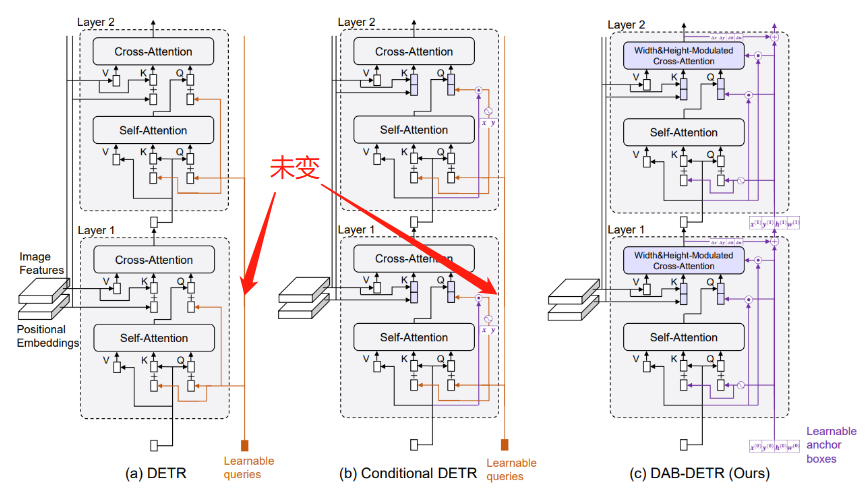
DAB-DETR是吸收了Deformable-DETR,Conditional-DETR,Anchor-DETR等基础上完善而来的。其主要贡献为将query初始化为x,y,w,h思维坐标形式。
这篇博文主要从代码角度来分析DAB-DETR所完成的工作。
DAB-DETR主要是对Decoder模型进行改进。

位置编码的温度值调整
首先是position_encoding.py文件,该文件中重新定义了一个PositionEmbeddingSineHW方法,其作用就是将高频位置编码部分的宽高温度值分开,可以让宽高有不同的温度值。该文件中还提高了sincos位置编码方式和可学习的位置编码方式。
class PositionEmbeddingSineHW(nn.Module):
"""
This is a more standard version of the position embedding, very similar to the one
used by the Attention is all you need paper, generalized to work on images.
"""
def __init__(self, num_pos_feats=64, temperatureH=10000, temperatureW=10000, normalize=False, scale=None):
super().__init__()
self.num_pos_feats = num_pos_feats
self.temperatureH = temperatureH
self.temperatureW = temperatureW
self.normalize = normalize
if scale is not None and normalize is False:
raise ValueError("normalize should be True if scale is passed")
if scale is None:
scale = 2 * math.pi
self.scale = scale
def forward(self, tensor_list: NestedTensor):
x = tensor_list.tensors
mask = tensor_list.mask
assert mask is not None
not_mask = ~mask
y_embed = not_mask.cumsum(1, dtype=torch.float32)
x_embed = not_mask.cumsum(2, dtype=torch.float32)
# import ipdb; ipdb.set_trace()
if self.normalize:
eps = 1e-6
y_embed = y_embed / (y_embed[:, -1:, :] + eps) * self.scale
x_embed = x_embed / (x_embed[:, :, -1:] + eps) * self.scale
dim_tx = torch.arange(self.num_pos_feats, dtype=torch.float32, device=x.device)
dim_tx = self.temperatureW ** (2 * (dim_tx // 2) / self.num_pos_feats)
pos_x = x_embed[:, :, :, None] / dim_tx
dim_ty = torch.arange(self.num_pos_feats, dtype=torch.float32, device=x.device)
dim_ty = self.temperatureH ** (2 * (dim_ty // 2) / self.num_pos_feats)
pos_y = y_embed[:, :, :, None] / dim_ty
pos_x = torch.stack((pos_x[:, :, :, 0::2].sin(), pos_x[:, :, :, 1::2].cos()), dim=4).flatten(3)
pos_y = torch.stack((pos_y[:, :, :, 0::2].sin(), pos_y[:, :, :, 1::2].cos()), dim=4).flatten(3)
pos = torch.cat((pos_y, pos_x), dim=3).permute(0, 3, 1, 2)
# import ipdb; ipdb.set_trace()
return pos
Transformer整体架构
我们先来了解Transformer的整体架构:
首先我们来看看forward传入的参数:
src:由backbone提取的特征信息,shape初始为 torch.Size([2, 256,19,24]) 后变为torch.Size([456, 2, 256])
mask:对图像进行补全掩码信息,shape初始为 torch.Size([2, 19, 24]) 后展平为 torch.Size([2, 456])
refpoint_embed:参考点坐标编码,即object_query,torch.Size([300, 4])。在Decoder模块使用,其是在DAB-DETR模块定义初始化的:self.refpoint_embed = nn.Embedding(num_queries, query_dim),初始为torch.Size([300,4]),后经过refpoint_embed = refpoint_embed.unsqueeze(1).repeat(1, bs, 1)变为torch.Size([300, 4])。
pos_embed:位置编码信息,shape初始为 torch.Size([2, 256,19,24]) 后变为torch.Size([456, 2, 256])
上述过程执行代码如下:
# flatten NxCxHxW to HWxNxC
bs, c, h, w = src.shape #初始为2,256,19,24
src = src.flatten(2).permute(2, 0, 1)#拉平:
pos_embed = pos_embed.flatten(2).permute(2, 0, 1)
refpoint_embed = refpoint_embed.unsqueeze(1).repeat(1, bs, 1)
mask = mask.flatten(1)
随后将数据送入Encoder模块,输出memory为:torch.Size([456, 2, 256])
memory = self.encoder(src, src_key_padding_mask=mask, pos=pos_embed)
随后对tgt进行初始化,根据self.num_patterns判断其模式,这里默认为0。tgt初始化为全0,shape为:torch.Size([300, 2, 256]),这里与DETR是相似的,其作为最开始的decoder输入。
num_queries = refpoint_embed.shape[0]
if self.num_patterns == 0:
tgt = torch.zeros(num_queries, bs, self.d_model, device=refpoint_embed.device)
else:
tgt = self.patterns.weight[:, None, None, :].repeat(1, self.num_queries, bs, 1).flatten(0, 1) # n_q*n_pat, bs, d_model
refpoint_embed = refpoint_embed.repeat(self.num_patterns, 1, 1) # n_q*n_pat, bs, d_model
随后送入Decoder模块:
hs, references = self.decoder(tgt, memory, memory_key_padding_mask=mask,
pos=pos_embed, refpoints_unsigmoid=refpoint_embed)
return hs, references
Encoder模块构建
DAB-DETR的Encoder模块与DETR并没有太大差别。
EncoderLayer
src_mask=None
src_key_padding_mask:将图片补全shape为【2,456】
src:通过ResNet提取到的特征,由二维转为一维,shape为 torch.Size([456, 2, 256])
pos:位置编码信息,原本为两种,分别为sincos位置编码与可学习的位置编码,此外,DAB-DETR还提出一种可以跳转宽高的位置编码方式。shape为 torch.Size([456, 2, 256])
src2 通过self-attention获得,shape为 torch.Size([456, 2, 256]),随后经过dropout层,norm层。最终的输出结果为src:torch.Size([456, 2, 256]),将该结果送入Decoder。
q = k = self.with_pos_embed(src, pos)
src2 = self.self_attn(q, k, value=src, attn_mask=src_mask,
key_padding_mask=src_key_padding_mask)[0]
src = src + self.dropout1(src2)
src = self.norm1(src)
src2 = self.linear2(self.dropout(self.activation(self.linear1(src))))
src = src + self.dropout2(src2)
src = self.norm2(src)
return src
与DETR一样,with_pos_embed是直接相加。
def with_pos_embed(self, tensor, pos: Optional[Tensor]):
return tensor if pos is None else tensor + pos
Encoder模块
Encoder即有6个EncoderLayer构成。
class TransformerEncoder(nn.Module):
def __init__(self, encoder_layer, num_layers, norm=None, d_model=256):
super().__init__()
self.layers = _get_clones(encoder_layer, num_layers)
self.num_layers = num_layers
self.query_scale = MLP(d_model, d_model, d_model, 2)
self.norm = norm
def forward(self, src,
mask: Optional[Tensor] = None,
src_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None):
output = src
for layer_id, layer in enumerate(self.layers):
# rescale the content and pos sim
pos_scales = self.query_scale(output)
output = layer(output, src_mask=mask,
src_key_padding_mask=src_key_padding_mask, pos=pos*pos_scales)
if self.norm is not None:
output = self.norm(output)
return output
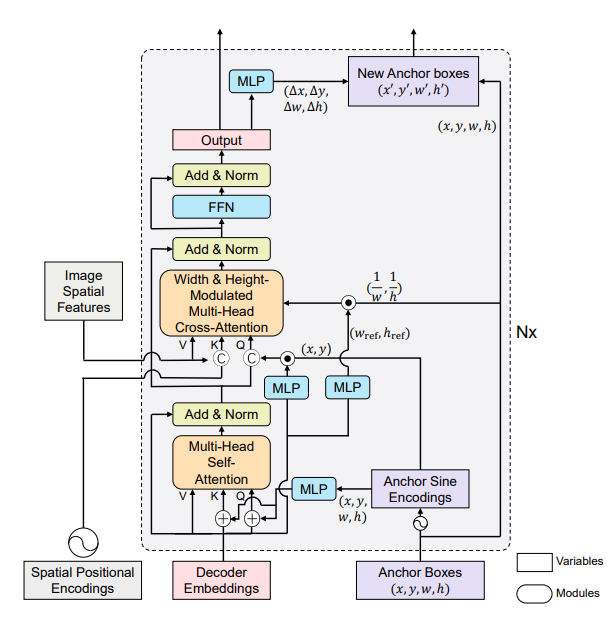
Decoder简要概述
在Decoder部分的query ancor(Anchor Boxes)中,其初始化为【2,300,4】会通过Anchor Sine Encoding,x,y,w,h都会进行,都转换为128维度,4个即为512维,随后通过一个MLP转换为256。
位置编码方式如下:总共4个,被编码维128维。
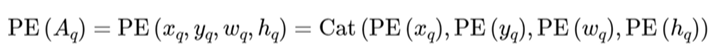
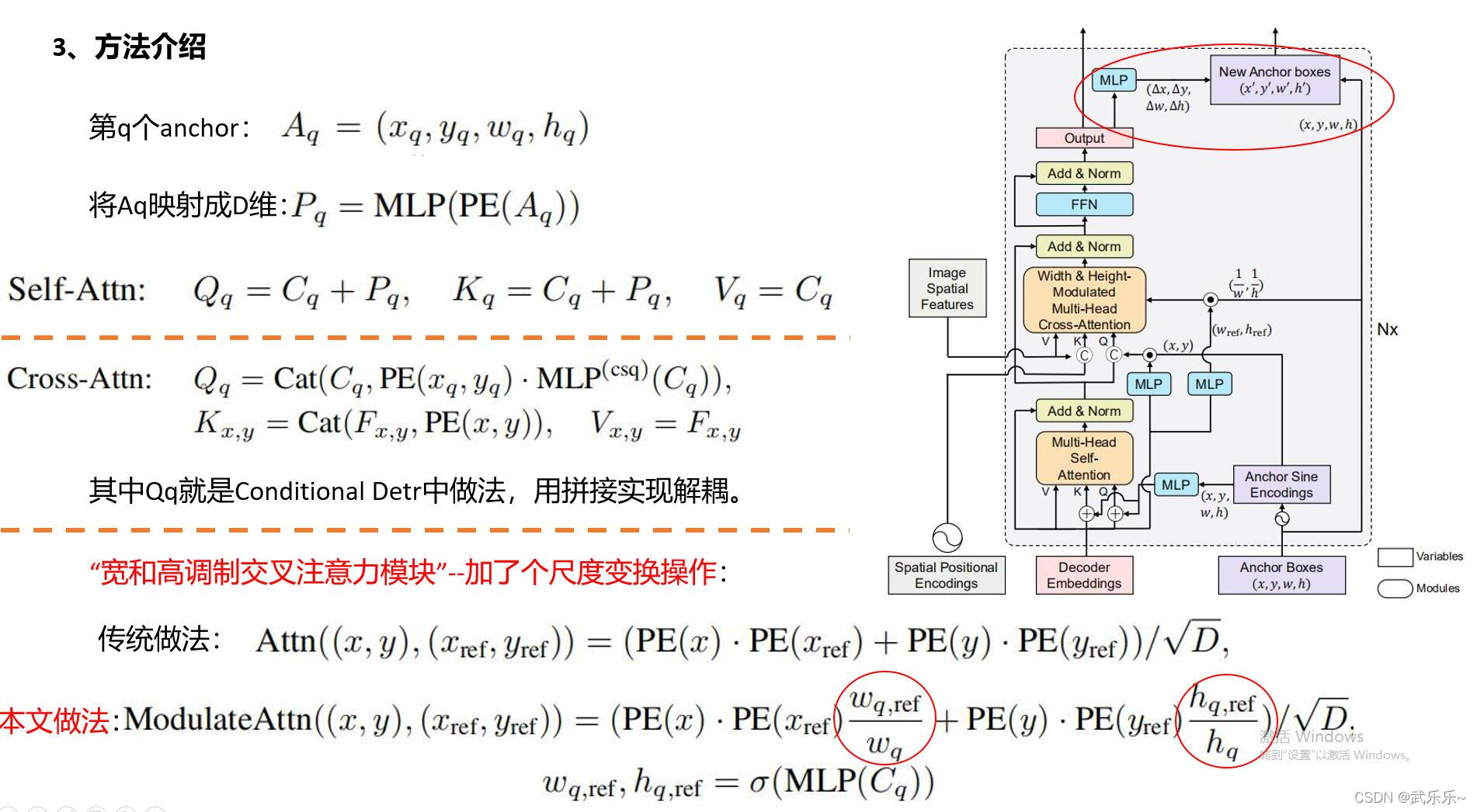
下面是其主要的一个创新点,加入了宽高调制的注意力机制,之所以这样做是让注意力能够对宽高也比较敏感。


Decoder模块代码实现
首先,将tgt的值给output,这里可以看出,输出结果为output,其shape为torch.Size([300, 2, 256])
output = tgt
将reference_points归一化,shape仍为torch.Size([300, 2, 4])
reference_points = refpoints_unsigmoid.sigmoid()
进入Decoder循环中后,首先对reference_points进行高频位置编码,即取出全部值,进入高频位置编码模块,由torch.Size([300, 2, 4])变为torch.Size([300, 2, 512]),每个变为128,如下:

随后经过一个self.ref_point_head(MLP)变为torch.Size([300, 2, 256])
obj_center = reference_points[..., :self.query_dim] #torch.Size([300, 2, 4])
query_sine_embed = gen_sineembed_for_position(obj_center) #torch.Size([300,2,512])
query_pos = self.ref_point_head(query_sine_embed) #torch.Size([300, 2, 256])
gen_sineembed_for_position方法如下:
def gen_sineembed_for_position(pos_tensor):
# n_query, bs, _ = pos_tensor.size()
# sineembed_tensor = torch.zeros(n_query, bs, 256)
scale = 2 * math.pi
dim_t = torch.arange(128, dtype=torch.float32, device=pos_tensor.device)
dim_t = 10000 ** (2 * (dim_t // 2) / 128)
x_embed = pos_tensor[:, :, 0] * scale
y_embed = pos_tensor[:, :, 1] * scale
pos_x = x_embed[:, :, None] / dim_t
pos_y = y_embed[:, :, None] / dim_t
pos_x = torch.stack((pos_x[:, :, 0::2].sin(), pos_x[:, :, 1::2].cos()), dim=3).flatten(2)
pos_y = torch.stack((pos_y[:, :, 0::2].sin(), pos_y[:, :, 1::2].cos()), dim=3).flatten(2)
if pos_tensor.size(-1) == 2:
pos = torch.cat((pos_y, pos_x), dim=2)
elif pos_tensor.size(-1) == 4:
w_embed = pos_tensor[:, :, 2] * scale
pos_w = w_embed[:, :, None] / dim_t
pos_w = torch.stack((pos_w[:, :, 0::2].sin(), pos_w[:, :, 1::2].cos()), dim=3).flatten(2)
h_embed = pos_tensor[:, :, 3] * scale
pos_h = h_embed[:, :, None] / dim_t
pos_h = torch.stack((pos_h[:, :, 0::2].sin(), pos_h[:, :, 1::2].cos()), dim=3).flatten(2)
pos = torch.cat((pos_y, pos_x, pos_w, pos_h), dim=2)
else:
raise ValueError("Unknown pos_tensor shape(-1):{}".format(pos_tensor.size(-1)))
return pos
随后进行一些初始化,self.query_scale为MLP层,output可认为是上一层Decoder的输出结果。
取出 query_sine_embed 的前256维,即x,y与pos_transformation(第一层时为1)相乘。
ref_anchor_head是一个MLP,self.ref_anchor_head = MLP(d_model, d_model, 2, 2)输入维度为256,中间层宽度为256,输出维度为2,隐藏层数为2。
refHW_cond为torch.Size([300, 2, 2])
query_sine_embed 初始为torch.Size([300, 2, 512]),经过下面query_sine_embed = query_sine_embed[...,:self.d_model] * pos_transformation后变为torch.Size([300, 2, 256]),该句代码意思为取前256维
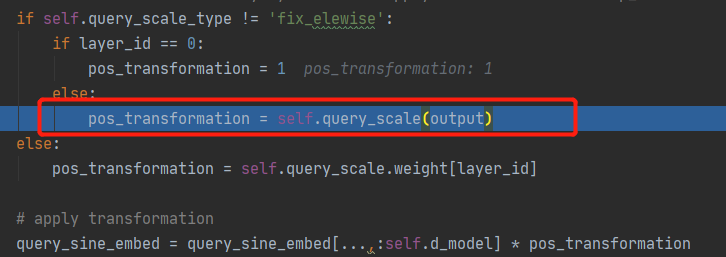
if self.query_scale_type != 'fix_elewise':#执行
if layer_id == 0:#第一层时执行
pos_transformation = 1
else:
pos_transformation = self.query_scale(output) #query_scale为MLP
else:
pos_transformation = self.query_scale.weight[layer_id]
#取出 query_sine_embed的前256维,即x,y与pos_transformation相乘
query_sine_embed = query_sine_embed[...,:self.d_model] * pos_transformation
if self.modulate_hw_attn:
refHW_cond = self.ref_anchor_head(output).sigmoid() #将其送入MLP后进行归一化 torch.Size([300, 2, 2])
query_sine_embed[..., self.d_model // 2:] *= (refHW_cond[..., 0] / obj_center[..., 2]).unsqueeze(-1)
query_sine_embed[..., :self.d_model // 2] *= (refHW_cond[..., 1] / obj_center[..., 3]).unsqueeze(-1)
上述代码执行的其实就是下面这个过程:注意此时并非是没有乘以PE(Xref),PE(Yref),而是由于其设置为1,即pos_transformation = 1,这里我们到了第二层DecoderLayer中可以看到。
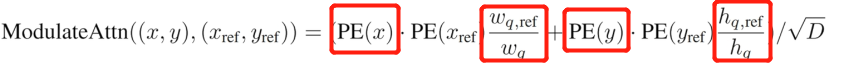
随后将数据送入DecoderLayer,注意此时DecoderLayer是第一层。
output = layer(output, memory, tgt_mask=tgt_mask,
memory_mask=memory_mask,
tgt_key_padding_mask=tgt_key_padding_mask,
memory_key_padding_mask=memory_key_padding_mask,
pos=pos, query_pos=query_pos, query_sine_embed=query_sine_embed,
is_first=(layer_id == 0))
第一层DecoderLayer模块
Self_Attention
首先时进行DecoderLayer中自注意力机制的计算。
我们来看看数据是如何变化的:
tgt即上一层DecoderLayer的输出结果,此时全为0,shape为 torch.Size([300, 2, 256])
首先经过一个线性层(sa_qcontent_proj = nn.Linear(d_model, d_model))得到q_content
shape为torch.Size([300, 2, 256])
需要注意的是,tgt在通过线性层完成qkv初始化时,尽管tgt全为0,但q,k,v却不是
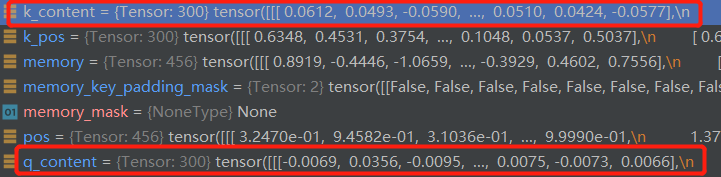
随后将q_pos(Anchor经过高频位置编码与MLP获得的xywh信息)也经过一个线性层sa_qpos_proj维度不变:shape为 torch.Size([300, 2, 256])
同时k,v也采用相同的方式进行初始化。与DETR相同,v是没有位置信息的。
综上所述,在self-attention中,由Anchor Box变换来的query_pos提供位置信息,由初始化为全0或上一层DecoderLayer的输出结果提供内容信息,位置信息与内容信息也是采用相加的方式合并在一起,如: q = q_content + q_pos
至于后面与DETR完全相同,送入q,k,v参与运算即可。
if not self.rm_self_attn_decoder:
# Apply projections here
# shape: num_queries x batch_size x 256
q_content = self.sa_qcontent_proj(tgt) # target is the input of the first decoder layer. zero by default.
q_pos = self.sa_qpos_proj(query_pos)
k_content = self.sa_kcontent_proj(tgt)
k_pos = self.sa_kpos_proj(query_pos)
v = self.sa_v_proj(tgt)
num_queries, bs, n_model = q_content.shape
hw, _, _ = k_content.shape
q = q_content + q_pos
k = k_content + k_pos
tgt2 = self.self_attn(q, k, value=v, attn_mask=tgt_mask,
key_padding_mask=tgt_key_padding_mask)[0]
#tgt2为Attention计算结果,torch.Size([300, 2, 256])
# ========== End of Self-Attention =============
tgt = tgt + self.dropout1(tgt2)
tgt = self.norm1(tgt)
最终获得self-attention的输出tgt,shape为 torch.Size([300, 2, 256]),上述代码执行的便是下图框出部分。
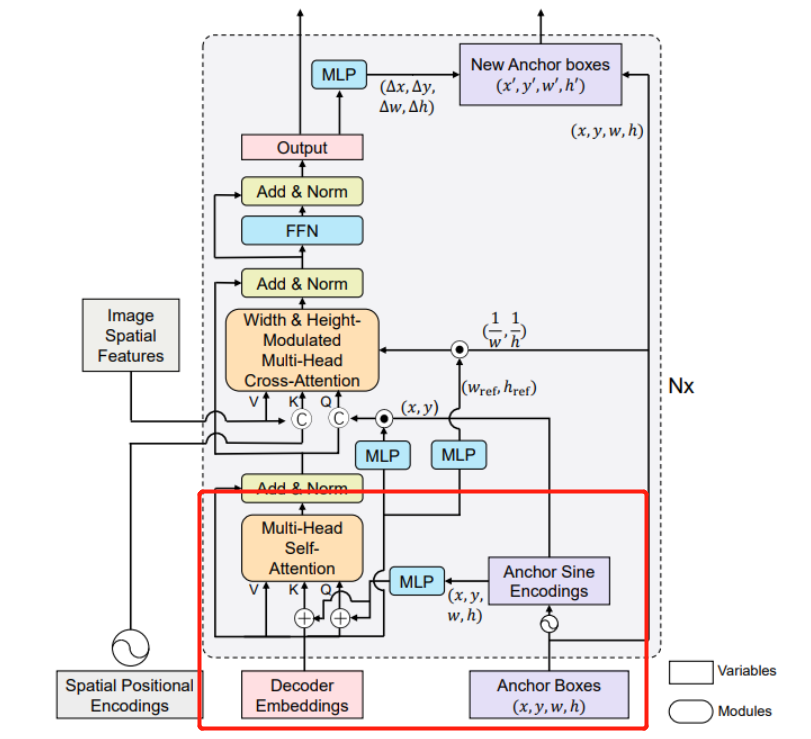
随后准备送入cross-attention进行计算
Cross_Attention
首先是q k v的初始化过程,可以看到,q来源于self-attention的输出结果,经过一个线性层,k,v则来自于Encoder的输出结果。memory的维度为torch.Size([456, 2, 256])
q_content = self.ca_qcontent_proj(tgt)#torch.Size([300, 2, 256])
k_content = self.ca_kcontent_proj(memory)#torch.Size([456, 2, 256])
v = self.ca_v_proj(memory)#torch.Size([456, 2, 256])
k_pos = self.ca_kpos_proj(pos)#对K进行位置编码,pos来自于Encoder。torch.Size([456, 2, 256])
由于是第一层,需要执行下面操作,即首先将 query_pos 【torch.Size([300, 2, 256])】通过一个全连接层,维度不发生变化,即生成 q_pos 的过程,
if is_first or self.keep_query_pos:#self.keep_query_pos默认为False
q_pos = self.ca_qpos_proj(query_pos)# query_pos:torch.Size([300, 2, 256])
q = q_content + q_pos
k = k_content + k_pos
else:
q = q_content
k = k_content
接下来便是送入Cross_Attention的Q,K,V的初始化过程:需要注意的是,这里将注意力分头操作放到外面了,原本是在注意力内部完成的。
q = q.view(num_queries, bs, self.nhead, n_model//self.nhead)# q分头:torch.Size([300, 2, 8, 32])
query_sine_embed = self.ca_qpos_sine_proj(query_sine_embed)#query_sine_embed即
query_sine_embed = query_sine_embed.view(num_queries, bs, self.nhead, n_model//self.nhead)
q = torch.cat([q, query_sine_embed], dim=3).view(num_queries, bs, n_model * 2)
#q经过拼接变为torch.Size([300, 2, 512])
k = k.view(hw, bs, self.nhead, n_model//self.nhead)#torch.Size([456, 2, 8, 32])
k_pos = k_pos.view(hw, bs, self.nhead, n_model//self.nhead)#torch.Size([456, 2, 8, 32])
k = torch.cat([k, k_pos], dim=3).view(hw, bs, n_model * 2)#torch.Size([456, 2, 512])
随后将Q,K,V送入Cross_Attention进行计算:总结一下,q:torch.Size([300, 2, 512]),k:torch.Size([456, 2, 512]),v:torch.Size([456, 2, 256])
tgt2 = self.cross_attn(query=q, key=k, value=v, attn_mask=memory_mask, key_padding_mask=memory_key_padding_mask)[0]
具体执行下面过程:Q K V不同维度
return multi_head_attention_forward(
query, key, value, self.embed_dim, self.num_heads,
self.in_proj_weight, self.in_proj_bias,
self.bias_k, self.bias_v, self.add_zero_attn,
self.dropout, self.out_proj.weight, self.out_proj.bias,
training=self.training,
key_padding_mask=key_padding_mask, need_weights=need_weights,
attn_mask=attn_mask, out_dim=self.vdim)
完成cross_attention计算后,tgt2维度为torch.Size([300, 2, 256]),关于维度变化可以参考Attention计算公式:
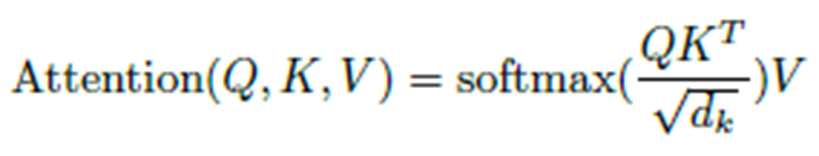
随后便是经过一系列残次连接,批归一化操作输出结果了,最终结果仍为 torch.Size([300, 2, 256])。
锚点更新策略
该模块也是DAB-DETR的一个创新点,即锚点更新策略 Anchor Update
即经过了DecoderLayer的cross_attention计算后出了将输出值传给下一层DecoderLayer外还将其用于锚点更新,使用MLP网络获得x,y,w,h的偏移量,shape为torch.Size([300, 2, 4])。与我们初始化的参考点坐标reference_points(即Anchor box,shape为torch.Size([300, 2, 4]) )相加。此即为锚点更新策略,而先前的DETR模型中的初始化anchor是一直不变的。
if self.bbox_embed is not None:
if self.bbox_embed_diff_each_layer:#是否共享参数:false
tmp = self.bbox_embed[layer_id](output)
else:
tmp = self.bbox_embed(output)#经过MLP获得output偏移量x,y,w,h torch.Size([300, 2, 4])
# import ipdb; ipdb.set_trace()
tmp[..., :self.query_dim] += inverse_sigmoid(reference_points)
new_reference_points = tmp[..., :self.query_dim].sigmoid()
if layer_id != self.num_layers - 1:
ref_points.append(new_reference_points)
reference_points = new_reference_points.detach()
if self.return_intermediate:
intermediate.append(self.norm(output))
由上述代码可知reference_points会不断更新,即Anchor更新策略
为了实现自动微分,PyTorch跟踪所有涉及张量的操作,可能需要为其计算梯度(即require_grad为True)。 这些操作记录为有向图。 detach()方法在张量上构造一个新视图,该张量声明为不需要梯度
上述代码执行的便是下图框出过程:
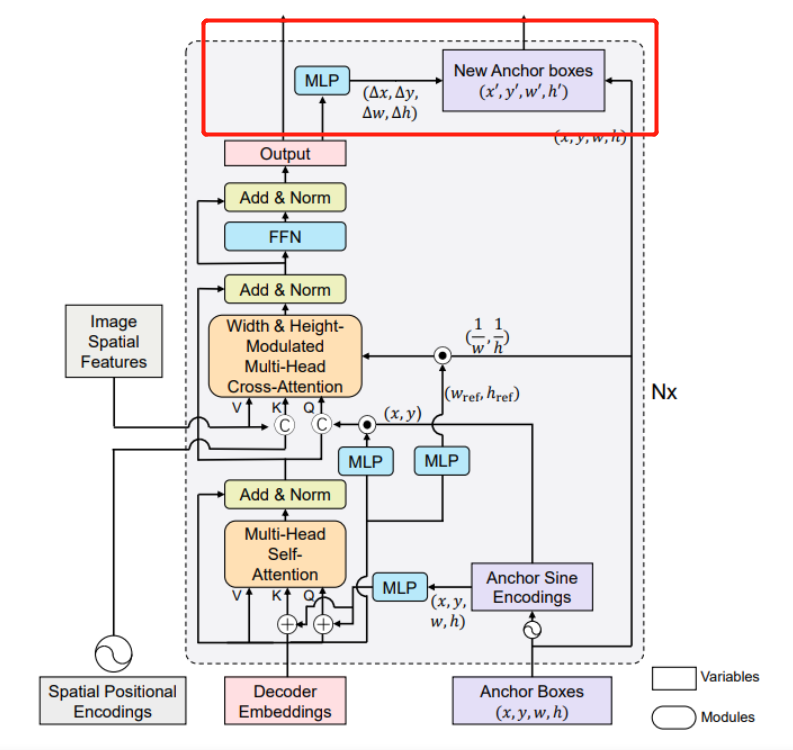
第二层DecoderLayer模块
相较于第一层DecoderLayer,第二层的结构上与第一层是没有差别的,只是第一层的Decoder-Embedding的初始化tgt为全0,第二层变为了第一层的输出而已,此外由于锚点更新策略,第二层的Anchor Boxes也变为了第一层Anchor Boxes加上xywh的偏移量。
首先是Anchor Boxes的变化,reference_points(即Anchor Boxes)在经过了上一层Decoderlayer后值得到了更新,再次经过高频位置编码,MLP层将数据维度变为 torch.Size([300, 2, 256])
obj_center = reference_points[..., :self.query_dim]
query_sine_embed = gen_sineembed_for_position(obj_center)
query_pos = self.ref_point_head(query_sine_embed)
紧接着,这里凸显了不同之处,首先,此时的query_scale_type变为 cond_elewise ,且由于到了第二层,output(即上一层的输出结果)通过
self.query_scale = MLP(d_model, d_model, d_model, 2)
进行编码得到pos_transformation维度为 torch.Size([300, 2, 256])
紧接着query_sine_embed[...,:self.d_model] * pos_transformation,这里的query_sine_embed为 torch.Size([300, 2, 512]),取前面的256维,即对应取得是x,y。与pos_transformation相乘,pos_transformation即Xref,Yref,这里完成的便是下面的操作:
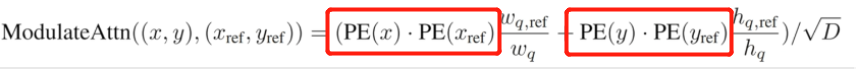
由此可见,在第一层中并非是没有乘以PE(Xref),PE(Yref),而是由于其值为1。
之后的过程就与第一层DecodeLayer完全相同了。