基于神经网络的通用股票预测模
下载地址:基于LSTM神经网络的通用股票预测源代码+模型+数据集
0 使用方法 How to use
-
- 使用getdata.py下载数据,或者使用自己的数据源,将数据放在stock_daily目录下
-
- 使用data_preprocess.py预处理数据,生成pkl文件,放在pkl_handle目录下(可选)
-
- 调整train.py和init.py中的参数,先使用predict…py训练模型,生成模型文件,再使用predict.py进行预测,生成预测结果或测试比照图
0.1 predict.py参数介绍 Introduction to predict.py parameters
-
- –model: 模型名称,目前支持lstm和transformer
-
- –mode: 模式,目前支持train,test和predict
-
- –pkl: 是否使用pkl文件,目前支持1和0
-
- –pkl_queue: 是否使用pkl队列模式,以增加训练速度,目前支持1和0
-
- –test_code: 测试代码,目前支持股票代码
-
- –test_gpu: 是否使用gpu测试,目前支持1和0
-
- –predict_days: 预测天数,目前支持数字
0.2 init.py部分参数介绍 Introduction to some parameters in init.py
-
- TRAIN_WEIGHT: 训练权重,目前支持小于等于1的数字
-
- SEQ_LEN: 序列长度,目前支持数字
-
- BATCH_SIZE: 批量大小,目前支持数字
-
- EPOCH: 训练轮数,目前支持数字
-
- LEARNING_RATE: 学习率,目前支持小于等于1的数字
-
- WEIGHT_DECAY: 权重衰减,目前支持小于等于1的数字
-
- SAVE_NUM_ITER: 保存模型间隔,目前支持数字
-
- SAVE_NUM_EPOCH: 保存模型间隔,目前支持数字
-
- SAVE_INTERVAL: 保存模型时间间隔(秒),目前支持数字
-
- OUTPUT_DIMENSION: 输出维度,目前支持数字
-
- INPUT_DIMENSION: 输入维度,目前支持数字
-
- NUM_WORKERS: 线程数,目前支持数字
-
- PKL: 是否使用pkl文件,目前支持True和False
-
- BUFFER_SIZE: 缓冲区大小,目前支持数字
-
- symbol: 股票代码,目前支持股票代码或Generic.Data表示全部已下载的数据
-
- name_list: 需要预测的内容名称
-
- use_list: 需要预测的内容开关,1表示使用,0表示不使用
1 项目介绍 Project Introduction
New
-
20230402
-
- 修改dataset读取方式,使用data queue以及buffer,减少IO次数,提高训练速度
-
- 将全局变量移动到init.py中,方便修改
-
20230328
-
- 修改预处理数据文件格式,增加ts_code和date两个字段,方便后续使用
-
- 修改lstm和transformer模型,以支持混合长度输入
-
- 在transformer模型,增加了 decoder层,期望增加预测精度
-
20230327
-
- 修改了部分运行逻辑,配合load pkl预处理文件,极大的提高了训练速度
-
- 修正了一个影响极大的关于数据流方向的bug
-
- 尝试使用新的模型
-
- 增加了一个新的指标,用于评估模型的好坏
-
20230325
-
- 增加数据预处理功能,并能将预处理好的queue保存为pkl文件,减少IO损耗
-
- 修改不必要的代码
-
- 简化逻辑,减少时间负责度,方向是以空间换时间
-
- 增加常见的指标,增加预测精度
-
20230322
-
- 增加输出内容控制,可以自行定义输出的内容和数量
-
- 修改读取数据源为本地csv文件
-
- 修改IO逻辑,使用多线程读取指定文件夹下的csv文件,并存储到内存中,反复训练,减少IO次数
-
- 修改lstm, transformer模型
-
- 增加下载数据功能,请使用自己的api token
获取下载数据的api token: Get the api token to download data:
-
- 在https://tushare.pro/ 网站注册,并按要求获取足够的积分(到2023年3月为止,只需要修改下用户信息,就足够积分了,以后不能确定)
-
- 在https://tushare.pro/user/token 页面可以查看自己的api token
-
- 在本项目根目录建立一个api.txt,并将获得的api token写入这个文件
-
- 使用本项目getdata.py,即可自动下载日数据
股票行情是引导交易市场变化的一大重要因素,若能够掌握股票行情的走势,则对于个人和企业的投资都有巨大的帮助。然而,股票走势会受到多方因素的影响,因此难以从影响因素入手定量地进行衡量。但如今,借助于机器学习,可以通过搭建网络,学习一定规模的股票数据,通过网络训练,获取一个能够较为准确地预测股票行情的模型,很大程度地帮助我们掌握股票的走势。本项目便搭建了**LSTM(长短期记忆网络)**成功地预测了股票的走势。
首先在数据集方面,我们选择上证000001号,中国平安股票(编号SZ_000001)数据集采用2016.01.01-2019.12.31股票数据,数据内容包括当天日期,开盘价,收盘价,最高价,最低价,交易量,换手率。数据集按照0.1比例分割产生测试集。训练过程以第T-99到T天数据作为训练输入,预测第T+1天该股票开盘价。(此处特别感谢Tushare提供的股票日数据集,欢迎大家多多支持)
在训练模型及结果方面,我们首先采用了LSTM(长短期记忆网络),它相比传统的神经网络能够保持上下文信息,更有利于股票预测模型基于原先的行情,预测未来的行情。LSTM网络帮助我们得到了很好的拟合结果,loss很快趋于0。之后,我们又采用比LSTM模型更新提出的Transformer Encoder部分进行测试。但发现,结果并没有LSTM优越,曲线拟合的误差较大,并且loss的下降较慢。因此本项目,重点介绍LSTM模型预测股票行情的实现思路。
2 LSTM模型原理 Principles of LSTM model
2.1 时间序列模型 Time Series Model
时间序列模型:时间序列预测分析就是利用过去一段时间内某事件时间的特征来预测未来一段时间内该事件的特征。这是一类相对比较复杂的预测建模问题,和回归分析模型的预测不同,时间序列模型是依赖于事件发生的先后顺序的,同样大小的值改变顺序后输入模型产生的结果是不同的。
2.1 从RNN到LSTM From RNN to LSTM
RNN:递归神经网络RNN每一次隐含层的计算结果都与当前输入以及上一次的隐含层结果相关。通过这种方法,RNN的计算结果便具备了记忆之前几次结果的特点。其中,x为输入层,o为输出层,s为隐含层,而t指第几次的计算,V,W,U为权重,第t次隐含层状态如下公式所示:
S
t
=
f
(
U
∗
X
t
+
W
∗
S
t
−
1
)
(1)
St = f(U*Xt + W*St-1) (1)
St=f(U∗Xt+W∗St−1) (1)

可见,通过RNN模型想要当前隐含层状态与前n次相关,需要增大计算量,复杂度呈指数级增长。然而采用LSTM网络可解决这一问题。
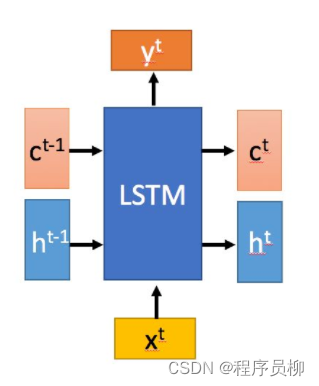
LSTM(长短期记忆网络)LSTM (Long Short-Term Memory Network):
LSTM是一种特殊的RNN,它主要是Eileen解决长序列训练过程中的梯度消失和梯度爆炸问题。相比RNN,LSTM更能够在长的序列中又更好的表现。
-
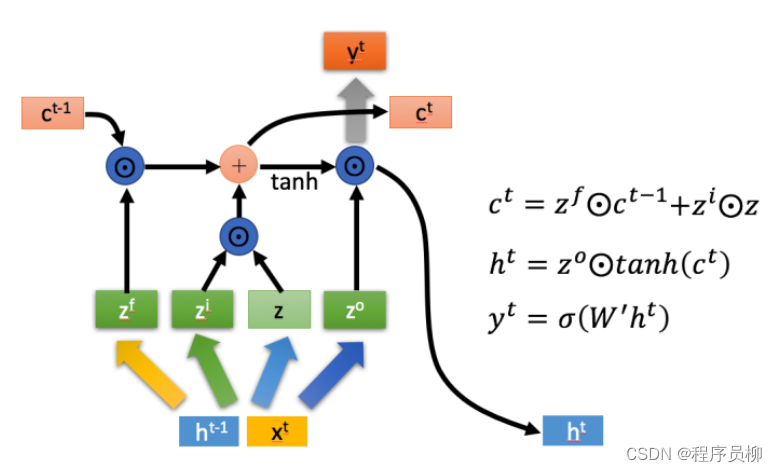
LSTM内部有三个阶段:忘记阶段、选择记忆阶段、输出阶段 LSTM has three stages: the forget stage, the select memory stage, and the output stage.
-
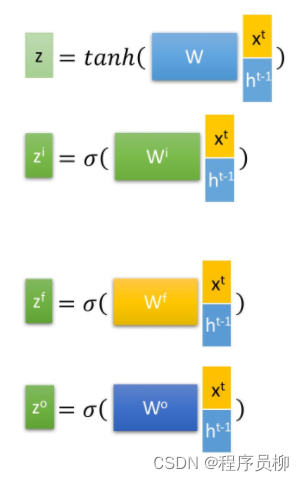
**忘记阶段:**通过计算来作为门控,控制上一个状态的 需要遗忘的内容。
-
**选择记忆阶段:**对输入进行选择记忆,门控信号由进行控制,输入内容由[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传进行表示。
-
**输出阶段:**决定当前状态输出的内容,通过 控制,并且还对上一阶段得到的进行放缩。
-
3LSTM预测股票模型实现 LSTM prediction model implementation for stock forecasting
1、数据集准备
1. Data set preparation
-
数据集分割:数据集按照0.1比例分割产生测试集。训练过程以第T-99到T天数据作为训练输入,预测第T+1天该股票开盘价。
-
对数据进行标准化:训练集与测试集都需要按列除以极差。在训练完成后需要进行逆处理来获得结果。
t r a i n ( [ : , i ] ) = ( t r a i n ( [ : , i ] ) ) − m i n ( t r a i n [ : , i ] ) / ( m a x ( t r a i n [ : , i ] ) − m i n ( t r a i n [ : , i ] ) ) ( 2 ) train([:,i])=(train([:,i]))-min(train[:,i])/(max(train[:,i])-min(train[:,i])) (2) train([:,i])=(train([:,i]))−min(train[:,i])/(max(train[:,i])−min(train[:,i]))(2)
t e s t ( [ : , i ] ) = ( t e s t ( [ : , i ] ) ) − m i n ( t r a i n [ : , i ] ) / ( m a x ( t r a i n [ : , i ] ) − m i n ( t r a i n [ : , i ] ) ) ( 3 ) test([:,i])=(test([:,i]))-min(train[:,i])/(max(train[:,i])-min(train[:,i])) (3) test([:,i])=(test([:,i]))−min(train[:,i])/(max(train[:,i])−min(train[:,i]))(3)
2、模型搭建
2. Model construction
使用pytorch框架搭建LSTM模型,torch.nn.LSTM()当中包含的参数设置:
-
输入特征的维数: input_size=dimension(dimension=8)
-
LSTM中隐层的维度: hidden_size=128
-
循环神经网络的层数:num_layers=3
-
batch_first: TRUE
-
偏置:bias默认使用
全连接层参数设置:
-
第一层:in_features=128, out_featrues=16
-
第二层:in_features=16, out_features=1 (映射到一个值)
3、模型训练
3. Model training
-
经过调试,确定学习率lr=0.00001
-
优化函数:批量梯度下降(SGD)
-
批大小batch_size=4
-
训练代数epoch=100
-
损失函数:MSELoss均方损失函数,最终训练模型得到MSELoss下降为0.8左右。
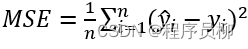
4、模型预测
4. Model prediction
测试集使用已训练的模型进行验证,与真实数据不叫得到平均绝对百分比误差(MAPELoss)为0.04,可以得到测试集的准确率为96%。
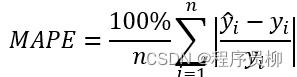
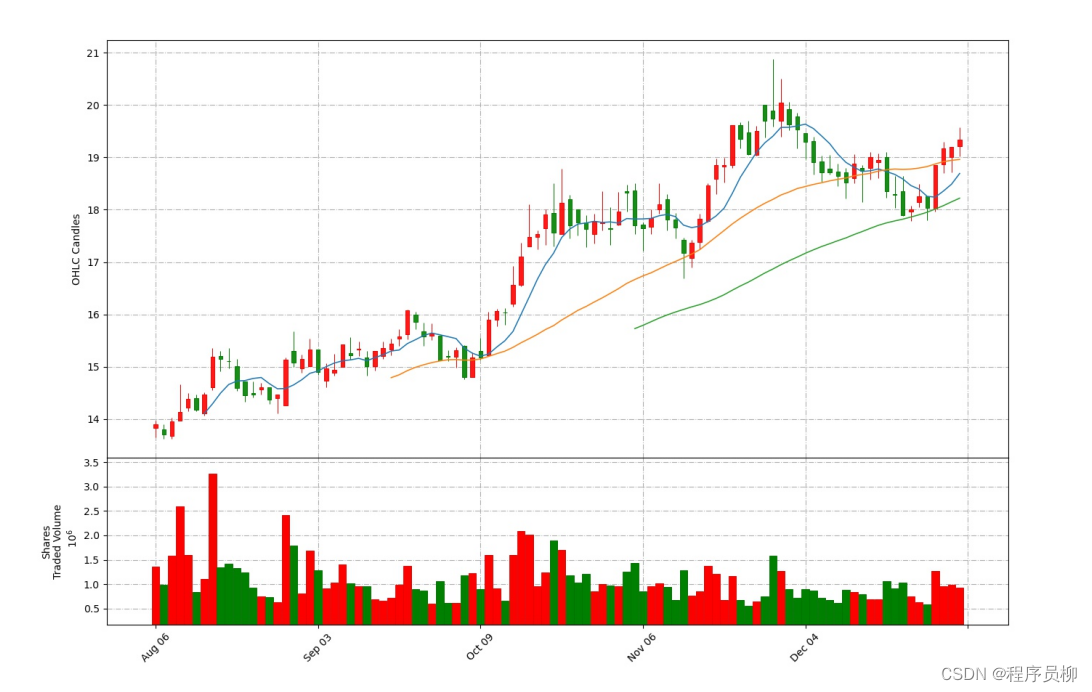
5、模型成果
5. Model results
下图是对整体数据集最后一百天的K线展示:当日开盘价低于收盘价则为红色,当日开盘价高于收盘价为绿色。图中还现实了当日交易量以及均线等信息。
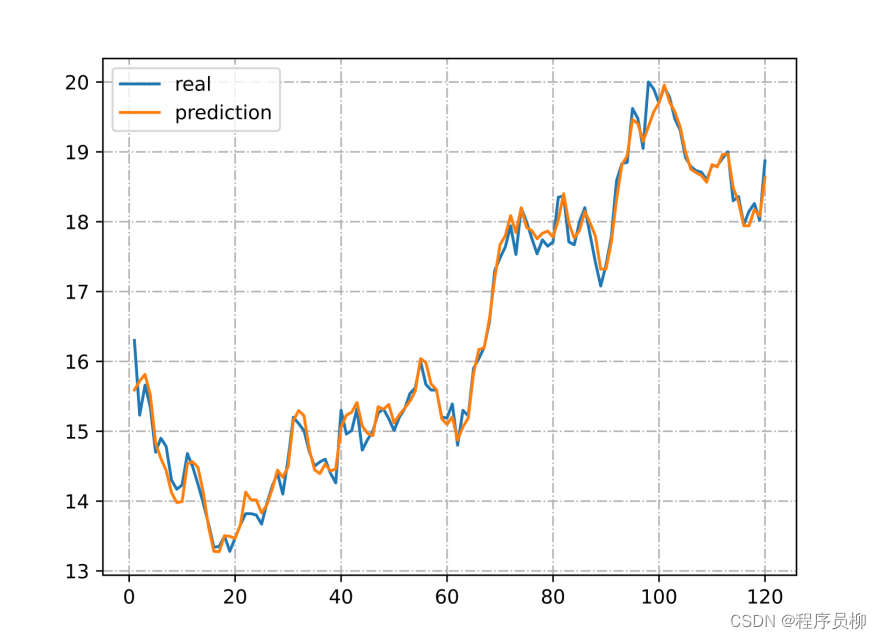
LSTM模型进行预测的测试集结果与真实结果对比图,可见LSTM模型预测的结果和现实股票的走势十分接近,因此具有很大的参考价值。
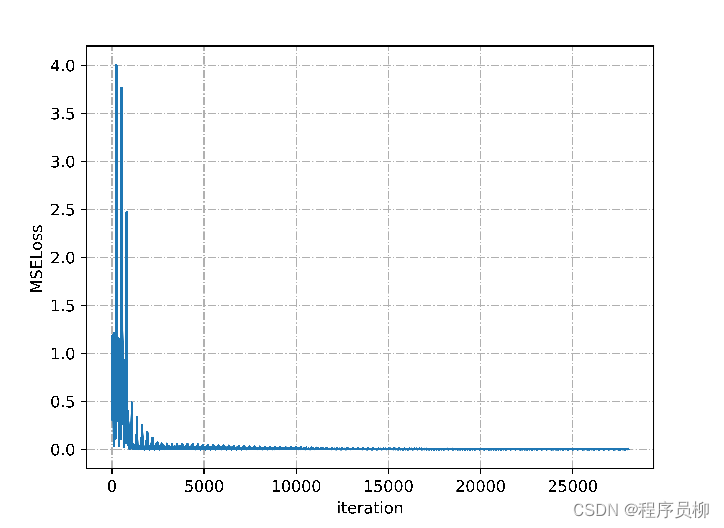
LSTM模型训练过程中MSELoss的变化,可以看到随着训练代数的增加,此模型的MSELoss逐渐趋于0。
4结语
4 Conclusion
本项目使用机器学习方法解决了股票市场预测的问题。项目采用开源股票数据中心的上证000001号,中国平安股票(编号SZ_000001),使用更加适合进行长时间序列预测的LSTM(长短期记忆神经网络)进行训练,通过对训练集序列的训练,在测试集上预测开盘价,最终得到准确率为96%的LSTM股票预测模型,较为精准地实现解决了股票市场预测的问题。
在项目开展过程当中,也采用过比LSTM更加新提出的Transformer模型,但对测试集的预测效果并不好,后期分析认为可能是由于在一般Transformer模型中由encoder和对应的decoder层,但在本项目的模型中使用了全连接层代替decoder,所以导致效果不佳。在后序的研究中,可以进一步改进,或许可以得到比LSTM更加优化的结果。
下载地址:基于LSTM神经网络的通用股票预测源代码+模型+数据集