介质中接收光并将其记录为图像。 通常,图像传感器是矩形的。 因此,它不会覆盖圆形图像平面的角。 图像的对角线视场(FOV:要成像的 3D 空间的角度范围)与焦距,图像传感器的宽度和图像传感器的高度具有三角关系 。 我们将尽快探讨这种关系。
这是说明上述定义的图:
对于计算机视觉,我们通常使用固定焦距的镜头,这对于给定的应用是最佳的。 但是,镜头可以具有可变的焦距。 这种镜头称为变焦镜头。 放大意味着增加焦距,而缩小意味着减少焦距。 在机械上,变焦镜头通过移动镜头内部的光学元件来实现此目的。
让我们使用变量f表示焦距,然后使用变量(c[x],c[y])代表图像传感器在图像平面内的中心点。 OpenCV 使用以下矩阵,称为摄像机矩阵,表示摄像机和镜头的基本参数:
f | 0 | c[x] |
| 0 | f | c[y] |
| 0 | 0 | 1 |
假设图像传感器在图像平面中居中(通常应该如此),我们可以计算出c[x]和c[y],具体取决于图像传感器的宽度w和高度h,如下所示:
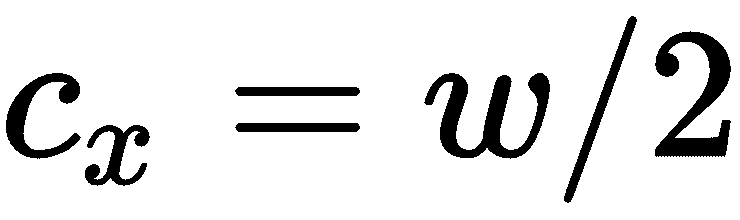
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qVbOC07e-1681871605269)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/learn-opencv4-cv-py3/img/1f51d1cf-fedc-4d5e-8532-cfb3b4acfb34.png)]
如果我们知道对角 FOV θ,则可以使用以下三角公式来计算焦距:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-eWmauJli-1681871605269)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/learn-opencv4-cv-py3/img/47c9fc57-a965-4d7a-9597-8866328e6e28.png)]
或者,如果我们不知道对角 FOV,但是我们知道水平 FOV ɸ和垂直 FOV ψ,则可以如下计算焦距:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-W1cp7gUi-1681871605269)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/learn-opencv4-cv-py3/img/7b1d78be-2fb1-4cc4-84e7-784a6b8f9db6.png)]
您可能想知道我们如何获取这些变量中任何一个的值作为起点。 有时,相机或镜头的制造商会在产品的规格表中提供有关传感器尺寸,焦距或 FOV 的数据。 例如,规格表可能以毫米为单位列出传感器尺寸和焦距,以度为单位列出 FOV。 但是,如果规格表的信息不足,我们还有其他方法来获取必要的数据。 重要的是,传感器的大小和焦距无需以实际单位(例如毫米)表示。 我们可以用任意单位表示它们,例如像素等效单位。
您可能会问,什么是像素等效单位? 好吧,当我们从相机捕获一帧时,图像中的每个像素对应于图像传感器的某个区域,并且该区域具有真实世界的宽度(和真实世界的高度,通常与宽度相同) )。 因此,如果我们要捕获分辨率为1280 x 720的帧,则可以说图像传感器的宽度w为 1280 个像素当量单位,高度为h, 是 720 像素等效单位。 这些单元无法在不同的实际传感器尺寸或分辨率下进行比较。 但是,对于给定的摄像机和分辨率,它们使我们能够进行内部一致的测量,而无需知道这些测量的实际规模。
这个技巧使我们能够为任何图像传感器定义w和h(因为我们始终可以检查捕获帧的像素尺寸)。 现在,为了能够计算焦距,我们只需要另一种数据类型:FOV。 我们可以使用一个简单的实验来测量。 拿一张纸并将其粘贴到墙壁(或另一个垂直表面)上。 放置相机和镜头,使其直接面对纸张,并且纸张对角填充框架。 (如果纸张的纵横比与框架的纵横比不匹配,请裁切纸张以使其匹配。)测量从纸张的一个角到对角线对角的对角线大小s。 此外,测量从纸张到镜头镜筒下半点的距离d。 然后,通过三角法计算对角 FOV θ:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vUYr4Psd-1681871605269)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/learn-opencv4-cv-py3/img/7f285e25-ea97-444c-bec6-e968b4b1154f.png)]
假设通过该实验,我们确定给定的相机和镜头的对角 FOV 为 70 度。 如果我们知道以1280 x 720的分辨率捕获帧,则可以按像素等效单位计算焦距,如下所示:
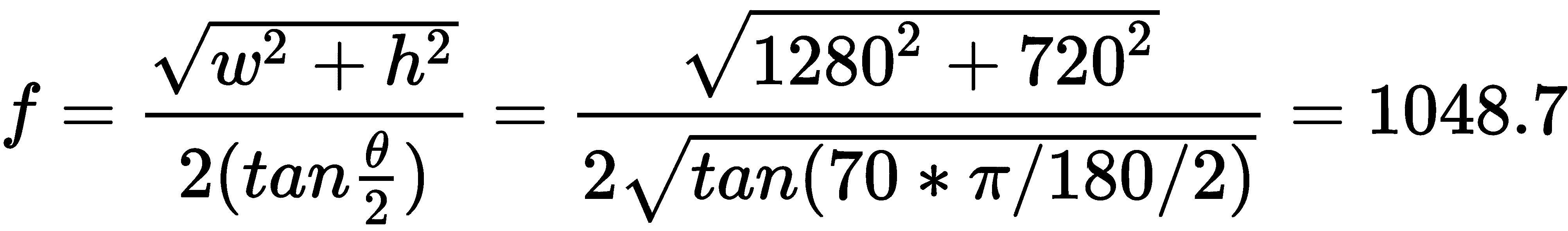
除此之外,我们还可以计算图像传感器的中心坐标:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PYI7kpCP-1681871605270)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/learn-opencv4-cv-py3/img/a223d627-103a-4141-a05c-0b759e70b4f9.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-k6T7Apf9-1681871605270)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/learn-opencv4-cv-py3/img/321cf98a-fcbf-44a8-b826-5a24c71f15f9.png)]
因此,我们有以下相机矩阵:
| 1048.7 | 0 | 640 |
| 0 | 1048.7 | 360 |
| 0 | 0 | 1 |
前面的参数对于 3D跟踪是必需的,它们正确地代表了理想的相机和镜头。 但是,实际设备可能会明显偏离此理想状态,并且仅相机矩阵无法代表所有可能的偏差类型。 失真系数是一组附加参数,可以表示与理想模型的以下几种偏差:
- 径向畸变:这意味着镜头无法平等地放大图像的所有部分; 因此,它会使直边显得弯曲或波浪状。 对于径向失真系数,使用诸如
k[n]等变量名(例如通常使用k[1],k[2],k[3]等)。 如果k[1] < 0,则通常表示镜头遭受镜筒变形的影响,这意味着直边似乎朝着镜框的边界向外弯曲。 图片。 相反,k[1] > 0通常表示镜头遭受枕形畸变,这意味着直边似乎向内向图像中心弯曲。 如果符号在整个系列中交替出现(例如k[1] > 0,k[2] < 0和k[3] > 0),这可能意味着镜头遭受了胡子变形的困扰,这意味着笔直的边缘显得波浪状。 - 切向失真:这意味着镜头的主轴(长度方向)不垂直于图像传感器; 因此,透视图是倾斜的,直线边缘之间的角度似乎不同于正常透视图投影中的角度。 对于切向失真系数,使用变量名称,例如
p[n](例如,通常使用p[1],p[2]等)。 系数的符号取决于镜头相对于图像传感器的倾斜方向。
下图说明了某些类型的径向变形:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qF3gjM4W-1681871605270)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/learn-opencv4-cv-py3/img/e9873543-c06a-427e-adbe-3307ca26f8f5.png)]
OpenCV 提供的功能可处理多达五个失真系数:k[1],k[2],p[1],p[2]和k[3]。 (OpenCV 期望它们以此顺序作为数组的元素。)很少地,您可能能够从相机或镜头供应商那里获得有关畸变系数的官方数据。 另外,您可以使用 OpenCV 的棋盘校准过程来估计失真系数以及相机矩阵。 这涉及从各种位置和角度捕获一系列印刷棋盘图案的图像。 有关更多详细信息,请参考官方教程。
出于演示目的,我们将简单假设所有失真系数均为 0,这意味着没有失真。 当然,我们并不真正相信我们的网络摄像头是光学工程中的无畸变杰作。 我们只是认为失真还不足以明显影响我们的 3D 跟踪和 AR 演示。 如果我们试图构建一个精确的测量设备而不是视觉演示,那么我们将更加关注失真的影响。
与棋盘校准过程相比,我们在本节中概述的公式和假设产生了更为受限或理想的模型。 但是,我们的方法具有更简单,更容易重现的优点。 棋盘校准过程比较费力,每个用户可能会以不同的方式执行它,从而产生不同的(有时是错误的)结果。
吸收了有关相机和镜头参数的背景信息之后,现在让我们检查一个 OpenCV 函数,该函数使用这些参数作为 6DOF 跟踪问题解决方案的一部分。
了解cv2.solvePnPRansac
cv2.solvePnPRansac函数为所谓的n点透视(PnP)问题实现了求解器。 给定 3D 和 2D 点之间的一组n唯一匹配,以及生成此 3D 点 2D 投影的相机和镜头的参数,求解器将尝试估计 3D 对象相对于相机的 6DOF 姿态。 这个问题有点类似于寻找一组 2D 到 2D 关键点匹配的单应性,就像我们在第 6 章“检索图像并使用图像描述符搜索”中所做的那样。 但是,在 PnP 问题中,我们有足够的其他信息来估计更具体的空间关系(自由度姿势),而不是单应性,后者只是告诉我们一种投影关系。
那么cv2.solvePnPRansac如何工作? 顾名思义,该函数实现了 Ransac 算法,这是一种通用的迭代方法,旨在处理可能包含异常值(在我们的情况下为不匹配)的一组输入。 每次 Ransac 迭代都会找到一个潜在的解决方案,该解决方案可最大程度地减少对输入的平均误差的度量。 然后,在下一次迭代之前,将具有不可接受的大误差的所有输入标记为离群值并丢弃。 此过程一直持续到解收敛为止,这意味着没有发现新的异常值,并且平均误差也可以接受。
对于 PnP 问题,误差是根据重投影误差来衡量的,这意味着根据相机和镜头参数观察到的 2D 点的位置与预测位置之间的距离以及我们得出的 6DOF 姿态,目前正在考虑它作为潜在的解决方案。 在过程的最后,我们希望获得与大多数 3D 到 2D 关键点匹配一致的 6DOF 姿势。 此外,我们想知道该解决方案的匹配项是哪些。
让我们考虑cv2.solvePnPRansac的函数签名:
retval, rvec, tvec, inliers = cv.solvePnPRansac(
objectPoints,
imagePoints,
cameraMatrix,
distCoeffs,
rvec=None,
tvec=None,
useExtrinsicGuess=False
iterationsCount=100,
reprojectionError=8.0,
confidence=0.98,
inliers=None,
flags=cv2.SOLVEPNP_ITERATIVE)
如我们所见,该函数具有四个返回值:
retval:如果求解器收敛于一个解,则为True; 否则为False。rvec:此数组包含r[x],r[y]和r[z]– 6DOF 姿态中的三个旋转自由度。tvec:此数组包含t[x],t[y]和t[z]– 6DOF 姿态中的三个平移(位置)自由度。inliers:如果求解器收敛于一个解,则此向量包含与该解一致的输入点的索引(在objectPoints和imagePoints中)。
该函数还具有 12 个参数:
objectPoints:这是 3D 点的数组,表示没有平移和旋转时(换句话说,当 6DOF 姿态变量都为 0 时)对象的关键点。imagePoints:这是 2D 点的数组,代表图像中对象的关键点匹配。 具体而言,认为imagePoints[i]与objectPoints[i]匹配。cameraMatrix:此 2D 数组是相机矩阵,我们可以按照前面的“了解相机和镜头参数”部分中介绍的方式导出。distCoeffs:这是失真系数的数组。 如果我们不知道它们,可以(为简单起见)假定它们全为 0,如上一节所述。rvec:如果求解器收敛于一个解,它将把解的r[x],r[y]和r[z]此数组中的值。tvec:如果求解器收敛于一个解,它将把解的t[x],t[y]和t[z]值在此数组中。useExtrinsicGuess:如果这是True,则求解器会将rvec和tvec参数中的值视为初始猜测,然后尝试找到与这些近似的解决方案。 否则,求解器将在搜索解决方案时采取不偏不倚的方法。iterationsCount:这是求解器应尝试的最大迭代次数。 如果经过此迭代次数后仍未收敛于解决方案,则放弃。reprojectionError:这是求解器将接受的最大重投影误差; 如果某个点的重投影误差大于此误差,则求解器会将其视为异常值。confidence:求解器尝试收敛于置信度得分大于或等于此值的解决方案。inliers:如果求解器收敛于一个解,则它将解的内点的索引放入此数组中。flags:这些标志指定求解器的算法。 默认值cv2.SOLVEPNP_ITERATIVE是使重投影误差最小并且没有特殊限制的方法,因此通常是最佳选择。 一个有用的替代方法是cv2.SOLVEPNP_IPPE(IPPE,是基于无限小平面的姿势估计的缩写),但它仅限于平面对象。
尽管此函数涉及很多变量,但我们会发现它的使用是对第 6 章,“检索图像和使用图像描述符搜索”的关键点匹配问题的自然扩展。 ,以及本章要介绍的 3D 和投影问题。 考虑到这一点,让我们开始探索本章的示例代码。
实现演示应用
我们将在单个脚本ImageTrackingDemo.py中实现我们的演示,该脚本将包含以下组件:
- 导入语句
- 用于自定义灰度转换的辅助函数
- 辅助函数可将关键点从 2D 空间转换为 3D 空间
- 应用类
ImageTrackingDemo,它将封装相机和镜头的模型,参考图像的模型,卡尔曼过滤器,6DOF 跟踪结果,以及将跟踪图像并绘制简单的 AR 可视化效果的应用循环 main函数启动应用
该脚本将依赖于另一个文件reference_image.png,它将代表我们要跟踪的图像。
事不宜迟,让我们深入研究脚本的实现。
导入模块
在 Python 标准库中,我们将使用math模块进行三角计算,并使用timeit模块进行精确的时间测量(这将使我们能够更有效地使用卡尔曼过滤器)。 和往常一样,我们还将使用 NumPy 和 OpenCV。 因此,我们对ImageTrackingDemo.py的实现始于以下import语句:
import math
import timeit
import cv2
import numpy
现在,让我们继续执行辅助函数。
执行灰度转换
在本书中,我们使用以下代码执行了灰度转换:
gray_img = cv2.cvtColor(bgr_img, cv2.COLOR_BGR2GRAY)
也许早就应该提出一个问题:此函数如何将 BGR 值准确映射到灰度值? 答案是每个输出像素的灰度值都是相应输入像素的 B,G 和 R 值的加权平均值,如下所示:
gray = (0.114 * blue) + (0.587 * green) + (0.299 * red)
这些砝码被广泛使用。 它们来自于 1982 年发布的称为 CCIR 601 的电信行业标准。 当我们看到明亮的场景时,我们的眼睛对黄绿色光线最为敏感。 此外,这些配重应该在带有淡黄色灯光和带蓝色阴影的场景(例如晴天的室外场景)中产生高对比度。 这些是我们使用 CCIR 601 砝码的充分理由吗? 不,他们不是; 没有科学证据表明 CCIR 601 转换权重可为计算机视觉中的任何特定目的提供最佳的灰度输入。
实际上,出于图像跟踪的目的,有证据支持其他灰度转换算法。 SamuelMacêdo,GivânioMelo 和 Judith Kelner 在他们的论文中谈到了这个主题,《针对应用于 SIFT 描述符的灰度转换技术的比较研究》(SBC 交互式系统杂志,第 6 卷,第 2 期,2015 年) 。 他们测试各种转换算法,包括以下类型:
- 加权平均转换
gray = (0.07 * blue) + (0.71 * green) + (0.21 * red),与 CCIR 601 有点相似 - 非加权平均转换
gray = (blue + green + red) / 3 - 仅基于单个颜色通道的转换,例如
gray = green - 经过伽玛校正的转换,例如
gray = 255 * (green / 255) ^ (1/2.2),其中,灰度值随输入呈指数(非线性)变化
根据该论文,加权平均转换产生的结果相对不稳定-有利于找到某些图像的匹配和单应性,而对于其他图像则不好。 非加权平均转换和单通道转换产生更一致的结果。 对于某些图像,经伽玛校正的转换可产生最佳结果,但这些转换在计算上更加昂贵。
为了演示的目的,我们将通过获取每个像素的 B,G 和 R 值的简单(未加权)平均值来执行灰度转换。 这种方法在计算上很便宜(在实时跟踪中很理想),并且我们期望它比 OpenCV 中的默认加权平均转换带来更一致的跟踪结果。 这是我们用于执行自定义转换的辅助函数的实现:
def convert_to_gray(src, dst=None):
weight = 1.0 / 3.0
m = numpy.array([[weight, weight, weight]], numpy.float32)
return cv2.transform(src, m, dst)
注意cv2.transform函数的使用。 这是 OpenCV 提供的经过优化的通用矩阵转换函数。 我们可以使用它来执行以下操作:像素输出通道的值是输入通道值的线性组合。 在我们的 BGR 到灰度转换的情况下,我们有一个输出通道和三个输入通道,因此我们的转换矩阵m有一行三列。
编写了用于灰度转换的辅助函数后,让我们继续考虑用于从 2D 到 3D 空间转换的辅助函数。
执行 2D 到 3D 空间的转换
请记住,我们有一个参考图像reference_image.png,并且我们希望 AR 应用跟踪该图像的打印副本。 出于 3D 跟踪的目的,我们可以将此打印图像表示为 3D 空间中的平面。 让我们定义局部坐标系的方式是,通常(当 6DOF 姿势的元素全部为 0 时),此平面对象像悬挂在墙上的图片一样竖立; 它的正面是上面有图像的一侧,其原点是图像的中心。
现在,让我们假设我们想将参考图像中的给定像素映射到此 3D 平面上。 给定 2D 像素坐标,图像的像素尺寸以及将像素转换为我们要在 3D 空间中使用的度量单位的比例因子,我们可以使用以下辅助函数将像素映射到平面上:
def map_point_onto_plane(point_2D, image_size, image_scale):
x, y = point_2D
w, h = image_size
return (image_scale * (x - 0.5 * w),
image_scale * (y - 0.5 * h),
0.0)
比例因子取决于打印图像的实际大小和我们选择的单位。 例如,我们可能知道我们的打印图像高 20 厘米–或我们可能不在乎绝对比例,在这种情况下,我们可以定义一个任意单位,以使打印图像高一个单位。 无论如何,只要以任何单位(绝对或相对)给出 2D 像素坐标,参考图像的尺寸以及参考图像的实际高度的列表,我们就可以使用以下帮助器函数在列表上获取相应 3D 坐标的列表。 飞机:
def map_points_to_plane(points_2D, image_size, image_real_height):
w, h = image_size
image_scale = image_real_height / h
points_3D = [map_point_onto_plane(
point_2D, image_size, image_scale)
for point_2D in points_2D]
return numpy.array(points_3D, numpy.float32)
请注意,我们为多个点map_points_to_plane提供了一个辅助函数,并且为每个点map_point_to_plane都调用了一个辅助函数。
稍后,在“初始化跟踪器”部分中,我们将为参考图像生成 ORB 关键点描述符,并且我们将使用我们的map_points_to_plane辅助函数将关键点坐标从 2D 转换为 3D。 我们还将转换图像的四个 2D 顶点(即其左上角,右上角,右下角和左下角),以获得平面的四个 3D 顶点。 在执行 AR 绘制时,我们将使用这些顶点-特别是在“绘制跟踪结果”部分中。 与绘图相关的功能(在 OpenCV 和许多其他框架中)期望为 3D 形状的每个面按顺时针顺序(从正面角度)指定顶点。 为了满足此要求,让我们实现另一个专用于映射顶点的辅助函数。 这里是:
def map_vertices_to_plane(image_size, image_real_height):
w, h = image_size
vertices_2D = [(0, 0), (w, 0), (w, h), (0, h)]
vertex_indices_by_face = [[0, 1, 2, 3]]
vertices_3D = map_points_to_plane(
vertices_2D, image_size, image_real_height)
return vertices_3D, vertex_indices_by_face
请注意,我们的顶点映射帮助函数map_vertices_to_plane调用了map_points_to_plane帮助函数,该函数又调用了map_point_to_plane。 因此,我们所有的映射函数都有一个共同的核心。
当然,除了平面外,2D 到 3D 关键点映射和顶点映射也可以应用于其他 3D 形状。 若要了解我们的方法如何扩展到 3D 长方体和 3D 圆柱体,请参阅 Joseph Howse 的《可视化不可视》demo 项目,该项目可在这个页面。
我们已经完成了辅助函数的实现。 现在,让我们继续进行代码的面向对象部分。
实现应用类
我们将在名为ImageTrackingDemo的类中实现我们的应用,该类将具有以下方法:
__init__(self, capture, diagonal_fov_degrees, target_fps, reference_image_path, reference_image_real_height):初始化器将为参考图像设置捕获设备,相机矩阵,卡尔曼过滤器以及 2D 和 3D 关键点。run(self):此方法将运行应用的主循环,该循环捕获,处理和显示帧,直到用户通过按Esc键退出。 在其他方法的帮助下执行每个帧的处理,这些方法将在此列表中接下来提到。_track_object(self):此方法将执行 6DOF 跟踪并绘制跟踪结果的 AR 可视化图像。_init_kalman_transition_matrix(self, fps):此方法将配置卡尔曼过滤器,以确保针对指定的帧速率正确模拟加速度和速度。_apply_kalman(self):此方法将通过应用卡尔曼过滤器来稳定 6DOF 跟踪结果。
让我们从__init__开始一步一步地介绍方法的实现。
初始化追踪器
__init__方法涉及许多步骤来初始化相机矩阵,ORB 描述符提取器,卡尔曼过滤器,参考图像的 2D 和 3D 关键点以及与我们的跟踪算法相关的其他变量:
- 首先,让我们看一下
__init__接受的参数。 其中包括一个称为capture的cv2.VideoCapture对象(相机); 摄像机的对角 FOV,以度为单位; 每秒帧(FPS)中的预期帧速率; 包含参考图像的文件的路径; 以及参考图像实际高度的度量(以任何单位):
class ImageTrackingDemo():
def __init__(self, capture, diagonal_fov_degrees=70.0,
target_fps=25.0,
reference_image_path='reference_image.png',
reference_image_real_height=1.0):
- 我们尝试从相机捕获一帧以确定其像素尺寸。 否则,我们将从相机的属性中获取尺寸:
self._capture = capture
success, trial_image = capture.read()
if success:
# Use the actual image dimensions.
h, w = trial_image.shape[:2]
else:
# Use the nominal image dimensions.
w = capture.get(cv2.CAP_PROP_FRAME_WIDTH)
h = capture.get(cv2.CAP_PROP_FRAME_HEIGHT)
self._image_size = (w, h)
- 现在,给定帧的尺寸(以像素为单位)以及相机和镜头的 FOV,我们可以使用三角函数以像素等效单位计算焦距。 (该公式是我们在本章前面的“了解相机和镜头参数”部分中得出的公式。)此外,利用焦距和镜框的中心点,我们可以构建相机矩阵。 以下是相关代码:
diagonal_image_size = (w ** 2.0 + h ** 2.0) ** 0.5
diagonal_fov_radians = \
diagonal_fov_degrees * math.pi / 180.0
focal_length = 0.5 * diagonal_image_size / math.tan(
0.5 * diagonal_fov_radians)
self._camera_matrix = numpy.array(
[[focal_length, 0.0, 0.5 * w],
[0.0, focal_length, 0.5 * h],
[0.0, 0.0, 1.0]], numpy.float32)
- 为了简单起见,我们假定镜头不会遭受任何扭曲:
self._distortion_coefficients = None
- 最初,我们不跟踪对象,因此我们无法估计其旋转和位置。 我们只将相关变量定义为
None:
self._rotation_vector = None
self._translation_vector = None
- 现在,让我们设置一个卡尔曼过滤器:
self._kalman = cv2.KalmanFilter(18, 6)
self._kalman.processNoiseCov = numpy.identity(
18, numpy.float32) * 1e-5
self._kalman.measurementNoiseCov = numpy.identity(
6, numpy.float32) * 1e-2
self._kalman.errorCovPost = numpy.identity(
18, numpy.float32)
self._kalman.measurementMatrix = numpy.array(
[[1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0,
0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0],
[0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0,
0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0],
[0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0,
0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0],
[0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0,
1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0],
[0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0,
0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0],
[0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0,
0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0]],
numpy.float32)
self._init_kalman_transition_matrix(target_fps)
如前面的代码cv2.KalmanFilter(18, 6)所示,该卡尔曼过滤器将基于 6 个输入变量(或测量值)跟踪 18 个输出变量(或预测)。 具体来说,输入变量是 6DOF 跟踪结果的元素:t[x],t[y],t[z],r[x],r[y]和r[z]。 输出变量是稳定的 6DOF 跟踪结果的元素,以及它们的一阶导数(速度)和二阶导数(加速度),其顺序如下:t[x],t[y],t[z], t[x]',t[y]',t[z]',t[x]',t[y]',t[z]',r[x],r[y],r[z],r[x]',r[y]',r[z]',r[x]',r[y]'和r[z]'。 卡尔曼过滤器的测量矩阵有 18 列(代表输出变量)和 6 行(代表输入变量)。 在每一行中,我们在与匹配的输出变量相对应的索引中放入 1.0; 在其他地方,我们放 0.0。 我们还初始化了一个转换矩阵,该矩阵定义了输出变量之间随时间的关系。 初始化的这一部分由辅助方法_init_kalman_transition_matrix(target_fps)处理,我们将在稍后的“初始化和应用卡尔曼过滤器”部分中进行检查。
并非我们的__init__方法都会初始化所有的卡尔曼过滤器矩阵。 由于实际帧速率(以及时间步长)可能会发生变化,因此在跟踪过程中每帧更新过渡矩阵。 每次我们开始跟踪对象时,都会初始化状态矩阵。 我们将在适当的时候在“初始化和应用卡尔曼过滤器”部分中介绍卡尔曼过滤器使用的这些方面。
- 我们需要一个布尔变量(最初是
False)来指示我们是否成功跟踪了前一帧中的对象:
self._was_tracking = False
- 我们需要定义一些 3D 图形的顶点,作为 AR 可视化的一部分,我们将绘制每一帧。 具体而言,图形将是代表对象的
X,Y和Z轴的一组箭头。 这些图形的比例将与实际对象的比例有关,即我们要跟踪的打印图像。 请记住,作为其参数之一,__init__方法采用图像的比例尺-特别是其高度-并且此度量单位可以是任何单位。 让我们将 3D 轴箭头的长度定义为打印图像高度的一半:
self._reference_image_real_height = \
reference_image_real_height
reference_axis_length = 0.5 * reference_image_real_height
- 使用我们刚刚定义的长度,让我们定义相对于打印图像中心
[0.0, 0.0, 0.0]的轴箭头的顶点:
self._reference_axis_points_3D = numpy.array(
[[0.0, 0.0, 0.0],
[-reference_axis_length, 0.0, 0.0],
[0.0, -reference_axis_length, 0.0],
[0.0, 0.0, -reference_axis_length]], numpy.float32)
请注意,OpenCV 的坐标系具有非标准轴方向,如下所示:
X(正 X 方向)是对象的左手方向,或者是在对象正视图中查看者的右手方向。Y是向下。Z是对象的后向方向,即在对象的正面视图中观察者的向前方向。
为了获得以下标准右手坐标系,我们必须取反所有上述方向,就像在许多 3D 图形框架(例如 OpenGL)中使用的那样:
X是对象正面的方向,即观看者的左手方向。Y是向上。Z是对象的正面方向,或者是查看者在对象的正面视图中的向后方向。
出于本书的目的,我们使用 OpenCV 绘制 3D 图形,因此即使在绘制可视化效果时,我们也可以简单地遵循 OpenCV 的非标准轴方向。 但是,如果将来要进行进一步的 AR 工作,则可能需要使用右手坐标系将计算机视觉代码与 OpenGL 和其他 3D 图形框架集成在一起。 为了更好地为您做好准备,我们将在以 OpenCV 为中心的演示中转换轴方向。
- 我们将使用三个数组来保存三种图像:BGR 视频帧(将在其中进行 AR 绘制),帧的灰度版本(将用于关键点匹配)和遮罩(在其中进行绘制) 被跟踪对象的轮廓)。 最初,这些数组都是
None:
self._bgr_image = None
self._gray_image = None
self._mask = None
- 我们将使用
cv2.ORB对象来检测关键点,并为参考图像以及随后的相机帧计算描述符。 我们按以下方式初始化cv2.ORB对象:
# Create and configure the feature detector.
patchSize = 31
self._feature_detector = cv2.ORB_create(
nfeatures=250, scaleFactor=1.2, nlevels=16,
edgeThreshold=patchSize, patchSize=patchSize)
有关 ORB 算法及其在 OpenCV 中的用法的更新,请参考第 6 章,“检索图像并使用图像描述符进行搜索”,特别是“将 ORB 与 FAST 特征和 BERIEF 描述符一起使用”部分。
在这里,我们为cv2.ORB的构造器指定了几个可选参数。 描述符覆盖的直径为 31 个像素,我们的图像金字塔有 16 个级别,连续级别之间的缩放系数为 1.2,并且每次检测尝试最多需要 250 个关键点和描述符。
- 现在,我们从文件中加载参考图像,调整其大小,将其转换为灰度,并为其创建一个空的遮罩:
bgr_reference_image = cv2.imread(
reference_image_path, cv2.IMREAD_COLOR)
reference_image_h, reference_image_w = \
bgr_reference_image.shape[:2]
reference_image_resize_factor = \
(2.0 * h) / reference_image_h
bgr_reference_image = cv2.resize(
bgr_reference_image, (0, 0), None,
reference_image_resize_factor,
reference_image_resize_factor, cv2.INTER_CUBIC)
gray_reference_image = convert_to_gray(bgr_reference_image)
reference_mask = numpy.empty_like(gray_reference_image)
调整参考图像的大小时,我们选择使其比相机框高两倍。 确切的数字是任意的; 但是,我们的想法是我们要使用覆盖了有用放大倍率的图像金字塔来执行关键点检测和描述。 金字塔的底面(即调整大小后的参考图像)应大于摄像头框架,以便即使目标对象离摄像头非常近,以致无法完全适合框架,我们也可以以适当的比例匹配关键点 。 相反,金字塔的顶层应该小于摄影机框架,这样即使目标物体距离无法填满整个框架,我们也可以以适当的比例匹配关键点。
让我们考虑一个例子。 假设我们的原始参考图像为4000 x 3000像素,而我们的相机帧为4000 x 3000像素。 我们将参考图像的尺寸调整为4000 x 3000像素(帧高度的两倍,并且纵横比与原始参考图像相同)。 因此,我们的图像金字塔的底面也是4000 x 3000像素。 由于我们的cv2.ORB对象配置为使用 16 个金字塔等级且比例因子为 1.2,因此图像金字塔的顶部宽度为1920 / (1.2^(16-1)) = 124像素,高度为1440 / (1.2^(16-1)) = 93像素; 换句话说,它是4000 x 3000像素。 因此,即使物体相距太远,以至于它仅占框架宽度或高度的 10%,我们也可以匹配关键点并跟踪该物体。 实际上,要在此级别上执行有用的关键点匹配,我们需要一个好的镜头,该物体需要聚焦,并且照明也必须很好。
- 在此阶段,我们有一个大小适当的 BGR 颜色和灰度参考图像,并且对此图像有一个空遮罩。 我们将图像划分为 36 个大小相等的兴趣区域(在
6 x 6网格中),并且对于每个区域,我们将尝试生成多达 250 个关键点和描述符(因为已使用最大数量的关键点和描述符配置cv2.ORB对象)。 这种分区方案有助于确保我们在每个区域中都有一些关键点和描述符,因此即使对象的大多数部分在给定帧中不可见,我们也可以潜在地匹配关键点并跟踪对象。 以下代码块显示了我们如何在兴趣区域上进行迭代,并为每个区域创建掩码,执行关键点检测和描述符提取,以及将关键点和描述符附加到主列表中:
# Find keypoints and descriptors for multiple segments of
# the reference image.
reference_keypoints = []
self._reference_descriptors = numpy.empty(
(0, 32), numpy.uint8)
num_segments_y = 6
num_segments_x = 6
for segment_y, segment_x in numpy.ndindex(
(num_segments_y, num_segments_x)):
y0 = reference_image_h * \
segment_y // num_segments_y - patchSize
x0 = reference_image_w * \
segment_x // num_segments_x - patchSize
y1 = reference_image_h * \
(segment_y + 1) // num_segments_y + patchSize
x1 = reference_image_w * \
(segment_x + 1) // num_segments_x + patchSize
reference_mask.fill(0)
cv2.rectangle(
reference_mask, (x0, y0), (x1, y1), 255, cv2.FILLED)
more_reference_keypoints, more_reference_descriptors = \
self._feature_detector.detectAndCompute(
gray_reference_image, reference_mask)
if more_reference_descriptors is None:
# No keypoints were found for this segment.
continue
reference_keypoints += more_reference_keypoints
self._reference_descriptors = numpy.vstack(
(self._reference_descriptors,
more_reference_descriptors))
- 现在,我们在灰度参考图像上方绘制关键点的可视化效果:
cv2.drawKeypoints(
gray_reference_image, reference_keypoints,
bgr_reference_image,
flags=cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS)
- 接下来,我们将可视化文件保存到名称后附加
_keypoints的文件中。 例如,如果参考图像的文件名是reference_image.png,则将可视化文件另存为reference_image_keypoints.png。 以下是相关代码:
ext_i = reference_image_path.rfind('.')
reference_image_keypoints_path = \
reference_image_path[:ext_i] + '_keypoints' + \
reference_image_path[ext_i:]
cv2.imwrite(
reference_image_keypoints_path, bgr_reference_image)
- 我们继续使用自定义参数初始化基于 FLANN 的匹配器:
FLANN_INDEX_LSH = 6
index_params = dict(algorithm=FLANN_INDEX_LSH,
table_number=6, key_size=12,
multi_probe_level=1)
search_params = dict()
self._descriptor_matcher = cv2.FlannBasedMatcher(
index_params, search_params)
这些参数指定我们正在使用具有 6 个哈希表,12 位哈希键大小和 1 个多探针级别的多探针 LSH(位置敏感哈希)索引算法。
有关多探针 LSH 算法的说明,请参阅论文《多探针 LSH:高维相似性搜索的有效索引》(VLDB,2007 年),由 Qin Lv,William Josephson,Zhe Wang, 摩西·查里卡尔(Moses Charikar)和李凯(Kai Li)。 可在这个页面获得电子版本。
- 我们通过向其提供参考描述符来训练匹配器:
self._descriptor_matcher.add([self._reference_descriptors])
- 我们获取关键点的 2D 坐标,并将它们馈送到
map_points_to_plane辅助函数中,以便在对象平面的表面上获得等效的 3D 坐标:
reference_points_2D = [keypoint.pt
for keypoint in reference_keypoints]
self._reference_points_3D = map_points_to_plane(
reference_points_2D, gray_reference_image.shape[::-1],
reference_image_real_height)
- 类似地,我们调用
map_vertices_to_plane函数以获得平面的 3D 顶点和 3D 面:
(self._reference_vertices_3D,
self._reference_vertex_indices_by_face) = \
map_vertices_to_plane(
gray_reference_image.shape[::-1],
reference_image_real_height)
到此结束__init__方法的实现。 接下来,让我们看一下run方法,它表示应用的主循环。
实现主循环
像往常一样,我们的主循环的主要作用是捕获和处理帧,直到用户按下Esc键。 每个帧的处理(包括 3D 跟踪和 AR 绘制)都委托给称为_track_object的辅助方法,稍后将在《跟踪 3D 图像》部分中进行探讨。 主循环还具有辅助作用:即通过测量帧速率并相应地更新卡尔曼过滤器的转换矩阵来执行计时。 此更新委托给另一种辅助方法_init_kalman_transition_matrix,我们将在“初始化和应用卡尔曼过滤器”部分中进行研究。 考虑到这些角色,我们可以在run方法中实现main循环,如下所示:
def run(self):
num_images_captured = 0
start_time = timeit.default_timer()
while cv2.waitKey(1) != 27: # Escape
success, self._bgr_image = self._capture.read(
self._bgr_image)
if success:
num_images_captured += 1
self._track_object()
cv2.imshow('Image Tracking', self._bgr_image)
delta_time = timeit.default_timer() - start_time
if delta_time > 0.0:
fps = num_images_captured / delta_time
self._init_kalman_transition_matrix(fps)
请注意 Python 标准库中timeit.default_timer函数的使用。 此函数提供了以秒为单位的当前系统时间的精确测量值(作为浮点数,因此可以表示秒的分数)。 就像名称timeit所暗示的那样,此模块包含有用的功能,适用于以下情况:您具有时间敏感的代码,并且想要为其计时。
让我们继续进行_track_object的实现,因为此助手代表run执行了应用工作的最大部分。
在 3D 中追踪图像
_track_object方法直接负责关键点匹配,关键点可视化和解决 PnP 问题。 此外,它调用其他方法来处理卡尔曼滤波,AR 绘制和掩盖被跟踪的对象:
- 为了开始
_track_object的实现,我们调用convert_to_gray辅助函数将帧转换为灰度:
def _track_object(self):
self._gray_image = convert_to_gray(
self._bgr_image, self._gray_image)
- 现在,我们使用
cv2.ORB对象检测灰度图像的遮罩区域中的关键点并计算描述符:
if self._mask is None:
self._mask = numpy.full_like(self._gray_image, 255)
keypoints, descriptors = \
self._feature_detector.detectAndCompute(
self._gray_image, self._mask)
如果我们已经在前一帧中跟踪了对象,则遮罩将覆盖我们先前找到该对象的区域。 否则,遮罩会覆盖整个框架,因为我们不知道对象可能在哪里。 稍后,我们将在“绘制跟踪结果并屏蔽被跟踪的对象”部分中了解如何创建遮罩。
- 接下来,我们使用 FLANN 匹配器查找参考图像的关键点与帧的关键点之间的匹配项,并根据比率测试过滤这些匹配项:
# Find the 2 best matches for each descriptor.
matches = self._descriptor_matcher.knnMatch(descriptors, 2)
# Filter the matches based on the distance ratio test.
good_matches = [
match[0] for match in matches
if len(match) > 1 and \
match[0].distance < 0.6 * match[1].distance
]
有关 FLANN 匹配和比率测试的详细信息,请参考第 6 章,“检索图像并使用图像描述符进行搜索”。
- 在此阶段,我们列出了通过比率测试的良好匹配项。 让我们选择与这些良好匹配相对应的框架关键点的子集,然后在框架上绘制红色圆圈以可视化这些关键点:
# Select the good keypoints and draw them in red.
good_keypoints = [keypoints[match.queryIdx]
for match in good_matches]
cv2.drawKeypoints(self._gray_image, good_keypoints,
self._bgr_image, (0, 0, 255))
- 找到了不错的比赛之后,我们显然知道其中有多少人。 如果计数很小,那么总的来说,这组匹配项可能会令人怀疑且不足以进行跟踪。 我们为良好匹配的最小数量定义了两个不同的阈值:较高的阈值(如果我们只是开始跟踪(即,我们没有在前一帧中跟踪对象))和较低的阈值(如果我们正在继续跟踪) 跟踪前一帧中的对象):
min_good_matches_to_start_tracking = 8
min_good_matches_to_continue_tracking = 6
num_good_matches = len(good_matches)
- 如果我们甚至没有达到下限阈值,那么我们会注意到我们没有在该帧中跟踪对象,因此我们将遮罩重置为覆盖整个帧:
if num_good_matches < min_good_matches_to_continue_tracking:
self._was_tracking = False
self._mask.fill(255)
- 另一方面,如果我们有足够的匹配项来满足适用的阈值,那么我们将继续尝试跟踪对象。 第一步是在框架中选择良好匹配的 2D 坐标,并在
reference对象的模型中选择其 3D 坐标:
elif num_good_matches >= \
min_good_matches_to_start_tracking or \
self._was_tracking:
# Select the 2D coordinates of the good matches.
# They must be in an array of shape (N, 1, 2).
good_points_2D = numpy.array(
[[keypoint.pt] for keypoint in good_keypoints],
numpy.float32)
# Select the 3D coordinates of the good matches.
# They must be in an array of shape (N, 1, 3).
good_points_3D = numpy.array(
[[self._reference_points_3D[match.trainIdx]]
for match in good_matches],
numpy.float32)
- 现在,我们准备使用本章开头在“了解
cv2.solvePnPRansac”部分中介绍的各种参数来调用cv2.solvePnPRansac。 值得注意的是,我们仅从良好匹配中使用 3D 参考关键点和 2D 场景关键点:
# Solve for the pose and find the inlier indices.
(success, self._rotation_vector,
self._translation_vector, inlier_indices) = \
cv2.solvePnPRansac(good_points_3D, good_points_2D,
self._camera_matrix,
self._distortion_coefficients,
self._rotation_vector,
self._translation_vector,
useExtrinsicGuess=False,
iterationsCount=100,
reprojectionError=8.0,
confidence=0.99,
flags=cv2.SOLVEPNP_ITERATIVE)
- 解算器可能收敛或未收敛于 PnP 问题的解决方案。 如果没有收敛,则此方法将不再做任何事情。 如果收敛,则下一步是检查是否已在上一帧中跟踪对象。 如果我们尚未跟踪它(换句话说,如果我们开始在此帧中重新跟踪对象),则可以通过调用辅助方法
_init_kalman_state_matrices重新初始化卡尔曼过滤器:
if success:
if not self._was_tracking:
self._init_kalman_state_matrices()
- 现在,无论如何,我们都在该帧中跟踪对象,因此我们可以通过调用另一个辅助方法
_apply_kalman来应用卡尔曼过滤器:
self._was_tracking = True
self._apply_kalman()
- 在这一阶段,我们有一个经过卡尔曼滤波的 6DOF 姿态。 我们还列出了
cv2.solvePnPRansac中的内部关键点。 为了帮助用户可视化结果,让我们以绿色绘制内部关键点:
# Select the inlier keypoints.
inlier_keypoints = [good_keypoints[i]
for i in inlier_indices.flat]
# Draw the inlier keypoints in green.
cv2.drawKeypoints(self._bgr_image, inlier_keypoints,
self._bgr_image, (0, 255, 0))
请记住,在此方法的前面,我们用红色绘制了所有关键点。 现在,我们以绿色绘制了内部关键点,只有外部关键点仍然是红色。
- 最后,我们再调用两个辅助方法:
self._draw_object轴绘制被跟踪对象的 3D 轴,self._make_and_draw_object_mask绘制并绘制包含对象的区域的遮罩:
# Draw the axes of the tracked object.
self._draw_object_axes()
# Make and draw a mask around the tracked object.
self._make_and_draw_object_mask()
结束我们的_track_object方法的实现。 到目前为止,我们已经大致了解了跟踪算法的实现,但是我们仍然需要实现与卡尔曼过滤器有关的辅助方法(在下一节“初始化和应用卡尔曼过滤器”中)以及遮罩和 AR 绘制(在其后的“绘制跟踪结果并遮盖跟踪的对象”部分中)。
初始化和应用卡尔曼过滤器
我们在“初始化跟踪器”部分中介绍了卡尔曼过滤器初始化的某些方面。 但是,在该部分中,我们注意到,随着应用运行在各种帧以及跟踪或不跟踪的各种状态下,卡尔曼过滤器的某些矩阵需要多次初始化或重新初始化。 具体来说,以下矩阵将发生变化:
- 转换矩阵:此矩阵表示所有输出变量之间的时间关系。 例如,该矩阵可以模拟加速度对速度的影响以及速度对位置的影响。 我们将每帧重新初始化转换矩阵,因为帧速率(以及帧之间的时间步长)是可变的。 有效地,这是缩放先前的加速度和速度预测以匹配新时间步长的一种方法。
- 校正前和校正后状态矩阵:这些矩阵包含输出变量的预测。 预校正矩阵中的预测仅考虑先前状态和转换矩阵。 校正后矩阵中的预测还考虑了新的输入和卡尔曼过滤器的其他矩阵。 每当我们从非跟踪状态变为跟踪状态时,换句话说,当我们无法在前一帧中跟踪对象但现在我们成功地在当前帧中跟踪对象时,我们将重新初始化状态矩阵。 实际上,这是一种清除过时的预测并从新的测量重新开始的方法。
让我们先看一下转换矩阵。 其初始化方法将使用一个参数fps,即每秒帧数。 我们可以通过三个步骤来实现该方法:
- 我们首先验证
fps参数。 如果不是正数,我们将立即返回而不会更新过渡矩阵:
def _init_kalman_transition_matrix(self, fps):
if fps <= 0.0:
return
- 确定
fps为正后,我们继续计算速度和加速度的过渡速率。 我们希望速度转换速率与时间步长(即每帧的时间)成比例。 因为fps(每秒帧数)是时间步长的倒数(即每帧秒数),所以速度转换率与fps成反比。 加速度变化率与速度变化率的平方成正比(因此,加速度变化率与fps的平方成反比)。 选择 1.0 作为速度转换率的基本比例,选择 0.5 作为加速度转换率的基本比例,我们可以在代码中进行如下计算:
# Velocity transition rate
vel = 1.0 / fps
# Acceleration transition rate
acc = 0.5 * (vel ** 2.0)
- 接下来,我们填充转换矩阵。 由于我们有 18 个输出变量,因此转换矩阵具有 18 行和 18 列。 首先,让我们看一下矩阵的内容,然后,我们将考虑如何解释它:
self._kalman.transitionMatrix = numpy.array(
[[1.0, 0.0, 0.0, vel, 0.0, 0.0, acc, 0.0, 0.0,
0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0],
[0.0, 1.0, 0.0, 0.0, vel, 0.0, 0.0, acc, 0.0,
0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0],
[0.0, 0.0, 1.0, 0.0, 0.0, vel, 0.0, 0.0, acc,
0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0],
[0.0, 0.0, 0.0, 1.0, 0.0, 0.0, vel, 0.0, 0.0,
0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0],
[0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, vel, 0.0,
0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0],
[0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, vel,
0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0],
[0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0,
0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0],
[0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0,
0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0],
[0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0,
0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0],
[0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0,
1.0, 0.0, 0.0, vel, 0.0, 0.0, acc, 0.0, 0.0],
[0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0,
0.0, 1.0, 0.0, 0.0, vel, 0.0, 0.0, acc, 0.0],
[0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0,
0.0, 0.0, 1.0, 0.0, 0.0, vel, 0.0, 0.0, acc],
[0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0,
0.0, 0.0, 0.0, 1.0, 0.0, 0.0, vel, 0.0, 0.0],
[0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0,
0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, vel, 0.0],
[0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0,
0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, vel],
[0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0,
0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0],
[0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0,
0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0],
[0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0,
0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0]],
numpy.float32)
每行表示一个公式,用于根据前一帧的输出值来计算新的输出值。 让我们以第一行为例。 我们可以将其解释如下:
新的t[x]值取决于旧的t[x],t[x]'和t[x]'值,以及速度转换率v和加速度转换率a。 正如我们之前在此函数中看到的那样,这些过渡速率可能会有所变化,因为时间步长可能会有所不同。
到此结束了用于初始化或更新转换矩阵的辅助方法的实现。 请记住,由于帧速率(以及时间步长)可能已更改,因此我们每帧都调用此函数。
我们还需要一个辅助函数来初始化状态矩阵。 请记住,每当我们从非跟踪状态过渡到跟踪状态时,我们都会调用此方法。 此过渡是清除以前所有预测的适当时间; 相反,我们重新开始时就相信对象的 6DOF 姿势正是 PnP 求解器所说的。 此外,我们假设物体是静止的,速度为零,加速度为零。 这是辅助方法的实现:
def _init_kalman_state_matrices(self):
t_x, t_y, t_z = self._translation_vector.flat
r_x, r_y, r_z = self._rotation_vector.flat
self._kalman.statePre = numpy.array(
[[t_x], [t_y], [t_z],
[0.0], [0.0], [0.0],
[0.0], [0.0], [0.0],
[r_x], [r_y], [r_z],
[0.0], [0.0], [0.0],
[0.0], [0.0], [0.0]], numpy.float32)
self._kalman.statePost = numpy.array(
[[t_x], [t_y], [t_z],
[0.0], [0.0], [0.0],
[0.0], [0.0], [0.0],
[r_x], [r_y], [r_z],
[0.0], [0.0], [0.0],
[0.0], [0.0], [0.0]], numpy.float32)
注意,由于我们有 18 个输出变量,因此状态矩阵有 1 行和 18 列。
现在我们已经介绍了初始化和重新初始化卡尔曼过滤器的矩阵的过程,让我们看一下如何应用过滤器。 正如我们之前在第 8 章,“跟踪对象”中所看到的,我们可以要求卡尔曼过滤器估计对象的新姿态(输出变量的校正前状态),然后我们可以告诉它考虑最新的不稳定跟踪结果(输入变量)以调整其估计值(从而产生校正后的状态),最后,我们可以从调整后的估计值中提取变量以用作稳定后的跟踪结果。 与我们以前的工作相比,这次的唯一区别是我们有更多的输入和输出变量。 以下代码显示了我们如何实现在 6DOF 跟踪器的上下文中应用卡尔曼过滤器的方法:
def _apply_kalman(self):
self._kalman.predict()
t_x, t_y, t_z = self._translation_vector.flat
r_x, r_y, r_z = self._rotation_vector.flat
estimate = self._kalman.correct(numpy.array(
[[t_x], [t_y], [t_z],
[r_x], [r_y], [r_z]], numpy.float32))
self._translation_vector = estimate[0:3]
self._rotation_vector = estimate[9:12]
这里,请注意,estimate[0:3]对应于t[x],t[y]和t[z],而estimate[9:12]对应于r[x],r[y]和r[z]。 estimate数组的其余部分对应于一阶导数(速度)和二阶导数(加速度)。
至此,我们几乎完全探索了 3D 跟踪算法的实现,包括使用卡尔曼过滤器来稳定 6DOF 姿态以及速度和加速度。 现在,让我们将注意力转向ImageTrackingDemo类的两个最终实现细节:AR 绘制方法和基于跟踪结果创建遮罩。
绘制跟踪结果并遮盖被跟踪对象
我们将实现一个辅助方法_draw_object_axes,以绘制跟踪对象的X,Y和Z轴的可视化图像。 我们还将实现另一种辅助方法_make_and_draw_object_mask,以将对象的顶点从 3D 投影到 2D,基于对象的轮廓创建遮罩,并将该遮罩的区域染成黄色以显示。
让我们从_draw_object_axes的实现开始。 我们可以分三个阶段来考虑:
- 首先,我们要获取一组沿轴放置的 3D 点,并将这些点投影到 2D 图像空间。 请记住,我们在“初始化跟踪器”部分的
__init__方法中定义了 3D 轴点。 它们将仅用作我们将绘制的轴箭头的端点。 使用cv2.projectPoints函数,6DOF 跟踪结果和相机矩阵,我们可以找到 2D 投影点,如下所示:
def _draw_object_axes(self):
points_2D, jacobian = cv2.projectPoints(
self._reference_axis_points_3D, self._rotation_vector,
self._translation_vector, self._camera_matrix,
self._distortion_coefficients)
除了返回投影的 2D 点之外,cv2.projectPoints还返回雅可比矩阵,该矩阵表示用于计算 2D 点的函数的偏导数(相对于输入参数)。 此信息可能对相机校准很有用,但在本示例中不使用它。
- 投影点采用浮点格式,但是我们需要整数才能传递给 OpenCV 的绘图函数。 因此,我们将以下转换为整数格式:
origin = (int(points_2D[0, 0, 0]), int(points_2D[0, 0, 1]))
right = (int(points_2D[1, 0, 0]), int(points_2D[1, 0, 1]))
up = (int(points_2D[2, 0, 0]), int(points_2D[2, 0, 1]))
forward = (int(points_2D[3, 0, 0]), int(points_2D[3, 0, 1]))
- 在计算了端点之后,我们现在可以绘制三个箭头线来表示 X,Y 和 Z 轴:
# Draw the X axis in red.
cv2.arrowedLine(self._bgr_image, origin, right, (0, 0, 255))
# Draw the Y axis in green.
cv2.arrowedLine(self._bgr_image, origin, up, (0, 255, 0))
# Draw the Z axis in blue.
cv2.arrowedLine(
self._bgr_image, origin, forward, (255, 0, 0))
我们已经完成了_draw_object_axes的实现。 现在,让我们将注意力转移到_make_and_draw_object_mask上,我们也可以从三个步骤来考虑:
- 像以前的函数一样,该函数从将点从 3D 投影到 2D 开始。 这次,我们在“初始化跟踪器”部分的
__init__方法中定义了参考对象的顶点。 这是投影代码:
def _make_and_draw_object_mask(self):
# Project the object's vertices into the scene.
vertices_2D, jacobian = cv2.projectPoints(
self._reference_vertices_3D, self._rotation_vector,
self._translation_vector, self._camera_matrix,
self._distortion_coefficients)
- 同样,我们将投影点从浮点格式转换为整数格式(因为 OpenCV 的绘图函数需要整数):
vertices_2D = vertices_2D.astype(numpy.int32)
- 投影的顶点形成凸多边形。 我们可以将遮罩涂成黑色(作为背景),然后以白色绘制此凸多边形:
# Make a mask based on the projected vertices.
self._mask.fill(0)
for vertex_indices in \
self._reference_vertex_indices_by_face:
cv2.fillConvexPoly(
self._mask, vertices_2D[vertex_indices], 255)
请记住,我们的_track_object方法在处理下一帧时将使用此掩码。 具体来说,_track_object将仅在遮罩区域中查找关键点。 因此,它将尝试在我们最近找到它的区域中找到该对象。
潜在地,我们可以通过应用形态学扩张操作来扩展遮罩区域来改进此技术。 这样,我们不仅可以在最近找到它的区域中搜索对象,而且可以在周围区域中搜索。
- 现在,在 BGR 框架中,让我们以黄色突出显示被遮罩的区域,以可视化被跟踪对象的形状。 为了使区域更黄,我们可以从蓝色通道中减去一个值。
cv2.subtract函数适合我们的目的,因为它接受可选的mask参数。 这是我们的用法:
# Draw the mask in semi-transparent yellow.
cv2.subtract(
self._bgr_image, 48, self._bgr_image, self._mask)
当我们告诉cv2.subtract从图像中减去单个标量值(例如 48)时,它仅从图像的第一个通道(在这种情况下(大多数情况下)是 BGR 图像的蓝色通道)中减去该值。 可以说这是一个错误,但可以方便地将其着色为黄色!
那是ImageTrackingDemo类中的最后一个方法。 现在,让我们通过实例化该类并调用其run方法来使演示栩栩如生!
运行和测试应用
为了完成ImageTrackingDemo.py的实现,让我们编写一个main函数,该函数以指定的捕获设备,FOV 和目标帧速率启动应用:
def main():
capture = cv2.VideoCapture(0)
capture.set(cv2.CAP_PROP_FRAME_WIDTH, 1280)
capture.set(cv2.CAP_PROP_FRAME_HEIGHT, 720)
diagonal_fov_degrees = 70.0
target_fps = 25.0
demo = ImageTrackingDemo(
capture, diagonal_fov_degrees, target_fps)
demo.run()
if __name__ == '__main__':
main()
在这里,我们使用的捕获分辨率为 1280 x 720,对角 FOV 为 70 度,目标帧速率为 25 FPS。 您应该选择适合您的相机和镜头以及系统速度的参数。
假设我们运行该应用,并从reference_image.png加载以下图像:

当然,这是约瑟夫·霍斯(Joseph Howse)所著的《OpenCV 4 for Secret Agents》(Packt Publishing,2019)的封面。 它不仅是秘密知识的库,而且还是图像跟踪的良好目标。 您应该购买印刷本!
在初始化期间,应用将参考关键点的以下可视化保存到名为reference_image_keypoints.png的新文件中:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2XeWuXO8-1681871605271)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/learn-opencv4-cv-py3/img/ec7a39dc-9e79-4bce-a24d-ece3ca277e6d.png)]
在第 6 章,“检索图像和使用图像描述符进行搜索”之前,我们已经看到了这种类型的可视化。 大圆圈表示可以在小范围内匹配的关键点(例如,当我们从远距离或使用低分辨率相机查看打印的图像时)。 小圆圈代表可以大规模匹配的关键点(例如,当我们近距离观看打印的图像或使用高分辨率相机时)。 最好的关键点是许多同心圆标记的,因为它们可以在不同的比例下匹配。 在每个圆圈内,径向线表示关键点的法线方向。
通过研究此可视化,我们可以推断出该图像的最佳关键点集中在图像顶部的高对比度文本(白色对深灰色)中。 在许多区域中还可以找到其他有用的关键点,包括图像底部的高对比度线(黑与饱和色)。
接下来,我们看到一个相机供稿。 将参考图像打印在相机前面时,我们会看到跟踪结果的 AR 可视化效果:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mUkex5SM-1681871605271)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/learn-opencv4-cv-py3/img/617090ff-841d-45e9-864b-f06adfbf1017.png)]
当然,前面的屏幕快照显示了书封面的近正面视图。 轴方向按预期绘制。 X 轴(红色)指向书套的右侧(查看者的左侧)。 Y 轴(绿色)指向上方。 Z 轴(蓝色)从书的封面指向前方(朝着查看者)。 作为增强现实效果,在跟踪的书的封面(包括由 Joseph Howse 的食指和中指覆盖的部分)上叠加了半透明的黄色高光。 绿色和红色小点的位置表明,在此帧中,良好的关键点匹配集中在书名的区域中,而这些良好的匹配中的大多数都是cv2.solvePnPRansac的整数。
如果您正在阅读本书的印刷版,则屏幕截图将以灰度复制。 为了使 X,Y 和 Z 轴在灰度打印中更容易区分,已将文本标签手动添加到屏幕截图中。 这些文本标签不属于程序输出的一部分。
因为我们努力在整个图像的多个区域中找到良好的关键点,所以即使被跟踪图像的很大一部分处于阴影,被遮盖或在框架外时,跟踪也可以成功。 例如,在下面的屏幕截图中,即使大部分书的封面(包括几乎所有具有最佳关键点的书名)都在框架之外,轴方向和突出显示的区域也是正确的:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xoiQsCvJ-1681871605271)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/learn-opencv4-cv-py3/img/13ce7249-4049-43e4-a447-959288040e24.png)]
继续并使用各种参考图像,照相机和观看条件进行自己的实验。 为参考图像和相机尝试各种分辨率。 切记要测量相机的 FOV 并相应地调整 FOV 参数。 研究关键点的可视化效果和跟踪结果。 在我们的演示中,哪种输入产生良好(或不良)的跟踪结果?
如果您发现使用打印的图像进行跟踪不方便,则可以将相机对准要显示要跟踪的图像的屏幕(例如智能手机屏幕)。 由于屏幕是背光的(也可能是光滑的),因此它可能无法忠实地表示打印图像在任何给定场景中的外观,但通常可以很好地用于跟踪器的目的。
对心脏的内容进行实验后,让我们考虑一些 3D 跟踪器可以改进的方法。
改进 3D 跟踪算法
本质上,我们的 3D 跟踪算法结合了三种方法:
- 使用 PnP 求解器查找 6DOF 姿势,该姿势的输入取决于基于 FLANN 的 ORB 描述符匹配。
- 使用卡尔曼过滤器来稳定 6DOF 跟踪结果。
- 如果在前一帧中跟踪到对象,请使用遮罩将搜索限制到现在最有可能找到该对象的区域。
3D 跟踪的商业解决方案通常涉及其他方法。 我们依靠成功地为每个帧使用描述符匹配器和 PnP 解算器。 但是,更复杂的算法可能会提供一些替代方案,如后备或交叉检查机制。 这是因为描述符匹配器和 PnP 求解器在某些帧中错过了对象,或者它们在计算上过于昂贵而无法用于每个帧。 广泛使用以下替代方法:
- 根据光流更新先前的关键点匹配,并根据关键点的旧位置和新位置之间的单应性更新前一个 6DOF 姿势(根据光流)。
- 根据陀螺仪和磁力计(罗盘)更新 6DOF 姿势的旋转分量。 通常,即使在消费类设备中,这些传感器也可以成功地测量旋转的大小变化。
- 根据气压计和 GPS 更新 6DOF 姿态的位置分量。 通常,在消费类设备中,气压计可以以大约 10cm 的精度测量高度变化,而 GPS 可以以大约 10m 的精度测量经度和纬度的变化。 根据使用情况,这些精度可能是有用的,也可能不是。 如果我们试图在大而远的景观特征上进行增强现实(例如),如果我们想绘制一条栖息在真实山顶上的虚拟巨龙,那么 10m 的精度可能会更好。 对于详细的工作(例如,如果我们想在真实的手指上画一个虚拟的戒指),则无法使用 10 厘米的精度。
- 根据加速度计更新卡尔曼过滤器的位置加速度分量。 通常,在消费类设备中,加速度计会产生漂移(误差会在一个方向或另一个方向上显示失控的趋势),因此应谨慎使用此选项。
这些替代技术不在本书的讨论范围之内,实际上,其中一些不是计算机视觉技术,因此我们将其留给您进行独立研究。
最后一句话:有时,通过更改预处理算法而不是跟踪算法本身,可以显着改善跟踪结果。 在本章前面的“执行灰度转换”部分中,我们提到了 Macêdo,Melo 和 Kelner 关于灰度转换算法和 SIFT 描述符的论文。 您可能希望阅读该论文并进行自己的实验,以确定在使用 ORB 描述符或其他类型的描述符时,灰度转换算法的选择如何影响跟踪内线的数量。
总结
本章介绍了 AR,以及一组针对 3D 空间中图像跟踪问题的可靠方法。
我们首先学习了 6DOF 跟踪的概念。 我们认识到,熟悉的工具(例如 ORB 描述符,基于 FLANN 的匹配和卡尔曼滤波)在这种跟踪中很有用,但是我们还需要使用相机和镜头参数来解决 PnP 问题。
接下来,我们讨论了如何以灰度图像,一组 2D 关键点和一组 3D 关键点的形式最好地表示参考对象(例如书的封面或照片)的实际考虑。
我们着手实现了一个类,该类封装了 3D 空间中的图像跟踪演示,并以 3D 高亮效果作为 AR 的基本形式。 我们的实现涉及实时考虑,例如需要根据帧速率的波动来更新卡尔曼过滤器的转换矩阵。
最后,我们考虑了使用其他计算机视觉技术或其他基于传感器的技术来潜在改善 3D 跟踪算法的方法。
现在,我们正在接近本书的最后一章,该章对到目前为止我们已经解决的许多问题提供了不同的观点。 我们可以暂时搁置相机和几何学的思想,而开始以统计学家的身份思考,因为我们将通过研究人工神经网络(ANN)。
十、使用 OpenCV 的神经网络简介
本章介绍了一系列称为人工神经网络(ANNs)或有时仅称为神经网络的机器学习模型。 这些模型的主要特征是它们试图以多层的方式学习变量之间的关系。 在将这些结果合并为一个函数以预测有意义的内容(例如对象的类别)之前,他们学习了多种特征来预测中间结果。 OpenCV 的最新版本包含越来越多的与 ANN 相关的功能-尤其是具有多层的 ANN,称为深度神经网络(DNN)。 在本章中,我们将对较浅的 ANN 和 DNN 进行试验。
在其他各章中,我们已经对机器学习有所了解,尤其是在第 7 章,“构建自定义对象检测器”中,我们使用 SURF 描述符开发了汽车/非汽车分类器, BoW 和一个 SVM。 以此为基础进行比较,您可能会想知道,人工神经网络有什么特别之处? 我们为什么将本书的最后一章专门介绍给他们?
人工神经网络旨在在以下情况下提供卓越的准确率:
- 输入变量很多,它们之间可能具有复杂的非线性关系。
- 有许多输出变量,这些变量可能与输入变量具有复杂的非线性关系。 (通常,分类问题中的输出变量是类的置信度得分,因此,如果有很多类,那么会有很多输出变量。)
- 有许多隐藏的(未指定)变量可能与输入和输出变量具有复杂的非线性关系。 DNN 甚至旨在建模多个隐变量层,这些隐层主要彼此相关,而不是主要与输入或输出变量相关。
这些情况存在于许多(也许是大多数)现实世界中的问题中。 因此,人工神经网络和 DNN 的预期优势是诱人的。 另一方面,众所周知,人工神经网络(尤其是 DNN)是不透明的模型,因为它们通过预测是否存在可能与其他所有事物有关的任意数量的无名,隐藏变量而起作用。
在本章中,我们将涵盖以下主题:
- 将人工神经网络理解为统计模型和有监督的机器学习工具。
- 了解 ANN 拓扑,或者将 ANN 组织到相互连接的神经元层中。 特别地,我们将考虑使 ANN 能够用作一种分类器的拓扑,称为多层感知器(MLP)。
- 在 OpenCV 中训练和使用人工神经网络作为分类器。
- 生成检测和识别手写数字(0 到 9)的应用。 为此,我们将基于被广泛使用的称为 MNIST 的数据集训练 ANN,该数据集包含手写数字的样本。
- 在 OpenCV 中加载和使用经过预训练的 DNN。 我们将介绍 DNN 的对象分类,人脸检测和性别分类的示例。
到本章结束时,您将很容易在 OpenCV 中训练和使用 ANN,可以使用来自各种来源的经过预先训练的 DNN,并可以开始探索其他可用来训练自己的 DNN 的库。
技术要求
本章使用 Python,OpenCV 和 NumPy。 有关安装说明,请参阅第 1 章,“设置 OpenCV”的。
本章的完整代码和示例视频可以在本书的 GitHub 存储库中找到,位于chapter10文件夹中。
了解人工神经网络
让我们根据其基本角色和组成部分来定义 ANN。 尽管有关人工神经网络的许多文献都强调它们是通过神经元在大脑中的连接方式受到生物学启发,但我们并不需要是生物学家或神经科学家来了解人工神经网络的基本概念。
首先,人工神经网络是统计模型。 什么是统计模型? 统计模型是一对元素,即空间S(一组观察值)和概率P,其中P是近似于S的分布(换句话说,一个函数,它生成一组与S非常相似的观察结果。
这是思考P的两种不同方法:
P是复杂场景的简化。P是首先生成S或至少与S非常相似的一组观察结果的函数。
因此,人工神经网络是一个模型,它采用一个复杂的现实,对其进行简化,并推导一个函数以(近似)以数学形式表示我们期望从该现实中获得的统计观察结果。
与其他类型的机器学习模型一样,人工神经网络可以通过以下方式之一从观察中学习:
- 监督学习:在这种方法下,我们希望模型的训练过程产生一个函数,该函数将一组已知的输入变量映射到一组已知的输出变量。 我们知道,先验是预测问题的性质,我们将找到解决该问题的函数的过程委托给了 ANN。 要训练模型,我们必须提供输入样本以及正确的相应输出。 对于分类问题,输出变量可以是一个或多个类别的置信度得分。
- 无监督学习:在这种方法下,先验不知道输出变量的集合。 模型的训练过程必须产生一组输出变量,以及将输入变量映射到这些输出变量的函数。 对于分类问题,无监督学习可能导致发现先前未知的类别,例如医学数据中的先前未知的疾病。 无监督学习可以使用包括(但不限于)聚类的技术,我们在第 7 章,“构建自定义对象检测器”的 BoW 模型的上下文中对此进行了探讨。
- 强化学习:这种方法可以颠倒典型的预测问题。 在训练模型之前,我们已经有一个系统,当我们为一组已知的输入变量输入值时,该系统会为一组已知的输出变量产生值。 我们知道,先验是一种基于输出的优劣(合意性)或缺乏而对输出序列进行评分的方法。 但是,我们可能不知道将输入映射到输出的实际函数,或者,即使我们知道它,也是如此复杂,以至于无法为最佳输入求解。 因此,我们希望模型的训练过程能够产生一个函数,该函数根据最后的输出来预测序列中的下一个最优输入。 在训练过程中,模型从分数中学习,该分数最终是由其动作(所选输入)产生的。 从本质上讲,该模型必须学会在特定的奖惩系统中成为优秀的决策者。
在本章的其余部分中,我们将讨论仅限于监督学习,因为这是在计算机视觉环境下进行机器学习的最常用方法。
理解 ANN 的下一步是了解 ANN 如何在简单的统计模型和其他类型的机器学习方面进行改进。
如果生成数据集的函数可能需要大量(未知)输入怎么办?
人工神经网络采用的策略是将工作委托给多个神经元,节点或单元,每个单元都可以近似于创建神经元的功能。 输入。 在数学中,逼近是定义一个更简单的函数的过程,至少对于某些输入范围,其输出类似于更复杂的函数的输出。
近似函数的输出与原始函数的输出之间的差异称为误差。 神经网络的定义特征是神经元必须能够逼近非线性函数。
让我们仔细看看神经元。
了解神经元和感知器
通常,为了解决分类问题,将 ANN 设计为多层感知器(MLP),其中每个神经元都充当一种称为感知器的二分类器。 感知器的概念可以追溯到 1950 年代。 简而言之,感知器是一种需要大量输入并产生单个值的函数。 每个输入具有关联的权重,该权重表示其在激活函数中的重要性。 激活函数应具有非线性响应; 例如,Sigmoid 函数(有时称为 S 曲线)是常见的选择。 将阈值函数判别式应用于激活函数的输出,以将其转换为 0 或 1 的二分类。这是此序列的可视化图,左边是输入,激活函数在中间,右边是阈值函数:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zwDYeK2D-1681871605271)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/learn-opencv4-cv-py3/img/46e3e3ef-46bf-4f05-b4d9-8316b98fea3f.png)]
输入权重代表什么,如何确定?
在一个神经元的输出可以作为许多其他神经元的输入的范围内,神经元是相互关联的。 每个输入权重定义了两个神经元之间连接的强度。 这些权重是自适应的,这意味着它们会根据学习算法随时间变化。
由于神经元的互连性,网络具有层次。 现在,让我们检查一下通常如何组织这些层。
了解神经网络的各层
这是神经网络的直观表示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-eDEr94uj-1681871605272)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/learn-opencv4-cv-py3/img/e0bfde8f-89b0-484d-ae27-2b847fcdcb99.png)]
如上图所示,神经网络中至少有三个不同的层:输入层,隐藏层和输出层。 可以有多个隐藏层。 但是,一个隐藏层足以解决许多现实生活中的问题。 具有多个隐藏层的神经网络有时称为深度神经网络(DNN)。
如果我们将 ANN 用作分类器,则每个输出节点的输出值是一个类的置信度得分。 对于给定的样本(即给定的一组输入值),我们想知道哪个输出节点产生最高的输出值。 该得分最高的输出节点对应于预测的类别。
我们如何确定网络的拓扑结构,以及我们需要为每个层创建多少个神经元? 让我们逐层进行此确定。
选择输入层的大小
根据定义,输入层中的节点数是网络的输入数。 例如,假设您要创建一个人工神经网络,以帮助您根据动物的物理属性确定动物的种类。 原则上,我们可以选择任何可测量的属性。 如果我们选择根据重量,长度和牙齿数量对动物进行分类,那就是三个属性的集合,因此我们的网络需要包含三个输入节点。
这三个输入节点是否是物种分类的充分基础? 好吧,对于现实生活中的问题,当然不是-但是在玩具问题中,这取决于我们试图实现的输出,这是我们接下来要考虑的问题。
选择输出层的大小
对于分类器,根据定义,输出层中的节点数就是网络可以区分的分类数。 继续前面的动物分类网络示例,如果我们知道要处理以下动物,则可以使用四个节点的输出层:狗,秃鹰,海豚和龙(!)。 如果我们尝试对不在这些类别之一中的动物的数据进行分类,则网络将预测最有可能与这种无代表性动物相似的类别。
现在,我们遇到了一个困难的问题-隐藏层的大小。
选择隐藏层的大小
选择隐藏层的大小没有公认的经验法则。 必须根据实验进行选择。 对于要在其上应用 ANN 的每个实际问题,都需要对 ANN 进行训练,测试和重新训练,直到找到许多可以接受的准确率的隐藏节点。
当然,即使通过实验选择参数值,您也可能希望专家为您的测试建议一个起始值或一系列值。 不幸的是,在这些方面也没有专家共识。 一些专家根据以下广泛建议提供经验法则(这些建议应加盐):
- 如果输入层很大,则隐藏神经元的数量应在输入层的大小和输出层的大小之间,并且通常应更接近输出层的大小。
- 另一方面,如果输入和输出层都较小,则隐藏层应为最大层。
- 如果输入层较小,但输出层较大,则隐藏层应更接近输入层的大小。
其他专家建议,还应考虑训练样本的数量; 大量的训练样本意味着更多的隐藏节点可能有用。
要记住的一个关键因素是过拟合。 与训练数据实际提供的信息相比,当隐藏层中包含如此大量的伪信息时,就会发生过拟合,因此分类不太有意义。 隐藏层越大,为了正确学习而需要的训练数据就越多。 当然,随着训练数据集的大小增加,训练时间也会增加。
对于本章中的一些 ANN 示例项目,我们将使用 60 的隐藏层大小作为起点。 给定一个庞大的训练集,对于各种分类问题,60 个隐藏节点可以产生不错的准确率。
现在,我们对什么是人工神经网络有了一个大致的了解,让我们看看 OpenCV 如何实现它们,以及如何充分利用它们。 我们将从一个最小的代码示例开始。 然后,我们将充实我们在前两节中讨论的以动物为主题的分类器。 最后,我们将努力开发更现实的应用,在该应用中,我们将基于图像数据对手写数字进行分类。
在 OpenCV 中训练基本的 ANN
OpenCV 提供了cv2.ml_ANN_MLP类,该类将 ANN 实现为多层感知器(MLP)。 这正是我们之前在“了解神经元和感知器”部分中描述的模型。
要创建cv2.ml_ANN_MLP的实例并为该 ANN 的训练和使用格式化数据,我们依赖于 OpenCV 的机器学习模块cv2.ml中的功能。 您可能还记得过,这与我们在第 7 章,“构建自定义对象检测器”中用于 SVM 相关功能的模块相同。 此外,cv2.ml_ANN_MLP和cv2.ml_SVM共享一个称为cv2.ml_StatModel的公共基类。 因此,您会发现 OpenCV 为 ANN 和 SVM 提供了类似的 API。
让我们来看一个虚拟的例子,作为对 ANN 的简要介绍。 该示例将使用完全无意义的数据,但它将向我们展示用于在 OpenCV 中训练和使用 ANN 的基本 API:
- 首先,我们照常导入 OpenCV 和 NumPy:
import cv2
import numpy as np
- 现在,我们创建一个未经训练的人工神经网络:
ann = cv2.ml.ANN_MLP_create()
- 创建 ANN 后,我们需要配置其层数和节点数:
ann.setLayerSizes(np.array([9, 15, 9], np.uint8))
层大小由传递给setLayerSizes方法的 NumPy 数组定义。 第一个元素是输入层的大小,最后一个元素是输出层的大小,所有中间元素定义隐藏层的大小。 例如,[9, 15, 9]指定 9 个输入节点,9 个输出节点以及具有 15 个节点的单个隐藏层。 如果将其更改为[9, 15, 13, 9],它将指定两个分别具有 15 和 13 个节点的隐藏层。
- 我们还可以配置激活函数,训练方法和训练终止标准,如下所示:
ann.setActivationFunction(cv2.ml.ANN_MLP_SIGMOID_SYM, 0.6, 1.0)
ann.setTrainMethod(cv2.ml.ANN_MLP_BACKPROP, 0.1, 0.1)
ann.setTermCriteria(
(cv2.TERM_CRITERIA_MAX_ITER | cv2.TERM_CRITERIA_EPS, 100, 1.0))
在这里,我们使用对称的 Sigmoid 激活函数(cv2.ml.ANN_MLP_SIGMOID_SYM)和反向传播训练方法(cv2.ml.ANN_MLP_BACKPROP)。 反向传播是一种算法,用于计算输出层的预测误差,从先前的层向后追溯误差的来源,并更新权重以减少误差。
- 让我们训练 ANN。 我们需要指定训练输入(或 OpenCV 术语中的
samples),相应的正确输出(或responses),以及数据的格式(或layout)是每个样本一行还是每个样本一行。 这是一个如何使用单个样本训练模型的示例:
training_samples = np.array(
[[1.2, 1.3, 1.9, 2.2, 2.3, 2.9, 3.0, 3.2, 3.3]], np.float32)
layout = cv2.ml.ROW_SAMPLE
training_responses = np.array(
[[0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0]], np.float32)
data = cv2.ml.TrainData_create(
training_samples, layout, training_responses)
ann.train(data)
实际上,我们希望使用包含一个以上样本的更大数据集来训练任何 ANN。 我们可以通过扩展training_samples和training_responses使其包含多个行来表示多个样本及其相应的响应,从而做到这一点。 或者,我们可以多次调用 ANN 的train方法,每次都使用新数据。 后一种方法需要train方法使用一些其他参数,下一节“在多个周期中训练 ANN 分类器”将对此进行演示。
请注意,在这种情况下,我们正在训练 ANN 作为分类器。 每个响应都是一个类的置信度得分,在这种情况下,有 9 个类。 我们将通过基于 0 的索引将它们称为 0 到 8 类。在这种情况下,我们的训练样本的响应为[0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0],这意味着它是 5 类的实例(置信度 1.0),并且它绝对不是任何其他类的实例(因为其他所有类的置信度为 0.0)。
- 为了完成对 ANN API 的最小介绍,让我们制作另一个示例,对其进行分类并打印结果:
test_samples = np.array(
[[1.4, 1.5, 1.2, 2.0, 2.5, 2.8, 3.0, 3.1, 3.8]], np.float32)
prediction = ann.predict(test_samples)
print(prediction)
这将打印以下结果:
(5.0, array([[-0.08763029, -0.01616517, 0.13196233, 0.0402631 , 0.05711843,
1.1642447 , 0.18130444, 0.1857026 , -0.07486832]],
dtype=float32))
这意味着所提供的输入被归类为第 5 类。再次,这只是一个虚拟示例,该分类是毫无意义的。 但是,网络行为正常。 在前面的代码中,我们仅提供了一个训练记录,该训练记录是第 5 类的样本,因此网络将新输入归为第 5 类。(据我们有限的训练数据集显示,除 5 以外的其他类可能永远不会发生。)
您可能已经猜到了,预测的输出是一个元组,第一个值是类,第二个值是包含每个类的概率的数组。 预测的类别将具有最高的值。
让我们继续一个更可信的例子-动物分类。
在多个周期中训练 ANN 分类器
让我们创建一个 ANN,尝试根据三种度量对动物进行分类:体重,长度和牙齿数量。 当然,这是一个模拟场景。 实际上,没有人会只用这三个统计数据来描述动物。 但是,我们的目的是在将 ANN 应用于图像数据之前,加深对 ANN 的理解。
与上一节中的最小示例相比,我们的动物分类模型将通过以下方式更加复杂:
- 我们将增加隐藏层中神经元的数量。
- 我们将使用更大的训练数据集。 为方便起见,我们将随机生成此数据集。
- 我们将在多个周期训练 ANN,这意味着我们将使用相同的数据集每次对其进行多次训练和重新训练。
隐藏层中神经元的数量是重要的参数,需要进行测试才能优化任何 ANN 的准确率。 您会发现,较大的隐藏层可以在一定程度上提高准确率,然后过拟合,除非您开始使用庞大的训练数据集进行补偿。 同样,在一定程度上,更多的周期可能会提高准确率,但过多的周期会导致过拟合。
让我们逐步执行一下实现:
- 首先,我们照例导入 OpenCV 和 NumPy。 然后,从 Python 标准库中,导入
randint函数以生成伪随机整数,并导入uniform函数以生成伪随机浮点数:
import cv2
import numpy as np
from random import randint, uniform
- 接下来,我们创建并配置 ANN。 这次,我们使用三个神经元输入层,一个 50 神经元隐藏层和一个四个神经元输出层,如以下代码中以粗体突出显示:
animals_net = cv2.ml.ANN_MLP_create()
animals_net.setLayerSizes(np.array([3, 50, 4]))
animals_net.setActivationFunction(cv2.ml.ANN_MLP_SIGMOID_SYM, 0.6, 1.0)
animals_net.setTrainMethod(cv2.ml.ANN_MLP_BACKPROP, 0.1, 0.1)
animals_net.setTermCriteria(
(cv2.TERM_CRITERIA_MAX_ITER | cv2.TERM_CRITERIA_EPS, 100, 1.0))
- 现在,我们需要一些数据。 我们对准确地代表动物并不感兴趣。 我们只需要一堆记录作为训练数据即可。 因此,我们定义四个函数以生成不同类别的随机样本,另外定义四个函数以生成正确的分类结果以进行训练:
"""Input arrays
weight, length, teeth
"""
"""Output arrays
dog, condor, dolphin, dragon
"""
def dog_sample():
return [uniform(10.0, 20.0), uniform(1.0, 1.5),
randint(38, 42)]
def dog_class():
return [1, 0, 0, 0]
def condor_sample():
return [uniform(3.0, 10.0), randint(3.0, 5.0), 0]
def condor_class():
return [0, 1, 0, 0]
def dolphin_sample():
return [uniform(30.0, 190.0), uniform(5.0, 15.0),
randint(80, 100)]
def dolphin_class():
return [0, 0, 1, 0]
def dragon_sample():
return [uniform(1200.0, 1800.0), uniform(30.0, 40.0),
randint(160, 180)]
def dragon_class():
return [0, 0, 0, 1]
- 我们还定义了以下辅助函数,以便将样本和分类转换为一对 NumPy 数组:
def record(sample, classification):
return (np.array([sample], np.float32),
np.array([classification], np.float32))
- 让我们继续创建假动物数据。 我们将为每个类创建 20,000 个样本:
RECORDS = 20000
records = []
for x in range(0, RECORDS):
records.append(record(dog_sample(), dog_class()))
records.append(record(condor_sample(), condor_class()))
records.append(record(dolphin_sample(), dolphin_class()))
records.append(record(dragon_sample(), dragon_class()))
- 现在,让我们训练 ANN。 正如我们在本节开头所讨论的,我们将使用多个训练周期。 每个周期都是循环的迭代,如以下代码所示:
EPOCHS = 10
for e in range(0, EPOCHS):
print("epoch: %d" % e)
for t, c in records:
data = cv2.ml.TrainData_create(t, cv2.ml.ROW_SAMPLE, c)
if animals_net.isTrained():
animals_net.train(data, cv2.ml.ANN_MLP_UPDATE_WEIGHTS | cv2.ml.ANN_MLP_NO_INPUT_SCALE | cv2.ml.ANN_MLP_NO_OUTPUT_SCALE)
else:
animals_net.train(data, cv2.ml.ANN_MLP_NO_INPUT_SCALE | cv2.ml.ANN_MLP_NO_OUTPUT_SCALE)
对于具有庞大且多样化的训练数据集的实际问题,ANN 可能会受益于数百个训练周期。 为了获得最佳结果,您可能希望继续训练和测试 ANN,直到达到收敛为止,这意味着进一步的周期将不再对结果的准确率产生明显的改善。
请注意,我们必须将cv2.ml.ANN_MLP_UPDATE_WEIGHTS标志传递给 ANN 的train函数,以更新以前训练的模型,而不是从头开始训练新的模型。 这是每当您逐步训练模型时都必须记住的关键点,就像我们在这里所做的那样。
- 训练完我们的人工神经网络后,我们应该进行测试。 对于每个类别,让我们生成 100 个新的随机样本,使用 ANN 对其进行分类,并跟踪正确分类的数量:
TESTS = 100
dog_results = 0
for x in range(0, TESTS):
clas = int(animals_net.predict(
np.array([dog_sample()], np.float32))[0])
print("class: %d" % clas)
if clas == 0:
dog_results += 1
condor_results = 0
for x in range(0, TESTS):
clas = int(animals_net.predict(
np.array([condor_sample()], np.float32))[0])
print("class: %d" % clas)
if clas == 1:
condor_results += 1
dolphin_results = 0
for x in range(0, TESTS):
clas = int(animals_net.predict(
np.array([dolphin_sample()], np.float32))[0])
print("class: %d" % clas)
if clas == 2:
dolphin_results += 1
dragon_results = 0
for x in range(0, TESTS):
clas = int(animals_net.predict(
np.array([dragon_sample()], np.float32))[0])
print("class: %d" % clas)
if clas == 3:
dragon_results += 1
- 最后,让我们打印准确率统计信息:
print("dog accuracy: %.2f%%" % (100.0 * dog_results / TESTS))
print("condor accuracy: %.2f%%" % (100.0 * condor_results / TESTS))
print("dolphin accuracy: %.2f%%" % \
(100.0 * dolphin_results / TESTS))
print("dragon accuracy: %.2f%%" % (100.0 * dragon_results / TESTS))
当我们运行脚本时,前面的代码块应产生以下输出:
dog accuracy: 100.00%
condor accuracy: 100.00%
dolphin accuracy: 100.00%
dragon accuracy: 100.00%
由于我们正在处理随机数据,因此每次您运行脚本时,结果可能会有所不同。 通常,由于我们已经建立了一个简单的分类问题,即输入数据的范围不重叠,因此准确率应该很高甚至是完美的。 (狗的随机权重值的范围与龙的范围不重叠,依此类推。)
您可能需要花一些时间来尝试以下修改(一次进行一次),以便了解 ANN 的准确率如何受到影响:
- 通过修改
RECORDS变量的值来更改训练样本的数量。 - 通过修改
EPOCHS变量的值来更改训练周期的数量。 - 通过在
dog_sample,condor_sample,dolphin_sample和dragon_sample函数中编辑uniform和randint函数调用的参数,使输入数据的范围部分重叠。
准备就绪后,我们将继续一个包含真实图像数据的示例。 这样,我们将训练 ANN 来识别手写数字。
用人工神经网络识别手写数字
手写数字是 10 个阿拉伯数字(0 到 9)中的任何一个,用笔或铅笔手动书写,而不是用机器打印。 手写数字的外观可能会有很大差异。 不同的人有不同的笔迹,并且-一个熟练的书法家可能会例外-一个人每次书写都不会产生相同的数字。 这种可变性意味着手写数字的视觉识别对于机器学习来说是一个不小的问题。 确实,机器学习的学生和研究人员经常通过尝试训练手写数字的准确识别器来测试他们的技能和新算法。 我们将通过以下方式应对这一挑战:
- 从 MNIST 数据库的 Python 友好版本加载数据。 这是一个广泛使用的数据库,其中包含手写数字的图像。
- 使用 MNIST 数据,在多个周期训练 ANN。
- 加载一张纸上有许多手写数字的图像。
- 基于轮廓分析,检测纸张上的各个数字。
- 使用我们的人工神经网络对检测到的数字进行分类。
- 查看结果,以确定我们的探测器和基于 ANN 的分类器的准确率。
在深入研究实现之前,让我们回顾一下有关 MNIST 数据库的信息。
了解 MNIST 手写数字数据库
可在这个页面上公开获得 MNIST 数据库(或美国国家标准混合技术研究院数据库)。该数据库包括一个包含 60,000 个手写数字图像的训练集。 其中一半是由美国人口普查局的雇员撰写的,而另一半是由美国的高中生撰写的。
该数据库还包括从同一作者那里收集的 10,000 张图像的测试集。 所有训练和测试图像均为灰度格式,尺寸为28 x 28像素。 在黑色背景上,数字为白色(或灰色阴影)。 例如,以下是 MNIST 训练样本中的三个:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-AkdubCnU-1681871605272)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/learn-opencv4-cv-py3/img/aafb1f29-c71f-488d-8696-2307830f5cea.png)]
作为使用 MNIST 的替代方法,您当然可以自己构建一个类似的数据库。 这将涉及收集大量手写数字的图像,将图像转换为灰度图像,对其进行裁剪以使每个图像在标准化位置均包含一个数字,然后缩放图像以使它们都具有相同的大小。 您还需要标记图像,以便程序可以读取正确的分类,以训练和测试分类器。
许多作者提供了有关如何将 MNIST 数据库与各种机器学习库和算法结合使用的示例-不仅是 OpenCV,还不仅仅是 ANN。 免费在线书籍《神经网络和深度学习》的作者 Michael Nielsen 在这里为 MNIST 和 ANN 专门撰写了一章。 他展示了如何仅使用 NumPy 几乎从头开始实现 ANN,如果您想加深对 OpenCV 公开的高级功能的了解,那么这是一本非常好的读物。 他的代码可在 GitHub 上免费获得。
Nielsen 提供了 MNIST 版本,为PKL.GZ(gzip 压缩的 Pickle)文件,可以轻松地将其加载到 Python 中。 出于本书 OpenCV 示例的目的,我们(作者)采用了 Nielsen 的 MNIST 的PKL.GZ版本,为我们的目的对其进行了重组,并将其放置在本书的chapter10/digits_data/mnist.pkl.gz的 GitHub 存储库中。
既然我们已经了解了 MNIST 数据库,那么让我们考虑一下适合该训练集的 ANN 参数。
为 MNIST 数据库选择训练参数
每个 MNIST 样本都是一个包含 784 像素(即28 x 28像素)的图像。 因此,我们的人工神经网络的输入层将具有 784 个节点。 输出层将有 10 个节点,因为有 10 类数字(0 到 9)。
我们可以自由选择其他参数的值,例如隐藏层中的节点数,要使用的训练样本数以及训练周期数。 与往常一样,实验可以帮助我们找到可提供可接受的训练时间和准确率的值,而不会使模型过度适合训练数据。 根据本书作者所做的一些实验,我们将使用 60 个隐藏节点,50,000 个训练样本和 10 个周期。 这些参数足以进行初步测试,将训练时间缩短至几分钟(取决于计算机的处理能力)。
实现训练 ANN 的模块
您也可能希望在未来的项目中基于 MNIST 训练 ANN。 为了使我们的代码更具可重用性,我们可以编写一个专门用于此训练过程的 Python 模块。 然后(在下一节“实现主模块”中),我们将把这个训练模块导入到主模块中,在这里我们将进行数字检测和分类的演示。
让我们在名为digits_ann.py的文件中实现训练模块:
- 首先,我们将从 Python 标准库中导入
gzip和pickle模块。 和往常一样,我们还将导入 OpenCV 和 NumPy:
import gzip
import pickle
import cv2
import numpy as np
我们将使用gzip和pickle模块解压缩并从mnist.pkl.gz文件中加载 MNIST 数据。 我们之前在“了解 MNIST 手写数字数据库”部分中简要提到了此文件。 它包含嵌套元组中的 MNIST 数据,格式如下:
((training_images, training_ids),
(test_images, test_ids))
反过来,这些元组的元素具有以下格式:
- 让我们编写以下帮助函数来解压缩并加载
mnist.pkl.gz的内容:
def load_data():
mnist = gzip.open('./digits_data/mnist.pkl.gz', 'rb')
training_data, test_data = pickle.load(mnist)
mnist.close()
return (training_data, test_data)
注意,在前面的代码中,training_data是一个元组,等效于(training_images, training_ids),test_data也是一个元组,等效于(test_images, test_ids)。
- 我们必须重新格式化原始数据,以匹配 OpenCV 期望的格式。 具体来说,当我们提供用于训练 ANN 的样本输出时,它必须是具有 10 个元素(用于 10 类数字)的向量,而不是单个数字 ID。 为方便起见,我们还将应用 Python 内置的
zip函数以一种可以对匹配的输入和输出向量对(如元组)进行迭代的方式来重组数据。 让我们编写以下辅助函数来重新格式化数据:
def wrap_data():
tr_d, te_d = load_data()
training_inputs = tr_d[0]
training_results = [vectorized_result(y) for y in tr_d[1]]
training_data = zip(training_inputs, training_results)
test_data = zip(te_d[0], te_d[1])
return (training_data, test_data)
- 请注意,前面的代码调用
load_data和另一个帮助函数vectorized_result。 后者将 ID 转换为分类向量,如下所示:
def vectorized_result(j):
e = np.zeros((10,), np.float32)
e[j] = 1.0
return e
例如,将 ID 1转换为包含值[0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0\. 0.0]的 NumPy 数组。 您可能已经猜到,这个由 10 个元素组成的数组对应于 ANN 的输出层,我们在训练 ANN 时可以将其用作正确输出的样本。
先前的函数load_data,wrap_data和vectorized_result已从 Nielsen 的代码中进行了修改,以加载他的mnist.pkl.gz版本。 有关 Nielsen 的工作的更多信息,请参阅本章的“了解 MNIST 手写数字数据库”部分。
- 到目前为止,我们已经编写了用于加载和重新格式化 MNIST 数据的函数。 现在,让我们编写一个函数来创建未经训练的 ANN:
def create_ann(hidden_nodes=60):
ann = cv2.ml.ANN_MLP_create()
ann.setLayerSizes(np.array([784, hidden_nodes, 10]))
ann.setActivationFunction(cv2.ml.ANN_MLP_SIGMOID_SYM, 0.6, 1.0)
ann.setTrainMethod(cv2.ml.ANN_MLP_BACKPROP, 0.1, 0.1)
ann.setTermCriteria(
(cv2.TERM_CRITERIA_MAX_ITER | cv2.TERM_CRITERIA_EPS,
100, 1.0))
return ann
请注意,我们已经根据 MNIST 数据的性质对输入和输出层的大小进行了硬编码。 但是,我们允许此函数的调用者指定隐藏层中的节点数。
有关参数的进一步讨论,请参考本章“选择 MNIST 数据库的训练参数”。
- 现在,我们需要一个训练函数,允许调用者指定 MNIST 训练样本的数量和周期的数量。 我们以前的 ANN 样本应该熟悉很多训练函数,因此让我们看一下整个实现,然后再讨论一些细节:
def train(ann, samples=50000, epochs=10):
tr, test = wrap_data()
# Convert iterator to list so that we can iterate multiple
# times in multiple epochs.
tr = list(tr)
for epoch in range(epochs):
print("Completed %d/%d epochs" % (epoch, epochs))
counter = 0
for img in tr:
if (counter > samples):
break
if (counter % 1000 == 0):
print("Epoch %d: Trained on %d/%d samples" % \
(epoch, counter, samples))
counter += 1
sample, response = img
data = cv2.ml.TrainData_create(
np.array([sample], dtype=np.float32),
cv2.ml.ROW_SAMPLE,
np.array([response], dtype=np.float32))
if ann.isTrained():
ann.train(data, cv2.ml.ANN_MLP_UPDATE_WEIGHTS | cv2.ml.ANN_MLP_NO_INPUT_SCALE | cv2.ml.ANN_MLP_NO_OUTPUT_SCALE)
else:
ann.train(data, cv2.ml.ANN_MLP_NO_INPUT_SCALE | cv2.ml.ANN_MLP_NO_OUTPUT_SCALE)
print("Completed all epochs!")
return ann, test
请注意,我们加载数据,然后通过迭代指定数量的训练周期(每个周期中都有指定数量的样本)来递增地训练 ANN。 对于我们处理的每 1,000 个训练样本,我们会打印一条有关训练进度的消息。 最后,我们同时返回经过训练的 ANN 和 MNIST 测试数据。 我们可能刚刚返回了 ANN,但是如果我们想检查 ANN 的准确率,则手头准备测试数据会很有用。
- 当然,经过训练的 ANN 的目的是进行预测,因此我们将提供以下
predict函数,以便包装 ANN 自己的predict方法:
def predict(ann, sample):
if sample.shape != (784,):
if sample.shape != (28, 28):
sample = cv2.resize(sample, (28, 28),
interpolation=cv2.INTER_LINEAR)
sample = sample.reshape(784,)
return ann.predict(np.array([sample], dtype=np.float32))
该函数获取训练有素的人工神经网络和样本图像; 它通过确保样本图像为28 x 28并通过调整大小(如果不是)来执行最少的数据清理。 然后,它将图像数据展平为向量,然后再将其提供给 ANN 进行分类。
这就是我们支持演示应用所需的所有与 ANN 相关的函数。 但是,让我们还实现一个test函数,该函数通过对一组给定的测试数据(例如 MNIST 测试数据)进行分类来测量经过训练的 ANN 的准确率。 以下是相关代码:
def test(ann, test_data):
num_tests = 0
num_correct = 0
for img in test_data:
num_tests += 1
sample, correct_digit_class = img
digit_class = predict(ann, sample)[0]
if digit_class == correct_digit_class:
num_correct += 1
print('Accuracy: %.2f%%' % (100.0 * num_correct / num_tests))
现在,让我们走一小段弯路,编写一个利用所有前面的代码和 MNIST 数据集的最小测试。 之后,我们将继续实现演示应用的主要模块。
实现最小的测试模块
让我们创建另一个脚本test_digits_ann.py,以测试digits_ann模块中的功能。 测试脚本非常简单; 这里是:
from digits_ann import create_ann, train, test
ann, test_data = train(create_ann())
test(ann, test_data)
请注意,我们尚未指定隐藏节点的数量,因此create_ann将使用其默认参数值:60 个隐藏节点。 同样,train将使用其默认参数值:50,000 个样本和 10 个周期。
当我们运行此脚本时,它应打印类似于以下内容的训练和测试信息:
Completed 0/10 epochs
Epoch 0: Trained on 0/50000 samples
Epoch 0: Trained on 1000/50000 samples
... [more reports on progress of training] ...
Completed all epochs!
Accuracy: 95.39%
在这里,我们可以看到,对 MNIST 数据集中的 10,000 个测试样本进行分类时,ANN 的准确率达到了 95.39%。 这是一个令人鼓舞的结果,但让我们看一下 ANN 的概括程度。 是否可以对来自与 MNIST 无关的完全不同来源的数据进行准确分类? 我们的主要应用会从我们自己的一张纸的图像中检测数字,这将给分类器带来这种挑战。
实现主要模块
我们的演示程序的主要脚本吸收了本章中有关 ANN 和 MNIST 的所有知识,并将其与我们在前几章中研究的一些对象检测技术相结合。 因此,从很多方面来说,这对我们来说都是一个顶点项目。
让我们在名为detect_and_classify_digits.py的新文件中实现主脚本:
- 首先,我们将导入 OpenCV,NumPy 和我们的
digits_ann模块:
import cv2
import numpy as np
import digits_ann
- 现在,让我们编写一些辅助函数来分析和调整数字和其他轮廓的边界矩形。 如前几章所述,重叠检测是一个常见问题。 以下称为
inside的函数将帮助我们确定一个边界矩形是否完全包含在另一个边界矩形内:
def inside(r1, r2):
x1, y1, w1, h1 = r1
x2, y2, w2, h2 = r2
return (x1 > x2) and (y1 > y2) and (x1+w1 < x2+w2) and \
(y1+h1 < y2+h2)
借助inside函数,我们将能够轻松地为每个数字选择最外面的矩形。 这很重要,因为我们不希望检测器遗漏任何手指的四肢。 这样的检测错误可能使分类器的工作变得不可能。 例如,如果我们仅检测到数字的下半部分 8,则分类器可能会合理地将该区域视为 0。
为了进一步确保边界矩形满足分类器的需求,我们将使用另一个名为wrap_digit的辅助函数,将紧密拟合的边界矩形转换为带有围绕数字填充的正方形。 请记住,MNIST 数据包含28 x 28像素的数字正方形图像,因此在尝试使用 MNIST 训练的 ANN 对其进行分类之前,我们必须将任何兴趣区域重新缩放至此大小。 通过使用填充的边界正方形而不是紧密拟合的边界矩形,我们确保骨感数字(例如 1)和粗体数字(例如 0)不会不同地拉伸。
- 让我们看一下
wrap_digit的实现。 首先,我们修改矩形的较小尺寸(宽度或高度),使其等于较大尺寸,然后修改矩形的x或y位置,以使中心保持不变:
def wrap_digit(rect, img_w, img_h):
x, y, w, h = rect
x_center = x + w//2
y_center = y + h//2
if (h > w):
w = h
x = x_center - (w//2)
else:
h = w
y = y_center - (h//2)
- 接下来,我们在所有侧面添加 5 像素填充:
padding = 5
x -= padding
y -= padding
w += 2 * padding
h += 2 * padding
在这一点上,我们修改后的矩形可能会延伸到图像外部。
- 为了避免超出范围的问题,我们对矩形进行裁剪,使其完全位于图像内。 在这些边缘情况下,这可能会给我们留下非正方形的矩形,但这是可以接受的折衷方案。 我们宁愿使用感兴趣的非正方形区域,而不是仅仅因为它位于图像的边缘而完全抛弃检测到的数字。 这是用于边界检查和裁剪矩形的代码:
if x < 0:
x = 0
elif x > img_w:
x = img_w
if y < 0:
y = 0
elif y > img_h:
y = img_h
if x+w > img_w:
w = img_w - x
if y+h > img_h:
h = img_h - y
- 最后,我们返回修改后的矩形的坐标:
return x, y, w, h
到此结束wrap_digit辅助函数的实现。
- 现在,让我们进入程序的主要部分。 在这里,我们首先创建一个 ANN 并在 MNIST 数据上对其进行训练:
ann, test_data = digits_ann.train(
digits_ann.create_ann(60), 50000, 10)
请注意,我们正在使用digits_ann模块中的create_ann和train函数。 如前所述(“在 MNIST 数据库中选择参数”),我们正在使用 60 个隐藏节点,50,000 个训练样本和 10 个周期。 尽管这些是函数的默认参数值,但无论如何我们还是在这里指定它们,以便以后我们想尝试其他值时更易于查看和修改。*
- 现在,让我们在一张白纸上加载一个包含许多手写数字的测试图像:
img_path = "./digit_https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/learn-opencv4-cv-py3/img/digits_0.jpg"
img = cv2.imread(img_path, cv2.IMREAD_COLOR)
我们使用的是乔·米尼诺(Joe Minichino)手写的以下图像(但是,当然,您可以根据需要替换其他图像):
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nGjbEM6f-1681871605272)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/learn-opencv4-cv-py3/img/5bac9c25-a8d2-4f07-9238-d7e5998374be.jpg)]
- 让我们将图像转换为灰度并使其模糊,以消除噪点并使墨水的暗度更加均匀:
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
cv2.GaussianBlur(gray, (7, 7), 0, gray)
- 现在我们有了一个平滑的灰度图像,我们可以应用一个阈值和一些形态学操作,以确保数字与背景脱颖而出,并且轮廓相对没有不规则性,这可能会超出预测。 以下是相关代码:
ret, thresh = cv2.threshold(gray, 127, 255, cv2.THRESH_BINARY_INV)
erode_kernel = np.ones((2, 2), np.uint8)
thresh = cv2.erode(thresh, erode_kernel, thresh, iterations=2)
注意阈值标志cv2.THRESH_BINARY_INV,它是反二进制阈值。 由于 MNIST 数据库中的样本是黑底白字(而不是黑底白字),因此我们将图像转换为带有白色数字的黑色背景。 我们将阈值图像用于检测和分类。
- 进行形态学操作后,我们需要分别检测图片中的每个数字。 为此,首先,我们需要找到轮廓:
contours, hier = cv2.findContours(thresh, cv2.RETR_TREE,
cv2.CHAIN_APPROX_SIMPLE)
- 然后,我们遍历轮廓并找到其边界矩形。 我们丢弃任何我们认为太大或太小而无法数字化的矩形。 我们还将丢弃完全包含在其他矩形中的所有矩形。 其余的矩形将追加到一个良好的矩形列表中(我们相信),这些矩形包含单个数字。 让我们看下面的代码片段:
rectangles = []
img_h, img_w = img.shape[:2]
img_area = img_w * img_h
for c in contours:
a = cv2.contourArea(c)
if a >= 0.98 * img_area or a <= 0.0001 * img_area:
continue
r = cv2.boundingRect(c)
is_inside = False
for q in rectangles:
if inside(r, q):
is_inside = True
break
if not is_inside:
rectangles.append(r)
- 现在我们有了一个好的矩形列表,可以遍历它们,使用
wrap_digit函数对它们进行清理,并对其中的图像数据进行分类:
for r in rectangles:
x, y, w, h = wrap_digit(r, img_w, img_h)
roi = thresh[y:y+h, x:x+w]
digit_class = int(digits_ann.predict(ann, roi)[0])
- 此外,在对每个数字进行分类之后,我们绘制了经过清理的边界矩形和分类结果:
cv2.rectangle(img, (x,y), (x+w, y+h), (0, 255, 0), 2)
cv2.putText(img, "%d" % digit_class, (x, y-5),
cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 0, 0), 2)
- 处理完所有兴趣区域后,我们将保存阈值图像和带有完整标注的图像,并显示它们,直到用户按下任何键以结束程序为止:
cv2.imwrite("detected_and_classified_digits_thresh.png", thresh)
cv2.imwrite("detected_and_classified_digits.png", img)
cv2.imshow("thresh", thresh)
cv2.imshow("detected and classified digits", img)
cv2.waitKey()
脚本到此结束。 运行它时,我们应该看到阈值图像以及检测和分类结果的可视化。 (最初两个窗口可能重叠,因此您可能需要移动一个窗口才能看到另一个窗口。)这是阈值图像:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-k2Y1moA6-1681871605272)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/learn-opencv4-cv-py3/img/92d5e988-1408-45b1-922e-a5b78068deeb.png)]
这是结果的可视化:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cHubVUQr-1681871605273)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/learn-opencv4-cv-py3/img/e2a4e4cd-f574-49cb-a452-0a70c4d37ab0.png)]
该图像包含 110 个采样位:从 0 到 9 的一位数字中的 10 位,再加上从 10 到 59 的两位数字中的 100 位。在这 110 个采样中,可以正确检测到 108 个采样的边界,这意味着,探测器的准确率为 98.18%。 然后,在这 108 个正确检测的样本中,对 80 个样本的分类结果是正确的,这意味着 ANN 分类器的准确率为 74.07%。 这比随机分类器要好得多,后者只能在 10% 的时间内正确分类一个数字。
因此,ANN 显然能够学习一般地对手写数字进行分类,而不仅仅是 MNIST 训练和测试数据集中的数字。 让我们考虑一些改善学习的方法。
试图改善人工神经网络的训练
我们可以对训练 ANN 的问题进行一些潜在的改进。 我们已经提到了其中一些潜在的改进,但让我们在这里进行回顾:
- 您可以尝试训练数据集的大小,隐藏节点的数量和周期的数量,直到找到最高的准确率。
- 您可以修改
digits_ann.create_ann函数,使其支持多个隐藏层。 - 您也可以尝试其他激活函数。 我们使用了
cv2.ml.ANN_MLP_SIGMOID_SYM,但这不是唯一的选择。 其他包括cv2.ml.ANN_MLP_IDENTITY,cv2.ml.ANN_MLP_GAUSSIAN,cv2.ml.ANN_MLP_RELU和cv2.ml.ANN_MLP_LEAKYRELU。 - 同样,您可以尝试不同的训练方法。 我们使用了
cv2.ml.ANN_MLP_BACKPROP。 其他选项包括cv2.ml.ANN_MLP_RPROP和cv2.ml.ANN_MLP_ANNEAL。
有关 OpenCV 中与 ANN 相关的参数的更多信息,请访问这个页面上的官方文档。
除了试验参数外,请仔细考虑您的应用需求。 例如,您的分类器将在哪里和由谁使用? 并非每个人都以相同的方式绘制数字。 确实,不同国家的人们倾向于以略有不同的方式得出数字。
MNIST 数据库是在美国编译的,数字 7 与手写字符 7 一样是手写的。但是,在欧洲,数字 7 通常是用数字的对角线部分中间的一条小水平线手写的。 引入此笔划是为了帮助区分手写数字 7 和手写数字 1。
有关区域手写变化的更详细概述,请查看 Wikipedia 上有关该主题的文章,这是一个很好的介绍,可在这个页面上找到。
这种变化意味着在 MNIST 数据库上训练的 ANN 在应用于欧洲手写数字的分类时可能不太准确。 为了避免这样的结果,您可以选择创建自己的训练数据集。 在几乎所有情况下,最好利用属于当前应用域的训练数据。
最后,请记住,一旦对分类器的准确率感到满意,就可以随时将其保存并稍后重新加载,这样它就可以在应用中使用,而不必每次都训练 ANN。
该界面类似于在“保存和加载受过训练的 SVM”部分中看到的接口,该部分接近第 7 章,“构建自定义对象检测器”。 具体来说,您可以使用以下代码将经过训练的 ANN 保存到 XML 文件:
ann = cv2.ml.ANN_MLP_create()
data = cv2.ml.TrainData_create(
training_samples, layout, training_responses)
ann.train(data)
ann.save('my_ann.xml')
随后,您可以使用如下代码重新加载经过训练的 ANN:
ann = cv2.ml.ANN_MLP_create()
ann.load('my_ann.xml')
既然我们已经学习了如何为手写数字分类创建可重用的 ANN,让我们考虑一下这种分类器的用例。
寻找其他潜在的应用
前面的演示仅是手写识别应用的基础。 您可以轻松地将方法扩展到视频并实时检测手写数字,也可以训练 ANN 识别整个字母,以实现完整的光学字符识别(OCR)系统。
汽车牌照的检测和识别将是到目前为止我们所学课程的另一个有用的扩展。 车牌上的字符具有一致的外观(至少在给定的国家/地区内),这应该是问题的 OCR 部分的简化因素。
您也可以尝试将 ANN 应用于以前使用过 SVM 的问题,反之亦然。 这样,您可以看到它们的准确率如何与不同类型的数据进行比较。 回想一下,在第 7 章,“构建自定义对象检测器”中,我们使用 SIFT 描述符作为 SVM 的输入。 同样,人工神经网络能够处理高级描述符,而不仅仅是普通的旧像素数据。
如我们所见,cv2.ml_ANN_MLP类用途广泛,但实际上,它仅涵盖了 ANN 设计方法的一小部分。 接下来,我们将了解 OpenCV 对更复杂的深度神经网络(DNN)的支持,这些网络可以通过其他各种框架进行训练。
在 OpenCV 中使用其他框架的 DNN
OpenCV 可以加载和使用在以下任何框架中经过训练的 DNN:
- Caffe
- TensorFlow
- Torch
- Darknet
- ONNX
- DLDT
深度学习部署工具包(DLDT)是英特尔 OpenVINO 工具包的一部分。 DLDT 提供了用于优化其他框架中的 DNN 并将其转换为通用格式的工具。 兼容 DLDT 的模型的集合可在称为开放模型动物园的存储库中免费获得。 DLDT,开放模型动物园和 OpenCV 在其开发团队中拥有一些相同的人。 这三个项目均由英特尔赞助。
这些框架使用各种文件格式来存储经过训练的 DNN。 其中一些框架使用了一对文件格式的组合:一个用于描述模型参数的文本文件,以及一个用于存储模型本身的二进制文件。 以下代码段显示了与从每个框架加载模型相关的文件类型和 OpenCV 函数:
caffe_model = cv2.dnn.readNetFromCaffe(
'my_model_description.protext', 'my_model.caffemodel')
tensor_flow_model = cv2.dnn.readNetFromTensorflow(
'my_model.pb', 'my_model_description.pbtxt')
# Some Torch models use the .t7 extension and others use
# the .net extension.
torch_model_0 = cv2.dnn.readNetFromTorch('my_model.t7')
torch_model_1 = cv2.dnn.readNetFromTorch('my_model.net')
darknet_model = cv2.dnn.readNetFromDarket(
'my_model_description.cfg', 'my_model.weights')
onnx_model = cv2.dnn.readNetFromONNX('my_model.onnx')
dldt_model = cv2.dnn.readNetFromModelOptimizer(
'my_model_description.xml', 'my_model.bin')
加载模型后,我们需要预处理将用于模型的数据。 必要的预处理特定于给定 DNN 的设计和训练方式,因此,每当我们使用第三方 DNN 时,我们都必须了解该 DNN 的设计和训练方式。 OpenCV 提供了cv2.dnn.blobFromImage函数,该函数可以执行一些常见的预处理步骤,具体取决于我们传递给它的参数。 在将数据传递给此函数之前,我们可以手动执行其他预处理步骤。
神经网络的输入向量有时称为张量或 Blob,因此称为函数名称cv2.dnn.blobFromImage。
让我们继续来看一个实际的示例,在该示例中,我们将看到第三方 DNN 的运行。
使用第三方 DNN 检测和分类对象
对于此演示,我们将实时捕获来自网络摄像头的帧,并使用 DNN 来检测和分类任何给定帧中可能存在的 20 种对象。 是的,单个 DNN 可以在程序员可能使用的典型笔记本电脑上实时完成所有这些操作!
在深入研究代码之前,让我们介绍一下我们将使用的 DNN。 它是称为 MobileNet-SSD 的模型的 Caffe 版本,它使用 Google 的 MobileNet 框架与另一个称为单发检测器(SSD)MultiBox。 后一个框架在这个页面上有一个 GitHub 存储库。 Caffe 版本的 MobileNet-SSD 的训练技术由 GitHub 上的一个项目提供。 可以在本书的存储库中的chapter10/objects_data文件夹中找到以下 MobileNet-SSD 文件的副本:
MobileNetSSD_deploy.caffemodel:这是模型。MobileNetSSD_deploy.prototxt:这是描述模型参数的文本文件。
随着我们的示例代码的进行,该模型的功能和正确用法将很快变得清晰起来:
- 与往常一样,我们首先导入 OpenCV 和 NumPy:
import cv2
import numpy as np
- 我们以上一节中介绍的相同方式继续使用 OpenCV 加载 Caffe 模型:
model = cv2.dnn.readNetFromCaffe(
'objects_data/MobileNetSSD_deploy.prototxt',
'objects_data/MobileNetSSD_deploy.caffemodel')
- 我们需要定义一些特定于该模型的预处理参数。 它期望输入图像为 300 像素高。 此外,它期望图像中的像素值在 -1.0 到 1.0 的范围内。 这意味着相对于从 0 到 255 的通常标度,有必要减去 127.5,然后除以 127.5。 我们将参数定义如下:
blob_height = 300
color_scale = 1.0/127.5
average_color = (127.5, 127.5, 127.5)
- 我们还定义了一个置信度阈值,表示为了将检测作为真实对象而需要的最低置信度得分:
confidence_threshold = 0.5
- 该模型支持 20 类对象,其 ID 为 1 到 20(而不是 0 到 19)。 这些类的标签可以定义如下:
labels = ['airplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus',
'car', 'cat', 'chair', 'cow', 'dining table', 'dog',
'horse', 'motorbike', 'person', 'potted plant', 'sheep',
'sofa', 'train', 'TV or monitor']
稍后,当我们使用类 ID 在列表中查找标签时,必须记住从 ID 中减去 1,以获得 0 到 19(而不是 1 到 20)范围内的索引。
有了模型和参数,我们准备开始捕获帧。
- 对于每一帧,我们首先计算纵横比。 请记住,此 DNN 期望输入基于 300 像素高的图像; 但是,宽度可以变化以匹配原始的宽高比。 以下代码段显示了如何捕获帧并计算适当的输入大小:
cap = cv2.VideoCapture(0)
success, frame = cap.read()
while success:
h, w = frame.shape[:2]
aspect_ratio = w/h
# Detect objects in the frame.
blob_width = int(blob_height * aspect_ratio)
blob_size = (blob_width, blob_height)
- 此时,我们可以简单地使用
cv2.dnn.blobFromImage函数及其几个可选参数来执行必要的预处理,包括调整帧的大小并将其像素数据转换为 -1.0 到 1.0 的比例:
blob = cv2.dnn.blobFromImage(
frame, scalefactor=color_scale, size=blob_size,
mean=average_color)
- 我们将生成的 Blob 馈送到 DNN 并获取模型的输出:
model.setInput(blob)
results = model.forward()
结果是一个数组,其格式特定于我们使用的模型。
- 对于此对象检测 DNN(以及使用 SSD 框架训练的其他 DNN),结果包括检测到的对象的子数组,每个对象都有自己的置信度得分,矩形坐标和类 ID。 以下代码显示了如何访问它们,以及如何使用 ID 在我们先前定义的列表中查找标签:
# Iterate over the detected objects.
for object in results[0, 0]:
confidence = object[2]
if confidence > confidence_threshold:
# Get the object's coordinates.
x0, y0, x1, y1 = (object[3:7] * [w, h, w, h]).astype(int)
# Get the classification result.
id = int(object[1])
label = labels[id - 1]
- 遍历检测到的对象时,我们绘制检测矩形,分类标签和置信度得分:
# Draw a blue rectangle around the object.
cv2.rectangle(frame, (x0, y0), (x1, y1),
(255, 0, 0), 2)
# Draw the classification result and confidence.
text = '%s (%.1f%%)' % (label, confidence * 100.0)
cv2.putText(frame, text, (x0, y0 - 20),
cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 0, 0), 2)
- 我们对框架所做的最后一件事就是展示它。 然后,如果用户按下
Esc键,则退出; 否则,我们将捕获另一帧并继续循环的下一个迭代:
cv2.imshow('Objects', frame)
k = cv2.waitKey(1)
if k == 27: # Escape
break
success, frame = cap.read()
如果插入网络摄像头并运行脚本,则应该看到检测结果和分类结果的可视化图像,并实时更新。 这是一个截图,显示约瑟夫·豪斯和萨尼贝尔·德尔菲姆·安德洛梅达(一只强大,善良和公义的猫)在加拿大一个渔村的客厅中:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-B3PHAD0g-1681871605273)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/learn-opencv4-cv-py3/img/ad4e5406-cd70-4be5-850b-8949888fe547.png)]
DNN 已正确检测并分类了人类人(置信度为 99.4%),猫(85.4%),装饰性瓶子(72.1%),并进行了分类, 沙发的一部分(61.2%),以及船的纺织品图片(52.0%)。 显然,该 DNN 能够很好地对航海环境中的客厅进行分类!
这只是 DNN 可以做的事情的第一手–实时! 接下来,让我们看看通过在一个应用中组合三个 DNN 可以实现什么。
使用第三方 DNN 检测和分类人脸
在此演示中,我们将使用一个 DNN 来检测面部,并使用另外两个 DNN 来分类每个检测到的面部的年龄和性别。 具体来说,我们将使用预先训练的 Caffe 模型,这些模型存储在本书 GitHub 存储库的chapter10/faces_data文件夹中的以下文件中。
以下是此文件夹中文件的清单以及这些文件的来源:
detection/res10_300x300_ssd_iter_140000.caffemodel:这是用于人脸检测的 DNN。 OpenCV 团队已在这个页面提供了此文件。 这个 Caffe 模型是使用 SSD 框架训练的。 因此,它的拓扑类似于上一节示例中使用的 MobileNet-SSD 模型。detection/deploy.prototxt:这是文本文件,描述了用于人脸检测的先前 DNN 的参数。 OpenCV 团队在这个页面提供此文件。
chapter10/faces_data/age_gender_classification文件夹包含以下文件,这些文件均由 Gil Levi 和 Tal Hassner 在其 GitHub 存储库中及其项目页面上提供,他们在年龄和性别分类方面的工作:
age_net.caffemodel:这是用于年龄分类的 DNN。age_net_deploy.protext:这是文本文件,描述了用于年龄分类的先前 DNN 的参数。gender_net.caffemodel:这是用于性别分类的 DNN。gender_net_deploy.protext:这是文本文件,描述了用于年龄分类的先前 DNN 的参数。average_face.npy和average_face.png:这些文件表示分类器训练数据集中的平均面孔。 来自 Levi 和 Hassner 的原始文件称为mean.binaryproto,但我们已将其转换为 NumPy 可读格式和标准图像格式,这对于我们的使用更加方便。
让我们看看如何在代码中使用所有这些文件:
- 为了开始示例程序,我们加载人脸检测 DNN,定义其参数,并定义置信度阈值。 我们以与上一节样本中的对象检测 DNN 大致相同的方式执行此操作:
import cv2
import numpy as np
face_model = cv2.dnn.readNetFromCaffe(
'faces_data/detection/deploy.prototxt',
'faces_data/detection/res10_300x300_ssd_iter_140000.caffemodel')
face_blob_height = 300
face_average_color = (104, 177, 123)
face_confidence_threshold = 0.995
我们不需要为此 DNN 定义标签,因为它不执行任何分类。 它只是预测面矩形的坐标。
- 现在,让我们加载年龄分类器并定义其分类标签:
age_model = cv2.dnn.readNetFromCaffe(
'faces_data/age_gender_classification/age_net_deploy.prototxt',
'faces_data/age_gender_classification/age_net.caffemodel')
age_labels = ['0-2', '4-6', '8-12', '15-20',
'25-32', '38-43', '48-53', '60+']
请注意,在此模型中,年龄标签之间存在间隙。 例如,'0-2'后跟'4-6'。 因此,如果一个人实际上是 3 岁,则分类器没有适合这种情况的标签; 最多可以选择'0-2'或'4-6'之一。 大概是,模型的作者有意选择了不连续的范围,以确保类别相对于输入而言是可分离的。 让我们考虑替代方案。 根据面部图像中的数据,是否可以将 4 岁以下的人群与每天 4 岁以下的人群分开? 当然不是。 他们看起来一样。 因此,根据连续的年龄范围来制定分类问题是错误的。 可以训练 DNN 将年龄预测为连续变量(例如,浮点数的年数),但这与分类器完全不同,分类器预测各个类别的置信度得分。
- 现在,让我们加载性别分类器并定义其标签:
gender_model = cv2.dnn.readNetFromCaffe(
'faces_data/age_gender_classification/gender_net_deploy.prototxt',
'faces_data/age_gender_classification/gender_net.caffemodel')
gender_labels = ['male', 'female']
- 年龄和性别分类器使用相同的 Blob 大小和相同的平均值。 他们使用的不是平均颜色,而是平均颜色的人脸图像,我们将从
NPY文件中加载该图像(作为浮点格式的 NumPy 数组)。 稍后,我们将在执行分类之前从实际的面部图像中减去该平均面部图像。 以下是斑点大小和平均图像的定义:
age_gender_blob_size = (256, 256)
age_gender_average_image = np.load(
'faces_data/age_gender_classification/average_face.npy')
如果要查看普通脸的外观,请打开chapter10/faces_data/age_gender_classification/average_face.png的文件,该文件包含标准图像格式的相同数据。 这里是:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3l1E2MOd-1681871605273)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/learn-opencv4-cv-py3/img/3bc621b4-edb4-4462-8520-68e5ad9014b3.png)]
当然,这只是特定训练数据集的平均面孔。 它不一定代表世界人口或任何特定国家或社区的真实平均面孔。 即使这样,在这里,我们仍可以看到一张由许多面孔组成的模糊面孔,并且没有明显的年龄或性别线索。 请注意,该图像是方形的,以鼻子的尖端为中心,并且从前额的顶部垂直延伸到颈部的底部。 为了获得准确的分类结果,我们应注意将此分类器应用于以相同方式裁剪的面部图像。
- 设置好模型及其参数后,让我们继续从相机捕获和处理帧。 对于每一帧,我们首先创建一个与帧相同的宽高比的 blob,然后将此 blob 馈送到人脸检测 DNN:
cap = cv2.VideoCapture(0)
success, frame = cap.read()
while success:
h, w = frame.shape[:2]
aspect_ratio = w/h
# Detect faces in the frame.
face_blob_width = int(face_blob_height * aspect_ratio)
face_blob_size = (face_blob_width, face_blob_height)
face_blob = cv2.dnn.blobFromImage(
frame, size=face_blob_size, mean=face_average_color)
face_model.setInput(face_blob)
face_results = face_model.forward()
- 就像我们在上一部分示例中使用的对象检测器一样,人脸检测器提供置信度得分和矩形坐标作为结果的一部分。 对于每个检测到的面部,我们需要检查置信度得分是否可以接受地高,如果是,则将获得面部矩形的坐标:
# Iterate over the detected faces.
for face in face_results[0, 0]:
face_confidence = face[2]
if face_confidence > face_confidence_threshold:
# Get the face coordinates.
x0, y0, x1, y1 = (face[3:7] * [w, h, w, h]).astype(int)
- 此人脸检测 DNN 生成的矩形长于宽度。 但是,DNN 的年龄和性别分类要求使用方形面孔。 让我们加宽检测到的脸部矩形以使其成为正方形:
# Classify the age and gender of the face based on a
# square region of interest that includes the neck.
y1_roi = y0 + int(1.2*(y1-y0))
x_margin = ((y1_roi-y0) - (x1-x0)) // 2
x0_roi = x0 - x_margin
x1_roi = x1 + x_margin
if x0_roi < 0 or x1_roi > w or y0 < 0 or y1_roi > h:
# The region of interest is partly outside the
# frame. Skip this face.
continue
请注意,如果正方形的一部分落在图像的边界之外,我们将跳过此检测结果并继续进行下一个检测。
- 此时,我们可以选择正方形兴趣区域(ROI),其中包含将用于年龄和性别分类的图像数据。 我们将 ROI 缩放到分类器的斑点大小,将其转换为浮点格式,然后减去平均脸部。 根据生成的缩放后的标准化脸部,创建斑点:
age_gender_roi = frame[y0:y1_roi, x0_roi:x1_roi]
scaled_age_gender_roi = cv2.resize(
age_gender_roi, age_gender_blob_size,
interpolation=cv2.INTER_LINEAR).astype(np.float32)
scaled_age_gender_roi[:] -= age_gender_average_image
age_gender_blob = cv2.dnn.blobFromImage(
scaled_age_gender_roi, size=age_gender_blob_size)
- 我们将斑点输入年龄分类器,选择具有最高置信度得分的类 ID,然后记下该 ID 的标签和置信度得分:
age_model.setInput(age_gender_blob)
age_results = age_model.forward()
age_id = np.argmax(age_results)
age_label = age_labels[age_id]
age_confidence = age_results[0, age_id]
- 同样,我们将性别分类:
gender_model.setInput(age_gender_blob)
gender_results = gender_model.forward()
gender_id = np.argmax(gender_results)
gender_label = gender_labels[gender_id]
gender_confidence = gender_results[0, gender_id]
- 我们绘制检测到的脸部矩形,扩展的方形 ROI 和分类结果的可视化图像:
# Draw a blue rectangle around the face.
cv2.rectangle(frame, (x0, y0), (x1, y1),
(255, 0, 0), 2)
# Draw a yellow square around the region of interest
# for age and gender classification.
cv2.rectangle(frame, (x0_roi, y0), (x1_roi, y1_roi),
(0, 255, 255), 2)
# Draw the age and gender classification results.
text = '%s years (%.1f%%), %s (%.1f%%)' % (
age_label, age_confidence * 100.0,
gender_label, gender_confidence * 100.0)
cv2.putText(frame, text, (x0_roi, y0 - 20),
cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 255), 2)
- 最后,我们显示带标注的帧,并继续捕获更多帧,直到用户按下
Esc键:
cv2.imshow('Faces, age, and gender', frame)
k = cv2.waitKey(1)
if k == 27: # Escape
break
success, frame = cap.read()
该程序如何报告约瑟夫·豪斯? 让我们来看看:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-tD78QkCB-1681871605273)(https://gitcode.net/apachecn/apachecn-cv-zh/-/raw/master/docs/learn-opencv4-cv-py3/img/7061d12a-b3ed-4db8-9c5a-9ba3c0f259ba.png)]
没有虚荣心,约瑟夫·豪斯(Joseph Howse)将就此结果写几段文字。
首先,让我们考虑面部的检测和 ROI 的选择。 已正确检测到脸部。 ROI 已正确扩展到包括脖子的方形区域,或者在这种情况下为完整的胡须,这对于分类年龄和性别可能是重要的区域。
其次,让我们考虑分类。 事实是,约瑟夫·豪斯(Joseph Howse)是男性,在这张照片拍摄时大约 35.8 岁。 看到约瑟夫·豪斯的脸的其他人也能够完全自信地断定他是男性。 但是,他们对他的年龄的估计差异很大。 性别分类 DNN 满怀信心(100.0%)说约瑟夫·豪斯是男性。 年龄分类 DNN 充满信心(96.6%)表示他年龄在 25-32 岁之间。 取这个范围的中点 28.5 也许很诱人,并说该预测的误差为-7.3 年,从客观上来说,这是一个大大的低估了,它是真实年龄的-20.4%。 但是,这种评估是预测含义的延伸。
请记住,此 DNN 是年龄分类器,而不是连续年龄值的预测指标,并且 DNN 的年龄类别被标记为不连续的范围; '25-32'之后的下一个是'38-43'。 因此,该模型与约瑟夫·豪斯(Joseph Howse)的真实年龄之间存在差距,但至少它设法从边界上选择了两个类别之一。
该演示结束了我们对 ANN 和 DNN 的介绍。 让我们回顾一下我们学到的东西和做过的事情。
总结
本章概述了人工神经网络的广阔而迷人的世界。 我们了解了人工神经网络的结构,以及如何根据应用需求设计网络拓扑。 然后,我们专注于 OpenCV 对 MLP ANN 的实现,以及 OpenCV 对在其他框架中进行过训练的各种 DNN 的支持。
我们将神经网络应用于现实世界中的问题:特别是手写数字识别; 目标检测和分类; 以及实时的人脸识别,年龄分类和性别分类的组合。 我们看到,即使在这些入门演示中,神经网络在多功能性,准确率和速度方面也显示出很大的希望。 希望这可以鼓励您尝试各种作者的经过预先训练的模型,并学习在各种框架中训练自己的高级模型。
带着这种思想和良好的祝愿,我们现在将分开。
本书的作者希望您通过 OpenCV 4 的 Python 绑定一起经历了我们的旅程。尽管涵盖了 OpenCV 4 的所有功能及其所有绑定将涉及一系列书籍,但我们探索了许多有趣而又充满未来感的概念,并且我们鼓励您与我们以及 OpenCV 社区取得联系,让我们了解您在计算机视觉领域的下一个突破性项目!
十一、附录 A:使用“曲线”过滤器弯曲颜色空间
从第 3 章“使用 OpenCV 处理图像”开始,我们的Cameo演示应用合并了一种称为曲线的图像处理效果,用于模拟某些物体的色偏。 摄影胶片。 本附录描述了曲线的概念及其使用 SciPy 的实现。
曲线是一种重新映射颜色的技术。 使用曲线时,目标像素处的通道值是(仅)源像素处的相同通道值的函数。 而且,我们不直接定义函数; 而是,对于每个函数,我们定义一组必须通过插值拟合的控制点。 在伪代码中,对于 BGR 图像,我们具有以下内容:
dst.b = funcB(src.b) where funcB interpolates pointsB
dst.g = funcG(src.g) where funcG interpolates pointsG
dst.r = funcR(src.r) where funcR interpolates pointsR
尽管应避免控制点处的不连续坡度,但会产生曲线,但这种插值方式可能会因实现方式而异。 只要控制点数量足够,我们将使用三次样条插值。
让我们先来看一下如何实现插值。
定义曲线
我们迈向基于曲线的过滤器的第一步是将控制点转换为函数。 大部分工作都是通过名为scipy.interp1d的 SciPy 函数完成的,该函数接受两个数组(x和y坐标)并返回一个对点进行插值的函数。 作为scipy.interp1d的可选参数,我们可以指定kind插值; 支持的选项包括'linear','nearest','zero','slinear'(球形线性),'quadratic'和'cubic'。 另一个可选参数bounds_error可以设置为False,以允许外插和内插。
让我们编辑我们在Cameo演示中使用的utils.py脚本,并添加一个将scipy.interp1d包裹起来的函数,该函数的接口稍微简单一些:
def createCurveFunc(points):
"""Return a function derived from control points."""
if points is None:
return None
numPoints = len(points)
if numPoints < 2:
return None
xs, ys = zip(*points)
if numPoints < 3:
kind = 'linear'
elif numPoints < 4:
kind = 'quadratic'
else:
kind = 'cubic'
return scipy.interpolate.interp1d(xs, ys, kind,
bounds_error = False)
我们的函数不是使用两个单独的坐标数组,而是采用(x,y)对的数组,这可能是指定控制点的一种更易读的方式。 必须对数组进行排序,以使x从一个索引增加到下一个索引。 通常,为获得自然效果,y值也应增加,并且第一个和最后一个控制点应为(0, 0)和(255, 255),以保留黑白。 注意,我们将x视为通道的输入值,并将y视为对应的输出值。 例如,(128, 160)将使通道的中间色调变亮。
请注意,三次插值至少需要四个控制点。 如果只有三个控制点,则退回到二次插值;如果只有两个控制点,则退回到线性插值。 为了获得自然效果,应避免这些后备情况。
在本章的其余部分中,我们力求以有效且井井有条的方式使用由createCurveFunc函数生成的曲线。
缓存和应用曲线
现在,我们可以获得插入任意控制点的曲线的函数。 但是,此函数可能很昂贵。 我们不希望每个通道每个像素运行一次(例如,如果应用于640 x 480视频的三个通道,则每帧运行 921,600 次)。 幸运的是,我们通常只处理 256 个可能的输入值(每个通道 8 位),并且可以廉价地预先计算并存储许多输出值。 然后,我们的每通道每像素成本只是对缓存的输出值的查找。
让我们编辑utils.py文件并添加一个将为给定函数创建查找数组的函数:
def createLookupArray(func, length=256):
"""Return a lookup for whole-number inputs to a function.
The lookup values are clamped to [0, length - 1].
"""
if func is None:
return None
lookupArray = numpy.empty(length)
i = 0
while i < length:
func_i = func(i)
lookupArray[i] = min(max(0, func_i), length - 1)
i += 1
return lookupArray
我们还添加一个函数,该函数会将查找数组(例如前一个函数的结果)应用于另一个数组(例如图像):
def applyLookupArray(lookupArray, src, dst):
"""Map a source to a destination using a lookup."""
if lookupArray is None:
return
dst[:] = lookupArray[src]
请注意,createLookupArray中的方法仅限于输入值为整数(非负整数)的输入值,因为该输入值用作数组的索引。 applyLookupArray函数通过使用源数组的值作为查找数组的索引来工作。 Python 的切片符号([:])用于将查找的值复制到目标数组中。
让我们考虑另一个优化。 如果我们要连续应用两个或更多曲线怎么办? 执行多次查找效率低下,并且可能导致精度降低。 我们可以通过在创建查找数组之前将两个曲线函数组合为一个函数来避免这些问题。 让我们再次编辑utils.py并添加以下函数,该函数返回两个给定函数的组合:
def createCompositeFunc(func0, func1):
"""Return a composite of two functions."""
if func0 is None:
return func1
if func1 is None:
return func0
return lambda x: func0(func1(x))
createCompositeFunc中的方法仅限于采用单个参数的输入函数。 参数必须是兼容类型。 请注意,使用 Python 的lambda关键字创建匿名函数。
以下是最终的优化问题。 如果我们想对图像的所有通道应用相同的曲线怎么办? 在这种情况下,拆分和合并通道很浪费,因为我们不需要区分通道。 我们只需要applyLookupArray使用的一维索引。 为此,我们可以使用numpy.ravel函数,该函数将一维接口返回到预先存在的给定数组(可能是多维数组)。 返回类型为numpy.view,其接口与numpy.array几乎相同,除了numpy.view仅拥有对数据的引用,而非副本。
NumPy 数组具有flatten方法,但这将返回一个副本。
numpy.ravel适用于具有任意数量通道的图像。 因此,当我们希望所有通道都相同时,它可以抽象出灰度图像和彩色图像之间的差异。
现在,我们已经解决了与曲线使用有关的几个重要的优化问题,让我们考虑如何组织代码,以便为诸如Cameo之类的应用提供简单且可重用的界面。
设计面向对象的曲线过滤器
由于我们为每个曲线缓存了一个查找数组,因此基于曲线的过滤器具有与之关联的数据。 因此,我们将它们实现为类,而不仅仅是函数。 让我们制作一对曲线过滤器类,以及一些可以应用任何函数而不仅仅是曲线函数的相应高级类:
VFuncFilter:这是一个用函数实例化的类,然后可以使用apply将其应用于图像。 该函数适用于灰度图像的 V(值)通道或彩色图像的所有通道。VCurveFilter:这是VFuncFilter的子类。 而不是使用函数实例化,而是使用一组控制点实例化,这些控制点在内部用于创建曲线函数。BGRFuncFilter:这是一个用最多四个函数实例化的类,然后可以使用apply将其应用于 BGR 图像。 这些函数之一适用于所有通道,而其他三个函数均适用于单个通道。 首先应用整体函数,然后再应用每通道函数。BGRCurveFilter:这是BGRFuncFilter的子类。 而不是使用四个函数实例化,而是使用四组控制点实例化,这些控制点在内部用于创建曲线函数。
此外,所有这些类都接受数字类型的构造器参数,例如numpy.uint8,每个通道 8 位。 此类型用于确定查找数组中应包含多少个条目。 数值类型应为整数类型,并且查找数组将覆盖从 0 到该类型的最大值(包括该值)的范围。
首先,让我们看一下VFuncFilter和VCurveFilter的实现,它们都可以添加到filters.py中:
class VFuncFilter(object):
"""A filter that applies a function to V (or all of BGR)."""
def __init__(self, vFunc=None, dtype=numpy.uint8):
length = numpy.iinfo(dtype).max + 1
self._vLookupArray = utils.createLookupArray(vFunc, length)
def apply(self, src, dst):
"""Apply the filter with a BGR or gray source/destination."""
srcFlatView = numpy.ravel(src)
dstFlatView = numpy.ravel(dst)
utils.applyLookupArray(self._vLookupArray, srcFlatView,
dstFlatView)
class VCurveFilter(VFuncFilter):
"""A filter that applies a curve to V (or all of BGR)."""
def __init__(self, vPoints, dtype=numpy.uint8):
VFuncFilter.__init__(self, utils.createCurveFunc(vPoints),
dtype)
在这里,我们正在内部使用几个以前的函数:utils.createCurveFunc,utils.createLookupArray和utils.applyLookupArray。 我们还使用numpy.iinfo根据给定的数字类型确定相关的查找值范围。
现在,让我们看一下BGRFuncFilter和BGRCurveFilter的实现,它们也都可以添加到filters.py中:
class BGRFuncFilter(object):
"""A filter that applies different functions to each of BGR."""
def __init__(self, vFunc=None, bFunc=None, gFunc=None,
rFunc=None, dtype=numpy.uint8):
length = numpy.iinfo(dtype).max + 1
self._bLookupArray = utils.createLookupArray(
utils.createCompositeFunc(bFunc, vFunc), length)
self._gLookupArray = utils.createLookupArray(
utils.createCompositeFunc(gFunc, vFunc), length)
self._rLookupArray = utils.createLookupArray(
utils.createCompositeFunc(rFunc, vFunc), length)
def apply(self, src, dst):
"""Apply the filter with a BGR source/destination."""
b, g, r = cv2.split(src)
utils.applyLookupArray(self._bLookupArray, b, b)
utils.applyLookupArray(self._gLookupArray, g, g)
utils.applyLookupArray(self._rLookupArray, r, r)
cv2.merge([b, g, r], dst)
class BGRCurveFilter(BGRFuncFilter):
"""A filter that applies different curves to each of BGR."""
def __init__(self, vPoints=None, bPoints=None,
gPoints=None, rPoints=None, dtype=numpy.uint8):
BGRFuncFilter.__init__(self,
utils.createCurveFunc(vPoints),
utils.createCurveFunc(bPoints),
utils.createCurveFunc(gPoints),
utils.createCurveFunc(rPoints), dtype)
同样,我们正在内部使用几个以前的函数:utils.createCurvFunc,utils.createCompositeFunc,utils.createLookupArray和utils.applyLookupArray。 我们还使用numpy.iinfo,cv2.split和cv2.merge。
这四个类可以按原样使用,在实例化时将自定义函数或控制点作为参数传递。 或者,我们可以创建其他子类,这些子类对某些功能或控制点进行硬编码。 这样的子类可以实例化而无需任何参数。
现在,让我们看一下子类的一些示例。
模拟摄影胶片
曲线的常用用法是模拟数字前摄影中常见的调色板。 每种类型的胶卷都有自己独特的颜色(或灰色)表示法,但我们可以概括一些与数字传感器的区别。 电影往往会损失细节和阴影饱和度,而数字往往会遭受高光的这些缺陷。 而且,胶片在光谱的不同部分上往往具有不均匀的饱和度,因此每张胶片都有某些弹出或跳出的颜色。
因此,当我们想到漂亮的电影照片时,我们可能会想到明亮的且具有某些主导色彩的场景(或副本)。 在另一个极端,也许我们还记得曝光不足的胶卷的暗淡外观,而实验室技术人员的努力并不能改善它。
在本节中,我们将使用曲线创建四个不同的类似于电影的过滤器。 它们受到三种胶片和冲洗技术的启发:
- 柯达波特拉(Kodak Portra),这是一系列针对肖像和婚礼进行了优化的电影。
- Fuji Provia,一个通用电影家族。
- 富士·维尔维亚(Fuji Velvia),针对风景优化的电影系列。
- 交叉处理是一种非标准的胶片处理技术,有时用于在时装和乐队摄影中产生低劣的外观。
每个电影模拟效果都实现为BGRCurveFilter的非常简单的子类。 在这里,我们只需重写构造器即可为每个通道指定一组控制点。 控制点的选择基于摄影师 Petteri Sulonen 的建议。 有关更多信息,请参见他在这个页面上有关胶片状曲线的文章。
Portra,Provia 和 Velvia 效果应产生看起来正常的图像。 除了前后比较之外,这些效果应该不明显。
让我们从 Portra 过滤器开始,检查四个胶片仿真过滤器中每个过滤器的实现。
模拟柯达 Portra
Portra 具有宽广的高光范围,倾向于暖色(琥珀色),而阴影则较冷(蓝色)。 作为人像电影,它倾向于使人们的肤色更白皙。 而且,它会夸大某些常见的衣服颜色,例如乳白色(例如婚纱)和深蓝色(例如西装或牛仔裤)。 让我们将 Portra 过滤器的此实现添加到filters.py:
class BGRPortraCurveFilter(BGRCurveFilter):
"""A filter that applies Portra-like curves to BGR."""
def __init__(self, dtype=numpy.uint8):
BGRCurveFilter.__init__(
self,
vPoints = [(0,0),(23,20),(157,173),(255,255)],
bPoints = [(0,0),(41,46),(231,228),(255,255)],
gPoints = [(0,0),(52,47),(189,196),(255,255)],
rPoints = [(0,0),(69,69),(213,218),(255,255)],
dtype = dtype)
从柯达到富士,接下来我们将模拟 Provia。
模拟富士 Provia
普罗维亚(Provia)具有很强的对比度,并且在大多数色调中略微凉爽(蓝色)。 天空,水和阴影比太阳增强更多。 让我们将 Provia 过滤器的此实现添加到filters.py:
class BGRProviaCurveFilter(BGRCurveFilter):
"""A filter that applies Provia-like curves to BGR."""
def __init__(self, dtype=numpy.uint8):
BGRCurveFilter.__init__(
self,
bPoints = [(0,0),(35,25),(205,227),(255,255)],
gPoints = [(0,0),(27,21),(196,207),(255,255)],
rPoints = [(0,0),(59,54),(202,210),(255,255)],
dtype = dtype)
接下来是我们的 Fuji Velvia 过滤器。
模拟富士 Velvia
Velvia 具有深阴影和鲜艳的色彩。 它通常可以在白天产生蔚蓝的天空,在日落时产生深红色的云。 这种效果很难模拟,但是这是我们可以添加到filters.py的尝试:
class BGRVelviaCurveFilter(BGRCurveFilter):
"""A filter that applies Velvia-like curves to BGR."""
def __init__(self, dtype=numpy.uint8):
BGRCurveFilter.__init__(
self,
vPoints = [(0,0),(128,118),(221,215),(255,255)],
bPoints = [(0,0),(25,21),(122,153),(165,206),(255,255)],
gPoints = [(0,0),(25,21),(95,102),(181,208),(255,255)],
rPoints = [(0,0),(41,28),(183,209),(255,255)],
dtype = dtype)
现在,让我们来看一下交叉处理的外观!
模拟交叉处理
交叉处理会在阴影中产生强烈的蓝色或绿蓝色调,在高光区域产生强烈的黄色或绿黄色。 黑色和白色不一定要保留。 而且,对比度非常高。 交叉处理的照片看起来很不舒服。 人们看起来黄疸,而无生命的物体看起来很脏。 让我们编辑filters.py并添加以下交叉处理过滤器的实现:
class BGRCrossProcessCurveFilter(BGRCurveFilter):
"""A filter that applies cross-process-like curves to BGR."""
def __init__(self, dtype=numpy.uint8):
BGRCurveFilter.__init__(
self,
bPoints = [(0,20),(255,235)],
gPoints = [(0,0),(56,39),(208,226),(255,255)],
rPoints = [(0,0),(56,22),(211,255),(255,255)],
dtype = dtype)
现在我们已经看过一些有关如何实现胶片仿真过滤器的示例,我们将包装本附录,以便您可以回到第 3 章“使用 OpenCV 处理图像”中的Cameo应用的主要实现。
总结
在scipy.interp1d函数的基础上,我们实现了一系列曲线过滤器,这些过滤器高效(由于使用查找数组)并且易于扩展(由于面向对象的设计)。 我们的工作包括专用曲线过滤器,可以使数字图像看起来更像胶卷照。 这些过滤器可以很容易地集成到诸如Cameo之类的应用中,如第 3 章,“用 OpenCV 处理图像”中使用我们的 Portra 胶片仿真过滤器所示。



![【PWN刷题wp】[BJDCTF 2020]babystack](https://img-blog.csdnimg.cn/1ab107b013584c0c973b5251a57fb9f0.png)