前言
本文记录实践中用paddleocr训练自己的模型的基本步骤和常用命令,以detection为例
更详细内容请参考官方文档https://github.com/PaddlePaddle/PaddleOCR/tree/release/2.6/doc/doc_ch
〇、环境准备
0.1 paddlepaddle环境安装
paddle环境安装链接 根据自己的配置安装环境
0.2 克隆PaddleOCR repo代码
git clone https://github.com/PaddlePaddle/PaddleOCR
# 进入目录安装依赖
cd PaddleOCR
pip3 install -r requirements.txt
一、训练前准备
1.1 准备数据集(合成 / 下载)
https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.6/doc/doc_ch/dataset/ocr_datasets.md
到该链接根据要求的格式合成数据集 或 下载相关公开数据集
1.2 下载预训练模型(若需要的话)
这边列举几个预训练模型
wget -P ./pretrain_models/ https://paddleocr.bj.bcebos.com/pretrained/MobileNetV3_large_x0_5_pretrained.pdparams
# 或,下载ResNet18_vd的预训练模型
wget -P ./pretrain_models/ https://paddleocr.bj.bcebos.com/pretrained/ResNet18_vd_pretrained.pdparams
# 或,下载ResNet50_vd的预训练模型
wget -P ./pretrain_models/ https://paddleocr.bj.bcebos.com/pretrained/ResNet50_vd_ssld_pretrained.pdparams
1.3 修改配置文件
根据下载的预训练模型修改对应的配置文件;
https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.6/doc/doc_ch/config.md 可以到该链接找到配置文件的参数的用途和解释。
二、训练
2.1 开始训练
# 单机单卡训练 mv3_db 模型
python3 tools/train.py -c configs/det/det_mv3_db.yml \
-o Global.pretrained_model=./pretrain_models/MobileNetV3_large_x0_5_pretrained
# 单机多卡训练,通过 --gpus 参数设置使用的GPU ID
python3 -m paddle.distributed.launch --gpus '0,1,2,3' tools/train.py -c configs/det/det_mv3_db.yml \
-o Global.pretrained_model=./pretrain_models/MobileNetV3_large_x0_5_pretrained
-c 选择训练使用configs/det/det_mv3_db.yml配置文件,
-o 在不需要修改yml文件的情况下,改变训练的参数,比如,调整训练的学习率为0.0001
python3 tools/train.py -c configs/det/det_mv3_db.yml -o Optimizer.base_lr=0.0001
其他参考:
- 百度Paddlepaddle-GPU运行时出现Error: Cannot load cudnn shared library. Cannot invoke method cudnnGetVersion
- PaddleOCR遇到RuntimeError: (PreconditionNotMet) Cannot load cudnn shared library. 错误的解决
参考总结就是:
若开始训练遇到了如下报错
RuntimeError: (PreconditionNotMet) Cannot load cudnn shared library. Cannot invoke method cudnnGetVersion.
[Hint: cudnn_dso_handle should not be null.] (at /paddle/paddle/phi/backends/dynload/cudnn.cc:60)
第一步:用locate libcudnn.so 定位libcudnn.so所在路径
第二步:export LD_LIBRARY_PATH=xxx/lib:$LD_LIBRARY_PATH
2.2 断点训练
如果训练程序中断,如果希望加载训练中断的模型从而恢复训练,可以通过指定Global.checkpoints指定要加载的模型路径:
python3 tools/train.py -c configs/det/det_mv3_db.yml -o Global.checkpoints=./your/trained/model
注意:Global.checkpoints的优先级高于Global.pretrained_model的优先级,即同时指定两个参数时,优先加载Global.checkpoints指定的模型,如果Global.checkpoints指定的模型路径有误,会加载Global.pretrained_model指定的模型。
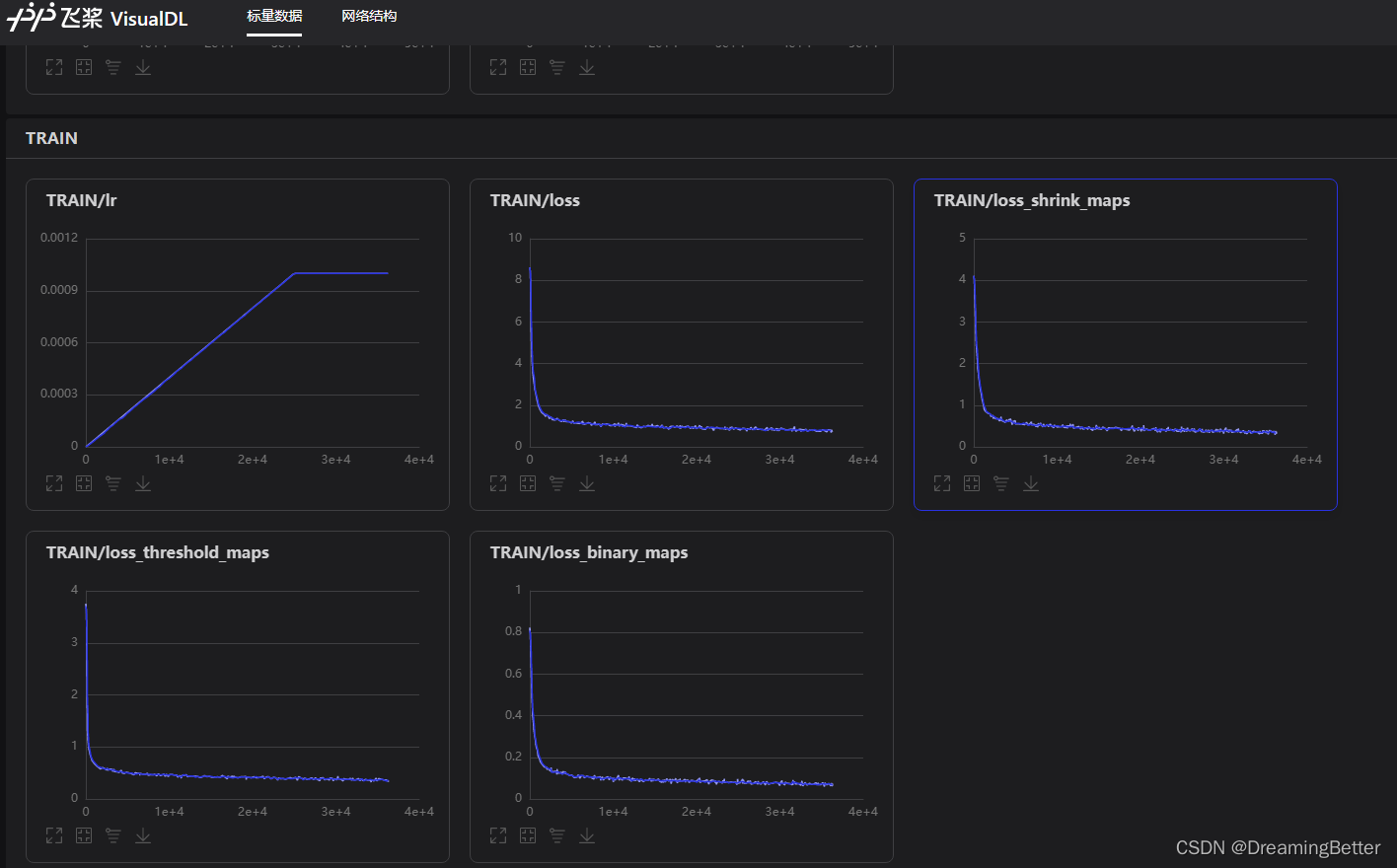
2.3 visualdl可视化训练
- 在配置文件中配置
Global.use_visualdl = True,log日志会默认保存到./output/{Global.save_model_dir}/vdl/下。 - 在命令行执行
visualdl --logdir ./output/{Global.save_model_dir}/vdl/ --host 0.0.0.0 --port 8080,即可开启训练过程的可视化。
三、模型评估与预测
3.1 评估
训练中模型参数默认保存在Global.save_model_dir目录下。在评估指标时,需要设置Global.checkpoints指向保存的参数文件。
python3 tools/eval.py -c configs/det/det_mv3_db.yml -o Global.checkpoints="{path/to/weights}/best_accuracy"
3.2 预测
测试单张图像的检测效果:
python3 tools/infer_det.py -c configs/det/det_mv3_db.yml -o Global.infer_img="./doc/imgs_en/img_10.jpg" Global.pretrained_model="./output/det_db/best_accuracy"
测试文件夹下所有图像的检测效果:
python3 tools/infer_det.py -c configs/det/det_mv3_db.yml -o Global.infer_img="./doc/imgs_en/" Global.pretrained_model="./output/det_db/best_accuracy"
四、模型导出与预测
4.1 导出为inference
检测模型转inference 模型方式:
# 加载配置文件`det_mv3_db.yml`,从`output/det_db`目录下加载`best_accuracy`模型,inference模型保存在`./output/det_db_inference`目录下
python3 tools/export_model.py -c configs/det/det_mv3_db.yml -o Global.pretrained_model="./output/det_db/best_accuracy" Global.save_inference_dir="./output/det_db_inference/"
4.2 预测
DB检测模型inference 模型预测:
python3 tools/infer/predict_det.py --det_algorithm="DB" --det_model_dir="./output/det_db_inference/" --image_dir="./doc/imgs/" --use_gpu=True