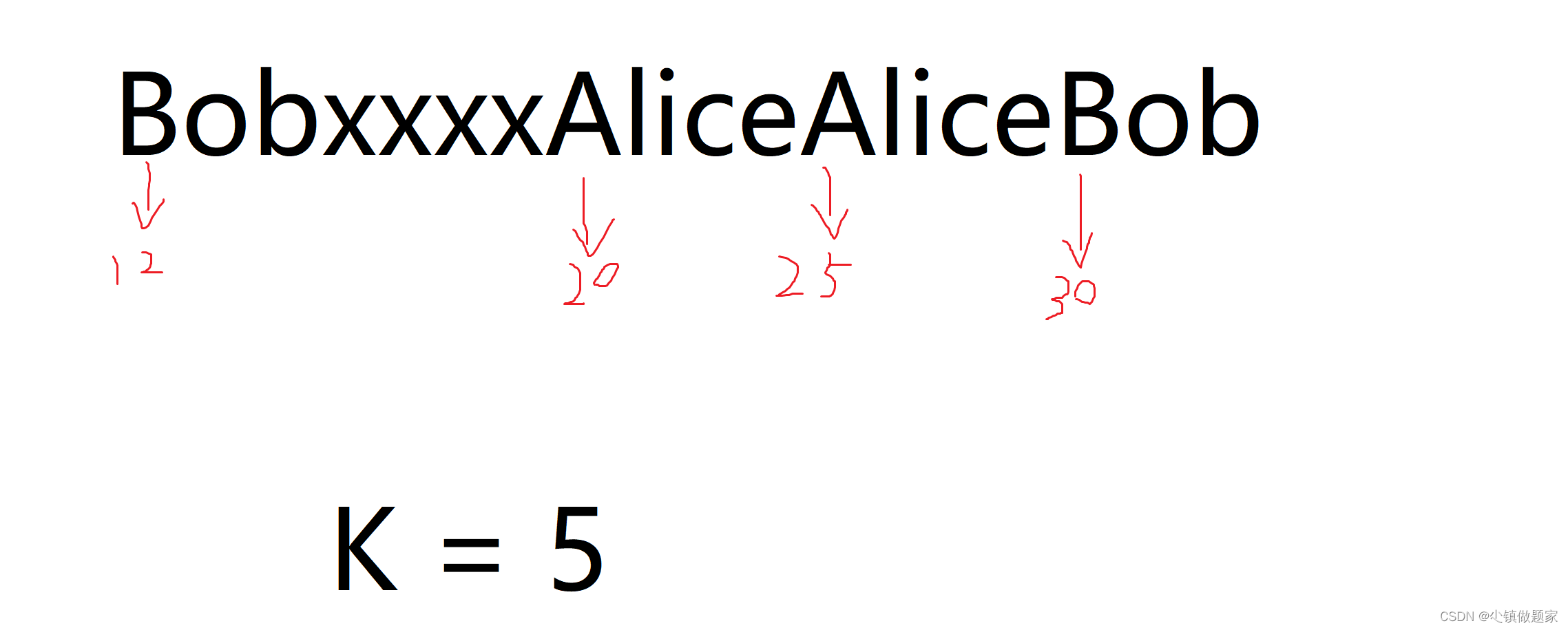文章目录
- 一、论文总览
- 二、摘要 & 目录
- 三、数据集的展示
- 四、部分代码
- 4.1 降低内存
- 4.2 部分特征生成
- 4.3 热力图分析
- 4.4 变量分布图
- 4.5 聚类算法
- 4.6 聚类结果的展示(部分)
- 4.7 聚类后的特征图
完整版的论文+代码+数据集地址:
https://mbd.pub/o/bread/ZJecmJty

【另外,接写论文的业务,价格好商量,具体可以私聊我】
一、论文总览

共计26页,8104个字。
二、摘要 & 目录
随着大数据时代的到来,个性化营销越来越受到企业的关注。客户个性分析是一种重要的市场营销策略,通过对客户数据的聚类分析,可以将客户划分为不同的群体,从而实现精细化的营销推送。本论文选用了三种常用的聚类算法,包括K-means++、Agglomerative Clustering和Spectral Clustering,通过对一个数据集的实证研究,探讨了不同聚类算法在客户个性分析中的应用。
首先,本文介绍了K-means++、Agglomerative Clustering和Spectral Clustering这三种聚类算法的基本原理和特点,并针对研究问题设定了最小簇数为2,最大簇数为8的实验设置。接着,本文选用了Silhouette score作为聚类算法的评价指标,该指标可以衡量聚类结果的紧密性和分离性。通过在实验数据集上运行不同聚类算法,并计算其对应的Silhouette score,本文得出了最好的模型为Agglomerative Clustering,并且设置簇数为3。
进一步地,本文构建了特征的主要特征图,通过对聚类结果的可视化分析,得出了最终的分类结果。这对于企业进行客户个性化营销推送具有重要的实际应用意义,可以帮助企业更好地理解客户群体的特点和需求,从而优化营销策略,提高市场竞争力。
本研究的结果表明,Agglomerative Clustering算法在客户个性分析中具有较好的性能,可以有效地帮助企业进行客户细分和个性化营销推送。同时,特征的主要特征图的构建和可视化分析也为企业提供了直观的营销决策参考。这对于企业在面对大规模客户数据时,利用聚类算法进行个性化营销具有重要的实际应用价值。
关键词:客户个性分析,K-means++,Agglomerative Clustering,Spectral Clustering,Silhouette score,特征可视化

三、数据集的展示

四、部分代码
4.1 降低内存
def reduce_mem_usage(df: pd.DataFrame) -> pd.DataFrame:
"""Iterate through all the columns of a dataframe and modify the data type to reduce memory usage"""
start_mem = df.memory_usage().sum() / 1024 ** 2
print('Memory usage of DataFrame is {:.2f} MB'.format(start_mem))
for col in df.columns:
col_type = df[col].dtype
if col_type != object:
c_min = df[col].min()
c_max = df[col].max()
if str(col_type)[: 3] == 'int':
if c_min > np.iinfo(np.int8).min and c_max < np.iinfo(np.int8).max:
df[col] = df[col].astype(np.int8)
elif c_min > np.iinfo(np.int16).min and c_max < np.iinfo(np.int16).max:
df[col] = df[col].astype(np.int16)
elif c_min > np.iinfo(np.int32).min and c_max < np.iinfo(np.int32).max:
df[col] = df[col].astype(np.int32)
elif c_min > np.iinfo(np.int64).min and c_max < np.iinfo(np.int64).max:
df[col] = df[col].astype(np.int64)
else:
if c_min > np.finfo(np.float32).min and c_max < np.finfo(np.float32).max:
df[col] = df[col].astype(np.float32)
else:
df[col] = df[col].astype(np.float64)
else:
df[col] = df[col].astype('category')
end_mem = df.memory_usage().sum() / 1024 ** 2
print('Memory usage after optimization is: {:.2f} MB'.format(end_mem))
print('Decreased by {:.1f}%'.format(100 * (start_mem - end_mem) / start_mem))
return df

4.2 部分特征生成

4.3 热力图分析

4.4 变量分布图

4.5 聚类算法

4.6 聚类结果的展示(部分)
聚类中心从2到8:













4.7 聚类后的特征图