可分离卷积+ViT实现轻量级transformer结构
- 1. 论文主要工作
- 1.1 摘要内容
- 1.2 写作动机(Motivations)
- 1.2.1 Transformer Patch结构的巨大计算量问题
- 1.2.2 Swin:针对计算量的优化
- 1.2.3 Twins:针对边缘端部署优化
- 1.2.4 Cswin:存在吞吐量问题
- 1.2.5 提出 SepViT结构
- 2. 轻量级模型:从AlexNet的分组卷积 到 MobileNet系列
- 3. Pytorch的demo测试
- 3.1 模型关键结构
- 3.2 模型的变体结构
- 3.2 程序-mnist数据集测试
- 3.3 测试结果
- 参考文献资料
前言: 这篇论文第一作者是Bytedance实习生Li Wei,电子科技大学一名学生。论文主体是轻量级ViT。本博客简单解读了该论文的主要工作,并基于Python+Pytorch,做了一个结构的简单测试试验分享。
1. 论文主要工作
1.1 摘要内容
Vision Transformers在一系列的视觉任务中取得了巨大的成功。然而,它们通常都需要大量的计算来实现高性能,这在部署在资源有限的设备上这是一个负担。
为了解决这些问题,作者受深度可分离卷积启发设计了深度可分离Vision Transformers,缩写为SepViT。SepViT通过一个深度可分离Self-Attention促进Window内部和Window之间的信息交互。并群欣设计了新的Window Token Embedding和分组Self-Attention方法,分别对计算成本可忽略的Window之间的注意力关系进行建模,并捕获多个Window的长期视觉依赖关系。
在各种基准测试任务上进行的大量实验表明,SepViT可以在准确性和延迟之间的权衡方面达到最先进的结果。其中,SepViT在ImageNet-1K分类上的准确率达到了84.0%,而延迟率降低了40%。在下游视觉任务中,SepViT在ADE20K语义分割任务达到50.4%的mIoU,基于RetinaNet的COCO目标检测任务达到47.5AP,基于Mask R-CNCN的48.7 box AP检测和分割任务实现43.9 mask AP。
1.2 写作动机(Motivations)
近年来,许多计算机视觉(CV)研究人员致力于设计面向CV的Vision Transformers,以超过卷积神经网络(CNNs)的性能。Vision Transformers具有较高的远距离依赖建模能力,在图像分类、语义分割、目标检测等多种视觉任务中取得了显著的效果。然而,强大的性能通常是以计算复杂度为代价的。
1.2.1 Transformer Patch结构的巨大计算量问题
最初,ViT首先将Transformer引入图像识别任务中。它将整个图像分割为几个Patches,并将每个Patch作为一个Token提供给Transformer。然而,由于计算效率低下的Self-Attention,基于Patch的Transformer很难部署。
1.2.2 Swin:针对计算量的优化
为了解决这个问题,Swin提出了基于Window的Self-Attention,限制了非重叠子Window中Self-Attention的计算。显然,基于Window的Self-Attention在很大程度上降低了复杂性,但构建Window间连接的Shift操作符给ONNX或TensorRT的部署带来了困难。
1.2.3 Twins:针对边缘端部署优化
Twins利用基于Window的Self-Attention和PVT的Spatial Reduction Attention,提出了空间可分离Self-Attention。尽管Twins是部署友好型的,并且具有出色的性能,但它的计算复杂度几乎没有降低。
1.2.4 Cswin:存在吞吐量问题
CSWin通过Cross-Shaped Window Self-Attention得到了最先进的性能,但吞吐量较低。
尽管在这些著名的Transformer中取得了不同程度的进展,但它最近的大部分成功都伴随着巨大的资源需求。
1.2.5 提出 SepViT结构
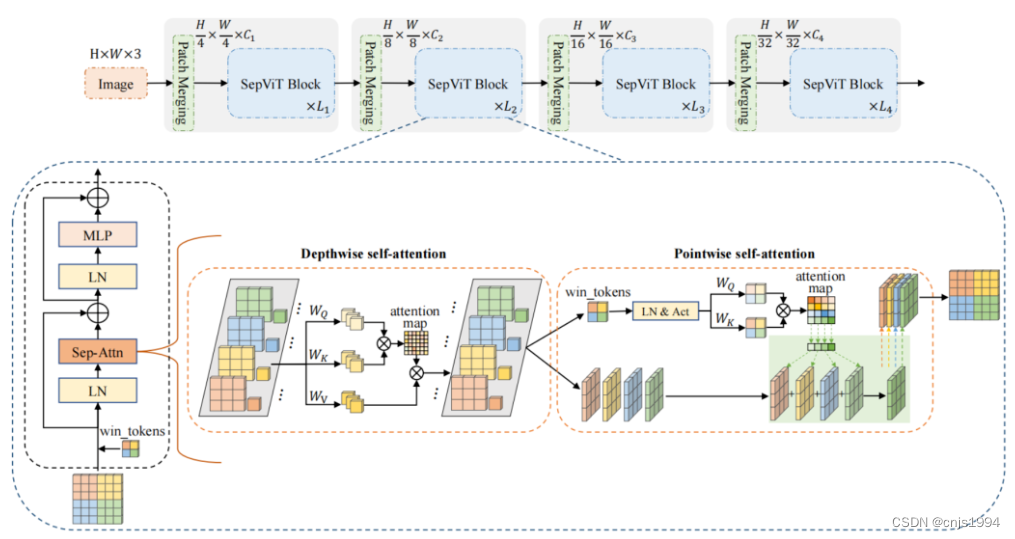
为了克服上述问题本文提出了一种高效的Transformer Backbone,称为可分离Vision Transformers (SepViT),它可以按顺序捕获局部和全局依赖。SepViT的一个关键设计元素是深度可分离的Self-Attention模块,如图2所示。
受MobileNet中深度可分卷积的启发重新设计了Self-Attention模块,并提出了深度可分离Self-Attention,它由Depthwise Self-Attention和Pointwise Self-Attention组成,分别对应于MobileNet中的Depthwise和PointWise卷积。Depthwise Self-Attention用于捕获每个Window内的局部特征,Pointwise Self-Attention用于构建Window间的连接,提高表达能力。
2. 轻量级模型:从AlexNet的分组卷积 到 MobileNet系列
2.2 轻量化模型
针对移动端视觉任务,提出了许多轻量级和移动端友好的卷积方案。其中,分组卷积是由AlexNet首次提出的分组卷积,它对特征映射进行分组并进行分布式训练。
那么,移动端友好卷积的代表性工作必须是具有深度可分离卷积的MobileNet。深度可分离卷积包括用于空间信息通信的Depthwise卷积和用于跨通道信息交换的Pointwise卷积。随着时间的推移,许多基于上述工作的变体被开发出来。从v1堆叠可分离卷积结构到v2引入linear bottleneck与inverted residual,再到v3的结构搜索,轻量级模型似乎已经发展到了尽头。
而这篇论文的工作中,作者将深度可分离卷积的思想应用到Transformer中【1】,旨在在不牺牲性能的情况下降低Transformer的计算复杂度。
3. Pytorch的demo测试
3.1 模型关键结构
如下图所示,SepViT遵循了广泛使用的层次体系结构和基于Window的Self-Attention。
此外,SepViT还采用了条件位置编码(CPE)。对于每个阶段,都有一个重叠的Patch合并层用于特征图降采样,然后是一系列的SepViT Block。空间分辨率将以stride=4步或stride=2步逐步进行下采样,最终达到32倍下采样,通道尺寸也逐步增加一倍。
值得注意的是,局部上下文和全局信息都可以在单个SepViT Block中捕获,而其他工作应该使用2个连续的Block来完成这种局部-全局建模。
在SepViT块中,每个Window内的局部信息通信是通过DepthWise Self-Attention(DWA)实现的,Window间的全局信息交换是通过PointWise Self-Attention(PWA)进行。
3.2 模型的变体结构
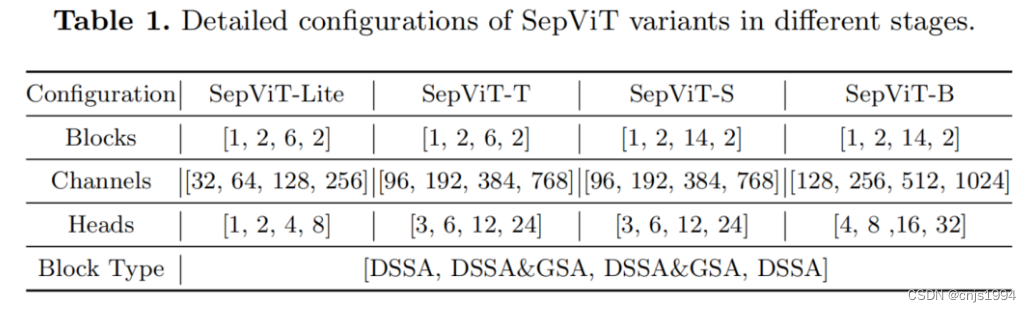
此外,还设计了SepViT-Lite变体与一个非常轻的模型尺寸。SepViT变体的具体配置如表1所示,由于SepViT的效率更高,因此在某些阶段,SepViT的Embedding块深度比竞争对手要小。
DSSA和GSA分别表示具有Depthwise Separable Self-Attention和Grouped Self-Attention Block。此外,每个MLP层的扩展比设置为4,在所有SepViT变体中,DSSA和GSA的Window Sizes分别为7×7和14×14。
PS: 但是,Github代码这个库的所有者提到了一个问题:它只将SepViT的版本与这个特定的自我注意层结合起来,因为他觉得分组的注意层既不显著也不新颖,作者也不清楚他们是如何处理组自我注意层的窗口标记的。此外,似乎仅凭DSSA层,他们就能够击败Swin。
3.2 程序-mnist数据集测试
包安装
pip install vit-pytorch -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
demo程序测试
from torch.optim.lr_scheduler import StepLR
from vit_pytorch.sep_vit import SepViT
import torch
from torch import nn
from torch import optim
from torchvision import datasets
from torchvision.transforms import ToTensor
from torch.utils.data import DataLoader
import torchvision
'''
1. sep_vit.py模型中定义的是3通道数据张量数据输入,现在修改为了单通道的数据输入
2. window_size参数修改为1
'''
##########################################################################################################
# Training Hyper-parameters settings
batch_size = 49
epochs = 20
lr = 3e-5
gamma = 0.7
seed = 42
# device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# inputs, labels = inputs.to(device), labels.to(device)
###########################################################################################################
# 模型定义
model = SepViT(
num_classes=10,
dim=32, # dimensions of first stage, which doubles every stage (32, 64, 128, 256) for SepViT-Lite
dim_head=32, # attention head dimension
heads=(1, 2, 4, 8), # number of heads per stage
depth=(1, 2, 6, 2), # number of transformer blocks per stage
window_size=1, # window size of DSS Attention block (报错:height 64 and width 64 must be divisible by window size 7)
dropout=0.1 # dropout
)
# loss function
loss_func = nn.CrossEntropyLoss()
# optimizer
optimizer = optim.Adam(model.parameters(), lr=lr)
# scheduler
scheduler = StepLR(optimizer, step_size=1, gamma=gamma)
######################################################################################################################
# 其余超参数设置
# loss function
criterion = nn.CrossEntropyLoss()
# optimizer
optimizer = optim.Adam(model.parameters(), lr=lr)
# scheduler
scheduler = StepLR(optimizer, step_size=1, gamma=gamma)
# model.to(device)
model.eval()
############################################################################################################
# Mnist数据加载
train_data = datasets.MNIST(
root = 'data',
train = True,
transform = torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(
(0.1307,), (0.3081,))
]),
download = True,
)
test_data = datasets.MNIST(
root = 'data',
train = False,
transform = torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(
(0.1307,), (0.3081,))
]))
loaders = {
'train': torch.utils.data.DataLoader(train_data,
batch_size=100,
shuffle=True,
num_workers=1),
'test': torch.utils.data.DataLoader(test_data,
batch_size=100,
shuffle=True,
num_workers=1),
}
#############################################################################################################
# 模型训练
from torch.autograd import Variable
num_epochs = 10
def train(num_epochs, cnn, loaders):
cnn.train()
# Train the model
total_step = len(loaders['train'])
for epoch in range(num_epochs):
for i, (images, labels) in enumerate(loaders['train']):
# gives batch data, normalize x when iterate train_loader
b_x = Variable(images) # batch x
b_y = Variable(labels) # batch y
output = model(b_x)
loss = loss_func(output, b_y)
# clear gradients for this training step
optimizer.zero_grad()
# backpropagation, compute gradients
loss.backward()
# apply gradients
optimizer.step()
if (i + 1) % 100 == 0:
print('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}'
.format(epoch + 1, num_epochs, i + 1, total_step, loss.item()))
pass
pass
pass
if __name__ == '__main__':
train(num_epochs, model, loaders)
3.3 测试结果
Epoch [1/10], Step [100/1875], Loss: 1.1673
Epoch [1/10], Step [200/1875], Loss: 0.4501
Epoch [1/10], Step [300/1875], Loss: 0.6198
Epoch [1/10], Step [400/1875], Loss: 0.3469
Epoch [1/10], Step [500/1875], Loss: 0.3964
Epoch [1/10], Step [600/1875], Loss: 0.4239
Epoch [1/10], Step [700/1875], Loss: 0.4740
Epoch [1/10], Step [800/1875], Loss: 0.3085
Epoch [1/10], Step [900/1875], Loss: 0.6178
Epoch [1/10], Step [1000/1875], Loss: 0.6015
Epoch [1/10], Step [1100/1875], Loss: 0.1161
Epoch [1/10], Step [1200/1875], Loss: 0.2946
Epoch [1/10], Step [1300/1875], Loss: 0.2689
Epoch [1/10], Step [1400/1875], Loss: 0.3746
Epoch [1/10], Step [1500/1875], Loss: 0.2356
Epoch [1/10], Step [1600/1875], Loss: 0.0904
Epoch [1/10], Step [1700/1875], Loss: 0.2226
...
参考文献资料
【1】SepViT: Separable Vision Transformer