Kafka Java Consumer设计原理
目前市面上大多数计算机都采用多核CPU来提升系统的处理性能,但是如果在程序开发层面使用单线程的话,那么必定不能完全发挥出系统的真实性能,而kafka Consumer就是单线程的。而这个只是针对于消费消息这个层面来说。
内部包含的是用户主线程和心跳线程,用户主线程说白了就是消费consumer的main线程,而心跳线程是在Consumer API中,会自动和Broker进行心跳检测的线程,两个线程指责不同,进行拆分出来也是非常合理的。可以解耦真实的消息处理和心跳检测管理机制。
为什么Kafka不涉及成支持并发Consumer
从语言层面来说,并不是每个语言都可以很好的支持并发机制。并且从Kakfa推广层面来说,想要更好的打造上下游生态,那么必须要具备较好的移植性。
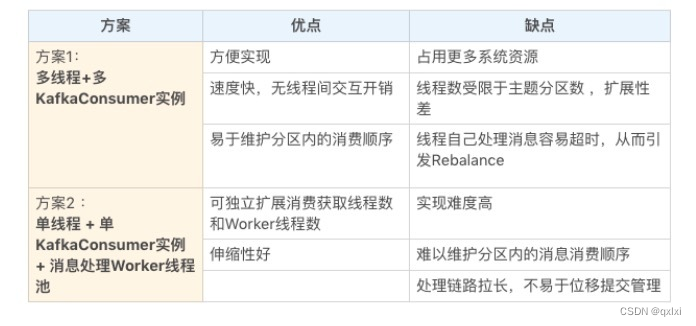
多线程方案
KakfaConsumer不是线程安全的。
1.消费者启动多个线程,每个线程维护专属的KakfaConsumer实例,进行消息的获取、消费流程。
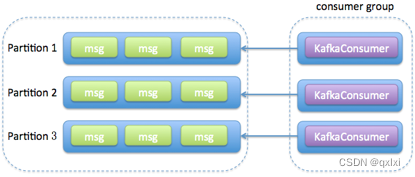
2.消费者使用单或者多线程获取消息,然后启动多个线程消费消息。获取消息可以是单个线程,或者是多个线程,但是每个线程都有专属的KafkaConsumer,将消息的获取和消息处理进行解耦合。
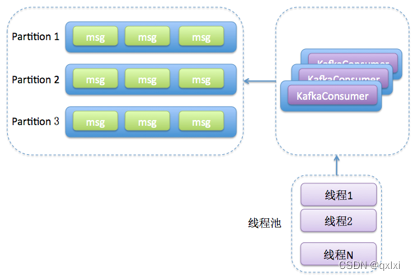
好了,我们来对比一个上述的两个方案。
如果说我们获取消息和处理消息分为1,2,3,4个过程。方案1会为创建多个线程,每个线程完整的执行完1,2,3,4过程,整个任务并不会被进行拆分,而方案2,用单线程处理1,2,然后多个线程处理3,4两个过程。
Code
方案1
public class KafkaConsumerRunner implements Runnable {
private final AtomicBoolean closed = new AtomicBoolean(false);
private final KafkaConsumer consumer;
public void run() {
try {
consumer.subscribe(Arrays.asList("topic"));
while (!closed.get()) {
ConsumerRecords records =
consumer.poll(Duration.ofMillis(10000));
// 执行消息处理逻辑
}
} catch (WakeupException e) {
// Ignore exception if closing
if (!closed.get()) throw e;
} finally {
consumer.close();
}
}
// Shutdown hook which can be called from a separate thread
public void shutdown() {
closed.set(true);
consumer.wakeup();
}
方案2
private final KafkaConsumer<String, String> consumer;
private ExecutorService executors;
...
private int workerNum = ...;
executors = new ThreadPoolExecutor(
workerNum, workerNum, 0L, TimeUnit.MILLISECONDS,
new ArrayBlockingQueue<>(1000),
new ThreadPoolExecutor.CallerRunsPolicy());
...
while (true) {
ConsumerRecords<String, String> records =
consumer.poll(Duration.ofSeconds(1));
for (final ConsumerRecord record : records) {
executors.submit(new Worker(record));
}
}
..