目录
1:列表初始化
2:std::initializer_list
3:变量类型推导
3.1:auto推导类型
3.2:decltype
3.3:nullptr
4:范围for
5:STL新增容器和容器新增接口
5.1:array
6:左值引用和右值引用
6.1:左值
6.2:右值
6.3:左值引用
6.4:右值引用
6.5:左值引用的场景和短板
6.5.1:编译器关于构造的优化场景回顾
6.6:右值引用场景一:移动构造
6.7:右值引用场景二:移动赋值
1:列表初始化
C++11扩大了列表初始化的范围,旨在一切类型皆可用。
在C语言中,列表初始化可以用于结构体的初始化。
struct date
{
int month;
int day;
};
int main()
{
date d1 = { 8,4 };
date d2[2] = { {1,1},{2,2} };
}对于内置类型,我们可以通过花括号这样初始化
int x1 = 1;
int x2 = { 1 };
int x3{ 1 };但是这样有点鸡肋,感觉这个语法在c++11里面就是多余的成分。再看下面
可以在new对象,new变量的时候使用列表初始化。
int* p1 = new int[4];//原本定义方式
int* p2 = new int[4]{ 0 };//给4个0初始化
int* p3 = new int[4]{ 0,1,2,3 };//用0123初始化但是还是感觉没啥意义,再看下面,关于创建类对象的时候。
class date2
{
public:
date2(int year,int month, int day)
:_year(year)
,_month(month)
,_day(day)
{}
private:
int _year;
int _month;
int _day;
};
date2 dd1(2023, 4, 11);
date2 dd2 = {2023,4,11};
date2 dd3{2023,4,11 };这里就是调用了构造函数进行初始化。
初始化列表的原理是什么呢?
2:std::initializer_list
C++11会自动识别花括号里面的内容为initializer_list的内容,举个例子:
auto il = { 1,2,3,4 };
cout << typeid(il).name() << endl;![]()
就像 这样。
其实initializer_list就是相当于保存常量的一个容器,经常用作构造函数的参数,也可以作为operator=的参数,可以用于花括号赋值。关于该容器,有这样几个接口:

用vector举个例子,vector可以这样初始化。
vector<int> v{ 1,2,3,4 };从底层来说就是先用initializer_list保存花括号里面的常量,然后再遍历initializer_list,push_back到vector中。接下来模拟实现该原理。
namespace bit
{
template<class T>
class vector {
public:
typedef T* iterator;
vector(initializer_list<T> l)
{
_start = new T[l.size()];
_finish = _start + l.size();
_endofstorage = _start + l.size();
iterator vit = _start;
typename initializer_list<T>::iterator lit = l.begin();
while (lit != l.end())
{
*vit++ = *lit++;
}
//for (auto e : l)
// *vit++ = e;
}
vector<T>& operator=(initializer_list<T> l) {
vector<T> tmp(l);
std::swap(_start, tmp._start);
std::swap(_finish, tmp._finish);
std::swap(_endofstorage, tmp._endofstorage);
return *this;
}
private:
iterator _start;
iterator _finish;
iterator _endofstorage;
};
}同样的,list也能这样初始化。
3:变量类型推导
3.1:auto推导类型
vector<int> v(10, 0);
vector<int>::iterator it1 = v.begin();
auto it2 = v.begin();
map<string, string> m;
map<string, string>::iterator it1 = m.begin();
auto it2 = m.begin();auto可以实现自动类型判断,但也并非万能。
3.2:decltype
该关键字可以将变量声明为表达式指定的类型。如:
template<class T1,class T2>
void Func(T1 x, T2 y)
{
decltype(x * y) ret = x * y;
cout << ret << endl;
}T1和T2可能是两个不同的非类型模板参数,比如int和double相乘,如果用T1或者T2去声明ret,就会有结果误差。因此decltype可以精准的推导出x*y的类型。
void Func(T1 x, T2 y)
{
decltype(x * y) ret = x * y;
auto ret2 = x * y;
cout << ret <<" "<< ret2 << endl;
}
Func(1, 2.2);
Func(1, 3);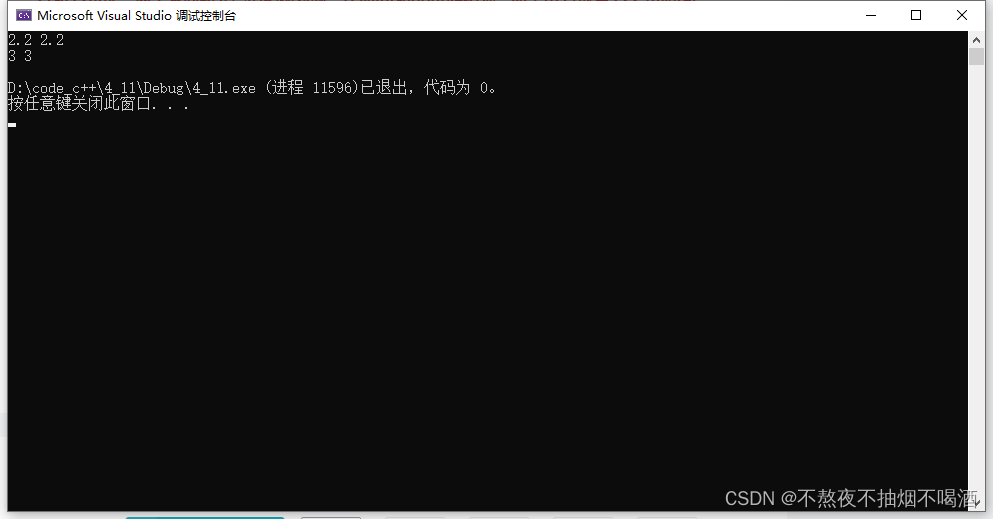
这里auto一样可以推导类型,所以decltype在auto不能起作用的地方起作用,实际上意义不大,但是要认识这个关键字。
3.3:nullptr
#ifndef NULL
#ifdef __cplusplus
#define NULL 0
#else
#define NULL ((void *)0)
#endif
#endifc++中有人将NULL定义为0,所以在某些地方判断条件的时候用NULL会有bug,因此如果想判断某个指针为空,需要使用nullptr。
4:范围for
一个比较实用的语法糖,
有3个条件
- 迭代范围需确定
- 需要写出迭代器的begin和end接口,左闭右开
- 迭代器需要支持++和==
void TestFor(int array[])
{
for(auto& e : array)
cout<< e <<endl;
}这个就不能迭代,因为array的范围不确定。
5:STL新增容器和容器新增接口

最下面2个应该不陌生,是比较方便查找的哈希表。
5.1:array
array是一个静态数组,相比较于c语言中的数组,多了一个越界写可以检查出来的机制。
int arr[10];
arr[10];
arr[20] = 1;c语言中的数组越界读没问题,而越界写则是随机检查。

int arr[10];
arr[10];
arr[20] = 1;
arr[10] = 1;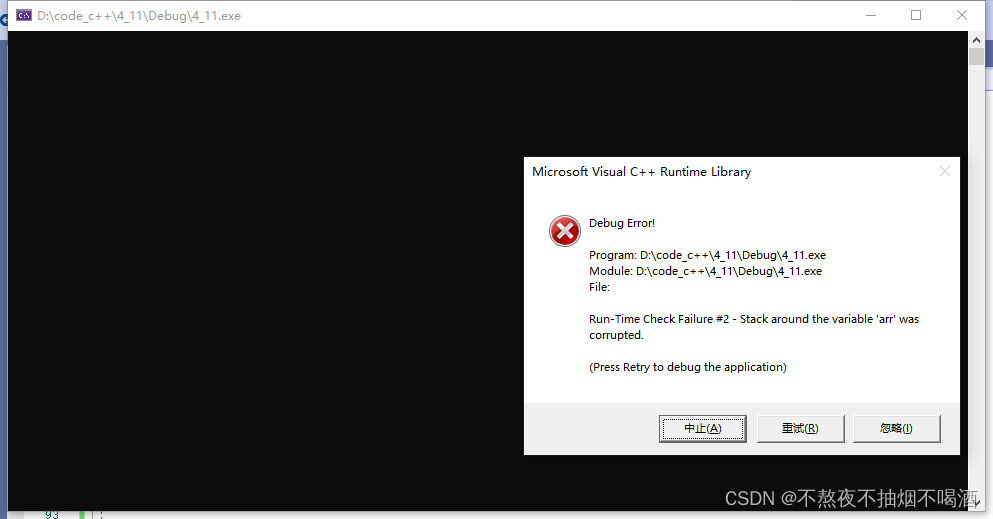
当对10下标的元素进行写的时候,报错,对20下标不报错。因此C语言的数组只能随机对写进行检查。对读不检查。
而array既能对读检查,也能对写检查。
array<int,10> a;
a[10];
读报错。
array<int,10> a;
a[10] = 1;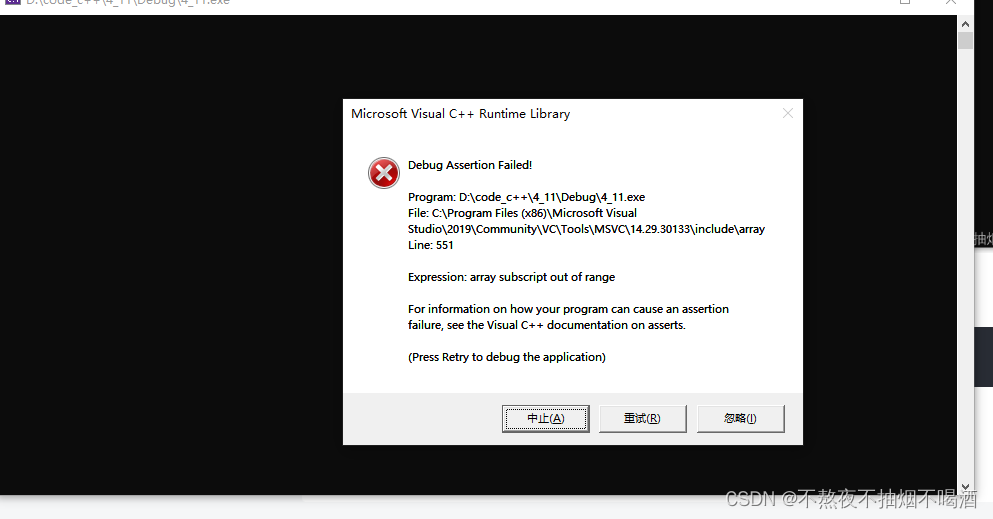
写报错。
但是其实这样不如使用我们的vector。
6:左值引用和右值引用
6.1:左值
左值:是一个数据的表达式(如变量名或者指针解引用),可以在该语句之后还能获取到他的地址,能对他进行取地址和赋值操作,左值既可以在赋值符号左边,也可以在右边。
// 以下的p、b、c、*p都是左值
int* p = new int(0);
int b = 1;
const int c = 2;
// 以下几个是对上面左值的左值引用
int*& rp = p;
int& rb = b;
const int& rc = c;
int& pvalue = *p;6.2:右值
右值:也是一个数据表达式,通常比如:字面常量,传值返回的函数的返回值,表达式返回值。
double x = 1.1, y = 2.2;
// 以下几个都是常见的右值
10;
x + y;
fmin(x, y);
// 以下几个都是对右值的右值引用
int&& rr1 = 10;
double&& rr2 = x + y;
double&& rr3 = fmin(x, y);
// 这里编译会报错:error C2106: “=”: 左操作数必须为左值
10 = 1;
x + y = 1;
fmin(x, y) = 1;
fmin的函数返回值不能是左值引用,否则该返回值就不是右值。
double x = 1.1, y = 2.2;
int&& rr1 = 10;
const double&& rr2 = x + y;
rr1 = 20;
rr2 = 5.5; // 报错6.3:左值引用
- 左值引用只能引用左值。
- const左值引用既可以引用左值,也可以引用右值。
int a = 10;
const int& x1 = a;
const int& x2 = 10;6.4:右值引用
- 右值引用只能引用右值。
- 右值可以引用左值move之后的值。
int a = 10;
int&& x1 = 10;
int&& x2 = std::move(a);6.5:左值引用的场景和短板
用于函数引用传参,和传引用返回,可以减少拷贝。
namespace wjw
{
const string& to_string(const string& x)
{
return x;
}
}
wjw::to_string("abcd");x是一个静态变量,可以直接返回x,且传引用返回没问题,减少值拷贝。但是如果碰到下面的情况呢?
const string& to_string(const string& x)
{
string str;
return str;
}这样写就有很大的问题,str是一个局部变量,出了函数作用域就会销毁,这里用左值引用返回就是返回一个已经销毁的变量,很明显不行。
所以需要使用传值返回,但是如果是传值返回,我们在函数栈帧学过,返回临时变量的时候,会创建一个临时变量,再把str拷贝构造给临时变量,这样就多了一次拷贝,这个时候就需要使用右值引用返回。

这里分为2步:
- 创建临时对象,str拷贝构造给临时对象,临时对象拷贝构造给ret2,因为这个时候ret2是正在创建的,不是已经创建好的(所以ret2=这一步是拷贝构造,不是赋值重载)这里是一个拷贝构造+拷贝构造,编译器会自动优化成一次拷贝构造,就是将ret直接拷贝构造给ret2。
6.5.1:编译器关于构造的优化场景回顾
void f1(A aa)
{}
A f2()
{
A aa;
return aa;
}
int main()
{
// 传值传参
A aa1;
f1(aa1);
cout << endl;
// 传值返回
f2();
cout << endl;
// 隐式类型,连续构造+拷贝构造->优化为直接构造
f1(1);
// 一个表达式中,连续构造+拷贝构造->优化为一个构造
f1(A(2));
cout << endl;
// 一个表达式中,连续拷贝构造+拷贝构造->优化一个拷贝构造
A aa2 = f2();
cout << endl;
// 一个表达式中,连续拷贝构造+赋值重载->无法优化
aa1 = f2();
cout << endl;6.6:右值引用场景一:移动构造

前面说过,连续的拷贝构造编译器会优化成一个拷贝构造,因为to_string是传值返回,返回值是一个右值,用这个右值去拷贝构造ret2,因为ret2的拷贝构造函数的参数是一个const左值引用,所以没有编译错误,这里就是调用了一个深拷贝。
拷贝的代价太大了如何解决?
str反正是一个要销毁的变量了,我们何妨不直接把他的资源偷窃给ret2呢?这里需要用到右值引用.。
string(string&& s)
:_str(nullptr)
,_size(0)
,_capacity(0)
{
cout<<"string(string&& s)"<<"移动语义"<<endl;
swap(s);
}c++中的右值有2种

顾名思义,str是一个即将销毁的变量,我们直接对他进行引用,把他的资源偷窃给_str,就无需使用拷贝构造了。
6.7:右值引用场景二:移动赋值
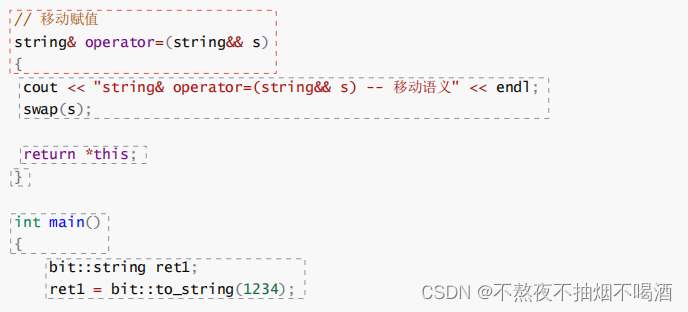
ret1是已经创建好的变量,之前说过拷贝构造+赋值重载不能进行优化,所以这里会发生2个步骤,先创建一个临时对象,编译器在这里会很聪明的把str的返回值识别成一个右值,这样的话临时对象就不会调用拷贝构造str,而是直接移动构造str,然后再把临时对象作为to_string的返回值赋值给ret1。所以结果会是一个移动构造+一个移动赋值
这里总结: