大数据开发必备面试题Flume篇合集
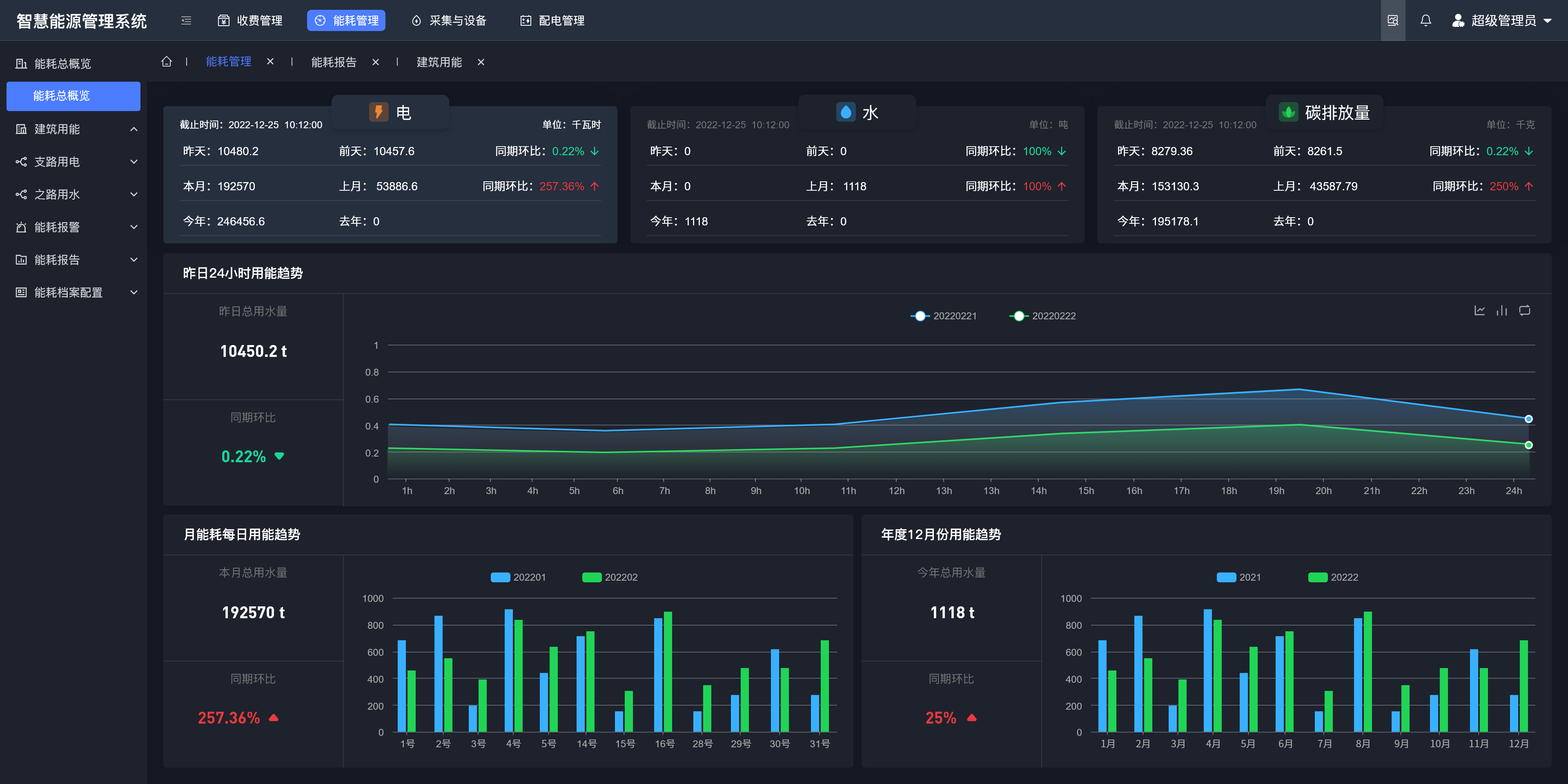
- 1 、详细介绍Flume有哪些组件?
- 2、你是如何实现Flume数据传输的监控的?
- 3、Flume参数怎么调优?
- 4、简述下Flume的事务机制。
- 5、 Flume采集数据会丢失吗?
- 6、简述下Flume使用场景。
- 7、简述下 Flume丢包问题。
- 8、 数据怎么采集到Kafka,用什么实现方式?
- 9、 Flume管道内存,flume宕机了数据丢失怎么解决?
- 10、简述下Flume不采集Nginx日志,通过Logger4j采集日志的优缺点。
- 11、Flume和Kafka采集日志区别,采集日志时中间停了,怎么记录之前的日志?
- 12、如何实现Flume数据传输断点续传?
1 、详细介绍Flume有哪些组件?
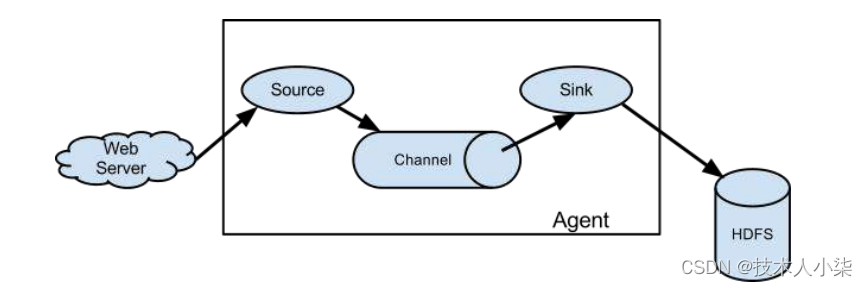
(1)source:用于采集数据,Source是产生数据流的地方,同时Source会将产生的数据流传输到Channel,这个有点类似于Java IO部分的Channel;
(2)channel:用于桥接Sources和Sinks,类似于一个队列;
(3)sink:从Channel收集数据,将数据写到目标源(可以是下一个Source,也可以是HDFS或者HBase)。
2、你是如何实现Flume数据传输的监控的?
使用第三方框架Ganglia实时监控flume。
3、Flume参数怎么调优?
(1)Source
增加Source个数(使用Tair Dir Source时可增加FileGroups个数)可以增大Source的读取数据的能力。
例如:当某一个目录产生的文件过多时需要将这个文件目录拆分成多个文件目录,同时配置好多个Source 以保证Source有足够的能力获取到新产生的数据。
batchSize参数决定Source一次批量运输到Channel的event条数,适当调大这个参数可以提高Source搬运Event到Channel时的性能。
(2)Channel
type 选择memory时Channel的性能最好,但是如果Flume进程意外挂掉可能会丢失数据。type选择file时Channel的容错性更好,但是性能上会比memory channel差。
使用file Channel时dataDirs配置多个不同盘下的目录可以提高性能。
Capacity 参数决定Channel可容纳最大的event条数。transactionCapacity 参数决定每次Source往channel里面写的最大event条数和每次Sink从channel里面读的最大event条数。transactionCapacity需要大于Source和Sink的batchSize参数。
(3) Sink
增加Sink的个数可以增加Sink消费event的能力。Sink也不是越多越好够用就行,过多的Sink会占用系统资源,造成系统资源不必要的浪费。
batchSize参数决定Sink一次批量从Channel读取的event条数,适当调大这个参数可以提高Sink从Channel搬出event的性能。
4、简述下Flume的事务机制。
Flume的事务机制(类似数据库的事务机制):Flume使用两个独立的事务分别负责从Soucrce到Channel,以及从Channel到Sink的事件传递。比如spooling directory source 为文件的每一行创建一个事件,一旦事务中所有的事件全部传递到Channel且提交成功,那么Soucrce就将该文件标记为完成。同理,事务以类似的方式处理从Channel到Sink的传递过程,如果因为某种原因使得事件无法记录,那么事务将会回滚。且所有的事件都会保持到Channel中,等待重新传递。
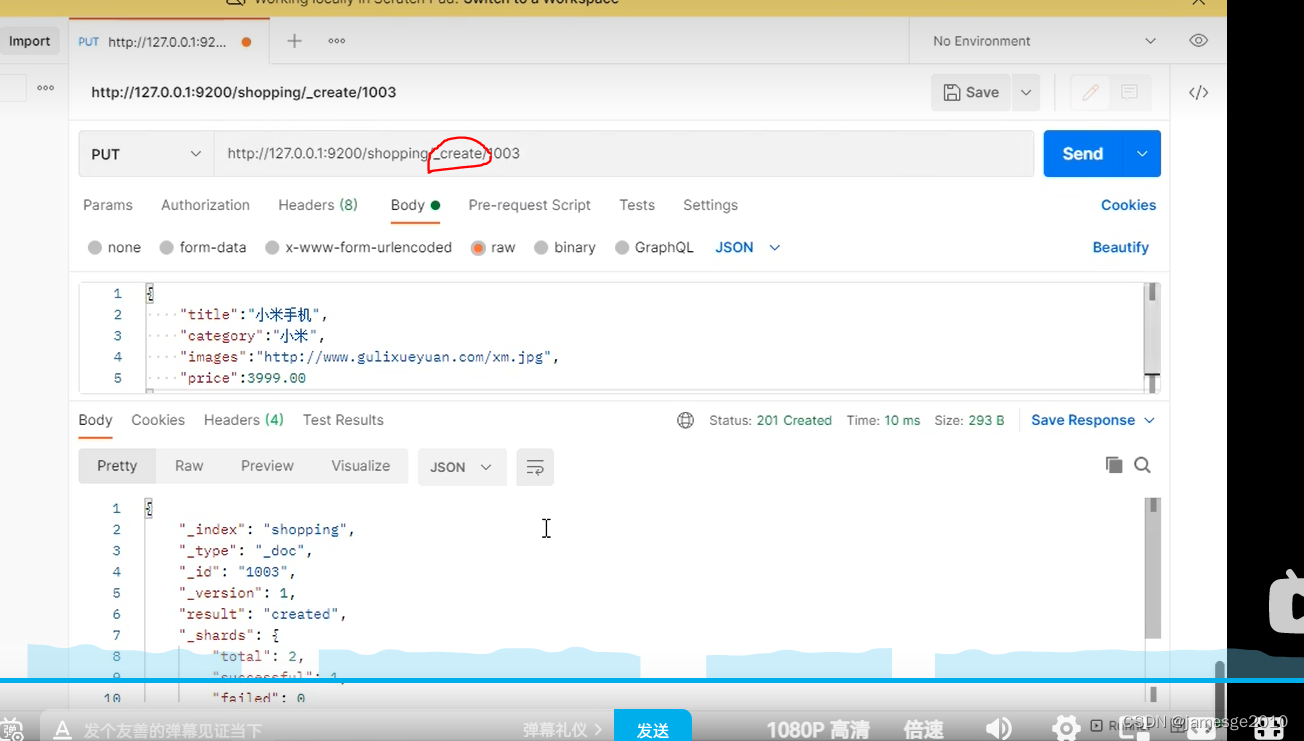
5、 Flume采集数据会丢失吗?
不会,Channel存储可以存储在File中,数据传输自身有事务。
6、简述下Flume使用场景。
线上数据一般主要是落地(存储到磁盘)或者通过socket传输给另外一个系统,这种情况下,你很难推动线上应用或服务去修改接口,实现直接向kafka里写数据,这时候你可能就需要flume这样的系统帮你去做传输。
7、简述下 Flume丢包问题。
单机upd的flume source的配置,100+M/s数据量,10w qps flume就开始大量丢包,因此很多公司在搭建系统时,抛弃了Flume,自己研发传输系统,但是往往会参考Flume的Source-Channel-Sink模式。
一些公司在Flume工作过程中,会对业务日志进行监控,例如Flume agent中有多少条日志,Flume到Kafka后有多少条日志等等,如果数据丢失保持在1%左右是没有问题的,当数据丢失达到5%左右时就必须采取相应措施。
8、 数据怎么采集到Kafka,用什么实现方式?
使用官方提供的flumeKafka插件,插件的实现方式是自定义了flume的sink,将数据从channle中取出,通过kafka的producer写入到kafka中,可以自定义分区等。
9、 Flume管道内存,flume宕机了数据丢失怎么解决?
(1)Flume的channel分为很多种,可以将数据写入到文件;
(2)防止非首个agent宕机的方法数可以做集群或者主备。
10、简述下Flume不采集Nginx日志,通过Logger4j采集日志的优缺点。
优点:Nginx的日志格式是固定的,但是缺少sessionid,通过logger4j采集的日志是带有sessionid的,而session可以通过redis共享,保证了集群日志中的同一session落到不同的tomcat时,sessionId还是一样的,而且logger4j的方式比较稳定,不会宕机。
缺点:不够灵活,logger4j的方式和项目结合过于紧密,而flume的方式比较灵活,拔插式比较好,不会影响项目性能。
11、Flume和Kafka采集日志区别,采集日志时中间停了,怎么记录之前的日志?
Flume采集日志是通过流的方式直接将日志收集到存储层,而kafka试讲日志缓存在kafka集群,待后期可以采集到存储层。
Flume采集中间停了,可以采用文件的方式记录之前的日志,而kafka是采用offset的方式记录之前的日志。
12、如何实现Flume数据传输断点续传?
TailDirSource支持断点续传。通过Json格式文件写入上次传递位置信息,断点续传从下个位置开始。