原文:Mobile Deep Learning with TensorFlow Lite, ML Kit and Flutter
协议:CC BY-NC-SA 4.0
译者:飞龙
本文来自【ApacheCN 深度学习 译文集】,采用译后编辑(MTPE)流程来尽可能提升效率。
不要担心自己的形象,只关心如何实现目标。——《原则》,生活原则 2.3.c
一、移动深度学习简介
在本章中,我们将探索移动设备上深度学习的新兴途径。 我们将简要讨论机器学习和深度学习的基本概念,并将介绍可用于将深度学习与 Android 和 iOS 集成的各种选项。 本章还介绍了使用本机和基于云的学习方法进行深度学习项目的实现。
在本章中,我们将介绍以下主题:
- 基于人工智能(AI)的移动设备的发展
- 了解机器学习和深度学习
- 介绍一些常见的深度学习架构
- 强化学习和自然语言处理(NLP)简介
- 在 Android 和 iOS 上集成 AI 的方法
人工智能移动设备的增长
AI 变得比以前更加移动,因为更小的设备具有更多的计算能力。 移动设备原本仅用于拨打电话和发送短信,但随着 AI 的引入,如今已转变为智能手机。 这些设备现在能够利用 AI 不断增强的功能来学习用户的行为和喜好,增强照片,进行全面的对话等等。 人工智能驱动的智能手机的功能预计只会一天一天地增长。 根据 Gartner 的数据,到 2022 年,80% 的智能手机将支持 AI。
支持 AI 的硬件变化
为了应对 AI 的高计算能力,对手机的硬件支持进行了定期更改和增强,以使他们具有思考和行动的能力。 移动制造公司一直在不断升级移动设备上的硬件支持,以提供无缝和个性化的用户体验。
华为已经发布了麒麟 970 SoC,该芯片可以使用专门的神经网络处理单元来实现设备上的 AI 体验。 苹果设备装有称为神经引擎的 AI 芯片,该芯片是 A11 Bionic 芯片的一部分。 它专用于机器学习和深度学习任务,例如面部和语音识别,记录动画和拍摄照片时的对象检测。 高通公司和联发科已经发布了他们自己的芯片,这些芯片支持设备上的 AI 解决方案。 三星宣布的 Exynos 9810 是一种基于神经网络的芯片,例如高通的 Snapdragon 845。 2018 年的三星设备 Galaxy S9 和 S9+ 包括这些基于其销售国家/地区的芯片。 借助 Galaxy S9,该公司非常明显地表明它将集成 AI 以改善设备相机的功能和实时文本翻译。 最新的三星 Galaxy S10 系列由 Qualcomm Snapdragon 855 提供支持,以支持设备上的 AI 计算。
Google Translate Word Lens 和 Bixby 个人助理已用于开发该功能。 有了这些技术,该设备即可翻译多达 54 种语言。 这些电话足够智能,可以在 f/2.4 和 f/1.5 的传感器之间进行选择,非常适合在弱光条件下拍摄照片。 Google Pixel 2 利用其机器学习的强大功能,通过其协处理器 Pixel Visual Core 集成了八个图像处理单元。
为什么移动设备需要使用 AI 芯片?
集成 AI 芯片不仅有助于提高效率和计算能力,而且还保留了用户的数据和隐私。 在移动设备上包含 AI 芯片的优势可以列举如下:
- 性能:当前日期中移动设备的 CPU 不适合机器学习的需求。 尝试在这些设备上部署机器学习模型通常会导致服务速度缓慢和电池消耗更快,从而导致不良的用户体验。 这是因为 CPU 缺乏执行 AI 计算所需的大量小型计算的效率。 AI 芯片类似于负责处理设备上图形的图形处理器(GPU)芯片,提供了单独的空间来执行与机器学习和深度学习过程专门相关的计算 。 这使 CPU 可以将时间集中在其他重要任务上。 通过合并专用的 AI 硬件,设备的性能和电池寿命得到了改善。
- 用户隐私:硬件还确保提高用户隐私和安全性。 在传统的移动设备中,数据分析和机器学习过程将需要将用户数据的大块发送到云中,从而威胁到用户数据隐私和移动设备的安全性。 借助设备上的 AI 芯片,可以在设备本身上离线执行所有必需的分析和计算。 在移动设备中包含专用硬件的这种方式极大地降低了用户数据被黑或泄漏的风险。
- 效率:在现实世界中,通过集成 AI 芯片,诸如图像识别和处理之类的任务可能会快得多。 华为的神经网络处理单元就是一个很好的例子。 它能够以每秒 2,000 张图片的效率识别图像。 该公司声称这比标准 CPU 所花费的时间快 20 倍。 当使用 16 位浮点数时,它可以执行 1.92 teraflops 或每秒 1 万亿次浮点运算。 苹果公司的神经引擎每秒可处理约 6000 亿次操作。
- 经济性:设备上的 AI 芯片减少了将数据发送到云中的需求。 此功能使用户可以脱机访问服务并保存数据。 因此,可以避免使用应用的人为服务器付费。 这对用户和开发人员都是有利的。
让我们简要概述一下移动设备上的 AI 如何影响我们与智能手机交互的方式。
在移动设备上使用 AI 改善用户体验
人工智能的使用极大地增强了移动设备上的用户体验。 可以将其大致分为以下几类。
个性化
个性化主要是指修改服务或产品以适合特定个人的偏好,有时与个人集群有关。 在移动设备上,使用 AI 通过使设备和应用适应用户的习惯及其独特的个人资料(而不是面向通用个人资料的应用)来帮助改善用户体验。 移动设备上的 AI 算法利用可用的特定于用户的数据(例如位置,购买历史记录和行为模式)来预测和个性化当前和将来的交互,例如在一天的特定时间段内用户的首选活动或音乐。
例如,AI 收集有关用户购买历史的数据,并将其与从在线流量,移动设备,电子设备中嵌入的传感器和车辆中获得的其他数据进行编译。 然后,这些经过编译的数据将用于分析用户的行为,并允许品牌采取必要的措施来提高用户参与率。 因此,用户可以利用基于 AI 的应用的好处来获得个性化的结果,这将减少他们的滚动时间,并让他们探索更多的产品和服务。
最好的例子是通过购物平台(如沃尔玛,亚马逊)或媒体平台(如 YouTube 或 Netflix)运行的推荐系统。
2011 年,亚马逊报告的销售额增长了 29%,从 99 亿美元增至 128.3 亿美元。 凭借最成功的推荐率,亚马逊 35% 的销售额来自遵循其产品推荐引擎生成的推荐的客户。
虚拟助手
虚拟助手是一种可以理解语音命令并为用户完成任务的应用。 他们能够使用自然语言理解(NLU)来解释人的语音,并且通常会通过合成语音进行响应。 您可能会使用虚拟助手来完成真正的私人助手为您执行的几乎所有任务,即代表您打电话给他人,记下您指定的笔记,打开或关闭家中的电灯/ 在家庭自动化的帮助下办公,为您播放音乐,甚至只是与您讨论您想谈论的任何话题! 虚拟助手可能能够接受文本,音频或视觉手势形式的命令。 虚拟助手会随着时间的推移适应用户习惯并变得更聪明。
利用 NLP 的功能,虚拟助手可以识别口头语言的命令,并从您上传到助手或保存在他们可以访问的任何在线相册中的图像中识别人和宠物。
目前市场上最受欢迎的虚拟助手是亚马逊上运行的 Amazon Alexa,Google 助手,iPhone 的 Siri,微软的 Cortana 和在三星设备上运行的 Bixby。 一些虚拟助手是被动监听器,仅当他们收到特定的唤醒命令时才响应。 例如,可以使用“嘿谷歌”或“确定谷歌”激活 Google 助手,然后使用“关闭卧室灯”命令关闭谷歌助手,或者使用来从联系人列表中呼叫某人。 “打给”。 在 Google IO '18 中,Google 推出了双工电话预订 AI,这表明 Google Assistant 不仅能够拨打电话,而且还可以进行对话并有可能独自在美发沙龙中进行预订 。
虚拟助手的使用呈指数增长,预计到 2021 年将达到 18 亿用户。54% 的用户同意虚拟助手有助于简化日常任务,而 31% 的人已经在日常生活中使用助手。 此外,有 64% 的用户将虚拟助手用于多个目的。
面部识别
足以识别或验证面部或从数字图像和视频中识别面部表情的技术被称为面部识别。 该系统通常通过将给定图像中最常见和最显着的面部特征与数据库中存储的面部进行比较来工作。 面部识别还具有根据个人的面部纹理和形状来理解图案和变化的能力,以唯一地识别一个人,通常被称为基于 AI 的生物识别应用。
最初,面部识别是计算机应用的一种形式。 但是,近来它在移动平台上被广泛使用。 面部识别以及诸如指纹和虹膜识别之类的生物识别技术在移动设备的安全系统中得到了普遍的应用。 通常,人脸识别过程分两个步骤进行:特征提取和选择是第一步,对象分类是第二步。 后来的发展引入了其他几种方法,例如使用面部识别算法,三维识别,皮肤纹理分析和热像仪。
Apple 的 iPhone X 中引入的 Face ID 是生物识别认证的后继产品,是几种基于 Android 的智能手机中基于指纹的认证系统的继任者。 人脸 ID 的人脸识别传感器由两部分组成:Romeo模块和Juliet模块。 Romeo 模块负责将 30,000 多个红外点投射到用户的脸上。 该模块的对应部分Juliet 模块,读取用户面部上的点形成的图案。 然后将图案发送到设备 CPU 中的设备上Secure Enclave模块,以确认面部是否与所有者匹配。 苹果无法直接访问这些面部图案。 当用户闭上眼睛时,系统不允许授权工作,这是增加的安全性。
该技术从用户外观的变化中吸取教训,并可以用于化妆,胡须,眼镜,太阳镜和帽子。 它也可以在黑暗中工作。 泛光照明器是专用的红外闪光灯,可将不可见的红外光投射到用户的脸上,以正确读取面部表情,并帮助系统在弱光条件下甚至在完全黑暗的情况下运行。 与 iPhone 相反,三星设备主要依赖于二维面部识别,并带有虹膜扫描仪,该虹膜扫描仪可在 Galaxy Note 8 中用作生物识别。印度领先的高级智能手机销售商 OnePlus 也仅依赖于二维面部识别。
到 2023 年,利用面部识别的软件全球市场预计将从 2017 年的 38.5 亿美元增长到 97.8 亿美元。亚太地区是增长最快的地区,其市场份额约为 16%。
人工智能相机
相机中的 AI 集成使他们能够识别,理解和增强场景和照片。 AI 摄像机能够理解和控制摄像机的各种参数。 这些相机基于称为计算摄影的数字图像处理技术的原理工作。 它使用算法而不是光学过程来寻求使用机器视觉来识别和改善图片内容。 这些相机使用深度学习模型,这些模型在包含数百万个样本的巨大图像数据集上进行训练,可自动识别场景,光线的可用性以及所捕获场景的角度。
当相机指向正确的方向时,相机的 AI 算法将接管更改相机的设置,以产生最佳质量的图像。 在幕后,实现 AI 摄影的系统并不简单。 所使用的模型经过高度优化,可在检测到几乎实时捕获的场景特征时产生正确的相机设置。 它们还可以添加动态曝光,颜色调整以及图像的最佳效果。 有时,图像可能会由 AI 模型自动进行后处理,而不是在单击照片时进行处理,以减少设备的计算开销。
如今,移动设备通常配备双镜头相机。 这些相机使用两个镜头在照片上添加散景效果(日语中为“模糊”)。 背景虚化效果为主要拍摄对象周围的背景增添了模糊感,使其在美学上令人愉悦。 基于 AI 的算法有助于模拟识别对象的效果,并使剩余部分模糊,从而产生人像效果。
Google Pixel 3 相机可以在 Top Shot 和 Photobooth 两种拍摄模式下工作。 相机最初在用户尝试捕获之前和之后捕获几帧。 然后,设备中可用的 AI 模型就可以选择最佳帧。 通过为相机的图像识别系统提供大量训练,使之成为可能,然后,该系统便能够选择看上去最好的图片,几乎就像人在捡照片一样。 照相棚模式允许用户简单地将设备对准动作场景,并在相机预测为图像完美的时刻自动拍摄图像。
预测文本
预测文本是一种输入技术,通常在消息传递应用中使用,根据输入的单词和短语向用户建议单词。 每次按键后的预测都是唯一的,而不是以相同的恒定顺序产生重复的字母序列。 预测性文本可以通过一次按键即可输入整个单词,从而可以大大加快输入过程。 这使得输入书写任务(例如键入文本消息,编写电子邮件或使用较少的设备键来使地址簿中的条目高效输入)成为可能。 预测文本系统将用户的首选界面样式与他们学习预测文本软件的能力水平联系在一起。 通过分析和适应用户的语言,系统最终变得更智能。 T9 词典是此类文本预测器的一个很好的例子。 它分析使用的单词的频率,并生成多个最可能的单词。 它也能够考虑单词的组合。
快速类型是苹果公司在其 iOS 8 版本中宣布的一种预想性文本功能。 它使用机器学习和 NLP,这使软件可以根据用户的打字习惯来构建自定义词典。 这些词典随后用于预测。 这些预测系统还取决于对话的上下文,并且能够区分正式和非正式语言。 此外,它支持全球多种语言,包括美国英语,英国英语,加拿大英语,澳大利亚英语,法语,德语,意大利语,巴西葡萄牙语,西班牙语和泰语。
Google 还推出了一项新功能,该功能将帮助用户比以前更快地撰写和发送电子邮件。 名为 Smart Compose 的功能可以理解键入的文本,以便 AI 可以建议单词和短语来完成句子。 智能撰写功能可通过纠正拼写错误和语法错误以及建议用户最常用的单词,帮助用户节省编写电子邮件的时间。 智能回复是另一个功能,类似于 LinkedIn 消息中的回复建议,该建议根据用户接收到的电子邮件的上下文,建议单击一次即可发送的回复。 例如,如果用户收到一封祝贺他们接受的应用的电子邮件,则“智能回复”功能可能会提供以下选项来进行回复:“谢谢!”,“谢谢让我知道”和“谢谢您” 接受我的申请。” 然后,用户可以单击首选答复并发送快速答复。
在 1940 年代,林语堂创建了一种打字机,其中的启动键会根据所选字符提示字符。
使用 AI 的最受欢迎的移动应用
近年来,我们看到将 AI 集成到其功能中以增加用户参与度和定制服务交付的应用数量激增。 在本节中,我们将简要讨论移动应用领域中一些最大的参与者如何利用 AI 的优势来促进其业务发展。
Netflix
Netflix 是移动应用中机器学习的最佳和最受欢迎的例子。 该应用使用线性回归,逻辑回归和其他机器学习算法为用户提供完美的个性化推荐体验。 按演员,体裁,时长,评论,年等分类的内容用于训练机器学习算法。 所有这些机器学习算法都会学习并适应用户的动作,选择和偏好。 例如,约翰看了一个新电视连续剧的第一集,但并不十分喜欢,所以他不会看后续的几集。 Netflix 涉及的推荐系统了解他不喜欢这种电视节目,因此将其从推荐中删除。 同样,如果约翰从推荐列表中选择了第八条推荐,或者在看完电影预告片后写了一篇不好的评论,则所涉及的算法会尝试适应其行为和偏好,以提供极为个性化的内容。
Seeing AI
微软开发的 Seeing AI 是一款智能相机应用,它使用计算机视觉来听觉上帮助盲人和视障人士了解周围的环境。 它具有一些功能,例如为用户读取简短的文本和文档,提供有关人的描述,使用设备的相机识别其他应用中的货币,颜色,笔迹,光线甚至图像。 为了使该应用具有先进的实时响应能力,开发人员采用了使服务器与 Microsoft Cognitive Services 通信的想法。 OCR,条形码扫描仪,面部识别和场景识别是该应用整合在一起的最强大的技术,可为用户提供一系列出色的功能。
Allo
Allo 是 Google 开发的以 AI 为中心的消息传递应用。 自 2019 年 3 月起,Allo 已停产。 但是,这是 Google 推动 AI 应用发展的重要里程碑。 该应用允许用户通过语音在 Android 手机上执行操作。 它使用了智能回复功能,该功能可以通过分析对话的上下文来建议单词和短语。 该应用不仅限于文本。 实际上,它同样能够分析对话期间共享的图像并提出回复建议。 强大的图像识别算法使之成为可能。 后来,此智能回复功能也在 Google 收件箱中实现,现在已在 Gmail 应用中提供。
英语语音助手
英语语音助手(ELSA)被评为全球基于 AI 的应用排名前五的应用,它是世界上最智能的 AI 语音导师。 该移动应用可以帮助人们提高发音。 它被设计为冒险游戏,按级别进行区分。 每个级别呈现一组供用户发音的单词,将其作为输入。 仔细检查用户的响应以指出他们的错误并帮助他们改进。 当应用检测到错误的发音时,它会通过指示用户嘴唇和舌头的正确运动来教给用户正确的发音,以便正确地说出单词。
Socratic
Socratic 是一个导师应用,它允许用户拍摄数学问题,并给出答案以解释其背后的理论,并详细说明应如何解决。 该应用不仅限于数学。 当前,它可以为 23 个不同主题的用户提供帮助,包括英语,物理,化学,历史,心理学和微积分。 该应用使用 AI 的功能来分析所需的信息,并通过分步解决方案返回视频。 该应用的算法与计算机视觉技术相结合,能够读取图像中的问题。 此外,它使用针对数百万个示例问题训练的机器学习分类器,有助于准确预测解决问题所涉及的概念。
现在,让我们更深入地研究机器学习和深度学习。
了解机器学习和深度学习
在能够研究包含与 AI 领域相关的技术和算法的解决方案之前,了解一些机器学习和深度学习的关键概念很重要。 当我们谈论 AI 的当前状态时,我们通常指的是能够搅动大量数据以找到模式并根据这些模式进行预测的系统。
尽管“人工智能”一词可能会带来说话的类人机器人或自动驾驶到外行的图像,但对于研究该领域的人来说,它们可能是互连的计算模块图和网络的形式。
在下一节中,我们将首先介绍机器学习。
了解机器学习
1959 年,亚瑟·塞缪尔(Arthur Samuel)创造了术语机器学习。 在他对机器学习的定义的轻描淡写中,使机器能够从过去的经验中学习并在提供未知输入的情况下基于它们进行预测的计算机科学领域称为机器学习。
机器学习的更精确定义可以描述如下:
- 通过学习有关任务
T的经验E来提高其在任何任务T上的性能P的计算机程序,称为机器学习程序。 - 使用前面的定义,在目前类似的情况下,
T是与预测有关的任务,而P是计算机程序在执行任务T时所达到的准确率度量,基于程序能够学习的内容,该学习称为E。 随着E的增加,计算机程序会做出更好的预测,这意味着P得到改善,因为该程序以更高的精度执行任务T。 - 在现实世界中,您可能会遇到一位老师在教学生执行特定任务,然后通过让学生参加考试来评估学生执行任务的技能。 学生接受的训练越多,他们执行任务的能力就越好,并且他们的考试成绩也就越高。
在下一节中,让我们尝试了解深度学习。
了解深度学习
我们已经很长时间听到了学习一词,并且在某些情况下通常意味着获得执行任务的经验。 但是,以学习为前缀的深度是什么意思?
在计算机科学中,深度学习是指一种机器学习模型,其中涉及多个学习层。 这意味着计算机程序由多种算法组成,数据通过这些算法逐一传递,最终产生所需的输出。
深度学习系统是使用神经网络的概念创建的。 神经网络是连接在一起的神经元层的组成,因此数据从一层神经元传递到另一层,直到到达最终层或输出层。 神经元的每一层以与最初将数据作为输入提供给神经网络的形式相同或不同的形式获取数据输入。
考虑以下神经网络图:
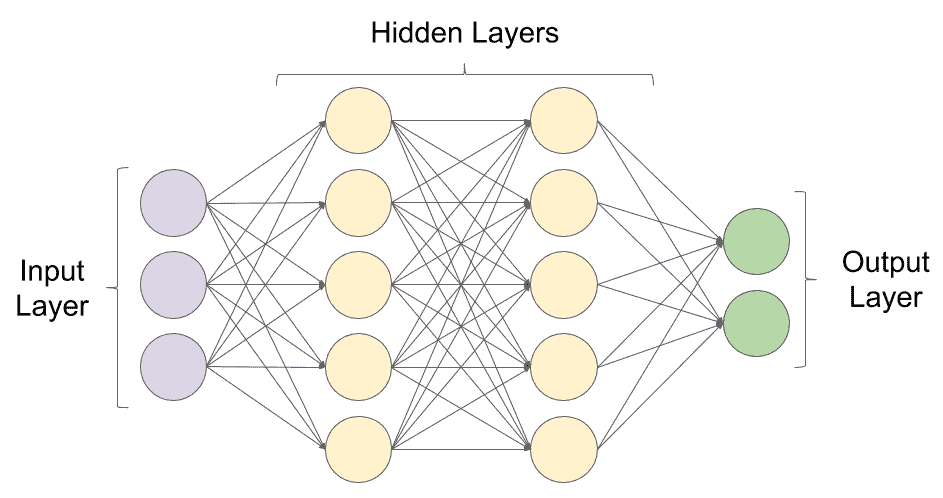
前面的屏幕截图中介绍了一些术语。 让我们简要地讨论其中的每一个。
输入层
保留输入值的层称为输入层。 有人认为该层实际上不是一个层,而仅仅是一个保存数据的变量,因此是数据本身,而不是一个层。 但是,保持该层的矩阵的尺寸很重要,必须正确定义,以使神经网络与第一隐藏层进行通信。 因此,从概念上讲,它是保存数据的层。
隐藏层
输入层和输出层之间的任何中间层都称为隐藏层。 生产环境中使用的典型神经网络可能包含数百个输入层。 通常,隐藏层比输入或输出层包含更多的神经元。 但是,在某些特殊情况下,这可能不成立。 通常会在隐藏层中包含大量神经元,以处理输入以外的维度中的数据。 这使程序可以以用户将其馈入网络时所呈现的格式,以数据的形式获得洞察力或模式,这些数据可能不可见。
神经网络的复杂性直接取决于网络中神经元的层数。 尽管神经网络可以通过添加更多层来发现数据中更深的模式,但它也增加了网络的计算成本。 网络也有可能进入称为过拟合的错误状态。 相反,如果网络太简单,或者说网络不够深,它将到达另一个错误状态,称为欠拟合。
您可以在这个页面上了解有关过拟合和不足的更多信息。
输出层
产生并存储所需输出的最后一层称为输出层。 该层通常对应于所需输出类别的数量,或具有一个包含所需回归输出的单个神经元。
激活函数
神经网络中的每一层都接受称为激活函数的函数。 此函数的作用是将神经元内部包含的数据保持在正常范围内,否则该范围会变得太大或太小,并导致与计算机中大十进制系数或大数的处理有关的计算错误。 另外,激活函数使神经网络能够处理数据中模式的非线性。
一些常见的深度学习架构简介
在对关键术语进行简短修订之后,我们现在准备更深入地研究深度学习领域。 在本节中,我们将学习一些著名的深度学习算法及其工作原理。
卷积神经网络
从动物视觉皮层得到启发,卷积神经网络(CNN)主要用于图像处理,并且实际上已经成为图像处理的标准。 卷积层的核心概念是核(或过滤器)的存在,这些核学习区分图像的特征。 核通常比图像矩阵短得多,并且以滑动窗口的方式传递到整个图像上,从而产生核的点积与待处理图像的相应矩阵切片。 点积使程序可以识别图像中的特征。
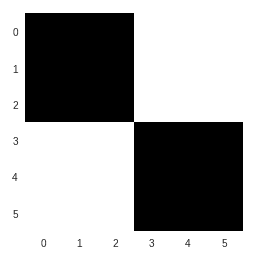
考虑以下图像向量:
[[10, 10, 10, 0, 0, 0],
[10, 10, 10, 0, 0, 0],
[10, 10, 10, 0, 0, 0],
[0, 0, 0, 10, 10, 10],
[0, 0, 0, 10, 10, 10],
[0, 0, 0, 10, 10, 10]]
前面的矩阵对应于如下图像:
在应用过滤器检测水平边缘时,过滤器由以下矩阵定义:
[[1, 1, 1],
[0, 0, 0],
[-1, -1, -1]]
原始图像与过滤器卷积后产生的输出矩阵如下:
[[ 0, 0, 0, 0],
[ 30, 10, -10, -30],
[ 30, 10, -10, -30],
[ 0, 0, 0, 0]]
在图像的上半部或下半部没有检测到边缘。 从左边缘移到图像的垂直中间时,会发现清晰的水平边缘。 在向右移动时,在水平边缘的另一个清晰实例之前找到了两个水平边缘的不清楚实例。 但是,现在发现的清晰水平边缘的颜色与上一个相反。
因此,通过简单的卷积,可以发现图像文件中的图案。 CNN 还使用其他几个概念,例如池化。
可以从以下屏幕截图中了解池化:
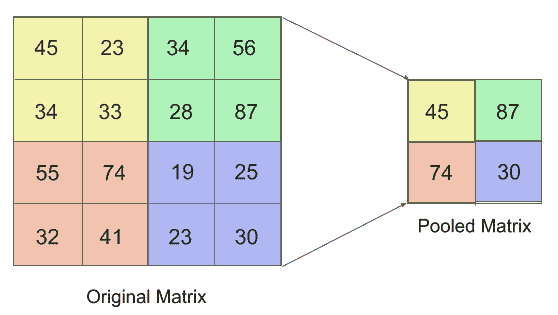
用最简单的术语来说,合并是将多个图像像素合并为单个像素的方法。 前面的屏幕快照中使用的合并方法称为最大池化,其中只有来自所选滑动窗口核的最大值保留在所得矩阵中。 这极大地简化了图像,并有助于训练通用且不是单个图像专用的过滤器。
生成对抗网络
生成对抗网络(GAN)是 AI 领域中一个相当新的概念,并且最近已成为一项重大突破。 它们是由 Ian Goodfellow 在 2014 年的研究论文中介绍的。GAN 的核心思想是两个相互竞争的神经网络的并行运行。 第一个神经网络执行生成样本的任务,称为生成器。 另一个神经网络尝试根据先前提供的数据对样本进行分类,称为判别器。 可以通过以下屏幕截图了解 GAN 的功能:

在此,随机图像向量经过生成过程以生成伪造图像,然后由已经用真实图像训练的判别器对伪造图像进行分类。 具有较高分类置信度的伪图像将进一步用于生成,而具有较低置信度的伪图像将被丢弃。 随着时间的流逝,判别器学会正确识别伪造的图像,而生成器学会在每一代之后逐渐生成与真实图像相似的图像。
在学习结束时,我们将拥有一个可以产生近乎真实数据的系统,以及一个可以非常精确地对样本进行分类的系统。
在接下来的章节中,我们将了解有关 GAN 的更多信息。
对于 GAN 的深入研究,您可以阅读 Ian Goodfellow 在这个页面上发表的研究论文。
循环神经网络
并非世界上所有数据都独立于时间而存在。 股市价格和口语/书面文字只是与时间序列相关的数据的几个示例。 因此,数据序列具有时间维度,您可能会假设能够以适合数据的方式使用它(随时间的流逝而不是保持不变的数据块)会更直观,更直观。 会产生更好的预测精度。 在许多情况下,这是事实,并导致了神经网络架构的出现,在学习和预测时可能需要时间。
一种这样的架构是循环神经网络(RNN)。 这种网络的主要特征是它不仅以顺序的方式将数据从一层传递到另一层,而且还从任何先前的层获取数据。 回顾“了解机器学习和深度学习”部分的示意图,该图具有两个隐藏层,是一个简单的人工神经网络(ANN)。 数据仅由上一层馈入下一层。 在具有两个隐藏层的 RNN 中,并非强制要求仅由第一隐藏层提供对第二隐藏层的输入,就像在简单的 ANN 中那样。
以下屏幕截图中的虚线箭头表示了这一点:

与简单的 ANN 相比,RNN 使用一种称为时间上的反向传播(BPTT)的方法,而不是 ANN 中的经典反向传播。 BPTT 通过在与网络中必须重复出现的输入有关的函数中定义时间,从而确保在错误的反向传播中很好地表示时间。
长期记忆
在 RNN 中观察到消失和爆炸梯度非常普遍。 在深度 RNN 的实现中,这是一个严重的瓶颈,在深度 RNN 中,数据以特征之间的关系比线性函数更复杂的形式存在。 为了克服消失的梯度问题,德国研究人员 Sepp Hochreiter 和 Juergen Schmidhuber 于 1997 年提出了长短期记忆(LSTM)的概念。
LSTM 已被证明在 NLP,图像标题生成,语音识别和其他领域中非常有用,在引入后,LSTM 打破了先前建立的记录。 LSTM 将信息存储在网络外部,可以随时调用,就像计算机系统中的辅助存储设备一样。 这允许将延迟的奖励引入网络。 对 LSTM 进行了精神上的类比,称其为一个人因过去所采取的行动而获得的“业力”或报酬。
在本书的后续章节中,我们将更深入地研究 LSTM 和 CNN。
强化学习和自然语言处理简介
在本节中,我们将研究强化学习和自然语言处理的基本概念。 这些是 AI 领域中非常重要的主题。 他们可能会也可能不会使用深度学习网络来实现,但是通常会使用深度网络来实现。 因此,了解它们的功能至关重要。
强化学习
强化学习是机器学习的一个分支,用于创建 AI“智能体”,以在给定环境中执行一组可能的动作,以使报酬最大化。 机器学习的其他两个分支(有监督的和无监督的机器学习)通常以表的形式在数据集上执行学习,而强化学习智能体通常使用决策树进行学习,以在任何给定情况下进行决策,最终使决策树到达具有最大奖励的叶子。
例如,考虑一个希望学习走路的人形机器人。 它可以首先将其两条腿推到自己的前面,在这种情况下它会掉落,而奖励(在这种情况下,是人形机器人所覆盖的距离)将为 0。然后,它将学会在提出的前一条和提出的下一条之间增加一定的延迟。 由于存在一定程度的延迟,这可能是机器人能够在再次踩踏双脚同时向外并且摔倒之前采取x1的步骤。
强化学习采用探索的概念,这意味着寻求更好的解决方案,而利用的概念则意味着使用先前获得的知识。 继续我们的示例,由于x1大于 0,因此该算法学会了在跨步之间放置大约相同的特定延迟量。 随着时间的推移,在开发和探索的共同作用下,强化学习算法变得非常强大,在这种情况下,类人动物不仅能够学习如何走路,而且还能学习跑步。
自然语言处理
NLP 是 AI 的广阔领域,它通过使用计算机算法来处理和理解人类语言。 NLP 包含几种针对人类语言理解的不同部分的方法和技术,例如,基于两个文本摘录的相似性来理解含义,生成人类语言响应,理解人类语言中提出的问题或指令以及将文本从一种语言翻译到另一种语言。
NLP 已在当今的技术领域中得到了广泛的应用,几家顶尖的技术公司都在朝着该领域迈进。 有几种基于语音的用户助手,例如 Siri,Cortana 和 Google Assistant,它们严重依赖准确的 NLP 才能正确执行其功能。 NLP 还发现可以通过自动客户支持平台在客户支持中使用它们,这些平台可以回答最常见的查询,而无需人工代表来回答。 这些基于 NLP 的客户支持系统在与客户互动时,还可以从真实代表的响应中学习。 在新加坡开发银行创建的 DBS DigiBank 应用的“帮助”部分中,可以找到一种这样的主要部署系统。
目前正在这一领域进行广泛的研究,并有望在未来几天主导 AI 的所有其他领域。 在下一部分中,让我们看一下将深度学习与移动应用集成的当前可用方法。
在 Android 和 iOS 上集成 AI 的方法
随着 AI 的日益普及,移动应用用户希望应用能够适应提供给他们的信息。 使应用适应数据的唯一方法是部署经过微调的机器学习模型,以提供令人愉悦的用户体验。
Firebase ML 套件
Firebase ML Kit 是机器学习软件开发工具包(SDK),可在 Firebase 上为移动开发人员使用。 它促进了移动机器学习模型的托管和服务。 它减少了在移动设备上运行机器学习模型的繁重任务,从而减少了 API 调用,该 API 调用涵盖了常见的移动用例,例如面部检测,文本识别,条形码扫描,图像标记和地标识别。 它只是将输入作为参数,以便输出大量分析信息。 ML Kit 提供的 API 可以在设备上,在云上或在两者上运行。 设备上的 API 独立于网络连接,因此,与基于云的 API 相比,工作速度更快。 基于云的 API 托管在 Google Cloud Platform 上,并使用机器学习技术来提供更高的准确率。 如果可用的 API 无法满足所需的用例,则可以使用 Firebase 控制台构建,托管和提供自定义 TensorFlow Lite 模型。 ML Kit 充当自定义模型之间的 API 层,使其易于运行。 让我们看下面的截图:
在这里,您可以查看 Firebase ML Kit 的仪表板外观。
Core ML
Core ML 是 Apple 在 iOS 11 中发布的一种机器学习框架,用于使在 iOS 上运行的应用(例如 Siri,Camera 和 QuickType)更加智能。 通过提供有效的性能,Core ML 促进了 iOS 设备上机器学习模型的轻松集成,使应用能够根据可用数据进行分析和预测。 Core ML 支持标准的机器学习模型,例如树状集成体,SVM 和广义线性模型。 它包含具有 30 多种类型的神经元层的广泛的深度学习模型。
使用 Vision 框架,可以轻松地将面部跟踪,面部检测,文本检测和对象跟踪等功能与应用集成。 自然语言框架有助于分析自然文本并推导其特定于语言的元数据。 与 Create ML 一起使用时,该框架可用于部署自定义 NLP 模型。 对 GamePlayKit 的支持有助于评估学习的决策树。 Core ML 建立在诸如 Metal 和 Accelerate 之类的底层技术之上,因此非常高效。 这使其可以利用 CPU 和 GPU。 此外,Core ML 不需要活动的网络连接即可运行。 它具有很高的设备上优化能力。 这样可确保所有计算都在设备本身内部离线进行,从而最大程度地减少了内存占用和功耗。
Caffe2
Caffe2 建立在由加州大学伯克利分校开发的用于快速嵌入的原始卷积架构(Caffe)上,是一种轻量级,模块化,可扩展的深度学习框架,由 Facebook 开发。 它可以帮助开发人员和研究人员部署机器学习模型,并在 Android,iOS 和 Raspberry Pi 上提供 AI 驱动的性能。 此外,它支持在 Android Studio,Microsoft Visual Studio 和 Xcode 中进行集成。 Caffe2 带有可互换使用的本机 Python 和 C++ API,从而简化了原型设计和优化过程。 它足够有效地处理大量数据,并且有助于自动化,图像处理以及统计和数学运算。 Caffe2 是开源的,托管在 GitHub 上,它利用社区的贡献来开发新模型和算法。
TensorFlow
TensorFlow 是 Google Brain 开发的开源软件库,可促进高性能数值计算。 由于其灵活的架构,它允许在 CPU,GPU 和 TPU 之间轻松部署深度学习模型和神经网络。 Gmail 使用 TensorFlow 模型来了解邮件的上下文,并通过其广为人知的功能“智能回复”来预测回复。 TensorFlow Lite 是 TensorFlow 的轻量级版本,有助于在 Android 和 iOS 设备上部署机器学习模型。 它利用 Android 神经网络 API 的功能来支持硬件加速。
下图说明了可通过 TensorFlow Lite 用于移动设备的 TensorFlow 生态系统:
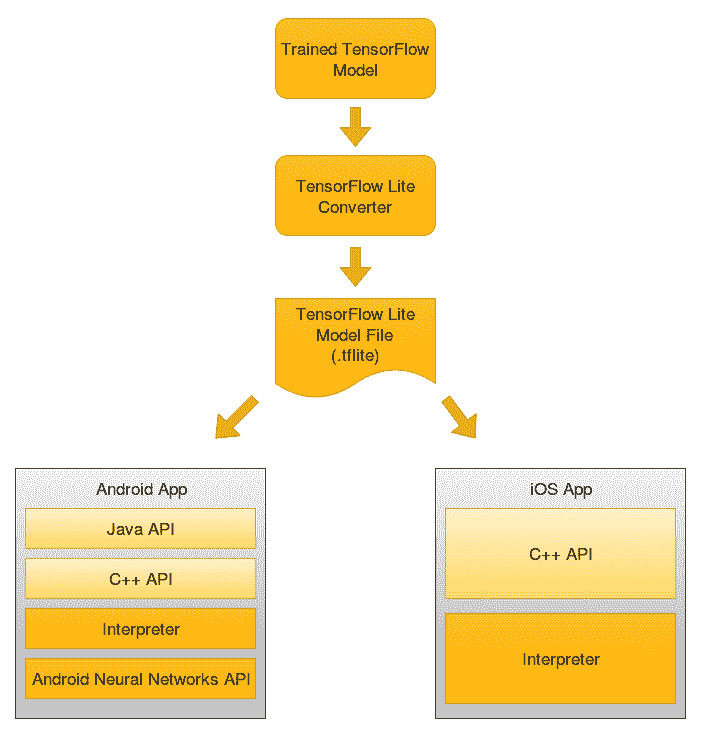
在上图中,您可以看到我们需要将 TensorFlow 模型转换为 TensorFlow Lite 模型,然后才能在移动设备上使用它。 这很重要,因为与优化运行在移动设备上的 Lite 模型相比,TensorFlow 模型体积更大且延迟更大。 转换是通过 TF Lite 转换器执行的,可以通过以下方式使用:
- 使用 Python API:可以使用 Python 和以下任何代码行将 TensorFlow 模型转换为 TensorFlow Lite 模型。
TFLiteConverter.from_saved_model(): Converts SavedModel directories.
TFLiteConverter.from_keras_model(): Converts tf.keras models.
TFLiteConverter.from_concrete_functions(): Converts concrete functions.
- 使用命令行工具:TensorFlow Lite 转换器也可以作为 CLI 工具使用,尽管它的功能与 Python API 版本相比有些不同:
tflite_convert \
--saved_model_dir=/tf_model \
--output_file=/tflite_model.tflite
在接下来的章节中,我们将演示将 TensorFlow 模型转换为 TensorFlow Lite 模型。
总结
在本章中,我们了解了移动设备中 AI 的增长,这使机器无需进行明确编程即可推理和做出决策。 我们还研究了机器学习和深度学习,其中包括与 AI 领域相关的技术和算法。 我们研究了各种深度学习架构,包括 CNN,GAN,RNN 和 LSTM。
我们介绍了强化学习和 NLP,以及在 Android 和 iOS 上集成 AI 的不同方法。 深度学习的基本知识以及如何将其与移动应用集成对于接下来的章节非常重要,在这些章节中,我们将广泛使用该知识来创建一些实际应用。
在下一章中,我们将学习使用设备上模型进行面部检测的知识。
二、移动视觉 - 使用设备上的模型的人脸检测
在本章中,我们将构建一个 Flutter 应用,该应用能够使用 ML Kit 的 Firebase Vision 人脸检测 API 从从设备图库上传的媒体中或直接从相机中检测人脸。 该 API 利用了 Firebase 上托管的预训练模型的功能,并为应用提供了识别面部关键特征,检测表情并获取检测到的面部轮廓的功能。 由于人脸检测是通过 API 实时执行的,因此它还可用于跟踪视频序列,视频聊天或响应用户表情的游戏中的人脸。 用 Dart 编码的应用将在 Android 和 iOS 设备上有效运行。
在本章中,我们将讨论以下主题:
- 图像处理简介
- 使用 Flutter 开发人脸检测应用
让我们先简单介绍一下图像识别的工作原理!
技术要求
您需要带有 Flutter 和 Dart 插件的 Visual Studio Code,并且需要设置 Firebase 控制台。 本章的 GitHub 存储库位于这里。
图像处理简介
在本章中,我们将检测图像中的人脸。 在人工智能的上下文中,为了提取有关该图像的视觉内容的信息而处理图像的动作称为图像处理。
得益于更好的人工智能驱动相机,基于医学图像的机器学习,自动驾驶汽车,人们从图像中分析人的情感以及许多其他应用的数量激增,图像处理是一个新兴领域。
考虑使用自动驾驶车辆进行图像处理。 车辆需要尽可能接近实时地做出决策,以确保最佳的无事故驾驶。 汽车驾驶 AI 模型的响应延迟可能会导致灾难性后果。 已经开发了几种技术和算法来进行快速和准确的图像处理。 图像处理领域中最著名的算法之一是卷积神经网络(CNN)。
我们不会在本章中开发完整的 CNN,但是,我们在 “第 1 章”,“移动深度学习简介”中简要讨论了 CNN。 稍后,我们将使用设备上存在的预训练模型构建面部检测 Flutter 应用。
了解图像
在深入研究图像处理之前,让我们从计算机软件的角度讨论图像的解剖结构。 考虑以下简单图像:

前面的图像是10 x 10像素的图像(放大); 前两行像素为紫色,后六行像素为红色,后两行像素为黄色。
但是,计算机看不到该图像中的颜色。 计算机以像素密度矩阵的形式看到此图像。 我们在这里处理 RGB 图像。 RGB 图像由三层颜色组成,即红色,绿色和蓝色。 这些层中的每一个都由图像中的矩阵表示。 每个矩阵的元素对应于图像的每个像素中该矩阵表示的颜色的强度。
让我们检查程序中的上一个图像。 紫色的两行像素之一由以下数组表示:
[[255, 0, 255],
[255, 0, 255],
[255, 0, 255],
[255, 0, 255],
[255, 0, 255],
[255, 0, 255],
[255, 0, 255],
[255, 0, 255],
[255, 0, 255],
[255, 0, 255]]
在前面的矩阵中,255的第一列表示红色。 第二列代表绿色,第三列代表蓝色。 因此,图像左上角的第一个像素是红色,绿色和蓝色的组合。 红色和蓝色都处于最大强度,而绿色则完全缺失。 因此,正如预期的那样,产生的组合颜色是紫色,基本上是红色和蓝色以相等的比例混合。 如果我们按预期观察到图像红色区域中的任何像素,则会得到以下数组:
[ 255, 0, 0 ]
同样,从黄色区域开始,由于黄色是红色和绿色的等比例组合,因此像素用以下形式表示:
[ 255, 255, 0 ]
现在,如果我们关闭图像的红色和绿色部分,仅打开蓝色通道,则会得到以下图像:

根据我们之前的观察,这非常多,只有前两行像素包含蓝色成分,而图像的其余部分没有蓝色成分,因此将其显示为黑色,这表示没有强度或0 蓝色强度。
处理图像
在本节中,我们将讨论如何对图像进行一些常见的操作以帮助图像处理。 通常,对图像进行一些简单的操作可以导致更快,更好的预测。
旋转
假设我们希望将示例中的图像旋转 90 度。 如果检查旋转后从顶部开始的第一行像素,则可以预期该行的前两个像素为紫色,中间的六个像素为红色,最后两个像素为黄色。 与矩阵旋转类似,这可以看作是转置操作,其中行转换为列,反之亦然。 图像如下所示:

而且,正如预期的那样,第一行像素由以下矩阵表示:
[[255, 0, 255],
[255, 0, 255],
[255, 0, 0],
[255, 0, 0],
[255, 0, 0],
[255, 0, 0],
[255, 0, 0],
[255, 0, 0],
[255, 255, 0],
[255, 255, 0]]
在此矩阵中,前两个元素代表紫色,然后是六个红色,最后两个是黄色。
灰度转换
在对其进行机器学习之前,从图像中完全删除颜色信息通常很有用。 原因是颜色有时不是所要求的预测的促成因素。 例如,在检测图像中数字的系统中,数字的形状很重要,而数字的颜色对解决方案无济于事。
简而言之,灰度图像是对图像区域中可见光的量度。 通常,最占主导地位的浅色元素会被完全去除,以显示可见度较低的区域的对比度。
将 RGB 转换为灰度的公式如下:
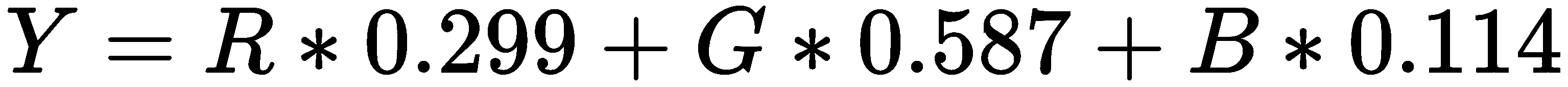
Y是要转换为灰度的像素将保留的最终值。R,G和B是该特定像素的红色,绿色和蓝色值。 产生的输出如下:

现在让我们开始研究面部检测应用!
使用 Flutter 开发人脸检测应用
通过“第 1 章”,“移动深度学习简介”以及如何在最基本的水平上完成图像处理,对 CNN 的工作原理有了基本的了解,我们准备继续使用 Firebase ML Kit 中的预训练模型来检测给定图像中的人脸。
我们将使用 Firebase ML Kit 人脸检测 API 来检测图像中的人脸。 Firebase Vision 人脸检测 API 的主要功能如下:
- 识别并返回检测到的每个脸部的面部特征的坐标,例如眼睛,耳朵,脸颊,鼻子和嘴巴。
- 获取检测到的面部和面部特征的轮廓。
- 检测面部表情,例如一个人在微笑还是闭着眼睛。
- 获取在视频帧中检测到的每个人脸的标识符。 该标识符在调用之间是一致的,可用于对视频流中的特定面孔执行图像处理。
让我们从第一步开始,添加所需的依赖项。
添加发布依赖
我们首先添加发布依赖项。 依赖项是特定功能正常运行所需的外部包。 在pubspec.yaml文件中指定了应用所需的所有依赖项。 对于每个依赖项,都应提及包的名称。 通常在其后跟随一个版本号,指定我们要使用的包的版本。 此外,还可以包括包的源代码,该资源告诉 pub 如何找到该包,以及源代码需要查找该包的任何描述。
要获取有关特定包的信息,请访问这里。
我们将用于此项目的依赖项如下:
-
firebase_ml_vision:一种 Flutter 插件,增加了对 Firebase ML Kit 功能的支持 -
image_picker:Flutter 插件,可使用相机拍照并从 Android 或 iOS 图像库中选择图像
包含依赖项后,pubspec.yaml文件的dependencies部分如下所示:
dependencies:
flutter:
sdk: flutter
firebase_ml_vision: ^0.9.2+1
image_picker: ^0.6.1+4
为了使用我们添加到pubspec.yaml文件的依赖项,我们需要安装它们。 只需在终端中运行flutter pub get或单击pubspec.yaml文件顶部操作区域右侧的“获取包”即可完成此操作。 一旦安装了所有依赖项,我们就可以简单地将它们导入我们的项目中。 现在,让我们看一下本章将要处理的应用的基本功能。
建立应用
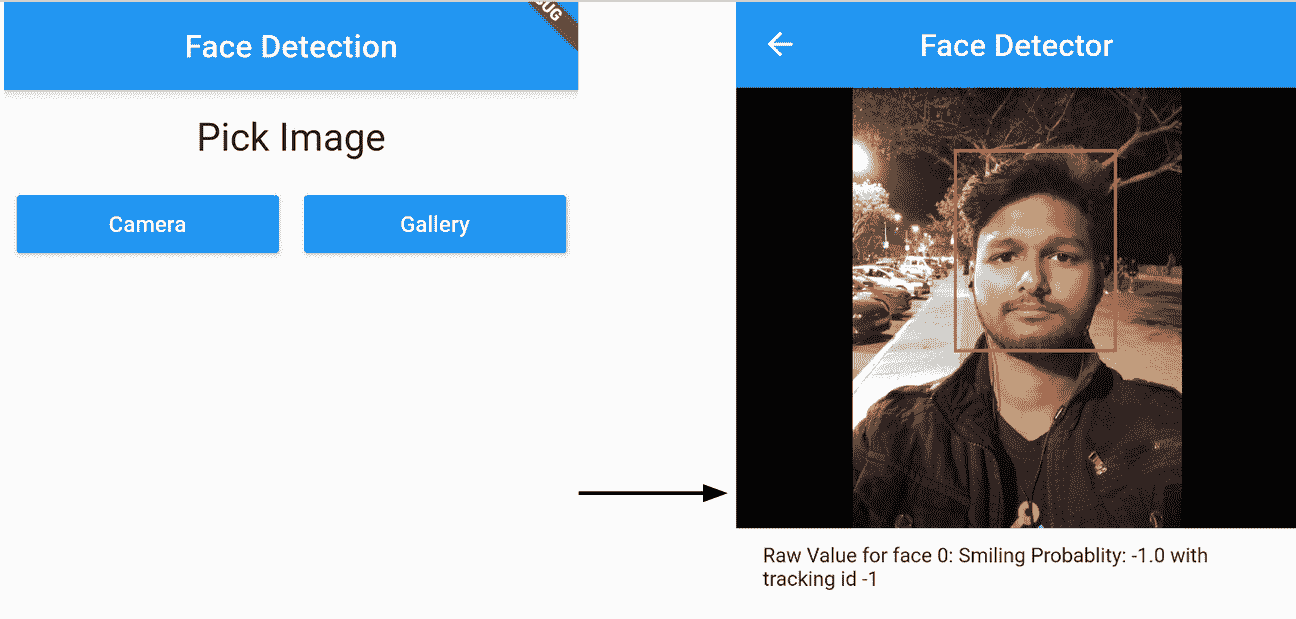
现在我们构建应用。 名为人脸检测的应用将包含两个屏幕。 第一个带有两个按钮的文本标题,允许用户从设备的图片库中选择图像或使用相机拍摄新图像。 此后,用户被引导至第二屏幕,该屏幕显示高亮显示检测到的面部而选择用于面部检测的图像。 以下屏幕截图显示了该应用的流程:
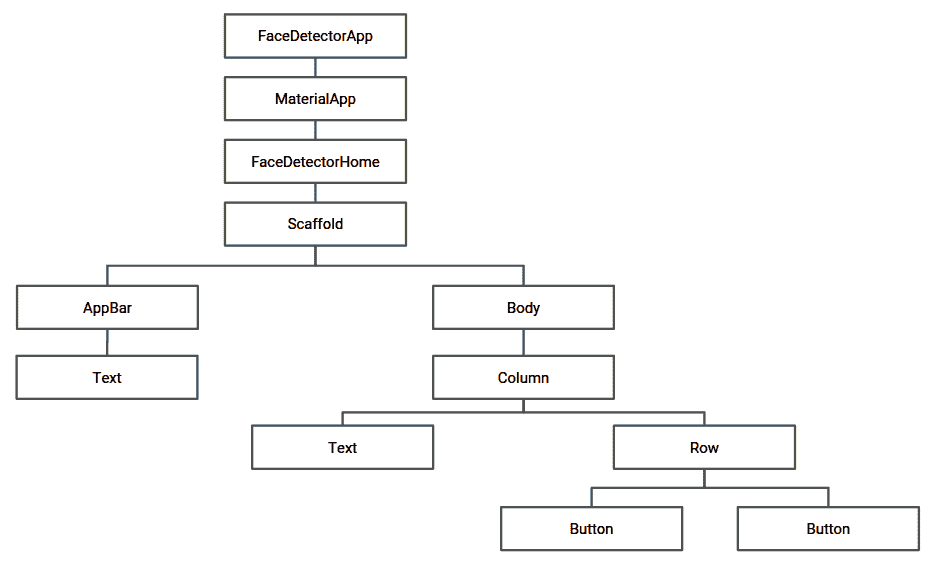
该应用的小部件树如下所示:
现在让我们详细讨论每个小部件的创建和实现。
创建第一个屏幕
在这里,我们创建第一个屏幕。 第一个屏幕的用户界面将包含一个文本标题Pick Image和两个按钮Camera和Gallery。 可以将其视为包含文本标题的列和带有两个按钮的行,如以下屏幕截图所示:
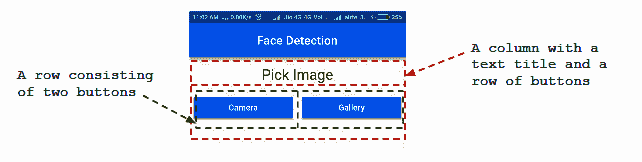
在以下各节中,我们将构建称为小部件的每个元素,然后将它们放在支架下。
用英语讲,支架表示提供某种支持的结构或平台。 就 Flutter 而言,可以将支架视为设备屏幕上的主要结构,所有次要组件(在此情况下为小部件)都可以放置在其上。
在 Flutter 中,每个 UI 组件都是小部件。 它们是 Flutter 框架中的中心类层次结构。 如果您以前使用过 Android Studio,则可以将小部件视为TextView或Button或任何其他视图组件。
建立行标题
然后正在建立行标题。 我们首先在face_detection_home.dart file内创建一个有状态的小部件FaceDetectionHome。 FaceDetectionHomeState将包含构建应用第一个屏幕所需的所有方法。
让我们定义一个称为buildRowTitle()的方法来创建文本标题:
Widget buildRowTitle(BuildContext context, String title) {
return Center(
child: Padding(
padding: EdgeInsets.symmetric(horizontal: 8.0, vertical: 16.0),
child: Text(
title,
style: Theme.of(context).textTheme.headline,
), //Text
) //Padding
); //Center
}
该方法用于使用title字符串中传递的值作为参数来创建带有标题的窗口小部件。 使用Center()将文本水平对齐到中心,并使用EdgeInsets.symmetric(horizontal: 8.0, vertical: 16.0)将文本水平8.0和16.0垂直填充。 它包含一个子级,用于创建带有标题的Text。 文本的印刷样式被修改为textTheme.headline,以更改文本的默认大小,粗细和间距。
Flutter 使用逻辑像素作为度量单位,与与设备无关的像素(dp)相同。 此外,每个逻辑像素中的设备像素的数量可以根据devicePixelRatio来表示。 为了简单起见,我们将仅使用数字项来谈论宽度,高度和其他可测量的属性。
使用按钮小部件构建行
接下来是使用按钮小部件构建行。 放置文本标题后,我们现在将创建一行两个按钮,使用户可以从图库中选择图像或从相机中获取新图像。 让我们按照以下步骤进行操作:
- 我们首先定义
createButton()以创建具有所有必需属性的按钮:
Widget createButton(String imgSource) {
return Expanded(
child: Padding(
padding: EdgeInsets.symmetric(horizontal: 8.0),
child: RaisedButton(
color: Colors.blue,
textColor: Colors.white,
splashColor: Colors.blueGrey,
onPressed: () {
onPickImageSelected(imgSource);
},
child: new Text(imgSource)
),
)
);
}
在提供8.0的水平填充之后,该方法返回一个小部件,即RaisedButton。 按钮的颜色设置为blue,按钮文本的颜色设置为white。 splashColor设置为blueGrey表示通过产生波纹效果来单击按钮。
按下按钮时,将执行onPressed内部的代码段。 在这里,我们调用了onPickImageSelected(),它在本章的后面部分中定义。 按钮内显示的文本设置为imgSource,这里可以是图库或照相机。 此外,整个代码段都包装在Expanded()中,以确保所创建的按钮完全占据所有可用空间。
- 现在,我们使用
buildSelectImageRowWidget()方法来构建带有两个按钮的行,以列出两个图像源:
Widget buildSelectImageRowWidget(BuildContext context) {
return Row(
children: <Widget>[
createButton('Camera'),
createButton('Gallery')
],
);
}
在前面的代码片段中,我们调用先前定义的createButton()方法将Camera和Gallery添加为图像源按钮,并将它们添加到该行的children小部件列表中。
- 现在,让我们定义
onPickImageSelected()。 此方法使用image_picker库将用户定向到图库或照相机以获取图像:
void onPickImageSelected(String source) async {
var imageSource;
if (source == 'Camera') {
imageSource = ImageSource.camera;
} else {
imageSource = ImageSource.gallery;
}
final scaffold = _scaffoldKey.currentState;
try {
final file = await ImagePicker.pickImage(source: imageSource);
if (file == null) {
throw Exception('File is not available');
}
Navigator.push(
context,
new MaterialPageRoute(
builder: (context) => FaceDetectorDetail(file)),
);
} catch (e) {
scaffold.showSnackBar(SnackBar(
content: Text(e.toString()),
));
}
}
首先,使用if-else块将imageSource设置为摄像机或图库。 如果传递的值为Camera,则图像文件的源设置为ImageSource.camera; 否则,将其设置为ImageSource.gallery。
一旦确定了图像的来源,就使用pickImage()来选择正确的imageSource。 如果源是Camera,则将引导用户到相机拍摄图像; 否则,将指示他们从图库中选择图片。
如果pickImage()未成功返回图像,则为处理异常,对该方法的调用包含在try-catch块内。 如果发生异常,则通过调用showSnackBar()将执行定向到catch块和小吃店,并在屏幕上显示错误消息:
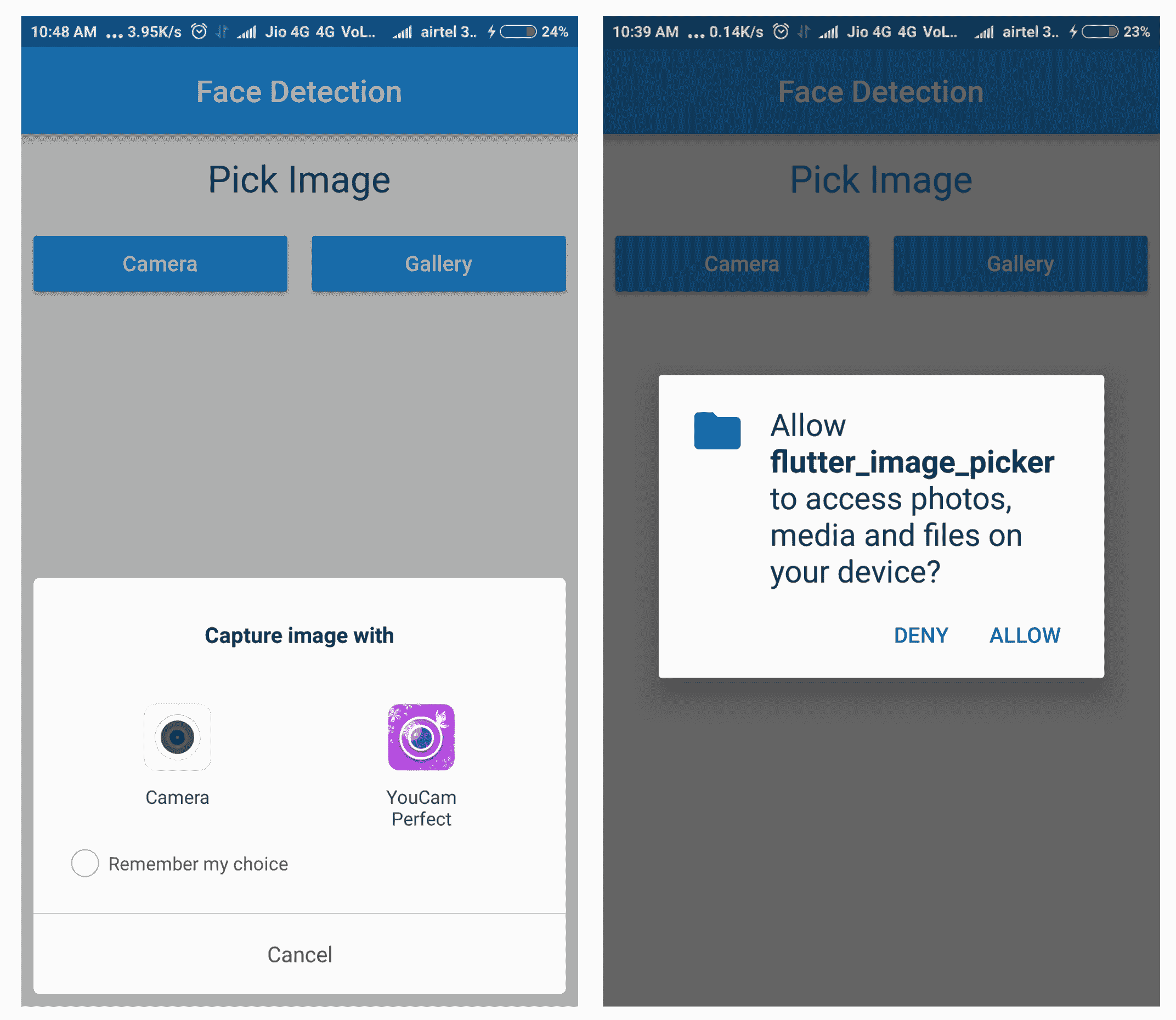
在成功选择图像并且file变量具有所需的uri之后,用户将迁移到下一个屏幕FaceDetectorDetail,这在“创建第二个屏幕”部分中进行了介绍,并使用Navigator.push()将当前上下文和所选文件传递到构造器中。 在FaceDetectorDetail屏幕上,我们用所选图像填充图像支架并显示有关检测到的面部的详细信息。
创建整个用户界面
现在,我们创建了整个用户界面,所有创建的小部件都放在了FaceDetectorHomeState类中被覆盖的build()方法中。
在以下代码片段中,我们为应用的第一个屏幕创建了最终的支架:
@override
Widget build(BuildContext context) {
return Scaffold(
key: _scaffoldKey,
appBar: AppBar(
centerTitle: true,
title: Text('Face Detection'),
),
body: SingleChildScrollView(
child: Column(
children: <Widget>[
buildRowTitle(context, 'Pick Image'),
buildSelectImageRowWidget(context)
],
)
)
);
}
通过在appBar中设置标题,可以将工具栏的文本设置为Face Detection。 另外,通过将centerTitle设置为true,文本将居中对齐。 接下来,支架的主体是一列小部件。 第一个是文本标题,第二个是一行按钮。
可以在这个页面上查看FaceDetectorHome.dart中的整个代码。
创建第二个屏幕
接下来,我们创建第二个屏幕。 成功获取用户选择的图像后,我们迁移到应用的第二个屏幕,在其中显示选择的图像。 此外,我们使用 Firebase ML Kit 标记在图像中检测到的面部。 我们首先在新的 Dart 文件face_detection.dart中创建一个名为FaceDetection的有状态小部件。
获取图像文件
首先,需要将所选图像传递到第二个屏幕进行分析。 我们使用FaceDetection()构造器执行此操作。
构造器是用于初始化类变量的特殊方法。 它们与类具有相同的名称。 构造器没有返回类型,并且在创建类的对象时会自动调用它们。
我们声明一个file变量,并使用参数化的构造器对其进行初始化,如下所示:
File file;
FaceDetection(File file){
this.file = file;
}
现在让我们继续下一步。
分析图像来检测面部
现在,我们分析图像以检测面部。 我们将创建FirebaseVision人脸检测器的实例,以使用以下步骤检测人脸:
- 首先,我们在
FaceDetectionState类内创建一个全局faces变量,如以下代码所示:
List<Face> faces;
- 现在我们定义一个
detectFaces()方法,在其中实例化FaceDetector如下:
void detectFaces() async{
final FirebaseVisionImage visionImage = FirebaseVisionImage.fromFile(widget.file);
final FaceDetector faceDetector = FirebaseVision.instance.faceDetector(FaceDetectorOptions( mode: FaceDetectorMode.accurate, enableLandmarks: true, enableClassification: true));
List<Face> detectedFaces = await faceDetector.processImage(visionImage);
for (var i = 0; i < faces.length; i++) {
final double smileProbablity = detectedFaces[i].smilingProbability;
print("Smiling: $smileProb");
}
faces = detectedFaces;
}
我们首先创建一个使用FirebaseVisionImage.fromFile()方法选择的图像文件的FirebaseVisionImage实例,该实例称为visionImage。 接下来,我们使用FirebaseVision.instance.faceDetector()方法创建FaceDetector的实例,并将其存储在名为faceDetector的变量中。 现在我们使用先前创建的FaceDetector实例faceDetector调用processImage(),并将图像文件作为参数传递。 方法调用返回检测到的面部列表,该列表存储在名为detectedFaces的列表变量中。 请注意,processImage()返回类型为Face的列表。 Face是一个对象,其属性包含检测到的脸部的特征。 Face对象具有以下属性:
getLandmarkhashCodehasLeftEyeOpenProbabilityhasRightEyeOpenProbabilityheadEulerEyeAngleYheadEylerEyeAngleZleftEyeOpenProbabilityrightEyeOpenProbabilitysmilingProbability
现在,我们使用for循环遍历脸部列表。 我们可以使用detectedFaces[i].smilingProbability获得第i个smilingProbablity值。 我们将其存储在名为smileProbablity的变量中,然后使用print()将其值打印到控制台。 最后,我们将全局faces列表的值设置为detectedFaces。
添加到detectFaces()方法的async修饰符使该方法能够异步执行,这意味着将创建一个与执行主线程不同的单独线程。 async方法适用于回调机制,以在执行完成后返回由其计算的值。
为了确保在用户迁移到第二个屏幕后立即检测到面部,我们将覆盖initState()并从其中调用detectFaces():
@override
void initState() {
super.initState();
detectFaces();
}
initState()是在创建窗口小部件之后调用的第一个方法。
标记检测到的面部
接下来,标记检测到的面部。 检测到图像中存在的所有面部之后,我们将通过以下步骤在其周围绘制矩形框:
- 首先,我们需要将图像文件转换为原始字节。 为此,我们定义
loadImage方法如下:
void loadImage(File file) async {
final data = await file.readAsBytes();
await decodeImageFromList(data).then(
(value) => setState(() {
image = value;
}),
);
}
loadImage()方法将图像文件作为输入。 然后,我们使用file.readAsByte()将文件的内容转换为字节,并将结果存储在数据中。 接下来,我们调用decodeImageFromList(),它用于将单个图像帧从字节数组加载到Image对象中,并将最终结果值存储在图像中。 我们从先前定义的detectFaces()内部调用此方法。
- 现在,我们定义一个名为
FacePainter的CustomPainter类,以便在所有检测到的面部周围绘制矩形框。 我们开始如下:
class FacePainter extends CustomPainter {
Image image;
List<Face> faces;
List<Rect> rects = [];
FacePainter(ui.Image img, List<Face> faces) {
this.image = img;
this.faces = faces;
for(var i = 0; i < faces.length; i++) {
rects.add(faces[i].boundingBox);
}
}
}
}
我们首先定义三个全局变量image,faces和rects。 类型为Image的image用于获取图像文件的字节格式。 faces是检测到的Face对象的List。 image和faces都在FacePainter构造器中初始化。 现在我们遍历这些面,并使用faces[i].boundingBox获得每个面的边界矩形,并将其存储在rects列表中。
- 接下来,我们覆盖
paint(),以用矩形绘制Canvas,如下所示:
@override
void paint(Canvas canvas, Size size) {
final Paint paint = Paint()
..style = PaintingStyle.stroke
..strokeWidth = 8.0
..color = Colors.red;
canvas.drawImage(image, Offset.zero, Paint());
for (var i = 0; i < faces.length; i++) {
canvas.drawRect(rects[i], paint);
}
}
我们从创建Paint类的实例开始,以描述绘制Canvas的样式,即我们一直在使用的图像。 由于我们需要绘制矩形边框,因此将style设置为PaintingStyle.stroke以仅绘制形状的边缘。 接下来,我们将strokeWidth,即矩形边框的宽度设置为8。 另外,我们将color设置为red。 最后,我们使用cavas.drawImage()绘制图像。 我们遍历rects列表内检测到的面部的每个矩形,并使用canvas.drawRect()绘制矩形。
在屏幕上显示最终图像
成功检测到面部并在其周围绘制矩形后,我们现在将在屏幕上显示最终图像。 我们首先为第二个屏幕构建最终的脚手架。 我们将覆盖FaceDetectionState中的build()方法,以返回支架,如下所示:
@override
Widget build(BuildContext context) {
return Scaffold(
appBar: AppBar(
title: Text("Face Detection"),
),
body: (image == null)
? Center(child: CircularProgressIndicator(),)
: Center(
child: FittedBox(
child: SizedBox(
width: image.width.toDouble(),
height: image.width.toDouble(),
child: CustomPaint(painter: FacePainter(image, faces))
),
),
)
);
}
我们首先为屏幕创建appBar,并提供标题Face Detection。 接下来,我们指定支架的body。 我们首先检查image的值,该值存储所选图像的字节数组。 直到时间为零,我们确信检测面部的过程正在进行中。 因此,我们使用CircularProgressIndicator()。 一旦检测到脸部的过程结束,用户界面就会更新,以显示具有与所选图像相同的宽度和高度的SizedBox。 SizedBox的child属性设置为CustomPaint,它使用我们之前创建的FacePainter类在检测到的脸部周围绘制矩形边框。
可以在这个页面上查看face_detection.dart中的整个代码。
创建最终的 MaterialApp
最后,我们创建最终的MaterialApp。 我们创建main.dart文件,该文件提供了整个代码的执行点。 我们创建一个名为FaceDetectorApp的无状态小部件,该小部件用于返回指定标题,主题和主屏幕的MaterialApp:
class FaceDetectorApp extends StatelessWidget {
@override
Widget build(BuildContext context) {
return new MaterialApp(
debugShowCheckedModeBanner: false,
title: 'Flutter Demo',
theme: new ThemeData(
primarySwatch: Colors.blue,
),
home: new FaceDetectorHome(),
);
}
}
现在,我们通过传入FaceDetectorApp()的实例,定义main()方法来执行整个应用,如下所示:
void main() => runApp(new FaceDetectorApp());
可以在这个页面中查看main.dart中的整个代码。
总结
在本章中,我们研究了图像处理背后的概念,以及如何将其与使用 Flutter 进行面部检测的基于 Android 或 iOS 的应用集成。 本章从添加相关的依赖关系开始,以支持 Firebase ML Kit 和image_picker库的功能。 添加了具有必要功能的必需 UI 组件。 该实现主要介绍了使用 Flutter 插件选择图像文件以及选择图像后如何对其进行处理。 给出了设备上人脸检测器模型用法的示例,并深入讨论了实现方法。
在下一章中,我们将讨论如何创建自己的 AI 驱动的聊天机器人,该聊天机器人可以使用 Google 平台上的 Actions 兼作虚拟助手。
三、使用 Google Action 的聊天机器人
在这个项目中,我们将介绍使用 Dialogflow API 实现对话聊天机器人的方法,以及如何借助 Google 的操作使对话聊天机器人在 Google Assistant 上执行不同的操作。 该项目将使您对如何构建使用引人入胜的基于语音和文本的对话界面的产品有很好的了解。
我们将实现一个聊天机器人,该机器人将询问用户名称,然后为该用户生成一个幸运数字。 我们还将研究如何使用 Google 的 Actions 在 Google Assistant 平台上提供聊天机器人。
本章将涵盖以下主题:
- 了解可用于创建聊天机器人的工具
- 创建一个 Dialogflow 帐户
- 创建一个 Dialogflow 智能体
- 了解 Dialogflow 控制台
- 在 Google 上创建您的第一个动作
- 在 Google 项目上创建操作
- 实现 Webhook
- 将 Webhook 部署到 Firebase 的 Cloud Functions
- 在 Google 版本上创建动作
- 为对话应用创建 UI
- 集成 Dialogflow 智能体
- 与助手添加音频交互
技术要求
对于移动应用,您将需要带有 Flutter 和 Dart 插件的 Visual Studio Code,以及 Firebase 控制台的设置和运行。
可以在本书的 GitHub 存储库中找到本章的代码文件。
了解可用于创建聊天机器人的工具
如果您希望使用聊天机器人为用户建立对话体验,那么您将有很多选择可以建立。 有几种平台具有不同的功能集,每种平台在其提供的服务方面都是独一无二的。
人工智能聊天机器人是近十年来一直在持续增长的聊天机器人类型,它已经成功地为聊天机器人更容易地进入专业网站和行业铺平了道路。 这些漫游器提供什么样的情报? 他们解决什么业务目标?
让我们尝试用一个场景回答这两个问题。
假设您拥有一家百货商店,并在商店中雇用了几名员工,以便他们可以将您的客户引导到正确的部门。 有一天,您意识到这些员工实际上正在加剧商店的拥挤。 为了替换它们,您想出了一个能够响应“在哪里可以找到一些谷物?”之类的问题的应用, 带有“谷物部分朝向商店的西北部,就在水果部分旁边!”之类的答案。
聊天机器人因此具有理解用户需求的能力,在这种情况下,该需求是找到谷物。 然后,聊天机器人能够确定谷物与杂货之间的关系。 根据对商店库存的了解,它可以将用户定向到正确的部门。 为了能够提出联想,甚至将单词从一种语言翻译成另一种语言,深度学习在聊天机器人的内部工作中起着至关重要的作用。
在以下各节中,我们将探讨各种支持人工智能的工具,这些工具可用于创建聊天机器人并将其部署在手机上。
Wit.ai
Wit.ai平台由 Facebook 制作,围绕自然语言处理(NLP)和语音转文本服务提供了一套 API。 Wit.ai平台是完全开源的,并在 NLP 领域提供一些最新服务。 它可以轻松地与移动应用和可穿戴设备集成,甚至可以用于家庭自动化。 该平台提供的语音文本服务使其非常适合创建使用语音接口的应用。
开发人员可以轻松设计完整的对话,甚至可以为聊天机器人添加个性。 Wit.ai支持超过 130 种语言的对话和语音到文本服务,这使其成为专注于全球语言可访问性的应用的绝佳选择。
要了解有关该平台的更多信息,请访问这里。
Dialogflow
从Api.ai重命名的 Dialogflow 提供了基于深度神经网络的自然语言处理,以创建可与多个平台(例如 Facebook Messenger,Slack,WhatsApp,Telegram 等)无缝集成的对话界面。
Dialogflow 项目在 Google Cloud 上运行,并且能够从与构建会话相关的所有 Google Cloud 产品中受益,例如获取用户的位置,在 Firebase 或 App Engine 上部署 Webhooks 以及在这两个平台上由 Google 开发的应用中启动操作 Android 和 iOS。 您可以通过这里了解有关该平台的更多信息。
现在,让我们更深入地研究 Dialogflow 及其功能,以了解如何为移动设备开发类似 Google Assistant 的应用。
Dialogflow 如何工作?
在上一节中,我们简要介绍了一些可用于根据需要使用文本和语音开发聊天机器人和对话界面的工具。 我们遇到了 Dialogflow,我们将在本节中对其进行深入讨论。 我们还将使用它来快速开发行业级的聊天解决方案。
在开始开发 Dialogflow 聊天机器人之前,我们需要了解 Dialogflow 的工作原理,并了解与 Dialogflow 相关的一些术语。
下图显示了使用 Dialogflow 的应用中的信息流:
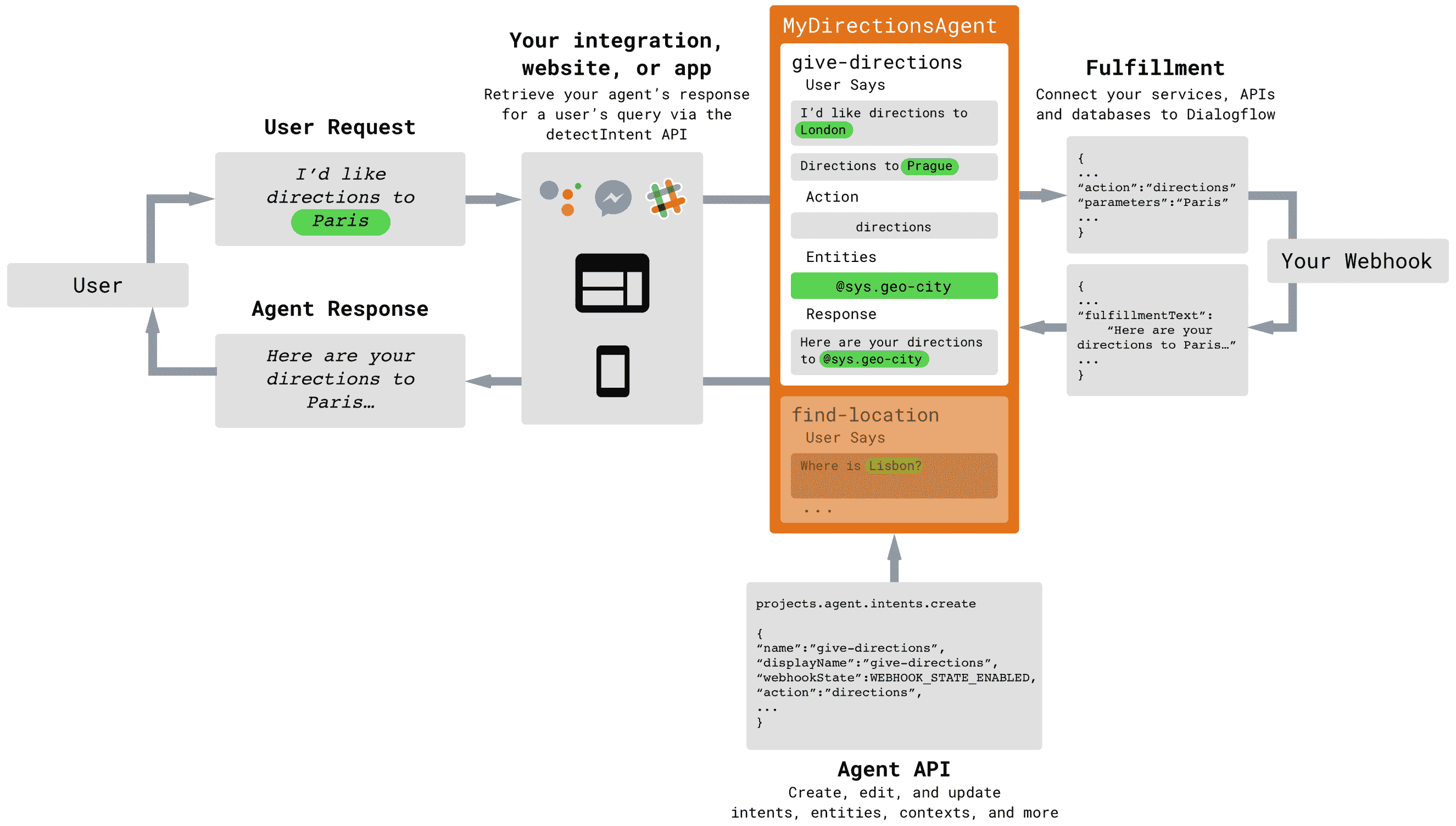
让我们讨论上图中引入的术语:
- 用户:用户是使用聊天机器人/应用的人,并且负责发出用户请求。 用户请求只是由用户发出的口语或句子,必须由聊天机器人进行解释。 需要针对它生成适当的响应。
- 集成:集成是一个软件组件,负责将用户请求传递给聊天机器人逻辑,并将智能体响应传递给用户。 这种集成可以是您创建的应用或网站,也可以是现有服务(例如 Slack,Facebook Messenger),也可以是调用 Dialogflow 聊天机器人的脚本。
- 智能体:我们使用 Dialogflow 工具开发的聊天机器人称为智能体。 聊天机器人生成的响应称为智能体响应。
- 意图:这表示用户在其用户请求中尝试执行的操作。 用户输入的自然语言必须与意图相匹配,以确定针对任何特定请求要生成的响应类型。
- 实体:在用户请求中,用户有时可能会使用处理响应所需的单词或短语。 这些以实体的形式从用户请求中提取,然后按需使用。 例如,如果用户说“我在哪里可以买到芒果?” 聊天机器人应该提取芒果一词,以便搜索其可用的数据库或互联网以提出适当的响应。
- 上下文:要了解 Dialogflow 中的上下文,请考虑以下情形,在这种情况下,您无法与聊天机器人交谈来维护上下文:
您问您的聊天机器人“谁是主要角色? 印度大臣?” 并生成适当的响应。 接下来,您问您的聊天机器人“他几岁了?” 您的聊天机器人不知道“他的”是指谁。 因此,上下文是在聊天会话或会话的一部分上维护的会话状态,除非上下文被与聊天机器人的会话中的新事物所覆盖。 - 实现:实现是处理聊天机器人内业务逻辑的软件组件。 它是一个可以通过 Webhooks 访问的 API,可以接收有关传递给它的实体的输入,并生成响应,然后聊天机器人可以使用该响应来生成最终的智能体响应。
涵盖了 Dialogflow 的基本术语和工作流程之后,我们现在将构建一个基本的 Dialogflow 智能体,该智能体可以提供对用户请求的响应。
创建一个 Dialogflow 帐户
要开始使用 Dialogflow,您需要在 Dialogflow 网站上创建一个帐户。 为此,请按照下列步骤操作:
- 访问这里开始帐户创建过程。
您将需要一个 Google 帐户来创建 Dialogflow 帐户。 如果尚未创建一个,请访问这里。
- 在 Dialogflow 网站的主页上,单击“免费注册”以创建帐户,或单击“进入控制台”以打开 Dialogflow 控制台:

- 单击“使用 Google 登录”后,系统会要求您使用 Google 帐户登录。 您将被要求获得使用 Dialogflow 的帐户权限,然后接受条款和条件。
现在,我们可以开始创建 Dialogflow 智能体。
创建一个 Dialogflow 智能体
正如我们在“Dialogflow 如何工作”部分中讨论的那样,智能体是我们在 Dialogflow 平台中创建的聊天机器人。
成功创建帐户后,将显示 Dialogflow 控制台的登录屏幕,提示您创建智能体:
- 单击“创建智能体”提示。 您将被带到一个类似于以下内容的屏幕:
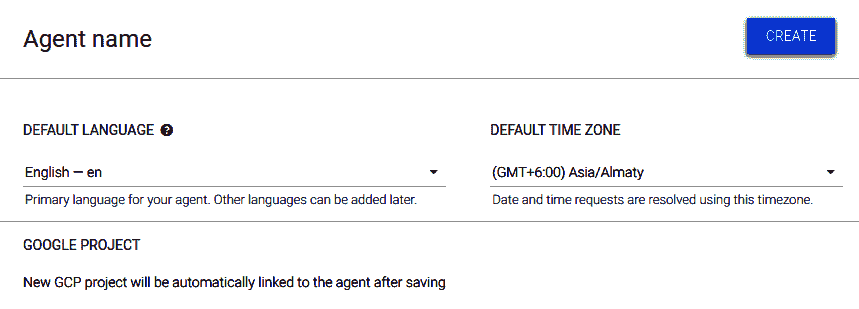
- 填写智能体的名称。 我们将其命名为
DemoBot。 - 将任何现有的 Google Project 链接到聊天机器人。 如果您还没有合格的 Google Project,则单击“创建”按钮时将创建一个新项目。
您需要在 Google Project 上启用结算功能才能创建 Dialogflow 聊天机器人。 要了解如何创建 Google Project,请访问这里。
了解 Dialogflow 控制台
Dialogflow 控制台是图形用户界面,用于管理聊天机器人,意图,实体以及 Dialogflow 提供的所有其他功能。
创建智能体后,您应该能够看到以下屏幕:

Dialogflow 控制台提示您创建一个新的意图。 让我们创建一个新的意图,该意图可以识别用户名并使用它为用户生成一个幸运数字。
创建一个意图并获取实体
现在,我们将创建一个意图,该意图从用户那里获取输入并确定用户名称。 然后,该意图提取名称的值并将其存储在一个实体中,该实体稍后将传递给 Webhook 进行处理。 请按照以下步骤操作:
-
单击屏幕右上方的“创建意图”按钮。 意向创建表单打开。
-
我们必须为该意图提供一个名称,例如
luckyNum。 然后,向下滚动到“训练短语”部分并添加一个训练短语:name is John。 -
抓住所需的实体,然后选择单词
John。 将出现一个下拉列表,将单词与任何预定义实体匹配。 我们将使用@sys.person实体获取名称并将其存储为userName参数,如以下屏幕截图所示:

- 向下滚动到“操作和参数”部分,并添加
userName参数,如以下屏幕快照所示:
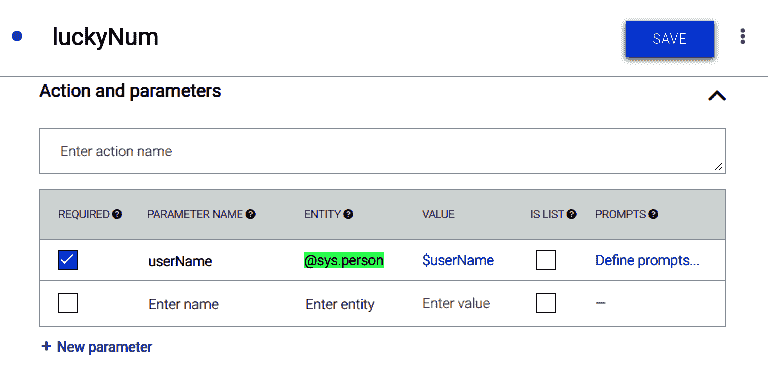
- 现在,只要用户查询类似于名称的东西,就会将某些东西提取到
$userName变量中。 现在可以将其传递到 webhook 或 Firebase Cloud Function 以根据其值生成响应。
现在,让我们添加一个操作,以便可以通过 Google Assistant 访问 Dialogflow 智能体。
在 Google 上创建您的第一个动作
在 Google 上创建动作之前,让我们尝试了解什么是动作。 您可能听说过 Google 助手,它在本质上可以与 Siri 或 Cortana 媲美。 它围绕虚拟助手的概念构建,虚拟助手是一种软件,能够根据用户的指示以文本或语音形式为用户执行任务。
Google 助手可以执行的每个任务称为操作。 因此,当用户发出类似于“向我显示购物清单”或“打给 Sam 的请求”的请求时执行的任务是这样的动作,其中,函数showShoppingList()或makeCall(Sam)以适当的方式执行附加的参数。
Google 平台上的 Actions 使我们能够创建充当 Google Assistant 上的 Actions 的聊天机器人。 一旦调用,我们就可以进行对话,直到被用户结束为止。
调用操作是在 Google 助手中执行的,该助手将调用请求与其目录中的操作列表进行匹配,并启动适当的操作。 然后,用户接下来要做的几个动作就是与动作。 因此,Google 助手会充当多个此类操作的汇总器,并提供对其进行调用的方法。
您为什么是 Google Action?
Google 平台上的操作为有兴趣构建聊天机器人的开发人员提供了哪些商业利益? 考虑以下屏幕截图:
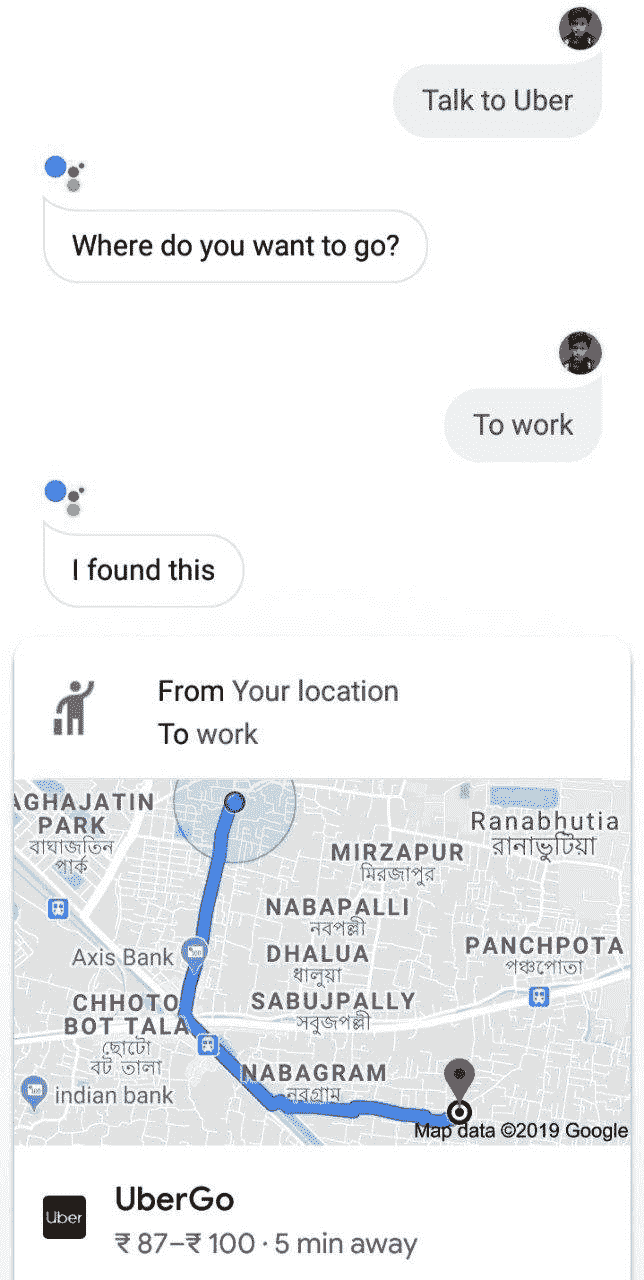
只需与 Google 助理交谈,用户便可以获取 Uber 选项。 这是因为“与 Uber 对话”调用与由 Uber 开发并通过 Google 平台上的“操作”提供的聊天机器人相匹配,该聊天机器人正在响应“与 Uber 对话”用户请求。
因此,Uber 通过提供无文本的界面(如果使用语音输入)来提高其可用性和交互性,并受益于 Google 助手中最先进的 NLP 算法,从而最终增强了其销量。
有效地将您创建的聊天机器人发布到 Google 的 Actions 上,可以为您的企业提供对话界面。 您可以使用 webhooks(我们将在本章稍后介绍)来管理业务逻辑。现在,让我们在 Google 上创建一个 Action 并将其链接到我们的聊天机器人。
在 Google 项目上创建操作
在本部分中,我们将在 Google Project 上创建一个 Actions,然后将其与 Google Assistant 应用集成。 这将使我们构建的聊天机器人可以通过 Google 助手应用访问,该助手在全球数十亿设备上都可用。
让我们从在 Google 项目上创建操作开始:
- 在浏览器中,打开这里,以打开 xGoogle 主页上的“操作”,您可以在其中阅读有关该平台的所有信息,并对其进行介绍。
- 要进入控制台,请单击开始构建或转到操作控制台按钮。 您将被带到 Google 控制台上的“操作”,系统将提示您创建一个项目。
- 在继续进行项目创建时,您将看到一个对话框,如以下屏幕截图所示:
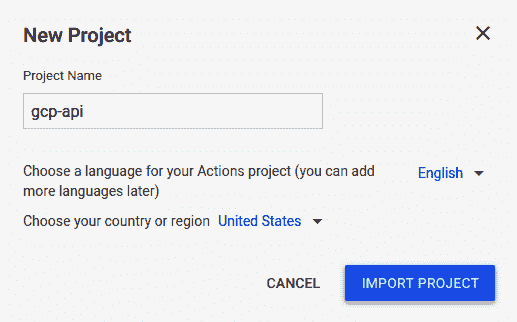
您必须选择在其中创建 Dialogflow chatbot 智能体的同一 Google Project。
- 单击“导入项目”,将 Dialogflow 聊天机器人的操作添加到 Google 助手。 在加载的下一个屏幕上,选择“对话”模板以创建我们的操作。
- 然后,您将被带到 Google 控制台上的“操作”,如下所示:
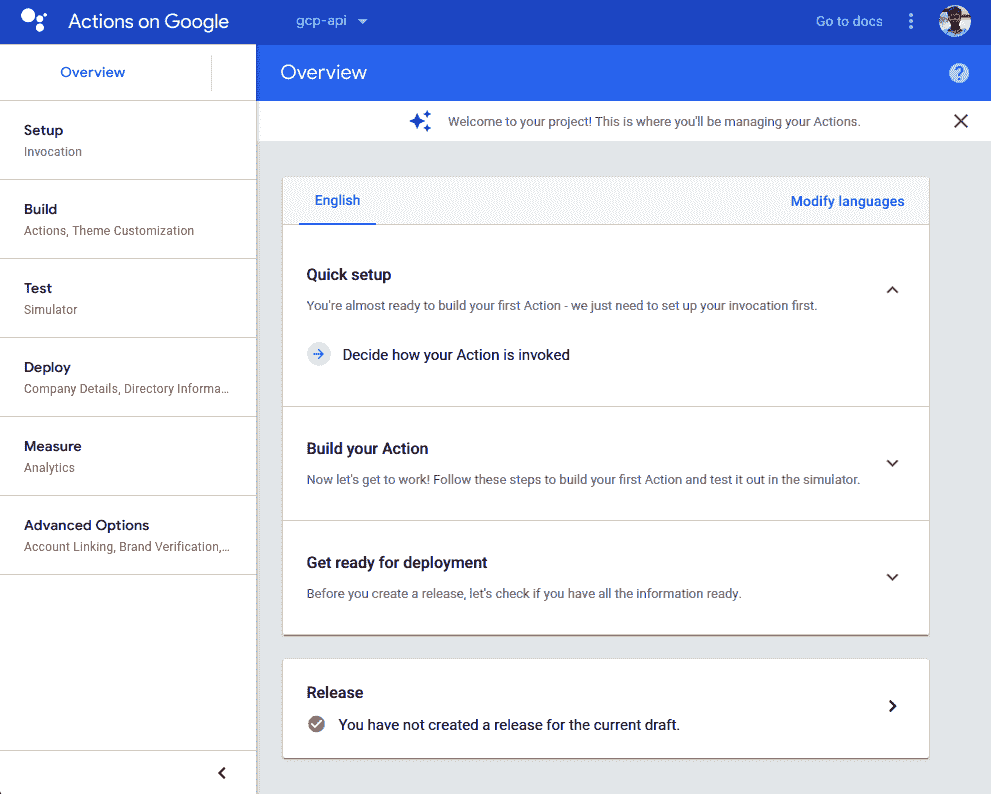
在顶部栏上,您将看到内置 Action 的 Google Project 的项目 ID。在左侧垂直导航栏上,将列出所有不同步骤,您需要执行它们才能完成设置 Action。 在右侧的主要内容部分,提供了一个快速演练来设置您的第一个 Action。
- 单击“确定”如何调用操作。 您需要为您的操作提供唯一的调用字符串。 对于本章中的示例,我们使用了
Talk to Peter please调用。 您将需要选择稍微不同的调用。
成功设置调用后,演练将要求您添加一个动作。
- 单击“添加动作”链接以开始动作创建过程。
- 在出现的“创建操作”对话框中,在左侧列表中选择“自定义意图”,然后单击“构建”按钮。 这将带您回到 Dialogflow 界面。
现在,您需要在 Google 上启用“操作”才能访问您的聊天机器人的意图。
创建与 Google Assistant 的集成
默认情况下,您在 Dialogflow 控制台中构建的聊天机器人不允许 Google Actions 项目访问其中可用的意图。 通过执行以下步骤,我们可以启用对意图的访问:
- 在 Dialogflow 界面上,单击左侧导航窗格上的
Integrations按钮。 - 在加载的页面上,将为您提供 Dialogflow 支持的各种服务的集成选项,其中包括所有主要的社交聊天平台,以及 Amazon 的 Alexa 和 Microsoft 的 Cortana。
- 在屏幕上,您应该看到 Google 助手的“集成设置”按钮。 单击该按钮。 将打开一个对话框,如以下屏幕截图所示:

前面的屏幕快照中的对话框使您可以快速定义 Dialogflow 智能体与 Google 项目中的操作之间的集成设置。
- 在“默认调用”下,将“默认欢迎意图”设置为当用户开始通过 Google Assistant 与您的聊天机器人进行交互时将首先运行的意图。
- 在隐式调用中,指定我们之前创建的
luckyNum意图。 这将用于为用户生成幸运数字。 - 启用自动预览更改是个好主意,因为它使您可以将集成设置自动传播到 Google Console 上的“操作”和 Google Assistant 测试模拟器(我们将在稍后讨论),以便在为以下版本创建版本之前测试我们的应用。
现在,让我们为“默认欢迎意图”提供有意义的提示,以要求用户输入其名称,以便在用户做出响应时,其输入类似于luckyNum意图的训练短语,从而调用它:
- 单击“意图”按钮。 然后,单击“默认欢迎意图”。 向下滚动到“意图”编辑页面的“响应”部分,然后删除那里的所有响应。 由于
luckyNum意图希望用户说类似My name is XYZ的内容,因此合适的问题是What is your name?。 因此,我们将响应设置为Hi, what is your name?。
请注意,“响应”部分的选项卡式导航中有一个名为“Google 助手”的新导航栏。 这样,当我们从 Google Assistant 调用此意图时,我们可以为其指定其他响应。
- 单击选项卡,然后从默认选项卡中启用用户响应作为第一个响应。 我们这样做是因为我们不想在聊天机器人中指定特定于 Google 助手的其他响应。
- 向上滚动到“事件”部分,并检查它是否类似于以下屏幕截图:

- 如果缺少前面两个事件中的任何一个,则可以通过简单地键入它们并从出现的自动建议框中选择它们来包括它们。
- 单击 Dialogflow 控制台中间部分右上方的“保存”。
现在,我们准备创建我们的业务逻辑,以便为用户生成幸运数字。 首先,我们将为luckyNum意图创建一个 Webhook,然后将其部署到 Firebase 的 Cloud Functions 中。
实现 Webhook
在本节中,我们将为luckyNum意图启用 webhook,并为luckyNum意图的逻辑准备 webhook 代码。 请按照以下步骤操作:
- 打开
luckyNum意图的意图编辑页面,然后向下滚动到“实现”部分。 在这里,启用“为此意图启用 webhook 调用”选项。
现在,此意图将寻找从 webhook 生成的响应。
- 打开您选择的文本编辑器以创建用于 Webhook 的代码,使其使用 JavaScript 并在 Firebase 提供的 Node.js 平台上运行:
'use strict';
上一行确保我们使用 ECMAScript 5 中定义的一组编码标准,这些编码标准对 JavaScript 语言进行了一些有用的修改,从而使其更加安全并且减少了混乱。
- 使用
require函数将 JavaScript 中的模块导入到项目中。 包括actions-on-google模块和firebase-functions模块,因为脚本将部署到 Firebase:
// Import the Dialogflow module from the Actions on Google client library.
const {dialogflow} = require('actions-on-google');
// Import the firebase-functions package for deployment.
const functions = require('firebase-functions');
- 为我们构建的 Dialogflow 智能体实例化一个新的客户端对象:
// Instantiate the Dialogflow client.
const app = dialogflow({debug: true});
注意,这里的 Dialogflow 变量是actions-on-google模块的对象。
- 将 Webhook 响应的意图设置为
luckyNum,然后将其传递给conv变量:
app.intent('luckyNum', (conv, {userName}) => {
let name = userName.name;
conv.close('Your lucky number is: ' + name.length );
});
app变量保存正在处理的会话的状态信息以及我们从luckyNum意图中提取的userName参数。 然后,我们声明变量名称,并将其设置为userName变量的名称键。 这样做是因为userName变量是一个 JavaScript 对象。 您可以在右侧部分的“测试”控制台中通过为luckyNum意图(例如My name is Max)键入匹配的调用来查看此内容。
- 设置 Webhook,使其响应所有 HTTPS POST 请求,并通过 Firebase 将其导出为 Dialogflow 实现:
// Set the DialogflowApp object to handle the HTTPS POST request.
exports.dialogflowFirebaseFulfillment = functions.https.onRequest(app);
我们在本节中开发的脚本需要部署到服务器以使其响应。 我们将为 Firebase 使用 Cloud Functions 部署此脚本并将其用作聊天机器人的 webhook 端点。
将 Webhook 部署到 Firebase 的 Cloud Functions
既然我们已经完成了 Webhook 的逻辑创建,那么在 Firebase 上使用 Cloud Functions 部署它就非常简单。 请按照以下步骤操作:
- 单击 Dialogflow 控制台左侧导航上的
Fulfillment按钮。 使内联编辑器能够添加您的 Webhook 并将其直接部署到 Cloud Functions。
您必须清除内联编辑器中的默认样板代码才能执行此操作。
- 将上一部分中的编辑器中的代码粘贴到
index.js选项卡式导航丸中,然后单击Deploy。
请记住,用于部署的环境是 Node.js,因此index.js是包含所有业务逻辑的文件。 package.json文件管理您的项目所需的包。
使用 Cloud Functions 具有部署 Webhook 的简单性和最小化设置的优势。 另一方面,仅设置index.js的限制可防止您将 Webhook 逻辑拆分为多个文件,这通常是在大型 chatbot 应用中完成的。 现在,您准备为 Action 创建一个发行版。
在 Google 版本上创建动作
最后,我们处于可以在 Google chatbot 上为 Actions 创建发行版的阶段。 但在这样做之前,重要的是在 Google Assistant 测试模拟器中测试聊天机器人:
-
单击 Google 控制台上“操作”左侧导航窗格中的“模拟器”按钮,以进入模拟器。 在模拟器中,将显示一个类似于在手机上使用 Google Assistant 的界面。 建议的输入将包含您的操作的调用方法。
-
在模拟器中为您的操作输入调用,在本例中为
Talk to Peter Please。 这将产生来自默认欢迎意图要求您输入名称的输出。 输入您的姓名作为响应后,类似于My name is Sammy,您将看到您的幸运数字,如下所示:

现在我们知道我们的聊天机器人可以正常工作,并且可以与 Google 上的 Action 集成在一起,让我们为其创建一个发行版:
- 在 Google 控制台上的操作中单击“概述”,您将看到准备部署的提示。
- Actions 测试控制台要求您输入一些 Action 所需的信息。 这些通常是简短和长格式的说明,开发人员的详细信息,隐私策略,操作条款和条件以及徽标。 成功填写所有内容后,单击“保存”。
- 在“部署”类别下的左侧导航栏中单击“发布”,以打开“发布”页面。 在这里,选择
Alpha发布选项,然后单击Submit发布。
部署将需要几个小时才能完成。 部署完成后,您将能够在已登录到内置 Action 的 Google 帐户的任何设备上测试您的操作。成功创建并部署 Dialogflow 智能体后,我们现在将使用以下方法开发 Flutter 应用: 与智能体进行交互的能力。 单屏应用将具有与任何基本的移动聊天应用非常相似的用户界面,带有一个用于输入消息的文本框,这些消息是 Dialogflow 智能体的查询,还有一个将每个查询发送到智能体的发送按钮。 该屏幕还将包含一个列表视图,以显示来自用户的所有查询和来自智能体的响应。 另外,在“发送”按钮旁边将有一个麦克风选项,以便用户可以利用语音到文本功能将查询发送到智能体。
为对话应用创建 UI
我们将从使用一些硬编码文本为应用创建基本用户界面开始,以测试 UI 是否正确更新。 然后,我们将集成 Dialogflow 智能体,以便它可以回答查询并告诉用户他们的幸运数字,然后添加一个mic选项,以便我们可以利用语音转文本功能。
该应用的整体小部件树如下所示:
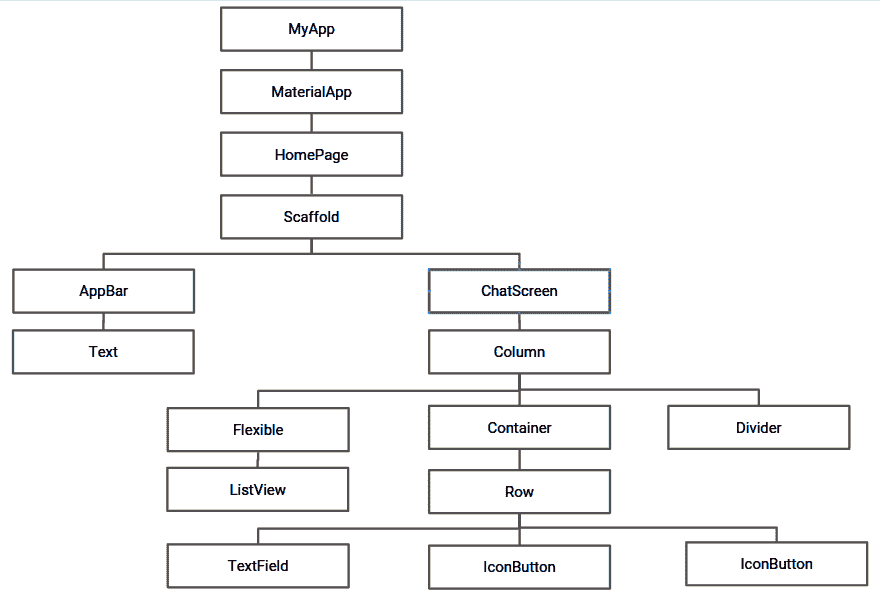
现在,让我们详细讨论每个小部件的实现。
创建文本控制器
首先,让我们在名为chat_screen.dart的新 dart 文件中创建一个名为ChatScreen的 StatefulWidget。 现在,请按照下列步骤操作:
- 创建一个文本框-用 Flutter 项
TextField-允许用户输入输入文本。 要创建TextField,我们需要定义createTextField():
Widget createTextField() {
return new Flexible(
child: new TextField(
decoration:
new InputDecoration.collapsed(hintText: "Enter your message"),
controller: _textController,
onSubmitted: _handleSubmitted,
),
);
}
当用户指示已完成将文本输入到文本字段中时,onSubmitted属性用作文本字段的回调,以处理文本输入。 当按下键盘上的Enter按钮时,将触发该属性。
在前面的TextField小部件中,当用户输入完文本后便会调用_handleSubmitted()。 稍后将详细描述_handleSubmitted()。
我们还将decoration属性指定为折叠状态,以删除可能出现在文本字段中的默认边框。 我们还将hintText属性指定为Enter your message。 要收听更改并更新TextField,我们还附加了TextEditingController的实例。 可以通过执行以下代码来创建实例:
final TextEditingController _textController = new TextEditingController();
与 Java 不同,Dart 没有诸如public,private或protected之类的关键字来定义变量的使用范围。 而是在标识符名称之前使用下划线_来指定该标识符是类专有的。
- 接下来,创建一个发送按钮,该按钮可用于向
createSendButton()函数内部的智能体发送查询:
Widget createSendButton() {
return new Container(
margin: const EdgeInsets.symmetric(horizontal: 4.0),
child: new IconButton(
icon: new Icon(Icons.send),
onPressed: () => _handleSubmitted(_textController.text),
),
);
}
在 Flutter 中,可以使用Icons类轻松添加类似于发送按钮的图形图标。 为此,我们创建一个新的Icon实例并指定Icons.send,以便将小部件用作发送按钮。 用作icon属性的参数。 我们还设置了onPressed属性,该属性在用户点击“发送”按钮时调用。 在这里,我们再次致电_handleSubmitted。
=>(有时称为箭头)是一种速记符号,用于定义包含一行的方法。 定义为fun() { return 10; }的方法可以写为fun() => return 10;。
- 文本字段和发送按钮应该并排显示,因此可以通过将它们作为子代添加到
Row小部件中来将它们包装在一行中。 包装好的Row小部件位于屏幕底部。 我们在_buildTextComposer()中创建此小部件:
Widget _buildTextComposer() {
return new IconTheme(
data: new IconThemeData(color: Colors.blue),
child: new Container(
margin: const EdgeInsets.symmetric(horizontal: 8.0),
child: new Row(
children: <Widget>[
createTextField(),
createSendButton(),
],
),
),
);
}
_buildTextComposer()函数返回一个以Container作为其子元素的IconTheme小部件。 容器包含由文本字段和我们在“步骤 1”和2中创建的发送按钮组成的Row小部件。
在下一节中,我们将构建ChatMessage小部件,该小部件用于显示用户与聊天机器人的交互。
创建ChatMessage
来自用户的查询和来自智能体的响应可以被视为单个组件的两个不同部分。 我们将为它们创建两个不同的容器,然后将它们添加到名为ChatMessage的单个单元中。 这样可以确保每个查询及其答案的显示顺序与用户输入的顺序相同。 我们将在一个名为chat_message.dart的新 dart 文件中创建一个名为ChatMessage的有状态小部件。 下图显示了ChatMesage的查询和响应划分:
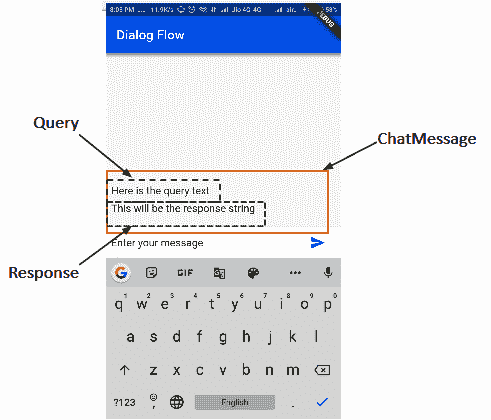
要创建屏幕的 UI,请按照下列步骤操作:
- 创建一个包含一些文本的容器,该容器将在屏幕上显示用户输入的查询:
new Container(
margin: const EdgeInsets.only(top: 8.0),
child: new Text("Here is the query text",
style: TextStyle(
fontSize: 16.0,
color: Colors.black45,
),
),
)
我们从为容器提供8.0的上边距开始,该边距包含一个当用户输入查询时将显示的字符串。 当调用_handleSubmitted()时,我们会将这个硬编码的字符串修改为字符串参数。 我们还将fontSize属性的边距修改为16.0,并将颜色设置为black45(深灰色),以帮助用户区分查询和响应。
- 创建一个容器以显示响应字符串:
new Container(
margin: const EdgeInsets.only(top: 8.0),
child: new Text("This will be the response string",
style: TextStyle(
fontSize: 16.0
),
),
)
顶部边距属性为8.0的容器包含一个硬编码的响应字符串。 稍后将对其进行修改,使其可以适应用户的响应。
- 将两个容器包装在单个
Column中,然后将其作为有状态窗口小部件(即ChatMessage)中覆盖的build()方法的容器返回:
@override
Widget build(BuildContext context) {
return new Container(
margin: const EdgeInsets.symmetric(vertical: 10.0),
child: new Column(
crossAxisAlignment: CrossAxisAlignment.start,
children: <Widget>[
new Container(
margin: const EdgeInsets.only(top: 8.0),
child: new Text("Here is the query text",
style: TextStyle(
fontSize: 16.0,
color: Colors.black45,
),
),
),
new Container(
margin: const EdgeInsets.only(top: 8.0),
child: new Text("this will be the response text",
style: TextStyle(
fontSize: 16.0
),
),
)
]
)
);
在 Flutter 中,文本包装在Container中。 通常,当它们太长而无法水平放置在屏幕中时,它们往往会从屏幕上溢出。 这可以看成是屏幕角落的红色标记。 为避免文本溢出,请确保将Container和Text包裹在Flexible内,以便文本可以垂直占据可用空间并自行调整。
- 为了存储和显示所有字符串(查询和响应),我们将使用
ChatMessage类型的List:
final List<ChatMessage> _messages = <ChatMessage>[];
此列表应出现在我们先前创建的TextField上方,以接受用户输入。
- 为了确保字段以垂直顺序正确显示,我们需要将它们包装在列中,然后从
ChatScreen.dart的Widget build()方法返回它们。 该列的三个子级是一个灵活的列表视图,一个分隔符和一个带有文本字段的容器。 通过重写build()方法来创建 UI,如下所示:
@override
Widget build(BuildContext context) {
return new Column(
children: <Widget>[
new Flexible(
child: new ListView.builder(
padding: new EdgeInsets.all(8.0),
reverse: true,
itemBuilder: (_, int index) => _messages[index],
itemCount: _messages.length,
),
),
new Divider(
height: 1.0,
),
new Container(
decoration: new BoxDecoration(
color: Theme.of(context).cardColor,
),
child: _buildTextComposer(),
),
],
);
}
以ChatMessages作为其子元素的ListView被制作为Flexible,以便在放置分隔符和文本字段的容器之后,可以在垂直方向上占据屏幕上可用的整个空间。 在所有四个基本方向上都给8.0填充。 另外,将reverse属性设置为true可以使其在底部到顶部的方向上滚动。 itemBuilder属性被分配索引的当前值,以便它可以构建子项。 另外,为itemCount分配了一个值,该值可帮助列表视图正确估计最大可滚动内容。 列的第二个子级创建分隔符。 这是一条devicePixel粗水平线,标记了列表视图和文本字段的分隔。 在该列的最底部位置,我们将带有文本字段的容器作为其子容器。 这是通过对我们先前定义的_buildTextComposer()进行方法调用而构建的。
- 在
ChatScreen.dart方法内定义_handleSubmit(),以正确响应用户的“发送消息”操作:
void _handleSubmitted(String query) {
_textController.clear();
ChatMessage message = new ChatMessage(
query: query, response: "This is the response string",
);
setState(() {
_messages.insert(0, message);
});
}
方法的字符串参数包含用户输入的查询字符串的值。 该查询字符串以及一个硬编码的响应字符串用于创建ChatMessage的实例,并插入到_messages列表中。
- 在
ChatMessage中定义一个构造器,以便正确传递和初始化参数值,查询和响应:
final String query, response;
ChatMessage({this.query, this.response});
- 分别在
ChatMessages.dart中修改用于查询和响应的容器内Text属性的值,以使屏幕上显示的文本与用户和用户输入的文本相同。 从动作助手获得的回复:
//Modifying the query text
child: new Text(query,
style:.......
)
//Modify the response text
child: new Text(response,
style:.......
)
成功编译到目前为止我们编写的代码后,屏幕应如下所示:
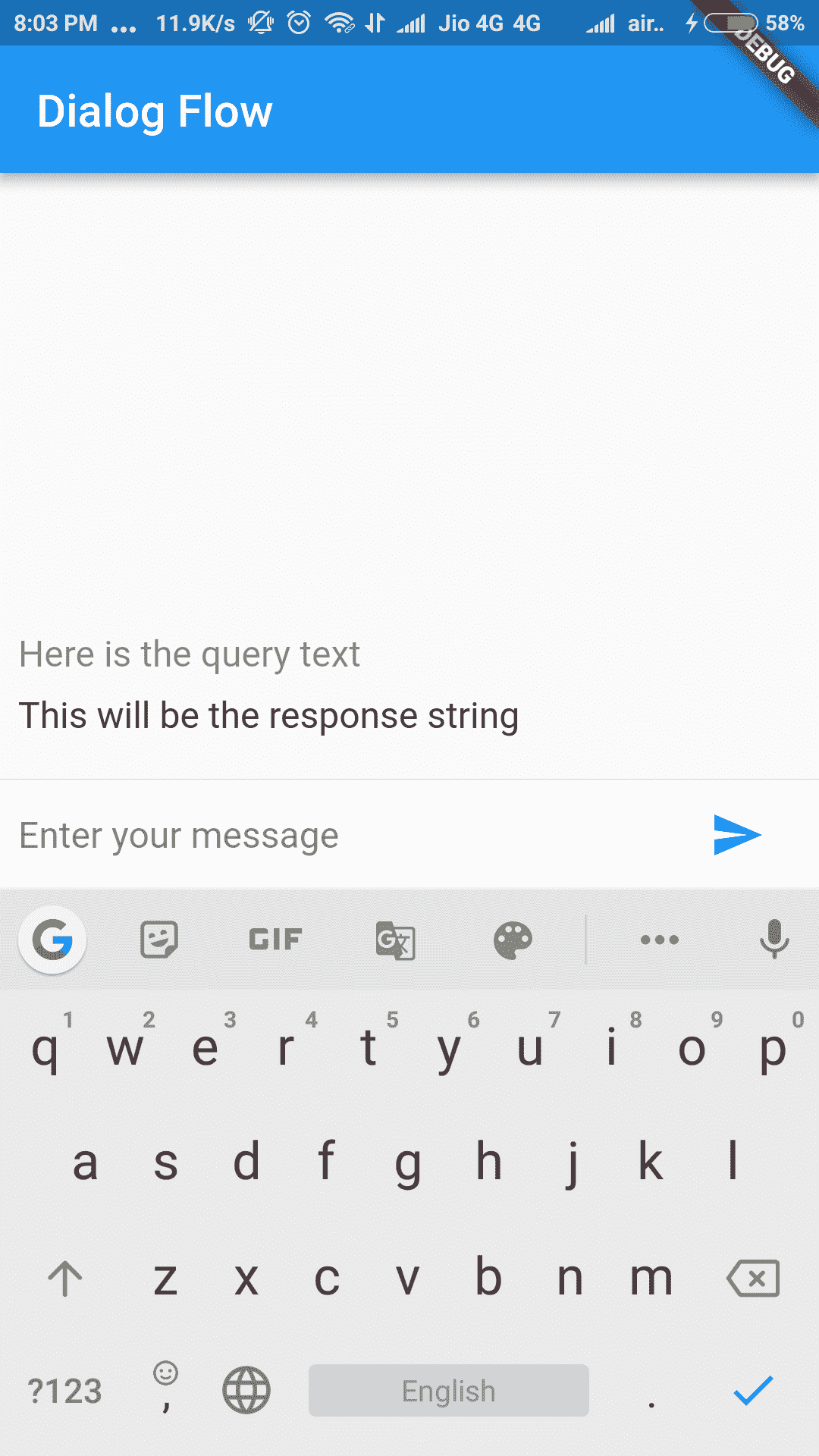
在前面的屏幕截图中,您可以看到将由用户编写的虚拟查询文本以及来自聊天机器人的响应字符串。
整个chat_message.dart文件可以在 GitHub 上查看。
在下一节中,我们将集成 Dialogflow 智能体,以便我们对用户查询具有实时响应。
集成 Dialogflow 智能体
现在,我们已经为应用创建了一个非常基本的用户界面,我们将把 Dialogflow 智能体与应用集成在一起,以便该智能体实时响应用户输入的文本。 按着这些次序:
- 为了将 Dialogflow 集成到应用中,我们将使用名为
flutter_dialogflow的 Flutter 插件。
要浏览此插件,请转到这里。
将依赖项添加到pubspec.yaml文件中的插件:
dependencies:
flutter_dialogflow: ^0.1.0
- 接下来,我们需要安装依赖项。 可以使用
$ flutter pub get命令行参数,也可以通过单击屏幕上显示的选项来完成。 在这里,我们将使用dialogflow_v2,因此让我们将包导入chat_screen.dart文件中:
import 'package:flutter_dialogflow/dialogflow_v2.dart';
- 添加
.json文件,其中包含您在项目的控制台上创建 Dialogflow 智能体时下载的 GCP 凭据。 为此,创建一个assets文件夹并将文件放在其中:

- 将文件的路径添加到
pubspec.yaml文件的assets部分:
flutter:
uses-material-design: true
assets:
- assets/your_file_downloaded_google_cloud.json
- 修改
_handleSubmitted(),以便它可以与智能体进行通信并获得对用户输入的查询的响应:
Future _handleSubmitted(String query) async {
_textController.clear();
//Communicating with DailogFlow agent
AuthGoogle authGoogle = await AuthGoogle(fileJson: "assets/gcp-api.json").build();
Dialogflow dialogflow = Dialogflow(authGoogle: authGoogle,language: Language.english);
AIResponse response = await dialogflow.detectIntent(query);
String rsp = response.getMessage();
ChatMessage message = new ChatMessage(
query: query, response: rsp
);
setState(() {
_messages.insert(0, message);
});
}
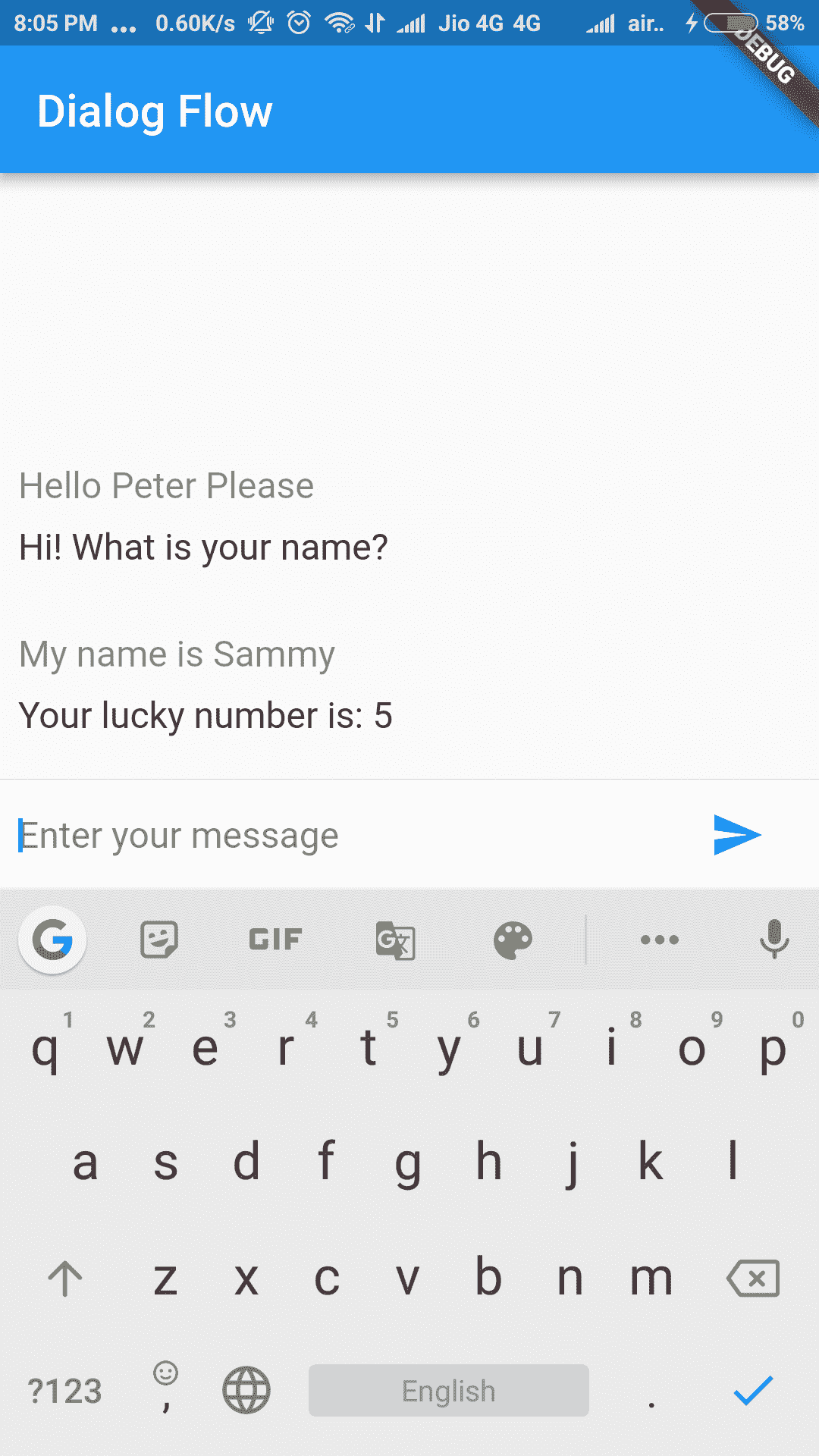
首先,我们通过指定assets文件夹的路径来创建一个名为authGoogle的AuthGoogle实例。 接下来,我们创建Dialogflow智能体的实例,该实例指定 Google 认证实例以及用于与其通信的语言。 在这里,我们选择了英语。 然后使用response.getMessage()提取响应,并将其存储在rsp字符串变量中,然后在创建ChatMessage实例时传递该变量,以确保两个字符串(输入文本和响应)均在屏幕上正确更新。
以下屏幕快照显示了在进行上述修改以反映用户的实际查询和 Dialogflow 智能体的响应之后的应用:
在下一部分中,我们将向应用添加音频交互功能。
添加与助手的音频交互
现在,我们将语音识别添加到应用中,以便它可以监听用户的查询并采取相应的措施。
添加插件
我们将在此处使用speech_recognition插件。 让我们添加依赖项,如下所示:
- 将依赖项添加到
pubspec.yaml文件,如下所示:
dependencies:
speech_recognition: "^0.3.0"
- 通过运行以下命令行参数来获取包:
flutter packages get
- 现在,由于我们正在使用设备的麦克风,因此我们需要征得用户的许可。 为此,我们需要添加以下代码行:
在 iOS 上,权限是在infos.plist中指定的:
<key>NSMicrophoneUsageDescription</key>
<string>This application needs to access your microphone</string>
<key>NSSpeechRecognitionUsageDescription</key>
<string>This application needs the speech recognition permission</string>
在 Android 上,权限在AndroidManifest.xml文件中指定:
<uses-permission android:name="android.permission.RECORD_AUDIO" />
- 现在,我们准备将包导入到
chat_screen.dart文件中,以便可以使用它:
import 'package:speech_recognition/speech_recognition.dart';
在下一节中,我们将添加将利用speech_recognition插件来帮助进行音频交互的方法。
添加语音识别
添加speech_recognition插件并导入包后,我们都准备在我们的应用中使用它。 让我们从添加将在应用内部处理语音识别的方法开始,如下所示:
- 添加并初始化所需的变量:
SpeechRecognition _speechRecognition;
bool _isAvailable = false;
bool _isListening = false;
String transcription = '';
_speechRecognition是SpeechRecognition的实例。 _isAvailable很重要,因为它可以让平台(Android/iOS)知道我们正在与之交互,并且_isListening将用于检查应用当前是否正在监听麦克风。
最初,我们将两个boolean变量的值都设置为false。 transcription是一个字符串变量,将用于存储已监听的字符串。
- 定义
activateSpeechRecognizer()方法以设置音频操作:
void activateSpeechRecognizer() {
_speechRecognition = SpeechRecognition();
_speechRecognition.setAvailabilityHandler((bool result)
=> setState(() => _isAvailable = result));
_speechRecognition.setRecognitionStartedHandler(()
=> setState(() => _isListening = true));
_speechRecognition.setRecognitionResultHandler((String text)
=> setState(() => transcription = text));
_speechRecognition.setRecognitionCompleteHandler(()
=> setState(() => _isListening = false));
}
在前面的代码片段中,我们在_speechRecognition内部初始化了SpeechRecognition的实例。 然后,我们通过调用_speechRecognition.setAvailabilityHandler()回调函数来设置AvailabilityHandler,该回调函数需要传回可以分配给_isAvailable的boolean结果。 接下来,我们设置RecognitionStartedHandler,它在启动语音识别服务时执行,并将_isListening设置为true表示移动设备的麦克风当前处于活动状态并且正在监听。 然后,我们使用setRecognitionResultHandler设置RecognitionResultHandler,这将给我们返回生成的文本。 这存储在字符串转录中。 最后,我们设置RecognitionCompleteHandler,当麦克风停止收听时,将_isListening设置为false。
- 公开内部的
initState()函数调用activateSpeechRecognizer()来设置_speechRecognition实例,如下所示:
@override
void initState(){
super.initState();
activateSpeechRecognizer();
}
此时,该应用能够识别音频并将其转换为文本。 现在,我们将增强 UI,以便用户可以提供音频作为输入。
添加麦克风按钮
现在,我们已经激活了语音识别器,我们将在发送按钮旁边添加一个麦克风图标,以允许用户利用该选项进行语音识别。 请按照以下步骤操作:
- 首先,我们定义
createMicButton()函数,该函数作为第三个子项添加到_buildTextComposer()内部的Row小部件中:
Widget createMicButton() {
return new Container(
margin: const EdgeInsets.symmetric(horizontal: 4.0),
child: new IconButton(
icon: new Icon(Icons.mic),
onPressed: () {
if (_isAvailable && !_isListening) {
_speechRecognition.recognitionStartedHandler();
_speechRecognition .listen(locale: "en_US")
.then((transcription) => print('$transcription'));
} else if (_isListening) {
_isListening = false;
transcription = '';
_handleSubmitted(transcription);
_speechRecognition
.stop()
.then((result) => setState(() => _isListening = result));
}
}
),
);
}
在前面的代码片段中,我们返回带有子项IconButton的Container,其子项为Icons.mic。 我们为使用onPressed()的按钮提供了双重功能,以便它可以开始收听用户的声音,并且再次按下该按钮时,可以通过传递记录的字符串以与智能体进行交互来停止记录并调用_handleSubmitted()方法。
首先,我们使用_isAvailable和_isListening变量检查麦克风是否可用并且尚未在收听用户的声音。 如果if语句中的条件为true,则将_isListening的值设置为true。 然后,我们通过调用_speechRecognition上的.listen()方法开始监听。 locale参数指定语言,此处为en_US。 相应的字符串存储在transcription变量中。
当第二次按下麦克风停止录制时,由于_isListening的值设置为true,因此if条件将不满足。 现在,执行else块。 在这里,通过传递记录的字符串以使其可以与智能体进行交互来调用_handleSubmitted(),然后使用结果将_isListening的值设置为true:

成功编译所有代码并将ChatScreen包裹在main.dart文件中的MaterialApp实例中之后,该应用的外观将与前面的屏幕快照类似。
可以在这个页面和这个页面上查看chat_screen.dart文件。
总结
在本章中,我们研究了一些可用于创建聊天机器人的最常用工具,然后对 Dialogflow 进行了深入讨论,以了解所使用的基本术语。 我们了解了 Dialogflow 控制台的工作方式,以便我们可以创建自己的 Dialogflow 智能体。 为此,我们创建了一个意图,该意图可以提取用户的姓名并将其添加为与 Google Assistant 的集成,从而可以用幸运数字进行响应。
在将 Webhook 部署为 Firebase 的 Cloud Functions 并在 Google 版本上创建 Actions 之后,我们创建了一个对话式 Flutter 应用。 我们学习了如何创建对话应用界面,并集成了 Dialogflow 智能体以根据聊天机器人的响应促进深度学习模型。 最后,我们使用 Flutter 插件向应用添加语音识别,该应用再次使用基于深度学习的模型将语音转换为文本。
在下一章中,我们将研究定义和部署自己的自定义深度学习模型并将其集成到移动应用中。
四、认识植物种类
该项目将深入讨论如何构建自定义的 TensorFlow Lite 模型,该模型能够从图像中识别植物物种。 该模型将在移动设备上运行,并将主要用于识别不同的植物物种。 该模型使用在 TensorFlow 的 Keras API 上开发的深层卷积神经网络(CNN)进行图像处理。 本章还向您介绍了如何使用基于云的 API 来执行图像处理。 以 Google Cloud Platform(GCP)提供的 Cloud Vision API 为例。
在本章结束时,您将了解基于云的服务对于深度学习(DL)应用的重要性,设备模型对脱机执行的好处,以及移动设备上的即时深度学习任务。
在本章中,我们将介绍以下主题:
- 图像分类简介
- 了解项目架构
- Cloud Vision API 简介
- 配置 Cloud Vision API 进行图像识别
- 使用软件开发套件(SDK)/工具来建立模型
- 创建用于图像识别的自定义 TensorFlow Lite 模型
- 创建 Flutter 应用
- 运行图像识别
技术要求
本章的技术先决条件如下:
- 具有 Python 3.6 及更高版本的 Anaconda
- TensorFlow 2.0
- 启用了结算功能的 GCP 帐户
- Flutter
您可以在 GitHub 存储库中找到本章介绍的代码。
图像分类简介
图像分类是当今人工智能(AI)的主要应用领域。 我们可以在我们周围的许多地方找到图像分类的实例,例如手机的面部解锁,对象识别,光学字符识别,照片中人物的标记等等。 从人的角度来看,这些任务看起来很简单,但对于计算机而言却并不那么简单。 首先,系统必须从图像中识别出物体或人,并在其周围绘制一个边界框,然后进行分类。 这两个步骤都是计算密集型的,很难在计算机上执行。
研究人员每天都在努力克服图像处理中的若干挑战,例如戴眼镜或新留胡子的人的脸部识别,在拥挤的地方通过脸部识别和跟踪多个人,以及新样式的字符识别。 手写或全新的语言。 深度学习一直以来都是克服这些挑战的好工具,它能够学习图像中的几种不可见图案。
深度学习中用于图像处理的一种非常常见的方法是部署 CNN,我们已经在前面的章节中进行了介绍。 要查看其概念和基本工作,请参阅“第 2 章”,“移动视觉–使用设备上模型的人脸检测”。 在这个项目中,我们将介绍如何将这些模型转换为可以在移动设备上高效运行的压缩模型。
您可能想知道我们将如何构建这些模型。 为了简化语法,对 TensorFlow API 的强大支持以及广泛的技术支持社区,我们将使用 Python 构建这些模型。 很明显,您的开发计算机上将需要 Python 运行时,但对于该项目,我们将选择一种更快,更强大的选项-Google 的 Colaboratory 环境。 Colaboratory(或简称为 Colab)为即时可用的运行时提供了几个重要的机器学习(ML)以及与运行时预装的数据科学相关的模块。 另外,Colaboratory 还为启用图形处理器(GPU)和张量处理单元(TPU)的运行时提供支持。 训练深度学习模型可谓小菜一碟。 然后,我们将直接在设备上部署 TensorFlow Lite 模型,这是一种适合快速运行且不需要定期更新的模型的良好做法。
让我们开始了解项目架构。
了解项目架构
我们将在本章中构建的项目将包括以下技术:
- TensorFlow:使用 CNN 构建分类模型
- TensorFlow Lite:一种浓缩 TensorFlow 模型的格式,可以在移动设备上高效运行
- Flutter:跨平台应用的开发库
您可以通过访问前面的链接来了解这些技术。 以下屏幕快照给出了这些技术在该项目中发挥作用的框图:
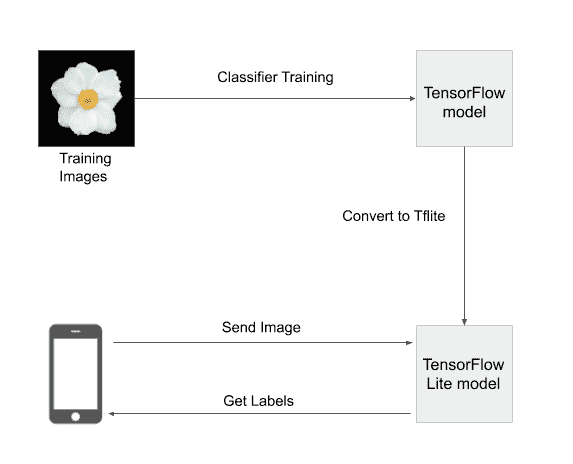
首先,我们将在包含数百张图像的数据集上训练分类模型。 为此,我们将使用 Python 构建 TensorFlow 模型。 然后,必须以的格式保存模型。 tflite,是 TensorFlow Lite 模型的扩展。 后端到此结束,我们切换到前端。
在前端,我们首先使用 Flutter 构建一个应用,该应用可以从设备上存在的图库中加载图像。 Firebase 上的预测模型已下载并缓存到设备上。 从图库中选择的图像将传递到模型,该模型将预测包含图像中显示的植物物种名称的标签。 模型存储在移动设备上,即使离线也可以使用模型。
设备上模型是在移动应用上使用深度学习的强大且首选的方式。 如今,普通人的手机上有几种应用使用设备上的模型来为其应用带来智能。 设备上模型通常是在桌面上开发的模型的压缩形式,并且可能会或可能不会编译为字节码。 诸如 TensorFlow Lite 之类的框架在上执行特殊的优化。 tflite 模型,使其比非移动形式的体积更小,运行更快。
但是,在我们开始为任务构建定制模型之前,让我们全面了解一下我们可以使用哪些预先存在的工具或服务来执行此类任务。
介绍 Cloud Vision API
Cloud Vision API 是 GCP 套件中流行的 API。 它已成为使用计算机视觉构建应用的基准服务。 简而言之,计算机视觉是计算机识别图像中实体的能力,范围从人脸到道路和自动驾驶任务的车辆。 此外,计算机视觉可用于使人类视觉系统执行的任务自动化,例如计算道路上行驶中的车辆的数量,以及观察物理环境的变化。 计算机视觉已在以下领域得到广泛应用:
- 在社交媒体平台上标记公认的人脸
- 从图像中提取文本
- 从图像中识别物体
- 自动驾驶汽车
- 基于医学图像的预测
- 反向图像搜索
- 地标检测
- 名人识别
通过 Cloud Vision API,可以轻松访问前面的某些任务,并为每个识别的实体返回标签。 例如,我们可以看到在下面的屏幕截图中,正确识别了具有 200 年历史的著名工程学杰作 Howrah Bridge。 根据有关地标的信息,可以预测该图像属于加尔各答市:

至于前面截图的标签,最主要的标签是桥和悬索桥,它们都与桥有关。 如前面的屏幕截图所示,还可以通过单击“响应”部分中的“文本”选项卡来检查图像中是否有任何可识别的文本。 要检查图像是否适合安全搜索或单击其中是否有干扰内容的内容,请单击“安全搜索”选项卡。 例如,从著名名人那里接到电话的图像很可能是欺骗,如以下屏幕快照所示:

接下来,我们将从设置 GCP 帐户开始,然后继续创建用于使用 API的示例 Flutter 应用。
为图像识别配置 Cloud Vision API
在本节中,我们将准备通过 Flutter 应用使用 Cloud Vision API。 必须为此任务拥有一个 Google 帐户,我们假设您已经拥有该帐户。 否则,您可以通过以下链接注册免费创建 Google 帐户。
如果您目前拥有 Google 帐户,请继续进行下一部分。
启用 Cloud Vision API
要创建 GCP 帐户,请转到以下链接。 初始注册后,您将能够看到类似于以下屏幕截图的仪表板:
在左上角,您将能够看到三栏菜单,该菜单会列出 GCP 上所有可用的服务和产品的列表。 项目名称显示在搜索栏的左侧。 确保您为该项目创建并启用计费功能,以便本章进一步介绍。 在右侧,您可以看到用户个人资料信息,通知和 Google Cloud Shell 调用图标。 仪表板中心显示当前用户正在运行的服务的各种日志和统计信息。
为了访问 Cloud Vision API 并使用它,我们首先需要为项目启用它并为服务创建 API 密钥。 为此,请执行以下步骤:
- 点击左上方的汉堡菜单图标。 这将弹出一个菜单,类似于以下屏幕快照中所示的菜单:

- 单击“API 和服务”选项。 这将打开 API 仪表板,其中显示了与项目中启用的 API 相关的统计信息。
- 单击“启用 API 和服务”按钮。
- 在出现的搜索框中,键入
Cloud Vision API。 - 单击相关的搜索结果。 该 API 供应商将列为 Google。
- API 页面打开后,单击“启用”。 之后,应该显示一个图标,表明您已启用此 API,并且“启用”按钮变为“管理”。
为了能够使用 Cloud Vision API,您必须为此服务创建一个 API 密钥。 我们将在下一部分中进行此操作。
创建 Cloud Vision API 密钥
现在,您必须创建一个 API 密钥来访问 API 并从中获取响应。 为此,请执行以下步骤:
- 再次打开左侧的导航菜单,并将鼠标悬停在“API 和服务”菜单项上。 出现一个子菜单-单击“凭据”。
- 单击“创建凭据”按钮。 在显示的下拉菜单中,选择 API 密钥,如以下屏幕截图所示:
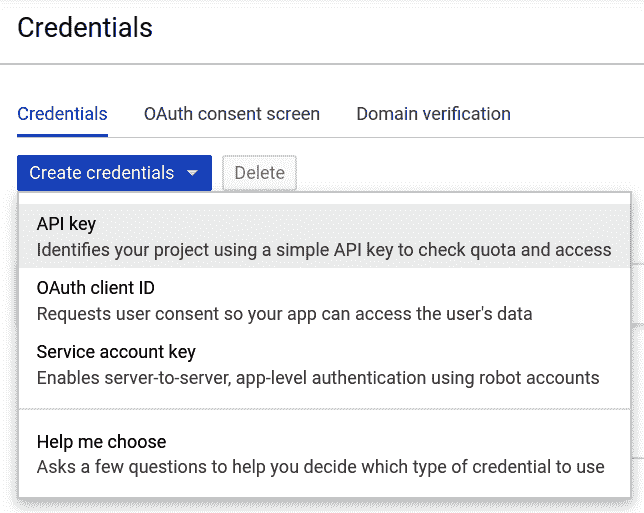
- API 密钥已创建。 在调用 Cloud Vision API 时,您将需要此 API 密钥。
API 密钥方法仅适用于 GCP 的部分选定 API 和服务,并非十分安全。 如果要完全访问所有 API 和服务以及细粒度的安全性,则需要对服务帐户使用该方法。 为此,您可以阅读 GCP 官方文档中的以下文章。
有了 API 密钥,您现在就可以通过 Flutter 应用进行 API 调用了。 在下一部分中,我们将在 Colab 上开发预测模型,并将其保存为.tflite模型。
使用 SDK /工具构建模型
我们介绍了针对现有任务使用预先存在的基于服务的深度学习模型的准备工作,以预测图片中存在的植物种类。 我们将在来自五种不同花的样本上训练图像分类器模型。 然后,模型将尝试确定花朵的任何图像可能所属的物种。 但是,此类模型通常在通常可用的数据集上进行训练,并且有时不具备特定的要求(例如,在科学实验室中)。 因此,您必须学习如何建立自己的模型来预测植物种类。
这可以通过完全从头训练模型或通过扩展先前存在的模型来实现。 从头开始完全训练模型的好处是,您可以完全控制输入到模型中的数据,以及训练过程中对模型所做的任何学习。 但是,如果以这种方式设计模型,则可能会出现缓慢或偏差。 TensorFlow 团队扩展了诸如 MobileNet 模型之类的预训练模型,其优点是速度超快。 该方法的缺点是它可能不如从头开始构建的模型那样准确,但是时间准确率的折衷使 MobileNet 模型更适合在移动设备上运行。
偏差是机器学习模型中非常关键的问题。 在统计术语中,这种偏差(或抽样偏差)是指数据集中的偏斜,即对于数据集中的每个分类类别,其样本数均相等。 这样的类别将获得较少的训练样本,因此很有可能被模型的输出预测所忽略。 偏见模型的一个很好的例子可能是仅在小孩脸上训练的面部识别模型。 该模型可能完全无法识别成年人或老年人的面孔。
您可以在汗学院(Khan Academy)的以下课程中了解有关识别样本偏差的更多信息。
因此,在接下来的部分中,我们将使用 MobileNet 模型来实现在移动设备上快速执行的功能。 为此,我们将使用 TensorFlow 的 Keras API。 用于该任务的语言是 Python,如前所述,它最能涵盖 TensorFlow 框架的功能。 我们假定您在接下来的部分中具有 Python 的基本工作知识。 但是,重要的是要了解 TensorFlow 和 Keras 在此项目中如何协同工作。
我们将在协作环境中工作。 让我们从了解该工具开始。
Google Colab 介绍
Google 提供的协作工具允许用户在公司提供的计算资源上运行类似笔记本的运行时,并可以选择免费使用 GPU 和 TPU,只要用户需要即可。 运行时预装了几个与 ML 和数据科学相关的 Python 模块。 Colaboratory 中的笔记本电脑都可以直接从代码内访问 GCP API(具有适当的配置)。 每个笔记本电脑都有自己的临时存储空间,当断开运行时时,该存储空间将被销毁。 同样,可以将 Colaboratory 笔记本与 GitHub 同步,从而实现最新的版本控制。 通常,协作笔记本位于用户的 Google 云端硬盘存储中。 它们可以与多个用户实时共享和一起工作。
要打开合作实验室,请转到以下链接。
您将获得一个样本,欢迎笔记本。 随意浏览欢迎笔记本,以基本了解 Colaboratory 的工作方式。 在笔记本电脑的左侧,您将能够看到导航选项卡药丸,如以下屏幕截图所示:

“目录”选项卡显示笔记本中创建的标题和子标题,并使用 Markdown 格式进行声明。 “代码片段”选项卡提供了快速单击并插入代码片段的功能,以用于 Colaboratory 上的某些常用功能。 如果您对协作实验室不是很熟悉,但希望执行特定任务,则可能需要在此处搜索任务。 第三个选项卡“文件”是分配给此笔记本的存储空间。 此处存储的文件是此笔记本的专用文件,不会在其他任何地方显示。 使用脚本下载或脚本创建的所有文件都存储在此处。 您可以使用此屏幕上的文件管理器来浏览笔记本的整个目录结构。
在右侧,主要内容部分是笔记本本身。 为了熟悉 Colaboratory 和 Notebooks 的使用,我们强烈建议您阅读以下文章。
创建用于图像识别的自定义 TensorFlow Lite 模型
一旦您在 Colaboratory 取得了不错的成绩,我们所有人都将建立自定义的 TensorFlow Lite 模型,用于识别植物物种的任务。 为此,我们将从新的协作笔记本开始并执行以下步骤:
- 导入项目所需的模块。 首先,我们导入 TensorFlow 和 NumPy。 NumPy 对于处理图像数组很有用,而 TensorFlow 将用于构建 CNN。 可以在以下片段中看到导入模块的代码:
!pip install tf-nightly-gpu-2.0-preview
import tensorflow as tf
import numpy as np
import os
注意第一行中使用的!pip install <package-name>命令。 这用于在正在运行的 Colaboratory 笔记本中安装包,在这种情况下,该笔记本将安装最新的 TensorFlow 版本,该版本内部实现了 Keras 库,该库将用于构建 CNN。
您可以在以下位置阅读有关使用!pip install命令以及其他将新库导入并安装到您的 Colaboratory 运行时的方法的更多信息。
- 要运行代码单元,请按住
Shift键并按Enter。 TensorFlow 版本的下载和安装进度显示在您执行代码的单元下方。这将需要几秒钟,之后您会收到类似于Successfully installed <package_name>, <package_name>, ...的消息。 - 最后,我们需要
os模块来处理文件系统上的文件。 - 下载数据集并提取图像。
现在,我们将从可用的统一资源定位器(URL)下载数据集,并将其提取到名为/content/flower_photos的文件夹中,如以下代码块所示:
_URL = "https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz"
zip_file = tf.keras.utils.get_file(origin=_URL,
fname="flower_photos.tgz",
extract=True, cache_subdir='/content',)
base_dir = os.path.join(os.path.dirname(zip_file), 'flower_photos')
您可以使用左侧面板上的“文件”选项卡浏览提取的文件夹的内容。 您会发现该文件夹还包含五个其他文件夹,其名称分别为:雏菊,蒲公英,玫瑰,向日葵和郁金香。 这些将是花朵的种类,我们将在其上训练我们的模型,此后称为标签。 下一步,我们将再次讨论这些文件夹名称。
- 下一步是设置生成器,以将数据传递到基于 TensorFlow 的 Keras 模型。
- 现在,我们将创建两个生成器函数,用于将数据输入 Keras 神经网络。 Keras 的
ImageDataGenerator类提供了两个工具函数,可通过使用flow_from_directory方法读取磁盘或通过使用flow_from_dataframe方法将图像转换为 NumPy 数组来将数据馈送到 Python 程序。 在这里,我们将使用flow_from_directory方法,因为我们已经有一个包含图像的文件夹。
但是,在此必须注意,包含图像的文件夹名称与图像所属的标签相同是故意的。 这是flow_from_directory方法要求其才能正常运行的文件夹结构的设计。 您可以在此处阅读有关此方法的更多信息。
可以使用以下屏幕快照中显示的目录树来对此进行总结:
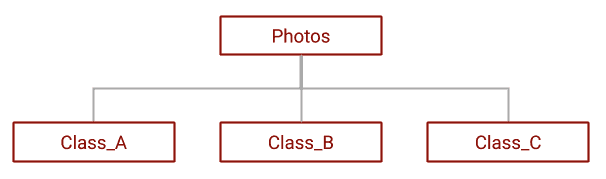
- 然后,我们创建
ImageDataGenerator类的对象,并使用它为训练数据集创建生成器,如以下代码块所示:
IMAGE_SIZE = 224
BATCH_SIZE = 64
datagen = tf.keras.preprocessing.image.ImageDataGenerator(
rescale=1./255,
validation_split=0.2)
train_generator = datagen.flow_from_directory(
base_dir,
target_size=(IMAGE_SIZE, IMAGE_SIZE),
batch_size=BATCH_SIZE,
subset='training')
datagen对象采用两个参数-rescale和validation_split。 rescale参数告诉对象将所有黑白图像转换为0到255的范围,就像红色,绿色和蓝色(RGB)的规模,因为 MobileNet 模型已经在 RGB 图像上进行了训练。 validation_split参数从数据集中分配 20%(0.2 x 100)的图像作为验证集。 但是,我们也需要为验证集创建一个生成器,就像我们为训练集所做的那样。
训练集生成器train_generator接受target_size和batch_size参数以及其他参数。 target_size参数设置要生成的图像的尺寸。 这样做是为了与 MobileNet 模型中的图像尺寸匹配。 batch_size参数指示单个批量应生成多少个图像。
- 对于验证集,我们具有生成器,如以下代码块所示:
val_generator = datagen.flow_from_directory(
base_dir,
target_size=(IMAGE_SIZE, IMAGE_SIZE),
batch_size=BATCH_SIZE,
subset='validation')
- 让我们快速看一下这些生成器生成的数据的形状,如下所示:
for image_batch, label_batch in train_generator:
break
image_batch.shape, label_batch.shape
这将产生以下输出:((64, 224, 224, 3), (64, 5)),这意味着在第一批train_generator中,创建了尺寸为224 x 224 x 3的 64 个图像,以及 5 个单编码格式的 64 个标签。
- 可以通过运行以下代码来获取分配给每个标签的编码索引:
print(train_generator.class_indices)
这将产生以下输出:{'daisy': 0, 'dandelion': 1, 'roses': 2, 'sunflowers': 3, 'tulips': 4}。 请注意标签名称的字母顺序。
- 现在,我们将保存这些标签,以备将来在 Flutter 应用中部署模型时使用,如下所示:
labels = '\n'.join(sorted(train_generator.class_indices.keys()))
with open('labels.txt', 'w') as f:
f.write(labels)
- 接下来,我们将创建一个基本模型并冻结层。 在这一步中,我们将首先创建一个基础模型,然后冻结除最后一层之外的所有模型层,如下所示:
IMG_SHAPE = (IMAGE_SIZE, IMAGE_SIZE, 3)
base_model = tf.keras.applications.MobileNetV2(input_shape=IMG_SHAPE,
include_top=False,
weights='imagenet')
通过导入 TensorFlow 团队提供的MobileNetV2模型来创建基本模型。 输入形状设置为(64、64、3),然后导入 ImageNet 数据集中的权重。 该模型可能在您的系统上不存在,在这种情况下,将从外部资源下载该模型。
- 然后,我们冻结基本模型,以使
MobileNetV2模型中的权重不受未来训练的影响,如下所示:
base_model.trainable = False
- 现在,我们将创建一个扩展的 CNN,并扩展基础模型以在基础模型层之后添加另一个层,如下所示:
model = tf.keras.Sequential([
base_model,
tf.keras.layers.Conv2D(32, 3, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.GlobalAveragePooling2D(),
tf.keras.layers.Dense(5, activation='softmax')
])
我们创建了一个扩展基础模型的顺序模型,这实质上意味着数据是在单层连续地在连续层之间传递的,一次是一层。 我们还添加了具有relu激活函数的 2D 卷积层,然后是Dropout层,然后是Pooling层。 最后,添加带有softmax激活的输出层。
- 然后,必须对模型进行编译以对其进行训练,如下所示:
model.compile(optimizer=tf.keras.optimizers.Adam(),
loss='categorical_crossentropy',
metrics=['accuracy'])
我们将损失设置为分类交叉熵,将模型评估指标设置为预测的准确率。 已经发现Softmax在分类交叉熵作为损失函数时表现最佳,因此是首选。
- 训练并保存模型。 最终,我们处于 ML 最激动人心的步骤之一-训练。 运行以下代码:
epochs = 10
history = model.fit(train_generator,
epochs=epochs,
validation_data=val_generator)
该模型经过 10 个周期的训练,这意味着每个样本至少要在神经网络上抛出 10 次。 注意在此函数中使用了train_generator和val_generator。 即使有 12GB+ 的 RAM 和 TPU 加速可用,训练也需要花费相当长的时间(这在任何个人中端设备上都是过大的)。 您将能够观察到运行上述代码的单元下方的训练日志。
- 然后,我们可以保存模型,之后可以继续转换保存的模型文件,如下所示:
saved_model_dir = ''
tf.saved_model.save(model, saved_model_dir)
- 将模型文件转换并下载到 TensorFlow Lite。 现在,我们可以使用以下代码转换保存的模型文件。 这会将模型另存为
model.tflite文件,如下所示:
converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir)
tflite_model = converter.convert()
with open('model.tflite', 'wb') as f:
f.write(tflite_model)
- 现在,我们需要下载此文件,以将其嵌入到我们构建的 Flutter 应用中。 我们可以使用以下代码进行操作:
from google.colab import files
files.download('model.tflite')
files.download('labels.txt')
注意,我们使用了google.colab库中的files模块。 我们还下载了在“步骤 11”中创建的labels.txt文件。
现在,我们准备开始创建 Flutter 应用,以演示 Cloud Vision API 的用法以及嵌入式 TensorFlow Lite 模型的用法。
创建 Flutter 应用
成功创建可识别多种植物物种的 TensorFlow Lite 模型后,现在让我们创建一个 Flutter 应用,以在移动设备上运行 TensorFlow Lite 模型。 该应用将有两个屏幕。 第一个屏幕将包含两个按钮,供用户在两个不同的模型(Cloud Vision API 和 TensorFlow Lite 模型)之间进行选择,这些模型可用于对任何选定的图像进行预测。 第二个屏幕将包含一个浮动操作按钮(FAB),使用户可以从设备的库中选择图像,一个图像视图来显示用户选择的图像,以及一个文本来使用所选模型显示预测。
以下屏幕截图说明了应用的流程:
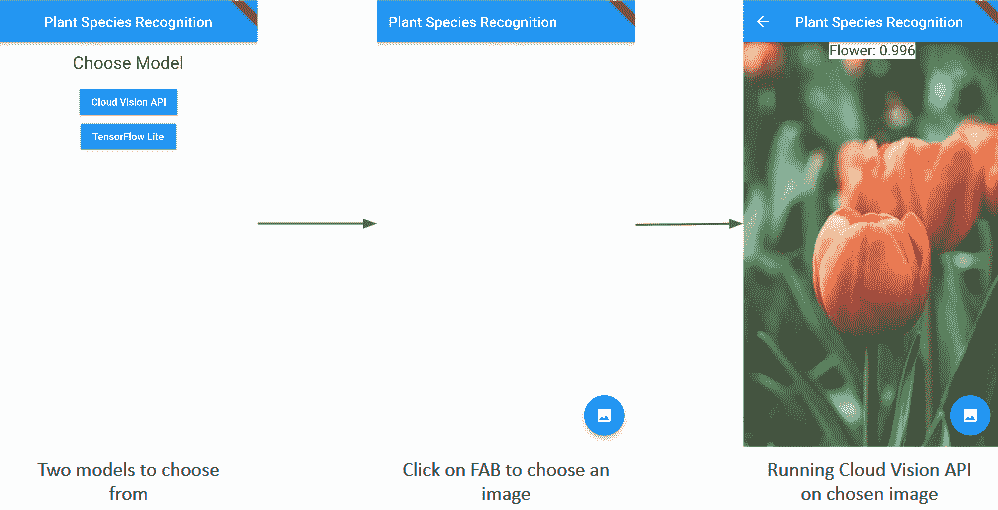
现在,让我们看一下构建应用的步骤。
在两个不同的模型之间进行选择
让我们从创建应用的第一个屏幕开始。 第一个屏幕将包含两个不同的按钮,使用户可以在 Cloud Vision API 和 TensorFlow Lite 模型之间进行选择。
首先,我们创建一个新的choose_a_model.dart文件,其中将包含ChooseModel有状态的小部件。 该文件将包含用于创建应用第一个屏幕的代码,其中包含带有一些文本和两个凸起按钮的列,如以下屏幕截图所示:

创建应用的第一个屏幕的步骤如下:
- 首先,我们将定义一些全局字符串变量,这些变量稍后将在创建用于选择模型的按钮以及保存用户选择的模型时使用,如下所示:
var str_cloud = 'Cloud Vision API';
var str_tensor = 'TensorFlow Lite';
- 现在,让我们定义一个方法来创建一个简单的
Text小部件,如下所示:
Widget buildRowTitle(BuildContext context, String title) {
return Center(
child: Padding(
padding: EdgeInsets.symmetric(horizontal: 8.0, vertical: 16.0),
child: Text(
title,
style: Theme.of(context).textTheme.headline,
),
),
);
}
该方法返回一个小部件,该小部件与中心对齐,并包含一些带有title值的文本作为参数传递,并带有标题为主题的“选择模型”字符串。 使用EdgeInsets.symmetric()属性和EdgeInsets.symmetric()属性,还为文本提供了水平和垂直填充。
- 接下来,我们将定义用于创建按钮的
createButton()方法,如下所示:
Widget createButton(String chosenModel) {
return (RaisedButton(
color: Colors.blue,
textColor: Colors.white,
splashColor: Colors.blueGrey,
child: new Text(chosenModel),
onPressed: () {
var a = (chosenModel == str_cloud ? 0 : 1);
Navigator.push(
context,
new MaterialPageRoute(
builder: (context) => PlantSpeciesRecognition(a)
),
);
}
)
);
}
该方法返回RaisedButton方法,其颜色为blue,textColor值为white,splashColor值为blueGrey。 该按钮具有一个Text子元素,该子元素是使用chosenModel中传递的值构建的。 如果用户单击了“运行 Cloud Vision API”的按钮,则chosenModel的值将为 Cloud Vision API,并且如果单击TensorFlow Lite的按钮,则其值为 TensorFlow Lite。
当按下按钮时,我们首先检查chosenModel中的值。 如果与str_cloud相同(即 Cloud Vision API),则分配给变量a的值为0; 否则,分配给变量a的值为1。 该值与使用Navigator.push()迁移到PlantSpeciesRecognition一起传递,这将在后面的部分中进行介绍。
- 最后,我们创建第一个屏幕的
appBar和主体,并从build()方法返回Scaffold,如下所示:
@override
Widget build(BuildContext context) {
return Scaffold(
appBar: AppBar(
centerTitle: true,
title: Text('Plant Species Recognition'),
),
body: SingleChildScrollView(
child: Column(
mainAxisAlignment: MainAxisAlignment.center,
children: <Widget>[
buildRowTitle(context, 'Choose Model'),
createButton(str_cloud),
createButton(str_tensor),
],
)
)
);
}
appBar包含位于中间的Plant Species Recognition标题。 Scaffold的主体是一列,其中包含一些文本和两个按钮,其值分别为str_cloud和str_tensor,并与中心对齐。
创建第二个屏幕
当用户选择了模型时,应用将迁移到第二个屏幕,该屏幕将允许用户从设备的本地存储中选择一个图像,然后在该图像上运行所选模型以进行预测。 我们从创建一个新文件plant_species_recognition.dart开始,该文件包含PlantSpeciesRecognition有状态的小部件。
创建用户界面
我们将首先创建一个新文件PlantSpeciesRecognition.dart,其中包含一个名为PlantSpeciesRecognition的有状态小部件,然后将覆盖其build()方法以放置用户界面(UI)的应用组件:
- 让我们创建一个带有 FAB 的
Scaffold和一个带有build()方法返回的应用标题的AppBar。 FAB 允许用户从设备的图库中选择图像,以预测图像中包含的植物种类,如下所示:
return Scaffold(
appBar: AppBar(
title: const Text('Plant Species Recognition'),
),
floatingActionButton: FloatingActionButton(
onPressed: chooseImageGallery,
tooltip: 'Pick Image',
child: Icon(Icons.image),
),
);
在前面的代码片段中,AppBar将包含Plant Species Recognition文本。 这将作为应用的标题显示在屏幕顶部的应用栏上。
在 Flutter 中,const关键字有助于冻结对象的状态。 描述为const的对象的完整状态是在应用本身的编译期间确定的,并且保持不变。 同样,当与Text()之类的构造器一起使用时,该关键字对于小型内存优化也很有用。 在代码中添加第二个Text()构造器会重用为第一个Text()构造器分配的内存,从而重用内存空间并使应用更快。
接下来,我们通过指定FloatingActionButton类并传递所需的参数来添加floatingActionButton属性。
FloatingActionButtons是圆形按钮,它们悬停在屏幕内容的顶部。 通常,一个屏幕应该包含一个位于右下角的 FAB,并且不受内容滚动的影响。
onPressed被添加到chooseImageGallery,按下该按钮将被调用。 接下来,我们添加tooltip属性,其String值为'Pick Image',描述按钮将执行的操作。 最后,我们将Icon(Icons.image)添加为child,将材质图标图像放置在 FAB 的顶部。
添加功能
现在,让我们添加功能,以允许用户从设备的图库中选择图像。 我们将使用image_picker插件来执行此操作,并且整个代码将放置在chooseImageGallery方法内,如下所示:
- 首先,将依赖项添加到
pubspec.yaml文件,指定名称和版本号,如下所示:
dev_dependencies:
flutter_test:
sdk: flutter
image_picker: ^0.6.0
有关发布依赖关系的详细讨论,请参阅“第 2 章”,“移动视觉–使用设备上模型的面部检测”。 确保运行Flutter包以在项目中包含依赖项。 要了解有关image_picker插件的更多信息,请访问这里。
- 将库导入到
PlantSpeciesRecognition.dart中,如下所示:
import 'package:image_picker/image_picker.dart';
- 此时,我们在
plant_species_recognition.dart内声明以下两个全局变量:
File_image:存储从图库中选择的图像文件bool _busy(初始值为false):一个用于平滑处理 UI 操作的标志变量
- 现在,让我们定义按下
FloatingActionButton按钮时将调用的chooseImageGallery()方法,如下所示:
Future chooseImageGallery() async {
var image = await ImagePicker.pickImage(source: ImageSource.gallery);
if (image == null) return;
setState(() {
_busy = true;
});
}
在这里,我们使用ImagePicker.pickImage()方法通过将其作为来源来从图库中获取图像。 我们将返回的值存储在变量图像中。 如果从调用返回的值为null,则由于无法对null值执行进一步的操作,因此我们返回了该调用。 否则,请将_busy的值更改为true,以指示正在对该图像进行进一步的操作。
setState()是一个同步回调,用于通知框架对象的内部状态已更改。 此更改可能实际上会影响应用的 UI,因此,框架将需要安排State对象的构建。 请参阅以下链接以进行进一步讨论。
此时,该应用已成功编译,然后按 FAB 启动画廊,可以从中选择图像。 但是,所选的图像不会显示在屏幕上,因此,现在让我们开始吧。
在屏幕上显示所选图像
现在,让我们添加一个小部件以显示在上一节中选择的图像,如下所示:
- 我们将使用小部件列表,从图库中选择的图像以及彼此堆叠或重叠的预测结果显示在屏幕上。 因此,我们首先声明一个空的小部件列表,其中将包含栈的所有子级。 另外,我们声明一个
size实例,以使用MediaQuery类查询包含应用的窗口的大小,如下所示:
List<Widget> stackChildren = [];
Size size = MediaQuery.of(context).size;
- 现在,将图像添加为栈的第一个子项,如下所示:
stackChildren.add(Positioned(
top: 0.0,
left: 0.0,
width: size.width,
child: _image == null ?Text('No Image Selected') : Image.file(_image),
));
Positioned类用于控制栈的子代的位置。 在这里,通过指定top,left和width属性的值。 top和left值分别指定子项的顶部和左侧边缘与栈顶部和左侧边缘的距离,此处为 0,即设备屏幕的左上角 。 width值指定子项的宽度-此处是包含应用的窗口的宽度,这意味着图像将占据整个宽度。
- 接下来,我们将添加子项,该子项将是一个文本,如果
_image的值为null,则表示未选择任何图像; 否则,它包含用户选择的图像。
为了在屏幕上显示栈,我们将stackChildren列表添加为build()方法返回的Scaffold的主体,如下所示:
return Scaffold(
appBar: AppBar(
title: const Text('Plant Species Recognition'),
),
//Add stackChildren in body
body: Stack(
children: stackChildren,
),
floatingActionButton: FloatingActionButton(
onPressed: chooseImageGallery,
tooltip: 'Pick Image',
child: Icon(Icons.image),
),
);
在前面的代码中,我们在Stack()内部传递stackChildren,以创建包含在列表内的所有小部件的覆盖结构。
- 此时编译代码将产生以下结果:
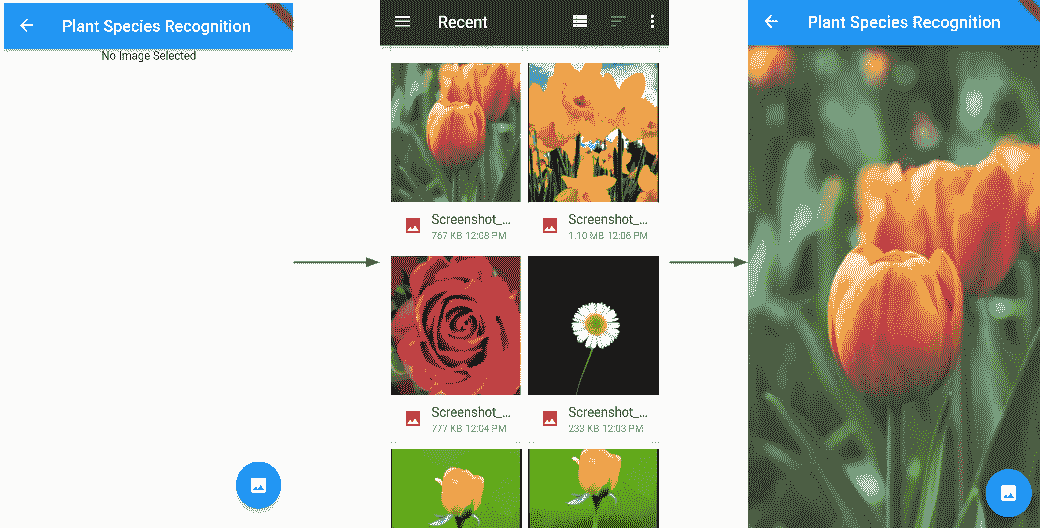
此时,单击FAB将启动图库,并且所选图像将显示在屏幕上。
接下来,我们将在设备上加载 TensorFlow Lite 模型,并向 Cloud Vision API 发出 HTTP 请求,以在所选图像上获得识别结果。
运行图像识别
现在,从图库中选择的图像可用作 Cloud Vision API 和 TensorFlow Lite 模型的两种预测方法的输入。 接下来,让我们定义两种方法。
使用 Cloud Vision API
在本节中,我们简单地定义一个visionAPICall方法,该方法用于向 CloudVision API 发出http Post请求,传入编码为json的请求字符串,该字符串返回一个json响应,该响应被解析以获取所需标签中的值:
- 首先,我们在
pubspec.yaml文件中定义一个http插件依赖项,如下所示:
http: ^0.12.0+2
- 将插件导入
PlantSpeciesRecognition.dart,以帮助发出http请求,如下所示:
import 'package:http/http.dart' as http;
- 现在,我们定义创建请求 URL 并发出
httpPOST请求的方法,如下所示:
List<int> imageBytes = _image.readAsBytesSync();
String base64Image = base64Encode(imageBytes);
为了能够将图像文件与 HTTP 发布请求一起发送进行分析,我们需要将png文件转换为 Base64 格式,即,转换为仅包含美国信息交换标准码(ASCII)的字符串值。 首先,我们使用readAsByteSync()读取_image的内容作为字节列表并将其存储在imageBytes中。 然后,通过将imageBytes列表作为base64Encode的参数传递给我们,以 Base64 格式对该列表进行编码。
- 接下来,我们创建请求字符串,其格式如下:
var request_str = {
"requests":[
{
"image":{
"content": "$base64Image"
},
"features":[
{
"type":"LABEL_DETECTION",
"maxResults":1
}
]
}
]
};
虽然整个字符串将被硬编码,但是内容密钥的值将根据用户选择的图像及其 base64 编码格式而有所不同。
- 我们将需要调用的 URL 存储在
url变量中,如下所示:
var url = 'https://vision.googleapis.com/v1/images:annotate?key=API_KEY;
确保用您生成的密钥替换API_KEY。
- 使用
http.post()方法发出 HTTP 发布请求,并传入url和响应字符串,如下所示:
var response = await http.post(url, body: json.encode(request_str));
print('Response status: ${response.statusCode}');
print('Response body: ${response.body}');
我们还使用response.statusCode检查状态码,如果请求成功,则状态码应为200。
- 由于来自服务器的响应是 JSON 格式,因此我们使用
json.decode()对其进行解码,然后进一步解析它,以将所需的值存储在str变量中,如下所示:
var responseJson = json.decode(response.body);
str = '${responseJson["responses"][0]["labelAnnotations"][0]["description"]}: ${responseJson["responses"][0]["labelAnnotations"][0]["score"].toStringAsFixed(3)}';
- 将所有内容放在一起后,整个
visionAPICall()方法将如下所示:
Future visionAPICall() async {
List<int> imageBytes = _image.readAsBytesSync();
print(imageBytes);
String base64Image = base64Encode(imageBytes);
var request_str = {
"requests":[
{
"image":{
"content": "$base64Image"
},
"features":[
{
"type":"LABEL_DETECTION",
"maxResults":1
}
]
}
]
};
var url = 'https://vision.googleapis.com/v1/images:annotate?key=AIzaSyDJFPQO3N3h78CLOFTBdkPIN3aE9_ZYHy0';
var response = await http.post(url, body: json.encode(request_str));
print('Response status: ${response.statusCode}');
print('Response body: ${response.body}');
var responseJson = json.decode(response.body);
str = '${responseJson["responses"][0]["labelAnnotations"][0]["description"]}: ${responseJson["responses"][0]["labelAnnotations"][0]["score"].toStringAsFixed(3)}';
}
在下一节中,我们将介绍使用设备上 TensorFlow Lite 模型的步骤。
使用设备上的 TensorFlow Lite 模型
现在,让我们为用户的第二选择添加功能,即使用 TensorFlow Lite 模型分析所选图像。 在这里,我们将使用我们先前创建的 TensorFlow Lite 模型。 以下步骤详细讨论了如何使用设备上的 TensorFlow Lite 模型:
- 我们将从在
pubspec.yaml文件中添加tflite依赖关系开始,如下所示:
dev_dependencies:
flutter_test:
sdk: flutter
image_picker: ^0.6.0
//Adding tflite dependency
tflite: ^0.0.5
- 接下来,我们在 Android 中配置
aaptOptions。 将以下代码行添加到android块内的android/app/build.gradle文件中:
aaptOptions {
noCompress 'tflite'
noCompress 'lite'
}
前面的代码段确保tflite文件未以压缩形式存储在 Android 应用包(APK)中。
- 接下来,我们需要将已经保存的
model.tflite和labels.txt文件包括在assests文件夹中,如以下屏幕截图所示:

- 在
pubspec.yaml文件中指定文件的路径,如下所示:
flutter:
uses-material-design: true
//Specify the paths to the respective files
assets:
- assets/model.tflite
- assets/labels.txt
- 现在,我们都准备从在设备上加载并运行我们的第一个 TensorFlow Lite 模型开始。 首先,将
tflite.dart文件导入到PlantSpeciesRecognition.dart中,如下所示:
import 'package:tflite/tflite.dart';
- 为了执行所有相关任务,我们定义了
analyzeTFLite()方法。 在这里,我们从加载模型开始,将model.tflite文件和labels.txt文件作为输入传递给Tflite.loadModel()中的model和labels参数。
如果成功加载模型,我们将结果输出存储在res字符串变量中,该变量将包含success值,如下所示:
String res = await Tflite.loadModel(
model: "assets/model.tflite",
labels: "assets/labels.txt",
numThreads: 1 // defaults to 1
);
print('Model Loaded: $res');
- 现在,我们使用
Tflite.runModelOnImage()方法在图像上运行模型,并传递存储在设备内部的所选图像的路径。 我们将结果存储在recognitions变量中,如下所示:
var recognitions = await Tflite.runModelOnImage(
path: _image.path
);
setState(() {
_recognitions = recognitions;
});
-
一旦模型在图像上成功运行并将结果存储在
recognitions局部变量中,我们将创建_recognitions全局列表并将其状态设置为recognitions中存储的值,以便可以更新 UI 结果正确。将所有内容放在一起后,整个
analyzeTfLite()方法将如下所示:
Future analyzeTFLite() async {
String res = await Tflite.loadModel(
model: "assets/model.tflite",
labels: "assets/labels.txt",
numThreads: 1 // defaults to 1
);
print('Model Loaded: $res');
var recognitions = await Tflite.runModelOnImage(
path: _image.path
);
setState(() {
_recognitions = recognitions;
});
print('Recognition Result: $_recognitions');
}
在成功选择并存储图像后,取决于用户单击的按钮,这是由visionAPICall()和analyzeTFLite()这两个定义的方法从chooseImageGallery()调用的,这取决于传递给窗口的值。 PlantSpeciesRecognition构造器:Cloud Vision API 为 0,TensorFlow Lite 为 1。
修改后的chooseImagGallery()方法如下所示:
Future chooseImageGallery() async {
var image = await ImagePicker.pickImage(source: ImageSource.gallery);
if (image == null) return;
setState(() {
_busy = true;
_image = image;
});
//Deciding on which method should be chosen for image analysis
if(widget.modelType == 0)
await visionAPICall();
else if(widget.modelType == 1)
await analyzeTFLite();
setState(() {
_image = image;
_busy = false;
});
}
在方法调用之前提到await关键字,以确保所有操作都是异步进行的。 在这里,我们还将_image的值设置为image,将_busy的值设置为false,以指示所有处理已完成,并且现在可以更新 UI。
用结果更新用户界面
在上一节“创建用户界面”中,我们通过向stackChildren添加一个额外的子代来更新 UI,以显示用户选择的图像。 现在,我们将另一个子项添加到栈中以显示图像分析的结果,如下所示:
- 首先,我们将添加 Cloud Vision API 的结果,如下所示:
stackChildren.add( Center (
child: Column(
children: <Widget>[
str != null?
new Text(str,
style: TextStyle(
color: Colors.black,
fontSize: 20.0,
background: Paint()
..color = Colors.white,
)
): new Text('No Results')
],
)
)
);
回想一下,请求的 JSON 响应已被解析,格式化并存储在str变量中。 在这里,我们使用str的值创建具有指定颜色和背景的Text。 然后,我们将此Text作为子级添加到列中,并对齐Text以显示在屏幕中央。 最后,我们将整个格式包装在stackChildren.add()周围,以将其添加到 UI 元素栈中。
- 接下来,我们将添加 TensorFlow Lite 的结果,如下所示:
stackChildren.add(Center(
child: Column(
children: _recognitions != null
? _recognitions.map((res) {
return Text(
"${res["label"]}: ${res["confidence"].toStringAsFixed(3)}",
style: TextStyle(
color: Colors.black,
fontSize: 20.0,
background: Paint()
..color = Colors.white,
),
);
}).toList() : [],
),
));
_recognitions列表中存储的 TensorFlow Lite 模型的结果逐元素进行迭代,并映射到使用.map()指定的列表。 列表中的每个元素都将进一步转换为Text,并作为与屏幕中心对齐的列子元素添加。
此外,请注意,需要将 Cloud Vision API 的输出或 TensorFlow Lite 模型的输出添加到栈中。 为了确保这一点,我们将前面的代码包装在if-else块中,这样,如果在构造器中传递的值(即modelChosen)为 0,则添加前者的输出;如果该值是,则添加后者的输出。 是 1。
- 最后,在各种图像集上运行 Cloud Vision API 将提供不同的输出。 以下屏幕快照显示了一些示例:

当 TensorFlow Lite 模型使用相同的图像集时,识别方式会有所不同。 以下屏幕快照显示了一些示例:
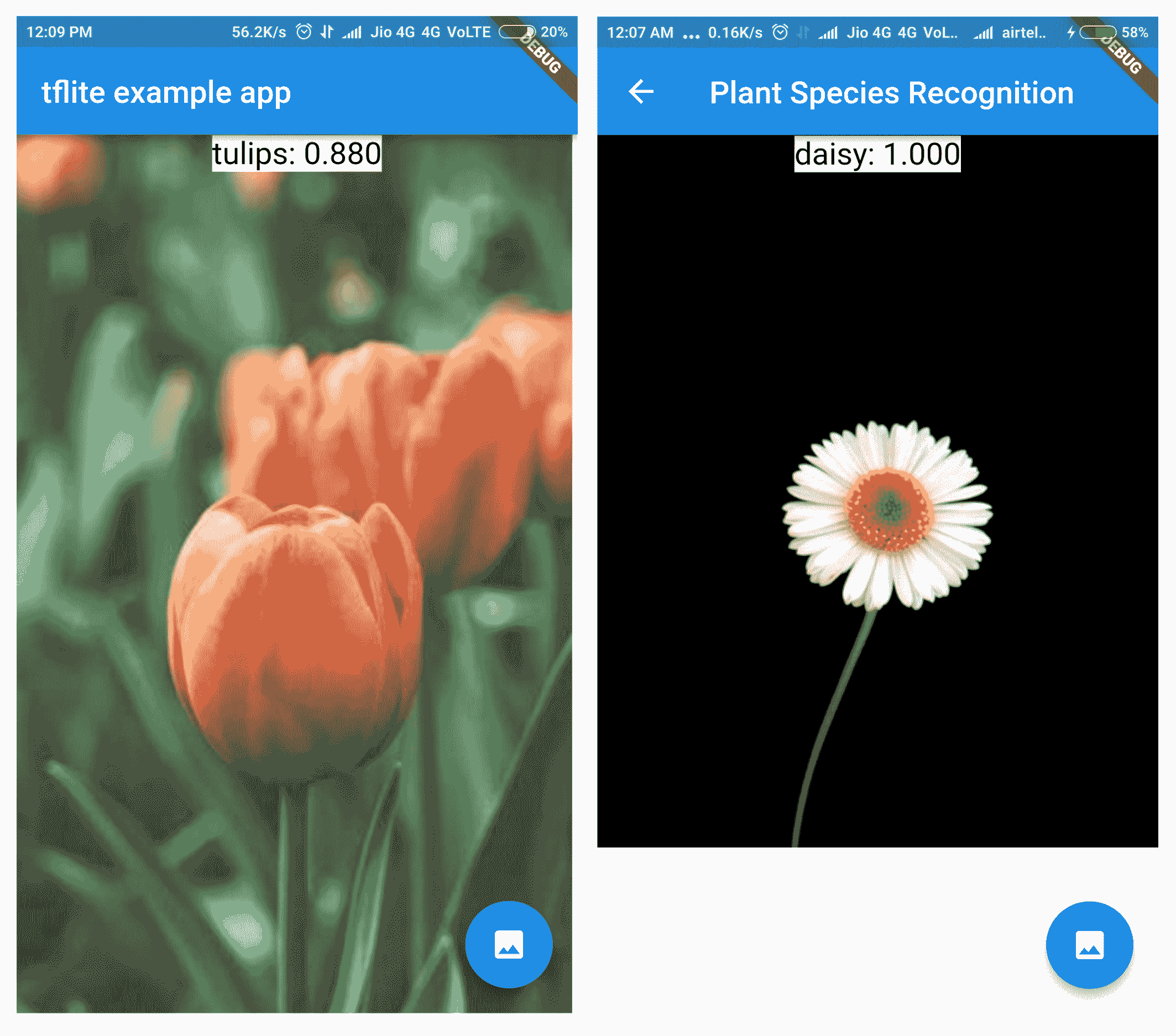
在上一个屏幕截图中,我们可以看到已正确识别将图像加载到图库中的花朵的种类。
总结
在本章中,我们介绍了如何使用流行的基于深度学习的 API 服务来使用图像处理。 我们还讨论了如何通过扩展先前创建的基础模型,将其与定制训练模型一起应用。 虽然我们没有明确提及,但是基础模型的扩展是称为迁移学习(TL)的过程的一部分,其中将在特定数据集上训练的模型导入并用在完全不同的场景中,几乎没有或只有很少的微调。
此外,本章还介绍了 TensorFlow Lite 为什么以及何时适合用于构建模型,以及如何将 Flutter 应用于在离线运行且非常快速的设备模型上进行应用。 本章设定了里程碑,在项目中引入了 Python 和 TensorFlow,在接下来的章节中将广泛使用这两种方法。
在下一章中,我们将介绍计算机科学的一个非常激动人心的领域,即增强现实,并介绍深度学习在现实世界中的应用。
五、从摄像机源生成实时字幕
作为人类,我们每天在不同的场景中看到一百万个物体。 对于人类来说,描述场景通常是一件微不足道的任务:我们所做的事情甚至都不需要花费大量的时间去思考。 但是,机器要理解图像或视频等视觉媒体中呈现给它的元素和场景是一项艰巨的任务。 但是,对于人工智能(AI)的几种应用,具有在计算机系统中理解此类图像的功能很有用。 例如,如果我们能够设计出可以将周围环境实时转换为音频的机器,则对视障人士将大有帮助。 此外,研究人员一直在努力实时生成图像和视频的字幕,以提高网站和应用上呈现的内容的可访问性。
本章介绍了一种使用摄像机供稿实时生成自然语言字幕的方法。 在此项目中,您将创建一个使用存储在设备上的自定义预训练模型的相机应用。 该模型使用深层卷积神经网络(CNN)和长短期记忆(LSTM)生成字幕。
我们将在本章介绍以下主题:
- 设计项目架构
- 了解图像字幕生成器
- 了解相机插件
- 创建相机应用
- 从相机源生成图像字幕
- 创建材质应用
让我们从讨论此项目将要遵循的架构开始。
设计项目架构
在这个项目中,我们将构建一个移动应用,当指向任何风景时,它将能够创建描述该风景的标题。 这样的应用对于有视觉缺陷的人非常有用,因为它既可以用作网络上的辅助技术,又可以与 Alexa 或 Google Home 等语音界面搭配使用,用作日常应用。 该应用将调用一个托管 API,该 API 将为传递给它的任何给定图像生成标题。 API 返回该图像的三个最佳字幕,然后该应用将其显示在应用中相机视图的正下方。
从鸟瞰图可以通过下图说明项目架构:
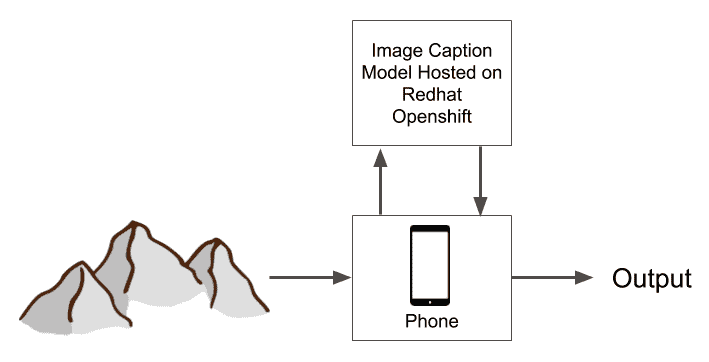
输入将是在智能手机中获得的相机提要,然后将其发送到托管为网络 API 的图像标题生成模型。 该模型在 Red Hat OpenShift 上作为 Docker 容器托管。 图像标题生成模型返回图像的标题,然后将其显示给用户。
有了关于如何构建应用的清晰思路,让我们首先讨论图像字幕的问题以及如何解决它们。
了解图像字幕生成器
计算机科学的一个非常流行的领域是图像处理领域。 它涉及图像的操纵以及我们可以从中提取信息的各种方法。 另一个流行的领域是自然语言处理(NLP),涉及如何制造可以理解和产生有意义的自然语言的机器。 图像标题定义了两个主题的混合,试图首先提取出现在任何图像中的对象的信息,然后生成描述对象的标题。
标题应以有意义的字串形式生成,并以自然语言句子的形式表示。
考虑下图:

图像中可以检测到的物体如下:勺子,玻璃杯,咖啡和桌子。
但是,我们对以下问题有答案吗?
- 杯子里装着咖啡还是汤匙,还是空的?
- 桌子在玻璃上方还是下方?
- 汤匙在桌子上方还是下方?
我们意识到,为了回答上述问题,我们需要使用如下语句:
- 杯子里装着咖啡。
- 玻璃放在桌子上。
- 汤匙放在桌子上。
因此,如果我们试图在图像周围创建标题,而不是简单地识别图像中的项目,我们还需要在可见项目之间建立一些位置和特征关系。 这将帮助我们获得良好的图像标题,例如一杯咖啡在桌子上,旁边放着勺子。 在图像标题生成算法中,我们尝试从图像创建此类标题。
但是,一个字幕可能并不总是足以描述风景,我们可能必须在两个可能相同的字幕之间进行选择,如以下屏幕截图所示:

Allef Vinicius 在 Unsplash 上的照片
您如何在前面的屏幕快照中描述图像?
您可以提出以下任何标题:
- 背景中有两棵树和多云的天空。
- 一把椅子和一把吉他放在地上。
根据用户,这提出了在任何图像中重要的问题。 尽管最近有一些设计用于处理这种情况的方法,例如“注意机制”方法,但在本章中我们将不对其进行深入讨论。
您可以在 CaptionBot 的这个页面上查看由 Microsoft 创建的图像字幕系统的非常酷的演示。
现在让我们定义将用于创建图像字幕模型的数据集。
了解数据集
不出所料,我们需要大量的通用图像以及可能列出的标题。 我们已经在上一节“了解图像字幕生成器”中显示,单个图像可以具有多个字幕,而不必任何一个都错了。 因此,在这个项目中,我们将研究 Flickr8k 数据集。 除此之外,我们还需要由 Jeffrey Pennington,Richard Socher 和 Christopher D. Manning 创建的 GloVE 嵌入。 简而言之,GloVE 告诉我们在给定单词之后可能跟随哪些单词,从而帮助我们从一组不连续的单词中形成有意义的句子。
您可以在这个页面上阅读有关 GloVE 嵌入的更多信息,以及描述它们的论文。
Flickr8k 数据集包含 8,000 个图像样本,以及每个图像的五个可能的标题。 还有其他可用于该任务的数据集,例如具有 30,000 个样本的 Flickr30k 数据集,或具有 180,000 张图像的 Microsoft COCO 数据集。 虽然使用较大的数据库会产生更好的结果,但是为了能够在普通机器上训练模型,我们将不再使用它们。 但是,如果可以使用高级计算能力,则可以肯定地尝试围绕较大的数据集构建模型。
您可以通过伊利诺伊大学厄本那香槟分校提供的以下格式的请求来下载 Flickr8k 数据集。
下载数据集时,您将能够看到以下文件夹结构:
Flickr8k/
- dataset
- images
- 8091 images
- text
- Flickr8k.token.txt
- Flickr8k.lemma.txt
- Flickr_8k.trainImages.txt
- Flickr_8k.devImages.txt
- Flickr_8k.testImages.txt
- ExpertAnnotations.txt
- CrowdFlowerAnnotations.txt
在可用的文本文件中,我们感兴趣的是Flickr8k.token.txt,其中包含dataset目录下images文件夹中每个图像的原始标题。
字幕以以下格式显示:
1007129816_e794419615.jpg#0 A man in an orange hat staring at something .
1007129816_e794419615.jpg#1 A man wears an orange hat and glasses .
1007129816_e794419615.jpg#2 A man with gauges and glasses is wearing a Blitz hat .
1007129816_e794419615.jpg#3 A man with glasses is wearing a beer can crocheted hat .
1007129816_e794419615.jpg#4 The man with pierced ears is wearing glasses and an orange hat .
通过检查,我们可以观察到前面示例中的每一行都包含以下部分:
Image_Filename#Caption_Number Caption
因此,通过浏览dataset/images文件夹中存在的图像的文件中的每一行,我们可以将标题映射到每个图像。
现在开始处理图像标题生成器代码。
建立图像字幕生成模型
在本节中,我们将看一看代码,这些代码将帮助我们创建一个管道,以将抛出该图像的图像转换为字幕。 我们将本节分为四个部分,如下所示:
- 初始化字幕数据集
- 准备字幕数据集
- 训练
- 测试
让我们从项目初始化开始。
初始化字幕数据集
在本节介绍的步骤中,我们将导入项目所需的模块并将数据集加载到内存中。 让我们从导入所需的模块开始,如下所示:
- 导入所需的库,如下所示:
import numpy as np
import pandas as pd
import nltk
from nltk.corpus import stopwords
import re
import string
import pickle
import matplotlib.pyplot as plt
%matplotlib inline
您会看到在这个项目中将使用许多模块和子模块。 在模型的运行中,它们都非常重要,从本质上讲,帮助器模块也是如此。 下一步,我们将导入更多特定于构建模型的模块。
- 导入 Keras 和子模块,如下所示:
import keras
from keras.layers.merge import add
from keras.preprocessing import image
from keras.utils import to_categorical
from keras.models import Model, load_model
from keras.applications.vgg16 import VGG16
from keras.preprocessing.sequence import pad_sequences
from keras.layers import Input, Dense, Dropout, Embedding, LSTM
from keras.applications.resnet50 import ResNet50, preprocess_input, decode_predictions
我们导入了 Keras 模块以及其他几个子模块和方法,以帮助我们快速构建深度学习模型。 Keras 是可用的最受欢迎的深度学习库之一,除 TensorFlow 外,还可以与 Theano 和 PyTorch 等其他框架一起使用。
- 加载字幕-在这一步中,我们将
Flickr8k.token.txt文件中存在的所有字幕加载到单个captions列表中,如下所示:
caption_file = "./data/Flickr8k/text/Flickr8k.token.txt"
captions = []
with open(caption_file) as f:
captions = f.readlines()
captions = [x.strip() for x in captions]
从文件加载所有标题后,让我们看看它们包含的内容,如下所示:
captions[:5]
正如预期的那样,并在前面的“了解数据集”部分中提到,我们获得了数据集中的以下前五行:
['1000268201_693b08cb0e.jpg#0\tA child in a pink dress is climbing up a set of stairs in an entry way .',
'1000268201_693b08cb0e.jpg#1\tA girl going into a wooden building .',
'1000268201_693b08cb0e.jpg#2\tA little girl climbing into a wooden playhouse .',
'1000268201_693b08cb0e.jpg#3\tA little girl climbing the stairs to her playhouse .',
'1000268201_693b08cb0e.jpg#4\tA little girl in a pink dress going into a wooden cabin .']
既然我们已经看到了写入每一行的模式,那么我们就可以继续分割每一行,以便可以将数据放入数据结构中,这比一大串字符串有助于更快地访问和更新。
准备字幕数据集
在以下步骤中,我们将处理加载的字幕数据集,并将其转换为适合对其进行训练的形式:
- 在此步骤中,我们将图像描述拆分并以字典格式存储,以方便将来的代码中使用,如以下代码块所示:
descriptions = {}
for x in captions:
imgid, cap = x.split('\t')
imgid = imgid.split('.')[0]
if imgid not in descriptions.keys():
descriptions[imgid] = []
descriptions[imgid].append(cap)
在前面的代码行中,我们将文件中的每一行细分为图像 ID 和每个图像标题的部分。 我们用它创建了一个字典,其中图像 ID 是字典键,每个键值对都包含五个标题的列表。
- 接下来,我们开始进行基本的字符串预处理,以便继续在字幕上应用自然语言技术,如下所示:
for key, caps in descriptions.items():
for i in range(len(caps)):
caps[i] = caps[i].lower()
caps[i] = re.sub("[^a-z]+", " ", caps[i])
- 另外,为了帮助我们将来分配合适的内存空间大小并准备词汇表,让我们创建标题文本中所有单词的列表,如下所示:
allwords = []
for key in descriptions.keys():
_ = [allwords.append(i) for cap in descriptions[key] for i in cap.split()]
- 一旦创建了所有单词的列表,就可以创建单词的频率计数。 为此,我们使用
collections模块的Counter方法。 一些单词在数据集中很少出现。 删除这些单词是一个好主意,因为它们不太可能频繁出现在用户提供的输入中,因此不会为字幕生成算法增加太多价值。 我们使用以下代码进行操作:
from collections import Counter
freq = dict(Counter(allwords))
freq = sorted(freq.items(), reverse=True, key=lambda x:x[1])
threshold = 15
freq = [x for x in freq if x[1]>threshold]
print(len(freq))
allwords = [x[0] for x in freq]
让我们通过运行以下代码来尝试查看最常用的单词:
freq[:10]
我们看到以下输出:
[('a', 62995),
('in', 18987),
('the', 18420),
('on', 10746),
('is', 9345),
('and', 8863),
('dog', 8138),
('with', 7765),
('man', 7275),
('of', 6723)]
我们可以得出结论,停用词在字幕文本中占很大比例。 但是,由于我们在生成句子时需要它们,因此我们不会将其删除。
训练
在以下步骤中,我们加载训练并测试图像数据集并对其进行训练:
- 现在,将分离的训练和测试文件加载到数据集中。 它们包含图像文件名列表,它们实际上是带有文件扩展名的图像 ID,如以下代码块所示:
train_file = "./data/Flickr8k/text/Flickr_8k.trainImages.txt"
test_file = "./data/Flickr8k/text/Flickr_8k.testImages.txt"
现在,我们将处理训练图像列表文件以提取图像 ID,并省略文件扩展名,因为在所有情况下它都相同,如以下代码片段所示:
with open(train_file) as f:
cap_train = f.readlines()
cap_train = [x.strip() for x in cap_train]
我们对测试图像列表进行相同的操作,如下所示:
with open(test_file) as f:
cap_test = f.readlines()
cap_test = [x.strip() for x in cap_test]
train = [row.split(".")[0] for row in cap_train]
test = [row.split(".")[0] for row in cap_test]
- 现在,我们将创建一个字符串,其中合并每个图像的所有五个可能的标题,并将它们存储在
train_desc中。 字典。 我们使用#START#和#STOP#区分字幕,以便将来在字幕生成中使用它们,如以下代码块所示:
train_desc = {}
max_caption_len = -1
for imgid in train:
train_desc[imgid] = []
for caption in descriptions[imgid]:
train_desc[imgid].append("#START# " + caption + " #STOP#")
max_caption_len = max(max_caption_len, len(caption.split())+1)
- 我们将使用 Keras 模型资源库中的
ResNet50预训练模型。 我们将输入形状设置为224 x 224 x 3,其中224 x 244是将传递给模型的每个图像的尺寸,而 3 是颜色通道的数量。 请注意,与美国国家混合标准技术研究院(MNIST)数据集不同,在该数据集中每个图像的尺寸均相等,而 Flickr8k 数据集则并非如此。 该代码可以在以下代码段中看到:
model = ResNet50(weights="imagenet", input_shape=(224,224,3))
model.summary()
从高速缓存中下载或加载模型后,将为每个层显示模型摘要。 但是,我们需要根据需要重新训练模型,因此我们将删除并重新创建模型的最后两层。 为此,我们使用与加载的模型相同的输入来创建一个新模型,并且输出等效于倒数第二层的输出,如以下代码片段所示:
model_new = Model(model.input, model.layers[-2].output)
- 我们将需要一个函数来重复预处理图像,预测图像中包含的特征,并根据图像中识别出的对象或属性形成特征向量。 因此,我们创建一个
encode_image函数,该函数接受图像作为输入参数,并通过ResNet50重新训练的模型运行图像,从而返回图像的特征向量表示,如下所示:
def encode_img(img):
img = image.load_img(img, target_size=(224,224))
img = image.img_to_array(img)
img = np.expand_dims(img, axis=0)
img = preprocess_input(img)
feature_vector = model_new.predict(img)
feature_vector = feature_vector.reshape((-1,))
return feature_vector
- 现在,我们需要将数据集中的所有图像编码为特征向量。 为此,我们首先需要将数据集中的所有图像一张一张地加载到内存中,并对其应用
encode_img函数。 首先,设置images文件夹的路径,如以下代码片段所示:
img_data = "./data/Flickr8k/dataset/images/"
完成后,我们使用先前创建的训练图像列表遍历文件夹中的所有图像,并对每个图像应用encode_img函数。 然后,将特征向量存储在以图像 ID 为键的字典中,如下所示:
train_encoded = {}
for ix, imgid in enumerate(train):
img_path = img_data + "/" + imgid + ".jpg"
train_encoded[imgid] = encode_img(img_path)
if ix%100 == 0:
print(".", end="")
我们类似地使用以下代码对测试数据集中的所有图像进行编码:
test_encoded = {}
for i, imgid in enumerate(test):
img_path = img_data + "/" + imgid + ".jpg"
test_encoded[imgid] = encode_img(img_path)
if i%100 == 0:
print(".", end="")
- 在接下来的几个步骤中,我们需要将加载的 GloVe 嵌入与项目中包含的单词列表进行匹配。 为此,我们当然必须找到任何给定单词的索引或在任何给定索引处找到该单词。 为方便起见,我们将在字幕数据集中找到的所有单词创建两个字典,将它们映射到索引和索引之间,如以下代码片段所示:
word_index_map = {}
index_word_map = {}
for i,word in enumerate(allwords):
word_index_map[word] = i+1
index_word_map[i+1] = word
我们还将在两个字典中分别使用"#START#"和"#STOP#"字创建两个附加的键值对,如下所示:
index_word_map[len(index_word_map)] = "#START#"
word_index_map["#START#"] = len(index_word_map)
index_word_map[len(index_word_map)] = "#STOP#"
word_index_map["#STOP#"] = len(index_word_map)
- 现在,将 GloVe 嵌入内容加载到项目中,如下所示:
f = open("./data/glove/glove.6B.50d.txt", encoding='utf8')
使用发现open,我们将嵌入内容读入字典,其中每个词都是键,如下所示:
embeddings = {}
for line in f:
words = line.split()
word_embeddings = np.array(words[1:], dtype='float')
embeddings[words[0]] = word_embeddings
读取完embeddings文件后,我们将其关闭以实现更好的内存管理,如下所示:
f.close()
- 现在,让我们在数据集中的标题中的所有单词与 GloVe 嵌入之间创建嵌入矩阵,如以下代码块所示:
embedding_matrix = np.zeros((len(word_index_map) + 1, 50))
for word, index in word_index_map.items():
embedding_vector = embeddings.get(word)
if embedding_vector is not None:
embedding_matrix[index] = embedding_vector
请注意,我们存储的最大嵌入数量为 50,这对于生成长而有意义的字符串是足够的。
- 接下来,我们将创建另一个模型,该模型将在从之前的步骤中获取特征向量后,专门用于为看不见的图像生成标题。 为此,我们将特征向量的形状作为输入来创建
Input层,如以下代码块所示:
in_img_feats = Input(shape=(2048,))
in_img_1 = Dropout(0.3)(in_img_feats)
in_img_2 = Dense(256, activation='relu')(in_img_1)
完成后,我们还需要以 LSTM 的形式在整个训练数据集中的标题中输入单词,以便给定任何单词,我们都能够预测接下来的 50 个单词。 我们使用以下代码进行操作:
in_caps = Input(shape=(max_caption_len,))
in_cap_1 = Embedding(input_dim=len(word_index_map) + 1, output_dim=50, mask_zero=True)(in_caps)
in_cap_2 = Dropout(0.3)(in_cap_1)
in_cap_3 = LSTM(256)(in_cap_2)
最后,我们需要添加一个decoder层,该层以 LSTM 的形式接受图像特征和单词,并在字幕生成过程中输出下一个可能的单词,如下所示:
decoder_1 = add([in_img_2, in_cap_3])
decoder_2 = Dense(256, activation='relu')(decoder_1)
outputs = Dense(len(word_index_map) + 1, activation='softmax')(decoder_2)
现在,通过运行以下代码,在适当添加输入和输出层之后,让我们对该模型进行总结:
model = Model(inputs=[in_img_feats, in_caps], outputs=outputs)
model.summary()
我们得到以下输出,描述了模型层:
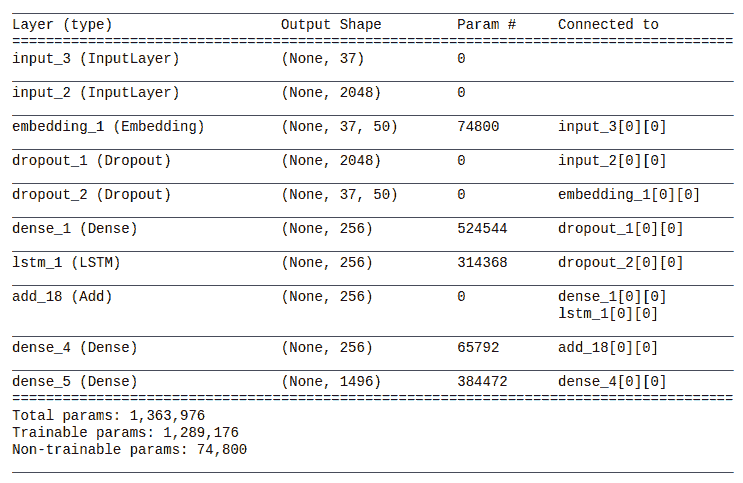
接下来,让我们在训练模型之前设置其权重。
- 我们将在 GloVe 嵌入中的单词和数据集的标题中的可用单词之间插入我们先前创建的
embedding_matrix,如以下代码块所示:
model.layers[2].set_weights([embedding_matrix])
model.layers[2].trainable = False
这样,我们就可以编译模型了,如下所示:
model.compile(loss='categorical_crossentropy', optimizer='adam')
- 由于数据集很大,因此我们不想在训练时将所有图像同时加载到数据集中。 为了促进模型的内存有效训练,我们使用生成器函数,如下所示:
def data_generator(train_descs, train_encoded, word_index_map, max_caption_len, batch_size):
X1, X2, y = [], [], []
n = 0
while True:
for key, desc_list in train_descs.items():
n += 1
photo = train_encoded[key]
for desc in desc_list:
seq = [word_index_map[word] for word in desc.split() if word in word_index_map]
for i in range(1, len(seq)):
xi = seq[0:i]
yi = seq[i]
xi = pad_sequences([xi], maxlen=max_caption_len, value=0, padding='post')[0]
yi = to_categorical([yi], num_classes=len(word_index_map) + 1)[0]
X1.append(photo)
X2.append(xi)
y.append(yi)
if n==batch_size:
yield [[np.array(X1), np.array(X2)], np.array(y)]
X1, X2, y = [], [], []
n = 0
- 我们现在准备训练模型。 在执行此操作之前,我们必须设置模型的一些超参数,如以下代码片段所示:
batch_size = 3
steps = len(train_desc)//batch_size
设置超参数后,我们可以使用以下代码行开始训练:
generator = data_generator(train_desc, train_encoded, word_index_map, max_caption_len, batch_size)
model.fit_generator(generator, epochs=1, steps_per_epoch=steps, verbose=1)
model.save('./model_weights/model.h5')
测试
现在,在以下步骤中,我们将基于前面步骤中训练的模型创建用于预测字幕的功能,并在示例图像上测试字幕:
- 我们终于到了可以使用模型生成图像标题的阶段。 我们创建了一个函数,该函数可以吸收图像并使用
model.predict方法在每个步骤中提出一个单词,直到在预测中遇到#STOP#。 它在那里停止并输出生成的字幕,如下所示:
def predict_caption(img):
in_text = "#START#"
for i in range(max_caption_len):
sequence = [word_index_map[w] for w in in_text.split() if w in word_index_map]
sequence = pad_sequences([sequence], maxlen=max_caption_len, padding='post')
pred = model.predict([img, sequence])
pred = pred.argmax()
word = index_word_map[pred]
in_text += (' ' + word)
if word == "#STOP#":
break
caption = in_text.split()[1:-1]
return ' '.join(caption)
- 让我们在测试数据集中的某些图像上测试生成模型,如下所示:
img_name = list(test_encoded.keys())[np.random.randint(0, 1000)]
img = test_encoded[img_name].reshape((1, 2048))
im = plt.imread(img_data + img_name + '.jpg')
caption = predict_caption(img)
print(caption)
plt.imshow(im)
plt.axis('off')
plt.show()
假设我们将以下屏幕截图中显示的图像输入了算法:

对于前面的屏幕快照中显示的图像,我们获得了以下生成的标题:一只棕色的狗正穿过草丛。 虽然标题不是很准确,但完全遗漏了图片中的第二只动物,但它的确足以确定一条棕色的狗在草地上奔跑。
但是,我们训练有素的模型非常不准确,因此不适合用于生产或实验以外的用途。 您可能已经注意到,我们将训练中的周期数设置为 1,这是一个非常低的值。 这样做是为了使该程序的训练在合理的时间内完成,以供您阅读本书!
在下一节中,我们将研究如何将图像字幕生成模型部署为 API 并使用它来生成实时的摄像机供稿字幕。
创建一个简单的可单击部署的图像标题生成模型
虽然我们在上一节“测试”中开发的图像标题生成模型看起来不错,但不是很好。 因此,在本节中,我们将向您展示一种方法,以单击方式将可直接用于生产环境的模型作为 Docker 映像部署在 Red Hat OpenShift 上,并由 IBM 出色的机器学习专家创建。
将微服务用于在任何网站上执行的此类微小且专用的操作是一种非常普遍的做法,因此,我们将把此图像标题服务视为微服务。
我们将使用的图像是 IBM 开发的 MAX 图像字幕生成器模型。 它基于im2txt模型的代码,作为 《Show and Tell: Lessons learned from the 2015 MSCOCO Image Captioning Challenge》论文的可公开使用的 TensorFlow 实现托管在 GitHub 上。
在更大的 Microsoft COCO 数据集上训练了图像中使用的模型,该数据集包含超过 200,000 个带标签图像的实例,以及总共超过 300,000 个图像实例。 该数据集包含包含超过 150 万个不同对象的图像,并且是用于构建对象检测和图像标记模型的最大,最受欢迎的数据集之一。 但是,由于其巨大的尺寸,很难在低端设备上训练模型。 因此,我们将使用已经可用的 Docker 映像,而不是尝试在其上训练我们的模型。 但是,项目章节前面各节中描述的方法与 Docker 映像中的代码所使用的方法非常相似,并且在有足够的可用资源的情况下,您绝对可以尝试训练并提高模型的准确率。
您可以在以下链接中查看有关此 Docker 映像项目的所有详细信息。
您可以在此 Docker 映像的项目页面上了解其他可用的方法来部署此映像,但我们将向您展示在 Red Hat OpenShift 上的部署,从而使您只需单击几下即可快速测试模型。 。
让我们看看如何部署此映像,如下所示:
- 创建一个 Red Hat OpenShift 帐户。 为此,请将浏览器指向这里,然后单击“免费试用”。
- 选择尝试 RedHat OpenShift Online,如以下屏幕截图所示:

- 在下一个屏幕中,选择“注册 Openshift Online”。 然后,单击页面右上方的“注册”以找到“注册”页面。
- 填写所有必要的详细信息,然后提交表格。 系统将要求您进行电子邮件验证,完成后将带您进入订阅确认页面,该页面将要求您确认平台免费订阅的详细信息,如以下屏幕快照所示:

请注意,前面的订阅详细信息随时可能更改,并且可能反映订阅的其他值,区域或持续时间。
- 确认订阅后,您将需要等待几分钟才能配置系统资源。 设置完成后,您应该能够看到将带您进入管理控制台的按钮,如以下屏幕截图所示:
在上一个屏幕快照中显示的管理控制台的左侧,您可以找到各种菜单选项,并且在当前页面的中心,将提示您创建一个新项目。
- 单击“创建项目”,然后在出现的对话框中填写项目名称。 确保您创建的项目具有唯一的名称。 创建项目后,将为您提供一个仪表板,其中显示了对所有可用资源及其使用情况的监视。
在左侧菜单上,选择“开发人员”以切换到控制台的“开发人员”视图,如以下屏幕截图所示:

- 现在,您应该能够看到控制台的 Developer 视图以及更新的左侧菜单。 在这里,单击“拓扑”以获取以下部署选项:
- 在显示有部署选项的屏幕中单击“容器映像”,以调出用于容器映像部署的表单。
在此处,将图像名称填写为codait/max-image-caption-generator,然后单击“搜索”图标。 其余字段将自动获取,并且将显示与图像有关的信息,如以下屏幕截图所示:
- 在显示部署详细信息的下一个屏幕中,单击屏幕中央的“部署的映像”选项,如以下屏幕截图所示:
- 然后,向下滚动显示在屏幕右侧的信息面板,找到“路由”信息,该信息类似于以下屏幕截图:

单击此路由,将为您提供以下已成功部署的 API 的 Swagger UI:

您可以通过将图像发布到/model/predict路由来快速检查模型的工作情况。 随意使用 Swagger UI 可以很好地了解其表现。 您也可以使用/model/metadata路由找到模型元数据。
我们准备在项目中使用此 API。 让我们在接下来的部分中了解如何构建相机应用以及如何将此 API 集成到应用中。 我们首先使用相机插件构建应用。
了解相机插件
通过camera依赖项提供的相机插件,使我们可以自由访问设备的摄像机。 它为 Android 和 iOS 设备提供支持。 该插件是开源的,并托管在 GitHub 上,因此任何人都可以自由访问代码,修复错误并提出对当前版本的增强建议。
该插件可用于在小部件上显示实时摄像机预览,捕获图像并将其本地存储在设备上。 它也可以用来录制视频。 此外,它具有访问图像流的功能。
可以通过以下三个简单步骤将相机插件添加到任何应用:
- 安装包
- 添加用于持久存储和正确执行的方法
- 编程
现在让我们详细讨论每个步骤。
安装相机插件
要在应用中使用相机插件,我们需要在pubspec.yaml文件中添加camera作为依赖项。 可以按照以下步骤进行:
camera: 0.5.7+3
最后,运行flutter pub get将依赖项添加到应用。
添加用于持久存储和正确执行的方法
对于 iOS 设备,我们还需要指定一个空间来存储系统可以轻松访问的配置数据。 iOS 设备借助Info.plist文件来确定要显示的图标,应用支持的文档类型以及其他行为。 您需要在此步骤中修改ios/Runner/Info.plist中存在的Info.plist文件。
这可以通过添加以下文本来完成:
<key>NSCameraUsageDescription</key>
<string>Can I use the camera please?</string>
<key>NSMicrophoneUsageDescription</key>
<string>Can I use the mic please?</string>
对于 Android 设备,插件正常运行所需的最低软件开发套件(SDK)版本是 21。因此,请将最低 Android SDK 版本更改为 21(或更高版本), 存储在android/app/build.gradle文件中,如下所示:
minSdkVersion 21
安装依赖项并进行必要的更改之后,现在让我们开始编写应用代码。
编码
安装插件并进行必要的修改后,现在就可以使用它来访问相机,单击图片并录制视频。
涉及的最重要步骤如下:
- 通过运行以下代码导入插件:
import 'package:camera/camera.dart';
- 通过运行以下代码来检测可用的摄像机:
List<CameraDescription> cameras = await availableCameras();
- 初始化相机控件实例,如下所示:
CameraController controller = CameraController(cameras[0], ResolutionPreset.medium);
controller.initialize().then((_) {
if (!mounted) {
return;
}
setState(() {});
});
- 通过运行以下代码来处理控制器实例:
controller?.dispose();
现在,我们已经具备了相机插件的基本知识,让我们为应用构建实时相机预览。
创建相机应用
现在,我们将开始构建移动应用,以为指向相机的对象生成标题。 它包括一个用于捕获图像的相机预览和一个用于显示模型返回的字幕的文本视图。
该应用可以大致分为两部分,如下所示:
- 建立相机预览
- 集成模型来获取标题
在以下部分中,我们将讨论构建基本的相机预览。
建立相机预览
现在,我们将为应用构建摄像机预览。 我们首先创建一个新文件generate_live_caption.dart和一个GenerateLiveCaption有状态小部件。
让我们看一下创建实时摄像机预览的以下步骤:
- 要添加实时摄像机预览,我们将使用
camera插件。 首先,将依存关系添加到pubspec.yaml文件中,如下所示:
camera: ^0.5.7
接下来,我们需要通过运行flutter pub get将依赖项添加到项目中。
-
现在,我们创建一个新文件
generate_live_captions.dart,其中包含GenerateLiveCaptions有状态的小部件。 进一步步骤中描述的所有代码将包含在_GenerateLiveCaptionState类中。 -
导入
camera库。 我们将其导入generate_live_captions.dart,如下所示:
import 'package:camera/camera.dart';
- 现在,我们需要检测设备上所有可用的摄像机。 为其定义
detectCameras()函数,如下所示:
Future<void> detectCameras() async{
cameras = await availableCameras();
}
cameras是包含所有可用摄像机的全局列表,并在GenerateLiveCaptionState中声明,如下所示:
List<CameraDescription> cameras;
- 现在,我们使用
initializeController()方法创建CameraController的实例,如下所示:
void initializeController() {
controller = CameraController(cameras[0], ResolutionPreset.medium);
controller.initialize().then((_) {
if (!mounted) {
return;
}
setState(() {});
});
}
在应用中,我们将使用设备的后置摄像头,因此我们使用camera[0]创建CameraController实例,并使用ResolutionPreset.medium将分辨率指定为中等。 接下来,我们使用controller.initialize()初始化控制器。
- 为了在应用的屏幕上显示摄像机源,我们定义了
buildCameraPreview()方法,如下所示:
Widget _buildCameraPreview() {
var size = MediaQuery.of(context).size.width;
return Container(
child: Column(
children: <Widget>[
Container(
width: size,
height: size,
child: CameraPreview(controller),
),
]
)
);
}
在前面的方法中,我们使用MediaQuery.of(context).size.width获取容器的宽度并将其存储在size变量中。 接下来,我们创建一列小部件,其中第一个元素是Container。 Container的子项只是CameraPreview,用于在应用的屏幕上显示摄像机的信息。
- 现在,我们覆盖
initState,以便在初始化GenerateLiveCaption后立即检测到所有摄像机,如下所示:
@override
void initState() {
super.initState();
detectCameras().then((_){
initializeController();
});
}
在前面的代码片段中,我们仅调用detectCameras()首先检测所有可用的摄像机,然后调用initializeController()用后置摄像机初始化CameraController。
- 要从相机供稿生成字幕,我们将从相机供稿中拍摄照片并将其存储在本地设备中。 这些单击的图片将稍后从图像文件中检索以生成标题。 因此,我们需要一种读取和写入文件的机制。 我们通过在
pubspec.yaml文件中添加以下依赖项来使用path_provider插件:
path_provider: ^1.4.5
接下来,我们通过在终端中运行flutter pub get来安装包。
- 要在应用中使用
path_provider插件,我们需要通过在文件顶部添加import语句将其导入generate_live_caption.dart中,如下所示:
import 'package:path_provider/path_provider.dart';
- 要将图像文件保存到磁盘,我们还需要导入
dart:io库,如下所示:
import 'dart:io';
- 现在,让我们定义一种方法
captureImages(),以从相机源中捕获图像并将其存储在设备中。 这些存储的图像文件将在以后用于生成字幕。 该方法定义如下:
capturePictures() async {
String timestamp = DateTime.now().millisecondsSinceEpoch.toString();
final Directory extDir = await getApplicationDocumentsDirectory();
final String dirPath = '${extDir.path}/Pictures/generate_caption_images';
await Directory(dirPath).create(recursive: true);
final String filePath = '$dirPath/${timestamp}.jpg';
controller.takePicture(filePath).then((_){
File imgFile = File(filePath);
});
}
在前面的代码片段中,我们首先使用DateTime.now().millisecondsSinceEpoch()找出当前时间(以毫秒为单位),然后将其转换为字符串并将其存储在变量timestamp中。 时间戳将用于为我们将进一步存储的图像文件提供唯一的名称。 接下来,我们使用getApplicationDocumentsDirectory()获取可用于存储图像的目录的路径,并将其存储在Directory类型的extDir中。 现在,我们通过在外部目录后附加'/Pictures/generate_caption_images'来创建适当的目录路径。 然后,我们通过将目录路径与当前时间戳组合并为其指定.jpg格式来创建最终的filePath。 由于时间戳始终具有不同的值,因此所有单击的图像的filePath将始终是唯一的。 最后,我们使用当前的相机控制器实例调用takePicture()并传入filePath来捕获图像。 我们存储在imgFile中创建的图像文件,稍后将用于生成适当的字幕。
- 如前所述,为了从实时摄像机的提要中生成字幕,我们会定期捕获图像。 为了使它起作用,我们修改
initializeController()并添加一个计时器,如下所示:
void initializeController() {
controller = CameraController(cameras[0], ResolutionPreset.medium);
controller.initialize().then((_) {
if (!mounted) {
return;
}
setState(() {});
const interval = const Duration(seconds:5);
new Timer.periodic(interval, (Timer t) => capturePictures());
});
}
在initializeController()内部,一旦正确初始化并安装了摄像机控制器,我们将使用Duration()类创建 5 秒的持续时间,并将其存储在间隔中。 现在,我们使用Timer.periodic创建一个定期计时器,并为其设置 5 秒的间隔。 此处指定的回调为capturePictures()。 将在指定间隔内重复调用它。
至此,我们创建了一个实时摄像机供稿,该供稿显示在屏幕上,并且能够以 5 秒的间隔捕获图像。 在下一部分中,我们将集成模型以为所有捕获的图像生成标题。
从相机源生成图像字幕
现在,我们对图像标题生成器有了一个清晰的想法,并有了一个带有摄像头提要的应用,我们准备为摄像头提要生成图像的标题。 要遵循的逻辑非常简单。 图像是在特定时间间隔从实时摄像机的提要中捕获的,并存储在设备的本地存储中。 接下来,检索存储的图片,并为托管模型创建HTTP POST请求,传入检索的图像以获取生成的字幕,解析响应并将其显示在屏幕上。
现在让我们看一下详细步骤,如下所示:
- 我们首先将
http依赖项添加到pubspec.yaml文件,以发出http请求,如下所示:
http: ^0.12.0
使用flutter pub get将依赖项安装到项目。
- 要在应用中使用
http包,我们需要将其导入generate_live_caption.dart中,如下所示:
import 'package:http/http.dart' as http;
- 现在,我们定义一个方法
fetchResponse(),它使用一个图像文件并使用该图像为托管模型创建一个帖子,如下所示:
Future<Map<String, dynamic>> fetchResponse(File image) async {
final mimeTypeData =
lookupMimeType(image.path, headerBytes: [0xFF, 0xD8]).split('/');
final imageUploadRequest = http.MultipartRequest(
'POST',
Uri.parse(
"http://max-image-caption-generator-mytest865.apps.us-east-2.starter.openshift-online.com/model/predict"));
final file = await http.MultipartFile.fromPath('image', image.path,
contentType: MediaType(mimeTypeData[0], mimeTypeData[1]));
imageUploadRequest.fields['ext'] = mimeTypeData[1];
imageUploadRequest.files.add(file);
try {
final streamedResponse = await imageUploadRequest.send();
final response = await http.Response.fromStream(streamedResponse);
final Map<String, dynamic> responseData = json.decode(response.body);
parseResponse(responseData);
return responseData;
} catch (e) {
print(e);
return null;
}
}
在上述方法中,我们首先通过查看文件的头字节来找到所选文件的 mime 类型。 然后,我们按照托管 API 的要求初始化一个多部分请求。 我们将传递给函数的文件附加为image POST 参数。 由于image_picker存在一些错误,因此错误地将图像扩展名与文件名(例如filenamejpeg)混合在一起,因此我们在请求正文中明确传递了图像扩展名,这会在服务器端管理或验证文件扩展名时产生问题。 响应采用 JSON 格式,因此,我们需要使用json.decode()对其进行解码,并使用res.body传入响应的主体。 现在,我们通过调用下一步定义的parseResponse()来解析响应。 此外,我们使用catchError()检测并打印执行POST请求时可能发生的任何错误。
- 成功执行
POST请求并从模型中获得带有传递的图像的标题的响应之后,我们在parseResponse()方法内部解析响应,如下所示:
void parseResponse(var response) {
String resString = "";
var predictions = response['predictions'];
for(var prediction in predictions) {
var caption = prediction['caption'];
var probability = prediction['probability'];
resString = resString + '${caption}: ${probability}\n\n';
}
setState(() {
resultText = resString;
});
}
在上述方法中,我们首先存储response['predictions']中存在的所有预测的列表,并将其存储在prediction变量中。 现在,我们使用prediction变量遍历for each循环内的每个预测。 对于每个预测,我们分别取出prediction['caption']和prediction['probability']中存储的标题和概率。 我们将它们附加到resString字符串变量,该变量将包含所有预测的字幕以及概率。 最后,我们将resultText的状态设置为resString中存储的值。 resultText是此处的全局字符串变量,将在接下来的步骤中使用它来显示预测的字幕。
- 现在,我们修改
capturePictures(),以便每次捕获新图像时都会发出 HTTP 发布请求,如下所示:
capturePictures() async {
. . . . .
controller.takePicture(filePath).then((_){
File imgFile = File(filePath);
fetchResponse(imgFile);
});
}
在前面的代码片段中,我们向fetchResponse()添加了一个调用,并传入了图像文件。
- 现在,让我们修改
buildCameraPreview()以显示所有预测,如下所示:
Widget buildCameraPreview() {
. . . . .
return Container(
child: Column(
children: <Widget>[
Container(
. . . . .
child: CameraPreview(controller),
),
Text(resultText),
]
)
);
}
在前面的代码片段中,我们简单地将Text与result.Text相加。 result.Text是一个全局字符串变量,它将包含“步骤 5”中所述的所有预测,并声明如下:
String resultText = "Fetching Response..";
- 最后,我们重写
build()方法以为应用创建最终的脚手架,如下所示:
@override
Widget build(BuildContext context) {
return Scaffold(
appBar: AppBar(title: Text('Generate Image Caption'),),
body: (controller.value.isInitialized)?buildCameraPreview():new Container(),
);
}
在前面的代码片段中,我们返回了一个标题为Generate Image Caption的appBar支架。 主体最初设置为空容器。 初始化摄像机控制器后,将更新主体以显示摄像机供稿以及预测的字幕。
- 最后,我们按以下方式处置摄像头控制器:
@override
void dispose() {
controller?.dispose();
super.dispose();
}
现在,我们已经成功创建了一种在屏幕上显示实时摄像机供稿的机制。 实时摄像头的提要以 5 秒的间隔被捕获,并作为输入发送到模型。 然后,所有捕获图像的预测字幕将显示在屏幕上。
在下一节中,我们现在创建最终的材质应用以将所有内容整合在一起。
创建材质应用
在使所有段正常工作之后,让我们创建最终的材质应用。 在main.dart文件中,我们创建StatelessWidget并覆盖build()方法,如下所示:
class MyApp extends StatelessWidget {
@override
Widget build(BuildContext context) {
return MaterialApp(
title: 'Flutter Demo',
theme: ThemeData(
primarySwatch: Colors.blue,
),
home: GenerateLiveCaption()
);
}
}
最后,我们执行以下代码:
void main() => runApp(MyApp());
您应该能够拥有一个应用屏幕,如以下屏幕截图所示:

请注意图像中显示的标题,如下所示:
- 放在桌子上的便携式计算机。
- 放在桌子上的一台打开的便携式计算机。
- 放在一张木桌上的一台打开的便携式计算机。
这些标题的描述非常准确。 但是,由于训练数据集中相关图片的不可用,它们有时可能表现不佳。
总结
在本章中,我们了解了如何创建一个应用,该应用使用深层的 CNN 和 LSTM 为摄像机的提要实时生成字幕。 我们还看到了如何快速将以 Docker 映像形式提供的某些机器学习/深度学习模型部署到 Red Hat OpenShift,并以可调用 API 的形式轻松获取它们。 从应用开发人员的角度来看,这是至关重要的,因为当与一组机器学习开发人员一起工作时,他们通常会为您提供要使用的模型的 Docker 映像,这样您就无需在其中执行任何代码或配置。 系统。 可以将这种应用用于多种用途,例如为盲人创建辅助技术,生成当时发生的事件的成绩单,或者(例如)为孩子提供现场指导,以帮助他们识别环境中的物体。 我们介绍了如何应用 Flutter 相机插件并在框架上进行深度学习。
在下一章中,我们将研究如何开发用于执行应用安全性的深度学习模型。