此文章为深度学习在计算机视觉领域的图片分类经典论文SeNet(Squeeze-and-Excitation Networks)论文总结。
此系列文章是非常适合深度学习领域的小白观看的图像分类经典论文。系列文章如下:
AlexNet:AlexNet论文解读/总结_alexnet论文原文_耿鬼喝椰汁的博客-CSDN博客
VGGNet:VGGNet论文解读/总结_耿鬼喝椰汁的博客-CSDN博客
GoogLeNet:GoogLeNet(Inceptionv1) 论文解读/总结_googlenet v1_耿鬼喝椰汁的博客-CSDN博客
ResNet:ResNet论文解读/总结_耿鬼喝椰汁的博客-CSDN博客
SeNet:SeNet论文解读/总结_耿鬼喝椰汁的博客-CSDN博客
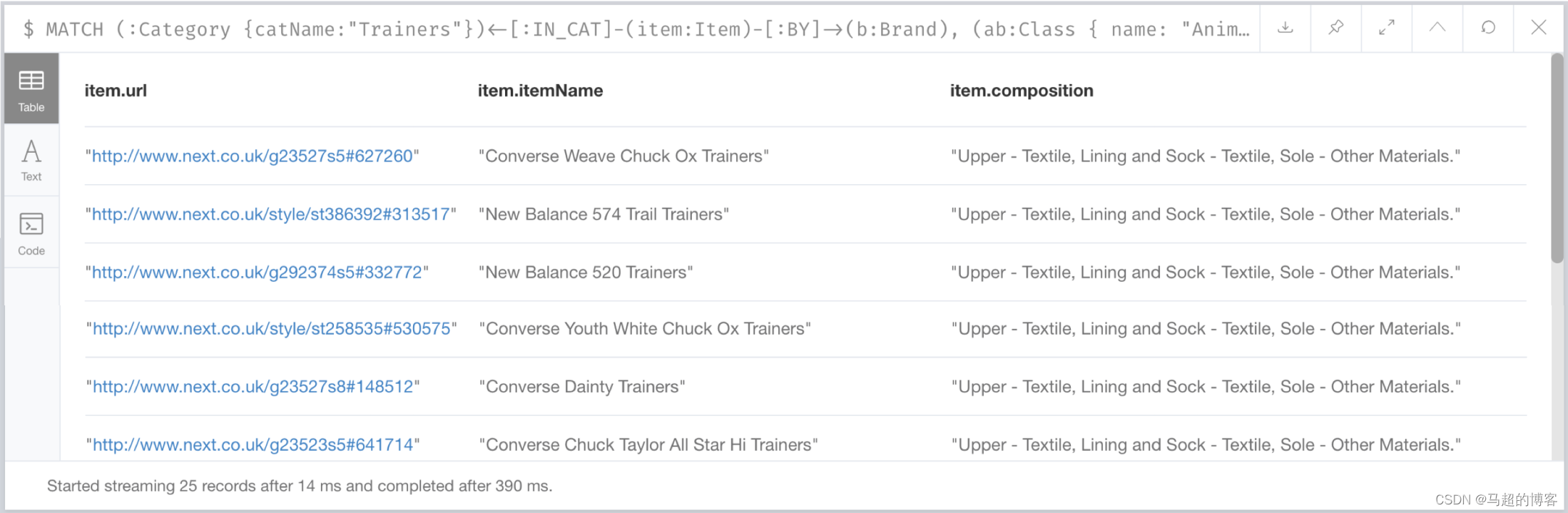
论文背景
在深度学习领域,已经有很多成果通过在空间维度上对网络的性能进行了提升。但是,SENet反其道而行之,通过通道关系进行建模来提升网络的性能。和Excitation是两个非常关键的操作,所以SENet以此来命名。SENet的动机是希望显式地建模特征通道之间的相互依赖关系,具体来说,就是通过学习的方式来自动获取每个通道的重要程度,然后依照这个重要程度去提升有用的特征并抑制对当前任务用处不大的特征。
论文成果
成果:最后一届ImageNet 2017竞赛 Image Classifcation任务的冠军.作者采用SENet block和ResNeXt结合在ILSVRC 2017的分类项目中拿到第一,在ImageNet数据集上将top-5 error降低到2.251%,原先的最好成绩是2.991%。
我们可以想象在进行图像识别的时候,卷积计算后生成了很多特征图,不同的滤波器会 得到不同的特征图,不同的特征图代表从图像中提取的不同的特征。我们得到了这么多的特征图,按理来说某些特征图的应该更重要,某些特征图应该没这么重要,并不是所有特征图 都一样的重要。所以 SENet 的核心思想就是给特征图增加注意力和门控机制,增强重要的特征图的信息,减弱不重要的特征图的信息。
SE结构块
给定一个输入 x,其特征通道数为C1,通过一系列卷积等一般变换后得到一个特征通道数为 C2 的特征。与传统的CNN不一样的是,接下来通过三个操作来重标定前面得到的特征。
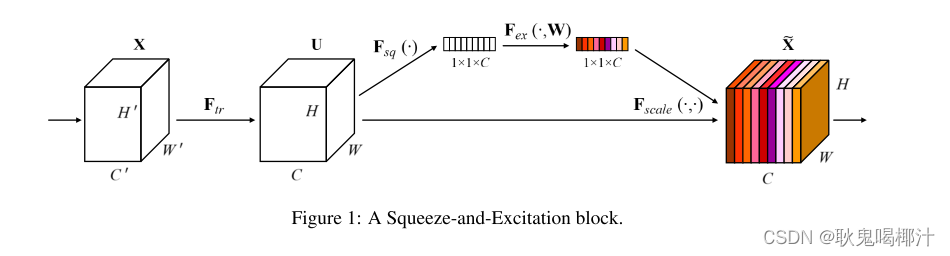
(1)Squeeze(压缩):顺着空间维度来进行特征压缩,将每个二维的特征通道变成一个实数,这个实数某种程度上具有全局的感受野,并且输出的维度和输入的特征通道数相匹配。它表征着在特征通道上响应的全局分布,而且使得靠近输入的层也可以获得全局的感受野,这一点在很多任务中都是非常有用。
(2)Excitation(激发):使用全连接层,对Sequeeze之后的结果做一个非线性变换。目的为为了完全捕获通道之间的相关性。它是一个类似于循环神经网络中门的机制。通过参数来为每个特征通道生成权重,其中参数被学习用来显式地建模特征通道间的相关性。
(3)Reweight(缩放):将Excitation的输出的权重看做是进过特征选择后的每个特征通道的重要性,然后通过乘法逐通道加权到先前的特征上,完成在通道维度上的对原始特征的重标定。
具体操作
1.对输入进来的特征层进行全局平均池化。
2.然后进行两次全连接(这两个全连接可用1*1卷积代替),第一次全连接神经元个数较少,第二次全连接神经元个数和输入特征层个数相同。
3.在完成两次全连接之后,再取一次sigmoid讲值固定到0-1之间,此时我们获得了输入特征层每一个通道的权值(0-1之间)。
4.在获得这个权值之后,将这个权值与原输入特征层相乘即可。
SE网络可以通过简单地堆叠SE构建块的集合来生成。
SE块在网络不同部分的作用有所不同:SE块也可以用作架构中任意深度的原始块的直接替换。
1.在前面的层中,它学习以类不可知的方式激发信息特征,增强共享的较低层表示的质量。
2.在后面的层中,SE块越来越专业化,并以高度类特定的方式响应不同的输入。
因此,SE块进行特征重新校准的好处可以通过整个网络进行累积。
SE结构块结合先进架构的灵活应用
SE模块的灵活性在于它可以直接应用现有的网络结构中。这里以Inception和ResNet为例。对于Inception网络,没有残差结构,这里对整个Inception模块应用SE模块。对于ResNet,SE模块嵌入到残差结构中的残差学习分支中。
1.SE-Inception模块:
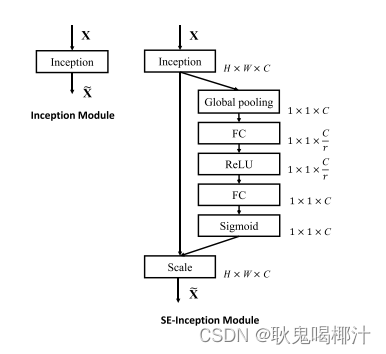
图中的 Global pooling 表示全局池化;W 表示图片宽度;H 表示图片高度;C 表示图片 通道数;FC表示全连接层;r 表示缩减率,意思是通道数在第一个全连接层缩减多少,总之 就是一个超参数,不用细究,一般取值为 16。
2.SE-Resnet模块:
在这里,SE块变换Ftr被认为是残差模块的非恒等分支。压缩和激励都在恒等分支相加之前起作用。
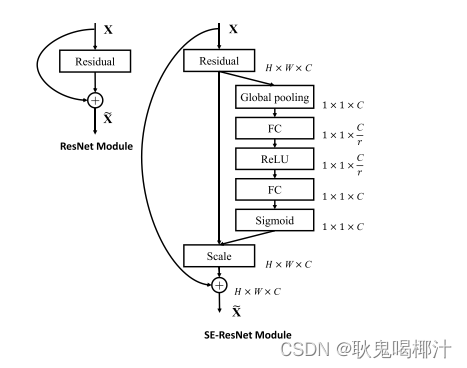
图中的 Global pooling 表示全局池化;W 表示图片宽度;H 表示图片高度;C 表示图片 通道数;FC表示全连接层;r 表示缩减率,意思是通道数在第一个全连接层缩减多少,总之 就是一个超参数,不用细究,一般取值为 16。
进行一系列实验及总结
经历一系列实验及数据表明,SE模块在参数量上的增加带来的计算量增长微乎其微,但是性能却有所提升,当然这也取决于实际应用,如果因为SE模块导致参数量增加的掠夺,可以针对性的在适当的位置削减SE模块的数量,而精度几乎不受影响。
以ResNet-50和SE-ResNet-50对比举例来说,SE-ResNet-50相对于ResNet-50有着10%模型参数的增长。额外的模型参数都存在于Bottleneck设计的两个Fully Connected中,由于ResNet结构中最后一个st age的特征通道数目为2048,导致模型参数有着较大的增长,实验发现移除掉最后一个stage中3个build block上的SE设定,可以将10%参数量的增长减少到2%。此时模型的精度几乎无损失。
论文总结
本文提出了SE模块,这是一种新颖的结构单元,旨在通过使网络能够执行动态通道特征重新校准来提高网络的表示能力。大量的实验证明了SENets的有效性,在多个数据集上达到了最先进的性能。此外,它们提供了对先前架构在建模通道式特征依赖性方面的局限性的一些见解,我们希望这可能证明对需要强区分特征的其他任务有用。最后,由SE块导出的特征重要性可能有助于相关领域,如用于压缩的网络修剪。
此系列文章是非常适合深度学习领域的小白观看的图像分类经典论文。系列文章如下:
AlexNet:AlexNet论文解读/总结_alexnet论文原文_耿鬼喝椰汁的博客-CSDN博客
VGGNet:VGGNet论文解读/总结_耿鬼喝椰汁的博客-CSDN博客
GoogLeNet:GoogLeNet(Inceptionv1) 论文解读/总结_googlenet v1_耿鬼喝椰汁的博客-CSDN博客
ResNet:ResNet论文解读/总结_耿鬼喝椰汁的博客-CSDN博客
SeNet:SeNet论文解读/总结_耿鬼喝椰汁的博客-CSDN博客
这篇论文的学习和总结到这里就结束啦,如果有什么问题可以在评论区留言呀~
如果帮助到大家,可以一键三连支持下~