目录
类型
不可变集合
可变集合
数组
不可变
可变数组
不可变数组与可变数组的转换
多维数组
List
list运算符
可变 ListBuffer
Set 集合
不可变 Set
可变 mutable.Set
Map 集合
可变 Map
元组
操作
通用操作
衍生集合操作
计算函数
排序
sorted
sortBy
sortWith
计算高级函数
实例
WordCount 案例
复杂案例
队列
并行集合
来源:
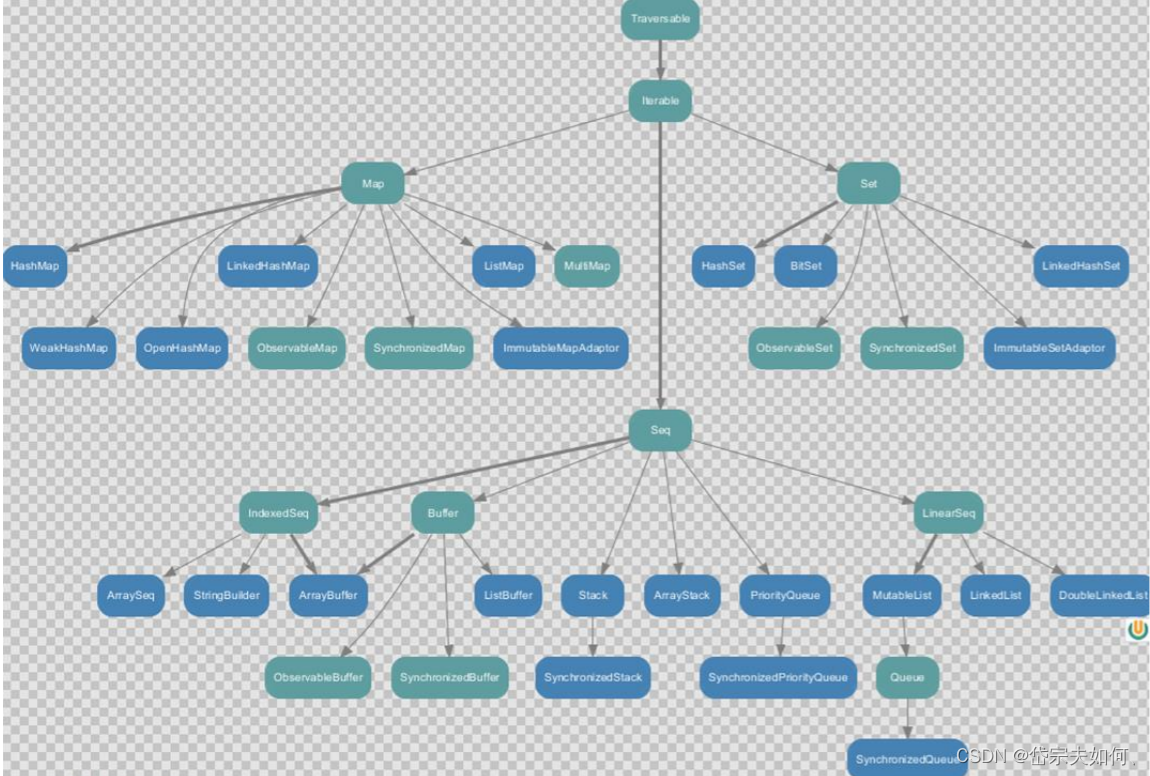
类型
不可变集合:scala.collection.immutable
可变集合: scala.collection.mutable不可变集合
可变集合

IndexedSeq 和 LinearSeq 的区别:
IndexedSeq 是通过索引来查找和定位,因此速度快,比如 String 就是一个索引集合,通过索引即可定位
LinearSeq 是线型的,即有头尾的概念,这种数据结构一般是通过遍历来查找
数组
不可变
val arr =new Array[类型](大小) val arr01 = new Array[Int](4)
println(arr01.length) // 4
//(2)数组赋值
//(2.1)修改某个元素的值
arr01(3) = 10
//(2.2)采用方法的形式给数组赋值
arr01.update(0, 1) //将第0个数赋值为1
//(3)遍历数组
//(3.1)查看数组
println(arr01.mkString(","))
//(3.2)普通遍历
for (i <- arr01) {
println(i)
}
//(3.3)简化遍历
def printx(elem: Int): Unit = {
println(elem)
}
arr01.foreach(printx)
// arr01.foreach((x)=>{println(x)})
// arr01.foreach(println(_))
arr01.foreach(println)
//(4)增加元素(由于创建的是不可变数组,增加元素,其实是产生新的数组)
println(arr01)
val ints: Array[Int] = arr01 :+ 5 //末尾追加
val ints1: Array[Int] = arr01 +: 5 //头部追加
println(ints)
//如果使用空格 替换掉 “.” 的时候,如果后面的操作符是以":" 号结尾的,那操作符是从右边往左边的
val new = Arr :+ 15
val new1 = 15 +: Arr
// 19 +: 32 +: Arr第二种方式定义数组
val arr1 = Array (1, 2)(1)在定义数组时,直接赋初始值
(2)使用 apply 方法创建数组对象
object TestArray {
def main(args: Array[String]): Unit = {
var arr02 = Array(1, 3, "bobo")
println(arr02.length)
for (i <- arr02) {
println(i)
}
}
}
可变数组
import scala.collection.mutable.ArrayBuffer
val arr01 = ArrayBuffer[Any](3, 2, 5) //(1)创建并初始赋值可变数组
val arr01 = ArrayBuffer[Any](1, 2, 3)
//(2)遍历数组
for (i <- arr01) {
println(i)
}
println(arr01.length) // 3
println("arr01.hash=" + arr01.hashCode())
//(3)增加元素
//(3.1)追加数据
arr01.+=(4)
arr01.foreach(print(_ ))
println()
//(3.2)向数组最后追加数据
arr01.append(5,6)//追加 5,6
arr01.foreach(print(_))
//(3.3)向指定的位置插入数据
arr01.insert(0,7,8) //第0个位置 插入 7,8
arr01.foreach(print(_))
println()
println("arr01.hash=" + arr01.hashCode())
//(4)修改元素
arr01(1) = 9 //修改第 2 个元素的值
println("--------------------------")
for (i <- arr01) {
println(i)
}
println(arr01.length) // 5不可变数组与可变数组的转换
arr1.toBuffer //不可变数组转可变数组
arr2.toArray //可变数组转不可变数组
(1)arr2.toArray 返回结果才是一个不可变数组,arr2 本身没有变化
(2)arr1.toBuffer 返回结果才是一个可变数组,arr1 本身没有变化多维数组
val arr = Array.ofDim[Double](3,4)
说明:二维数组中有三个一维数组,每个一维数组中有四个元素object DimArray {
def main(args: Array[String]): Unit = {
//(1)创建了一个二维数组, 有三个元素,每个元素是,含有 4 个元素一维
数组()
val arr = Array.ofDim[Int](3, 4)
arr(1)(2) = 88
//(2)遍历二维数组
for (i <- arr) { //i 就是一维数组
for (j <- i) {
print(j + " ")
}
println()
}
}
}List
object TestList {
def main(args: Array[String]): Unit = {
//(1)List 默认为不可变集合
//(2)创建一个 List(数据有顺序,可重复)
val list: List[Int] = List(1,2,3,4,3)
//(7)空集合 Nil
val list5 = 1::2::3::4::Nil
//(4)List 增加数据
//(4.1)::的运算规则从右向左
//val list1 = 5::list
val list1 = 7::6::5::list
//(4.2)添加到第一个元素位置
val list2 = list.+:(5)
//(5)集合间合并:将一个整体拆成一个一个的个体,称为扁平化
val list3 = List(8,9)
//val list4 = list3::list1
val list4 = list3:::list1
//(6)取指定数据
println(list(0))
//(3)遍历 List
//list.foreach(println)
//list1.foreach(println)
//list3.foreach(println)
//list4.foreach(println)
list5.foreach(println)
}
}list运算符
package test
/**
* scala中的:: , +:, :+, :::, +++, 等操作;
*/
object listTest {
def main(args: Array[String]): Unit = {
val list = List(1,2,3)
// :: 用于的是向队列的头部追加数据,产生新的列表, x::list,x就会添加到list的头部
println(4 :: list) //输出: List(4, 1, 2, 3)
// .:: 这个是list的一个方法;作用和上面的一样,把元素添加到头部位置; list.::(x);
println( list.:: (5)) //输出: List(5, 1, 2, 3)
// :+ 用于在list尾部追加元素; list :+ x;
println(list :+ 6) //输出: List(1, 2, 3, 6)
// +: 用于在list的头部添加元素;
val list2 = "A"+:"B"+:Nil //Nil Nil是一个空的List,定义为List[Nothing]
println(list2) //输出: List(A, B)
// ::: 用于连接两个List类型的集合 list ::: list2
println(list ::: list2) //输出: List(1, 2, 3, A, B)
// ++ 用于连接两个集合,list ++ list2
println(list ++ list2) //输出: List(1, 2, 3, A, B)
}
}可变 ListBuffer
import scala.collection.mutable.ListBuffer
object TestList {
def main(args: Array[String]): Unit = {
//(1)创建一个可变集合
val buffer = ListBuffer(1,2,3,4)
//(2)向集合中添加数据
buffer.+=(5)
buffer.append(6)
buffer.insert(1,2)
//(3)打印集合数据
buffer.foreach(println)
//(4)修改数据
buffer(1) = 6
buffer.update(1,7)
//(5)删除数据
buffer.-(5)
buffer.-=(5)
buffer.remove(5)
}
}Set 集合
不可变 Set
object TestSet {
def main(args: Array[String]): Unit = {
//(1)Set 默认是不可变集合,数据无序
val set = Set(1,2,3,4,5,6)
//(2)数据不可重复
val set1 = Set(1,2,3,4,5,6,3)
//(3)遍历集合
for(x<-set1){
println(x)
}
}
}可变 mutable.Set
object TestSet {
def main(args: Array[String]): Unit = {
//(1)创建可变集合
val set = mutable.Set(1,2,3,4,5,6)
//(3)集合添加元素
set += 8
//(4)向集合中添加元素,返回一个新的 Set
val ints = set.+(9)
println(ints)
println("set2=" + set)
//(5)删除数据
set-=(5)
//(2)打印集合
set.foreach(println)
println(set.mkString(","))
}
}Map 集合
object TestMap {
def main(args: Array[String]): Unit = {
// Map
//(1)创建不可变集合 Map
val map = Map( "a"->1, "b"->2, "c"->3 )
//(3)访问数据
for (elem <- map.keys) {
// 使用 get 访问 map 集合的数据,会返回特殊类型 Option(选项):
有值(Some),无值(None)
println(elem + "=" + map.get(elem).get)
}
//(4)如果 key 不存在,返回 0
println(map.get("d").getOrElse(0))
println(map.getOrElse("d", 0))
//(2)循环打印
map.foreach((kv)=>{println(kv)})
}
}可变 Map
object TestSet {
def main(args: Array[String]): Unit = {
//(1)创建可变集合
val map = mutable.Map( "a"->1, "b"->2, "c"->3 )
//(3)向集合增加数据
map.+=("d"->4)
// 将数值 4 添加到集合,并把集合中原值 1 返回
val maybeInt: Option[Int] = map.put("a", 4)
println(maybeInt.getOrElse(0))
//(4)删除数据
map.-=("b", "c")
//(5)修改数据
map.update("d",5)
map("d") = 5
//(2)打印集合
map.foreach((kv)=>{println(kv)})
}
}元组
object TestTuple {
def main(args: Array[String]): Unit = {
//(1)声明元组的方式:(元素 1,元素 2,元素 3)
val tuple: (Int, String, Boolean) = (40,"bobo",true)
//(2)访问元组
//(2.1)通过元素的顺序进行访问,调用方式:_顺序号
println(tuple._1)
println(tuple._2)
println(tuple._3)
//(2.2)通过索引访问数据
println(tuple.productElement(0))
//(2.3)通过迭代器访问数据
for (elem <- tuple.productIterator) {
println(elem)
}
//(3)Map 中的键值对其实就是元组,只不过元组的元素个数为 2,称之为
对偶
val map = Map("a"->1, "b"->2, "c"->3)
val map1 = Map(("a",1), ("b",2), ("c",3))
map.foreach(tuple=>{println(tuple._1 + "=" + tuple._2)})
}
}操作
通用操作
object TestList {
def main(args: Array[String]): Unit = {
val list: List[Int] = List(1, 2, 3, 4, 5, 6, 7)
//(1)获取集合长度
println(list.length)
//(2)获取集合大小,等同于 length
println(list.size)
//(3)循环遍历
list.foreach(println)
//(4)迭代器
for (elem <- list.itera tor) {
println(elem)
}
while (iter.hasNext){
println(iter.next())
}
//(5)生成字符串
println(list.mkString(","))
//(6)是否包含
println(list.contains(3)) //如果存在返回true,不存在返回false
}
}衍生集合操作
object TestList {
def main(args: Array[String]): Unit = {
val list1: List[Int] = List(1, 2, 3, 4, 5, 6, 7)
val list2: List[Int] = List(4, 5, 6, 7, 8, 9, 10)
//(1)获取集合的头
//获取集合的头使用head方法,可迭代的类型都可以用,一般在有序的类型里面有,无序的不考虑头和尾
println(list1.head) //1
//(2)获取集合的尾(不是头的就是尾)
println(list1.tail) //List(2, 3, 4, 5, 6, 7)
//(3)集合最后一个数据
println(list1.last) //7
//(4)集合初始数据(不包含最后一个)
println(list1.init) //List(1, 2, 3, 4, 5, 6)
//(5)反转
println(list1.reverse)
//(6)取前(后)n 个元素
println(list1.take(3))
println(list1.takeRight(3))
//(7)去掉前(后)n 个元素
println(list1.drop(3))
println(list1.dropRight(3))
//两个集合的操作
//(8)并集
println(list1.union(list2))
println(list1 ::: list2)
/如果是set做并集。那么重复的数据会被去重
val set = Set(6,12,33,45,56)
val set2 = Set(32,65,45,46,321,6)
val union2 = set.union(set2)
println(union2)
println(set ++ set2)
//(9)交集
println(list1.intersect(list2))
//(10)差集
println(list1.diff(list2))
//(11)拉链 注:如果两个集合的元素个数不相等,那么会将同等数量的数据进行拉链,多余的数据省略不用
println(list1.zip(list2))
// (12) 滑窗
//滑窗的意思是,第一次取123元素,第二次去234,每次取三个这样滑下去,每次取多少可以定义
println(list.sliding(3)) //滑窗使用sliding方法,里面的参数是每次滑的元素是几个,可以看到是一个迭代器
for(i <- list.sliding(3)){ //使用类似于迭代器的方式遍历出来
println(i)
}
println("================")
//要是里面有两个参数的话,第二个参数是步长,一个参数的时候默认步长是1
for(i <- list.sliding(3,2)){
println(i)
}
}
}计算函数
object TestList {
def main(args: Array[String]): Unit = {
val list: List[Int] = List(1, 5, -3, 4, 2, -7, 6)
//(1)求和
println(list.sum)
//(2)求乘积
println(list.product)
//(3)最大值
println(list.max)
//(4)最小值
println(list.min)
}
}排序
sorted
println(list.sorted) //这是升序,从小到大println(list.sorted.reverse) //降序可以先排序然后翻转列表,可以达到效果
println(list.sorted(Ordered[Int])) //降序sortBy
println(list.sortBy(x => x)) //按照元素大小排序
println(list.sortBy(x => x.abs)) //按照元素的绝对值大小排序sortWith
println(list.sortWith((x, y) => x < y)) //按元素大小升序排序
println(list.sortWith((x, y) => x > y)) //按元素大小降序排序计算高级函数
(1) 过滤
遍历一个集合并从中获取满足指定条件的元素组成一个新的集合
(2) 转换/映射(map)
将集合中的每一个元素映射到某一个函数
(3) 扁平化 (flatten)
有点像两个列表要合并,列表里面还套着列表,我们要将他打散,这样的操作就叫做扁平化
(4) 扁平化+映射 注:flatMap相当于先进行map操作,再进行flatten操作集合中的每个元素的子元素映射到某个函数并返回新的集合
就是将多个集合展开,组合成新的一个集合。
(5) 分组(group)
按照指定的规则对集合的元素进行分组,分组是转换成了map
(6) 简化(reduce归约)
通过指定的逻辑将集合中的数据进行聚合,从而减少数据,最
(7) 折叠(fold)
object TestList {
def main(args: Array[String]): Unit = {
val list: List[Int] = List(1, 2, 3, 4, 5, 6, 7, 8, 9)
val nestedList: List[List[Int]] = List(List(1, 2, 3), List(4, 5, 6), List(7, 8, 9))
val wordList: List[String] = List("hello world", "hello atguigu", "hello scala")
//(1)过滤
println(list.filter(x => x % 2 == 0))
//(2)转化/映射
println(list.map(x => x + 1))
//(3)扁平化
println(nestedList.flatten)
//(4)扁平化+映射 注:flatMap 相当于先进行 map 操作,在进行 flatten操作
println(wordList.flatMap(x => x.split(" ")))
//(5)分组
println(list.groupBy(x => x % 2))
}
}//reduce
object TestReduce {
def main(args: Array[String]): Unit = {
val list = List(1,2,3,4)
// 将数据两两结合,实现运算规则
val i: Int = list.reduce( (x,y) => x-y )
println("i = " + i)
// 从源码的角度,reduce 底层调用的其实就是 reduceLeft
//val i1 = list.reduceLeft((x,y) => x-y)
// ((4-3)-2-1) = -2
val i2 = list.reduceRight((x,y) => x-y)
println(i2)
}
}//Fold
list(1,2,3,4)
//10+1+2+3+4
println(list.fold(10)(_+_))
//10-1-2-3-4
list.foldLeft(10)(_-_)
//1-(2-(3-(4-10)))
list.foldRight(10)(_-_)实例
map1++map2 如果有相同的key,map1的value会被map2的value覆盖
object TestFold {
def main(args: Array[String]): Unit = {
// 两个 Map 的数据合并
val map1 = mutable.Map("a"->1, "b"->2, "c"->3)
val map2 = mutable.Map("a"->4, "b"->5, "d"->6)
//fold 要求两个()()里 的变量相同
val map3: mutable.Map[String, Int] = map2.foldLeft(map1)
{
(map, kv) => {
val k = kv._1
val v = kv._2
map(k) = map.getOrElse(k, 0) + v
map
}
}
println(map3)
}
}WordCount 案例
package com.qihang.bigdata.spark.core
class Person(){}
object Test {
def main(args: Array[String]): Unit = {
//数据
val stringList:List[String]=List(
"hello",
"hello world",
"hello scala",
"hello spark from scala",
"hello flink from scala"
)
//对字符串切分,打散所有单词的列表
// val wordList1 = stringList.map(_.split(" "))
// val wordList2 = wordList1.flatten
val wordList = stringList.flatMap(_.split(" "))
println(wordList) //List(hello, hello, world, hello, scala, hello, spark, from, scala, hello, flink, from, scala)
val groupMap = wordList.groupBy(word => word)
println(groupMap) //Map(world -> List(world), flink -> List(flink), spark -> List(spark), scala -> List(scala, scala, scala), from -> List(from, from), hello -> List(hello, hello, hello, hello, hello))
//对分组之后的list去长度,当成value
val countMap : Map[String,Int]= groupMap.map(kv => (kv._1, kv._2.length))
//排序,需要转化为list,进行排序,取前三
val sortList:List[(String,Int)]=countMap.toList
.sortWith( _._2 > _._2)
.take(3)
println(sortList)
}
}复杂案例
package com.qihang.bigdata.spark.core
class Person(){}
object Test {
def main(args: Array[String]): Unit = {
//数据
val stringList:List[(String,Int)]=List(
("hello",1),
("hello world",2),
("hello scala",3),
("hello spark from scala",1),
("hello flink from scala",2)
)
//思路1:打散,变成上一个案例
val newStringList:List[String]=stringList.map(
kv=>{
(kv._1.trim + " ")*kv._2
}
)
val wordCountList:List[(String,Int)]=newStringList
.flatMap(_.split(" "))
.groupBy(word=>word)
.map(kv=>(kv._1,kv._2.length))
.toList
.sortBy(_._2)(Ordering[Int].reverse) //降序排序
.take(3)
//2 基于预处理直接进行处理
//将字符串打散,并和个数包装成二元组
val preCountList:List[(String,Int)] = stringList.flatMap(
tuple =>{
val strings:Array[String]=tuple._1.split(" ")
strings.map( word => (word, tuple._2) )
}
)
println(preCountList)
//List((hello,1), (hello,2), (world,2), (hello,3), (scala,3), (hello,1), (spark,1), (from,1), (scala,1), (hello,2), (flink,2), (from,2), (scala,2))
//对二元组进行分组
val perCountMap:Map[String,List[(String,Int)]] = preCountList.groupBy( _._1 )
println(perCountMap)
//Map(world -> List((world,2)), flink -> List((flink,2)), spark -> List((spark,1)), scala -> List((scala,3), (scala,1), (scala,2)), from -> List((from,1), (from,2)), hello -> List((hello,1), (hello,2), (hello,3), (hello,1), (hello,2)))
//叠加每个单词预统计的个数值
//mapValues 将原有的元素集转换成新的元素集
val countMap = perCountMap.mapValues(
tupleList => tupleList.map(_._2).sum
)
println(countMap)
//Map(world -> 2, flink -> 2, spark -> 1, scala -> 6, from -> 3, hello -> 9)
//转List 排序取前三
val countList = countMap.toList //List((world,2), (flink,2), (spark,1), (scala,6), (from,3), (hello,9))
.sortWith( _._2 > _._2 )
.take(3)
println(countList)
}
}队列
object TestQueue {
def main(args: Array[String]): Unit = {
val que = new mutable.Queue[String]()
que.enqueue("a", "b", "c")
println(que.dequeue())
println(que.dequeue())
println(que.dequeue())
}
}并行集合
val result1 = (0 to 100).map{case _ =>
Thread.currentThread.getName}
val result2 = (0 to 100).par.map{case _ =>
Thread.currentThread.getName}来源:
尚硅谷
(8条消息) scala中的:: , +:, :+, :::, +++, 等操作的含义_scala:::_JasonLee实时计算的博客-CSDN博客
(11条消息) Scala 集合常用函数_scala滑窗_气质&末雨的博客-CSDN博客
每天学一点Scala之 高阶函数 flatten_51CTO博客_scala高阶函数