
论文链接:https://openaccess.thecvf.com/content/CVPR2022/papers/Ren_Shunted_Self-Attention_via_Multi-Scale_Token_Aggregation_CVPR_2022_paper.pdf
代码链接:https://github.com/OliverRensu/Shunted-Transformer
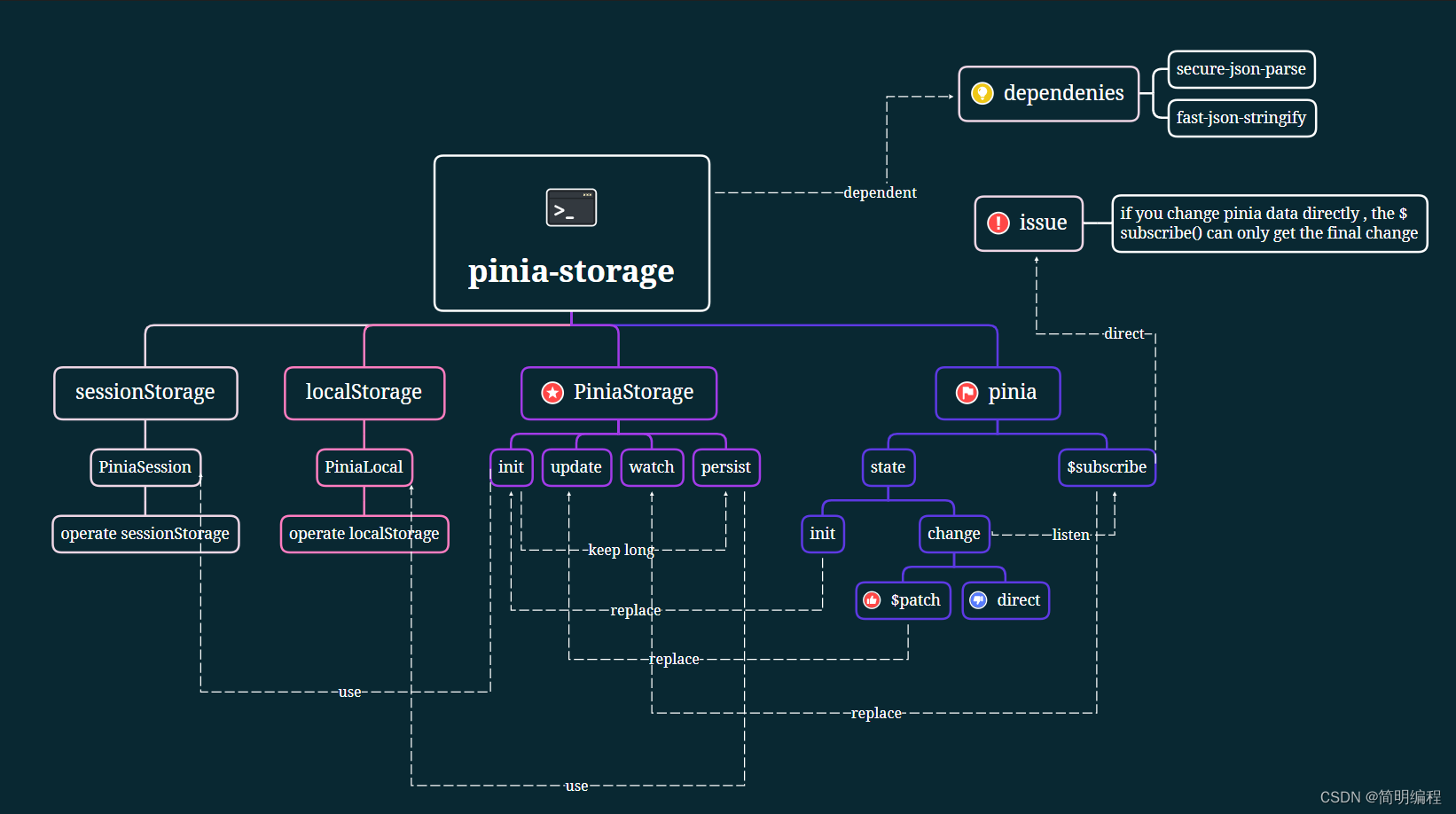
1. 动机
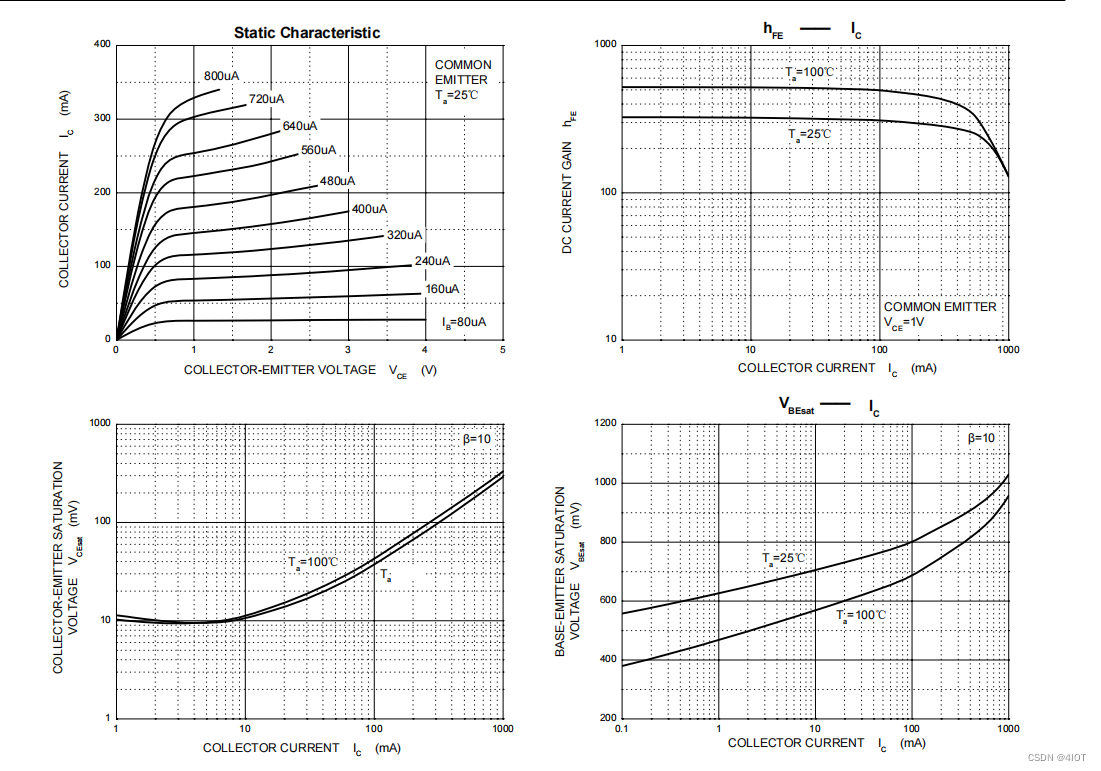
视觉转换器(ViT)模型具有通过self-attention对图像patch/token的长期依赖进行建模的能力。然而,这些模型通常为每一层中的每个token特性指定相似的感受野(如下图,相同大小的圆圈表示相应token的感受野大小)。它们在很大程度上忽略了注意层内场景对象的多尺度性质,这使得它们在涉及不同大小目标的野外场景中很脆弱。

2. 解决办法
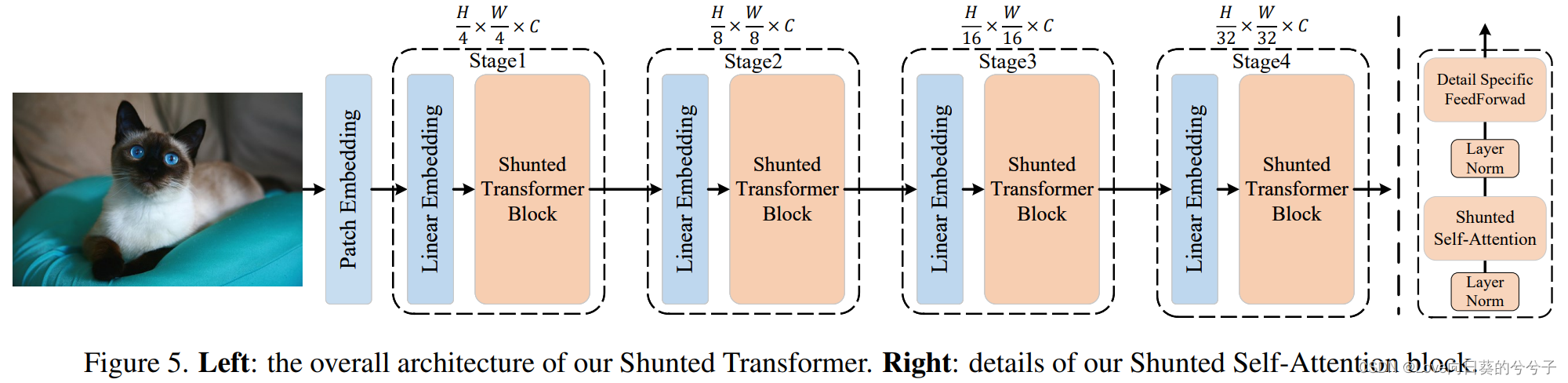
提出Shunted Transformer,如下图所示,其主要核心为shunted selfattention (SSA) block组成。
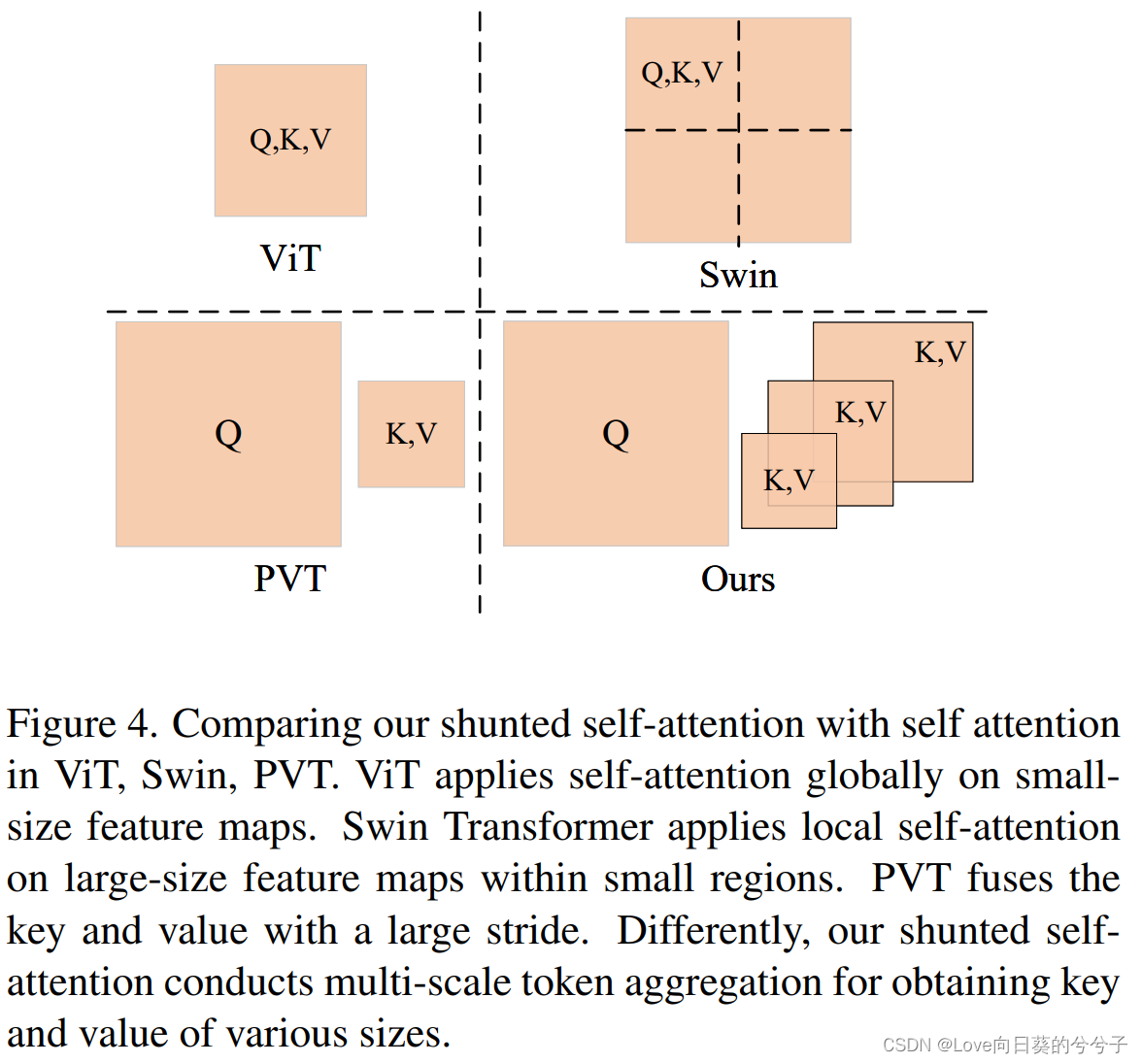
SSA明确地允许同一层中的自注意头分别考虑粗粒度和细粒度特征,有效地在同一层的不同注意力头同时对不同规模的对象进行建模,使其具有良好的计算效率以及保留细粒度细节的能力。如下图所示,不同颜色的圆圈表示不同大小的目标:

3. shunted selfattention (SSA) block
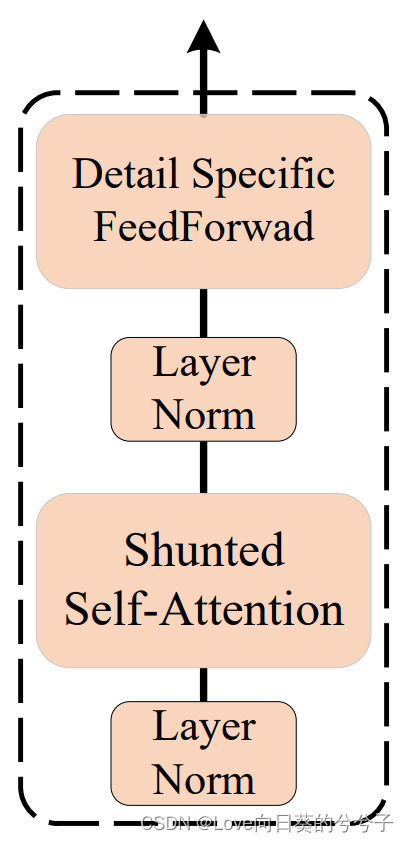
如下图所示,shunted selfattention block主要由shunted selfattention (SSA)和detail specific feed-forward组成。
3.1 shunted selfattention (SSA)
SSA可以看做是对 PVT 中
K
K
K 和
V
V
V 下采样的操作进行多尺度化改进,如下图所示。不同head的
K
,
V
K,V
K,V长度不同,以捕获不同粒度的信息,从而给出了多尺度token聚合(MTA)。具体来说,
K
K
K和
V
V
V对
i
i
i索引的不同head进行了不同大小的下采样。即,

这里的
M
A
T
(
⋅
;
r
i
)
MAT(·;r_i)
MAT(⋅;ri)是第
i
i
i个头中的多尺度token聚合层,下采样率为
r
i
r_i
ri。在实际应用中,作者采用核大小为
r
i
r_i
ri,步长为
r
i
r_i
ri的卷积层来实现下采样。
L
E
(
⋅
)
LE(·)
LE(⋅)是MTA通过深度卷积对
V
V
V进行局部增强的分量,这样,相比于spatial-reduction,保留了更多细粒度、低层次的细节。
然后,SSA能被定义为:
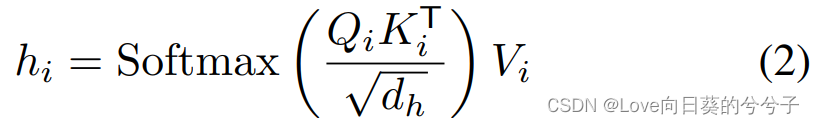
多亏了多尺度的key和value,本文的SSA在捕捉多尺度物体时更加强大。计算成本的降低可能取决于
r
r
r的值,因此,可以很好地定义模型和
r
r
r来权衡计算成本和模型性能。当
r
r
r变大时,
K
,
V
K, V
K,V中合并的token更多,
K
,
V
K, V
K,V的长度更短,因此计算成本较低,但仍保留了捕获大对象的能力。相比之下,当
r
r
r变小时,虽然保留了更多的细节,但也带来了更多的计算成本。将各种
r
r
r集成到一个自注意层中,使其能够捕获多粒度的特征。
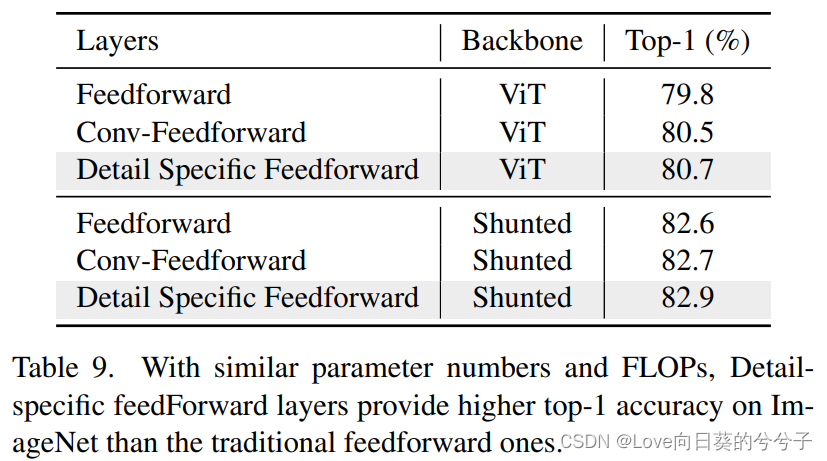
3.2 detail specific feed-forward
考虑到传统的feed-forward network中,全连接层是逐点的,不能学习cross token信息。在这里,未来通过指定前馈层中的细节来补充局部信息,作者提出detail specific feed-forward,如下图所示。具体地,通过在前馈层的两个全连接层之间添加特定于数据的层来补充前馈层中的局部细节。即
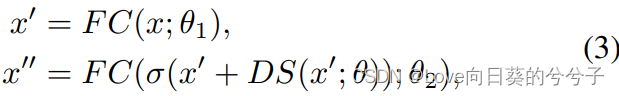
其中在
D
S
(
⋅
;
θ
)
DS(·;θ)
DS(⋅;θ)是带有参数
θ
θ
θ的细节特定层,在实践中通过深度卷积实现。
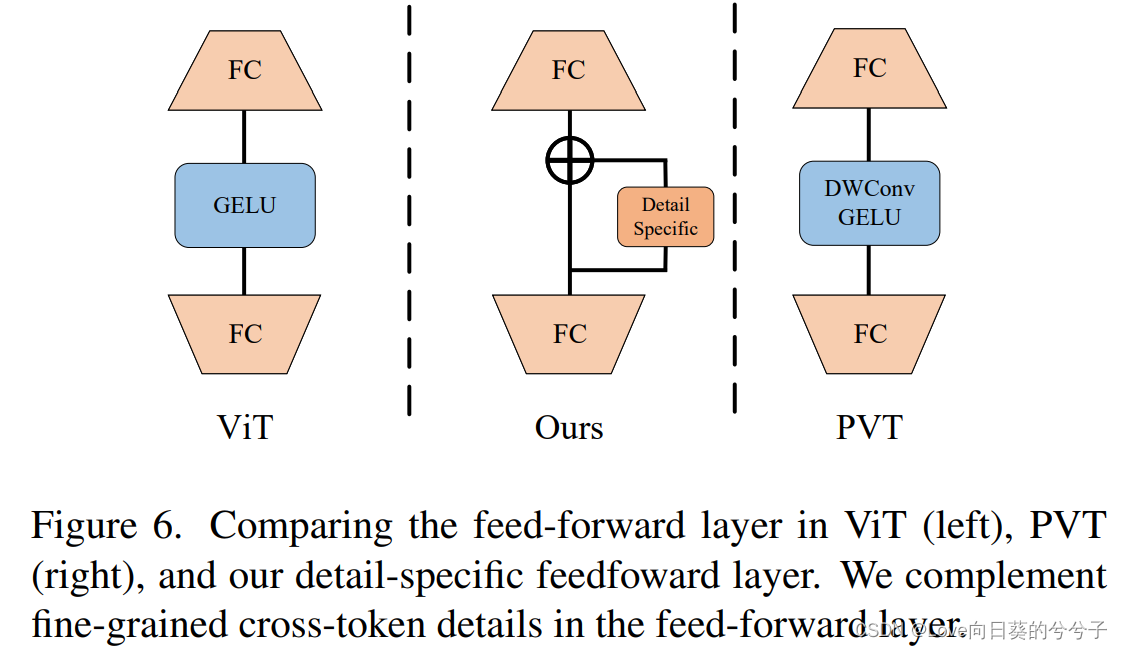
3.3 Shunted Transformer变体
本文提出了三种不同的模型配置,以便在相似的参数和计算成本下进行公平的比较。如下表1所示,
h
e
a
d
head
head和
N
i
N_i
Ni分别表示一个block中head的个数和一个stage中block的个数。变量只来自于不同stage的层数。具体来说,每个block中的head数设置为2、4、8、16。patch嵌入的卷积范围为1 ~ 3。

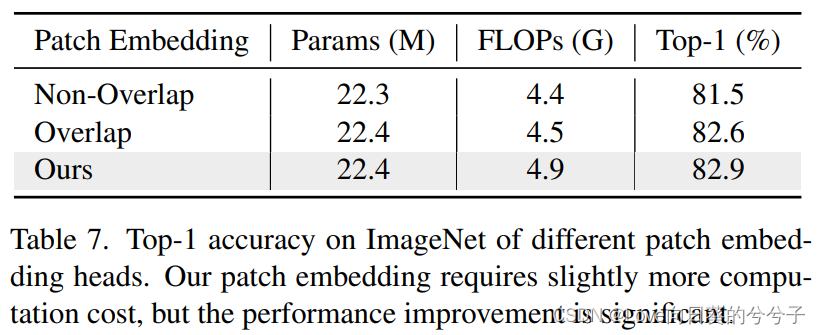
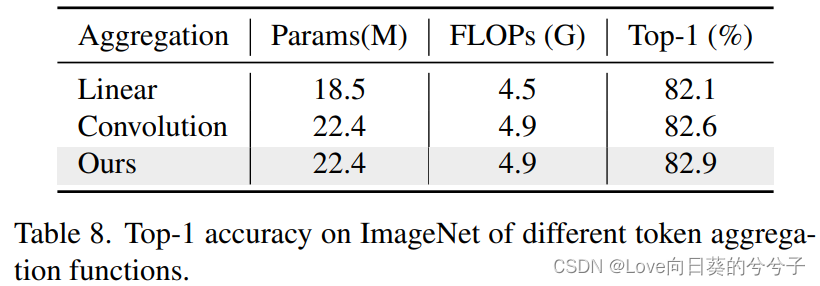
4. 实验结果
- ImageNet-1K图像分类任务

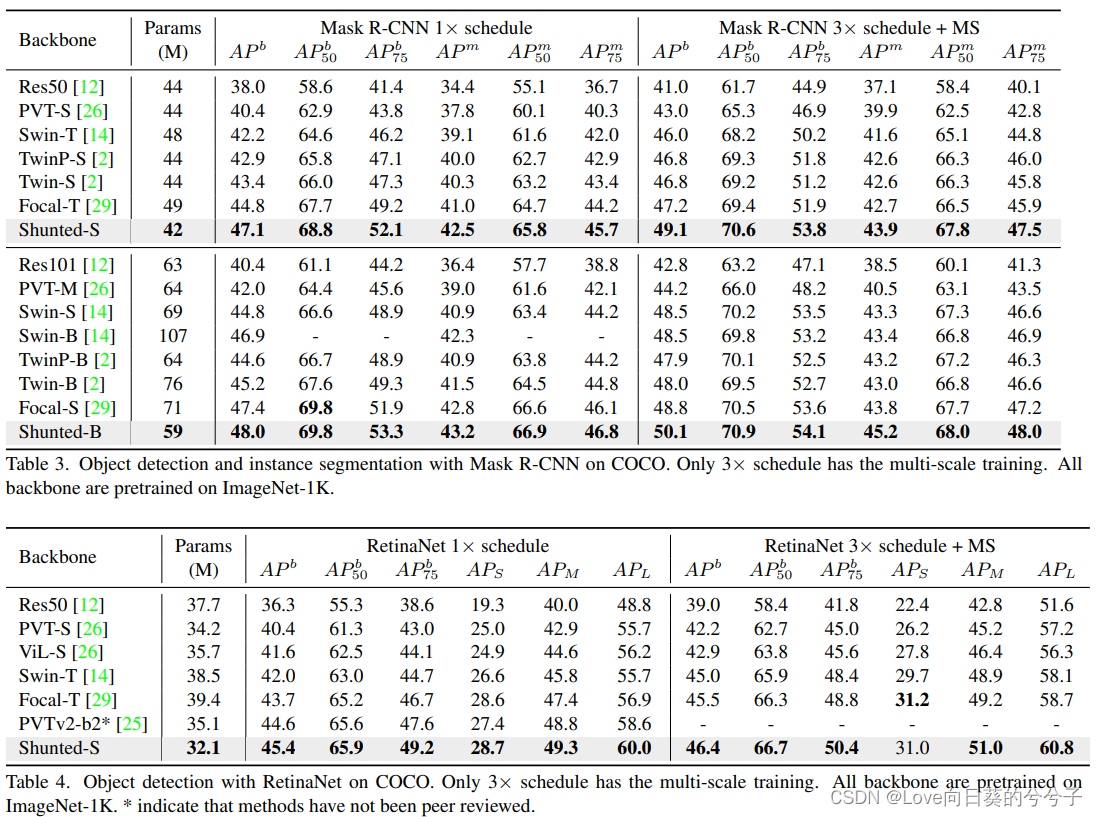
- 目标检测和实例分割任务
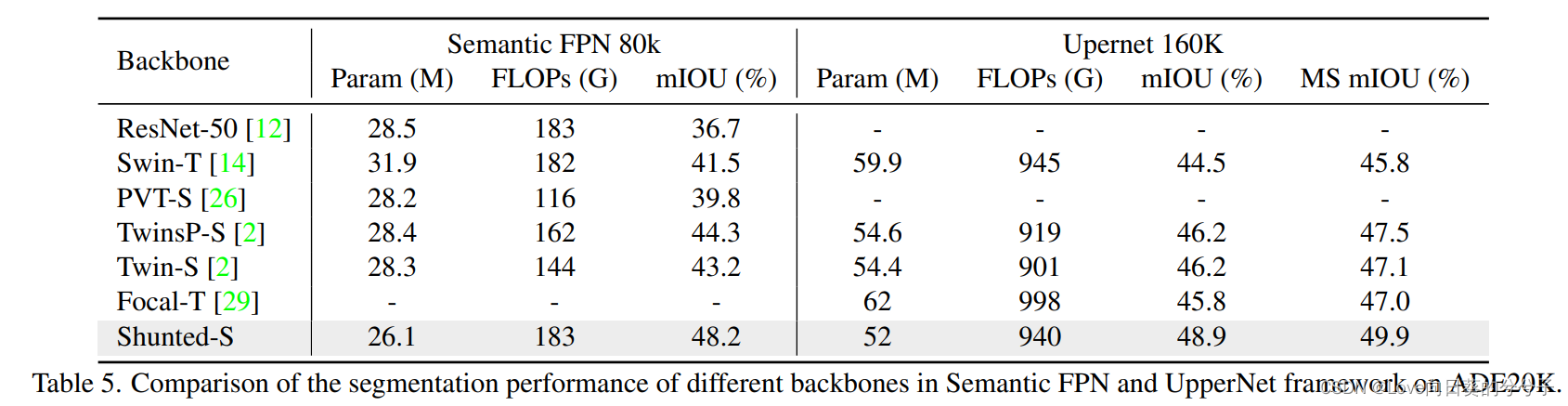
- 消融实验










![[入门必看]数据结构4.2:串的模式匹配](https://img-blog.csdnimg.cn/50b3c70d38fa44b7966ebf9ed7eefc10.png#pic_center)
![[LeetCode]路径总和](https://img-blog.csdnimg.cn/img_convert/2f6a8595f9e62ffaf3ea755b79e8e2ec.jpeg)