Wide & Deep Learning for Recommender Systems
论文地址https://arxiv.org/pdf/1606.07792.pdf
摘要
广义线性模型结合非线性特征转换,在处理具有大规模稀疏输入的回归和分类问题中已被广泛应用。通过一系列交叉积特征转换来记忆特征交互既有效又具有解释性,然而要实现更好的泛化性能,需要投入更多的特征工程工作。相较于此,深度神经网络能够通过为稀疏特征学习低维度密集嵌入,以较少的特征工程来更好地泛化至未见过的特征组合。但是,在用户与项目互动稀疏且高秩的情况下,具有嵌入的深度神经网络可能过度泛化,导致推荐的项目相关性较低。
为了解决这一问题,本文提出了一种名为Wide & Deep学习的方法,它联合训练宽线性模型和深度神经网络,将记忆与泛化的优势结合到推荐系统中。我们将该方法应用于Google Play商店,这是一个拥有超过10亿活跃用户和100万应用的商业移动应用平台,并对其进行了评估。在线实验结果表明,与仅使用宽模型或深模型相比,Wide & Deep方法显著提高了应用的下载量。同时,我们还在TensorFlow框架中开源了我们的实现方法。
CCS概念: • 计算方法 → 机器学习;神经网络;监督学习; • 信息系统 → 推荐系统;
关键词: Wide & Deep学习,推荐系统。
引言
推荐系统可以看作是一种搜索排名系统,它接收一组包含用户和上下文信息的输入查询,然后输出一个按照相关性排序的项目列表。在给定查询的情况下,推荐任务的目标是在数据库中找到相关的项目,并依据一定的目标(例如点击率或购买率)对这些项目进行排序。
与普通搜索排名问题类似,推荐系统面临的一个挑战是实现记忆和泛化的平衡。记忆可以简要地定义为学习项目或特征之间频繁共现的模式,并从历史数据中挖掘潜在的相关性。相对而言,泛化是基于相关性的传递性,旨在探索过去从未出现或很少出现的新特征组合。基于记忆的推荐通常更贴近用户兴趣,并与用户过去互动过的项目具有更直接的相关性。而与记忆相比,泛化更能够提高推荐项目的多样性,从而增加用户发现新内容的可能性。
本文主要关注Google Play商店的应用推荐问题,但所提出的方法同样适用于其他通用的推荐系统。
在实际应用中的大规模在线推荐和排名系统,广义线性模型(如逻辑回归)因其简单性、可扩展性和可解释性而被广泛采用。这些模型通常采用独热编码处理稀疏特征。以二进制特征“user_installed_app=netflix”为例,当用户安装了Netflix时,其值为1。有效地记忆特征可以通过在稀疏特征上进行交叉乘积转换来实现,例如AND(user_installed_app=netflix, impression_app=pandora)”,在用户安装了Netflix且后来安装了Pandora的情况下,其值为1。这表明特征对的共现与目标标签之间存在关联。通过使用较为宽泛的特征,例如AND(user_installed_category=video, impression_category=music),可以实现泛化,尽管可能需要进行手动特征工程。交叉乘积转换的局限在于,它们无法泛化到训练数据中未出现过的查询-项目特征对。
基于嵌入的模型,如因子分解机或深度神经网络,通过为每个查询和项目特征学习低维密集嵌入向量,减少了特征工程的负担,从而使模型能够泛化到之前未见过的查询-项目特征对。然而,在查询-项目矩阵稀疏且高秩的情况下(例如具有特定喜好的用户或只吸引少数人的小众项目),学习有效的低维表示可能会变得困难。在这种情况下,大部分查询-项目对之间实际上不存在交互,但密集嵌入可能导致所有查询-项目对都产生非零预测,从而导致过度泛化和不够相关的推荐结果。相比之下,采用交叉乘积特征转换的线性模型可以用更少的参数捕捉到这些“特殊规则”,从而更好地处理这种情况。
编辑切换为居中
添加图片注释,不超过 140 字(可选)
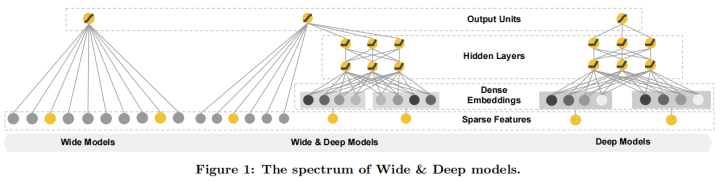
在本文中,我们提出了一种名为“Wide & Deep”学习框架,它能够在同一个模型中实现特征的记忆和泛化。该框架通过将线性模型组件与神经网络组件共同训练来实现这一目标,如图1所示。
本文的主要贡献如下: • 提出了Wide & Deep学习框架,该框架可以同时训练具有嵌入的前馈神经网络和带有特征转换的线性模型,适用于处理稀疏输入的通用推荐系统。 • 在Google Play上实现并评估了Wide & Deep推荐系统。Google Play是一个拥有超过10亿活跃用户和超过100万应用的移动应用商店。 • 我们已将实现及其高级API开源到TensorFlow1。
虽然这个想法看似简单,但我们证明了Wide & Deep框架在满足训练和服务速度度要求的同时,能够显著提高移动应用商店中应用的获取率。这表明该框架在实际应用中具有较高的价值。
编辑
添加图片注释,不超过 140 字(可选)
推荐系统简介
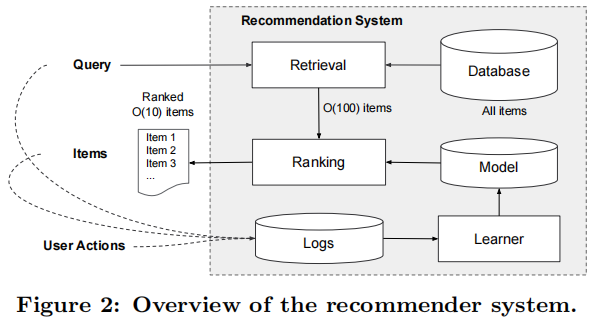
应用推荐系统的概述展示在图2中。当用户访问应用商店时,系统会根据各种用户和上下文特征生成一个查询请求。推荐系统会返回一个应用列表(亦称为展示项),在这些应用上,用户可以进行点击或购买等操作。这些用户操作,连同查询和展示项,都将记录在日志中,作为训练学习模型所需的数据。
鉴于数据库中拥有超过一百万款应用,要在满足服务延迟要求(通常为10毫秒级别)的前提下为每个查询逐一评分是不切实际的。因此,收到查询请求后的第一步便是检索。检索系统会利用各种信号(通常是机器学习模型与人工定义规则的结合)返回与查询最匹配的一小部分项目。在缩小候选项目范围后,排名系统会根据项目的得分对所有项目进行排序。得分通常基于P(y|x),即在给定特征x的条件下,用户操作标签y的概率。这些特征包括用户特征(如国家、语言、人口统计信息)、上下文特征(如设备、一天中使用的小时数、星期几使用)以及展示特征(如应用发布时长、应用的历史统计数据)。本文重点介绍了使用Wide & Deep学习框架的排名模型。
WIDE & DEEP
3.1 WIDE
WIDE是一种广义线性模型,其形式为 y = w^T x + b,如图1(左)所示。在这个模型中,y 代表预测值,x = [x1, x2, ..., xd] 是一个由 d 个特征组成的向量,w = [w1, w2, ..., wd] 是模型参数,b 是偏差项。特征集既包括原始输入特征,也包括经过变换的特征。其中一个最重要的变换就是交叉乘积变换,定义如下:
φk(x) = ∏ (i=1 to d) xi^cki, 其中 cki ∈ {0, 1}
在这个公式中,cki 是一个布尔变量。当第 i 个特征是第 k 个变换φk的一部分时,它的值为1;否则为0。对于二进制特征,交叉乘积变换(例如,“AND(gender=female, language=en)”)的值为1,当且仅当组成特征(如“gender=female”和“language=en”)都为1;否则为0。这样的交叉乘积变换捕捉了二进制特征之间的交互作用,并为广义线性模型引入了非线性。
通过引入交叉乘积变换,宽组件能够捕捉特征之间的复杂关系。这使得它在处理稀疏数据时具有较强的拟合能力,从而提高了推荐系统的表现。
3.2 DEEP
DEEP是一个前馈神经网络,如图1(右)所示。对于分类特征,原始输入是特征字符串(例如,“language=en”)。每一个这类稀疏的、高维的分类特征首先会被转换为低维且密集的实值向量,这通常被称为嵌入向量。嵌入向量的维度通常在 O(10) 到 O(100) 的数量级。嵌入向量最初是随机初始化的,然后在模型训练过程中调整其值以最小化最终损失函数。接下来,这些低维密集嵌入向量被输入到神经网络的隐藏层中。
具体而言,每个隐藏层执行以下计算:
A^(l+1) = f(W^(l) a^(l) + b^(l))
这里,l 表示层数,f 是激活函数,通常是(ReLU)。a^(l)、b^(l) 和 W^(l) 分别是第 l 层的激活值、偏差和模型权重。
通过这种方式,深度组件能够捕捉特征之间复杂的非线性关系。与宽度组件相结合,宽度和深度学习框架可以同时利用特征之间的线性关系(通过宽度组件)和非线性关系(通过深度组件)来提高模型的预测准确性。

编辑切换为居中
添加图片注释,不超过 140 字(可选)
在本文中,我们提出了一种宽度和深度学习框架,通过联合训练线性模型组件和神经网络组件,实现了在一个模型中同时具备记忆和泛化能力。与集成方法不同,联合训练在训练阶段同时考虑了宽度和深度部分以及它们之和的权重,从而优化了所有参数。在宽度和深度学习框架中,线性模型的宽度部分只需通过少量交叉乘积特征转换来弥补深度部分的不足,而不需要一个完整规模的宽度模型。
模型预测公式为:P(Y = 1|x) = σ(w_wide^T [x, φ(x)] + w_deep^T a^(lf) + b),其中Y是二元类标签,σ(·)是sigmoid函数,φ(x)表示原始特征x的交叉乘积变换,b是偏置项。w_wide是所有宽度模型权重的向量,w_deep是应用于最终激活a^(lf)的权重。
该框架将线性模型的宽度部分与神经网络的深度部分同时训练,使用小批量随机优化方法将梯度从输出反向传播到模型的宽度和深度部分。在实验中,我们使用带有L1正则化的FTRL算法作为宽度部分的优化器,使用AdaGrad作为深度部分的优化器。
简而言之,我们提出了一种宽度和深度学习框架,旨在实现一个模型中的记忆和泛化能力,通过联合训练线性模型组件和神经网络组件。这种方法在训练阶段同时考虑了模型各个部分,从而优化了所有参数。
应用推荐系统的实现包括三个阶段:数据生成、模型训练和模型服务,如图3所示。
4.1 数据生成在这个阶段,利用一段时间内的用户和应用展示数据来生成训练数据。每个样本对应一个应用展示。标签表示应用安装:如果展示的应用被安装,则为1,否则为0。
此阶段还会生成词汇表,这是一个将分类特征字符串映射到整数ID的表。系统会计算出现次数超过最小阈值的所有字符串特征的ID空间。对于连续的实数特征,通过将特征值x映射到其累积分布函数P(X≤x)并将其划分为nq个分位数来将其归一化到[0,1]范围内。对于处于第i个分位数的值,归一化值为(i-1/nq - 1)。在数据生成过程中计算分位数边界。
编辑切换为居中
添加图片注释,不超过 140 字(可选)
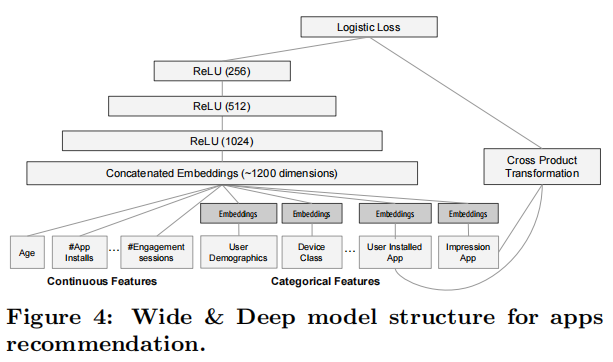
4.2 模型训练我们在实验中使用的模型结构如图4所示。训练过程中,输入层接收训练数据和词汇表,并一起生成稀疏和密集特征以及一个标签。宽模型部分包含了用户已安装应用与展示应用之间的交叉积变换。对于模型的深度部分,我们为每个分类特征学习一个32维的嵌入向量。我们将所有嵌入与密集特征连接在一起,形成一个大约1200维的密集向量。接着,将连接后的向量输入到3个ReLU层中,最后是逻辑输出单元。
Wide & Deep模型在超过5000亿个样本上进行了训练。每次收到新的训练数据时,都需要重新训练模型。然而,每次从头开始训练都会增加计算成本,延迟从数据到达到提供更新模型的时间。为了应对这个挑战,我们实现了一个热启动系统,该系统使用前一个模型的嵌入和线性模型权重初始化新模型。在将模型加载到模型服务器之前,进行一次干运行,以确保它不会在处理实时流量时出现问题。我们通过经验性地验证模型质量,将其与之前的模型进行对比,作为一个有效性检查。
“干运行”一般指在实际生产环境中,对某个系统或设备进行测试和验证,以确保其在正式使用前可以正常工作。这种测试可能涉及一系列的操作和流程,旨在模拟实际使用情况,以便在出现任何问题之前,能够及早发现和解决潜在的错误或缺陷。这种测试通常是在实际生产环境中进行,因为只有在实际使用情况下才能真正测试系统或设备的性能、可靠性和稳定性。
4.3 模型部署与服务当模型经过训练和验证后,我们将其加载到模型服务器中。对于每一个请求,服务器从应用检索系统中获取一组应用候选项,并利用用户特征对每个应用进行评分。接下来,根据评分将应用从高到低排序,按照这个顺序向用户展示。评分是通过在宽度和深度模型上执行一次前向推理计算得到的。
为了保证每个请求的响应时间在10毫秒以内,我们采用了多线程并行优化技术。通过并行执行较小批次,而非在单次大批量推理中为所有候选应用评分,从而提高了系统性能。
编辑切换为居中
添加图片注释,不超过 140 字(可选)
编辑切换为居中
添加图片注释,不超过 140 字(可选)
实验结果为了评估 Wide & Deep 学习在实际推荐系统中的有效性,我们进行了在线实验,并从两个方面对系统进行了评估:应用获取和服务性能。
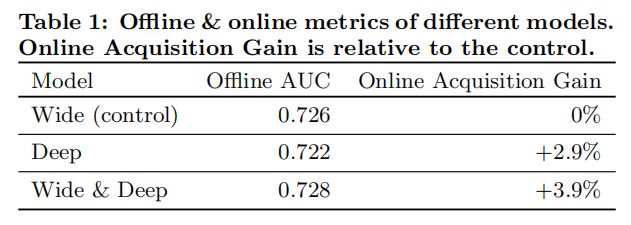
5.1 应用获取我们在 A/B 测试框架下进行了为期三周的在线实验。对于对照组,我们随机选择了1%的用户,向他们展示了由之前的排名模型生成的推荐。这个模型是一个高度优化的、仅基于宽度的逻辑回归模型,包含丰富的交叉特征转换。而对于实验组,我们向1%的用户展示了由 Wide & Deep 模型生成的推荐,该模型使用相同的特征集进行训练。如表1所示,与对照组相比,Wide & Deep 模型使应用商店首页的应用获取率相对提高了3.9%(具有统计显著性)。同时,我们还将结果与另一个仅使用相同特征和神经网络结构的深度模型的1%的用户组进行了比较,发现 Wide & Deep 模型相较于仅深度模型有1%的额外增益(具有统计显著性)。
除了在线实验,我们还在离线保留集上展示了接收者操作特征曲线下的面积(AUC)。尽管 Wide & Deep 在离线 AUC 方面略有提高,但其对在线流量的影响更为显著。这可能是因为离线数据集中的展示次数和标签是固定的,而在线系统可以通过将泛化与记忆相结合,生成新的探索性推荐,并从新的用户反馈中学习。
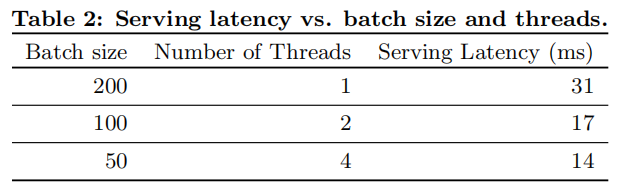
5.2 服务性能面对商业移动应用商店的高流量,实现高吞吐量和低延迟服务具有挑战性。在流量高峰期,我们的推荐服务器每秒需要为超过1000万个应用评分。使用单线程,在单个批次中为所有候选应用评分需要31毫秒。为了解决这个问题,我们采用了多线程并将每个批次拆分成较小的部分,显著降低了客户端延迟至14毫秒(包括服务开销),如表2所示。
相关研究将宽线性模型与交叉特征转换和深度神经网络与密集嵌入相结合的概念,受到了诸如因子分解机[5]等先前研究的启发。因子分解机通过将两个变量间的交互作用表现为两个低维嵌入向量间的点积,从而为线性模型增加泛化能力。在本文中,我们通过神经网络学习嵌入之间的高度非线性交互作用(而非点积),从而提高了模型的表达能力。
在语言模型方面,已提出联合训练递归神经网络(RNN)和具有n-gram特征的最大熵模型。通过学习输入和输出之间的直接权重,显著降低了RNN的复杂性[4]。在计算机视觉领域,通过使用快捷连接跳过一层或多层,深度残差学习[2]降低了训练更深模型的难度,并提高了准确性。神经网络与图模型的联合训练也被应用于从图像中估计人体姿态[6]。在本研究中,我们探索了前馈神经网络与线性模型的联合训练,以及稀疏特征与输出单元之间的直接连接,解决具有稀疏输入数据的通用推荐和排名问题。
在推荐系统文献中,已经探索了协同深度学习,它将深度学习用于内容信息处理,而协同过滤(CF)用于评分矩阵[7]。此外,还有一些关于移动应用推荐系统的研究,例如 AppJoy,它在用户的应用使用记录上使用 CF[8]。与之前基于 CF 或内容的方法不同,我们在应用推荐系统的用户和展示数据上联合训练 Wide & Deep 模型。
结论
对于推荐系统而言,记忆和泛化同等重要。宽线性模型通过交叉特征转换可以有效地记忆稀疏特征之间的交互,而深度神经网络则能通过低维嵌入实现对以往未见过的特征交互的泛化。我们提出了将这两种模型优势结合起来的 Wide & Deep 学习框架。我们将此框架应用于 Google Play 的推荐系统,并对这一大规模商业应用商店进行了实际评估。在线实验结果表明,与仅使用宽线性模型或深度神经网络的模型相比,Wide & Deep 模型在提高应用获取方面具有显著优势。
参考文献
-
J. Duchi, E. Hazan, 和 Y. Singer. 用于在线学习和随机优化的自适应梯度下降方法。机器学习研究杂志,12:2121–2159,2011年7月。
-
K. He, X. Zhang, S. Ren, 和 J. Sun. 深度残差学习用于图像识别。IEEE 计算机视觉和模式识别会议论文集,2016。
-
H. B. McMahan. 跟随正则化领导者和镜像下降:等价定理和 L1 正则化。在 AISTATS 论文集,2011。
-
T. Mikolov, A. Deoras, D. Povey, L. Burget, 和 J. H. Cernocky. 大规模神经网络语言模型的训练策略。在 IEEE 自动语音识别与理解研讨会,2011。
-
S. Rendle. 带有 libFM 的因子分解机。ACM 智能系统技术交易,3(3):57:1–57:22,2012年5月。
-
J. J. Tompson, A. Jain, Y. LeCun, 和 C. Bregler. 卷积网络和图形模型的联合训练用于人体姿态估计。在 Z. Ghahramani, M. Welling, C. Cortes, N. D. Lawrence 和 K. Q. Weinberger 编辑,NIPS,页面 1799–1807。2014。
-
H. Wang, N. Wang, 和 D.-Y. Yeung. 用于推荐系统的协同深度学习。在 KDD 论文集,页面 1235–1244,2015。
8. B. Yan 和 G. Chen. AppJoy:个性化的移动应用发现。在 MobiSys,页面 113–126,2011。
REFERENCES
[1] J. Duchi, E. Hazan, and Y. Singer. Adaptive
subgradient methods for online learning and stochastic
optimization. Journal of Machine Learning Research,
12:2121–2159, July 2011.
[2] K. He, X. Zhang, S. Ren, and J. Sun. Deep residual
learning for image recognition. Proc. IEEE Conference
on Computer Vision and Pattern Recognition, 2016.
[3] H. B. McMahan. Follow-the-regularized-leader and
mirror descent: Equivalence theorems and l1
regularization. In Proc. AISTATS, 2011.
[4] T. Mikolov, A. Deoras, D. Povey, L. Burget, and J. H.
Cernocky. Strategies for training large scale neural
network language models. In IEEE Automatic Speech
Recognition & Understanding Workshop, 2011.
[5] S. Rendle. Factorization machines with libFM. ACM
Trans. Intell. Syst. Technol., 3(3):57:1–57:22, May 2012.
[6] J. J. Tompson, A. Jain, Y. LeCun, and C. Bregler. Joint
training of a convolutional network and a graphical
model for human pose estimation. In Z. Ghahramani,
M. Welling, C. Cortes, N. D. Lawrence, and K. Q.
Weinberger, editors, NIPS, pages 1799–1807. 2014.
[7] H. Wang, N. Wang, and D.-Y. Yeung. Collaborative
deep learning for recommender systems. In Proc. KDD,
pages 1235–1244, 2015.
[8] B. Yan and G. Chen. AppJoy: Personalized mobile
application discovery. In MobiSys, pages 113–126, 2011.