1. Non-linear Activations
非线性激活函数官方文档:Non-linear Activations。
有深度学习基础的同学应该知道最常用的非线性激活函数就是 ReLU 和 Sigmoid 函数,多分类问题会在输出层使用 Softmax 函数。这三个函数在 PyTorch 中分别为 nn.ReLU、nn.Sigmoid 和 nn.Softmax。
这两个函数的输入都是只需指明 batch_size 即可,在 PyTorch1.0 之后的版本任何形状的数据都能被计算,无需指定 batch_size。
nn.ReLU 只有一个需要设置的参数 inplace,如果为 True 表示计算结果直接替换到输入数据上,例如:
input = -1
nn.ReLU(input, inplace=True)
# input = 0
构建 ReLU 层代码如下:
import torch
import torch.nn as nn
class Network(nn.Module):
def __init__(self):
super(Network, self).__init__()
self.relu1 = nn.ReLU()
def forward(self, input):
output = self.relu1(input)
return output
network = Network()
input = torch.tensor([
[1, -0.5],
[-1, 3]
])
output = network(input)
print(output)
# tensor([[1., 0.],
# [0., 3.]])
然后我们使用 Sigmoid 对图像进行处理:
from torchvision import transforms, datasets
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
import torch.nn as nn
class Network(nn.Module):
def __init__(self):
super(Network, self).__init__()
self.sigmoid1 = nn.Sigmoid()
def forward(self, input):
output = self.sigmoid1(input)
return output
test_set = datasets.CIFAR10('dataset/CIFAR10', train=False, transform=transforms.ToTensor())
data_loader = DataLoader(test_set, batch_size=64)
network = Network()
writer = SummaryWriter('logs')
for step, data in enumerate(data_loader):
imgs, targets = data
output = network(imgs)
writer.add_images('input', imgs, step)
writer.add_images('output', output, step)
writer.close()
结果如下:
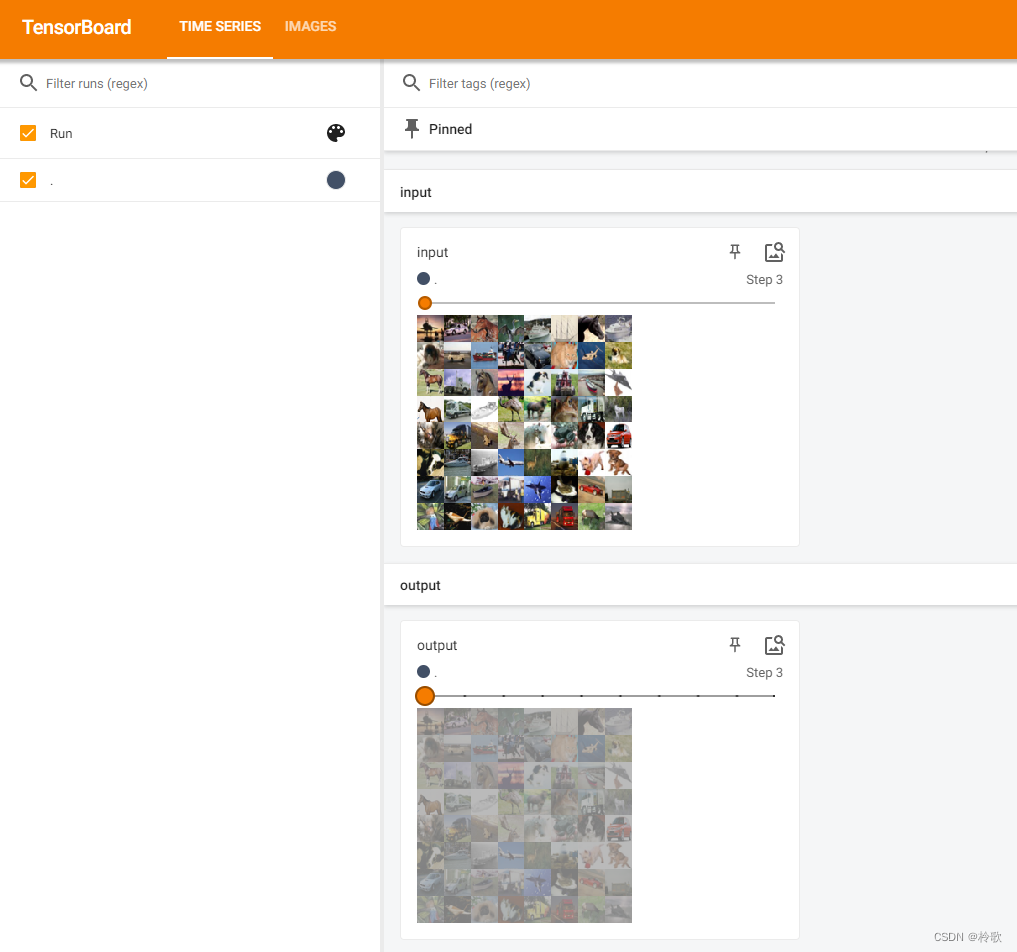
非线性激活的目的是为了在网络中引入一些非线性特征,因为非线性特征越多才能训练出符合各种曲线(特征)的模型。
2. Linear Layers
线性层官方文档:Linear Layers。
PyTorch 的 nn.Linear 是用于设置网络中的全连接层的,需要注意的是全连接层的输入与输出都是二维张量,一般形状为:[batch_size, size],不同于卷积层要求输入输出是四维张量,因此在将图像传入全连接层之前一般都会展开成一维的。
nn.Linear 有三个参数分别如下:
in_features:指的是输入的二维张量的大小,即输入的[batch_size, size]中的size。out_features:指的是输出的二维张量的大小,即输出的二维张量的形状为[batch_size, output_size],当然,它也代表了该全连接层的神经元个数。从输入输出的张量的 shape 角度来理解,相当于一个输入为[batch_size, in_features]的张量变换成了[batch_size, out_features]的输出张量。bias:偏置,相当于 y = ax + b 中的 b。
代码示例如下:
import torch
import torch.nn as nn
class Network(nn.Module):
def __init__(self):
super(Network, self).__init__()
self.linear1 = nn.Linear(24, 30)
def forward(self, input):
output = self.linear1(input)
return output
input = torch.tensor([
[1, 2, 3, 0, 1, 2, 3, 0],
[0, 1, 2, 3, 0, 1, 2, 3],
[3, 0, 1, 2, 3, 0, 1, 2],
], dtype=torch.float32)
print(input.shape) # torch.Size([3, 8])
input = torch.flatten(input) # 将 input 拉平成一维
print(input.shape) # torch.Size([24])
network = Network()
output = network(input)
print(output.shape) # torch.Size([30])

![[附源码]Python计算机毕业设计Django餐馆点餐管理系统](https://img-blog.csdnimg.cn/5e9aaa83a2064b728a75c77d17f5b198.png)