目录
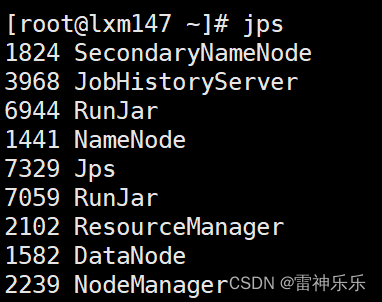
1.开启Hadoop集群和Hive元数据、Hive远程连接
2.配置
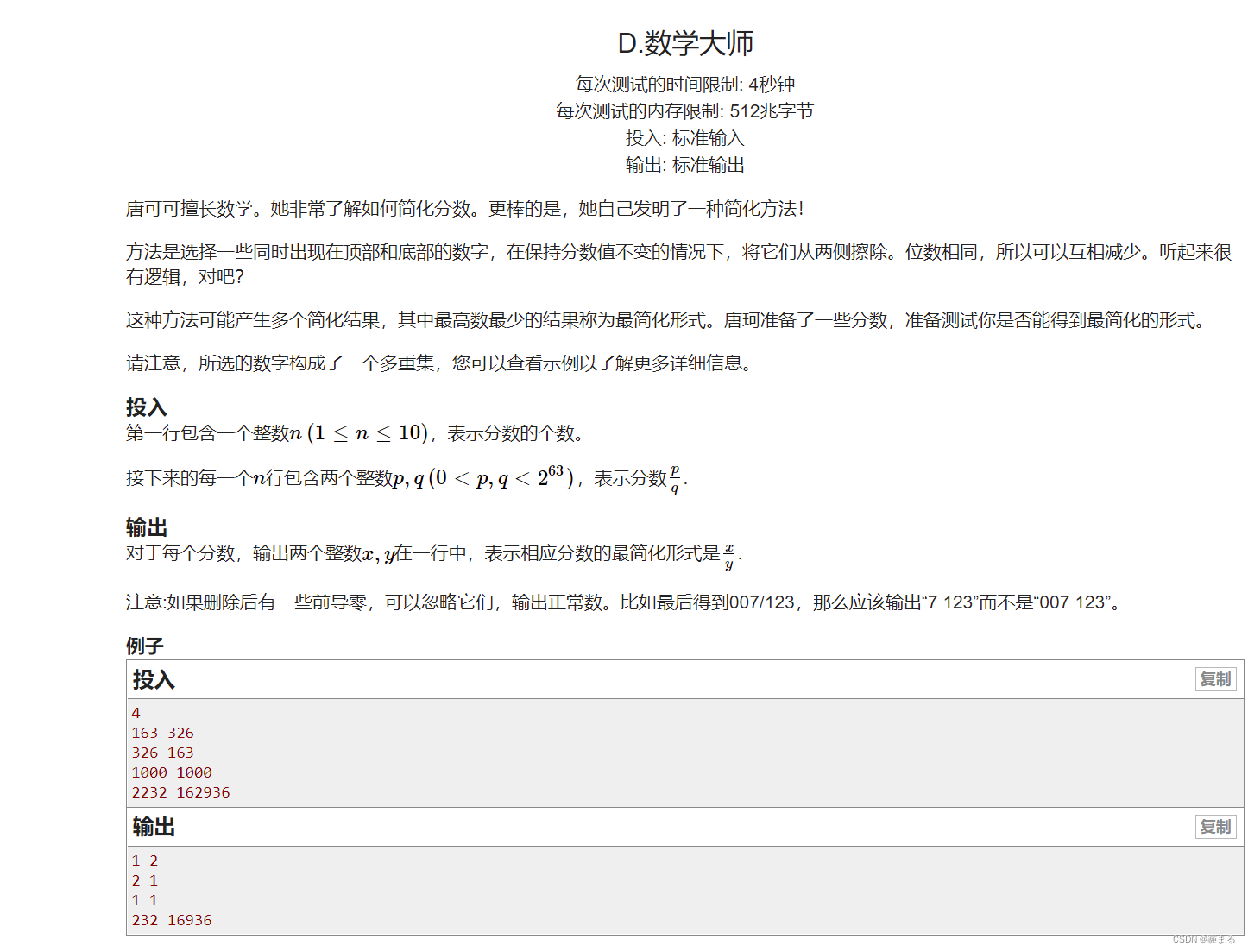
3.读取日志文件并清洗
4.单独处理第四列的数据——方法一:
5.单独处理第四列的数据——方法二:
6.单独处理第四列的数据——方法三:
7.数据清洗结果展示
8.存入Hive中
9.DataGrip中的代码
HDFS日志文件内容:
2023-02-20 15:19:46 INFO org.apache.hadoop.hdfs.server.namenode.TransferFsImage: Downloaded file edits_tmp_0000000000000030396-0000000000000033312_0000000000025236168 size 0 bytes.
2023-02-20 15:19:46 INFO org.apache.hadoop.hdfs.server.namenode.Checkpointer: Checkpointer about to load edits from 1 stream(s).
2023-02-20 15:19:46 INFO org.apache.hadoop.hdfs.server.namenode.FSImage: Reading /opt/soft/hadoop313/data/dfs/namesecondary/current/edits_0000000000000030396-0000000000000033312 expecting start txid #30396
2023-02-20 15:19:46 INFO org.apache.hadoop.hdfs.server.namenode.FSImage: Start loading edits file /opt/soft/hadoop313/data/dfs/namesecondary/current/edits_0000000000000030396-0000000000000033312我们要将上面的日志,使用DataFrame API清洗成表格并存入Hive中,清洗后的表格如下:

1.开启Hadoop集群和Hive元数据、Hive远程连接
2.配置
val spark: SparkSession = SparkSession.builder().appName("demo01")
.master("local[*]")
.config("hive.metastore.uris", "thrift://lxm147:9083")
.enableHiveSupport()
.getOrCreate()
val sc: SparkContext = spark.sparkContext
import spark.implicits._
import org.apache.spark.sql.functions._3.读取日志文件并清洗
// TODO 读取文件清洗
val df1: DataFrame = sc.textFile("in/hadoophistory.log")
.map(_.split(" "))
.filter(_.length >= 8)
.map(x => {
val tuple: (String, String, String, String, String) = (x(0), x(1), x(2), x(3), x(4))
tuple
}).toDF()
df1.show(4,false)
/*
+----------+--------+----+-------------------------------------------------------+------------+
|_1 |_2 |_3 |_4 |_5 |
+----------+--------+----+-------------------------------------------------------+------------+
|2023-02-20|15:19:46|INFO|org.apache.hadoop.hdfs.server.namenode.TransferFsImage:|Downloaded |
|2023-02-20|15:19:46|INFO|org.apache.hadoop.hdfs.server.namenode.Checkpointer: |Checkpointer|
|2023-02-20|15:19:46|INFO|org.apache.hadoop.hdfs.server.namenode.FSImage: |Reading |
|2023-02-20|15:19:46|INFO|org.apache.hadoop.hdfs.server.namenode.FSImage: |Start |
+----------+--------+----+-------------------------------------------------------+------------+
*/4.单独处理第四列的数据——方法一:
// TODO 单独处理第四列的数据
val df2: DataFrame =
df1.withColumn("test", split(col("_4"), "\\."))
.select(
$"_1".as("t1"),
$"_2".as("t2"),
$"_3".as("t3"),
col("test").getItem(0).as("a0"),
col("test").getItem(1).as("a1"),
col("test").getItem(2).as("a2"),
col("test").getItem(3).as("a3"),
col("test").getItem(4).as("a4"),
col("test").getItem(5).as("a5"),
col("test").getItem(6).as("a6"),
$"_5".as("t5")
)5.单独处理第四列的数据——方法二:
val df2: DataFrame =
df1.rdd.map(
line => {
val strings: Array[String] = line.toString().split(",")
val value: Array[String] = strings(3).split("\\.")
(strings(0).replaceAll("\\[", ""), strings(1), strings(2),
value(0), value(1), value(2), value(3), value(4), value(5), value(6),
strings(4).replaceAll("]", "")
)
}
).toDF("t1", "t2", "t3", "a1", "a2", "a3", "a4", "a5", "a6", "a7", "t5")6.单独处理第四列的数据——方法三:
方法三比较麻烦,但是可以对数据类型做单独处理,可以参考我的另一篇博文《》
另一篇博文中读取的日志数据更换了
7.数据清洗结果展示
df2.show(4, truncate = false)
+----------+--------+----+---+------+------+----+------+--------+----------------+------------+
|t1 |t2 |t3 |a1 |a2 |a3 |a4 |a5 |a6 |a7 |t5 |
+----------+--------+----+---+------+------+----+------+--------+----------------+------------+
|2023-02-20|15:19:46|INFO|org|apache|hadoop|hdfs|server|namenode|TransferFsImage:|Downloaded |
|2023-02-20|15:19:46|INFO|org|apache|hadoop|hdfs|server|namenode|Checkpointer: |Checkpointer|
|2023-02-20|15:19:46|INFO|org|apache|hadoop|hdfs|server|namenode|FSImage: |Reading |
|2023-02-20|15:19:46|INFO|org|apache|hadoop|hdfs|server|namenode|FSImage: |Start |
+----------+--------+----+---+------+------+----+------+--------+----------------+------------+8.存入Hive中
println("正在存储......")
df2.write.mode(SaveMode.Overwrite).saveAsTable("shopping.dataframe")
spark.close()
sc.stop()
println("存储完毕......")9.DataGrip中的代码
SET hive.exec.compress.output=true;
SET mapred.output.compression.codec=org.apache.hadoop.io.compress.SnappyCodec;
SET mapred.output.compression.type=BLOCK;
use shopping;
show tables;
select * from dataframe;
参考文章《将Spark数据帧保存到Hive:表不可读,因为“ parquet not SequenceFile”》