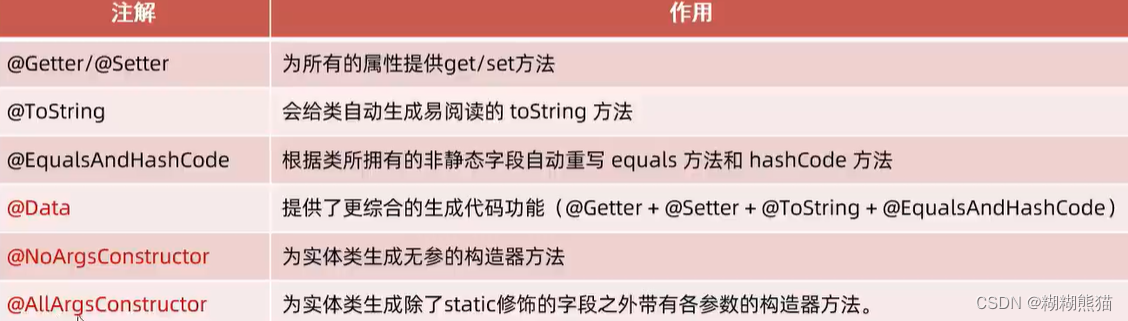
目录结构
注:提前言明 本文借鉴了以下博主、书籍或网站的内容,其列表如下:
1、参考书籍:《Oracle Database SQL Language Reference》
2、参考书籍:《PostgreSQL中文手册》
3、EDB Postgres Advanced Server User Guides,点击前往
4、PostgreSQL数据库仓库链接,点击前往
5、PostgreSQL中文社区,点击前往
6、Oracle Real Application Testing 官网首页,点击前往
7、Oracle 21C RAT Testing Guide,点击前往
1、本文内容全部来源于开源社区 GitHub和以上博主的贡献,本文也免费开源(可能会存在问题,评论区等待大佬们的指正)
2、本文目的:开源共享 抛砖引玉 一起学习
3、本文不提供任何资源 不存在任何交易 与任何组织和机构无关
4、大家可以根据需要自行 复制粘贴以及作为其他个人用途,但是不允许转载 不允许商用 (写作不易,还请见谅 💖)
Oracle数据库Real Application Testing之DBMS_SQLTUNE包技术详解
- 文章快速说明索引
- DBMS_SQLTUNE 概述
- SQL Tuning Advisor(SQL 调优顾问)
- SQL Profile Subprograms(SQL 配置文件子程序)
- SQL Tuning Sets(SQL 调优集)
- Import and Export of SQL Tuning Sets and SQL Profiles(SQL 调优集和 SQL 配置文件的导入和导出)
- Automatic Tuning Task Functions(自动调优任务函数)
- Real-Time SQL Monitoring(实时 SQL 监控)
- Tuning a Standby Database Workload(调优备用数据库工作负载)
- DBMS_SQLTUNE 安全模型
- DBMS_SQLTUNE 数据结构
- DBMS_SQLTUNE 子程序组
- DBMS_SQLTUNE SQL 调优顾问子程序
- DBMS_SQLTUNE SQL 配置文件子程序
- DBMS_SQLTUNE SQL 调优集子程序
- DBMS_SQLTUNE 实时SQL监控子程序
- DBMS_SQLTUNE SQL 性能报告子程序
- DBMS_SQLTUNE 子程序总结
- ACCEPT_ALL_SQL_PROFILES Procedure
- ACCEPT_SQL_PROFILE Procedure and Function
- ADD_SQLSET_REFERENCE Function
- ALTER_SQL_PROFILE Procedure
- CANCEL_TUNING_TASK Procedure
- CAPTURE_CURSOR_CACHE_SQLSET Procedure
- CREATE_SQL_PLAN_BASELINE Procedure
- CREATE_SQLSET Procedure and Function
- CREATE_STGTAB_SQLPROF Procedure
- CREATE_STGTAB_SQLSET Procedure
- CREATE_TUNING_TASK Functions
- DELETE_SQLSET Procedure
- DROP_SQL_PROFILE Procedure
- DROP_SQLSET Procedure
- DROP_TUNING_TASK Procedure
- EXECUTE_TUNING_TASK Function and Procedure
- IMPLEMENT_TUNING_TASK Procedure
- INTERRUPT_TUNING_TASK Procedure
- LOAD_SQLSET Procedure
- PACK_STGTAB_SQLPROF Procedure
- PACK_STGTAB_SQLSET Procedure
- REMAP_STGTAB_SQLPROF Procedure
- REMAP_STGTAB_SQLSET Procedure
- REMOVE_SQLSET_REFERENCE Procedure
- REPORT_AUTO_TUNING_TASK Function
- REPORT_SQL_DETAIL Function
- REPORT_SQL_MONITOR Function
- REPORT_SQL_MONITOR_LIST Function
- REPORT_TUNING_TASK Function
- REPORT_TUNING_TASK_XML Function
- RESET_TUNING_TASK Procedure
- RESUME_TUNING_TASK Procedure
- SCHEDULE_TUNING_TASK Function
- SCRIPT_TUNING_TASK Function
- SELECT_CURSOR_CACHE
- SELECT_SQL_TRACE Function
- SELECT_SQLPA_TASK Function
- SELECT_SQLSET Function
- SELECT_WORKLOAD_REPOSITORY Function
- SET_TUNING_TASK_PARAMETER Procedures
- SQLTEXT_TO_SIGNATURE Function
- UNPACK_STGTAB_SQLPROF Procedure
- UNPACK_STGTAB_SQLSET Procedure
- UPDATE_SQLSET Procedures

文章快速说明索引
学习目标:
目的:接下来这段时间我想做一些兼容Oracle数据库Real Application Testing (即:RAT)上的一些功能开发,本专栏这里主要是学习以及介绍Oracle数据库功能的使用场景、原理说明和注意事项等,基于PostgreSQL数据库的功能开发等之后 由新博客进行介绍和分享!今天我们主要看一下 DBMS_SQLTUNE package 的相关内容!
学习内容:(详见目录)
1、Oracle数据库Real Application Testing之DBMS_SQLTUNE包技术详解
学习时间:
2023年04月18日 21:16:21
学习产出:
1、Oracle数据库Real Application Testing之DBMS_SQLTUNE包技术详解
2、CSDN 技术博客 1篇
注:下面我们所有的学习环境是Centos7+PostgreSQL15.0+Oracle19c+MySQL5.7
postgres=# select version();
version
-----------------------------------------------------------------------------
PostgreSQL 15.0 on x86_64-pc-linux-gnu, compiled by gcc (GCC) 7.1.0, 64-bit
(1 row)
postgres=#
#-----------------------------------------------------------------------------#
SQL> select * from v$version;
BANNER BANNER_FULL BANNER_LEGACY CON_ID
--------------------------------------------------------------------------- --------------------------------------------------------------------------- --------------------------------------------------------------------------- ----------
Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production 0
Version 19.3.0.0.0
SQL>
#-----------------------------------------------------------------------------#
mysql> select version();
+-----------+
| version() |
+-----------+
| 5.7.19 |
+-----------+
1 row in set (0.06 sec)
mysql>
DBMS_SQLTUNE 概述
- 官方链接:https://docs.oracle.com/en/database/oracle/oracle-database/21/arpls/DBMS_SQLTUNE.html
DBMS_SQLTUNE 包是用于按需调优 SQL 的接口。相关包 DBMS_AUTO_SQLTUNE 包为 SQL Tuning Advisor 作为自动化任务运行提供了接口。
DBMS_SQLTUNE 包提供了许多相互关联的功能领域。
SQL Tuning Advisor(SQL 调优顾问)
SQL Tuning Advisor 是一组顾问中的一个,是一组识别并帮助解决数据库性能问题的专家系统。具体来说,SQL Tuning Advisor 自动调优有问题的 SQL 语句。它以一个或多个 SQL 语句作为输入,并就如何调优这些语句给出精确的建议。该顾问以 SQL 操作的形式提供建议,以调优 SQL 及其预期的性能优势。
DBMS_SQLTUNE SQL Tuning Advisor 子程序组提供了一个面向任务的界面,使您能够访问该顾问程序。您可以按给定的顺序调用以下子程序以使用 SQL Tuning Advisor 的某些功能:
- CREATE_TUNING_TASK 函数创建用于调优一个或多个 SQL 语句的调优任务
- EXECUTE_TUNING_TASK 函数和过程执行先前创建的调优任务
- REPORT_TUNING_TASK 函数显示调优任务的结果
- 您使用 SCRIPT_TUNING_TASK 函数创建一个 SQL*Plus 脚本,然后可以执行该脚本以实施一组顾问建议
SQL Profile Subprograms(SQL 配置文件子程序)
SQL Tuning Advisor 可能会建议创建 SQL 配置文件以提高语句的性能。SQL 配置文件由特定于语句的辅助统计信息组成。查询优化器对基数、选择性和成本进行估计,这些估计有时可能会有很大偏差,从而导致执行计划不佳。SQL 配置文件通过使用抽样和部分执行技术收集额外信息来调优这些估计来解决这个问题。
DBMS_SQLTUNE SQL Profile 子程序组提供了一种机制,用于将统计信息传递给以特定 SQL 语句为目标的优化器,并通过为该语句提供尽可能准确的统计信息来帮助优化器对该语句做出正确的决策。例如:
- 您可以使用 ACCEPT_SQL_PROFILE 过程和函数来接受 SQL Tuning Advisor 推荐的 SQL 配置文件
- 您可以使用 ALTER_SQL_PROFILE 过程更改现有 SQL 配置文件的 STATUS、NAME、DESCRIPTION 和 CATEGORY 属性
- 您可以使用 DROP_SQL_PROFILE 过程删除 SQL 配置文件
SQL Tuning Sets(SQL 调优集)
SQL 调优集存储 SQL 语句以及以下信息:
- 执行上下文,例如解析模式名称和绑定值
- 执行统计信息,例如平均运行时间和执行次数
- 执行计划,即数据库为运行 SQL 语句而执行的操作序列
- 行源统计信息,例如为计划中执行的每个操作处理的行数
您可以通过过滤或排名来自多个来源的 SQL 语句来创建 SQL 调优集:
- 使用 SELECT_CURSOR_CACHE 函数的共享 SQL 区
- 使用 SELECT_WORKLOAD_REPOSITORY 函数的自动工作负载存储库中的顶级 SQL 语句
- 使用 SELECT_SQLSET 函数的其他 SQL 调优集
- 使用 SELECT_SQLPA_TASK 函数的 SQL Performance Analyzer 任务比较结果
- 使用 SELECT_SQL_TRACE 函数的 SQL 跟踪文件
- 用户定义的工作负载
完整的 DBMS_SQLTUNE SQL 调优集子程序组有助于实现此功能。 例如:
- CREATE_SQLSET 过程和函数在数据库中创建一个 SQL 调优集对象
- LOAD_SQLSET 过程用一组选定的 SQL 填充 SQL 调优集
- CAPTURE_CURSOR_CACHE_SQLSET 过程在指定的时间间隔内从共享 SQL 区域收集 SQL 语句,试图构建数据库工作负载的真实情况
注:操作 SQL 调优集时,可以使用 DBMS_SQLSET 作为 DBMS_SQLTUNE 的替代方法。
Import and Export of SQL Tuning Sets and SQL Profiles(SQL 调优集和 SQL 配置文件的导入和导出)
使用 DBMS_SQLTUNE 子程序使用通用编程模型将 SQL 配置文件和 SQL 调优集从一个系统移动到另一个系统。在这两种情况下,您都在源数据库上创建一个暂存表,并使用相关数据填充该暂存表。然后,您可以按照您选择的方法(例如 Oracle 数据泵或数据库链接)将该暂存表移动到目标系统,在该系统中它用于以原始形式重构对象。以下步骤是通过该包中包含的子程序实现的:
- 要在源系统上创建暂存表,请调用 CREATE_STGTAB_SQLPROF 过程或 CREATE_STGTAB_SQLSET 过程
- 要使用来自源系统的信息填充暂存表,请调用 PACK_STGTAB_SQLPROF 过程或 PACK_STGTAB_SQLSET 过程
- 将暂存表移动到目标系统
- 要在新系统上重新创建对象,请调用 UNPACK_STGTAB_SQLPROF 过程或 UNPACK_STGTAB_SQLSET 过程
Automatic Tuning Task Functions(自动调优任务函数)
自动化系统任务 SYS_AUTO_SQL_TUNING_TASK 由数据库作为目录脚本的一部分创建。此任务自动从 AWR 中选择一组高负载 SQL 并在该 SQL 上运行 SQL Tuning Advisor。自动化任务执行与任何其他 SQL 优化任务相同的综合分析。
您可以通过 DBMS_AUTO_SQLTUNE.REPORT_AUTO_TUNING_TASK API 获取有关自动 SQL 调优任务活动的报告。
Real-Time SQL Monitoring(实时 SQL 监控)
实时 SQL 监控使 DBA 或性能分析师能够在长时间运行的 SQL 语句执行时监控它们的执行情况。游标统计信息(如 CPU 时间和 IO 时间)和执行计划统计信息(如输出行数、内存和使用的临时空间)在语句执行期间几乎实时更新。
V$SQL_MONITOR 和 V$SQL_PLAN_MONITOR 视图公开了这些统计信息。另外,DBMS_SQLTUNE提供了REPORT_SQL_MONITOR和REPORT_SQL_MONITOR_LIST函数来上报监控信息。
注意:DBMS_SQL_MONITOR 还包含 REPORT_SQL_MONITOR 和 REPORT_SQL_MONITOR_LIST 函数。
Tuning a Standby Database Workload(调优备用数据库工作负载)
在某些情况下,备用数据库除了其数据保护角色外还可以承担报告角色。备用数据库可以有自己的查询工作负载,其中一些可能需要调优。您可以在只读的备用数据库上发出 SQL Tuning Advisor 语句。备用数据库到主数据库的链接使 DBMS_SQLTUNE 能够将数据写入主数据库并从中读取数据。有资格调优备用工作负载的过程包括 database_link_to 参数。
DBMS_SQLTUNE 安全模型
这个包对 PUBLIC 可用,并执行它自己的安全检查。请注意以下事项:
-
因为 SQL Tuning Advisor 依赖于 Advisor 框架,所以所有调优任务接口 (*_TUNING_TASK) 都需要 ADVISOR 权限
-
SQL 调优集子程序 (*_SQLSET) 需要以下权限之一:
- 管理 SQL 调优集:您只能创建和修改您拥有的 SQL 调优集
- 管理任何 SQL 调优集:您可以对所有 SQL 调优集进行操作,甚至是其他用户拥有的调优集
-
在早期版本中,调用涉及 SQL 配置文件的子程序需要三种不同的权限:
- 创建任何 SQL 配置文件
- 更改任何 SQL 配置文件
- 删除任何 SQL 配置文件
前面的权限已被弃用,取而代之的是 ADMINISTER SQL MANAGEMENT OBJECT。
DBMS_SQLTUNE 数据结构
DBMS_SQLTUNE 包中的 SELECT_* 子程序返回 SQLSET_ROW 类型的对象。SQLSET_ROW 对象类型,如下:
- SQLSET_ROW 对象为用户建模 SQL 调优集的内容。
- 从逻辑上讲,SQL 调优集是 SQLSET_ROW 对象的集合。每个 SQLSET_ROW 都包含一个 SQL 语句及其执行上下文、统计信息、绑定和计划。SELECT_* 子程序将每个数据源建模为 SQLSET_ROW 对象的集合,每个对象由 (sql_id, plan_hash_value) 唯一标识。类似地,LOAD_SQLSET 过程将行类型为 SQLSET_ROW 的游标作为输入,根据用户请求的策略单独处理每个 SQLSET_ROW
- 几个子程序包接受对 SQL 调优集或数据源内容的基本过滤器。这些过滤器是根据定义的 SQLSET_ROW 中的属性来表示的
类型定义如下:
CREATE TYPE sqlset_row AS object (
sql_id VARCHAR(13),
force_matching_signature NUMBER,
sql_text CLOB,
object_list sql_objects,
bind_data RAW(2000),
parsing_schema_name VARCHAR2(30),
module VARCHAR2(48),
action VARCHAR2(32),
elapsed_time NUMBER,
cpu_time NUMBER,
buffer_gets NUMBER,
disk_reads NUMBER,
direct_writes NUMBER,
rows_processed NUMBER,
fetches NUMBER,
executions NUMBER,
end_of_fetch_count NUMBER,
optimizer_cost NUMBER,
optimizer_env RAW(2000),
priority NUMBER,
command_type NUMBER,
first_load_time VARCHAR2(19),
stat_period NUMBER,
active_stat_period NUMBER,
other CLOB,
plan_hash_value NUMBER,
sql_plan sql_plan_table_type,
bind_list sql_binds,
con_dbid NUMBER,
last_exec_start_time VARCHAR2(19))
属性解释如下:
| Attribute | Description |
|---|---|
sql_id | 唯一的 SQL ID |
forcing_matching_signature | 删除了文字、大小写和空格的签名 |
sql_text | SQL 语句的全文 |
object_list | 目前没有实施 |
bind_data | 绑定为此 SQL 捕获的数据。请注意,您不能为该参数和 bind_list 规定参数。它们是相互排斥的 |
parsing_schema_name | 解析 SQL 的模式 |
module | SQL 的最后一个应用程序模块 |
action | SQL 的最后一个应用程序操作 |
elapsed_time | 此 SQL 语句的总用时和 |
cpu_time | 此 SQL 语句的总 CPU 时间之和 |
buffer_gets | 缓冲区获取总数的总和 |
disk_reads | 磁盘读取总数的总和 |
direct_writes | 直接路径写入总数的总和 |
rows_processed | 此 SQL 处理的总行数 |
fetches | 提取总数的和 |
executions | 此 SQL 语句的总执行数 |
end_of_fetch_count | SQL 语句在读取其所有行的情况下完全执行的次数 |
optimizer_cost | 此 SQL 的优化器成本 |
optimizer_env | 此 SQL 语句的优化器环境 |
priority | 用户定义的优先级 (1,2,3) |
command_type | 语句类型, such as INSERT or SELECT. |
first_load_time | 父游标的加载时间 |
stat_period | 收集该SQL语句统计信息的时间段(秒) |
active_stat_period | SQL 语句处于活动状态的有效时间段(以秒为单位) |
other | 用户定义属性的其他列 |
plan_hash_value | plan的计划哈希值 |
sql_plan | SQL 语句的执行计划 |
bind_list | SQL 语句的用户指定绑定列表。这用于用户指定的工作负载。请注意,您不能为该参数和 bind_data 规定参数:它们是互斥的 |
con_dbid | PDB 或 CDB 根的 DBID |
last_exec_start_time | 此 SQL 语句的最近一次执行开始时间 |
DBMS_SQLTUNE 子程序组
DBMS_SQLTUNE 子程序按功能分组,如下:
- DBMS_SQLTUNE SQL 调优顾问子程序
- DBMS_SQLTUNE SQL 配置文件子程序
- DBMS_SQLTUNE SQL 调优集子程序
- DBMS_SQLTUNE 实时SQL监控子程序
- DBMS_SQLTUNE SQL 性能报告子程序
DBMS_SQLTUNE SQL 调优顾问子程序
这个子程序组提供了一个接口来管理 SQL 调优任务,如下:
| Subprogram | Description |
|---|---|
| “CANCEL_TUNING_TASK Procedure” | 取消当前正在执行的调优任务 |
| “CREATE_SQL_PLAN_BASELINE Procedure” | 为现有计划创建 SQL 计划基线 |
| “CREATE_TUNING_TASK Functions” | 为 SQL Tuning Advisor 创建单个语句或 SQL 调优集的调优 |
| “DROP_TUNING_TASK Procedure” | 删除 SQL 调优任务 |
| “EXECUTE_TUNING_TASK Function and Procedure” | 执行先前创建的调优任务 |
| “IMPLEMENT_TUNING_TASK Procedure” | 实施 SQL Tuning Advisor 提出的一组 SQL 配置文件建议 |
| “INTERRUPT_TUNING_TASK Procedure” | 中断当前正在执行的调优任务 |
| “REPORT_AUTO_TUNING_TASK Function” | 显示来自自动调优任务的报告,报告执行范围 |
| “REPORT_TUNING_TASK Function” | 显示调优任务的结果 |
| “RESET_TUNING_TASK Procedure” | 将当前执行的调优任务重置为初始状态 |
| “RESUME_TUNING_TASK Procedure” | 恢复先前为处理 SQL 调优集而创建的中断任务 |
| “SCHEDULE_TUNING_TASK Function” | 创建调优任务并将其执行安排为调度程序作业 |
| “SCRIPT_TUNING_TASK Function” | 创建一个 SQL*Plus 脚本,然后可以执行该脚本以实施一组 SQL Tuning Advisor 建议 |
| “SET_TUNING_TASK_PARAMETER Procedures” | 更新类型为 VARCHAR2NUMBER 的 SQL 调优参数的值 |
DBMS_SQLTUNE SQL 配置文件子程序
这个子程序组提供了一个接口来管理 SQL 配置文件,如下:
| Subprogram | Description |
|---|---|
| ACCEPT_ALL_SQL_PROFILES Procedure | 接受调优任务的特定执行推荐的所有 SQL 配置文件 |
| ACCEPT_SQL_PROFILE Procedure and Function | 为指定的调优任务创建 SQL 配置文件 |
| ALTER_SQL_PROFILE Procedure | 更改现有 SQL 配置文件对象的特定属性 |
| CREATE_STGTAB_SQLPROF Procedure | 创建用于将 SQL 配置文件从一个系统复制到另一个系统的暂存表 |
| DROP_SQL_PROFILE Procedure | 从数据库中删除指定的 SQL 配置文件 |
| PACK_STGTAB_SQLPROF Procedure | 将配置文件数据从模式中移到临时表 SYS 中 |
| REMAP_STGTAB_SQLPROF Procedure | 在执行解包操作之前更改暂存表中保存的配置文件数据值 |
| SQLTEXT_TO_SIGNATURE Function | 返回 SQL 文本的签名 |
| UNPACK_STGTAB_SQLPROF Procedure | 使用存储在暂存表中的配置文件数据在此系统上创建配置文件 |
DBMS_SQLTUNE SQL 调优集子程序
这个子程序组提供了一个接口来管理 SQL 调优集,如下:
| Subprogram | Description |
|---|---|
| ADD_SQLSET_REFERENCE Function | 向现有SQL调优集添加新引用,以指示客户机对其的使用 |
| CAPTURE_CURSOR_CACHE_SQLSET Procedure | 在指定的时间间隔内,增量地将工作负载从共享SQL区域捕获到SQL调优集 |
| CREATE_SQLSET Procedure and Function | 在数据库中创建SQL调优集对象 |
| CREATE_STGTAB_SQLSET Procedure | 创建一个staging表,通过该表导入和导出SQL调优集 |
| DELETE_SQLSET Procedure | 从SQL调优集中删除一组SQL语句 |
| DROP_SQLSET Procedure | 如果 SQL 调优集不活动,则将其删除 |
| LOAD_SQLSET Procedure | 使用一组选定的 SQL 填充 SQL 调优集 |
| PACK_STGTAB_SQLSET Procedure | 将模式中的调优集复制到临时表 SYS 中 |
| REMAP_STGTAB_SQLSET Procedure | 更改staging表中的调优集名称和所有者,以便可以使用与在主机系统上不同的值解压缩它们 |
| REMOVE_SQLSET_REFERENCE Procedure | 停用SQL调优集,以指示客户端不再使用它 |
| SELECT_CURSOR_CACHE Function | 从共享SQL区域收集SQL语句 |
| SELECT_SQL_TRACE Function | 读取一个或多个跟踪文件的内容,并以sqlset_row的格式返回它找到的SQL语句 |
| SELECT_SQLPA_TASK Function | 从 SQL 性能分析器比较任务中收集 SQL 语句 |
| SELECT_SQLSET Function | 从现有的 SQL 调优集中收集 SQL 语句 |
| SELECT_WORKLOAD_REPOSITORY Function | 从工作负载存储库中收集 SQL 语句 |
| UNPACK_STGTAB_SQLSET Procedure | 从staging表复制一个或多个SQL调优集 |
| UPDATE_SQLSET Procedures | 更新SQL调优集中SQL语句的选定字符串字段或SQL调优集中SQL的集数值属性 |
DBMS_SQLTUNE 实时SQL监控子程序
该子程序组提供收集到V$SQL_MONITORV$SQL_PLAN_MONITOR中的监控数据的报告功能,如下:
| Subprogram | Description |
|---|---|
| REPORT_SQL_MONITOR Function | 实时 SQL 监控报告 |
| REPORT_SQL_MONITOR_LIST Function | 为 Oracle 数据库监控的全部或部分语句构建报告 |
| REPORT_SQL_MONITOR_LIST_XML Function | 为 Oracle 数据库监控的全部或部分语句构建 XML 报告 |
DBMS_SQLTUNE SQL 性能报告子程序
该子程序组使用来自共享 SQL 区域和自动工作负载存储库 (AWR) 的统计信息提供有关 SQL 性能的详细报告。如下:
| Subprogram | Description |
|---|---|
| REPORT_SQL_DETAIL Function | 此函数报告特定的 SQL ID |
| REPORT_SQL_MONITOR Function | 此函数为代表目标语句执行收集的监视信息构建报告(文本、简单 HTML、活动 HTML、XML) |
| REPORT_SQL_MONITOR_LIST Function | 此功能为 Oracle 监控的所有语句或语句子集构建报告。对于每条语句,子程序都会提供关键信息和相关的全局统计信息 |
| REPORT_TUNING_TASK Function | 此函数显示调优任务的结果 |
| REPORT_TUNING_TASK_XML Function | 此函数显示调优任务的 XML 报告 |
DBMS_SQLTUNE 子程序总结
ACCEPT_ALL_SQL_PROFILES Procedure
该过程接受调优任务的特定执行推荐的所有SQL配置文件,并根据用户传递的参数值设置SQL配置文件的属性。其语法格式如下:
DBMS_SQLTUNE.ACCEPT_ALL_SQL_PROFILES (
task_name IN VARCHAR2,
category IN VARCHAR2 := NULL,
replace IN BOOLEAN := FALSE,
force_match IN BOOLEAN := FALSE,
profile_type IN VARCHAR2 := REGULAR_PROFILE,
autotune_period IN NUMBER := NULL,
execution_name IN VARCHAR2 := NULL,
task_owner IN VARCHAR2 := NULL,
description IN VARCHAR2 := NULL,
database_link_to IN VARCHAR2 := NULL);
其参数解释如下:
| 参数 | 描述 |
|---|---|
task_name | SQL 调优任务的(必填)名称 |
category | 这是类别名称,它必须与会话中 SQLTUNE_CATEGORY 参数的值相匹配,以便会话使用此 SQL 配置文件。它默认为值“DEFAULT”。这也是 SQLTUNE_CATEGORY 参数的默认值。该类别必须是有效的 Oracle 标识符。指定的类别名称始终转换为大写。规范化的 SQL 文本和类别名称的组合为 SQL 配置文件创建了一个唯一的键。如果此组合被复制,则 ACCEPT_SQL_PROFILE 将失败 |
replace | 如果配置文件已经存在,如果此参数为 TRUE,则将替换它。传递已用于另一个签名/类别对的名称是错误的,即使 replace 设置为 TRUE |
force_match | 如果为 TRUE,这会导致 SQL 配置文件将所有文本值规范化为绑定变量后具有相同文本的所有 SQL 语句作为目标。(请注意,如果在 SQL 语句中使用文字值和绑定值的组合,则不会发生绑定转换)这类似于 cursor_sharing 参数的 FORCE 选项使用的匹配算法。如果为 FALSE,则不转换文字。这类似于 cursor_sharing 参数的 EXACT 选项使用的匹配算法 |
profile_type | 选项: REGULAR_PROFILE - 不更改并行执行的配置文件(默认,相当于 NULL)。请注意,如果 SQL 语句当前有一个并行执行计划,则常规配置文件将导致优化器选择一个不同但仍然并行的执行计划。PX_PROFILE - 更改为并行执行的常规配置文件 |
autotune_period | SQL 自动调优的时间段。此设置仅适用于自动 SQL Tuning Advisor 任务。可能的值如下: null 或负值(默认值)- all 或 full。 结果包括所有任务执行。0 - 当前或最近任务执行的结果。1 - 最近 24 小时的结果。 7 - 最近 7 天的结果。该过程将任何其他值解释为最近执行任务的时间减去该参数的值。 |
execution_name | 要使用的任务执行的名称。如果为空,则该过程为最近的任务执行生成报告。 |
task_owner | 调优任务的所有者。这是一个可选参数,必须指定该参数才能接受与另一个用户拥有的调优任务关联的 SQL 配置文件。当前用户是默认值 |
description | 描述 SQL 配置文件用途的用户指定字符串。如果超过 256 个字符,描述将被截断。 最大大小为 500 个字符。 |
database_link_to | 备用数据库上存在的数据库链接的名称。该链接指定与主数据库的连接。默认情况下,该值为空,这意味着 SQL Tuning Advisor 会话是本地的。使用 DBMS_SQLTUNE 调优在 Active Data Guard 场景中运行在备用数据库上的高负载 SQL 语句。当你在备库本地执行REPORT_TUNING_TASK时,该函数使用数据库链接从主库获取数据,然后在备库本地构建。database_link_to 参数必须指定私有数据库链接。此链接必须由 SYS 拥有并由默认特权用户 SYS$UMF 访问。以下示例语句创建一个名为 lnk_to_pri 的链接:CREATE DATABASE LINK lnk_to_pri CONNECT TO SYS$UMF IDENTIFIED BY password USING ‘inst1’; |
安全模型
该权限是必需的。该特权已弃用。ADMINISTER SQL MANAGEMENT OBJECTCREATE ANY SQL PROFILE
ACCEPT_SQL_PROFILE Procedure and Function
该子程序创建 SQL Tuning Advisor 推荐的 SQL 配置文件。
尽管 SQL 文本以非规范化形式存储在数据字典中以提高可读性,但出于匹配目的对 SQL 文本进行了规范化。SQL 文本是通过对 SQL 调优任务的引用提供的。如果引用的 SQL 语句不存在,则数据库报错。其语法格式如下:
DBMS_SQLTUNE.ACCEPT_SQL_PROFILE (
task_name IN VARCHAR2,
object_id IN NUMBER := NULL,
name IN VARCHAR2 := NULL,
description IN VARCHAR2 := NULL,
category IN VARCHAR2 := NULL);
task_owner IN VARCHAR2 := NULL,
replace IN BOOLEAN := FALSE,
force_match IN BOOLEAN := FALSE,
profile_type IN VARCHAR2 := REGULAR_PROFILE);
DBMS_SQLTUNE.ACCEPT_SQL_PROFILE (
task_name IN VARCHAR2,
object_id IN NUMBER := NULL,
name IN VARCHAR2 := NULL,
description IN VARCHAR2 := NULL,
category IN VARCHAR2 := NULL;
task_owner IN VARCHAR2 := NULL,
replace IN BOOLEAN := FALSE,
force_match IN BOOLEAN := FALSE,
profile_type IN VARCHAR2 := REGULAR_PROFILE,
database_link_to IN VARCHAR2 := NULL)
RETURN VARCHAR2;
其参数解释如下:
| 参数 | 描述 |
|---|---|
task_name | SQL 调优任务的(必填)名称 |
object_id | 代表与调优任务关联的 SQL 语句的顾问框架对象的标识符 |
name | SQL 配置文件的名称。它不能包含双引号。名称区分大小写。如果未指定,系统会为 SQL 配置文件生成一个唯一的名称 |
description | 描述 SQL 配置文件用途的用户指定字符串。如果超过 256 个字符,描述将被截断。 最大大小为 500 个字符 |
category | 类别名称。此名称必须与会话中 SQLTUNE_CATEGORY 参数的值匹配,以便会话使用此 SQL 配置文件。它默认为值“DEFAULT”。这也是 SQLTUNE_CATEGORY 参数的默认值。该类别必须是有效的 Oracle 标识符。指定的类别名称始终转换为大写。规范化的 SQL 文本和类别名称的组合为 SQL 配置文件创建了一个唯一的键。如果此组合被复制,则 ACCEPT_SQL_PROFILE 将失败 |
task_owner | 调优任务的所有者。这是一个可选参数,必须指定它才能接受与另一个用户拥有的调优任务关联的 SQL 配置文件。当前用户是默认值 |
replace | 如果配置文件已经存在,如果此参数为 TRUE,则将替换它。传递已用于另一个签名/类别对的名称是错误的,即使 replace 设置为 TRUE |
force_match | 如果为 TRUE,这会导致 SQL 配置文件将所有文本值规范化为绑定变量后具有相同文本的所有 SQL 语句作为目标。(请注意,如果在 SQL 语句中使用文字值和绑定值的组合,则不会发生绑定转换)这类似于 cursor_sharing 参数的 FORCE 选项使用的匹配算法。如果为 FALSE,则不转换文字。这类似于 cursor_sharing 参数的 EXACT 选项使用的匹配算法 |
profile_type | 选项: REGULAR_PROFILE - 不更改并行执行的配置文件(默认,相当于 NULL)。请注意,如果 SQL 语句当前有一个并行执行计划,则常规配置文件将导致优化器选择一个不同但仍然并行的执行计划。PX_PROFILE - 更改为并行执行的常规配置文件 |
database_link_to | 备用数据库上存在的数据库链接的名称。该链接指定与主数据库的连接。默认情况下,该值为空,这意味着 SQL Tuning Advisor 会话是本地的。使用 DBMS_SQLTUNE 调优在 Active Data Guard 场景中运行在备用数据库上的高负载 SQL 语句。当你在备库本地执行REPORT_TUNING_TASK时,该函数使用数据库链接从主库获取数据,然后在备库本地构建。database_link_to 参数必须指定私有数据库链接。此链接必须由 SYS 拥有并由默认特权用户 SYS$UMF 访问。以下示例语句创建一个名为 lnk_to_pri 的链接:CREATE DATABASE LINK lnk_to_pri CONNECT TO SYS$UMF IDENTIFIED BY password USING ‘inst1’; |
其返回值为:SQL 配置文件的名称。
注:需要 ADMINISTER SQL MANAGEMENT OBJECT 特权。CREATE ANY SQL PROFILE 权限已弃用。
其使用案例如下:
您可以以相同的方式使用子程序的过程版本和函数版本,只是您必须指定返回值才能调用函数。这里我们只给出程序的例子。在此示例中,您从工作负载存储库中调优单个 SQL 语句,并创建 SQL Tuning Advisor 推荐的 SQL 配置文件。
VARIABLE stmt_task VARCHAR2(64);
VARIABLE sts_task VARCHAR2(64);
-- create a tuning task tune the statement
EXEC :stmt_task := DBMS_SQLTUNE.CREATE_TUNING_TASK(
begin_snap => 1, -
end_snap => 2, -
sql_id => 'ay1m3ssvtrh24');
-- execute the resulting task
EXEC DBMS_SQLTUNE.EXECUTE_TUNING_TASK(:stmt_task);
EXEC DBMS_SQLTUNE.ACCEPT_SQL_PROFILE(:stmt_task);
请注意,您不必为 SQL Tuning Advisor 创建的 Advisor 框架对象指定 ID(即 object_id)以表示已调优的 SQL 语句。
您可能还想在不同的类别(例如,TEST)中接受推荐的 SQL 配置文件,以便默认情况下不使用它。
EXEC DBMS_SQLTUNE.ACCEPT_SQL_PROFILE (
task_name => :stmt_task, -
category => 'TEST');
您可以使用命令 ALTER SESSION SET SQLTUNE_CATEGORY = ‘TEST’ 来查看此配置文件的行为方式。
以下调用创建一个 SQL 配置文件,该配置文件以任何与调优语句具有相同 force_matching_signature 的 SQL 语句为目标。
EXEC DBMS_SQLTUNE.ACCEPT_SQL_PROFILE (task_name => :stmt_task, -
force_match => TRUE);
在以下示例中,您调优了一个 SQL 调优集,并仅为 SQL 调优集中的一个 SQL 语句创建了一个 SQL 配置文件。SQL 语句由 ID 等于 5 的顾问框架对象表示。您必须将对象 ID 传递给 ACCEPT_SQL_PROFILE 过程,因为调优任务可能有许多 SQL 配置文件。此对象 ID 随报告一起提供。
EXEC :sts_task := DBMS_SQLTUNE.CREATE_TUNING_TASK ( -
sqlset_name => 'my_workload', -
rank1 => 'ELAPSED_TIME', -
time_limit => 3600, -
description => 'my workload ordered by elapsed time');
-- execute the resulting task
EXEC DBMS_SQLTUNE.EXECUTE_TUNING_TASK(:sts_task);
-- create the profile for the sql statement corresponding to object_id = 5.
EXEC DBMS_SQLTUNE.ACCEPT_SQL_PROFILE (
task_name => :sts_task, -
object_id => 5);
ADD_SQLSET_REFERENCE Function
此过程添加对现有 SQL 调优集的新引用以指示其由客户端使用。其语法格式如下:
DBMS_SQLTUNE.ADD_SQLSET_REFERENCE (
sqlset_name IN VARCHAR2,
description IN VARCHAR2 := NULL)
RETURN NUMBER;
注:DBMS_SQLTUNE.ADD_SQLSET_REFERENCE 和 DBMS_SQLSET.ADD_REFERENCE 的参数相同。
其参数解释如下:
| Parameter | Description |
|---|---|
sqlset_name | 指定 SQL 调优集的名称 |
description | 提供 SQL 调优集用法的可选描述。 如果超过 256 个字符,描述将被截断。 |
sqlset_owner | 指定 SQL 调优集的所有者,或者为当前模式所有者指定 NULL |
其返回值为:添加的引用的标识符。
其使用案例如下:
您可以添加对 SQL 调优集的引用。这可以防止调优集在使用时被修改。当您在 SQL 调优集上调用 SQL Tuning Advisor 时,会自动添加引用,因此您应该仅将此功能用于自定义目的。该函数返回一个引用 ID,用于稍后将其删除。您使用 REMOVE_SQLSET_REFERENCE 过程删除对 SQL 调优集的引用。
VARIABLE rid NUMBER;
EXEC :rid := DBMS_SQLTUNE.ADD_SQLSET_REFERENCE( -
sqlset_name => 'my_workload', -
description => 'my sts reference');
您可以使用 DBA_SQLSET_REFERENCES 视图查找给定 SQL 调优集上的所有引用。
ALTER_SQL_PROFILE Procedure
此过程更改现有 SQL 配置文件对象的特定属性。可以更改以下属性(使用这些属性名称):
- STATUS 可以设置为 ENABLED 或 DISABLED
- NAME 可以重置为有效名称,该名称必须是有效的 Oracle 标识符并且必须是唯一的
- DESCRIPTION 可以设置为任何长度不超过 500 个字符的字符串
- CATEGORY 可以重置为有效的类别名称,该名称必须是有效的 Oracle 标识符,并且在与规范化 SQL 文本组合时必须是唯一的
其语法格式如下:
DBMS_SQLTUNE.ALTER_SQL_PROFILE (
name IN VARCHAR2,
attribute_name IN VARCHAR2,
value IN VARCHAR2);
其参数解释如下:
| Parameter | Description |
|---|---|
name | 要更改的现有 SQL 配置文件的(强制)名称 |
attribute_name | 使用有效属性名称更改(不区分大小写)的(强制)属性名称 |
value | 使用有效属性值的属性的(强制)新值 |
注:需要 ALTER ANY SQL PROFILE 权限。
其使用案例如下:
-- Disable a profile, so it is not be used by any sessions.
EXEC DBMS_SQLTUNE.ALTER_SQL_PROFILE ( name => :pname, -
attribute_name => 'STATUS', -
value => 'DISABLED');
-- Enable it back:
EXEC DBMS_SQLTUNE.ALTER_SQL_PROFILE ( name => :pname, -
attribute_name => 'STATUS', -
value => 'ENABLED');
-- Change the category of the profile so it is used only by sessions
-- with category set to TEST.
-- Use ALTER SESSION SET SQLTUNE_CATEGORY = 'TEST' to see how this profile
-- behaves.
EXEC DBMS_SQLTUNE.ALTER_SQL_PROFILE ( name => :pname, -
attribute_name => 'CATEGORY', -
value => 'TEST');
-- Change it back:
EXEC DBMS_SQLTUNE.ALTER_SQL_PROFILE ( name => :pname, -
attribute_name => 'CATEGORY', -
value => 'DEFAULT');
CANCEL_TUNING_TASK Procedure
此过程取消当前正在执行的调优任务。删除所有中间结果数据。其语法格式如下:
DBMS_SQLTUNE.CANCEL_TUNING_TASK (
task_name IN VARCHAR2);
其参数解释如下:
| Parameter | Description |
|---|---|
task_name | 指定要取消的任务的名称 |
其使用案例如下:
当您需要停止执行任务并且不需要查看任何已完成的结果时,您可以取消任务。
EXEC DBMS_SQLTUNE.CANCEL_TUNING_TASK(:my_task);
CAPTURE_CURSOR_CACHE_SQLSET Procedure
此过程将工作负载从共享 SQL 区域捕获到 SQL 调优集中。
该过程在一段时间内多次轮询缓存,并更新存储在那里的工作负载数据。它可以根据捕获整个系统工作负载所需的时间执行。其语法格式如下:
DBMS_SQLTUNE.CAPTURE_CURSOR_CACHE_SQLSET (
sqlset_name IN VARCHAR2,
time_limit IN POSITIVE := 1800,
repeat_interval IN POSITIVE := 300,
capture_option IN VARCHAR2 := 'MERGE',
capture_mode IN NUMBER := MODE_REPLACE_OLD_STATS,
basic_filter IN VARCHAR2 := NULL,
sqlset_owner IN VARCHAR2 := NULL,
recursive_sql IN VARCHAR2 := HAS_RECURSIVE_SQL);
注:DBMS_SQLTUNE.CAPTURE_CURSOR_CACHE_SQLSET 和 DBMS_SQLSET.CAPTURE_CURSOR_CACHE 的参数相同。
其参数解释如下:
| Parameter | Description |
|---|---|
sqlset_name | 指定 SQL 调优集名称 |
time_limit | 定义执行的总时间(以秒为单位) |
repeat_interval | 定义在采样之间暂停的时间量(以秒为单位) |
capture_option | 指定是否插入新语句、更新现有语句或两者。值为 INSERT、UPDATE 或 MERGE。 这些值与 load_sqlset 中的 load_option 相同 |
capture_mode | 指定捕获模式(UPDATE 和 MERGE 捕获选项)。可能的值:MODE_REPLACE_OLD_STATS — 当执行次数大于存储在 SQL 调优集中的数量时替换统计信息。MODE_ACCUMULATE_STATS — 将新值添加到已存储的 SQL 的当前值中。请注意,此模式会检测语句是否已过期,因此统计信息的最终值是该语句下存在的所有游标的统计信息的总和 |
basic_filter | 定义一个过滤器以应用于每个示例的共享 SQL 区域。如果调用者没有设置 basic_filter,则子程序只捕获 CREATE TABLE、INSERT、SELECT、UPDATE、DELETE 和 MERGE 类型的语句 |
sqlset_owner | 指定 SQL 调优集的所有者或当前模式所有者的 NULL |
recursive_sql | 定义一个过滤器,在 SQL 调优集中包含递归 SQL (HAS_RECURSIVE_SQL) 或排除它 (NO_RECURSIVE_SQL) |
其使用案例如下:
在此示例中,捕获发生在 30 秒的时间内,每五秒轮询一次缓存。这会捕获该期间运行的所有语句,但不会捕获之前或之后运行的语句。如果相同的语句第二次出现,则该过程用新出现的语句替换存储的语句。
请注意,在生产系统中,时间限制和重复间隔会设置得更高。您应该根据系统的工作负载时间和共享 SQL 区域周转率属性调优 time_limit 和 repeat_interval 参数。
EXEC DBMS_SQLTUNE.CAPTURE_CURSOR_CACHE_SQLSET( -
sqlset_name => 'my_workload', -
time_limit => 30, -
repeat_interval => 5);
在下面的调用中,您可以边执行边累积执行统计信息。此选项生成每个游标的累积活动的准确图片,即使在超时期间也是如此,但它比前面的示例更昂贵。
EXEC DBMS_SQLTUNE.CAPTURE_CURSOR_CACHE_SQLSET( -
sqlset_name => 'my_workload', -
time_limit => 30, -
repeat_interval => 5, -
capture_mode => dbms_sqltune.MODE_ACCUMULATE_STATS);
此调用执行非常便宜的捕获,您只插入新语句并且在将它们插入到 SQL 调优集中后不更新它们的统计信息:
EXEC DBMS_SQLTUNE.CAPTURE_CURSOR_CACHE_SQLSET( -
sqlset_name => 'my_workload', -
time_limit => 30, -
repeat_interval => 5, -
capture_option => 'INSERT');
CREATE_SQL_PLAN_BASELINE Procedure
此过程为执行计划创建 SQL 计划基线。它可以在 SQL Tuning Advisor 进行的替代计划查找的上下文中使用。其语法格式如下:
DBMS_SQLTUNE.CREATE_SQL_PLAN_BASELINE (
task_name IN VARCHAR2,
object_id IN NUMBER := NULL,
plan_hash_value IN NUMBER,
owner_name IN VARCHAR2 := NULL,
database_link_to IN VARCHAR2 := NULL);
其参数解释如下:
| Parameter | Description |
|---|---|
task_name | 要为其获取脚本的任务的名称 |
object_id | SQL对应的对象ID |
plan_hash_value | 计划创建计划基线 |
owner_name | 相关调优任务的所有者。默认为当前架构所有者 |
database_link_to | 备用数据库上存在的数据库链接的名称。该链接指定与主数据库的连接。默认情况下,该值为空,这意味着 SQL Tuning Advisor 会话是本地的。使用 DBMS_SQLTUNE 调优在 Active Data Guard 场景中运行在备用数据库上的高负载 SQL 语句。当你在备库本地执行REPORT_TUNING_TASK时,该函数使用数据库链接从主库获取数据,然后在备库本地构建。database_link_to 参数必须指定私有数据库链接。此链接必须由 SYS 拥有并由默认特权用户 SYS$UMF 访问。以下示例语句创建一个名为 lnk_to_pri 的链接:CREATE DATABASE LINK lnk_to_pri CONNECT TO SYS$UMF IDENTIFIED BY password USING ‘inst1’; |
CREATE_SQLSET Procedure and Function
此过程或函数在数据库中创建一个 SQL 调优集对象。其语法格式如下:
DBMS_SQLTUNE.CREATE_SQLSET (
sqlset_name IN VARCHAR2,
description IN VARCHAR2 := NULL
sqlset_owner IN VARCHAR2 := NULL);
DBMS_SQLTUNE.CREATE_SQLSET (
sqlset_name IN VARCHAR2 := NULL,
description IN VARCHAR2 := NULL,
sqlset_owner IN VARCHAR2 := NULL)
RETURN VARCHAR2;
其语法格式如下:
| Parameter | Description |
|---|---|
sqlset_name | 指定创建的 SQL 调优集的名称。名称是传递给函数的名称。如果没有名称传递给函数,那么函数会自动生成一个名称 |
description | 提供 SQL 调优集的可选描述 |
sqlset_owner | 指定 SQL 调优集的所有者,或者为当前模式所有者指定 NULL |
其使用案例如下:
EXEC DBMS_SQLTUNE.CREATE_SQLSET(-
sqlset_name => 'my_workload', -
description => 'complete application workload');
CREATE_STGTAB_SQLPROF Procedure
此过程创建用于将 SQL 配置文件从一个系统复制到另一个系统的暂存表。其语法格式如下:
DBMS_SQLTUNE.CREATE_STGTAB_SQLPROF (
table_name IN VARCHAR2,
schema_name IN VARCHAR2 := NULL,
tablespace_name IN VARCHAR2 := NULL);
其参数解释如下:
| Parameter | Description |
|---|---|
table_name | 要创建的表的名称(不区分大小写,除非双引号) |
schema_name | 在其中创建表的模式,或当前模式的 NULL(不区分大小写,除非双引号) |
tablespace_name | 用于存储暂存表的表空间,或者当前用户的默认表空间为 NULL(不区分大小写,除非双引号) |
注意事项:
- 在发出对 PACK_STGTAB_SQLPROF 过程的调用之前调用此过程一次
- 要将不同的 SQL 配置文件放在不同的暂存表中,您可以多次调用此过程
- 这是一个 DDL 操作,因此它不会发生在事务中
其使用案例如下:
创建一个暂存表来存储可以移动到另一个系统的配置文件数据。
EXEC DBMS_SQLTUNE.CREATE_STGTAB_SQLPROF (table_name => 'PROFILE_STGTAB');
CREATE_STGTAB_SQLSET Procedure
此过程创建一个暂存表,通过该表导入和导出 SQL 调优集。其语法格式如下:
DBMS_SQLTUNE.CREATE_STGTAB_SQLSET (
table_name IN VARCHAR2,
schema_name IN VARCHAR2 := NULL,
tablespace_name IN VARCHAR2 := NULL,
db_version IN NUMBER := NULL);
其参数解释如下:
| Parameter | Description |
|---|---|
table_name | 指定要创建的表的名称。名称区分大小写 |
schema_name | 定义要在其中创建表的架构,或为当前架构定义 NULL。名称区分大小写 |
tablespace_name | 指定存储暂存表的表空间,或 NULL 表示当前用户的默认表空间。名称区分大小写 |
db_version | 指定确定暂存表格式的数据库版本。您还可以创建旧数据库版本暂存表以将 STS 导出到旧数据库版本。使用以下值之一: |
- NULL(默认值)— 指定当前数据库版本
- STS_STGTAB_10_2_VERSION — 指定 10.2 数据库版本
- STS_STGTAB_11_1_VERSION — 指定 11.1 数据库版本
- STS_STGTAB_11_2_VERSION — 指定 11.2 数据库版本
- STS_STGTAB_12_1_VERSION — 指定 12.1 数据库版本
- STS_STGTAB_12_2_VERSION — 指定 12.2 数据库版本
安全模型:您必须在指定的架构和表空间中具有 CREATE TABLE 权限
注意事项:
- 在打包 SQL 集之前调用此过程一次
- 要在不同的暂存表中使用不同的调优集,您可以多次调用此过程
- 这是一个 DDL 操作,因此它不会发生在事务中
- 临时表包含嵌套的表列和索引,因此不应重命名
其使用案例如下:
创建用于打包并最终导出 SQL 调优集的暂存表,如下:
EXEC DBMS_SQLTUNE.CREATE_STGTAB_SQLSET(table_name => 'STGTAB_SQLSET');
创建一个临时表以将 SQL 调优集打包为 Oracle Database 11g 第 2 版 (11.2) 格式,如下:
BEGIN
DBMS_SQLTUNE.CREATE_STGTAB_SQLSET(
table_name => 'STGTAB_SQLSET'
, db_version => DBMS_SQLTUNE.STS_STGTAB_11_2_VERSION );
END;
CREATE_TUNING_TASK Functions
此函数创建一个 SQL Tuning Advisor 任务。您可以使用此函数的不同形式来:
- 为给定文本的单个语句创建调优任务
- 从给定标识符的共享 SQL 区域为单个语句创建调优任务
- 给定一系列快照标识符,为来自工作负载存储库的单个语句创建调优任务
- 为 SQL 调优集创建调优任务
- 为 SQL Performance Analyzer 创建调优任务
在所有情况下,该函数主要创建 SQL Tuning Advisor 任务并设置其参数。
注意:多租户容器数据库是 Oracle Database 20c 中唯一受支持的架构。在修订文档时,遗留术语可能会继续存在。在大多数情况下,“数据库”和“非 CDB”指的是 CDB 或 PDB,具体取决于上下文。在某些情况下,例如升级,“非 CDB”是指来自先前版本的非 CDB。
其语法格式如下:
-- SQL text format:
DBMS_SQLTUNE.CREATE_TUNING_TASK (
sql_text IN CLOB,
bind_list IN sql_binds := NULL,
user_name IN VARCHAR2 := NULL,
scope IN VARCHAR2 := SCOPE_COMPREHENSIVE,
time_limit IN NUMBER := TIME_LIMIT_DEFAULT,
task_name IN VARCHAR2 := NULL,
description IN VARCHAR2 := NULL,
con_name IN VARCHAR2 := NULL,
database_link_to IN VARCHAR2 := NULL)
RETURN VARCHAR2;
-- SQL ID format:
DBMS_SQLTUNE.CREATE_TUNING_TASK (
sql_id IN VARCHAR2,
plan_hash_value IN NUMBER := NULL,
scope IN VARCHAR2 := SCOPE_COMPREHENSIVE,
time_limit IN NUMBER := TIME_LIMIT_DEFAULT,
task_name IN VARCHAR2 := NULL,
description IN VARCHAR2 := NULL,
con_name IN VARCHAR2 := NULL,
database_link_to IN VARCHAR2 := NULL)
RETURN VARCHAR2;
-- AWR format:
DBMS_SQLTUNE.CREATE_TUNING_TASK (
begin_snap IN NUMBER,
end_snap IN NUMBER,
sql_id IN VARCHAR2,
plan_hash_value IN NUMBER := NULL,
scope IN VARCHAR2 := SCOPE_COMPREHENSIVE,
time_limit IN NUMBER := TIME_LIMIT_DEFAULT,
task_name IN VARCHAR2 := NULL,
description IN VARCHAR2 := NULL,
con_name IN VARCHAR2 := NULL,
dbid IN NUMBER := NULL,
database_link_to IN VARCHAR2 := NULL)
RETURN VARCHAR2;
-- SQL tuning set format:
DBMS_SQLTUNE.CREATE_TUNING_TASK (
sqlset_name IN VARCHAR2,
basic_filter IN VARCHAR2 := NULL,
object_filter IN VARCHAR2 := NULL,
rank1 IN VARCHAR2 := NULL,
rank2 IN VARCHAR2 := NULL,
rank3 IN VARCHAR2 := NULL,
result_percentage IN NUMBER := NULL,
result_limit IN NUMBER := NULL,
scope IN VARCHAR2 := SCOPE_COMPREHENSIVE,
time_limit IN NUMBER := TIME_LIMIT_DEFAULT,
task_name IN VARCHAR2 := NULL,
description IN VARCHAR2 := NULL
plan_filter IN VARCHAR2 := 'MAX_ELAPSED_TIME',
sqlset_owner IN VARCHAR2 := NULL,
database_link_to IN VARCHAR2 := NULL)
RETURN VARCHAR2;
-- SQL Performance Analyzer format:
DBMS_SQLTUNE.CREATE_TUNING_TASK (
spa_task_name IN VARCHAR2,
spa_task_owner IN VARCHAR2 := NULL,
spa_compare_exec IN VARCHAR2 := NULL,
basic_filter IN VARCHAR2 := NULL,
time_limit IN NUMBER := TIME_LIMIT_DEFAULT,
task_name IN VARCHAR2 := NULL,
description IN VARCHAR2 := NULL)
RETURN VARCHAR2;
其参数解释如下:
| Parameter | Description |
|---|---|
sql_text | 指定 SQL 语句的文本 |
begin_snap | 指定开始快照标识符 |
end_snap | 指定结束快照标识符 |
sql_id | 指定 SQL 语句的标识符 |
bind_list | 定义 ANYDATA 类型的绑定值的有序列表。注意:备用数据库不支持此参数 |
plan_hash_value | 指定SQL 执行计划的哈希值 |
sqlset_name | 指定 SQL 调优集名称 |
basic_filter | 指定用于从 SQL 调优集中过滤 SQL 的谓词 |
object_filter | 指定对象过滤器 |
rank(i) | 在选定的 SQL 语句上指定 ORDER BY 子句 |
result_percentage | 指定排名度量总和的百分比 |
result_limit | 指定过滤或排序的 SQL 中排名靠前的 Limit SQL |
user_name | 指定要为其调优语句的用户名 |
scope | 指定调优范围: LIMITED:SQL Tuning Advisor 根据统计检查、访问路径分析和 SQL 结构分析生成建议。未生成 SQL 配置文件建议。COMPREHENSIVE:SQL Tuning Advisor 执行它在有限范围内执行的所有分析以及 SQL 分析 |
time_limit | 指定调优会话的最长持续时间(以秒为单位) |
task_name | 指定可选的调优任务名称 |
description | 提供 SQL 调优会话的描述,最多 256 个字符 |
plan_filter | 指定计划过滤器。当多个计划(plan_hash_value)与同一个语句关联时适用。此过滤器仅允许选择一个计划 (plan_hash_value)。可能的值如下: |
- LAST_GENERATED:最近的时间戳
- FIRST_GENERATED:最早的时间戳,与LAST_GENERATED相反
- LAST_LOADED:最近的first_load_time统计信息
- FIRST_LOADED:最早的first_load_time统计信息,与LAST_LOADED相反
- MAX_ELAPSED_TIME:最大运行时间
- MAX_BUFFER_GETS:最大缓冲区获取
- MAX_DISK_READS:最大磁盘读取
- MAX_DIRECT_WRITES:最大直接写入
- MAX_OPTIMIZER_COST:最大优化器成本
sqlset_owner | 指定 SQL 调优集的所有者,或者为当前模式所有者指定 NULL |
|---|---|
spa_task_name | 指定要调优其回归的 SQL 性能分析器任务的名称 |
spa_task_owner | 指定指定 SQL 性能分析器任务的所有者或当前用户的 NULL |
spa_compare_exec | 指定 SQL 性能分析器任务的比较性能试验的执行名称。如果为 NULL,则顾问程序使用最近执行的给定 SQL 性能分析器任务,类型为 COMPARE PERFORMANCE |
dbid | 指定导入的或 PDB 级 AWR 数据的 DBID。如果为 NULL,则使用当前数据库 DBID |
| con_name | 指定调优任务的容器。语义取决于函数格式 如下: |
- 对于 SQL 文本格式,此参数指定 SQL Tuning Advisor 在其中调优 SQL 语句的容器。如果为 null(默认),则 SQL Tuning Advisor 使用当前容器
- 对于SQL ID 格式,该参数指定数据库从哪个容器中获取SQL 语句进行调优。SQL Tuning Advisor 调优此容器中的语句。如果为 null,则数据库使用当前 PDB 进行调优,从执行 SQL 语句的所有有效容器的游标缓存中获取语句,并调优其容器中最昂贵的语句
- 对于 AWR 格式,此参数指定数据库从其 AWR 数据中提取 SQL 语句以进行调优的容器。SQL Tuning Advisor 调优此容器中的语句。如果为空,则数据库使用当前 PDB 进行调优,从所有具有此 SQL 语句的有效容器的 AWR 中获取语句,并调优其容器中最昂贵的语句
以下陈述适用于所有函数格式:
- 在非 CDB 中,忽略此参数
- 在 PDB 中,此参数必须为 null 或与 PDB 的容器名称匹配。否则,会发生错误
- 在 CDB 根中,此参数必须为 null 或匹配此 CDB 中容器的容器名称。否则,会发生错误
database_link_to | 该链接指定与主数据库的连接。默认情况下,该值为空,这意味着 SQL Tuning Advisor 会话是本地的。使用 DBMS_SQLTUNE 调优在 Active Data Guard 场景中运行在备用数据库上的高负载 SQL 语句。当你在备库本地执行REPORT_TUNING_TASK时,该函数使用数据库链接从主库获取数据,然后在备库本地构建。database_link_to 参数必须指定私有数据库链接。此链接必须由 SYS 拥有并由默认特权用户 SYS$UMF 访问。以下示例语句创建一个名为 lnk_to_pri 的链接:CREATE DATABASE LINK lnk_to_pri CONNECT TO SYS$UMF IDENTIFIED BY password USING ‘inst1’; |
|---|
其返回值为:用户唯一的 SQL 调优任务名称(两个不同的用户可以为他们的顾问任务指定相同的名称)。
注意事项:关于采用 SQL 调优集的此子程序的形式,提供给此函数的过滤器将作为当前用户运行的 SQL 的一部分进行评估。因此,它们以该用户的安全权限执行,并且可以包含用户可以访问的任何构造和子查询,但仅此而已。
其使用案例如下:
-- 以下示例假定以下变量定义:
VARIABLE stmt_task VARCHAR2(64);
VARIABLE sts_task VARCHAR2(64);
VARIABLE spa_tune_task VARCHAR2(64);
-- 使用 SQL 文本格式创建调优任务
EXEC :stmt_task := DBMS_SQLTUNE.CREATE_TUNING_TASK( -
sql_text => 'SELECT quantity_sold FROM sales s, times t WHERE s.time_id = t.time_id AND s.time_id = TO_DATE(''24-NOV-00'')');
-- 使用 SQL ID 格式创建调优任务
EXEC :stmt_task := DBMS_SQLTUNE.CREATE_TUNING_TASK(sql_id => 'ay1m3ssvtrh24');
EXEC :stmt_task := DBMS_SQLTUNE.CREATE_TUNING_TASK(sql_id => 'ay1m3ssvtrh24', -
scope => 'LIMITED');
EXEC :stmt_task := DBMS_SQLTUNE.CREATE_TUNING_TASK(sql_id => 'ay1m3ssvtrh24', -
time_limit => 600);
-- 使用 AWR 快照格式创建调优任务
EXEC :stmt_task := DBMS_SQLTUNE.CREATE_TUNING_TASK(begin_snap => 1, -
end_snap => 2, sql_id => 'ay1m3ssvtrh24');
-- 使用 SQL 调优集格式创建调优任务
-- 此示例创建一个任务,该任务按缓冲区获取的顺序调优 SQL 语句,并设置一小时的时间限制。默认排名度量是 elapsed time
EXEC :sts_task := DBMS_SQLTUNE.CREATE_TUNING_TASK( -
sqlset_name => 'my_workload', -
rank1 => 'BUFFER_GETS', -
time_limit => 3600, -
description => 'tune my workload ordered by buffer gets');
-- 使用 SPA 任务格式创建调优任务
-- 此示例调优被报告为已从名为 task_123 的 SQL 性能分析器任务的比较性能执行中退化的 SQL 语句
EXEC :spa_tune_task := DBMS_SQLTUNE.CREATE_TUNING_TASK(
spa_task_name => 'task_123',
spa_task_owner => 'SCOTT',
spa_compare_exec => 'exec1');
-- 在备库上创建 SQL 调优任务
-- 此示例在备用数据库上创建调优任务。tune_stby_wkld 任务使用 lnk_to_primary 数据库链接将数据写入打开读/写的主数据库
VAR tname VARCHAR2(30);
VAR query VARCHAR2(500);
EXEC :tname := 'tune_stby_wkld';
EXEC :query := 'SELECT /*+ FULL(t)*/ col1 FROM table1 t WHERE col1=9000';
EXEC :tname := DBMS_SQLTUNE.CREATE_TUNING_TASK(sql_text => :query,-
task_name => :tname, database_link_to => 'lnk_to_primary');
DELETE_SQLSET Procedure
此过程从 SQL 调优集中删除一组 SQL 语句。其语法格式如下:
DBMS_SQLTUNE.DELETE_SQLSET (
sqlset_name IN VARCHAR2,
basic_filter IN VARCHAR2 := NULL,
sqlset_owner IN VARCHAR2 := NULL);
其参数解释如下:
| Parameter | Description |
|---|---|
sqlset_name | 指定 SQL 调优集的名称 |
basic_filter | 指定用于从 SQL 调优集中过滤 SQL 的 SQL 谓词。此基本过滤器用作 SQL 调优集内容的 where 子句,以从 SQL 调优集中选择所需的 SQL 子集 |
sqlset_owner | 指定 SQL 调优集的所有者,或者为当前模式所有者指定 NULL |
其使用案例如下:
-- Delete all statements in a sql tuning set.
EXEC DBMS_SQLTUNE.DELETE_SQLSET(sqlset_name => 'my_workload');
-- Delete all statements in a sql tuning set which ran for less than a second
EXEC DBMS_SQLTUNE.DELETE_SQLSET(sqlset_name => 'my_workload', -
basic_filter => 'elapsed_time < 1000000');
DROP_SQL_PROFILE Procedure
此过程从数据库中删除指定的 SQL 配置文件。其语法格式如下:
DBMS_SQLTUNE.DROP_SQL_PROFILE (
name IN VARCHAR2,
ignore IN BOOLEAN := FALSE);
其参数解释如下:
| Parameter | Description |
|---|---|
name | 要删除的 SQL 配置文件的(强制)名称。名称区分大小写 |
ignore | 忽略由于对象不存在而导致的错误 |
注意事项:需要 DROP ANY SQL PROFILE 权限。
其使用案例如下:
-- Drop the profile:
EXEC DBMS_SQLTUNE.DROP_SQL_PROFILE(:pname);
DROP_SQLSET Procedure
如果 SQL 调优集不活动,则此过程会删除它。其语法格式如下:
DBMS_SQLTUNE.DROP_SQLSET (
sqlset_name IN VARCHAR2,
sqlset_owner IN VARCHAR2 := NULL);
其参数解释如下:
| Parameter | Description |
|---|---|
sqlset_name | 指定 SQL 调优集的名称 |
sqlset_owner | 指定 SQL 调优集的所有者,或者为当前模式所有者指定 NULL |
注意事项:当一个或多个客户端引用 SQL 调优集时,您不能删除它。
其使用案例如下:
-- Drop the sqlset.
EXEC DBMS_SQLTUNE.DROP_SQLSET ('my_workload');
DROP_TUNING_TASK Procedure
此过程删除 SQL 调优任务。任务及其所有结果数据将被删除。其语法格式如下:
DBMS_SQLTUNE.DROP_TUNING_TASK (
task_name IN VARCHAR2);
其参数解释如下:
| Parameter | Description |
|---|---|
task_name | 指定要删除的调优任务的名称 |
EXECUTE_TUNING_TASK Function and Procedure
此函数和过程执行先前创建的调优任务。函数和过程都在新任务执行的上下文中运行。区别在于函数版本返回新的执行名称。其语法格式如下:
DBMS_SQLTUNE.EXECUTE_TUNING_TASK (
task_name IN VARCHAR2,
execution_name IN VARCHAR2 := NULL,
execution_params IN dbms_advisor.argList := NULL,
execution_desc IN VARCHAR2 := NULL,
database_link_to IN VARCHAR2 := NULL)
RETURN VARCHAR2;
DBMS_SQLTUNE.EXECUTE_TUNING_TASK (
task_name IN VARCHAR2,
execution_name IN VARCHAR2 := NULL,
execution_params IN dbms_advisor.argList := NULL,
execution_desc IN VARCHAR2 := NULL,
database_link_to IN VARCHAR2 := NULL);
其参数解释如下:
| Parameter | Description |
|---|---|
task_name | 要执行的调优任务的名称 |
execution_name | 限定和标识执行的名称。如果未指定,则由顾问生成并由函数返回 |
execution_params | 指定执行的参数列表(名称、值)。执行参数仅对指定它们的执行有效。它们覆盖存储在任务中的参数值(通过 SET_TUNING_TASK_PARAMETER 过程设置) |
execution_desc | 描述执行的 256 长字符串 |
database_link_to | 备用数据库上存在的数据库链接的名称。该链接指定与主数据库的连接。默认情况下,该值为空,这意味着 SQL Tuning Advisor 会话是本地的。使用 DBMS_SQLTUNE 调优在 Active Data Guard 场景中运行在备用数据库上的高负载 SQL 语句。当你在备库本地执行REPORT_TUNING_TASK时,该函数使用数据库链接从主库获取数据,然后在备库本地构建。database_link_to 参数必须指定私有数据库链接。此链接必须由 SYS 拥有并由默认特权用户 SYS$UMF 访问。以下示例语句创建一个名为 lnk_to_pri 的链接:CREATE DATABASE LINK lnk_to_pri CONNECT TO SYS$UMF IDENTIFIED BY password USING ‘inst1’; |
注意事项:调优任务可以执行多次而无需重新设置。
其使用案例如下:
EXEC DBMS_SQLTUNE.EXECUTE_TUNING_TASK(:stmt_task);
IMPLEMENT_TUNING_TASK Procedure
此过程实施 SQL Tuning Advisor 提出的一组 SQL 配置文件建议。执行 IMPLEMENT_TUNING_TASK 相当于执行了 SCRIPT_TUNING_TASK Function,然后运行脚本。其语法格式如下:
DBMS_SQLTUNE.IMPLEMENT_TUNING_TASK(
task_name IN VARCHAR2,
rec_type IN VARCHAR2 := REC_TYPE_SQL_PROFILES,
owner_name IN VARCHAR2 := NULL,
execution_name IN VARCHAR2 := NULL,
database_link_to IN VARCHAR2 := NULL);
其参数解释如下:
| Parameter | Description |
|---|---|
task_name | 要为其实施建议的调优任务的名称 |
rec_type | 筛选要实施的建议类型。 仅支持 PROFILES |
owner_name | 相关调优任务的所有者或当前用户的 NULL |
execution_name | 要使用的任务执行的名称。如果为 NULL,则该过程实施上次任务执行时的建议 |
database_link_to | 备用数据库上存在的数据库链接的名称。该链接指定与主数据库的连接。默认情况下,该值为空,这意味着 SQL Tuning Advisor 会话是本地的。使用 DBMS_SQLTUNE 调优在 Active Data Guard 场景中运行在备用数据库上的高负载 SQL 语句。当你在备库本地执行REPORT_TUNING_TASK时,该函数使用数据库链接从主库获取数据,然后在备库本地构建。database_link_to 参数必须指定私有数据库链接。此链接必须由 SYS 拥有并由默认特权用户 SYS$UMF 访问。 以下示例语句创建一个名为 lnk_to_pri 的链接:CREATE DATABASE LINK lnk_to_pri CONNECT TO SYS$UMF IDENTIFIED BY password USING ‘inst1’; |
INTERRUPT_TUNING_TASK Procedure
此过程会中断当前正在执行的调优任务。任务像正常退出时一样结束其操作,以便用户可以访问中间结果。其语法格式如下:
DBMS_SQLTUNE.INTERRUPT_TUNING_TASK (
task_name IN VARCHAR2);
其参数解释如下:
| Parameter | Description |
|---|---|
task_name | 要中断的调优任务的名称 |
其使用案例如下:
EXEC DBMS_SQLTUNE.INTERRUPT_TUNING_TASK(:my_task);
LOAD_SQLSET Procedure
此过程使用一组选定的 SQL 语句填充 SQL 调优集。您可以多次调用该过程以添加新的 SQL 语句或替换现有语句的属性。其语法格式如下:
DBMS_SQLTUNE.LOAD_SQLSET (
sqlset_name IN VARCHAR2,
populate_cursor IN sqlset_cursor,
load_option IN VARCHAR2 := 'INSERT',
update_option IN VARCHAR2 := 'REPLACE',
update_condition IN VARCHAR2 := NULL,
update_attributes IN VARCHAR2 := NULL,
ignore_null IN BOOLEAN := TRUE,
commit_rows IN POSITIVE := NULL,
sqlset_owner IN VARCHAR2 := NULL);
其参数解释如下:
| Parameter | Description |
|---|---|
sqlset_name | 指定要加载的 SQL 调优集的名称 |
populate_cursor | 指定对要加载的 SQL 调优集的游标引用 |
load_option | 指定将哪些语句加载到 SQL 调优集中。可能的值是: INSERT(默认值)— 仅添加新语句。UPDATE — 更新现有的 SQL 语句并忽略任何新语句。MERGE——插入新语句并更新现有语句的信息 |
update_option | 指定现有 SQL 语句的更新方式。仅当使用 UPDATE 或 MERGE 作为选项指定 load_option 时才考虑此参数。可能的值有: REPLACE(默认值)— 使用新统计信息、绑定列表、对象列表等更新语句。ACCUMULATE — 尽可能合并属性(例如,elapsed_time 等统计信息),否则用提供的值替换现有值(例如,模块和操作)。可以累加的SQL语句属性有:elapsed_time、buffer_gets、direct_writes、disk_reads、row_processed、fetches、executions、end_of_fetch_count、stat_period和active_stat_period |
update_condition | 指定何时执行更新。该过程仅在满足指定条件时执行更新。条件可以指数据源或目标。条件必须使用以下前缀来引用源或目标中的属性:OLD — 引用 SQL 调优集(目标)中的语句属性。NEW — 指的是输入语句(来源)中的语句属性 |
update_attributes | 指定在合并或更新期间要更新的 SQL 语句属性列表。详细说明如下 |
ignore_null | 指定当新值为 NULL 时是否更新属性。如果为 TRUE,则当新值为 NULL 时过程不会更新属性。也就是说,除非有意,否则不要使用 NULL 值覆盖 |
commit_rows | 指定是否在 DML 之后提交语句。如果提供了值,则在插入每个指定数量的语句后加载提交。如果提供 NULL,则加载仅在操作结束时提交一次。为此参数提供一个值使您能够在 DBA_SQLSET 视图中监视 SQL 调优集加载操作的进度。STATEMENT_COUNT 值随着新 SQL 语句的加载而增加 |
sqlset_owner | 定义 SQL 调优集的所有者,或当前模式所有者(或当前所有者为 NULL) |
update_attributes 可能的值是:
- NULL(默认)— 指定输入游标的内容,执行上下文除外。换句话说,它相当于没有模块和动作等执行上下文的ALL
- BASIC — 仅指定统计信息和绑定
- TYPICAL — 指定带有 SQL 计划(没有行源统计信息)并且没有对象引用列表的 BASIC
- ALL — 指定所有属性,包括执行上下文属性,例如模块和操作
- 要更新的逗号分隔属性名称列表:
EXECUTION_CONTEXTEXECUTION_STATISTICS- SQL_BINDS
SQL_PLAN- SQL_PLAN_STATISTICS(类似于添加了行源统计信息的 SQL_PLAN)
例外情况:
- 当 sqlset_name 无效,或相应的 SQL 调优集不存在,或 populate_cursor 不正确而无法执行时,此过程将返回错误
- 提供无效过滤器时也会引发异常。过滤器可能无效,因为它们不解析(例如,它们引用不在 sqlset_row 中的属性),或者因为它们违反了用户的权限
注意事项:输入 populate_cursor 中的行必须是 SQLSET_ROW 类型。
其使用案例如下:
在此示例中,您使用所有共享 SQL 区域语句创建并填充一个 SQL 调优集,其中经过时间为 5 秒或更长时间的语句不包括属于 SYS 模式的语句(以模拟应用程序用户工作负载)。您选择 SQL 语句的所有属性并使用默认模式将它们加载到调优集中,该模式仅加载新语句,因为 SQL 调优集是空的。
-- create the tuning set
EXEC DBMS_SQLTUNE.CREATE_SQLSET('my_workload');
-- populate the tuning set from the shared SQL area
DECLARE
cur DBMS_SQLTUNE.SQLSET_CURSOR;
BEGIN
OPEN cur FOR
SELECT VALUE(P)
FROM table(
DBMS_SQLTUNE.SELECT_CURSOR_CACHE(
'parsing_schema_name <> ''SYS'' AND elapsed_time > 5000000',
NULL, NULL, NULL, NULL, 1, NULL,
'ALL')) P;
DBMS_SQLTUNE.LOAD_SQLSET(sqlset_name => 'my_workload', populate_cursor => cur);
END;
/
假设现在您希望使用工作负载存储库 (AWR) 中存储的信息来扩充此信息。您使用ACCUMULATE作为您的 update_option 填充调优集,因为假定当前在缓存中的游标自拍摄快照以来已经老化。
您省略了 elapsed_time 过滤器,因为假定在 AWR 中捕获的任何语句都很重要,但您仍然丢弃了 SYS 解析的游标以避免递归 SQL。
DECLARE
cur DBMS_SQLTUNE.SQLSET_CURSOR;
BEGIN
OPEN cur FOR
SELECT VALUE(P)
FROM table(
DBMS_SQLTUNE.SELECT_WORKLOAD_REPOSITORY(1,2,
'parsing_schema_name <> ''SYS''',
NULL, NULL,NULL,NULL,
1,
NULL,
'ALL')) P;
DBMS_SQLTUNE.LOAD_SQLSET(sqlset_name => 'my_workload',
populate_cursor => cur,
Using DBMS_SQLTUNE
load_option => 'MERGE',
update_option => 'ACCUMULATE');
END;
以下示例是一个简单的加载,它仅从工作负载存储库中插入新语句,跳过现有语句(在 SQL 调优集中)。请注意,INSERT是 LOAD_SQLSET 过程的 load_option 参数的默认值。
DECLARE
cur sys_refcursor;
BEGIN
OPEN cur FOR
SELECT VALUE(P)
FROM table(DBMS_SQLTUNE.SELECT_WORKLOAD_REPOSITORY(1,2)) P;
DBMS_SQLTUNE.LOAD_SQLSET(sqlset_name => 'my_workload', populate_cursor => cur);
END;
/
下一个示例演示了使用 UPDATE 选项进行加载。这会更新 SQL 调优集中已存在的语句,但不会添加新语句。默认情况下,旧统计信息会被新值替换。
DECLARE
cur sys_refcursor;
BEGIN
OPEN cur FOR
SELECT VALUE(P)
FROM table(DBMS_SQLTUNE.SELECT_CURSOR_CACHE) P;
DBMS_SQLTUNE.LOAD_SQLSET(sqlset_name => 'my_workload',
populate_cursor => cur,
load_option => 'UPDATE');
END;
/
PACK_STGTAB_SQLPROF Procedure
此过程从 SYS 复制配置文件数据。 模式到临时表中。其语法格式如下:
DBMS_SQLTUNE.PACK_STGTAB_SQLPROF (
profile_name IN VARCHAR2 := '%',
profile_category IN VARCHAR2 := 'DEFAULT',
staging_table_name IN VARCHAR2,
staging_schema_owner IN VARCHAR2 := NULL);
其参数解释如下:
| Parameter | Description |
|---|---|
profile_name | 要打包的配置文件的名称(% 可接受通配符,区分大小写) |
profile_category | 从中打包配置文件的类别(% 可接受通配符,区分大小写) |
staging_table_name | 要使用的表的名称(不区分大小写,除非双引号)。 必需的 |
staging_schema_owner | 表所在的模式,或当前模式的 NULL(不区分大小写,除非双引号) |
安全模型:此过程需要对暂存表具有 ADMINISTER SQL MANAGEMENT OBJECT 特权和 INSERT 特权。
使用说明:此函数在打包每个 SQL 配置文件后发出 COMMIT。如果在执行过程中出现错误,则通过删除其行来清除staging表。
其使用案例如下:
仅将 DEFAULT 类别中的那些配置文件放入暂存表。这对应于该系统默认使用的所有配置文件。
EXEC DBMS_SQLTUNE.PACK_STGTAB_SQLPROF (staging_table_name => 'PROFILE_STGTAB');
这是将所有配置文件放入暂存表的另一个示例。请注意,这会移动当前默认情况下未使用但属于其他类别的配置文件,例如用于测试目的。
EXEC DBMS_SQLTUNE.PACK_STGTAB_SQLPROF (profile_category => '%', -
staging_table_name => 'PROFILE_STGTAB');
PACK_STGTAB_SQLSET Procedure
此过程将一个或多个 SQL 调优集从它们在 SYS 模式中的位置复制到由 CREATE_STGTAB_SQLSET 过程创建的暂存表。其语法格式如下:
DBMS_SQLTUNE.PACK_STGTAB_SQLSET (
sqlset_name IN VARCHAR2,
sqlset_owner IN VARCHAR2 := NULL,
staging_table_name IN VARCHAR2,
staging_schema_owner IN VARCHAR2 := NULL,
db_version IN NUMBER := NULL);
其使用案例如下:
-- 将数据库上的所有 SQL 调优集放在暂存表中:
BEGIN
DBMS_SQLTUNE.PACK_STGTAB_SQLSET(
sqlset_name => '%'
, sqlset_owner => '%'
, staging_table_name => 'STGTAB_SQLSET');
END;
-- 仅将当前用户拥有的那些 SQL 调优集放在暂存表中:
BEGIN
DBMS_SQLTUNE.PACK_STGTAB_SQLSET(
sqlset_name => '%'
, staging_table_name => 'STGTAB_SQLSET');
END;
-- 打包特定的 SQL 调优集:
BEGIN
DBMS_SQLTUNE.PACK_STGTAB_SQLSET(
sqlset_name => 'my_workload'
, staging_table_name => 'STGTAB_SQLSET');
END;
-- 打包第二个 SQL 调优集:
BEGIN
DBMS_SQLTUNE.PACK_STGTAB_SQLSET(
sqlset_name => 'workload_subset'
, staging_table_name => 'STGTAB_SQLSET');
END;
-- 将 STS my_workload_subset 打包到为 Oracle Database 11g 第 1 版 (11.2) 创建的暂存表 stgtab_sqlset 中:
BEGIN
DBMS_SQLTUNE.PACK_STGTAB_SQLSET(
sqlset_name => 'workload_subset'
, staging_table_name => 'STGTAB_SQLSET'
, db_version => DBMS_SQLTUNE.STS_STGTAB_11_2_VERSION);
END;
REMAP_STGTAB_SQLPROF Procedure
此过程会在执行解包操作之前更改暂存表中保存的配置文件数据值。
您可以使用此过程来更改配置文件的类别。如果系统上已存在同名配置文件,您还可以使用它来更改配置文件的名称。其语法格式如下:
DBMS_SQLTUNE.REMAP_STGTAB_SQLPROF (
old_profile_name IN VARCHAR2,
new_profile_name IN VARCHAR2 := NULL,
new_profile_category IN VARCHAR2 := NULL,
staging_table_name IN VARCHAR2,
staging_schema_owner IN VARCHAR2 := NULL);
其参数解释如下:
| Parameter | Description |
|---|---|
old_profile_name | 重新映射操作的目标配置文件的名称(区分大小写) |
new_profile_name | 配置文件的新名称,或 NULL 保持不变(区分大小写) |
new_profile_category | 配置文件的新类别,或 NULL 保持不变(区分大小写) |
staging_table_name | 对其执行重新映射操作的表的名称(区分大小写)。必需的 |
staging_schema_owner | 表所在的模式,或当前模式的 NULL(区分大小写) |
安全模型:此过程需要临时表的更新权限。
其使用案例如下:
-- 在我们解压缩之前更改配置文件的名称,以避免冲突
BEGIN
DBMS_SQLTUNE.REMAP_STGTAB_SQLPROF(
old_profile_name => :pname
, new_profile_name => 'IMP' || :pname
, staging_table_name => 'PROFILE_STGTAB');
END;
-- 在我们导入它之前,将暂存表中的 SQL 配置文件更改为“TEST”类别。 这样用户就可以在新系统激活之前测试配置文件
BEGIN
DBMS_SQLTUNE.REMAP_STGTAB_SQLPROF(
old_profile_name => :pname
, new_profile_category => 'TEST'
, staging_table_name => 'PROFILE_STGTAB');
END;
REMAP_STGTAB_SQLSET Procedure
此过程更改暂存表中的调优集名称和所有者,以便它们可以用不同的值解包。其语法格式如下:
DBMS_SQLTUNE.REMAP_STGTAB_SQLSET (
old_sqlset_name IN VARCHAR2,
old_sqlset_owner IN VARCHAR2 := NULL,
new_sqlset_name IN VARCHAR2 := NULL,
new_sqlset_owner IN VARCHAR2 := NULL,
staging_table_name IN VARCHAR2,
staging_schema_owner IN VARCHAR2 := NULL
old_con_dbid IN NUMBER := NULL,
new_con_dbid IN NUMBER := NULL);
);
注:DBMS_SQLTUNE.REMAP_STGTAB_SQLSET 和 DBMS_SQLSET.REMAP_SQLSET 过程的参数相同。
其参数解释如下:
| Parameter | Description |
|---|---|
old_sqlset_name | 将调优集的名称指定为重新映射操作的目标。不支持通配符 (%) |
old_sqlset_owner | 指定要作为重映射操作目标的调优集所有者的新名称。当前模式所有者为 NULL |
new_sqlset_name | 指定调优集的新名称,或 NULL 以保持相同的调优集名称 |
new_sqlset_owner | 指定调优集的新所有者,或 NULL 以保持相同的所有者名称 |
staging_table_name | 指定要对其执行重映射操作的表的名称。该值区分大小写 |
staging_schema_owner | 指定暂存表所有者的名称,或者为当前模式所有者指定 NULL。该值区分大小写 |
old_con_dbid | 指定要重新映射到新容器 DBID 的旧容器 DBID。指定 NULL 以使用相同的容器 DBID。您必须同时提供 old_con_dbid 和 new_con_dbid 才能使重新映射成功 |
new_con_dbid | 指定要替换为旧容器 DBID 的新容器 DBID。指定 NULL 以使用相同的容器 DBID。您必须同时提供 old_con_dbid 和 new_con_dbid 才能使重新映射成功 |
注:多次调用此过程以重新映射多个调优集名称或所有者。此过程每次调用仅处理一个调优集。
其使用案例如下:
-- Change the name of an STS in the staging table before unpacking it.
-- 解包前更改暂存表中 STS 的名称
BEGIN
DBMS_SQLTUNE.REMAP_STGTAB_SQLSET(
old_sqlset_name => 'my_workload'
, old_sqlset_owner => 'SH'
, new_sqlset_name => 'imp_workload'
, staging_table_name => 'STGTAB_SQLSET');
-- Change the owner of an STS in the staging table before unpacking it.
-- 在解包之前更改暂存表中 STS 的所有者
DBMS_SQLTUNE.REMAP_STGTAB_SQLSET(
old_sqlset_name => 'imp_workload'
, old_sqlset_owner => 'SH'
, new_sqlset_owner => 'SYS'
, staging_table_name => 'STGTAB_SQLSET');
END;
REMOVE_SQLSET_REFERENCE Procedure
此过程停用 SQL 调优集以指示客户端不再使用它。其语法格式如下:
DBMS_SQLTUNE.REMOVE_SQLSET_REFERENCE (
sqlset_name IN VARCHAR2,
reference_id IN NUMBER,
sqlset_owner IN VARCHAR2 := NULL,
force_remove IN NUMBER := 0);
注:DBMS_SQLTUNE.REMOVE_SQLSET_REFERENCE 和 DBMS_SQLSET.REMOVE_REFERENCE 过程的参数相同。
其参数解释如下:
| Parameter | Description |
|---|---|
sqlset_name | 指定 SQL 调优集的名称 |
reference_id | 指定要删除的引用的标识符 |
sqlset_owner | 指定 SQL 调优集的所有者(或 NULL 表示当前模式所有者) |
force_remove | 指定是否可以为其他用户删除引用 (1) 或是否不能删除 (0)。将此参数设置为 1 仅在用户具有 ADMINISTER ANY SQL TUNING SET 权限时生效。否则,数据库只会删除用户拥有的引用 |
其使用案例如下:
-- 当您使用完给定的 SQL 调优集并希望使其再次可写时,您可以删除对它的引用。 以下示例删除对 my_workload 的引用:
EXEC DBMS_SQLTUNE.REMOVE_SQLSET_REFERENCE( -
sqlset_name => 'my_workload', -
reference_id => :rid,
sqlset_owner => NULL,
force_remove => 0);
-- 要查找对给定 SQL 调优集的所有引用,请查询 DBA_SQLSET_REFERENCES 视图。
REPORT_AUTO_TUNING_TASK Function
此函数显示来自自动调优任务的报告。
此函数报告一系列任务执行,而 REPORT_TUNING_TASK 函数报告单个执行。请注意,Oracle 数据库 11g 第 2 版 (11.2) 已弃用此函数,取而代之的是 DBMS_AUTO_SQLTUNE.REPORT_AUTO_TUNING_TASK。其语法格式如下:
DBMS_SQLTUNE.REPORT_AUTO_TUNING_TASK(
begin_exec IN VARCHAR2 := NULL,
end_exec IN VARCHAR2 := NULL,
type IN VARCHAR2 := TYPE_TEXT,
level IN VARCHAR2 := LEVEL_TYPICAL,
section IN VARCHAR2 := SECTION_ALL,
object_id IN NUMBER := NULL,
result_limit IN NUMBER := NULL)
RETURN CLOB;
其参数解释如下:
| Parameter | Description |
|---|---|
begin_exec | 指定从中开始报告的执行的名称。NULL 检索有关最近运行的报告 |
end_exec | 指定结束报告的执行名称。NULL 检索有关最近运行的报告 |
type | 指定要生成的报告的类型。可能的值是产生文本报告的 TYPE_TEXT |
level | 指定报告中的详细程度:LEVEL_BASIC:报告的简单版本。仅显示有关顾问采取的操作的信息。LEVEL_TYPICAL:显示有关每个已分析语句的信息,包括未实现的请求。LEVEL_ALL:高度详细的报告级别,还提供有关跳过的语句的注释 |
section | 将报告限制为单个部分(所有部分为 ALL):SECTION_SUMMARY - 摘要信息; SECTION_FINDINGS - 调优结果; SECTION_PLAN - 解释计划; SECTION_INFORMATION - 一般信息; SECTION_ERROR - 有错误的陈述; SECTION_ALL - 所有语句 |
object_id | 指定表示要限制报告的单个语句的顾问框架对象 ID。为所有语句指定 NULL。仅对针对单次执行的报告有效 |
result_limit | 指定要在报告中显示的 SQL 语句的最大数量 |
其返回值为:包含所需报告的 CLOB。
REPORT_SQL_DETAIL Function
此函数为特定 SQLID 构建报告。对于每个 SQLID,它提供从 V$ 视图和 AWR 获得的各种统计信息和详细信息。其语法格式如下:
DBMS_SQLTUNE.REPORT_SQL_DETAIL (
sql_id IN VARCHAR2 DEFAULT NULL,
sql_plan_hash_value IN NUMBER DEFAULT NULL,
start_time IN DATE DEFAULT NULL,
duration IN NUMBER DEFAULT NULL,
inst_id IN NUMBER DEFAULT NULL,
dbid IN NUMBER DEFAULT NULL,
event_detail IN VARCHAR2 DEFAULT 'YES',
bucket_max_count IN NUMBER DEFAULT 128,
bucket_interval IN NUMBER DEFAULT NULL,
top_n IN NUMBER DEFAULT 10,
report_level IN VARCHAR2 DEFAULT 'TYPICAL',
type IN VARCHAR2 DEFAULT 'ACTIVE',
data_source IN VARCHAR2 DEFAULT 'AUTO',
end_time IN DATE DEFAULT NULL,
duration_stats IN NUMBER DEFAULT NULL,
con_name IN VARCHAR2 DEFAULT NULL)
RETURN CLOB;
其参数解释如下:
| Parameter | Description |
|---|---|
sql_id | 需要显示监控信息的SQLID。如果为 NULL(默认值),则显示在当前会话中执行的最后一条 SQL 语句的 SQLID 的统计信息 |
sql_plan_hash_value | 显示特定 plan_hash_value 的 SQL 统计信息和详细信息。如果为 NULL(默认值),则显示 SQL_ID 的所有计划的统计信息和详细信息 |
start_time | 如果指定,则显示此时开始的 SQL 活动(来自 GV$ACTIVE_SESSION_HISTORY)。在 Oracle RAC 上,最小 start_time 是所有实例中内存中 ASH 缓冲区的最早 sample_time。如果为 NULL(默认),则为当前时间前一小时 |
duration | 报告的活动持续时间(以秒为单位)。如果为 NULL(默认),则使用 1 小时的值 |
inst_id | 从中获取 SQL 详细信息的目标实例。如果为 NULL,则使用来自所有实例的数据。如果为 0 或 -1,则使用当前实例 |
dbid | 从中获取 SQL 详细信息的 DBID。如果为 NULL,则使用当前 DBID |
event_detail | 当设置为NO时,活动仅由 wait_class 聚合。使用YES(默认值)按(wait_class,event_name)聚合 |
bucket_max_count | 如果指定,这应该是报告中创建的直方图桶的最大数量。如果未指定,则使用值 128 |
bucket_interval | 如果指定,这表示所有直方图桶的确切时间间隔(以秒为单位)。如果指定,bucket_max_count 将被忽略 |
top_n | 控制顶部维度部分中每个维度显示的条目数。如果未指定,则使用默认值 10 |
report_level | 参数解释如下 |
报告的详细程度,'BASIC','TYPICAL'or 'ALL'。 默认假定为“典型”。它们的含义解释如下。此外,还可以使用a +/- *section_name*启用或禁用各个报告部分。定义了几个部分:
- ‘TOP’- 显示 SQL 语句的 ASH 维度的最高值;默认开启
- ‘SPM’- 显示 SQL 语句的现有计划基线;默认关闭
- ‘MISMATCH’- 显示创建新子游标的原因(违反共享标准);默认关闭。
- ‘STATS’- 显示来自
GV$SQLAREA_PLAN_HASH的每个计划的 SQL 执行统计信息;默认开启 - ‘ACTIVITY’ - 显示来自 ASH 的每个 SQL 语句计划的最高活动;默认开启
- ‘ACTIVITY_ALL’ - 显示 ASH 中 SQL 语句计划的每一行的最高活动;默认关闭
- ‘HISTOGRAM’ - 显示 SQL 语句的每个计划的活动直方图(计划时间线直方图);默认开启
- ‘SESSIONS’ - 显示每个 SQL 语句计划的顶级会话的活动;默认关闭
- ‘MONITOR’ - 显示每个执行计划显示一个受监控的 SQL 执行;默认开启
- ‘XPLAN’ - 显示执行计划;默认开启
- ‘BINDS’ - 显示捕获的绑定数据;默认开启
此外,还可以在不同级别指定 SQL 文本:
- -SQL_TEXT - 报告中没有 SQL 文本
- +SQL_TEXT - OK 部分 SQL 文本最多前 2000 个字符存储在
GV$SQL_MONITOR中 - -SQL_FULLTEXT - 没有完整的 SQL 文本 (+SQL_TEXT)
- +SQL_FULLTEXT - 显示完整的 SQL 文本(默认值)
三个顶层报告层级的含义分别是:
- NONE - 最小可能
BASIC- SQL_TEXT+STATS+ACTIVITY+HISTOGRAMTYPICAL- SQL_FULLTEXT+TOP+STATS+ACTIVITY+HISTOGRAM+XPLAN+MONITOR- ALL - 一切
只能指定这 4 个级别中的一个,如果是,它必须位于 REPORT_LEVEL 字符串的开头
type | 报告格式:默认为“ACTIVE”。也可以是“XML”(请参阅使用说明) |
|---|---|
data_source | 根据以下值之一确定SQL数据的数据源: MEMORY:数据源为GV$view;DISK:数据源为DBA_HIST_* view;AUTO:根据时间范围自动确定数据源(默认) |
end_time | 如果指定,则显示从 start_time 到 end_time 的 SQL 活动。如果为 NULL(默认值),则显示 systimestamp 的 SQL 活动 |
duration_stats | 来自 AWR 的附加 SQL 执行统计数据的持续时间(以小时为单位),用于报告。如果为 NULL(默认值),则考虑 24 小时的持续时间 |
con_name | 多租户容器数据库 (CDB) 的名称 |
安全模型:调用者需要对 DBMS_XPLAN 包的 EXECUTE 特权。
返回值:包含所需报告的 CLOB。
使用说明:
- ACTIVE 报告具有类似于 Enterprise Manager 的丰富的交互式用户界面,同时不需要安装任何 EM。构建的报告文件是 HTML 格式,因此大多数现代浏览器都可以解释它。首次查看报告时,网络浏览器会透明下载支持活动报告的代码,因此查看它需要外部连接
- 调用者需要对以下视图的 SELECT 或 READ 权限:
V$SESSIONDBA_ADVISOR_FINDINGSV$DATABASEGV$ASH_INFOGV$ACTIVE_SESSION_HISTORYGV$SQLAREA_PLAN_HASHGV$SQLDBA_HIST_SNAPSHOTDBA_HIST_WR_CONTROLDBA_HIST_ACTIVE_SESS_HISTORYDBA_HIST_SQLSTATDBA_HIST_SQL_BIND_METADATADBA_HIST_SQLTEXTDBA_SQL_PLAN_BASELINESDBA_SQL_PROFILESDBA_ADVISOR_TASKSDBA_SERVICESDBA_USERSDBA_OBJECTSDBA_PROCEDURES
REPORT_SQL_MONITOR Function
此函数为代表目标语句执行收集的监视信息构建报告(文本、简单 HTML、活动 HTML、XML)。其语法格式如下:
DBMS_SQLTUNE.REPORT_SQL_MONITOR(
sql_id IN VARCHAR2 DEFAULT NULL,
dbop_name IN VARCHAR2 DEFAULT NULL,
dbop_exec_id IN NUMBER DEFAULT NULL,
session_id IN NUMBER DEFAULT NULL,
session_serial IN NUMBER DEFAULT NULL,
sql_exec_start IN DATE DEFAULT NULL,
sql_exec_id IN NUMBER DEFAULT NULL,
inst_id IN NUMBER DEFAULT NULL,
start_time_filter IN DATE DEFAULT NULL,
end_time_filter IN DATE DEFAULT NULL,
instance_id_filter IN NUMBER DEFAULT NULL,
parallel_filter IN VARCHAR2 DEFAULT NULL,
plan_line_filter IN NUMBER DEFAULT NULL,
event_detail IN VARCHAR2 DEFAULT 'YES',
bucket_max_count IN NUMBER DEFAULT 128,
bucket_interval IN NUMBER DEFAULT NULL,
base_path IN VARCHAR2 DEFAULT NULL,
last_refresh_time IN DATE DEFAULT NULL,
report_level IN VARCHAR2 DEFAULT 'TYPICAL',
type IN VARCHAR2 DEFAULT 'TEXT',
sql_plan_hash_value IN NUMBER DEFAULT NULL,
con_name IN VARCHAR2 DEFAULT NULL,
report_id IN NUMBER DEFAULT NULL)
RETURN CLOB;
其参数解释如下:
| Parameter | Description |
|---|---|
sql_id | 需要显示监控信息的SQL_ID。使用 NULL(默认值)报告 Oracle 监视的最后一条语句 |
dbop_name | 显示组合数据库操作监控信息的DBOP_NAME |
dbop_exec_id | 显示监控信息的复合数据库操作的执行标识 |
session_id | 如果不是 NULL,则此参数仅针对指定会话执行的语句子集。默认为 NULL。对当前会话使用 USERENV('SID') |
session_serial | 除了 session_id 参数之外,还可以指定其会话序列以确保所需的会话化身是有针对性的。当 session_id 为 NULL 时忽略此参数 |
sql_exec_start | 此参数与 sql_exec_id 一起仅在还指定了 sql_id 时适用。联合起来,它们可用于显示与 sql_id 标识的语句的任何执行相关的监视信息,假设此语句已被监视。当为 NULL(默认值)时,显示最后监视的 SQL sql_id 执行 |
sql_exec_id | 此参数与 sql_exec_start 一起仅在还指定了 sql_id 时适用。联合起来,它们可用于显示与 sql_id 标识的语句的任何执行相关的监视信息,假设此语句已被监视。当为 NULL(默认值)时,显示最后监视的 SQL sql_id 执行 |
inst_id | 只考虑在指定实例上启动的语句。使用 -1 来定位登录实例。 NULL(默认)针对所有实例 |
start_time_filter | 如果不为 NULL,则报告仅考虑指定日期之后记录的活动(来自 GV$ACTIVE_SESSION_HISTORY)。如果为 NULL,则报告的活动在目标 SQL 语句的执行开始时开始 |
end_time_filter | 如果不是 NULL,则报告仅显示在日期 end_time_filter 之前收集的活动(来自 GV$ACTIVE_SESSION_HISTORY)。如果为 NULL,则报告的活动在目标 SQL 语句执行结束时结束,或者如果该语句仍在执行则为当前时间 |
instance_id_filter | 仅当执行跨多个 Oracle Real Application Cluster (Oracle RAC) 实例并行运行时适用。该参数允许只报告指定实例的活动。使用 NULL 值(默认值)来包括执行并行查询的所有实例上的活动 |
parallel_filter | 解释如下 |
仅适用于并行执行并允许仅报告并行执行中涉及的进程子集的活动(查询协调器和/或并行执行服务器)。该参数的值可以是:
- NULL 以所有进程为目标
[qc][servers(<svr_grp>[,] <svr_set>[,] <srv_num>)]:“qc”代表查询协调器,servers() 规定要考虑哪些 PX 服务器。
以下示例显示了如何定位并行进程的子集:
- qc:仅针对查询协调器
- servers(1):以组号 1 中的所有并行执行服务器为目标。请注意,并行运行的语句有一个主服务器组(组号 1)加上一个附加组,用于并行运行的每个嵌套子查询
- servers(,2):以来自任何组的所有并行执行服务器为目标,但仅在每个组的第 1 组中运行(每个组最多有两组并行执行服务器)
- servers(1,1):只考虑组 1,集合 1
- servers(1,2,4):仅考虑第 1 组,第 2 组,服务器编号 4。此报告针对单个并行服务器进程
- qc servers(1,2,4):与上面相同,还包括查询协调器
event_detail | 当值为YES(默认值)时,来自 GV$ACTIVE_SESSION_HISTORY 的报告活动按 (wait_class, event_name) 聚合。 使用NO仅按 wait_class 聚合 |
|---|---|
bucket_max_count | 如果指定,这应该是报告中创建的直方图桶的最大数量 |
bucket_interval | 如果指定,这表示所有直方图桶的确切时间间隔(以秒为单位)。如果指定,bucket_max_count 将被忽略 |
base_path | flex HTML 资源的 URL 路径,因为访问外部文件(java 脚本和 flash SWF 文件本身)需要 flex HTML 格式 |
last_refresh_time | 如果不是 NULL(默认为 NULL),则为上次检索报告的时间(请参阅报告标记的 SYSDATE 属性)。使用此选项显示正在运行的查询的报告,以及报告定期刷新的时间。这优化了报告的大小,因为只返回新的或更改的信息。特别优化了以下内容:指定此选项时不返回 SQL 文本;活动直方图从当时相交的桶开始。返回桶的全部内容,即使 last_refresh_time 晚于该桶的开始 |
report_level | 解释如下 |
report_level (contd.) | 解释如下 |
type | 报告格式,默认为“TEXT”。可以是“TEXT”、“HTML”、“XML”或“ACTIVE”(请参阅使用说明) |
sql_plan_hash_value | 仅针对那些具有指定 plan_hash_value 的 SQL 执行。默认为 NULL |
con_name | 多租户容器数据库 (CDB) 的名称 |
report_id | 自动报告存储库中报告的 ID。可以在 DBA_HIST_REPORTS 中找到报告 ID |
report_level解释如下:
报告的详细程度:'NONE', 'BASIC','TYPICAL'or 'ALL'。默认假定为“典型”。此外,还可以使用 +/- section_name 启用或禁用各个报告部分。定义了几个部分:
- ‘XPLAN’- 显示解释计划;默认开启
- ‘PLAN’- 显示计划监控统计;默认开启
- ‘SESSIONS’- 显示会话详细信息。仅适用于并行查询;默认开启
- ‘INSTANCE’- 显示实例详细信息。仅适用于并行和交叉实例;默认开启
- ‘PARALLEL’- 用于指定会话+实例详细信息的伞形参数
- ‘ACTIVITY’ - 在全局级别、计划行级别和会话或实例级别(如果适用)显示活动摘要;默认开启
- ‘BINDS’ - 可用时显示绑定信息;默认开启
- ‘METRICS’ - 显示随时间推移的指标数据(CPU、I/O、…);默认开启
- ‘ACTIVITY_HISTOGRAM’ - 显示整体查询活动的直方图;默认开启
- ‘PLAN_HISTOGRAM’ - 在计划线级别显示活动直方图;默认关闭
- ‘OTHER’ - 其他信息;默认开启
此外,还可以在不同级别指定 SQL 文本:
- SQL_TEXT - 报告中没有 SQL 文本
- +SQL_TEXT - OK 部分 SQL 文本最多前 2000 个字符存储在
GV$SQL_MONITOR中 - -SQL_FULLTEXT - 没有完整的 SQL 文本 (+SQL_TEXT)
- +SQL_FULLTEXT - 显示完整的 SQL 文本(默认值)
report_level (contd.) 解释如下:三个顶层报告层级的含义分别是:
NONE- 最小可能+BASIC-SQL_TEXT-PLAN-XPLAN-SESSIONS-INSTANCE-ACTIVITY_HISTOGRAM-PLAN_HISTOGRAM-METRICSTYPICAL- 除PLAN_HISTOGRAM之外的一切ALL- everything
只能指定这 4 个级别中的一个,如果是,它必须位于 REPORT_LEVEL 字符串的开头
其返回值为:包含所需报告的 CLOB。
使用说明:
-
此报告的目标 SQL 语句可以是:
- Oracle 数据库监控的最新 SQL 语句。这是默认行为,因此无需指定任何参数
- 由特定会话执行并由 Oracle 监视的最新 SQL 语句。会话由其会话 ID 和可选的序列号标识。例如,对当前会话使用 session_id => 或对会话 ID 20、序列号 103 使用 session_id => 20、session_serial => 103
- 由其 sql_id 标识的特定语句的最近执行
- SQL 语句的特定执行由其执行键(sql_id、sql_exec_start 和 sql_exec_id)标识
-
该报告生成由下面列出的几个固定视图公开的性能数据。为此,报表函数的调用者必须具有从这些固定视图中选择数据的权限(例如 SELECT_CATALOG 角色)
GV$SQL_MONITORGV$SQL_PLAN_MONITORGV$SQL_PLANGV$ACTIVE_SESSION_HISTORYGV$SESSION_LONGOPSGV$SQL
-
bucket_max_count 和 bucket_interval 参数控制活动直方图。默认情况下,最大桶数设置为 128。数据库根据此计数得出 bucket_interval 值。计算 bucket_interval(值以秒为单位),使其成为 2 值的最小可能幂(从 1 秒开始),而不超过最大桶数。例如,如果查询已执行 600 秒,则数据库选择 8 秒(2 的幂)的 bucket_interval。数据库选择值 8,因为 600/8 = 74,小于 128 个桶的最大值。小于 8 秒将是 4 秒,这将导致比最大值 128 个更多的桶。如果指定了 bucket_interval,那么数据库将使用指定的值而不是从 bucket_max_count 派生
-
ACTIVE 报告具有类似于 Enterprise Manager 的丰富的交互式用户界面,同时不需要安装任何 EM。报告文件为 HTML 格式。首次查看报告时,Web 浏览器会透明地下载支持活动报告的代码。因此,查看报告需要外部连接
REPORT_SQL_MONITOR_LIST Function
此函数为 Oracle 数据库监视的所有语句或语句子集构建报告。对于每条语句,子程序都会提供关键信息和相关的全局统计信息。
使用 REPORT_SQL_MONITOR 函数获取单个 SQL 语句的详细监控信息。其语法格式如下:
DBMS_SQLTUNE.REPORT_SQL_MONITOR_LIST(
sql_id IN VARCHAR2 DEFAULT NULL,
session_id IN NUMBER DEFAULT NULL,
session_serial IN NUMBER DEFAULT NULL,
inst_id IN NUMBER DEFAULT NULL,
active_since_date IN DATE DEFAULT NULL,
active_since_sec IN NUMBER DEFAULT NULL,
active_before_date IN DATE DEFAULT NULL,
last_refresh_time IN DATE DEFAULT NULL,
dbop_name IN VARCHAR2 DEFAULT NULL,
monitor_type IN NUMBER DEFAULT MONITOR_TYPE_ALL,
max_sqltext_length IN NUMBER DEFAULT NULL,
top_n_count IN NUMBER DEFAULT NULL,
top_n_rankby IN VARCHAR2 DEFAULT 'LAST_ACTIVE_TIME',
report_level IN VARCHAR2 DEFAULT 'TYPICAL',
auto_refresh IN NUMBER DEFAULT NULL,
base_path IN VARCHAR2 DEFAULT NULL,
type IN VARCHAR2 DEFAULT 'TEXT',
con_name IN VARCHAR2 DEFAULT NULL,
top_n_detail_count IN NUMBER DEFAULT NULL)
RETURN CLOB;
其参数解释如下:
| Parameter | Description |
|---|---|
sql_id | 需要显示监控信息的SQL_ID。使用 NULL(默认值)报告 Oracle 监视的最后一条语句 |
session_id | 如果不是 NULL,则此参数仅针对指定会话执行的语句子集。默认为 NULL。对当前会话使用 -1 或 USERENV(‘SID’) |
session_serial | 除了 session_id 参数外,您还可以指定其会话序列以确保所需的会话化身是有针对性的。当 session_id 为 NULL 时忽略此参数 |
inst_id | 只考虑在指定实例上启动的语句。使用 -1 来定位登录实例。NULL(默认)针对所有实例 |
active_since_date | 如果不是 NULL(默认值),则仅返回自指定时间以来处于活动状态的受监视语句。这包括仍在执行的所有语句以及在指定日期和时间之后已完成执行的所有语句 |
active_since_sec | 与 active_since_date 相同,但指定的日期相对于当前 SYSDATE 减去指定的秒数。例如,使用 3600 应用 1 小时的限制 |
active_before_date | 如果不是 NULL(默认值),则仅返回在指定日期和时间之前处于活动状态的受监视语句 |
last_refresh_time | 如果不是 NULL(默认值),则为上次检索列表报告的日期和时间。这优化了应用程序显示列表并定期(例如每 5 秒一次)刷新报告的情况。在这种情况下,报告显示有关自指定的 last_refresh_time 以来活动的受监视查询执行情况的详细信息。对于其他查询,报告返回执行键(sql_id、sql_exec_start、sql_exec_id)。对于首次刷新时间在指定日期之后的查询,该函数仅返回 SQL 执行键和统计信息 |
dbop_name | 数据库操作名称。指定 NULL 以显示所有受监视的数据库操作 |
monitor_type | SQL 监视器操作的类型。指定以下值之一:MONITOR_TYPE_SQL - 仅返回 SQL 语句;MONITOR_TYPE_DBOP - 只返回数据库操作;MONITOR_TYPE_ALL - 返回 SQL 语句和数据库操作 |
max_sqltext_length | SQL 文本的最大长度。默认为 NULL(无限制) |
top_n_count | 限制需要包含在报告中的前 N 个 SQL 语句的数量 |
top_n_rankby | 指定对 SQL 语句进行排名的属性。当 top_n_count 值不为 NULL 时指定此值。SQL 语句的排名是根据以下值之一完成的:LAST_ACTIVE_TIME - 最后一个活动日期和时间(最近的前 N 个);DURATION - 执行的总持续时间;DB_TIME - 使用的数据库时间;CPU_TIME - 使用的 CPU 时间;IO_REQUESTS - I/O 请求数;IO_BYTES - I/O 字节数 |
report_level | 报告的详细程度。级别是以下之一:BASIC - SQL 文本最多 200 个字符。TYPICAL - 包括完整的 SQL 文本,假设游标没有老化,在这种情况下,SQL 文本最多包含 2000 个字符。ALL - 当前与 TYPICAL 相同 |
auto_refresh | 目前无法使用,保留供将来使用 |
base_path | flex HTML 资源的 URL 路径,因为访问外部文件(java 脚本和 flash SWF 文件本身)需要 flex HTML 格式 |
type | 报告格式:文本(默认)、HTML 或 XML |
con_name | 多租户容器数据库 (CDB) 的名称 |
top_n_detail_count | 限制报告中需要包含 SQL 监视器详细信息的前 N 个 SQL 语句的数量 |
返回值为:已监视的 SQL 语句列表的报告。报告类型是文本、XML 或 HTML。
使用说明:您必须有权访问以下固定视图:GV$SQL_MONITOR 和 GV$SQL。
REPORT_TUNING_TASK Function
此函数显示调优任务的结果。 默认情况下,报告为文本格式。其语法格式如下:
DBMS_SQLTUNE.REPORT_TUNING_TASK(
task_name IN VARCHAR2,
type IN VARCHAR2 := 'TEXT',
level IN VARCHAR2 := 'TYPICAL',
section IN VARCHAR2 := ALL,
object_id IN NUMBER := NULL,
result_limit IN NUMBER := NULL,
owner_name IN VARCHAR2 := NULL,
execution_name IN VARCHAR2 := NULL,
database_link_to IN VARCHAR2 := NULL)
RETURN CLOB;
其参数解释如下:
| Parameter | Description |
|---|---|
task_name | 调优任务的名称 |
type | 要生成的报告类型。可能的值是生成文本报告的 TEXT |
level | 报告的详细程度:BASIC:报告的简单版本。仅显示有关顾问采取的操作的信息。TYPICAL:显示有关每个已分析语句的信息,包括未实现的请求。ALL:高度详细的报告级别,还提供有关跳过的语句的注释 |
section | 要包含的报告部分。您可以将报告限制为以下任何一个部分(ALL 表示所有部分):SUMMARY - Summary information; FINDINGS - Tuning findings; PLAN - Explain plans; INFORMATION - General information; ERROR - Statements with errors; ALL - All statements |
object_id | Advisor 框架对象 ID,表示要限制报告的单个语句。NULL 对于所有语句。仅对针对单次执行的报告有效 |
result_limit | 报告中显示的 SQL 语句的最大数量 |
owner_name | 相关调优任务的所有者。默认为当前架构所有者 |
execution_name | 要使用的任务执行的名称。如果为 NULL,则该函数生成上次任务执行的报告 |
database_link_to | 备用数据库上存在的数据库链接的名称。该链接指定与主数据库的连接。默认情况下,该值为空,这意味着 SQL Tuning Advisor 会话是本地的。使用 DBMS_SQLTUNE 调优在 Active Data Guard 场景中运行在备用数据库上的高负载 SQL 语句。当你在备库本地执行REPORT_TUNING_TASK时,该函数使用数据库链接从主库获取数据,然后在备库本地构建。database_link_to 参数必须指定私有数据库链接。此链接必须由 SYS 拥有并由默认特权用户 SYS$UMF 访问。以下示例语句创建一个名为 lnk_to_pri 的链接:CREATE DATABASE LINK lnk_to_pri CONNECT TO SYS$UMF IDENTIFIED BY password USING ‘inst1’; |
其返回值为:包含所需报告的 CLOB。
其使用案例如下:
-- Display the report for a single statement.
-- 显示单个语句的报告
SELECT DBMS_SQLTUNE.REPORT_TUNING_TASK(:stmt_task)
FROM DUAL;
-- Display the summary for a SQL tuning set.
-- 显示 SQL 调优集的摘要
SELECT DBMS_SQLTUNE.REPORT_TUNING_TASK(:sts_task, 'TEXT', 'TYPICAL', 'SUMMARY')
FROM DUAL;
-- Display the findings for a specific statement.
-- 显示特定语句的结果
SELECT DBMS_SQLTUNE.REPORT_TUNING_TASK(:sts_task, 'TEXT', 'TYPICAL','FINDINGS', 5)
FROM DUAL;
REPORT_TUNING_TASK_XML Function
此函数显示调优任务的 XML 报告。其语法格式如下:
DBMS_SQLTUNE.REPORT_TUNING_TASK_LIST_XML(
task_name IN VARCHAR2 := NULL,
level IN VARCHAR2 := LEVEL_TYPICAL,
section IN VARCHAR2 := SECTION_ALL,
object_id IN NUMBER := NULL,
result_limit IN NUMBER := 160,
owner_name IN VARCHAR2 := NULL,
execution_name IN VARCHAR2 := NULL,
autotune_period IN NUMBER := NULL,
report_tag IN VARCHAR2 := NULL)
RETURN XMLTYPE;
其参数解释如下:
| Parameter | Description |
|---|---|
task_name | 调优任务的名称 |
level | 报告的详细程度: BASIC:报告的简单版本。仅显示有关顾问采取的操作的信息。TYPICAL:显示有关每个已分析语句的信息,包括未实现的请求。ALL:高度详细的报告级别,还提供有关跳过的语句的注释 |
section | 要包含的报告部分。您可以将报告限制为以下任何一个部分(ALL 表示所有部分):SUMMARY - 摘要信息。ALL - 所有语句 |
object_id | Advisor 框架对象 ID,表示要限制报告的单个语句。NULL 对于所有语句。仅对针对单次执行的报告有效 |
result_limit | 为其生成报告的 SQL 调优集或快照范围中的语句数。默认值为 160(20 个语句 * 8 个类别)。类别如下:Profile;Index;Restructure SQL;Alternate plan;Statistics;Errors;Information;No findings |
owner_name | 相关调优任务的所有者。默认为当前架构所有者 |
execution_name | 要使用的任务执行的名称。如果为 NULL,则函数生成最近任务执行的报告 |
autotune_period | SQL 自动调优的时间段。此设置仅适用于自动 SQL Tuning Advisor 任务。可能的值如下:Null 或负值(默认值)— All 或 full。结果包括所有任务执行。0 — 当前或最近任务执行的结果。1 — 最近 24 小时的结果。7 — 最近 7 天的结果。该过程将任何其他值解释为最近执行任务的时间减去该参数的值 |
report_tag | 根 XML 标记的名称。默认情况下,标签是报告框架生成的报告引用 |
返回值为:包含所需报告的 CLOB。
RESET_TUNING_TASK Procedure
在当前未执行的调优任务上调用此过程以准备重新执行。其语法格式如下:
DBMS_SQLTUNE.RESET_TUNING_TASK(
task_name IN VARCHAR2);
其参数解释如下:
| Parameter | Description |
|---|---|
task_name | 要重置的调优任务的名称 |
其使用案例如下:
-- reset and re-execute a task
EXEC DBMS_SQLTUNE.RESET_TUNING_TASK(:sts_task);
-- re-execute the task
EXEC DBMS_SQLTUNE.EXECUTE_TUNING_TASK(:sts_task);
RESUME_TUNING_TASK Procedure
此过程恢复先前中断的任务,该任务是为处理 SQL 调优集而创建的。其语法格式如下:
DBMS_SQLTUNE.RESUME_TUNING_TASK(
task_name IN VARCHAR2,
basic_filter IN VARCHAR2 := NULL);
其参数解释如下:
| Parameter | Description |
|---|---|
task_name | 要恢复的调优任务的名称 |
basic_filter | 用于从 SQL 调优集中过滤 SQL 的 SQL 谓词。请注意,此过滤器在调用 CREATE_TUNING_TASK 函数时与参数 basic_filteri 一起应用 |
使用说明:不支持恢复单个 SQL 调优任务(与 SQL 调优集相比,为调优单个 SQL 语句而创建的任务)。
其使用案例如下:
-- Interrupt the task
-- 中断任务
EXEC DBMS_SQLTUNE.INTERRUPT_TUNING_TASK(:conc_task);
-- Once a task is interrupted, we can elect to reset it, resume it, or check
-- out its results and then decide. For this example we will just resume.
-- 一旦任务被中断,我们可以选择重置它、恢复它或检查它的结果然后再决定。 对于这个例子,我们将继续
EXEC DBMS_SQLTUNE.RESUME_TUNING_TASK(:conc_task);
SCHEDULE_TUNING_TASK Function
此函数为单个 SQL 语句创建调优任务并调度 DBMS_SCHEDULER 作业来执行调优任务。该函数的一种形式在共享 SQL 区域中查找有关要调优的语句的信息,而另一种形式在 AWR 中查找信息。其语法格式如下:
-- Shared SQL Area Format:
DBMS_SQLTUNE.SCHEDULE_TUNING_TASK(
sql_id IN VARCHAR2,
plan_hash_value IN NUMBER := NULL,
start_date IN TIMESTAMP WITH TIME ZONE := NULL,
scope IN VARCHAR2 := SCOPE_COMPREHENSIVE,
time_limit IN NUMBER := TIME_LIMIT_DEFAULT,
task_name IN VARCHAR2 := NULL,
description IN VARCHAR2 := NULL,
con_name IN VARCHAR2 := NULL)
RETURN VARCHAR2;
-- AWR Format:
DBMS_SQLTUNE.SCHEDULE_TUNING_TASK(
begin_snap IN NUMBER,
end_snap IN NUMBER,
sql_id IN VARCHAR2,
plan_hash_value IN NUMBER := NULL,
start_date IN TIMESTAMP WITH TIME ZONE := NULL,
scope IN VARCHAR2 := SCOPE_COMPREHENSIVE,
time_limit IN NUMBER := TIME_LIMIT_DEFAULT,
task_name IN VARCHAR2 := NULL,
description IN VARCHAR2 := NULL,
con_name IN VARCHAR2 := NULL,
dbid IN NUMBER := NULL)
RETURN VARCHAR2;
其参数解释如下:
| Parameter | Description |
|---|---|
begin_snap | 开始的快照标识符。范围是独占的,即不包括该快照ID中的SQL语句 |
end_snap | 结束快照标识符。范围是包含的,即包含这个快照ID中的SQL语句 |
sql_id | 待调优语句的SQL ID |
plan_hash_value | 要调优的语句的计划哈希值。例如,调优作业为该 SQL 计划获取捕获的绑定 |
start_date | 计划生效的日期。如果为 null,则 SQL Tuning Advisor 立即执行任务 |
scope | 调优工作的范围:limited, or comprehensive |
time_limit | SQL 调优会话的最长持续时间(以秒为单位) |
task_name | 可选的 SQL 调优任务名称 |
description | SQL 调优会话的描述。说明最多可包含 256 个字符 |
con_name | SQL Tuning Advisor 从中访问 SQL 语句信息的容器 |
dbid | 导入的或 PDB 级 AWR 数据的 DBID。如果为 NULL,则使用当前数据库 DBID |
安全模型:调用者必须拥有该作业的 CREATE JOB 权限。
返回值为:每个用户唯一的 SQL 调优任务名称。多个用户可以为他们的顾问任务分配相同的名称。
使用说明:
- 该任务仅安排一次
- 调度程序作业的名称创建如下:sqltune_job_taskid_orahash(systimestamp)
SCRIPT_TUNING_TASK Function
此函数创建一个 SQL*Plus 脚本,然后可以执行该脚本以实施一组 SQL Tuning Advisor 建议。其语法格式如下:
DBMS_SQLTUNE.SCRIPT_TUNING_TASK(
task_name IN VARCHAR2,
rec_type IN VARCHAR2 := REC_TYPE_ALL,
object_id IN NUMBER := NULL,
result_limit IN NUMBER := NULL,
owner_name IN VARCHAR2 := NULL,
execution_name IN VARCHAR2 := NULL,
database_link_to IN VARCHAR2 := NULL)
RETURN CLOB;
其参数解释如下:
| Parameter | Description |
|---|---|
task_name | 要为其应用脚本的调优任务的名称 |
rec_type | 按要包含的建议类型过滤脚本。您可以使用以下值的任何子集,以逗号分隔:'ALL: '‘PROFILES’ '‘STATISTICS’ '‘INDEXES’。例如,带有配置文件和统计信息的脚本将使用过滤器“PROFILES,STATISTICS” |
object_id | 可选择按单个对象 ID 进行过滤 |
result_limit | 可选择仅显示前 n 个 SQL 的命令(按 object_id 排序,如果还指定了 object_id 则忽略) |
owner_name | 相关调优任务的所有者。默认为当前架构所有者 |
excution_name | 要使用的任务执行的名称。如果为 NULL,则为最后一次任务执行生成脚本 |
database_link_to | 备用数据库上存在的数据库链接的名称。该链接指定与主数据库的连接。默认情况下,该值为空,这意味着 SQL Tuning Advisor 会话是本地的。使用 DBMS_SQLTUNE 调优在 Active Data Guard 场景中运行在备用数据库上的高负载 SQL 语句。当你在备库本地执行REPORT_TUNING_TASK时,该函数使用数据库链接从主库获取数据,然后在备库本地构建。database_link_to 参数必须指定私有数据库链接。 此链接必须由 SYS 拥有并由默认特权用户 SYS$UMF 访问。 以下示例语句创建一个名为 lnk_to_pri 的链接:CREATE DATABASE LINK lnk_to_pri CONNECT TO SYS$UMF IDENTIFIED BY password USING ‘inst1’; |
返回值为:以 CLOB 的形式返回脚本。
使用说明:
- 脚本返回后,在执行之前检查它
- 调用 DBMS_ADVISOR.CREATE_FILE 将其放入文件中
其使用案例如下:
SET LINESIZE 140
-- Get a script for all actions recommended by the task.
-- 获取任务推荐的所有操作的脚本
SELECT DBMS_SQLTUNE.SCRIPT_TUNING_TASK(:stmt_task) FROM DUAL;
-- Get a script of only the sql profiles we should create.
-- 获取仅包含我们应创建的 sql 配置文件的脚本
SELECT DBMS_SQLTUNE.SCRIPT_TUNING_TASK(:stmt_task, 'PROFILES') FROM DUAL;
-- Get a script of only stale / missing stats
-- 获取仅包含陈旧/缺失统计信息的脚本
SELECT DBMS_SQLTUNE.SCRIPT_TUNING_TASK(:stmt_task, 'STATISTICS') FROM DUAL;
-- Get a script with recommendations about only one SQL statement when we have
-- tuned an entire STS.
-- 当我们调优了整个 STS 时,获取一个脚本,其中仅包含关于一个 SQL 语句的建议
SELECT DBMS_SQLTUNE.SCRIPT_TUNING_TASK(:sts_task, 'ALL', 5) FROM DUAL;
SELECT_CURSOR_CACHE
此函数从共享 SQL 区域收集 SQL 语句。其语法格式如下:
DBMS_SQLTUNE.SELECT_CURSOR_CACHE (
basic_filter IN VARCHAR2 := NULL,
object_filter IN VARCHAR2 := NULL,
ranking_measure1 IN VARCHAR2 := NULL,
ranking_measure2 IN VARCHAR2 := NULL,
ranking_measure3 IN VARCHAR2 := NULL,
result_percentage IN NUMBER := 1,
result_limit IN NUMBER := NULL,
attribute_list IN VARCHAR2 := NULL,
recursive_sql IN VARCHAR2 := HAS_RECURSIVE_SQL)
RETURN sys.sqlset PIPELINED;
其参数解释如下:
| Parameter | Description |
|---|---|
basic_filter | 指定从在 SQLSET_ROW 的属性上定义的共享 SQL 区域过滤 SQL 的 SQL 谓词。如果 basic_filter 没有被调用者设置,那么子程序只捕获类型为 CREATE TABLE、INSERT、SELECT、UPDATE、DELETE 和 MERGE 的语句 |
object_filter | Currently not supported. |
ranking_measure(n) | 在所选 SQL 上定义 ORDER BY 子句 |
result_percentage | 指定根据提供的排名度量选择前 n% 的筛选器。仅当提供一种排名度量时,该值才适用 |
result_limit | 定义来自按排名度量排名的筛选源的上限 SQL |
attribute_list | 参数解释如下 |
recursive_sql | 指定过滤器必须在 SQL 调整集中包含递归 SQL(HAS_RECURSIVE_SQL,这是默认设置)或将其排除在外 (NO_RECURSIVE_SQL) |
attribute_list解释:指定要在结果中返回的 SQL 语句属性列表。可能的值是:
- TYPICAL — 指定 BASIC plus SQL 计划(没有行源统计信息)并且没有对象引用列表(默认)
- BASIC — 指定除计划之外的所有属性(例如执行统计信息和绑定)。执行上下文始终是结果的一部分
- ALL — 指定所有属性
- Comma 逗号分隔的属性名称列表。此值仅返回 SQL 属性的一个子集:
EXECUTION_STATISTICSBIND_LISTOBJECT_LISTSQL_PLANSQL_PLAN_STATISTICS— 类似SQL_PLAN加上行源统计
返回值为:此函数针对每个数据源中找到的每个 SQL_ID 或 PLAN_HASH_VALUE 对返回一个 SQLSET_ROW。
使用说明:
- 提供给该函数的过滤器作为当前用户运行的 SQL 的一部分进行评估。因此,它们以该用户的安全权限执行,并且可以包含用户可以访问的任何构造和子查询,但仅此而已
- 用户需要对共享 SQL 区域视图具有特权
其使用案例如下:
-- Get sql ids and sql text for statements with 500 buffer gets.
-- 为具有 500 个缓冲区获取的语句获取 sql id 和 sql 文本
SELECT sql_id, sql_text
FROM table(DBMS_SQLTUNE.SELECT_CURSOR_CACHE('buffer_gets > 500'))
ORDER BY sql_id;
-- Get all the information we have about a particular statement.
-- 获取我们拥有的关于特定语句的所有信息
SELECT *
FROM table(DBMS_SQLTUNE.SELECT_CURSOR_CACHE('sql_id = ''4rm4183czbs7j'''));
-- Notice that some statements can have multiple plans. The output of the
-- SELECT_XXX table functions is unique by (sql_id, plan_hash_value). This is
-- because a data source can store multiple plans per sql statement.
-- 请注意,某些语句可以有多个计划。SELECT_XXX 表函数的输出是唯一的(sql_id,plan_hash_value)。这是因为数据源可以为每个 sql 语句存储多个计划
SELECT sql_id, plan_hash_value
FROM table(dbms_sqltune.select_cursor_cache('sql_id = ''ay1m3ssvtrh24'''))
ORDER BY sql_id, plan_hash_value;
-- PL/SQL examples: load_sqlset is called after opening a cursor, along the
-- lines given below
-- PL/SQL 示例:load_sqlset 在打开游标后调用,如下所示
-- Select all statements in the shared SQL area.
-- 选择共享SQL区的所有语句
DECLARE
cur sys_refcursor;
BEGIN
OPEN cur FOR
SELECT value(P)
FROM table(DBMS_SQLTUNE.SELECT_CURSOR_CACHE) P;
-- Process each statement (or pass cursor to load_sqlset).
-- 处理每个语句(或将游标传递给 load_sqlset)
CLOSE cur;
END;/
-- Look for statements not parsed by SYS.
-- 查找未被 SYS 解析的语句
DECLARE
cur sys_refcursor;
BEGIN
OPEN cur for
SELECT VALUE(P)
FROM table(
DBMS_SQLTUNE.SELECT_CURSOR_CACHE('parsing_schema_name <> ''SYS''')) P;
-- Process each statement (or pass cursor to load_sqlset).
-- 处理每个语句(或将游标传递给 load_sqlset)
CLOSE cur;
end;/
-- All statements from a particular module/action.
-- 来自特定模块/操作的所有语句
DECLARE
cur sys_refcursor;
BEGIN
OPEN cur FOR
SELECT VALUE(P)
FROM table(
DBMS_SQLTUNE.SELECT_CURSOR_CACHE(
'module = ''MY_APPLICATION'' and action = ''MY_ACTION''')) P;
-- Process each statement (or pass cursor to load_sqlset)
-- 处理每个语句(或将游标传递给 load_sqlset)
CLOSE cur;
END;/
-- all statements that ran for at least five seconds
-- 运行至少五秒钟的所有语句
DECLARE
cur sys_refcursor;
BEGIN
OPEN cur FOR
SELECT VALUE(P)
FROM table(DBMS_SQLTUNE.SELECT_CURSOR_CACHE('elapsed_time > 5000000')) P;
-- Process each statement (or pass cursor to load_sqlset)
-- 处理每个语句(或将游标传递给 load_sqlset)
CLOSE cur;
end;/
-- select all statements that pass a simple buffer_gets threshold and
-- are coming from an APPS user
-- 选择所有通过简单 buffer_gets 阈值且来自 APPS 用户的语句
DECLARE
cur sys_refcursor;
BEGIN
OPEN cur FOR
SELECT VALUE(P)
FROM table(
DBMS_SQLTUNE.SELECT_CURSOR_CACHE(
'buffer_gets > 100 and parsing_schema_name = ''APPS'''))P;
-- Process each statement (or pass cursor to load_sqlset)
-- 处理每个语句(或将游标传递给 load_sqlset)
CLOSE cur;
end;/
-- select all statements exceeding 5 seconds in elapsed time, but also
-- select the plans (by default we only select execution stats and binds
-- for performance reasons - in this case the SQL_PLAN attribute of sqlset_row
-- is NULL)
-- 选择所有运行时间超过 5 秒的语句,但也选择计划(默认情况下,出于性能原因,我们只选择执行统计和绑定——在这种情况下,sqlset_row 的 SQL_PLAN 属性为 NULL)
DECLARE
cur sys_refcursor;
BEGIN
OPEN cur FOR
SELECT VALUE(P)
FROM table(dbms_sqltune.select_cursor_cache(
'elapsed_time > 5000000', NULL, NULL, NULL, NULL, 1, NULL,
'EXECUTION_STATISTICS, SQL_BINDS, SQL_PLAN')) P;
-- Process each statement (or pass cursor to load_sqlset)
-- 处理每个语句(或将游标传递给 load_sqlset)
CLOSE cur;
END;/
-- Select the top 100 statements in the shared SQL area ordering by elapsed_time.
-- 选择共享SQL区中按elapsed_time排序的前100条语句
DECLARE
cur sys_refcursor;
BEGIN
OPEN cur FOR
SELECT VALUE(P)
FROM table(DBMS_SQLTUNE.SELECT_CURSOR_CACHE(NULL,
NULL,
'ELAPSED_TIME', NULL, NULL,
1,
100)) P;
-- Process each statement (or pass cursor to load_sqlset)
-- 处理每个语句(或将游标传递给 load_sqlset)
CLOSE cur;
end;/
-- Select the set of statements which cumulatively account for 90% of the
-- buffer gets in the shared SQL area. This means that the buffer gets of all
-- of these statements added up is approximately 90% of the sum of all
-- statements currently in the cache.
-- 选择累计占共享SQL区buffer gets 90%的语句集。这意味着所有这些语句的缓冲区获取加起来大约是当前缓存中所有语句总和的 90%
DECLARE
cur sys_refcursor;
BEGIN
OPEN cur FOR
SELECT VALUE(P)
FROM table(DBMS_SQLTUNE.SELECT_CURSOR_CACHE(NULL,
NULL,
'BUFFER_GETS', NULL, NULL,
.9)) P;
-- Process each statement (or pass cursor to load_sqlset).
-- 处理每个语句(或将游标传递给 load_sqlset)
CLOSE cur;
END;
/
SELECT_SQL_TRACE Function
此表函数读取一个或多个跟踪文件的内容,并以 sqlset_row 的格式返回它找到的 SQL 语句。其语法格式如下:
DBMS_SQLTUNE.SELECT_SQL_TRACE (
directory IN VARCHAR2,
file_name IN VARCHAR2 := NULL,
mapping_table_name IN VARCHAR2 := NULL,
mapping_table_owner IN VARCHAR2 := NULL,,
select_mode IN POSITIVE := SINGLE_EXECUTION,
options IN BINARY_INTEGER := LIMITED_COMMAND_TYPE,
pattern_start IN VARCHAR2 := NULL,
pattern_end IN VARCHAR2 := NULL,
result_limit IN POSITIVE := NULL)
RETURN sys.sqlset PIPELINED;
其参数解释如下:
| Parameter | Description |
|---|---|
directory | 定义包含跟踪文件的目录对象。此字段是必填字段 |
file_name | 指定跟踪文件的全部或部分名称。如果为 NULL,则该函数使用指定位置或路径中的当前或最新文件。匹配跟踪文件名时支持“%”通配符 |
mapping_table_name | 指定映射表名称。请注意,映射表名称不区分大小写。如果映射表名称为 NULL,则该函数使用当前数据库中的映射 |
mapping_table_owner | 指定映射表所有者。如果为 NULL,则该函数使用当前用户 |
select_mode | 指定从跟踪中选择 SQL 的模式。可能的值有:SINGLE_EXECUTION — 返回 SQL 的一次执行。这是默认值。ALL_EXECUTIONS — 返回所有执行 |
options | 指定返回哪些类型的 SQL 语句。LIMITED_COMMAND_TYPE — 返回命令类型为 CREATE、INSERT、SELECT、UPDATE、DELETE 和 MERGE 的 SQL 语句。此值为默认值。ALL_COMMAND_TYPE — 返回所有命令类型的 SQL 语句 |
pattern_start | 指定要考虑的跟踪文件部分的定界模式。当前无法操作 |
pattern_end | 指定要处理的跟踪文件部分的结束定界模式。当前无法操作 |
result_limit | 指定过滤源中排名靠前的 SQL。如果为 NULL,则默认为 MAXSB4 |
返回值为:该函数返回一个 SQLSET_ROW 对象。
使用说明:
- 为系统目录创建目录对象的能力会产生潜在的安全问题。例如,在 CDB 中,所有容器都将跟踪文件写入同一目录。对该目录具有 SELECT 权限的本地用户可以读取属于任何容器的跟踪文件的内容
- 要防止此类未经授权的访问,请将文件从默认的 SQL 跟踪目录复制到不同的目录,然后创建一个目录对象。使用 CREATE PLUGGABLE DATABASE 语句的 PATH_PREFIX 子句确保与 PDB 关联的所有目录对象路径都限制在指定目录或其子目录中
其使用案例如下:
以下代码显示了如何为一些 SQL 语句启用 SQL 跟踪并将结果加载到 SQL 调优集中:
-- turn on the SQL trace in the capture database
-- 在捕获数据库中打开 SQL 跟踪
ALTER SESSION SET EVENTS '10046 TRACE NAME CONTEXT FOREVER, LEVEL 4'
-- run sql statements
-- 运行sql语句
SELECT 1 FROM DUAL;
SELECT COUNT(*) FROM dba_tables WHERE table_name = :mytab;
ALTER SESSION SET EVENTS '10046 TRACE NAME CONTEXT OFF';
-- create mapping table from the capture database
-- 从捕获数据库创建映射表
CREATE TABLE mapping AS
SELECT object_id id, owner, substr(object_name, 1, 30) name
FROM dba_objects
WHERE object_type NOT IN ('CONSUMER GROUP', 'EVALUATION CONTEXT',
'FUNCTION', 'INDEXTYPE', 'JAVA CLASS',
'JAVA DATA', 'JAVA RESOURCE', 'LIBRARY',
'LOB', 'OPERATOR', 'PACKAGE',
'PACKAGE BODY', 'PROCEDURE', 'QUEUE',
'RESOURCE PLAN', 'TRIGGER', 'TYPE',
'TYPE BODY')
UNION ALL
SELECT user_id id, username owner, NULL name
FROM dba_users;
-- create the directory object where the SQL traces are stored
-- 创建存储 SQL 跟踪的目录对象
CREATE DIRECTORY SQL_TRACE_DIR as '/home/foo/trace';
-- create the STS
-- 创建 STS
EXEC DBMS_SQLTUNE.CREATE_SQLSET('my_sts', 'test purpose');
-- load the SQL statements into STS from SQL TRACE
-- 从 SQL TRACE 加载 SQL 语句到 STS
DECLARE
cur sys_refcursor;
BEGIN
OPEN cur FOR
SELECT value(p)
FROM TABLE(
DBMS_SQLTUNE.SELECT_SQL_TRACE(
directory=>'SQL_TRACE_DIR',
file_name=>'%trc',
mapping_table_name=>'mapping')) p;
DBMS_SQLTUNE.LOAD_SQLSET('my_sts', cur);
CLOSE cur;
END;
/
SELECT_SQLPA_TASK Function
此函数从 SQL Performance Analyzer 比较任务中收集 SQL 语句。其语法格式如下:
DBMS_SQLTUNE.SELECT_SQLPA_TASK(
task_name IN VARCHAR2,
task_owner IN VARCHAR2 := NULL,
execution_name IN VARCHAR2 := NULL,
level_filter IN VARCHAR2 := 'REGRESSED',
basic_filter IN VARCHAR2 := NULL,
object_filter IN VARCHAR2 := NULL,
attribute_list IN VARCHAR2 := 'TYPICAL')
RETURN sys.sqlset PIPELINED;
其参数解释如下:
| Parameter | Description |
|---|---|
task_name | 指定 SQL 性能分析器任务的名称 |
task_owner | 指定 SQL 性能分析器任务的所有者。如果为 NULL,则假定为当前用户 |
execution_name | 指定 SQL Performance Analyzer 任务执行的名称(type COMPARE PERFORMANCE),所提供的过滤器将从中应用。如果为 NULL,则假定最近的 COMPARE PERFORMANCE 执行 |
level_filter | 参数解释如下 |
basic filter | 除了级别过滤器之外,还指定用于过滤 SQL 的 SQL 谓词 |
object_filter | Currently not supported. |
attribute_list | 参数解释如下 |
level_filter解释:指定要包括的 SQL 语句子集。与 DBMS_SQLPA.REPORT_ANALYSIS_TASK.LEVEL 相同的格式,删除了一些可能的字符串。
- IMPROVED 仅包括改进的 SQL
- REGRESSED 仅包含回归的 SQL(默认)
- CHANGED 仅包括性能发生变化的 SQL
- UNCHANGED 仅包括性能不变的 SQL
- CHANGED_PLANS 仅包含具有计划更改的 SQL
- UNCHANGED_PLANS 仅包括计划未更改的 SQL
- ERRORS 仅包含有错误的 SQL
- MISSING_SQL 仅包含缺失的 SQL 语句(跨 STS)
- NEW_SQL 仅包含新的 SQL 语句(跨 STS)
attribute_list解释:定义要在结果中返回的 SQL 语句属性。可能的值是:
- TYPICAL — 返回 BASIC 加上 SQL 计划(没有行源统计信息)并且没有对象引用列表。这是默认设置
- BASIC — 返回除计划之外的所有属性(例如执行统计信息和绑定)。执行上下文始终是结果的一部分
- ALL — 返回所有属性
- Comma 逗号分隔的属性名称列表,这允许仅返回 SQL 属性的一个子集:EXECUTION_STATISTICS、SQL_BINDS、SQL_PLAN_STATISTICS(类似于 SQL_PLAN + 行源统计信息)
返回值为:此函数返回一个 SQL 调整集对象。
使用说明:例如,您可以使用此函数创建一个 SQL 调优集,其中包含在 SQL 性能分析器 (SPA) 实验期间回归的 SQL 语句的子集。您还可以指定其他任意过滤器。
SELECT_SQLSET Function
这是一个读取 SQL 调整集内容的表函数。其语法格式如下:
DBMS_SQLTUNE.SELECT_SQLSET (
sqlset_name IN VARCHAR2,
basic_filter IN VARCHAR2 := NULL,
object_filter IN VARCHAR2 := NULL,
ranking_measure1 IN VARCHAR2 := NULL,
ranking_measure2 IN VARCHAR2 := NULL,
ranking_measure3 IN VARCHAR2 := NULL,
result_percentage IN NUMBER := 1,
result_limit IN NUMBER := NULL)
attribute_list IN VARCHAR2 := NULL,
plan_filter IN VARCHAR2 := NULL,
sqlset_owner IN VARCHAR2 := NULL,
recursive_sql IN VARCHAR2 := HAS_RECURSIVE_SQL)
RETURN sys.sqlset PIPELINED;
其参数解释如下:
| Parameter | Description |
|---|---|
sqlset_name | 指定要查询的 SQL 调整集的名称 |
basic_filter | 指定 SQL 谓词以从在 SQLSET_ROW 的属性上定义的 SQL 调整集中过滤 SQL |
object_filter | Currently not supported. |
ranking_measure(n) | 在所选 SQL 上指定 ORDER BY 子句 |
result_percentage | 指定根据提供的排名度量选择前 n% 的筛选器。请注意,此参数仅在提供一个排名度量时适用 |
result_limit | 来自筛选源的上限 SQL,按排名度量排名 |
attribute_list | 参数解释如下 |
plan_filter | 参数解释如下 |
sqlset_owner | 指定 SQL 调整集的所有者,或者为当前模式所有者指定 NULL |
recursive_sql | 指定过滤器必须在 SQL 调整集中包含递归 SQL(HAS_RECURSIVE_SQL,这是默认设置)或将其排除在外 (NO_RECURSIVE_SQL) |
attribute_list解释:定义要在结果中返回的 SQL 语句属性。可能的值是:
-
BASIC — 返回除计划之外的所有属性(例如执行统计信息和绑定)。执行上下文包含在结果中
-
TYPICAL — 返回 BASIC 加上 SQL 计划,但没有行源统计信息和对象引用列表。这是默认设置
-
ALL — 返回所有属性
-
Comma 逗号分隔的属性名称列表。此值使函数能够仅返回 SQL 属性的一个子集:
EXECUTION_STATISTICSSQL_BINDSSQL_PLAN_STATISTICS(类似于SQL_PLAN加上行源统计)
plan_filter解释:指定计划过滤器。当语句有多个计划时,此参数使您可以选择单个计划。可能的值是:
- LAST_GENERATED — 返回具有最新时间戳的计划
- FIRST_GENERATED — 返回具有最近时间戳的计划
- LAST_LOADED — 返回具有最新 FIRST_LOAD_TIME 统计信息的计划
- FIRST_LOADED — 返回具有最近 FIRST_LOAD_TIME 统计信息的计划
- MAX_ELAPSED TIME — 返回已用时间最长的计划
- MAX_BUFFER_GETS — 返回具有最大缓冲区获取的计划
- MAX_DISK_READS — 返回具有最大磁盘读取的计划
- MAX_DIRECT_WRITES — 返回具有最大直接写入的计划
- MAX_OPTIMIZER_COST — 返回具有最大优化器成本值的计划
返回值为:此函数针对在每个数据源中找到的每个 SQL_ID 或 PLAN_HASH_VALUE 对返回一个 SQLSET_ROW。
使用说明:提供给该函数的过滤器作为当前用户运行的 SQL 的一部分进行评估。因此,它们以该用户的安全权限执行,并且可以包含用户可以访问的任何构造和子查询,但仅此而已。
其使用案例如下:
-- select from a sql tuning set
-- 从 sql 调优集中选择
DECLARE
cur sys_refcursor;
BEGIN
OPEN cur FOR
SELECT VALUE (P)
FROM table(dbms_sqltune.select_sqlset('my_workload')) P;
-- Process each statement (or pass cursor to load_sqlset)
-- 处理每个语句(或将游标传递给 load_sqlset)
CLOSE cur;
END;
/
SELECT_WORKLOAD_REPOSITORY Function
此函数从工作负载存储库中收集 SQL 语句。重载表单使您能够从以下来源收集 SQL 语句:
- begin_snap 和 end_snap 之间的快照
- 工作负载存储库基线
其语法格式如下:
DBMS_SQLTUNE.SELECT_WORKLOAD_REPOSITORY (
begin_snap IN NUMBER,
end_snap IN NUMBER,
basic_filter IN VARCHAR2 := NULL,
object_filter IN VARCHAR2 := NULL,
ranking_measure1 IN VARCHAR2 := NULL,
ranking_measure2 IN VARCHAR2 := NULL,
ranking_measure3 IN VARCHAR2 := NULL,
result_percentage IN NUMBER := 1,
result_limit IN NUMBER := NULL,
attribute_list IN VARCHAR2 := NULL,
recursive_sql IN VARCHAR2 := HAS_RECURSIVE_SQL,
dbid IN NUMBER := NULL)
RETURN sys.sqlset PIPELINED;
DBMS_SQLTUNE.SELECT_WORKLOAD REPOSITORY (
baseline_name IN VARCHAR2,
basic_filter IN VARCHAR2 := NULL,
object_filter IN VARCHAR2 := NULL,
ranking_measure1 IN VARCHAR2 := NULL,
ranking_measure2 IN VARCHAR2 := NULL,
ranking_measure3 IN VARCHAR2 := NULL,
result_percentage IN NUMBER := 1,
result_limit IN NUMBER := NULL,
attribute_list IN VARCHAR2 := NULL,
recursive_sql IN VARCHAR2 := HAS_RECURSIVE_SQL,
dbid IN NUMBER := NULL)
RETURN sys.sqlset PIPELINED;
其参数解释如下:
| Parameter | Description |
|---|---|
begin_snap | 定义开始 AWR 快照(非包含) |
end_snap | 定义结束 AWR 快照(包括) |
baseline_name | 指定 AWR 基线期的名称 |
basic_filter | 指定用于从工作负载存储库中过滤 SQL 的 SQL 谓词。过滤器是在 SQLSET_ROW 的属性上定义的。如果调用者没有设置 basic_filter,则子程序只捕获 CREATE TABLE、INSERT、SELECT、UPDATE、DELETE 和 MERGE 类型的语句 |
object_filter | Currently not supported. |
ranking_measure(n) | 在所选 SQL 上定义 ORDER BY 子句 |
result_percentage | 指定根据提供的排名度量选择前 n% 的筛选器。请注意,此百分比仅适用于给出一个排名指标的情况 |
result_limit | 根据提供的排名度量从源中指定上限 SQL |
attribute_list | 参数解释如下 |
recursive_sql | 指定在 SQL 调整集中包含递归 SQL (HAS_RECURSIVE_SQL) 或排除它 (NO_RECURSIVE_SQL) 的过滤器 |
dbid | 指定导入的或 PDB 级 AWR 数据的 DBID。如果为 NULL,则该函数使用当前数据库 DBID |
attribute_list解释:指定要在结果中返回的 SQL 语句属性。可能的值是:
- TYPICAL — 返回 BASIC 加上 SQL 计划(没有行源统计信息)并且没有对象引用列表。这是默认设置
- BASIC — 返回除计划外的所有属性(例如执行统计信息和绑定)。执行上下文始终是结果的一部分
- ALL — 返回所有属性
- Comma:逗号分隔的属性名称列表,这允许仅返回 SQL 属性的一个子集:EXECUTION_STATISTICS、SQL_BINDS、SQL_PLAN_STATISTICS(类似于 SQL_PLAN 加上行源统计信息)
返回值为:此函数针对在每个数据源中找到的每个 SQL_ID 或 PLAN_HASH_VALUE 对返回一个 SQLSET_ROW。
使用说明:提供给该函数的过滤器作为当前用户运行的 SQL 的一部分进行评估。因此,它们以该用户的安全权限执行,并且可以包含用户可以访问的任何构造和子查询,但仅此而已。
其使用案例如下:
-- select statements from snapshots 1-2
-- 从快照 1-2 中选择语句
DECLARE
cur sys_refcursor;
BEGIN
OPEN cur FOR
SELECT VALUE (P)
FROM table(dbms_sqltune.select_workload_repository(1,2)) P;
-- Process each statement (or pass cursor to load_sqlset)
-- 处理每个语句(或将游标传递给 load_sqlset)
CLOSE cur;
END;
/
SET_TUNING_TASK_PARAMETER Procedures
此过程更新类型为 VARCHAR2 或 NUMBER 的 SQL 调整参数的值。其语法格式如下:
DBMS_SQLTUNE.SET_TUNING_TASK_PARAMETER (
task_name IN VARCHAR2,
parameter IN VARCHAR2,
value IN VARCHAR2,
database_link_to IN VARCHAR2);
DBMS_SQLTUNE.SET_TUNING_TASK_PARAMETER (
task_name IN VARCHAR2,
parameter IN VARCHAR2,
value IN NUMBER,
database_link_to IN VARCHAR2);
);
其参数解释如下:
| Parameter | Description |
|---|---|
task_name | 要执行的任务的标识符 |
parameter | 参数解释如下 |
value | 指定参数的新值 |
database_link_to | 备用数据库上存在的数据库链接的名称。该链接指定与主数据库的连接。默认情况下,该值为空,这意味着 SQL Tuning Advisor 会话是本地的。使用 DBMS_SQLTUNE 调整在 Active Data Guard 场景中运行在备用数据库上的高负载 SQL 语句。当你在备库本地执行REPORT_TUNING_TASK时,该函数使用数据库链接从主库获取数据,然后在备库本地构建。database_link_to 参数必须指定私有数据库链接。此链接必须由 SYS 拥有并由默认特权用户 SYS$UMF 访问。以下示例语句创建一个名为 lnk_to_pri 的链接:CREATE DATABASE LINK lnk_to_pri CONNECT TO SYS$UMF IDENTIFIED BY password USING ‘inst1’; |
parameter解释:要设置的参数的名称。可以通过此过程使用 VARCHAR2 形式的参数设置的可能调整参数:
- APPLY_CAPTURED_COMPILENV:指示顾问程序是否可以使用通过 SQL 语句捕获的编译环境。默认值为 0(即 NO)
- BASIC_FILTER:SQL调优集的基本过滤器
- DAYS_TO_EXPIRE:任务被删除之前的天数
- DEFAULT_EXECUTION_TYPE:当 EXECUTE_TUNING_TASK 函数和过程没有指定时,任务默认为这种执行类型
- EXECUTION_DAYS_TO_EXPIRE:删除任务执行前的天数(不删除任务)
- LOCAL_TIME_LIMIT:每条语句超时(秒)
- MODE:调整范围(comprehensive, limited)
- OBJECT_FILTER:SQL 调优集的对象过滤器
- PLAN_FILTER:SQL 调整集的计划过滤器(请参阅 SELECT_SQLSET 了解可能的值)
- RANK_MEASURE1:SQL 调优集的第一个排名度量
- RANK_MEASURE2:SQL 调优集的第二个可能的排名度量
- RANK_MEASURE3:SQL 调优集的第三个可能的排名度量
- RESUME_FILTER:除了 BASIC_FILTER 之外的 SQL 调优集的额外过滤器
- SQL_LIMIT:要调整的 SQL 语句的最大数量
- SQL_PERCENTAGE:SQL调优集语句的百分比过滤器
- TEST_EXECUTE:完全/自动/关闭
FULL- 测试执行尽可能多的时间,直到 SQL 的本地时间限制(如果没有设置 SQL 时间限制,则为全局任务时间限制)
AUTO- 测试执行自动选择的时间与调整时间成比例
OFF- 不测试执行
- TIME_LIMIT:全局超时(秒)
- USERNAME:在其下解析语句的用户名
使用说明:设置自动调整任务参数时,使用 DBMS_AUTO_SQLTUNE 包中的 SET_AUTO_TUNING_TASK_PARAMETER 过程。
SQLTEXT_TO_SIGNATURE Function
此函数返回 SQL 文本的签名。该签名可用于识别 dba_sql_profiles 中的 SQL 文本。其语法格式如下:
DBMS_SQLTUNE.SQLTEXT_TO_SIGNATURE (
sql_text IN CLOB,
force_match IN BOOLEAN := FALSE)
RETURN NUMBER;
其参数解释如下:
| Parameter | Description |
|---|---|
sql_text | 需要签名的 SQL 文本。必需的 |
force_match | 如果为 TRUE,则返回支持 SQL 与转换为绑定变量的文字值匹配的签名。如果为 FALSE,则返回基于未转换文字的文本的签名 |
返回值为:此函数返回指定 SQL 文本的签名。
UNPACK_STGTAB_SQLPROF Procedure
此过程复制存储在暂存表中的配置文件数据以在系统上创建配置文件。其语法格式如下:
DBMS_SQLTUNE.UNPACK_STGTAB_SQLPROF (
profile_name IN VARCHAR2 := '%',
profile_category IN VARCHAR2 := 'DEFAULT',
replace IN BOOLEAN,
staging_table_name IN VARCHAR2,
staging_schema_owner IN VARCHAR2 := NULL);
其参数解释如下:
| Parameter | Description |
|---|---|
profile_name | 要解压的配置文件的名称(% 可接受通配符,区分大小写) |
profile_category | 从中解压配置文件的类别(% 可接受通配符,区分大小写) |
replace | 如果配置文件已经存在,则替换配置文件的选项。请注意,如果暂存表中的配置文件与不同 SQL 语句中的活动配置文件同名,则无法替换配置文件。如果为 FALSE,此函数会在您尝试创建已存在的配置文件时引发错误 |
staging_table_name | 对其执行重新映射操作的表的名称(不区分大小写,除非双引号)。必需的 |
staging_schema_owner | 表所在的模式,或当前模式的 NULL(不区分大小写,除非双引号) |
使用说明:使用此过程需要 CREATE ANY SQL PROFILE 特权和对暂存表的 SELECT 特权。
其使用案例如下:
-- Unpack all profiles stored in a staging table.
-- 解压存储在暂存表中的所有配置文件
BEGIN
DBMS_SQLTUNE.UNPACK_STGTAB_SQLPROF(
replace => FALSE
, staging_table_name => 'PROFILE_STGTAB');
END;
-- If there is a failure during the unpack operation, you can find the profile
-- that caused the error and perform a remap_stgtab_sqlprof operation targeting it.
-- You can resume the unpack operation by setting replace to TRUE so that
-- the profiles that were already created are replaced.
-- 如果在解包操作过程中出现错误,您可以找到导致错误的配置文件并针对它执行remap_stgtab_sqlprof 操作
-- 您可以通过将 replace 设置为 TRUE 来恢复解包操作,以便替换已经创建的配置文件
BEGIN
DBMS_SQLTUNE.UNPACK_STGTAB_SQLPROF(
replace => TRUE
, staging_table_name => 'PROFILE_STGTAB');
END;
UNPACK_STGTAB_SQLSET Procedure
此过程将一个或多个 SQL 调优集从它们在暂存表中的位置复制到 SQL 调优集架构中,使它们成为正确的 SQL 调优集。其语法格式如下:
DBMS_SQLTUNE.UNPACK_STGTAB_SQLSET (
sqlset_name IN VARCHAR2 := '%',
sqlset_owner IN VARCHAR2 := NULL,
replace IN BOOLEAN,
staging_table_name IN VARCHAR2,
staging_schema_owner IN VARCHAR2 := NULL);
其参数解释如下:
DBMS_SQLTUNE.UNPACK_STGTAB_SQLSET 和 DBMS_SQLSET.UNPACK_STGTAB 的参数相同。
| Parameter | Description |
|---|---|
sqlset_name | 指定要解压的调整集的名称(非空)。支持通配符 (%) 在一次调用中解压多个调整集。例如,指定 % 以从暂存表中解压所有调整集 |
sqlset_owner | 指定调整集所有者的名称,或者为当前模式所有者指定 NULL。支持通配符 (%) |
replace | 指定是否替换现有的 SQL 调整集。如果为 FALSE,则当您尝试创建已存在的调整集时,此过程会引发错误 |
staging_table_name | 指定暂存表的名称,在调用 DBMS_SQLTUNE.PACK_STGTAB_SQLSET 或 DBMS_SQLSET.PACK_STGTAB 过程后移动(区分大小写) |
staging_schema_owner | 指定暂存表所有者的名称,或为当前模式所有者指定 NULL(区分大小写) |
其使用案例如下:
-- unpack all STS in the staging table
-- 解压临时表中的所有 STS
EXEC DBMS_SQLTUNE.UNPACK_STGTAB_SQLSET(sqlset_name => '%', -
sqlset_owner => '%', -
replace => FALSE, -
staging_table_name => 'STGTAB_SQLSET');
-- errors can arise during STS unpack when a STS in the staging table has the
-- same name/owner as STS on the system. In this case, users should call
-- remap_stgtab_sqlset to patch the staging table and with which to call unpack
-- Replace set to TRUE.
-- 当暂存表中的 STS 与系统上的 STS 具有相同的名称/所有者时,STS 解压缩期间可能会出现错误
-- 在这种情况下,用户应调用 remap_stgtab_sqlset 来修补暂存表并将调用 unpack Replace 设置为 TRUE
EXEC DBMS_SQLTUNE.UNPACK_STGTAB_SQLSET(sqlset_name => '%', -
sqlset_owner => '%', -
replace => TRUE, -
staging_table_name => 'STGTAB_SQLSET');
UPDATE_SQLSET Procedures
此重载过程更新 SQL 调优集中 SQL 语句的选定字段。其语法格式如下:
DBMS_SQLTUNE.UPDATE_SQLSET (
sqlset_name IN VARCHAR2,
sql_id IN VARCHAR2,
attribute_name IN VARCHAR2,
attribute_value IN VARCHAR2 := NULL);
DBMS_SQLTUNE.UPDATE_SQLSET (
sqlset_name IN VARCHAR2,
sql_id IN VARCHAR2,
attribute_name IN VARCHAR2,
attribute_value IN NUMBER := NULL);
其参数解释如下:
| Parameter | Description |
|---|---|
sqlset_name | 指定 SQL 调整集的名称 |
sql_id | 指定要更新的 SQL 语句的标识符 |
plan_hash value | 指定 SQL 语句的执行计划的哈希值。当您想要更新语句的特定计划而不是语句的所有计划的属性时,请使用此参数 |
attribute_name | 指定要修改的属性的名称。您可以更新 MODULE、ACTION、PARSING_SCHEMA_NAME 和 OTHER 的文本字段。唯一可以更新的数字字段是 PRIORITY。如果一个语句有多个计划,则该过程会更改所有计划的属性值 |
attribute_value | 指定属性的新值 |