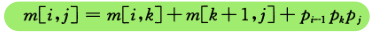该文章主要为完成实训任务,详细实现过程及结果见【http://t.csdn.cn/oT0of】
文章目录
- 一、准备工作
- 1.1 准备文件
- 1.1.1 准备本地系统文件
- 1.1.2 启动HDFS服务
- 1.1.3 上传文件到HDFS
- 1.2 启动Spark Shell
- 1.2.1 启动Spark服务
- 1.2.2 启动Spark Shell
- 二、创建RDD
- 2.1 通过并行集合创建RDD
- 2.1.1 利用`parallelize()`方法创建RDD
- 2.1.2 利用`makeRDD()`方法创建RDD
- 2.2 从外部存储创建RDD
- 2.2.1 从文件系统加载数据创建RDD
- 课堂练习:给输出数据添加行号
- 2.2.2 从HDFS中加载数据创建RDD
- 三、读取文件的问题
- 3.1 以集群方式启动Spark Shell
- 3.1.1 读取本地文件
- 3.1.2 读取HDFS文件
- 3.2 以本地模式启动Spark Shell
- 3.2.1 读取本地文件
- 3.2.2 访问HDFS文件
一、准备工作
1.1 准备文件
1.1.1 准备本地系统文件
-
在
/home目录里创建test.txt

-
单词用空格分隔

1.1.2 启动HDFS服务
- 执行命令:
start-dfs.sh

1.1.3 上传文件到HDFS
-
将
test.txt上传到HDFS的/park目录里

-
查看文件内容

1.2 启动Spark Shell
1.2.1 启动Spark服务
- 执行命令:
start-all.sh

1.2.2 启动Spark Shell
- 执行命令:
spark-shell(既可以读取本地文件,也可以读取HDFS文件)

- 查看Spark Shell的WebUI界面

- 查看执行器

二、创建RDD
2.1 通过并行集合创建RDD
- Spark可以通过并行集合创建RDD。即从一个已经存在的集合、数组上,通过SparkContext对象调用
parallelize()或makeRDD()方法创建RDD。
2.1.1 利用parallelize()方法创建RDD
- 执行命令:
val rdd = sc.parallelize(List(1, 2, 3, 4, 5, 6, 7, 8))

- 执行命令:
val rdd = sc.parallelize(Array(100, 300, 200, 600, 500, 900))

- 说明:不能基于Map、Tuple和Set来创建RDD
2.1.2 利用makeRDD()方法创建RDD
- 执行命令:
val rdd = sc.makeRDD(List(1, 2, 3, 4, 5, 6, 7, 8))

- 执行命令:
rdd.collect(),收集rdd数据进行显示

- 思考题:取出rdd中的偶数

2.2 从外部存储创建RDD
2.2.1 从文件系统加载数据创建RDD
- 执行命令:
val rdd = sc.textFile("file:///home/test.txt")

- 注意:访问本地文件,必须加
file://前缀,否则系统会认为是访问hdfs://master:9000/home/test.txt,从而会报错。 - 执行命令:
val lines = rdd.collec,查看RDD中的内容,保存到常量lines

- 执行命令:
lines.foreach(println)(利用foreach遍历算子)

课堂练习:给输出数据添加行号
- 利用for循环来实现

- 利用foreach遍历算子来实现

2.2.2 从HDFS中加载数据创建RDD
- 执行命令:
val rdd = sc.textFile("hdfs://master:9000/park/test.txt")

- 执行命令:
val lines = rdd.collect,查看RDD中的内容

- 获取包含spark的行,执行命令:
val sparkLines = rdd.filter(_.contains("spark"))

- 利用遍历算子显示
sparkLines内容

三、读取文件的问题
3.1 以集群方式启动Spark Shell
- 执行命令:
spark-shell --master spark://master:7077

3.1.1 读取本地文件
- 执行命令:
val rdd = sc.textFile("file:///home/test.txt")

- 执行命令:
rdd.collect,报错 -Input path does not exist: hdfs://master:9000/home/test.txt - 结论:集群模式启动的Spark Shell不能读取本地文件
3.1.2 读取HDFS文件
- 执行命令:
val rdd = sc.textFile("hdfs://master:9000/park/test.txt")

- 执行命令:
val rdd = sc.textFile("/park/test.txt")

- 结论:默认就是访问HDFS上的文件,因此
hdfs://master:9000前缀可以不写
3.2 以本地模式启动Spark Shell
- 执行命令:
spark-shell --master local[*]

3.2.1 读取本地文件
- 执行命令:
val rdd = sc.textFile("file:///home/test.txt")

- 执行命令:
val rdd = sc.textFile("/home/test.txt")

- 结论:本地模式启动的Spark Shell,默认读取的依然是HDFS文件,要访问本地文件,必须加
file://前缀
3.2.2 访问HDFS文件
- 执行命令:
val rdd = sc.textFile("hdfs://master:9000/park/test.txt")

- 执行命令:
val rdd = sc.textFile("/park/test.txt")

- 结论:默认就是访问HDFS文件,因此加不加
hdfs://master:9000前缀都是一样的效果文件。




![[JAVASE]初识Java:数据类型与变量](https://img-blog.csdnimg.cn/f2e7037addfd4e69ace7a02b30d06ba2.png)