附件下载链接
花指令
花指令的介绍
花指令(JunkCode)指的是使用一些技巧将代码复杂化,使人难以阅读的技术。广义上花指令与代码混淆(ObfusedCode)同义,包括结构混淆、分支混淆、语句膨胀等等
狭义上指的主要是干扰反汇编解析的技术。
花指令的原理
本质
- 反汇编器无法维护执行上下文,只能静态分析
- x86指令集是不定长指令集,每条指令的长度不确定。
线性扫描
早期反汇编器通常使用线性反汇编技术,如hex-dump, OllyDbg等
即从入口点或是代码段开头,逐条语句进行反汇编。
但这样的实现很容易被干扰。
考虑这样一段代码:
jmp label1
db 0xe8 ; 线性反汇编器会从这里开始分析
label1:
nop ; CPU从这里开始运行
当CPU执行的时候,遇到jmp label1语句就会将label1的地址写入IP寄存器
而反汇编器由于是线性扫描,则会从脏字节处开始反汇编
另外还可能由于起始地址错误导致大量指令反汇编错误
递归下降
现代反汇编器则会使用改良的递归下降技术进行反汇编,如IDA Pro。
这种技术的优点在于结合了动态执行的思想,根据跳转jmp和call的目的地址决定反汇编的起始地址
从而对抗上述花指令
但本质问题并没有解决,所以仍然可以进行干扰
考虑这样一段代码:
jz label1
jnz label1
db 0xe8 ; 干扰字节
label1:
nop ; 正常指令
由于jz和jnz都存在理论上的连续向下执行分支,所以IDA仍然会优先反汇编干扰字节,导致反汇编出错
而这里由于两条条件跳转指令的组合使用,产生了如jmp一样的效果
除了上述两种状态以外还有很多可以导致反汇编出错的技术,究其本质都是反汇编是静态的原因。
花指令的识别
反汇编错误通常会有三个特征
- call目的地址畸形
- 跳转到某条指令的中间,IDA中形如地址+x的样子
- 大量不常见、不合理的指令(由于反汇编错位而出现)
但反汇编错误并不意味着花指令,还可能是SMC(代码自解密)
具体可以考虑通过动态调试查看执行时的情况
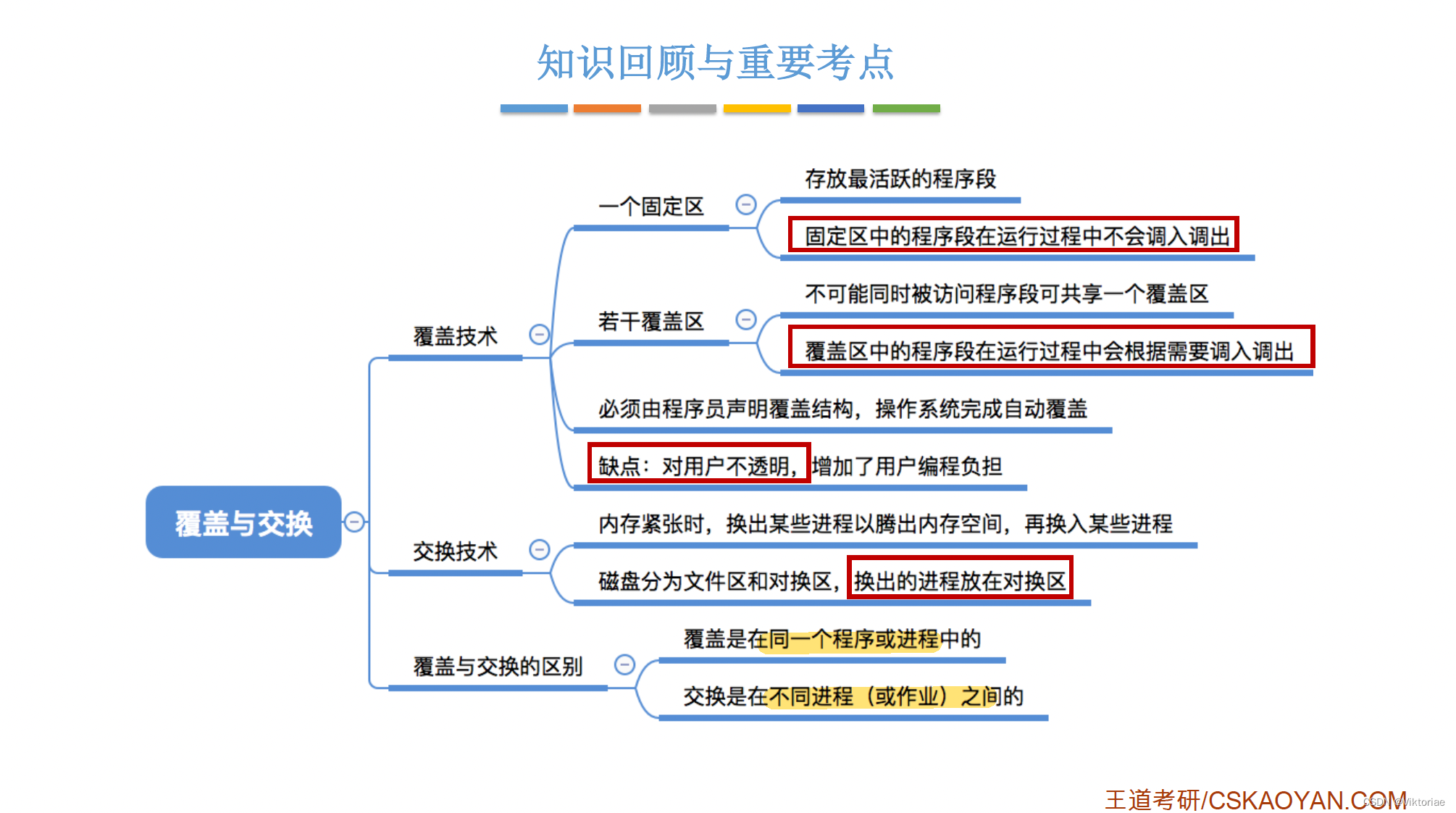
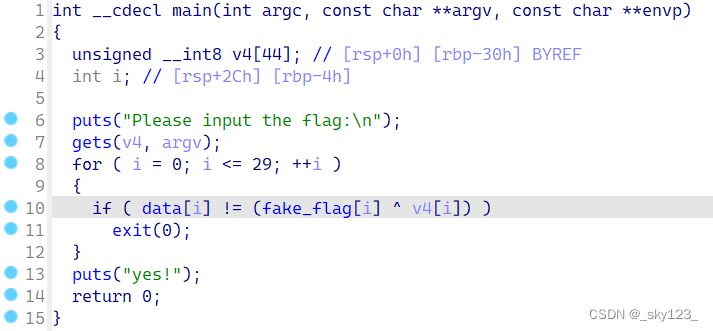
将附件中的 easy_junkcode 用 IDA64 打开,观察 main 函数可以观察到花指令的上述特征。
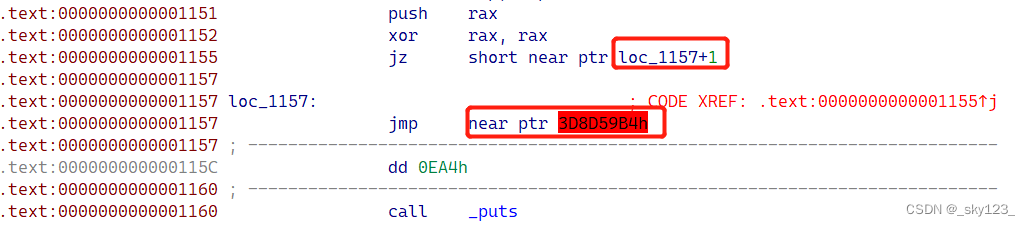
该位置实际上存在如下花指令:
__asm__(
"push rax;"
"xor rax,rax;"
"jz $+3;"
".byte 0xE9;"
"pop rax;"
);
由于 IDA无法准确判断出 jz $+3; 这条指令一定跳转,因此将 .byte 0xE9; 识别成汇编指令导致反汇编错误。
将 0x1157 开始的代码按快捷键 U undefine 然后在 0x1158 处按快捷键 C 将其识别为代码,此时反汇编结果正确。

手动去除花指令
通过Patch可以修改字节,使代码与其预期,即执行时的状态一致即可。
比如可以将 0xE9 patch 成 0x90 使其反汇编为 nop 指令。
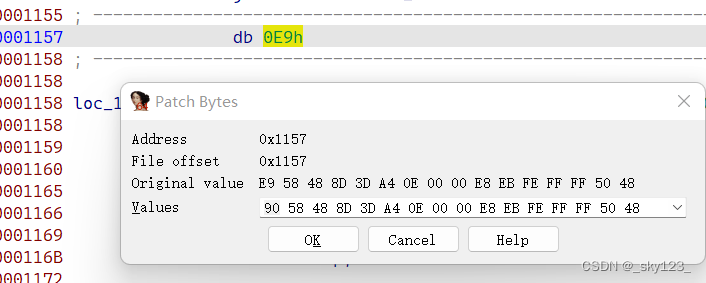
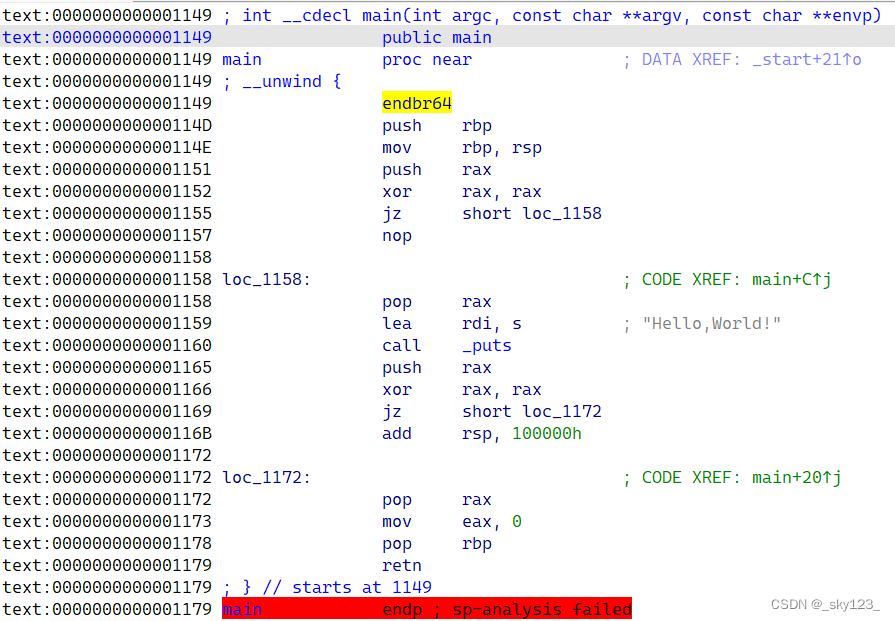
然后在 main 函数开始处按 P 快捷键让 IDA 重新分析该函数。
此时 main 函数可以正常识别。
花指令的其他影响
修复完成后按F5仍然会报错
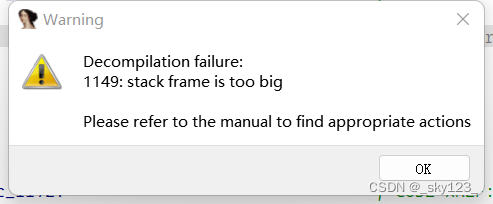
这是因为该程序中除了干扰反汇编的花指令以外,还有干扰反编译的花指令
0x1165 开始的花指令和前面的花指令原来相似,这条花指令会使 IDA 误以为 0x116B 处的指令可能会执行,导致 IDA 的栈分析出现错误。

修复方法除了前面的 patch 外还有修改 ida 对栈的分析结果。
在Options - General菜单中勾上Stack pointer选项可以查看每行指令执行之前的栈帧大小
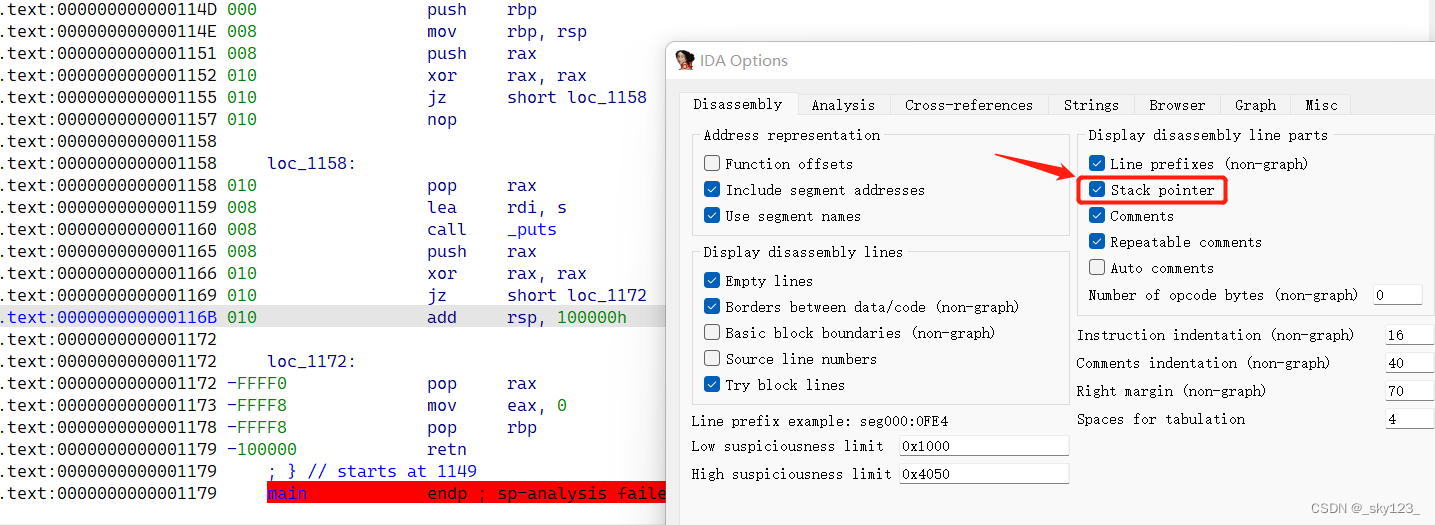
Alt + K 可以修改某条指令对栈指针的影响,从而消除这条花指令对反编译的影响。
修改后反编译正常。

利用脚本去除花指令 简单替换
用IDA打开hard_junkcode,可以发现main函数中存在花指令jz + jnz + xxx
从上往下阅读可以发现一共有三处花指令,分别在0x754、0x771和0x786地址,类型如下图所示:

观察三处花指令发现它们的机器码全都是740A7508E810000000EB04E8这一串字节序列
因此可以直接全局替换这一段内容为0x90,即NOP的机器码
from ida_bytes import get_bytes, patch_bytes
patch_bytes(0x740, get_bytes(0x740, 0x100).replace(bytes.fromhex("740A7508E810000000EB04E8"), bytes.fromhex("90" * 12)))
运行脚本后 main 函数可正常识别。
花指令的分类
常见的花指令有以下几种
-
jx + jnx

用连续两条相反的条件跳转,或是通过stc/clc汇编指令来设置位,使条件跳转变为跳转
-
call + pop
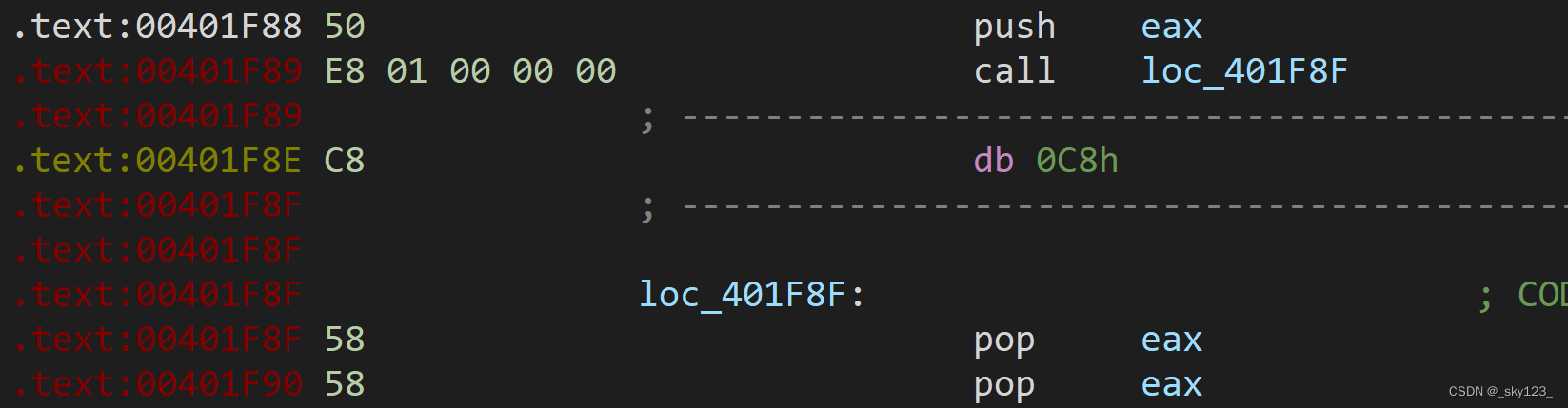
用pop的方式来清除call的压栈,使栈平衡。从而用call实现jmp。IDA会认为call的目标地址为函数起始地址,导致函数创建错误
-
call + add esp, 4
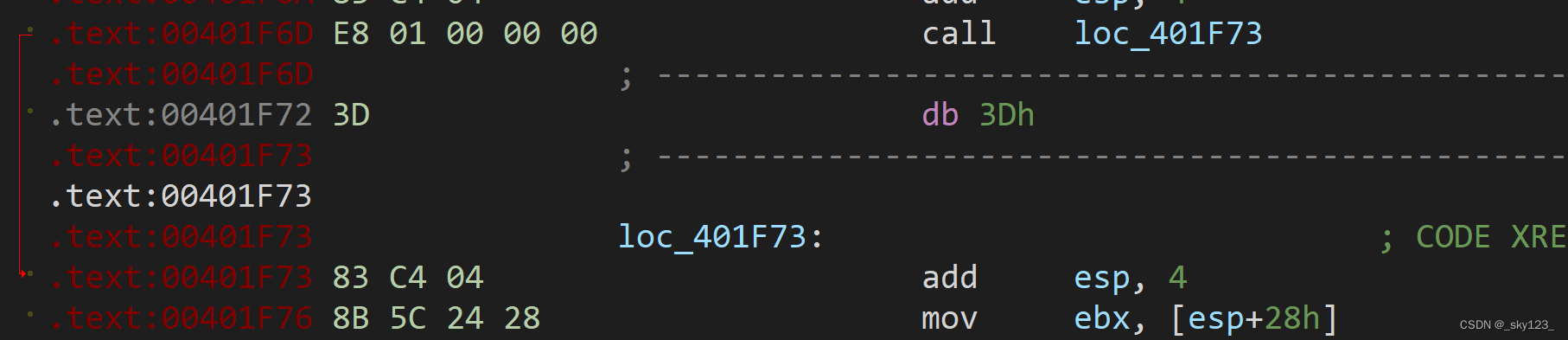
用add esp的方式来清除call的压栈,使栈平衡。从而用call实现jmp。
-
call + add [esp], n + retn
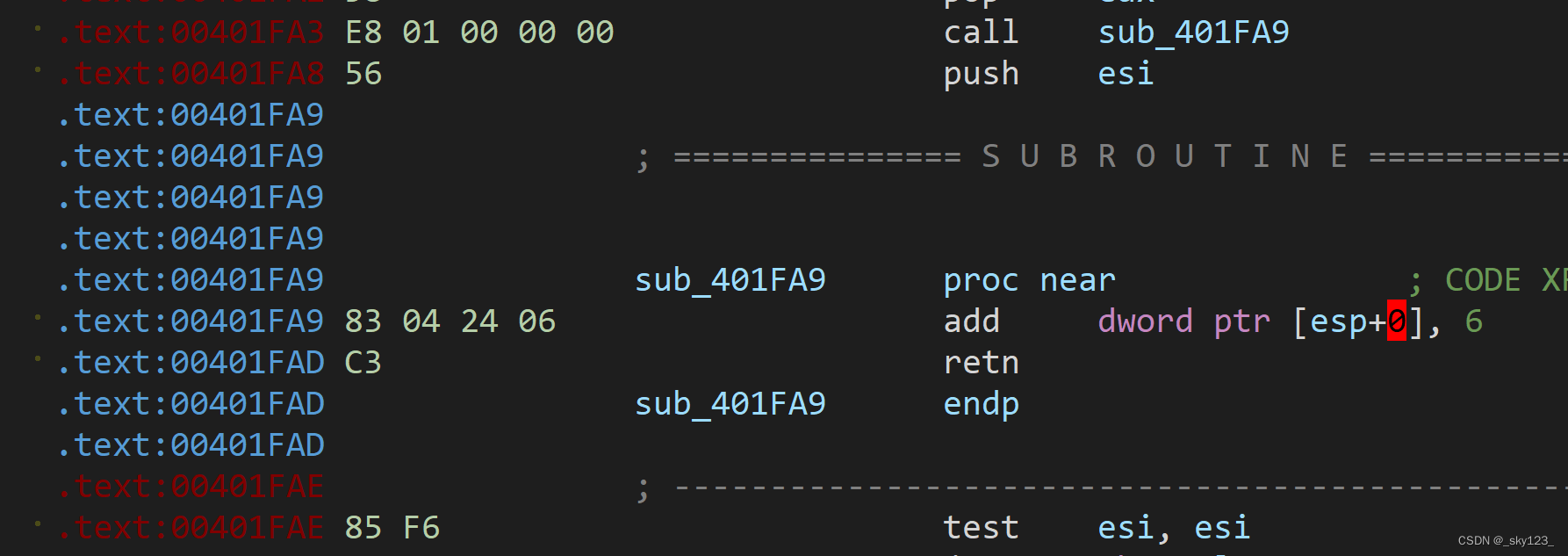
用add [esp], n和retn的方式来改变返回地址。
利用脚本去除花指令 复杂处理
用IDA打开DancingCircle,按G输入0x401f58跳转至核心函数,发现有大量花指令。因此需要借助 ida python 脚本正则表达式匹配去除。
分析汇编代码,发现花指令有如下几类:
call 花指令
-
call + pop
例如 0x00401F9B 处的花指令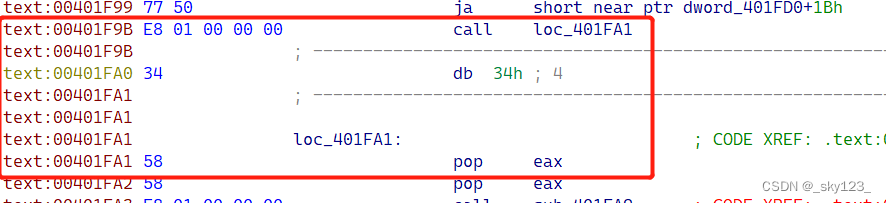
另外还有 push eax + call + pop eax + pop eax 类型的。 -
call + add esp, 4
例如 0x00401F62 处的花指令

-
call + add [esp], 6 + retn
例如 0x00401FA3 处的花指令

对于这种花指令,先用正则表达式 /\x50\xE8(.{4})(.*?)\x58\x58/ 特判 push eax + call + pop eax + pop eax 类型的,之后可用正则表达式 /\xE8(.{4})(.*?)(\x83\xC4\x04|\x58|\x83\x04\x24\x06\xc3)/ 进行匹配,即 \xE8 + 4字节立即数 + 任意长度字节的填充 + 后续特征字节 。同时根据 call 地址的计算方式可知 call 还要确保立即数要等于后面字节填充的长度。
def call_handler(s):
def work(pattern, s):
t = s[:]
for _ in range(end - start):
it = re.match(pattern, s[_:], flags=re.DOTALL)
if it is None: continue
if struct.unpack("<I", it.group(1))[0] == len(it.group(2)):
l, r = it.span()
l += _
r += _
p(s[l:r])
t = t[:l] + b"\x90" * (r - l) + t[r:]
return t
s = work(rb"\x50\xE8(.{4})(.*?)\x58\x58", s)
s = work(rb"\xE8(.{4})(.*?)(\x83\xC4\x04|\x58|\x83\x04\x24\x06\xc3)", s)
return s
jx + jnx 花指令
例如 0x00402D67 处的花指令

这类花指令可以先用正则表达式 /([\x70-\x7F])(.)([\x70-\x7F])(.).*/ 进行过滤,然后做如下检测:
- 两个跳转指令的第一个字节相差 1 且较小的那个是偶数。
- 前一个跳转的立即数比后一个多 2 。
因此可用如下方式去除,注意花指令包含特殊字符,在构造正则表达式时应注意转义。
def jx_jnx_handler(s):
for _ in range(0x70, 0x7F, 2):
def work(pattern, s):
t = s[:]
for _ in range(end - start):
it = re.match(pattern, s[_:], flags=re.DOTALL)
if it is None: continue
num1 = struct.unpack("<B", it.group(1))[0]
num2 = struct.unpack("<B", it.group(2))[0]
if num1 != num2 + 2: continue
l, r = it.span()
l += _
r += _ + num2
if num2 <= len(s):
p(s[l:r])
t = t[:l] + b"\x90" * (r - l) + t[r:]
return t
op1 = (b"\\" if _ in b"{|}" else b"") + struct.pack("<B", _)
op2 = (b"\\" if _ + 1 in b"{|}" else b"") + struct.pack("<B", _ + 1)
pattern = op1 + b"(.)" + op2 + b"(.)"
s = work(pattern, s)
pattern = op2 + b"(.)" + op1 + b"(.)"
s = work(pattern, s)
return s
fake jmp 花指令
例如 0x00401FB2 这处花指令:

这里有很多跳转,但分析后发现这些跳转都可以忽略。由于这一类花指令比较单一,因此直接匹配特征即可:
def fake_jmp_handle(s):
def work(pattern, s):
t = s[:]
for _ in range(end - start):
it = re.match(pattern, s[_:], flags=re.DOTALL)
if it is None: continue
l, r = it.span()
l += _
r += _
p(s[l:r])
t = t[:l] + b"\x90" * (r - l) + t[r:]
return t
s = work(rb"\x7C\x03\xEB\x03.\x74\xFB", s)
s = work(rb"\xEB\x07.\xEB\x01.\xEB\x04.\xEB\xF8.", s)
s = work(rb"\xEB\x01.", s)
return s
stx + jx 花指令
例如 0x0040261F 和 0x004026D7 两处花指令:

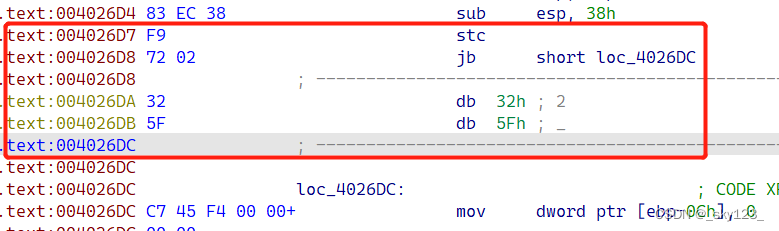
此类花指令本质是通过设置标志寄存器的值使得满足后面的条件跳转。
由于此类指令较少,直接匹配特征即可。注意,如果仅匹配前 2 个字节,那么可能会将某些指令中间的字节匹配上,这里通过 jx 跳转的距离来做简单的过滤。
def stx_jx_handler(s):
t = s[:]
pattern = rb"(?:\xF8\x73|\xF9\x72)(.)"
for _ in range(end - start):
it = re.match(pattern, s[_:], re.DOTALL)
if it is None: continue
l, r = it.span()
l += _
r += _ + struct.unpack("<B", it.group(1))[0]
if r - l > 0x40: continue
p(s[l:r])
t = t[:l] + b"\x90" * (r - l) + t[r:]
return t
完整代码
import ida_bytes
from idaapi import get_bytes, patch_bytes
import re
import struct
start = 0x00401000
end = 0x004B9CD0
def p(s): print(''.join(['%02X ' % b for b in s]))
def call_handler(s):
def work(pattern, s):
t = s[:]
for _ in range(end - start):
it = re.match(pattern, s[_:], flags=re.DOTALL)
if it is None: continue
if struct.unpack("<I", it.group(1))[0] == len(it.group(2)):
l, r = it.span()
l += _
r += _
p(s[l:r])
t = t[:l] + b"\x90" * (r - l) + t[r:]
return t
s = work(rb"\x50\xE8(.{4})(.*?)\x58\x58", s)
s = work(rb"\xE8(.{4})(.*?)(\x83\xC4\x04|\x58|\x83\x04\x24\x06\xc3)", s)
return s
def jx_jnx_handler(s):
for _ in range(0x70, 0x7F, 2):
def work(pattern, s):
t = s[:]
for _ in range(end - start):
it = re.match(pattern, s[_:], flags=re.DOTALL)
if it is None: continue
num1 = struct.unpack("<B", it.group(1))[0]
num2 = struct.unpack("<B", it.group(2))[0]
if num1 != num2 + 2: continue
l, r = it.span()
l += _
r += _ + num2
if num2 <= len(s):
p(s[l:r])
t = t[:l] + b"\x90" * (r - l) + t[r:]
return t
op1 = (b"\\" if _ in b"{|}" else b"") + struct.pack("<B", _)
op2 = (b"\\" if _ + 1 in b"{|}" else b"") + struct.pack("<B", _ + 1)
pattern = op1 + b"(.)" + op2 + b"(.)"
s = work(pattern, s)
pattern = op2 + b"(.)" + op1 + b"(.)"
s = work(pattern, s)
return s
def fake_jmp_handle(s):
def work(pattern, s):
t = s[:]
for _ in range(end - start):
it = re.match(pattern, s[_:], flags=re.DOTALL)
if it is None: continue
l, r = it.span()
l += _
r += _
p(s[l:r])
t = t[:l] + b"\x90" * (r - l) + t[r:]
return t
s = work(rb"\x7C\x03\xEB\x03.\x74\xFB", s)
s = work(rb"\xEB\x07.\xEB\x01.\xEB\x04.\xEB\xF8.", s)
s = work(rb"\xEB\x01.", s)
return s
def stx_jx_handler(s):
t = s[:]
pattern = rb"(?:\xF8\x73|\xF9\x72)(.)"
for _ in range(end - start):
it = re.match(pattern, s[_:], re.DOTALL)
if it is None: continue
l, r = it.span()
l += _
r += _ + struct.unpack("<B", it.group(1))[0]
if r - l > 0x40: continue
p(s[l:r])
t = t[:l] + b"\x90" * (r - l) + t[r:]
return t
if __name__ == '__main__':
ops = get_bytes(start, end - start)
ops = call_handler(ops)
ops = fake_jmp_handle(ops)
ops = jx_jnx_handler(ops)
ops = stx_jx_handler(ops)
patch_bytes(start, ops)
print("done")
运行效果
运行后 patch 掉了大量的花指令,可以进行反编译。

字符串混淆
字符串混淆介绍
原理
逆向工程中一个常用的技巧就是通过字符串来寻找核心代码,例如通过错误提示来找到判断的相关代码、通过提示语句找到相近的功能代码、通过日志输出找到相关的功能代码等等。可见字符串对于逆向人员是一个很重要的切入点。
因此,保护方使用字符串混淆技术,对静态文件中的字符串进行加密,使得直接在文件中搜索字符串无法获得信息。当程序运行时再对字符串进行解密,恢复其的可读性。
对抗
主要分为两种技术:
- 静态解密
- 动态记录
静态解密
简介
静态解密指的是对解密函数进行逆向,从而直接根据解密算法和加密内容进行恢复。
好处有以下几点
- 无需执行,避免环境配置、反调试等问题
- 覆盖面广,可以获取到所有可见的调用
操作
分析 ReverseMe.apk ,发现关键的验证函数在动态链接库中。
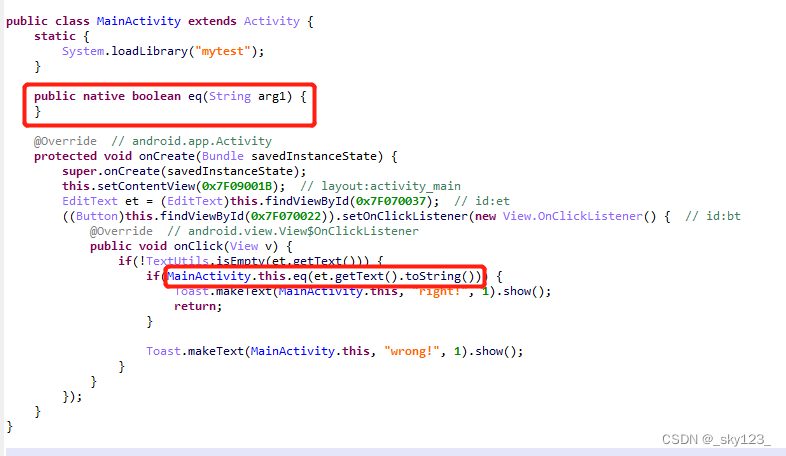
分析 libmytest.so ,发现字符串被加密。
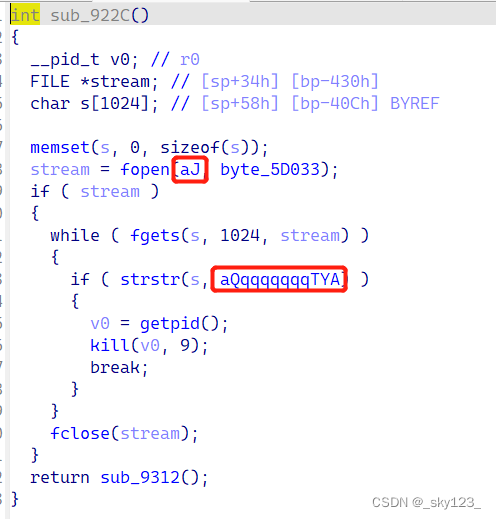
查找字符串引用,发现 datadiv_decode16733984597164250887 函数解密了字符串,解密方式是将字符串中的所有字符异或某一个值。

观察发现,这一段代码,实际上由长度为 0x1E 的代码块组成。每个代码块结构相同。
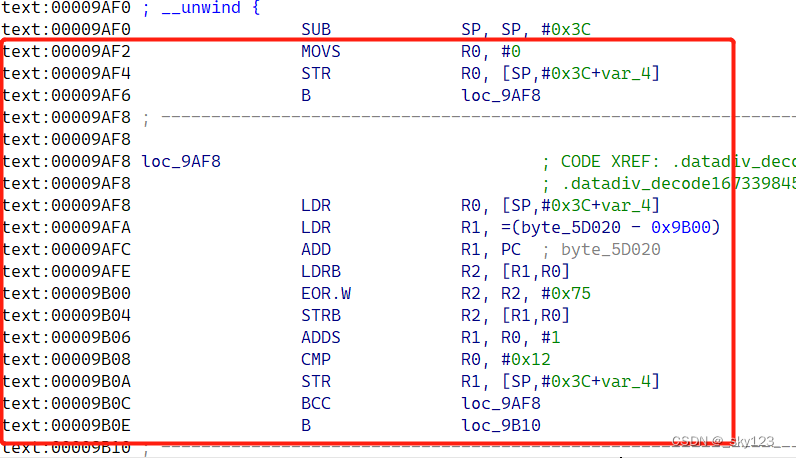
因此可以循环从每个代码块中提取参数,对待解密的字符串进行解密。
from idaapi import get_bytes, patch_bytes
import idc
start = 0x00009AF2
end = 0x00009CB2
size = 0x1E
def decode(addr, len, value):
buf = bytearray(get_bytes(addr, len))
for _ in range(len): buf[_] ^= value
print(bytes(buf))
patch_bytes(addr, bytes(buf))
if __name__ == '__main__':
for cur in range(start, end, size):
name = idc.generate_disasm_line(cur + 8, 0).split('(')[1].split(' ')[0]
addr = idc.get_name_ea_simple(name)
len = idc.get_operand_value(cur + 0x16, 1) + 1
value = idc.get_operand_value(cur + 0xE, 2)
decode(addr, len, value)
运行后解密出如下字符串:
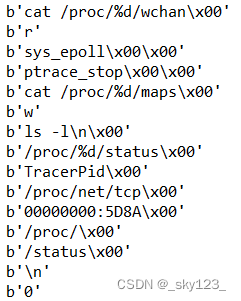
代码中的字符串被修改为原来的状态:

动态记录
简介
动态记录指的就是在程序运行以后对解密出的字符串进行记录。
这样做可以省去逆向分析的过程,因为字符串解密是程序对硬编码数据,即程序中固定的数据进行解密,与CrackMe的校验验证码是通过对输入的验证码进行解密的逻辑不同。
但缺点是要执行程序,以及可能要与反调试做对抗。另外如果字符串解密是部分触发的、甚至可能会在使用完之后加密回去,则要求记录的时间点精准。
操作
在 eq 函数下断点调试,发现字符串已经解密:
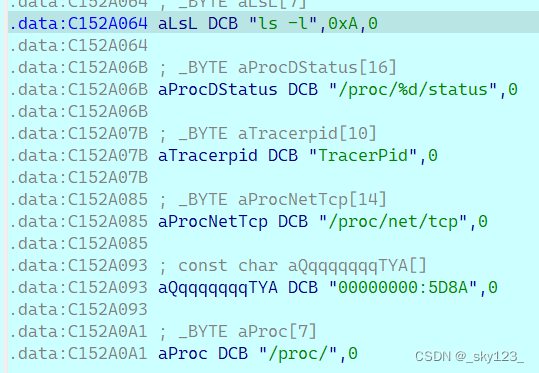
结束调试后,字符串名称已修改,便于静态分析。