具体的实践中,我们主要参考了腾讯的PLE(Progressive Layered Extraction)模型,PLE相对于前面的MMOE和ESMM,主要解决以下问题:
多任务学习中往往存在跷跷板现象,也就是说,多任务学习相对于多个单任务学习的模型,往往能够提升一部分任务的效果,同时牺牲另外部分任务的效果。即使通过MMoE这种方式减轻负迁移现象,跷跷板现象仍然是广泛存在的。
前面的MMOE模型存在以下两方面的缺点
MMOE中所有的Expert是被所有任务所共享的,这可能无法捕捉到任务之间更复杂的关系,从而给部分任务带来一定的噪声
不同的Expert之间没有交互,联合优化的效果有所折扣
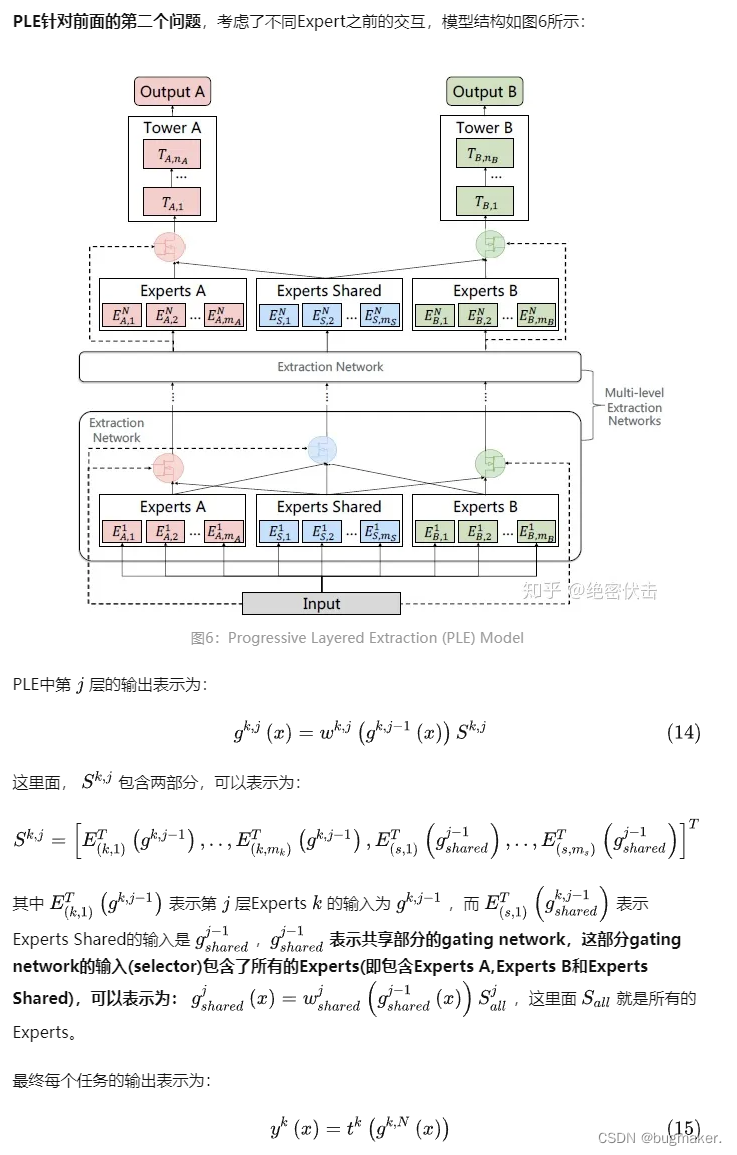
PLE针对上面第一个问题,每个任务有独立的Expert,同时保留了共享的Expert,模型结构如图5所示:
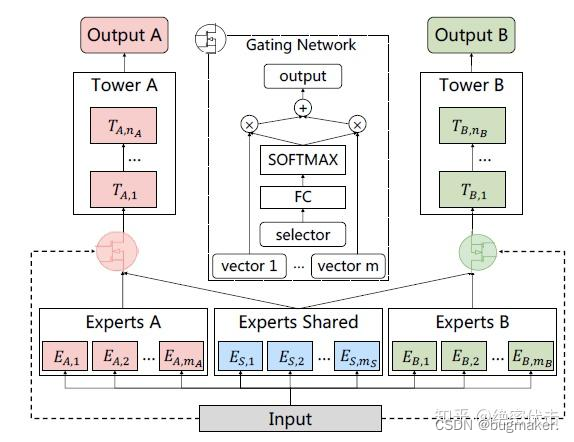
图中ExpertsA和ExpertsB是任务A和B各自的专家系统,中间的Experts Shared是共享的专家系统。图中的selector表示选择的专家系统。对于任务A,使用Experts A和Experts Shared里面的多个Expert的输出。

PLE训练优化
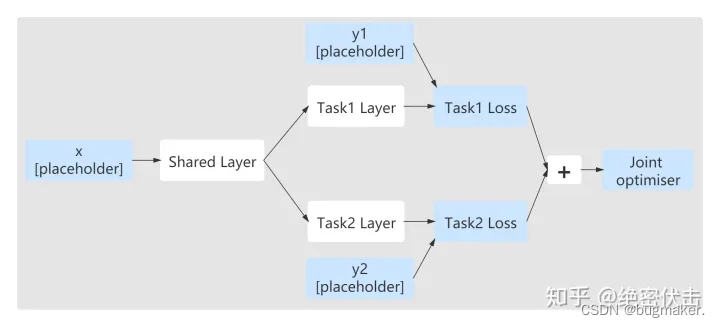
可以看出最终将每个任务的Loss加权和合并成一个Loss,使用一个优化器训练,tensorflow里面可以表示为:
联合训练比较适合在同一数据集进行训练,使用同一feature,但是不同任务输出不同结果,比如前面的pctr和pctcvr任务。
最开始上线的版本中,使用联合训练的方式,并且ctr和ysl两个任务的Loss系数都是1,后来考虑到ysl的均值是4左右,而ctr的均值不到0.2,模型会偏向于ysl。但是手动调节权值非常耗时,考虑使用UWL(Uncertainty to Weigh Losses),优化不同任务的权重系数。


多目标建模损失函数定义
在做多目标建模的时候,摆在我们面前的主要在于各个任务的损失函数如何权衡
baseline
最简单的做法就是人工经验给每个任务分配一个权重系数,也就是
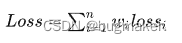
其中n代表任务个数
优点:简单,易懂
缺点:对人工经验要求较高,需要多次人工尝试调参才能达到最佳效果
这样做主要有这么几个问题
不同任务的Loss差异非常大,如果某个任务的Loss比其他几个任务的Loss大一个量级,其实多任务学习就演变成单任务学习
不同任务的梯度变化不同,有些任务参数更新快,有些任务参数更新慢
不同任务如何分配权重,也就是如何确定不同任务的重要度
1,论文 Multi-Task Learning Using Uncertainty to Weigh Losses for Scene Geometry and Semantics
motivation: 多任务学习各个任务的Loss权重确定是个头疼的事情,如果人工来调试的话,需要耗费大量的时间和经历,因此提出了基于任务的不确定性【???不好理解】来自动学习不同任务的权重
理论一大坨,以后有时间可以慢慢推导吧。。。。。只需要记住加上参数来动态惩罚对Loss大的任务进行
损失函数:
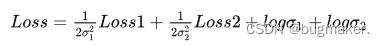
code:
for y_true, y_pred, log_var in zip(ys_true, ys_pred, self.log_vars):
precision = K.exp(-log_var[0])
loss += K.sum(precision * (y_true - y_pred)**2. + log_var[0], -1)