【NLP】自然语言处理_NLP入门——分词和词性标注
文章目录
- 【NLP】自然语言处理_NLP入门——分词和词性标注
- 1. 介绍
- 2. 概念和工具
- 2.1 分词
- 2.2 词性标注
- 2.3 NLTK
- 2.4 Jieba
- 2.5 LAC
- 3. 代码实现+举例
- 3.1 分词
- 3.1.1 使用nltk进行分词
- 3.1.2 使用jieba进行分词
- 3.1.3 使用LAC进行分词
- 3.2 词性标注
- 3.2.1 使用 nltk 实现词性标注
- 3.2.2 使用LAC实现词性标注
- 4. 可能的问题及解决
- 4.1 Resource punkt not found
- 5. 参考
1. 介绍
NLP 四大任务:
- 序列标注:分词,词性标注,命名实体识别
- 分类任务:文本分类,情感计算
- 句子关系判断:entailment(分类为蕴含或矛盾),相似度计算
- 生成式任务:机器翻译,问答系统,文本摘要
本文主要介绍NLP中最基础的任务分词和词性标注。难度属于入门级别。
2. 概念和工具
2.1 分词
分词是 NLP 的重要步骤。
- 分词就是将句子、段落、文章这种长文本,分解为以字词为单位的数据结构,方便后续的处理分析工作。
- 分词获得的就是由词语组成的 list,而不是原来的句子。
2.2 词性标注
词性标注是NLP四大基本任务中序列标注中的一项,其目的是对文本中的词汇实现词性的划分。标注的结果是一个由二元组组成的list,其中每一个二元组中标明了每个token对应的词性。
2.3 NLTK
NLTK全称:natural language toolkit,是一个基于python编写的自然语言处理工具箱。
安装非常简单,直接用conda或者pip安装即可。
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple nltk
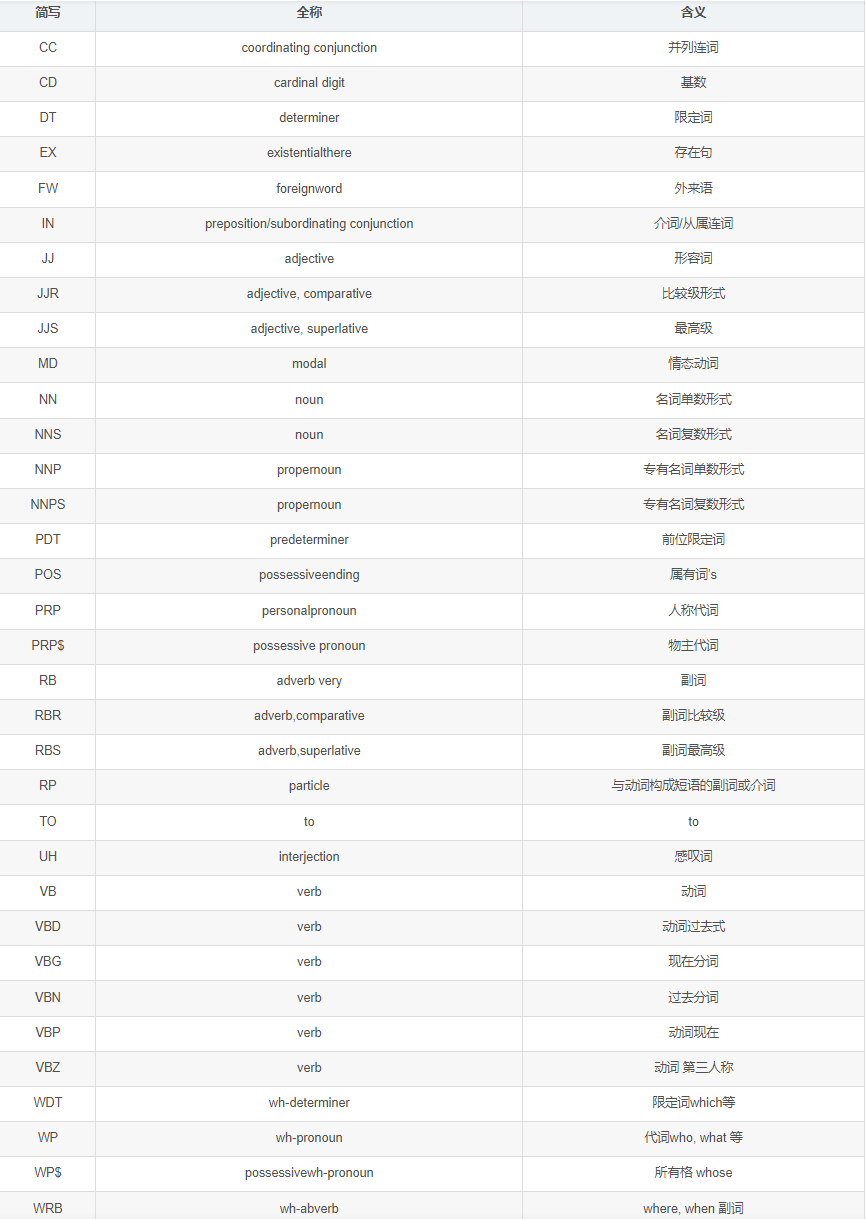
- 在nltk中,将词性归为以下类别:
2.4 Jieba
jieba是一个优秀的中文分词库,同样是基于python。
- 支持精确模式,全模式,搜索引擎模式等多种模式。
- Github:jieba
jieba安装可以在conda命令行通过如下指令完成:
conda install --channel https://conda.anaconda.org/conda-forge jieba
2.5 LAC
LAC全称Lexical Analysis of Chinese,是百度自然语言处理部研发的一款联合的词法分析工具,实现中文分词、词性标注、专名识别等功能。
- GitHub:LAC
LAC的安装也非常简单:
pip install lac -i https://mirror.baidu.com/pypi/simple
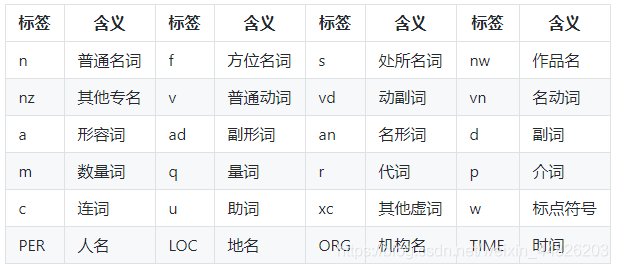
- 在词性标注任务中,LAC将词性归为以下类:
3. 代码实现+举例
3.1 分词
分词可以使用nltk实现,也可以使用其他工具如jieba实现。
- 使用nltk工具进行分词可以直接由文本到token划分,
- 也可以先进行sentence level的分词。
3.1.1 使用nltk进行分词
1)直接划分:
words = nltk.word_tokenize(text)
words
- 结果:
['life', 'is', 'short', '.', 'play', 'more', 'sport', '.']
2)1. 先进行句子划分:
import nltk
text = 'life is short. play more sport.'
sents = nltk.sent_tokenize(text)
sents
- 结果:
['life is short.', 'play more sport.']
2)2. 再进行分词
words = [nltk.word_tokenize(i) for i in sents]
words
- 结果:
[['life', 'is', 'short', '.'], ['play', 'more', 'sport', '.']]
3)但没有加载中文语料库的情况下,试图使用nltk进行中文分词就会出现问题:
words = nltk.word_tokenize('吃葡萄不吐葡萄皮,不吃葡萄倒吐葡萄皮')
words
- 结果可以看出,分词并没有成功:
['吃葡萄不吐葡萄皮,不吃葡萄倒吐葡萄皮']
接下来就介绍可以用于中文分词的工具。
3.1.2 使用jieba进行分词
jieba的分词功能可以由两个函数实现:
- cut函数返回的是一个generator,
- lcut函数直接返回一个list,
具体的使用方法:
1)cut
import jieba
import jieba.analyse
words = jieba.cut(text)
print('/'.join(words))
- 结果:
life/ /is/ /short/./ /play/ /more/ /sport/.
2)lcut
words = jieba.lcut(text)
print(words)
- 结果:
['life', ' ', 'is', ' ', 'short', '.', ' ', 'play', ' ', 'more', ' ', 'sport', '.']
注意:在这里可以看出:jieba分词与nltk之间的一个区别在于,jieba的分词结果中把空格也包含进去了,不限要空格的话就把它删掉就好了。
words = jieba.lcut(text)
while ' ' in words:
words.remove(' ')
print(words)
- 结果:
['life', 'is', 'short', '.', 'play', 'more', 'sport', '.']
3)jieba除了可以进行英文分词,也可以进行中文分词。
words = jieba.lcut('吃葡萄不吐葡萄皮,不吃葡萄倒吐葡萄皮')
words
- 结果:
['吃', '葡萄', '不吐', '葡萄', '皮', ',', '不吃', '葡萄', '倒', '吐', '葡萄', '皮']
3.1.3 使用LAC进行分词
使用LAC进行分词也很简单,下面是LAC官方的操作指引和样例结果。
from LAC import LAC
# 装载分词模型
lac = LAC(mode='seg')
# 单个样本输入,输入为Unicode编码的字符串
text = "LAC是个优秀的分词工具"
seg_result = lac.run(text)
# 批量样本输入, 输入为多个句子组成的list,平均速率会更快
texts = ["LAC是个优秀的分词工具", "百度是一家高科技公司"]
seg_result = lac.run(texts)
- 结果:
【单样本】:seg_result = [LAC, 是, 个, 优秀, 的, 分词, 工具] 【批量样本】:seg_result = [[LAC, 是, 个, 优秀, 的, 分词, 工具], [百度, 是, 一家, 高科技, 公司]]
3.2 词性标注
3.2.1 使用 nltk 实现词性标注
1)英文
pos_tags =nltk.pos_tag(words)
print(pos_tags)
- 结果:
[('life', 'NN'), ('is', 'VBZ'), ('short', 'JJ'), ('.', '.'), ('play', 'VB'), ('more', 'JJR'), ('sport', 'NN'), ('.', '.')]
可以看出:在英文分词方面nltk工具的效果还是很准确,很精细的。
2)中文
那么如果将分好的token输入给nltk,是否能够完成词性标注了?
words = jieba.lcut('吃葡萄不吐葡萄皮,不吃葡萄倒吐葡萄皮')
pos_tags =nltk.pos_tag(words)
pos_tags
-
结果:
[('吃', 'JJ'), ('葡萄', 'NNP'), ('不吐', 'NNP'), ('葡萄', 'NNP'), ('皮', 'NNP'), (',', 'NNP'), ('不吃', 'NNP'), ('葡萄', 'NNP'), ('倒', 'NNP'), ('吐', 'NNP'), ('葡萄', 'NNP'), ('皮', 'NN')] -
尽管标注完成了,但是通过判断发现它的标注并不准确,把“吃”标注成了形容词,“不吐”标注成了名词。
3.2.2 使用LAC实现词性标注
1)例子1
from LAC import LAC
# 装载LAC模型
lac = LAC(mode='lac')
# 单个样本输入,输入为Unicode编码的字符串
text = u"LAC是个优秀的分词工具"
lac_result = lac.run(text)
# 批量样本输入, 输入为多个句子组成的list,平均速率更快
texts = [u"LAC是个优秀的分词工具", u"百度是一家高科技公司"]
lac_result = lac.run(texts)
- 结果:
【单样本】: lac_result = ([百度, 是, 一家, 高科技, 公司], [ORG, v, m, n, n]) 【批量样本】:lac_result = [ ([百度, 是, 一家, 高科技, 公司], [ORG, v, m, n, n]), ([LAC, 是, 个, 优秀, 的, 分词, 工具], [nz, v, q, a, u, n, n]) ]
2)再来测试一下我们自己的例子
from LAC import LAC
# 装载LAC模型
lac = LAC(mode='lac')
# 单个样本输入,输入为Unicode编码的字符串
text = u"吃葡萄不吐葡萄皮,不吃葡萄倒吐葡萄皮"
lac_result = lac.run(text)
-
结果:
[['吃', '葡萄', '不', '吐', '葡萄皮', ',', '不', '吃', '葡萄', '倒', '吐', '葡萄皮'], ['v', 'nz', 'd', 'v', 'n', 'w', 'd', 'v', 'n', 'd', 'v', 'n']] -
结果同样十分准确,另外相比 jieba 分词的结果,把“葡萄皮”作为一个整体保留下来了。
4. 可能的问题及解决
4.1 Resource punkt not found
使用nltk分词时,报错LookupError Resource punkt not found,按照提示下载,nltk.download(‘punkt’),提示failed。
-
这是因为资源在外网,所以访问不了。解决方法,手动下载,并保存在指定位置.
-
下载链接在git上还有很多人的博客上都可以找到,为了防止失效,直接看这个网盘:
地址:https://pan.baidu.com/s/14KpU-BNuST6IwAFhWOosBA ;提取码:s8zt -
下载之后把缺少的包放在自动搜索的路径下,如各盘的根目录,在这里把它放在了anaconda的路径下。
- 在…\anaconda\share路径下创建文件夹nltk_data,以punkt为例,把下载的数据解压,把punkt中的english.pickle 放在…\anaconda\share\nltk_data\tokenizers\punkt\PY3\english.pickle,就可以了。
有一个细节需要注意一下,在解压之后的文件夹中并没有包含名为PY3的文件夹,如果不自己创建一个的话,仍然会报错。
类似的问题也采用类似的解决方法。
上面内容参考:https://blog.csdn.net/weixin_44826203/article/details/107484634
5. 参考
【1】https://blog.csdn.net/weixin_44826203/article/details/107484634
【2】https://blog.csdn.net/jasonjarvan/article/details/79955664
【3】https://blog.csdn.net/zzulp/article/details/77150129
【4】https://blog.csdn.net/qq_41595507/article/details/104123975
【5】https://github.com/baidu/lac