说明
既要坚定锻炼成熟架构的道路,也要在合理的范围内重塑设计
计算时序数据的特征,少不了“Rolling”类的操作。过去,直接采用pandas进行rolling,效率很不错,但是在实战应用时不太行。
反思下来:离线的操作拓展困难,很多都是一次性的
后来开发了ADBS,通过Mongo和Redis,在数据的持久化和吞吐上是没问题的。但是,对于全量的历史回滚计算遇到了问题。
ADBS的架构将问题简化到了一个时隙,大大简化了逻辑,开发完成也即生产完成,这点很好;但是在大量的全量计算中,Mongo库还是碰到了“大频次”访问的问题。目前我关注的时隙大约是60万,也就是说各Worker会频繁的发出数据查询请求。最终优化下来,处理的时间大约要1.5天。实时计算方面倒没什么问题,(每分钟计算300时隙 – 这不就是 TPS = 5吗?)
之前纠结的点在于使用硬件去堆高能力,而不去做设计上优化。但今天转念一想,不能轴啊,毕竟可以用很小的代价来实现的。
内容
1 问题本质
可使用内存服务的点在于:
- 1 数据不算很大,60万行数据,甚至占不了几百兆(内存装得下)
- 2 查询的条件很简单,就是其实和终止时隙(不需要额外的算法开销)
- 3 数据重复被取的次数会非常多(1个时隙可能会重复取数千次)
- 4 应用面广(假设会经常的增改新的指标)
- 5 几乎没有修改成本(只要在worker的取数环节改为向这个服务取数即可),可能需要给worker一个参数让它切换
TPS = 5 ,那么一天计算约40万次计算;因为我把时隙定在分钟,所以应该是TPM=300。
从吞吐的指标上看,至少要能达到TPS = 100或者 TPM = 6000这个水平。这样处理速度快20倍,不到1个小时就能跑完全量。
2 方案
构造一个服务,服务的主要目的是将这种滚动式的数据查询从数据库中挪到内存中
服务的构造上,在这个场景用Tornado是最合适的,不过我不想花时间去搞;还是要用Flask搭建,未来有时间了,还是应该把Tornado的模板搞一搞,又轻又快。
服务能够提速的原因在于:
- 1 读写只在内存,比硬盘能快几十倍
- 2 不需要数据库执行通用的条件筛选(可能从百毫秒级别,降到毫秒或者微秒级)
顺带的能稍微节约一下硬盘的耐久度消耗(虽然有时候我也暗搓搓的希望硬盘用坏了可以买新的,哈哈)。
服务最大的开销可能就是将结果进行序列化,然后在网络(局网)中传输了。
其实如果是非滚动的计算,当前的架构是完全可以满足的,所以新的服务应该只是这个特殊场景的补充,用最小化的功能来进行设计。
- 之所以不使用redis,是因为还要进行筛选(不仅仅是kv),没那么方便
2.1 取数接口
按 random_seed ,从某个库拖取区间数据
接口的入参需要指定:
- 1 数据库服务名称:服务会自动进行合适的连接,然后将表中的所有数据下载
接口服务在拉取数据后存入服务的内存变量(字典):
- 1 键值即为数据库服务名称
- 2 返回数据的条数
- 3 返回数据对象(df)所占的内存空间
在不使用时,通过重启容器来释放内存
2.2 返数接口
和原来查表同样的入参
一般来说,通过一组变量作为联合主键来进行数据的筛选,然后通过时隙的比较来进行取数,之后将结果作为listofdict返回。
3 实施一
采用了Tornado做网络服务,的确是比Flask强很多。
单核情况下,T的处理大约是120ms~150ms, F的处理 一般在200ms。所以T的TPS是7,而F的TPS是5。
在概念上,我有两个认知盲点或者错误:
- 1 这个取数不是IO密集,是CPU密集操作
- 2 进程间数据不共享
取数的时候,如果直接从Mongo取,那么需要数据库进行查询,这个会耗用CPU;当采用内存处理时,从python的对象转为json传输,也要耗用CPU。可能后者的耗用还会大一些。
因为现在都是在使用MA进行数据操作,MA为了标准化操作,也会进行转换,所以我觉得效率都消耗在这上面。
速度的确提高了很多,本以为这就是这个故事的结果,没想到又反转了。
实施一的问题
tornado在多核运行时出现了内存暴增的问题。我估计在多核状态下,可能还会有很多进程会被随机创建,然后每个进程会去获取静态数据(是的,肯定不是十个核拿十次,而是有多少进程多少次)。所以多核的时候,内存方案会有问题。我想以前碰到的一些(其他人)的工程上内存爆掉的问题,可能有一部分是类似这样的。python因为天生是单进程的,所以不太会体会到。
我觉得,如果要多核操作,一定还是要面向数据库的,还是转向redis找解决方案
4 实施二
擦,突然发现其实我已经有了答案,灯下黑啊。
我现在往Redis的Stream不就是存取数据,然后分发执行吗?效率很高啊。只是有一个地方需要改变,就是消息的id用我的时隙号替代就可以了…
甚至再往前一步,所有的实时数据可以一直往这个队列加啊,之前都是什么鬼方案,哈哈。
在python里使用redis操作,原来我就是没有使用id这个关键字。
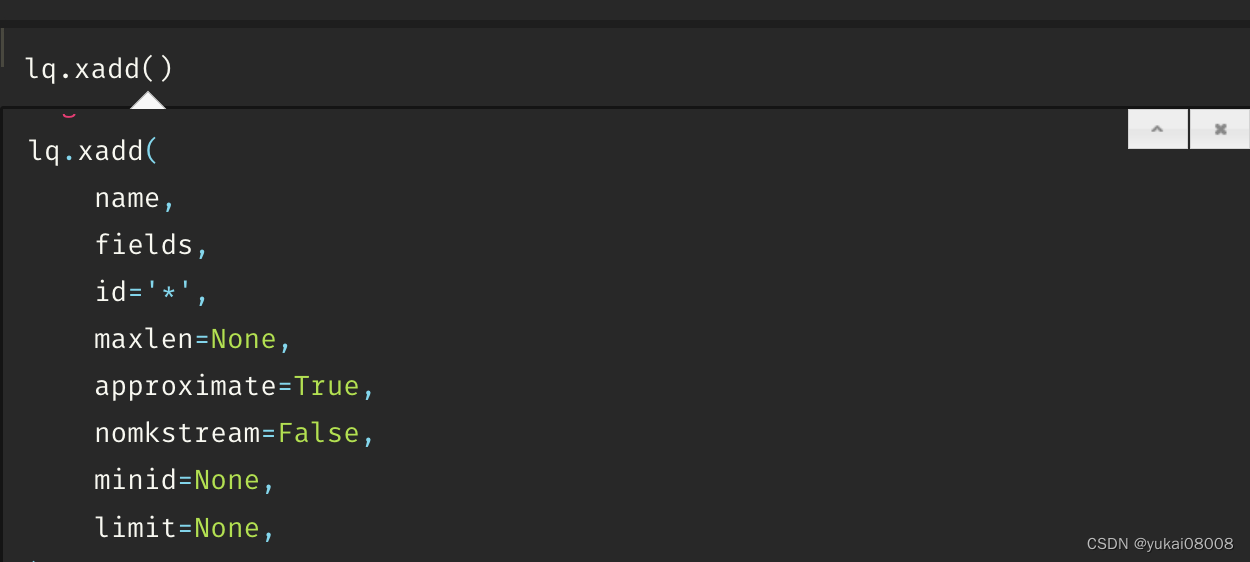
所以只要在现有的redis agent里加一个接口就行(10分钟都不用),完全不影响其他的操作。这样,就把这个问题重新简化为了IO问题。之前也看过,这60多万的内存占用应该也就200多M。
要点
- 1 在RedisAgent中添加一个接口,可以方便的生成一个队列(主要是为了方便)
- 2 在Worker中不通过Agent,直接访问Redis数据库
将mongo中的数据都搬到redis(60多万条数据,耗时7分钟左右)
100%|██████████| 115/115 [06:49<00:00, 3.57s/it]
from configs_base import redis_agent_host,project_name, worker01_config,cur_w
tier1 = 'MyQuantBaseStep1Signals'
tier2 = 'step1_mongo_in'
min_slot = cur_w.minmax(tier1 = tier1, tier2 = tier2, minmax='min', attrname='data_slot')['data']
max_slot = cur_w.minmax(tier1 = tier1, tier2 = tier2, minmax='max', attrname='data_slot')['data']
print(min_slot)
print(max_slot)
slot_tuple_list = slice_list_by_batch1(int(min_slot),int(max_slot)+1,50000)
redis_q_name = 'BUFF.%s.%s' %(tier1, tier2)
import tqdm
for tem_tuple in tqdm.tqdm(slot_tuple_list):
min_time_slot, max_time_slot = tem_tuple
recs = cur_w.query_recs(tier1 = tier1, tier2 = tier2,
filter_dict = {'$and':[{'market':market,
'code':code, 'data_slot':{'$gte':min_time_slot ,'$lt':max_time_slot}}]},
limits= (max_time_slot - min_time_slot) * 10,silent=True
)['data']
recs_df = pd.DataFrame(recs)
recs_df['_data_source_ranking'] = recs_df['data_source'].map(data_source_ranking).fillna(999)
recs_df1 = recs_df.sort_values(['_data_source_ranking']).drop_duplicates(['market','code','data_slot'])
tem_msg_id_list
keep_cols = [x for x in recs_df1.columns if not x.startswith('_')]
recs_df1 = recs_df1.sort_values(['data_slot'])
tem_msg_dict_list = recs_df1[keep_cols].to_dict(orient='records')
tem_msg_id_list = list(recs_df1['data_slot'].apply(int))
req.post(redis_agent_host + 'batch_add_msg_with_id/',
json={'stream_name':redis_q_name,
'msg_dict_list':tem_msg_dict_list,
'msg_id_list': tem_msg_id_list,
'maxlen':10000000}).json()
Worker从Redis取数
import redis
lq = redis.Redis()
def flat_kvlist2dict(some_list):
tem_dict = {}
for i in range(0,len(some_list),2):
k = some_list[i]
v = some_list[i+1]
tem_dict[k] = v
return tem_dict
%%timeit
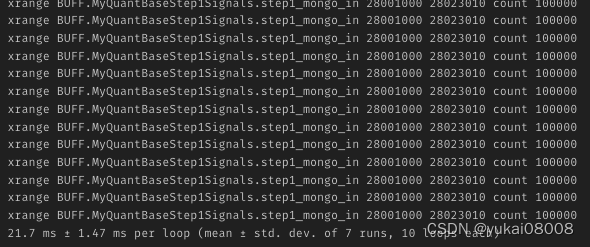
stream_name = redis_q_name
start_id = 28001000
end_id = 28023010
count = 100000
cmd = 'xrange %s %s %s count %s' %(stream_name,start_id,end_id,count)
print(cmd)
res = lq.execute_command(cmd)
res_df = pd.DataFrame(res)
msg_body_df = pd.DataFrame(res_df[1].apply(flat_kvlist2dict).tolist())
每次的取数大约20多毫秒(TPS ~ 50),看起来不再需要考虑序列化的问题(一来一去,每次全量减少120万次的json序列化工作)
再之后修改Worker的取数方式就好了。






![[JAVASE]初识Java:数据类型与变量](https://img-blog.csdnimg.cn/f2e7037addfd4e69ace7a02b30d06ba2.png)