版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
传送门:大数据系列文章目录

目录
- scala中特质
- 特质作为接口使用
- 特质中放置非抽象的成员
- 特质的模板操作
- 特质的混入对象操作
- 特质的执行链条
- 特质的构造执行流程
- 特质继承class
- 样例类
- 样例对象
- scala中模式匹配操作
- Option类型
- scala中偏函数
- scala中正则表达式操作
- scala中异常处理
- 柯里化
- 闭包
- 隐式转换和隐式参数
scala中特质
scala中没有Java中的接口(interface),替代的概念是——特质
语法
trait 名称 {
// 抽象字段
// 抽象方法
}
继承特质:
class 类 extends 特质1 with 特质2 {
// 字段实现
// 方法实现
}
说明:
- 特质是scala中代码复用的基础单元
- 它可以将方法和字段定义封装起来,然后添加到类中
- 与类继承不一样的是,类继承要求每个类都只能继承一个超类,而一个类可以添加任意数量的特质。
- 特质的定义和抽象类的定义很像,但它是使用trait关键字
- 使用extends来继承trait(scala不论是类还是特质,都是使用extends关键字)
- 如果要继承多个trait,则使用with关键字
特质作为接口使用
创建特质
package com.lee
trait Person {
//抽象成员变量
val name:String
val age: Int
var address:String
var birthday:String
// 抽象的方法
def work()
def eat()
}
继承特质
package com.lee
class Teacher extends Person {
override val name: String = "小胖"
override val age: Int = 45
override var address: String = "北海"
override var birthday: String = "1980-10-05"
override def work(): Unit = {
println("开始工作....")
}
override def eat(): Unit = {
println("小胖开始吃饭....")
}
}
相关的操作
package com.lee
object MainTest01 {
def main(args: Array[String]): Unit = {
val teacher = new Teacher
teacher.work()
println(teacher.age)
}
}
特质中放置非抽象的成员
创建特质
package com.lee
trait Person {
//抽象成员变量
val name:String
val age: Int
var address:String
var birthday:String
// 定义一个非抽象的成员变量
val sex:String = "男"
// 抽象的方法
def work()
def eat()
// 定义非抽象的方法
def run(): Unit ={
println("人人都需要跑步 健身....")
}
}
特质的模板操作
示例: 模拟一个日志输出到不同地方的操作
创建特质: 指定输出的内容 , 具体输出位置 并不清楚, 采用抽象
package com.lee
trait Logger {
def msg():String
def info() = println("输出info日志:"+msg())
def waring() = println("输出警告日志:"+msg())
def error() = println("输出错误日志:"+msg())
}
继承特质: 指定输出的地方
package com.lee
class ConsoleLogger extends Logger {
override def msg() = "控制台"
}
使用操作
package com.lee
object MainTest01 {
def main(args: Array[String]): Unit = {
val consoleLogger = new ConsoleLogger
consoleLogger.info()
}
}
特质的混入对象操作
作用: 可以增强对象的功能
格式:
new 类 with 特质
操作
创建特质
package com.lee
trait Person {
val name:String = "李哥"
def study() = {
println(name + ":爱学习....")
}
}
使用特质混入
package com.lee
object MainTest01 {
def main(args: Array[String]): Unit = {
// 对象混入特质: 提升当前这个对象的功能
val tearcher = new Tearcher with Person
tearcher.study()
}
}
特质的执行链条
说明: 当一个类继承了多个特质, 而多个特质又有相同的方法, 并每个方法都调用父类的方法, 此时执行顺序为从右往左依次执行
演示操作
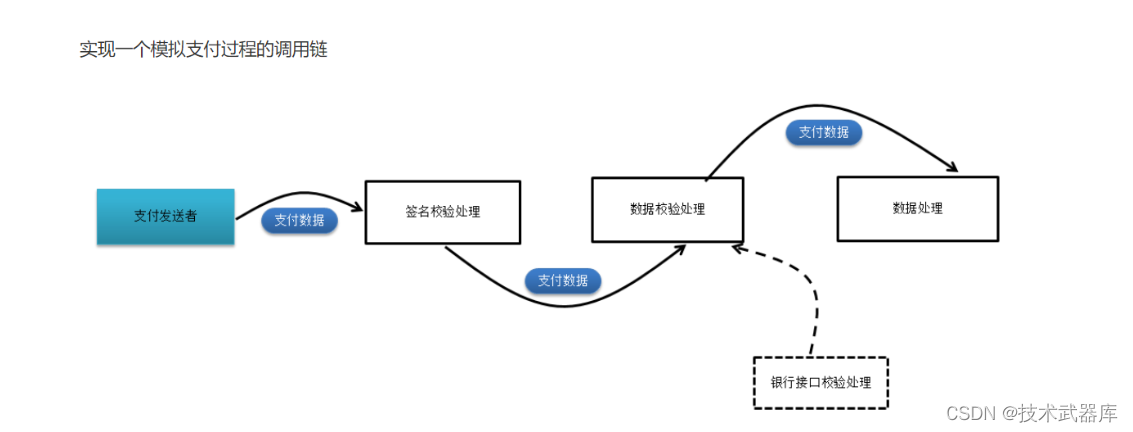
代码演示
trait HandlerTrait {
def handle(data:String) = println("处理数据...")
}
trait DataValidHanlderTrait extends HandlerTrait {
override def handle(data:String): Unit = {
println("验证数据...")
super.handle(data)
}
}
trait SignatureValidHandlerTrait extends HandlerTrait {
override def handle(data: String): Unit = {
println("校验签名...")
super.handle(data)
}
}
class PayService extends DataValidHanlderTrait with SignatureValidHandlerTrait {
override def handle(data: String): Unit = {
println("准备支付...")
super.handle(data)
}
}
def main(args: Array[String]): Unit = {
val service = new PayService
service.handle("支付参数")
}
// 程序运行输出如下:
// 准备支付...
// 检查签名...
// 验证数据...
// 处理数据...
特质的构造执行流程
说明: 当类继承了多个特质后, 而多个特质中都有构造方法, 此时执行的顺序为:
- trait也有构造代码,但和类不一样,特质不能有构造器参数
- 每个特质只有
一个无参数的构造器。 - 一个类继承另一个类、以及多个trait,当创建该类的实例时,它的构造顺序如下
- 执行父类的构造器
从左到右依次执行trait的构造器- 如果trait有父trait,先构造父trait,如果多个trait有同样的父trait,则只初始化一次
- 执行子类构造器
相关的操作:
创建多个特质
package com.lee
trait T1 {
println("这是T1的特质 构造方法.....")
}
package com.lee
trait T2 extends T1{
println("这是T2的特质 构造方法.....")
}
package com.lee
trait T3 extends T1{
println("这是T3的特质 构造方法.....")
}
package com.lee
trait T4 extends T3{
println("这是T4的特质 构造方法.....")
}
创建一个普通类 继承特质
package com.lee
class C5 extends T4 with T3 with T2 with T1{
println("这是 C5的构造方法")
}
调用使用
package com.lee
object MainTest01 {
def main(args: Array[String]): Unit = {
new C5
}
}
特质继承class
trait也可以继承class的。特质会将class中的成员都继承下来。
相关的操作:
创建一个类
package com.lee
class C1 {
val name:String = "张三"
def eat() = {
println(name+":吃东西")
}
}
创建一个特质
package com.lee
trait T1 extends C1{
}
创建测试:
package com.lee
object MainTest01 {
def main(args: Array[String]): Unit = {
val c = new C1
c.eat()
}
}
样例类
什么是样例类? 样例类主要的作用是为了进行封装数据的操作, 类似于java中实体类(POJO JavaBean)
如何实现一个样例类:
case class 样例类名([var/val] 成员变量名1:类型1, 成员变量名2:类型2, 成员变量名3:类型3)
使用说明:
1) 在定义样例类的时候,成员变量是不需要进行初始化的操作
2) 成员变量可使用val 或者 var修饰, 默认采用 val, 所以在定义的时候, 是可以省略的
3) 如果使用val来定义变量, 此变量在创建样例类对象后, 其变量只能被赋值一次
需求
- 定义一个Person样例类,包含姓名和年龄成员变量
- 创建样例类的对象实例(“张三”、20),并打印它
object Demo01 {
/*
需求
- 定义一个Person样例类,包含姓名和年龄成员变量
- 创建样例类的对象实例("张三"、20),并打印它
说明:
1) 在样例类中, 默认重写toString方法
2) 为成员变量自动实现 get 和 set 方法
3) 在样例类自动实现 apply方法, 构建样例类对象的时候, 可以不写new的
*/
case class Person(name:String , age:Int)
def main(args: Array[String]): Unit = {
val person:Person = new Person("张三",20)
println(person) // Person(张三,20)
// 创建person对象:
val person1:Person = Person("张三",20)
println(person1)
}
}
当我们定义一个样例类,编译器自动帮助我们实现了以下几个有用的方法:
- apply方法
- toString方法
- equals方法
- hashCode方法
- copy方法
样例对象
是单例的, 只有一个示例对象, 一般将样例对象, 看做是java中一种用于定义常量的操作(枚举)
格式:
case object 样例对象名
需求说明
- 定义一个性别Sex枚举,它只有两个实例(男性——Male、女性——Female)
- 创建一个Person类,它有两个成员(姓名、性别)
- 创建两个Person对象(“张三”、男性)、(“李四”、“女”)
package com.lee
object Demo02 {
/*
需求说明
- 定义一个性别Sex枚举,它只有两个实例(男性——Male、女性——Female)
- 创建一个Person类,它有两个成员(姓名、性别)
- 创建两个Person对象("张三"、男性)、("李四"、"女")
*/
trait Sex
case object Male extends Sex
case object Female extends Sex
case class Person(name:String ,sex:Sex)
def main(args: Array[String]): Unit = {
val person1 = Person("张三",Male)
val person2 = Person("李四",Female)
println(person1)
}
}
scala中模式匹配操作
scala中模式匹配的操作, 类似于java中switch语句, 但是要比java的switch语句要强大的多, 在java的switch语句仅支持一些基本数据类型
格式:
变量 match {
case "常量1" => 表达式1
case "常量2" => 表达式2
case "常量3" => 表达式3
case _ => 表达式4 // 默认配
}
相关的操作
package com.lee
class MatchDemo01 {}
import scala.io.StdIn
import scala.util.Random
object CaseDemo {
def main(args: Array[String]): Unit = {
//1.匹配字符串/数字....
println("---1.匹配字符串---")
val arr1 = Array("hadoop","spark")
var name = arr1(Random.nextInt(arr1.length)) //随机生成一个[0 ~ arr1.length)范围的数字
//name = "xxx"
println(name)
/*if( name == "hadoop"){
println("hadoop是大数据中离线存储和计算的框架....")
}else if (name == "spark") {
println( "spark是大数据中用于计算的框架, 既可以进行实时计算, 也可以离线计算操作")
}else {
println("既不是hadoop 也不是 spark....")
}*/
name match {
case "hadoop" => println("hadoop是大数据中离线存储和计算的框架....")
case "spark" => println( "spark是大数据中用于计算的框架, 既可以进行实时计算, 也可以离线计算操作")
case _ => println("既不是hadoop 也不是 spark....")
}
//注意:上面功能和Java中的功能一样!
//下面的才是Scala中的模式匹配特有的功能
//2.匹配类型
println("---2.匹配类型---")
//这样做的意义在于不用使用isInstanceOf和asInstanceOf方法
val arr2 = Array("hello", 1, CaseDemo)
val value = arr2(Random.nextInt(arr2.length))
println(value)
value match {
case a:String => println(s"${a} : 是一个 字符串类型的数据")
case a:Int => println(s"${a} : 是一个 int类型的数据")
case a:CaseDemo.type => println(s"${a} : 是一个 CaseDemo 类型的数据")
}
// 注意: 在判断的时候, 如果后面的表达式没有使用的前面的变量, 那么变量可以使用 _ 替代
value match {
case _:String => println("是一个 字符串类型的数据")
case _:Int => println("是一个 int类型的数据")
case _:CaseDemo.type => println("是一个 CaseDemo 类型的数据")
}
//3.匹配集合
println("---3.匹配集合---")
val arr3 = Array(1,2,3)
arr3 match {
case Array(1, x, y) => println(x + " " + y) //3 5 //自带break
case Array(0) => println("only 0")
case Array(1, _*) => println("1 ...")
case _ => println("没有匹配上")
}
val li = List(0,1)
li match {
case 0 :: Nil => println("only 0") //List(0)
case x :: y :: Nil => println(s"x: $x y: $y") //x: 3 y: -1 //List(x,y)
//case 0 :: xx => println("0 "+ xx)
case 0 :: tail => println("0 "+ tail)
case _ => println("没有匹配上")
}
val tup = (2, 3, 5)
tup match {
case (1, x, y) => println(s"1, $x , $y") //1, 3 , 7
case (_, z, 5) => println(z)
case _ => println("没有匹配上")
}
// 4. 模式匹配_守卫
val a = StdIn.readInt() // 键盘输入操作
a match {
case _ if a >= 0 && a <= 3 => println("[0-3]")
case _ if a >= 4 && a <= 8 => println("[4-8]")
case _ => println("未匹配")
}
//5.变量声明中隐藏的模式匹配 (了解)
println("---4.变量声明中隐藏的模式匹配---")
val (x, y) = (1, 2)
println(x) //1
println(y) //2
val (q, r) = BigInt(10) /% 3
println(q) //3
println(r) //1
val arr4 = Array(1, 7, 2, 9)
val Array(first, second, _*) = arr4
println(first, second) //(1,7)
//6.for循环中隐藏的模式匹配 (了解)
println("---5.for循环中隐藏的模式匹配---")
val map = Map("k1" -> "v1", "k2" -> "v2", "k3" -> "v3")
//val map = Map(("k1","v1"),("k2","v2"),("k3","v3"))
for ((k, v) <- map) {
println(k + ":" + v)
}
//6.函数式操作中的模式匹配
println("---6.函数式操作中的模式匹配---")
map.foreach {
case (k, v) => println(k, v)
}
//7.匹配样例类和样例对象
println("---7.匹配样例类---")
val arr = Array(StartTask("task1"), StopTask)
val obj =arr(1)
println(obj)
obj match {
case StartTask(name) => println("start")
case StopTask => println("stop")
}
}
}
case class StartTask(name: String) //case class可以带参数,可以封装数据,也可以用作模式匹配
case object StopTask//case object一般都作为模式匹配来使用,不能够带参数
Option类型
作用: 为了避免空指针的错误, 保证调用方法的时候, 返回值不会是Null
定义
scala中,Option类型来表示可选值。这种类型的数据有两种形式:
-
Some(x):表示实际的值
-
None:表示没有值
相关的方法:
isEmpty: 判断是否为空, 如果有数据 返回 false 如果没有数据(None) 返回true
get : 用于从Option类型中获取数据, 如果类型为Nont 直接抛出异常, 表达出那个部分出现问题
getOrElse: 当Option类型为None的时候, 返回设置的默认值
示例说明
- 定义一个两个数相除的方法,使用Option类型来封装结果
- 然后使用模式匹配来打印结果
不是除零,打印结果
除零打印异常错误
/**
* 定义除法操作
* @param a 参数1
* @param b 参数2
* @return Option包装Double类型
*/
def dvi(a:Double, b:Double):Option[Double] = {
if(b != 0) {
Some(a / b)
}
else {
None
}
}
def main(args: Array[String]): Unit = {
val result1 = dvi(1.0, 5)
result1 match {
case Some(x) => println(x)
case None => println("除零异常")
}
}
示例二
示例说明
- 重写上述案例,使用getOrElse方法,当除零时,或者默认值为0
参考代码
def dvi(a:Double, b:Double) = {
if(b != 0) {
Some(a / b)
}
else {
None
}
}
def main(args: Array[String]): Unit = {
val result = dvi(1, 0).getOrElse(0)
println(result)
}
scala中偏函数
偏函数可以提供了简洁的语法,可以简化函数的定义。配合集合的函数式编程,可以让代码更加优雅。
偏函数本质上就是一种函数
格式:
- 偏函数被包在花括号内没有match的一组case语句是一个偏函数
- 偏函数是PartialFunction[A, B]的一个实例
- A代表输入参数类型
- B代表返回结果类型
{
case x => 表达式
...
}
示例说明
- 定义一个列表,包含1-10的数字
- 请将1-3的数字都转换为[1-3]
- 请将4-8的数字都转换为[4-8]
- 将其他的数字转换为(8-*]
package com.lee
import scala.io.StdIn
object Demo01 {
/*
- 定义一个列表,包含1-10的数字
- 请将1-3的数字都转换为[1-3]
- 请将4-8的数字都转换为[4-8]
- 将其他的数字转换为(8-*]
*/
def main(args: Array[String]): Unit = {
val list1: List[Int] = (1 to 10).toList
// 原生写法: 基于普通函数的操作
val list2: List[String] = list1.map(i => {
if (i <= 3) {
"[1-3]"
} else if (i >= 4 && i <= 8) {
"[4-8]"
} else {
"(8-*]"
}
})
println(list2)
// 偏函数实现:
val list3: List[String] = list1.map {
case i if i <= 3 => "[1-3]"
case i if i >= 4 && i <= 8 => "[4-8]"
case _ => "(8-*]"
}
println(list3)
}
}
scala中正则表达式操作
使用scala如何通过正则判断字符串是否符合规则
定义
Regex类
-
scala中提供了Regex类来定义正则表达式
-
要构造一个RegEx对象,直接使用String类的r方法即可
-
建议使用三个双引号来表示正则表达式,不然就得对正则中的反斜杠来进行转义
val regEx = """正则表达式""".r
findAllMatchIn方法
- 使用findAllMatchIn方法可以获取到所有正则匹配到的字符串
示例一
示例说明
-
定义一个正则表达式,来匹配邮箱是否合法
val r = “”“.+@.+…+”“”.r
-
合法邮箱测试:qq12344@163.com
-
不合法邮箱测试:qq12344@.com
package com.lee
import scala.util.matching.Regex
object Demo01 {
def main(args: Array[String]): Unit = {
//1.定义用于判定邮箱是否正确的正则表达式
val regEx: Regex = """.+@.+..+""".r
//2. 定义一个邮箱
val email = "45781212@qq.com"
//3. 判定是否符合规则
if (regEx.findAllMatchIn(email).size > 0){
// 说明匹配到了数据, 说明传递的字符串是符合规则的
println(email+": 符合规则")
}else println("不符合规则")
}
}
示例二
示例说明
找出以下列表中的所有不合法的邮箱
"38123845@qq.com", "a1da88123f@gmail.com", "zhansan@163.com", "123afadff.com"
package com.lee
import scala.util.matching.Regex
object Demo02 {
def main(args: Array[String]): Unit = {
//1. 定义一个正则表达式: 用于判断邮箱
val regEx: Regex = """.+@.+..+""".r
//2. 定义一个集合, 内部放置多个邮箱地址
val list = List("38123845@qq.com", "a1da88123f@gmail.com", "zhansan@163.com", "123afadff.com")
//3. 判断过滤操作
/*for( i <- list) {
if(regEx.findAllMatchIn(i).size <=0 ){
println(i)
}
}*/
val list1 = list.filter(i => regEx.findAllMatchIn(i).size <= 0 )
println(list1)
}
}
scala中异常处理
在scala中如果出现了异常如何处理, 处理的方式有两种: 捕获异常 抛出异常
如何捕获异常 进行处理
格式:
try {
// 代码
}
catch {
case ex:异常类型1 => // 代码
case ex:异常类型2 => // 代码
}
finally {
// 代码
}
说明:
- try中的代码是我们编写的业务处理代码
- 在catch中表示当出现某个异常时,需要执行的代码
- 在finally中,是不管是否出现异常都会执行的代码
示例
示例说明
- 使用try…catch来捕获除零异常
package com.lee
object Demo01 {
/*
示例
示例说明
- 使用try..catch来捕获除零异常
*/
def main(args: Array[String]): Unit = {
try {
val a = 1 / 0
} catch {
case e:Exception => println("出现了异常操作......")
}finally {
println("模拟除零异常")
}
}
}
- 如何抛出异常
package com.lee
object Demo02 {
def main(args: Array[String]): Unit = {
throw new Exception("这是一个异常")
}
}
基本抛出的语法是与java是一致的, 但是不同在于scala中不需要在方法上 显现将异常抛出, scala认为这种显示操作是一种设计败笔, scala默认不执行try 直接飘出处理
柯里化
柯里化, 主要的目的是为了进行参数分类, 有时候需要传递参数的时候, 可能要传递多个, 多个参数分为两类, 为了能够方便区分, 可以通过柯里化, 将方法拆分成一个参数多个参数列表形式
而且通过柯里化, 可以提供代码的维护性和便利性
在实际使用中, 一般来说, 第一个 括号传递普通参数, 第二个括号传递制定一些规则
相关操作:
package com.lee
object Demo01 {
/*
- 编写一个方法,用来完成两个Int类型数字的计算 (+ - * / %)
- 具体如何计算封装到函数中
- 使用柯里化来实现上述操作
*/
def main(args: Array[String]): Unit = {
println(sumNum(10,20))
val value1 = calculateNum(10,20)( (a,b) => a + b )
val value2 = calculateNum(10,20)( (a,b) => a - b )
val value3 = calculateNum(10,20)( (a,b) => a * b )
val value4 = calculateNum(10,20)( (a,b) => a / b )
val value5 = calculateNum(10,20)( (a,b) => a % b )
println(value3)
}
//柯里化:
def calculateNum(a:Int,b:Int)(fun1:(Int,Int) => Int ) ={
fun1(a,b)
}
// 原始写法
def sumNum(a:Int,b:Int) = {
a + b
}
def minusNum(a:Int,b:Int) = {
a - b
}
def multiplyNum(a:Int,b:Int) = {
a * b
}
def divideNum(a:Int,b:Int) = {
a / b
}
}
闭包
闭包其实就是一个函数,只不过这个函数的返回值依赖于声明在函数外部的变量。
可以简单认为,就是可以访问不在当前作用域范围的一个函数。
示例一
定义一个闭包
val y=10
val add=(x:Int)=>{
x+y
}
println(add(5)) // 结果15
add函数就是一个闭包
示例二
柯里化就是一个闭包
def add(x:Int)(y:Int) = {
x + y
}
上述代码相当于
def add(x:Int) = {
(y:Int) => x + y
}
说明:
闭包指的在执行函数的内容的时候, 函数中使用的变量并不是自己 {} 作用范围内的变量值, 而是使用比这个作用范围更大的 {}内的变量, 我们将这种行为, 称为闭包
闭包存在弊端:
由于闭包 (函数) 会使用比起自己更大范围内数据, 就会导致这个更大范围内的数据的变量数据都被这个函数所加载到, 如果更大的作用范围下数据量非常的庞大, 也会导致这些变量被这个函数进行加载到内存, 从而导致内存使用增大, 然后执行变慢, 甚至出现内存溢出错误
隐式转换和隐式参数
所谓隐式转换,是指以implicit关键字声明的带有单个参数的方法。它是自动被调用的,自动将某种类型转换为另外一种类型。
使用步骤
- 在object中定义隐式转换方法(使用implicit)
- 在需要用到隐式转换的地方,引入隐式转换(使用import)
- 自动调用隐式转化后的方法
示例
示例说明
使用隐式转换,让File具备有read功能——实现将文本中的内容以字符串形式读取出来
步骤
- 创建RichFile类,提供一个read方法,用于将文件内容读取为字符串
- 定义一个隐式转换方法,将File隐式转换为RichFile对象
- 创建一个File,导入隐式转换,调用File的read方法
package com.lee
import java.io.File
import java.text.SimpleDateFormat
object Demo01 {
class RichFile(file:File) {
def read() = {
println("执行了read方法, 读取数据....")
}
}
class RichFile2(format:SimpleDateFormat) {
def read() = {
println("执行了read方法, 读取数据....")
}
def eat() = {
println(" xxxxx")
}
def parse() = {
println(" 执行parse")
}
}
object Rich_File {
implicit def file2RichFile(file:File) = new RichFile(file)
implicit def formatRichFile(format:SimpleDateFormat) = new RichFile2(format)
implicit val pre_post: (String, String) = "<<<" -> ">>>"
}
// 方法可以带有一个标记为implicit的参数列表。这种情况,编译器会查找缺省值,提供给该方法。
def book(name:String) ( implicit pre_post: (String, String)) ={
println( pre_post._1 + name + pre_post._2)
}
def main(args: Array[String]): Unit = {
import Rich_File._
/*
val file = new File("D:\\传智工作\\上课\\scala")
file.read()
val format = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss")
format.eat()
format.parse()
*/
book("斗破苍穹")
}
}
什么时候会执行转换:
- 当对象调用类中不存在的方法或者成员时,编译器会自动将对象进行隐式转换
- 当方法中的参数的类型与目标类型不一致时


![[附源码]SSM计算机毕业设计闲置物品交易管理系统JAVA](https://img-blog.csdnimg.cn/47ef026d4b4d46e8b87ede6a764f958b.png)