目录标题
- 1 Spark 简介与原理
- 1.1 Spark与Hadoop的区别
- 1.2 Spark的应用场景
- 1.3 Spark的作业运行流程
- 1.4 Spark 2.X与Spark 1.X的区别
1 Spark 简介与原理
Spark 是一个大规模数据处理的统一分析引擎。
具有迅速、通用、易用、支持多种资源管理器的特点。
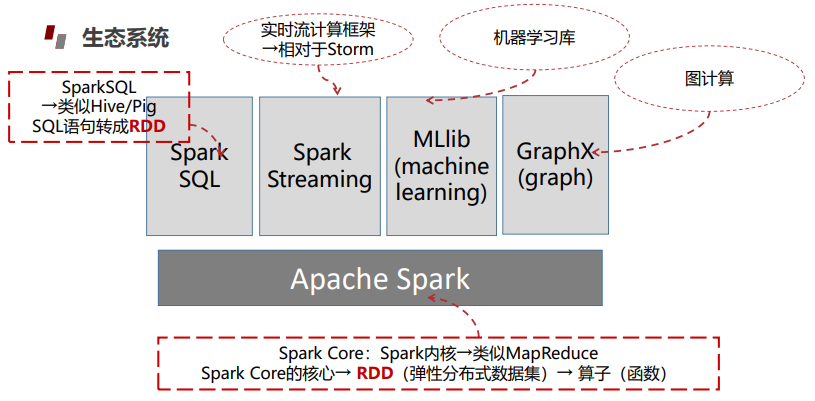
Spark生态系统:
Spark SQL是一种结构化的数据处理模块。它提供了一个称为Data Frame的编程抽象,也可以作为分布式SQL查询引擎。
Spark Streaming是一个Sprak API核心的一个存在可达到超高通量的扩展,并可处理实时数据流并容错。
数据可以从许多来源Kafka,Flume,Twitter,ZeroMQ, Kinesis,TCP sockets并且可以使用复杂的算法和高级功能表示处理Map,Reduce,Join和Window。 最后,处理后的数据可以被推送到文件系统,数据库。
MLlib(machine learning library)是Spark提供的可扩展的机器学习库。MLlib中已经包含了一些通用的学习算法和工具,如:分类、回归、聚类、协同过滤、降维以及底层的优化原语等算法和工具。MLlib提供的API主要分为以下两类:
•spark.mllib包中提供的主要API。
•spark.ml包中提供的构建机器学习工作流的高层次的API。
GraphX在Graphs和Graph-parallel并行计算中是一个新的部分,GraphX是Spark上的分布式图形处理架构,可用于图表计算。
1.1 Spark与Hadoop的区别
两者解决问题的方式不一样。
Hadoop是分布式数据设施;由普通计算机组成的Spark则是一个专门的工具,但它并不会进行分布式数据的存储。两者可合可分等。
Hadoop可用自身的MapReduce来代替Spark,Spark也可不依赖Hadoop,而选择其他基于云的数据系统平台。
1.2 Spark的应用场景
- 保险行业:通过使用Spark的机器学习功能来处理和分析所有索赔,优化索赔报销流程。
- 医疗保健:使用Spark Core,Streaming和SQL构建病人护理系统。
- 零售业:使用Spark分析销售点数据和优惠券使用情况。
- 互联网:使用Spark的ML功能来识别虚假的配置文件,并增强他们向客户展示的产品匹配。
- 银行业:使用机器学习模型来预测某些金融产品的零售银行客户的资料。
- 科学研究:通过时间,深度,地理分析地震事件来预测未来的事件。
- Twitter情绪分析:分析大量的推文,以确定特定组织和产品的积极,消极或中立的情绪。
- 地理空间分析:按时间和地理分析Uber旅行,以预测未来的需求和定价。
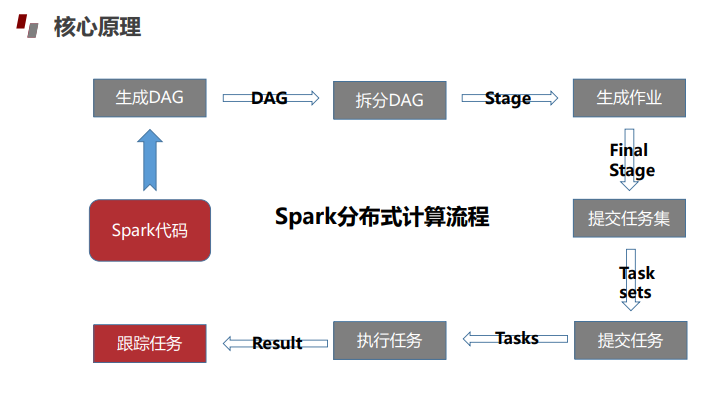
1.3 Spark的作业运行流程
- 启动SparkContext
- 注册申请资源
- 分配资源,之后启动Executor
- Executor向SparkContext注册
- 分配提交任务
- 注销释放资源

1.4 Spark 2.X与Spark 1.X的区别
- Spark2.x 引入了很多优秀特性,性能上有较大提升,API 更易用。
- 在“编程统一”方面非常惊艳,实现了离线计算和流计算 API 的统一,实现了 Spark sql 和 Hive Sql 操作 API 的统一。
- Spark 2.x 基本上是基于 Spark 1.x 进行了更多的功能和模块的扩展,及性能的提升。