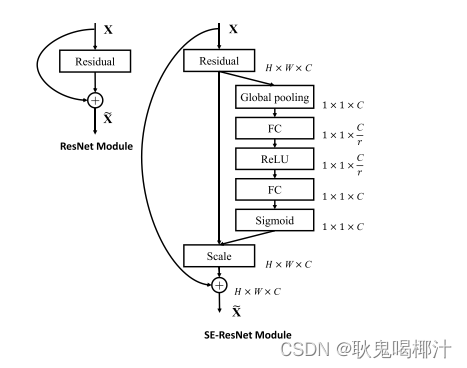
线性回归

广义的线性模型
不仅是自变量是一次方的是线性模型,参数是一次方的也是线性模型,比如:
总结:线性关系的一定是线性模型,线性模型的不一定是线性关系。
损失函数

优化损失
求解模型中的w,使得损失最小。
正规方程
理解:X为特征值矩阵,Y为目标值矩阵,直接求到最好的结果(矩阵求导得极值再得最值)
缺点:当特征过多过复杂时,求解速度太慢而且得不到结果
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression
import numpy as np
import pandas as pd
def linear1():
"""
正规方程的优化方法对波士顿房价进行预测
:return:
"""
# 1)获取数据
# 因为波士顿的数据因为道德问题在新版本中从scikit-learn中移除了,所以这里换种方式而不是直接load_boston()
data_url = "http://lib.stat.cmu.edu/datasets/boston"
raw_df = pd.read_csv(data_url, sep="\s+", skiprows=22, header=None)
data = np.hstack([raw_df.values[::2, :], raw_df.values[1::2, :2]])
target = raw_df.values[1::2, 2]
# 2)划分数据集
x_train, x_test, y_train, y_test = train_test_split(data, target, random_state=22)
# 3)标准化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# 4)预估器
estimator = LinearRegression()
estimator.fit(x_train, y_train)
# 5)得出模型
print("正规方程-权重系数为:\n", estimator.coef_)
print("正规方程-偏置为:\n", estimator.intercept_)
# 6)模型评估
y_predict = estimator.predict(x_test)
print("预测房价:\n", y_predict)
error = mean_squared_error(y_test, y_predict)
print("正规方程-均方误差为:\n", error)
return None
if __name__ == "__main__":
linear1()
梯度下降
理解:为学习率,需要手动指定(超参数),
旁边的整体表示方向沿着这个函数下降的方向找,最后就能找到山谷的最低点,然后更新w值。
使用:面对训练数据规模十分庞大的任务,能够找到较好的结果。
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import SGDRegressor
import numpy as np
import pandas as pd
def linear2():
"""
梯度下降的优化方法对波士顿房价进行预测
:return:
"""
# 1)获取数据
# 因为波士顿的数据因为道德问题在新版本中从scikit-learn中移除了,所以这里换种方式而不是直接load_boston()
data_url = "http://lib.stat.cmu.edu/datasets/boston"
raw_df = pd.read_csv(data_url, sep="\s+", skiprows=22, header=None)
data = np.hstack([raw_df.values[::2, :], raw_df.values[1::2, :2]])
target = raw_df.values[1::2, 2]
# 2)划分数据集
x_train, x_test, y_train, y_test = train_test_split(data, target, random_state=22)
# 3)标准化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# 4)预估器
# learning_ratew为学习率的算法,constant指的是每次下降的度都一样,eta0是学习率,max_iter是迭代次数
estimator = SGDRegressor(learning_rate="constant", eta0=0.01, max_iter=10000)
estimator.fit(x_train, y_train)
# 5)得出模型
print("梯度下降-权重系数为:\n", estimator.coef_)
print("梯度下降-偏置为:\n", estimator.intercept_)
# 6)模型评估
y_predict = estimator.predict(x_test)
print("预测房价:\n", y_predict)
error = mean_squared_error(y_test, y_predict)
print("梯度下降-均方误差为:\n", error)
return None
if __name__ == "__main__":
linear2()
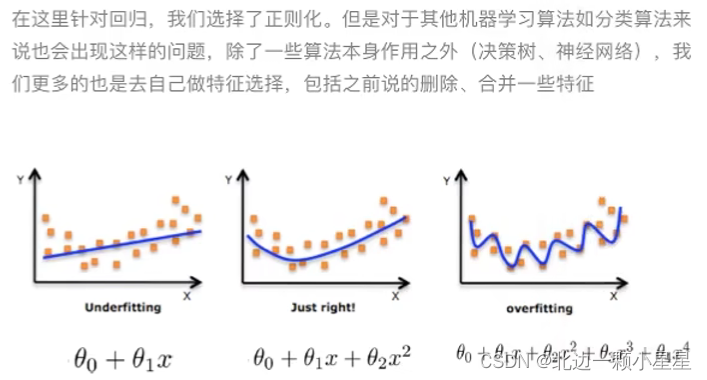
欠拟合
- 原因:学习的数据特征太少。比如没有掌握足够特征,认为骡子是马。
- 解决:增加数据的特征数量
过拟合
- 原因:原始特征过多,存在嘈杂特征。比如将白作为是马的一个特征, 认为黑马不是马。
- 解决:正则化


正则化
公式中,决定了正则化的程度,当
越大时,正则化的作用就越强,模型的复杂度就越小。
L2正则化(加了该正则化了回归叫Ridge回归即岭回归)
作用:可以使得其中一些很小,接近于0,消弱某个特征的影响,更适合处理相对平滑的数据(惩罚项的形式虽然让所有参数都受到惩罚,但是惩罚程度不同,较大的参数值会受到更严重的惩罚,因此它会让一些不重要的参数的值趋近于零,但是不会将这些参数完全消除,而是将它们变得非常小)。
优点:有效地减轻过拟合问题,同时保持参数的平滑性,使得模型的泛化能力更强。
注:是对于样本
的预测结果,m为样本数,n为特征数。
L1正则化(加了该正则化了回归叫LASSO回归)
作用:可以其中一些直接为0,删除这个特征的影响,更适合处理高维稀疏数据。
优点:实现特征选择,即通过让某些参数等于零,来消除对模型无用的特征,从而提高模型的精度和可解释性。
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import Ridge
import numpy as np
import pandas as pd
def linear3():
"""
岭回归方法对波士顿房价进行预测
:return:
"""
# 1)获取数据
# 因为波士顿的数据因为道德问题在新版本中从scikit-learn中移除了,所以这里换种方式而不是直接load_boston()
data_url = "http://lib.stat.cmu.edu/datasets/boston"
raw_df = pd.read_csv(data_url, sep="\s+", skiprows=22, header=None)
data = np.hstack([raw_df.values[::2, :], raw_df.values[1::2, :2]])
target = raw_df.values[1::2, 2]
# 2)划分数据集
x_train, x_test, y_train, y_test = train_test_split(data, target, random_state=22)
# 3)标准化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# 4)预估器
# 其实SGDRegressor默认也是岭回归,即参数penalty="l2"
estimator = Ridge(alpha=0.5, max_iter=10000)
estimator.fit(x_train, y_train)
# 5)得出模型
print("岭回归-权重系数为:\n", estimator.coef_)
print("岭回归-偏置为:\n", estimator.intercept_)
# 6)模型评估
y_predict = estimator.predict(x_test)
print("预测房价:\n", y_predict)
error = mean_squared_error(y_test, y_predict)
print("岭回归-均方误差为:\n", error)
return None
if __name__ == "__main__":
linear3()
逻辑回归
逻辑回归其实是在线性回归的基础上增添,让它可用于分类,用以解决二分类问题。
输入
线性回归的输出就是逻辑回归的输入,即把h(w)代入到sigmoid函数的自变量中。
sigmoid函数
代入后即
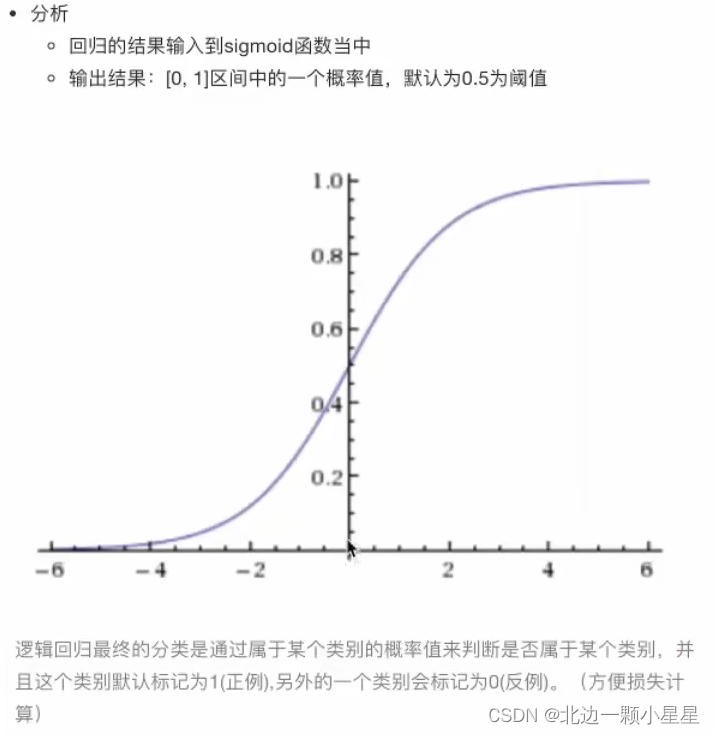
损失及其优化
损失
逻辑回归的损失,称之为对数似然损失。
综合完整损失函数(与上面的是等价的式子)
精确率与召回率
混淆矩阵

TP:True Positive FN:False Negative
FP:False Positive TN:True Negative
精确率(Precision)与召回率(Recall)



ROC曲线与AUC指标
TPR与FTR
- TPR=TP/(TP+FN)——所有真实类别为1的样本中,预测类别为1的比例(即召回率)
- FPR=FP/(FP+TN)—— 所有真实类别为0的样本中,预测类别为1的比例
ROC曲线
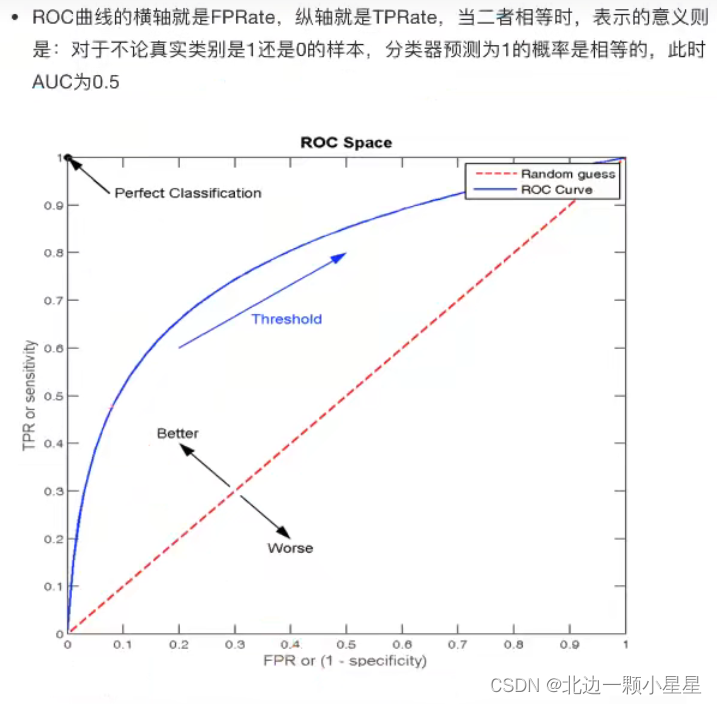
AUC指标

- AUC只能用来评价二分类
- AUC非常适合评价样本不平衡中的分类器性能
from sklearn.metrics import classification_report, roc_auc_score
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
import numpy as np
import pandas as pd
def cancer_demo():
"""
逻辑回归对癌症进行分类
:return:
"""
# 1)读取数据
path = "https://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/breast-cancer-wisconsin.data"
column_name = ['Sample code number', 'Clump Thickness', 'Uniformity of Cell Size', 'Uniformity of Cell Shape',
'Marginal Adhesion', 'Single Epithelial Cell Size', 'Bare Nuclei', 'Bland Chromatin',
'Normal Nucleoli', 'Mitoses', 'Class']
data = pd.read_csv(path, names=column_name)
# 2)缺失值处理
# 替换-》np.nan
data = data.replace(to_replace="?", value=np.nan)
# 删除缺失样本
data.dropna(inplace=True)
# 3)划分数据集
# 筛选特征值和目标值
x = data.iloc[:, 1:-1]
y = data["Class"]
x_train, x_test, y_train, y_test = train_test_split(x, y)
# 4)标准化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# 5)预估器流程
estimator = LogisticRegression()
estimator.fit(x_train, y_train)
# 6)模型评估
# 方法1:直接比对真实值和预测值
y_predict = estimator.predict(x_test)
print("y_predict:\n", y_predict)
print("直接比对真实值和预测值:\n", y_test == y_predict)
# 方法2:计算准确率
score = estimator.score(x_test, y_test)
print("准确率为:\n", score)
# 查看精确率、召回率、F1-score
report = classification_report(y_test, y_predict, labels=[2, 4], target_names=["良性", "恶性"])
print(report)
# y_true:每个样本的真实类别,必须为0(反例),1(正例)标记
# 将y_test 转换成 0 1
y_true = np.where(y_test > 3, 1, 0)
# roc曲线面积即auc值
score = roc_auc_score(y_true, y_predict)
print("roc_auc_score:",score)
return None
if __name__ == "__main__":
cancer_demo()
无监督学习—K-Means算法
无监督是因为没有目标值,聚类一般在分类之前做。
K-Means聚类步骤
- 随机选取K个特征空间的点作为初始的聚类中心(中心点可以不是原本就存在的点)
- 分别计算其他每个点到K个中心的距离,未知的点选择最近的一个聚类中心点作为标记类别
- K个聚类都完成之后,重新计算出每个聚类的新中心点(算坐标平均值得点)
- 如果计算出的新中心点与原中心点一样,那么结束,否则重新进行第二步(迭代)
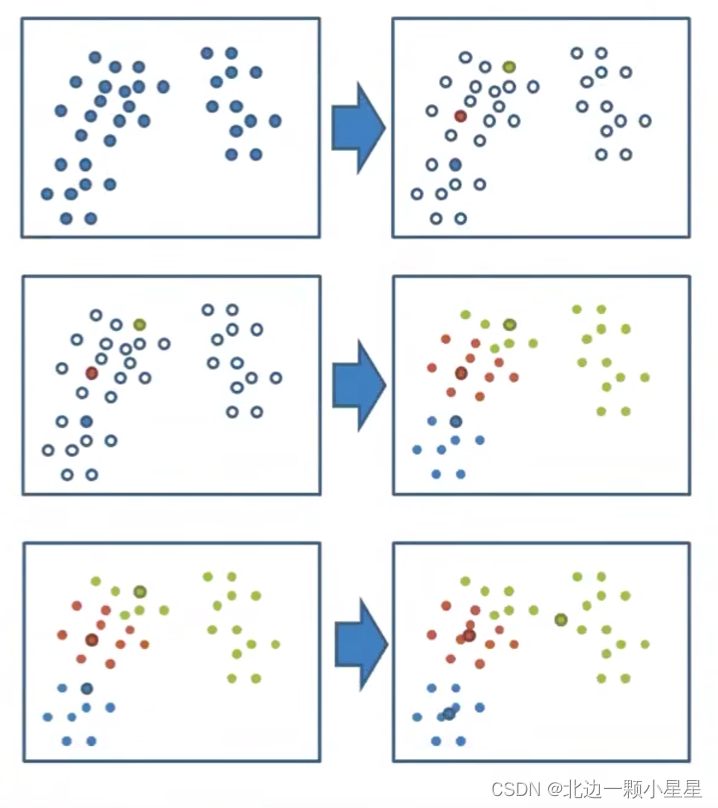 K-Means性能评估指标
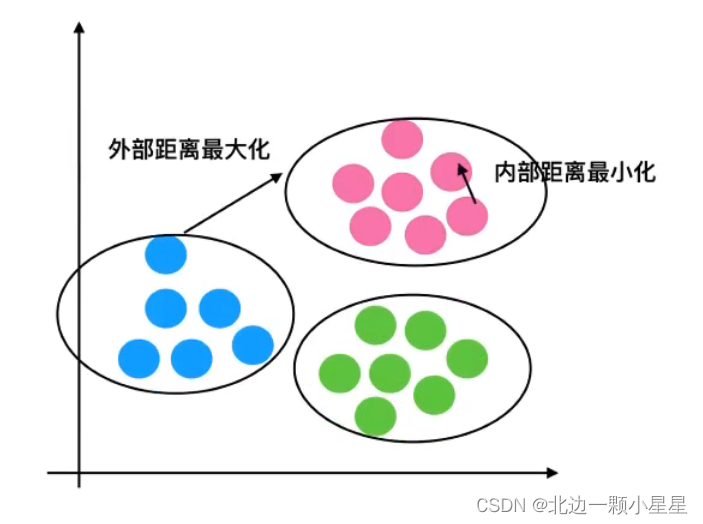
K-Means性能评估指标
轮廓系数
注:对于每个点i为已聚类数据中的样本,为i到其他簇的所有样本的距离最小值,
为i到本身簇的距离平均值,最终计算出所有的样本点的轮廓系数平均值。
如果此时
;若
,则
,故
。
轮廓系数越趋于1效果越好,即“高内聚,低耦合”。
from sklearn.cluster import KMeans
from sklearn.decomposition import PCA
from sklearn.metrics import silhouette_score
import pandas as pd
def kmeans_demo():
"""
用K-Means将用户根据偏好分类
:return:
"""
# 1)获取数据
order_products = pd.read_csv("./instacart/order_products__prior.csv")
products = pd.read_csv("./instacart/products.csv")
orders = pd.read_csv("./instacart/orders.csv")
aisles = pd.read_csv("./instacart/aisles.csv")
# 2)合并表
# order_products__prior.csv:订单与商品信息
# 字段:order_id, product_id, add_to_cart_order, reordered
# products.csv:商品信息
# 字段:product_id, product_name, aisle_id, department_id
# orders.csv:用户的订单信息
# 字段:order_id,user_id,eval_set,order_number,….
# aisles.csv:商品所属具体物品类别
# 字段: aisle_id, aisle
# 合并aisles和products aisle和product_id
tab1 = pd.merge(aisles, products, on=["aisle_id", "aisle_id"])
tab2 = pd.merge(tab1, order_products, on=["product_id", "product_id"])
tab3 = pd.merge(tab2, orders, on=["order_id", "order_id"])
# 3)找到user_id和aisle之间的关系
table = pd.crosstab(tab3["user_id"], tab3["aisle"])
data = table[:10000]
# 4)PCA降维
# 1)实例化一个转换器类
transfer = PCA(n_components=0.95)
# 2)调用fit_transform
data_new = transfer.fit_transform(data)
# 5)K-Means预估器流程
estimator = KMeans(n_clusters=3, n_init=10) # n_clusters聚类数,n_init迭代次数,默认10次
estimator.fit(data_new)
y_predict = estimator.predict(data_new)
print(y_predict[:300]) # 查看前300个预测结果
# 6)模型评估-轮廓系数
sc = silhouette_score(data_new, y_predict)
print("轮廓系数:", sc)
return None
if __name__ == "__main__":
kmeans_demo()
缺点:容易收敛到局部最优解。
模型的保存与加载
from sklearn.externals import joblib
# 保存模型
joblib.dump(estimator, "my_model.pkl")
# 加载模型
estimator = joblib.load("my_model.pkl")