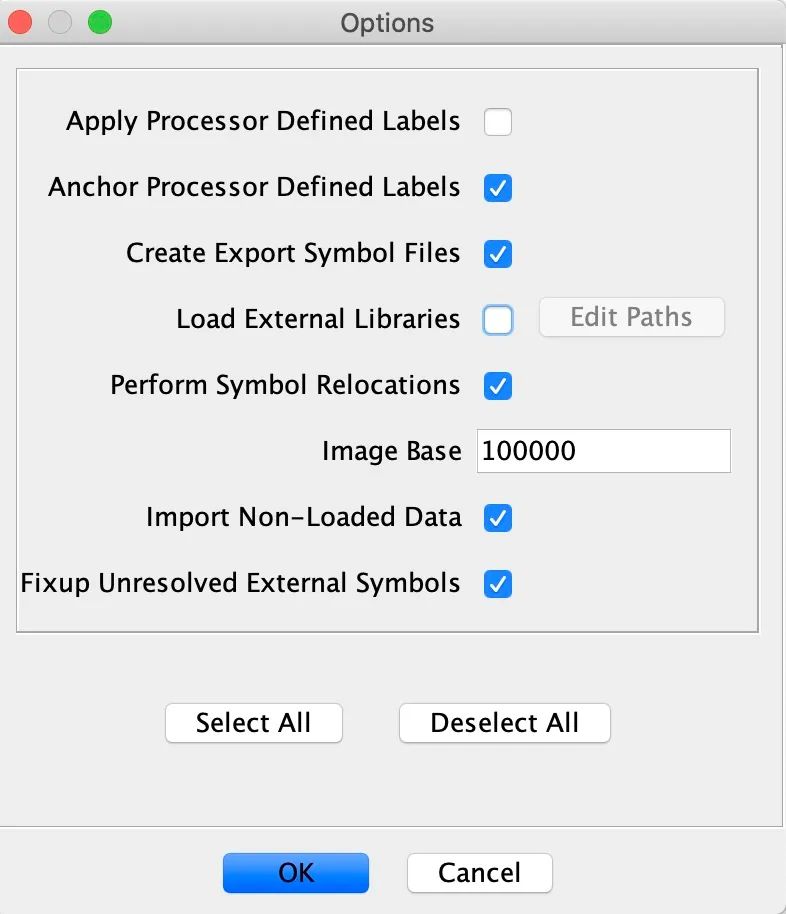
==Apply Processor Defined Lables==
在Ghidra中,apply processor defined labels功能可以为汇编代码中的地址和数据自动添加注释,这可以大大提高反汇编代码的可读性。
使用步骤如下:
打开您要反汇编的文件,进入Code Browser窗口。
点击Edit菜单,选择Apply Processor Defined Labels。
在弹出窗口中,选择要应用的处理器类型,比如ARM或Intel x86。选中“Apply to data at defined data labels”选项。
点击OK按钮,Ghidra将为汇编代码中的相关地址和数据自动添加注释。
这时你会看到类似如下的代码注释:
ARM: 0x1000: ldr r0, [pc, #0xc] ; 0x1014 @Load address of _start
ARM: 0x1004: blx r0 ; Branch to _start ARM: 0x1008: .word _start ; 0x1000 @Pointer to _start
Ghidra通过分析处理器规范,得到了各种地址和数据的值对应的语义注释,并为汇编代码添加上这些注释,极大提高了可读性。
这是一个Ghidra非常有用的功能,可以让反汇编变得更简单高效。但是,它的前提是您要选择与目标文件相匹配的处理器类型,否则无法正确分析并添加注释。
==Anchor Processor Defined Lables==
Anchor Processor Defined Labels是一个类似的功能,但它可以让您手动设置要添加注释的地址。
使用步骤如下:
定位您要添加注释的指令地址,右键选择Set Anchor Here。
点击Edit菜单,选择Apply Processor Defined Labels。
与前面介绍的功能相同,选择处理器类型和要应用到的数据,然后点击OK。
这时,Ghidra只会为设置过Anchor的地址添加注释,而不会自动分析整个文件。
设置Anchor可以让您有更精确的控制,只为感兴趣的特定地址添加注释。
举个例子,如果您的文件中有一小段特定的代码您感兴趣,那么可以只为这段代码设置Anchor,Apply Processor Defined Labels时只会为Anchor中的地址添加注释,而忽略文件中的其他地址。
这给了您更高的灵活性,可以根据需要选择只为特定地方添加注释,而不必注释整个文件。
与自动分析相比,手动设置Anchor所需要的处理器知识也更少,您只需要确定感兴趣的指令地址,并选中正确的处理器类型,Ghidra即可自动为该地址添加语义注释。
Anchor Processor Defined Labels功能让Ghidra的注释功能更加高效和可控,用户可以根据具体需要添加注释,而无需完全依赖Ghidra的自动分析。这在一定程度上降低了用户对各种指令格式的依赖,更加灵活方便。
两者的区别:
Anchor Processor Defined Labels和Apply Processor Defined Labels的主要区别在于:
Anchor Processor Defined Labels:
需要用户手动设置感兴趣的指令地址(Anchor),然后才可以添加注释。
只会为设置过Anchor的地址添加注释,忽略文件中其他地址。
用户控制更精细,可以有选择性地只为特定地址添加注释。
对处理器知识的依赖较少,用户只需要确定正确的处理器类型。
Apply Processor Defined Labels:
会自动分析整个文件,为所有的指令地址和数据添加注释。
需要正确选择与目标文件相匹配的处理器类型,否则无法正确分析和添加注释。
需要对相应的处理器指令格式和规范有一定了解,才能判断分析结果是否正确。
适用于需要完全理解反汇编代码的情况,需要为所有的地址添加注释。
所以,两者的选择依据如下:
如果您需要完全理解反汇编代码,选择Apply Processor Defined Labels。但需要对处理器知识有一定了解。
如果您只需要理解文件的某一小段代码,选择Anchor Processor Defined Labels。这需要更少的处理器知识,更加简单和可控。
如果文件很大,但您只关注其中一小部分,推荐选择Anchor Processor Defined Labels,可以避免为整个文件添加大量无用注释。
如果您不确定正确的处理器类型,Anchor Processor Defined Labels也是一个更安全的选择,它只依赖您正确设置Anchor所在的地址。
两者也可以结合使用,针对不同的需求选择不同的功能。
==Create Export Symbol File==
该功能可以将反汇编代码中的函数和变量导出为符号文件。该符号文件包含了所有函数和变量的名称、地址以及相关信息。
导出符号文件有以下主要用途:
与其他工具共享符号信息。许多调试器、IDA等工具都支持导入符号文件,以显示函数和变量的名称,而不仅仅是地址。
方便其他人理解你的反汇编代码。通过导入符号文件,其他研究人员可以直接看到函数和变量的名称,更好理解代码逻辑。
方便自己重新审查文件。有的时候你可能需要在很长时间之后重新审查一个文件,导入符号文件可以立刻恢复对各个函数和变量名称的记忆,无需全部重新命名。
进行差分分析。如果有多个相似的文件,通过分别为每个文件创建符号文件,然后对比两个符号文件,可以快速找到两者之间的不同之处。
使用步骤如下:
反汇编并命名好您要导出的文件中的所有函数和变量。
点击File菜单,选择Create Export Symbol File。
设置符号文件相关选项,比如要包含的数据类型、函数和变量等。选中“Create mapping file”可以额外创建一个TMAP文件以映射符号地址。
点击OK,Ghidra会生成两个文件:yourfile.sym作为符号文件,yourfile.tmap作为地址映射文件。
这两个文件即包含了您反汇编文件中的所有符号信息,可以导入到其他工具或文件中使用。
导出符号信息是逆向工程中的一个重要步骤,可以saying方便各种后续工作的进行。Ghidra提供了简单方便的功能来导出并共享符号信息,这在团队合作等情况下尤为有用。
==Load External Libraries==
在Ghidra中,Load External Libraries功能可以导入外部库文件,以提供更丰富的反汇编信息。导入外部库的主要作用有:
提供库函数名和参数信息。有了库文件,Ghidra可以显示调用库函数的函数名和参数,而不仅仅是地址,这极大提高了可读性。
识别库调用。有了库信息,Ghidra可以正确识别文件中调用的库函数,而不会将其误认为数据或其他指令。
帮助数据类型推断。库文件包含了函数的参数和返回值类型信息,这可以帮助Ghidra推断数据类型,为变量和参数选择正确的类型。
理解文件依赖。通过查看文件调用了什么库函数,可以理解程序需要依赖什么库来编译和运行。
使用步骤如下:
获得要导入的外部库文件。格式可以是Ghidra支持的库文件格式,比如CodeView等。
点击File菜单,选择Load External Libraries。
点击“Add File”按钮,选择库文件并打开。可以添加多个库文件。
设置好库文件的相关选项,比如处理器类型等。然后点击“OK”按钮。
Ghidra会加载指定的库文件,并在Background Tasks窗口显示导入进度。
导入成功后,文件中调用库函数的地方将显示函数名和参数,相应数据类型也会被推断。
可以在Defined Functions和Defined Data Types窗口查看导入的库信息。加载外部库是一个提高Ghidra反汇编效果的重要手段。但是,它也依赖获得正确的库文件,并选择与目标文件匹配的处理器类型和设置。所以,用户仍需要具备一定的逆向知识,才能充分利用这个功能。
==Perform Symbol Relocations==
该功能可以重新定位反汇编代码中的符号(函数和变量)地址。
重新定位符号地址的主要作用有:
修复误识别的函数和变量。有时候Ghidra在自动分析文件时可能会误识别一些数据为函数或变量,这会导致它们的地址不正确。重新定位可以修复这些误识别的符号。
处理反汇编后地址变化的情况。比如,您修改了一些代码后重新编译,地址就可能会发生变化。这时需要重新定位符号以更新地址。
使符号地址与其他工具的结果匹配。有时候您可能会使用多个工具分析同一个文件,此时重新定位可以使Ghidra的符号地址与其他工具的结果一致。
重命名已有符号。重新定位时您可以选择为某个现有符号输入一个新的名称,这就实现了符号的重命名功能。
使用步骤如下:
定位您要重新定位的符号,右键选择Relocate Symbol。
在弹出窗口中,可以为该符号输入新的名称和地址。地址可以选择相对于image base或文件开始的绝对地址。
设置好相关选项后点击“OK”按钮,该符号的地址和名称将被更新。
继续以上的步骤重新定位其他符号。您也可以选择多个符号一起重新定位。
重新定位完成后,检查代码中相关调用和引用的地址都已正确更新。
重新定位功能给用户提供了更高的控制权,可以根据需要手动修改和修复符号信息。但同时也增加了用户工作量,需要手动逐个检查符号并更新信息。
所以,一个好的工作流程是:首先尽量利用Ghidra的自动分析功能生成符号信息;然后通过手动审查和对比其他工具的结果,检查自动分析的结果,并仅针对必要的符号进行手动重新定位,这可以最大限度利用Ghidra的功能,同时也保证符号信息的准确性。
==Import Non-Loaded Data==
该功能可以导入当前文件中未加载的数据段。
导入未加载数据段的主要作用有:
完整显示文件的所有数据段。有时候Ghidra在加载文件时可能无法自动解析某些数据段,无法将其加载入内存。导入可以手动加载这些未解析的数据段。
分析文件中其他工具无法加载的数据。某些保护机制可能会导致其他工具无法完整加载文件的数据,但Ghidra的导入功能可以绕过这些保护加载全部数据。
处理文件扩展或 Truncation 的情况。如果文件大小发生变化,那么默认加载的大小也会变化。导入功能可以加载新增的数据或忽略删除的数据。
自定义数据段加载方式。通过选择不同的加载选项,用户可以自定义数据段的加载方式,而不局限于Ghidra的默认自动解析。
使用步骤如下:
利用Ghidra的各种数据查看功能,查找文件中当前未加载的数据段。通常显示为红色或深灰色背景。
定位要导入的数据段,右键选择Import Non-Loaded Data。
在弹出窗口中,设置数据段的名称、大小、加载地址等选项。
选择数据段的加载方式,可以选择加载为byte数组、字符数组等不同格式。
设置好相关选项后点击“OK”按钮,该数据段将被加载入内存,并在Listing窗口中显示。
继续以上的步骤导入其他未加载数据段。
导入完成后,利用各种分析工具查看并理解已经导入的数据内容。
导入未加载数据功能使Ghidra的加载不再局限于它的自动解析,用户可以更加灵活地控制文件数据的加载方式。但是,它也增加了用户手动分析和选择数据格式的工作量。
所以,一个好的工作流程是:首先利用自动解析功能加载尽可能多的数据;然后通过手动分析 located 未加载的数据段,仅针对必要和无法自动解析的数据进行手动导入。这可以最大限度减少人工工作,同时也使最终的文件加载结果更加准确全面。
==Fixedup Unresolved External Symbols==
该功能可以修复文件中未解析的外部符号。
未解析的外部符号通常出现在以下情况:
文件调用了未加载的外部库函数。如果未导入相关外部库,调用该库的函数则无法解析。
文件引用了其他文件的函数或变量,但未加载该文件。跨文件调用导致的未解析符号。
编译器优化或保护机制导致某些符号在文件中未显式出现。这时Ghidra无法自动解析这些符号。
修复未解析符号的主要作用有:
恢复文件正常的调用关系和逻辑。有了符号,调用和引用关系才能被正确理解。
显示函数和变量的真实名称,提高代码可读性。
帮助数据类型推断。有了函数和变量的类型信息,可以为相关参数和变量推断正确类型。
理解文件编译环境和选项。某些优化方案和保护机制会产生未解析符号,分析这些符号可以帮助理解编译过程。
使用步骤如下:
定位文件中显示为红色的未解析外部符号,比如外部函数调用等。
右键选择该符号,选择Fixedup Unresolved External Symbols。
在弹出窗口中,为该符号输入正确的名称、地址和类型信息。
设置好相关选项后点击“OK”按钮,该符号将被解析,并在文件中正确显示名称和类型。
继续以上的步骤修复其他未解析符号。您也可以选择多个符号一起修复。
修复完成后,检查代码中相关调用和引用已全部解析正确。
修复未解析符号功能增加了用户手动解析和命名的工作量。但是,这也给用户更高的控制权,可以根据具体文件情况和经验为符号选择最合适的信息。
一个好的工作流程是:首先尽量通过加载外部库等方式自动解析尽可能多的符号;然后手动fix剩余未解析且关键的符号。这可以避免过多人工工作,同时也使最终结果达到满意的精度。
行数:248
字数:3992