序论
之前一直做的lidar感知,现在感觉大趋势是多传感器融合,所以博主也在向BEV下的融合框架学习,希望大家后面可以多多交流,下面会分为两类进行介绍,后期的文章会在下面两类中以小标题的形式出现,BEV下的两类检测算法主要区分点在于img2bev模块,一类是显示转换,以lss为基础,一类是以transformer为基础的隐式转换。
一、显示转换的BEV感知
1.LSS
论文链接:https://arxiv.org/pdf/2008.05711.pdf
代码链接:GitHub - nv-tlabs/lift-splat-shoot: Lift, Splat, Shoot: Encoding Images from Arbitrary Camera Rigs by Implicitly Unprojecting to 3D (ECCV 2020)
lss目前应该是显示转换的鼻祖,大部分都是基于它进行优化的,所以这个部分会进行详细介绍。
优点:实现了相机特征到BEV特征的转换
缺点:极度的依赖depth预测的准确性,同时矩阵外积过于耗时,要想在depth维度有较高的精度,HWD计算量特别大。
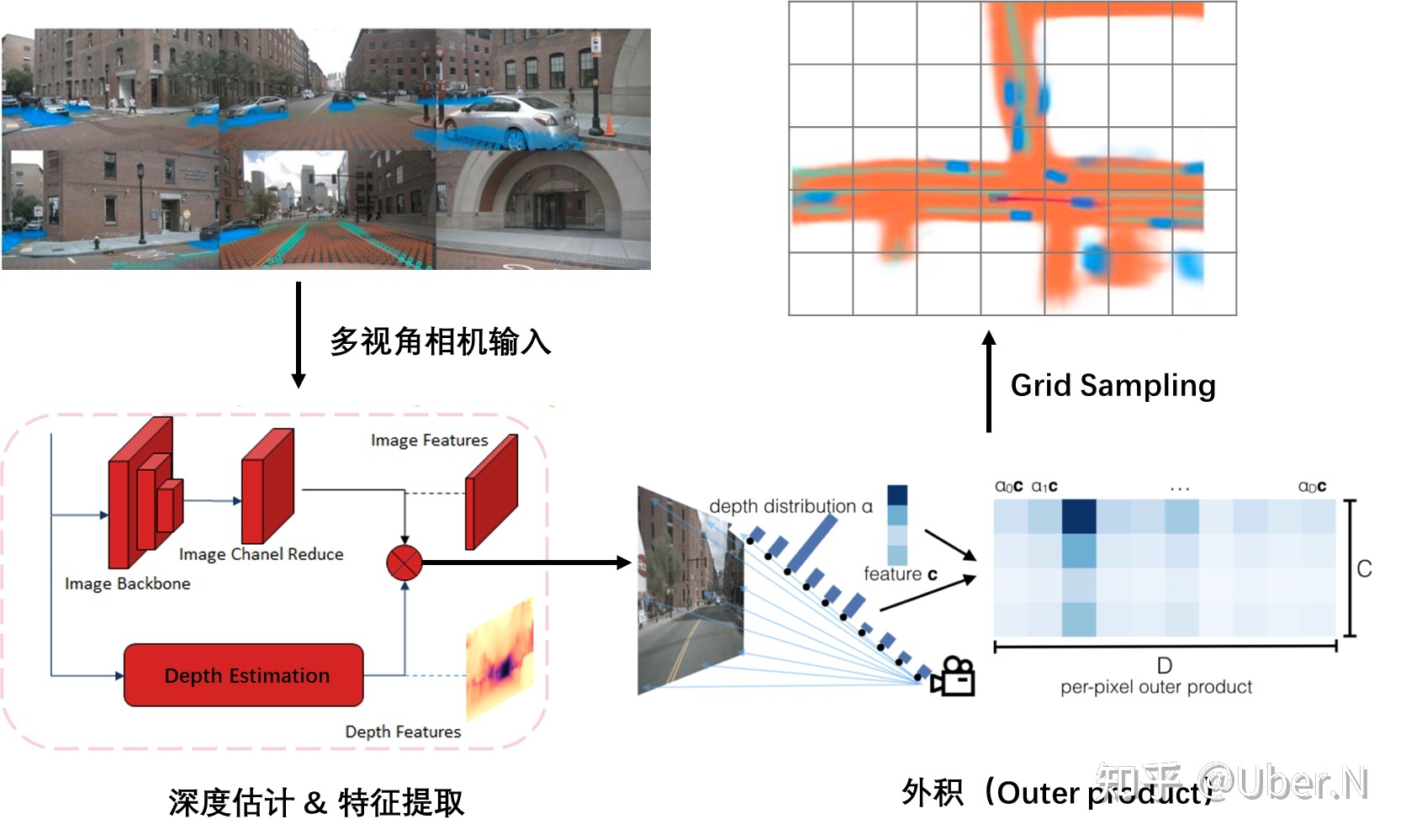
A:Lift操作
LSS中的L表示lift,升维的意思,表示把H*W*C的图像特征升维到H*W*D*C,D表示在每个像素点都预测了一个D维的深度信息,比如D是50维,相当于这个像素点在0-50m里出现的概率。D的一个维度表示在这一米出现的概率。
第一步:get_geometry(得到特征图与3D空间的索引对应)
torch.arange生成D的列表,view加expand变成(D,H,W)的维度
torch.linespace生成特征图长宽HW的列表分布,里面的值是像素坐标,同样view+expand变为(D,H,W),然后用torch.stack将这三个在-1维度拼接。得到(D,H,W,3)的矩阵,相当于给定一个D,H,W的特征点,我们可以得到三维的像素坐标表示,这个像素坐标需要转换到真实车身坐标系。
将图像数据增强进行抵消,同时根据相机内外参矩阵与上面的相乘,得到(D,H,W,3)这个3表示的就是车身坐标系的3D位置。此时我们就可以根据一个D,H,W索引的特征点,得到其在真实空间的位置。这一步是接下来投影的关键。
第二步:get_cam_feats(得到相机的D,H,W型feature)
图像经过骨干网络处理之后,用一个1*1的卷积,将channel变为D+C,在channel维度选取前D维,进行softmax操作,相当于说这个H,W的特征点在D的深度上的分布概率。将(N,1,D)和(N,C,1)做乘法,相当于矩阵外积,得到(N,C,D)的张量,N表示的是H*W,所以我们就得到了(D,H,W,C)的图像特征。
B:Splat操作
splat表示拍平的意思,上一步我们得到了像素空间与真实3D空间的坐标索引,同时也得到了(D,H,W,C)的图像特征高维表示。这一步就是把特征转换到BEV空间中,并拍平为2D,相当于pointpillar的操作。
第一步:预处理操作
传进来的就是geom_feats维度为(D,H,W,3)和X图像高维特征(D,H,W,C),首先geom_feats里3这个维度,里面的值是车身坐标系的3D位置,有正有负,我们先把他变为从0开始的长整形分布,比如x是0-100m,y是0-60m,z是0-5m这样,全为正的表示,相当于做个平移。然后view成(Nprime,3),然后循环batch,用torch.cat以及torch.full生成一个(Nprime,1)的batch索引,再和geom_feats用torch.cat一下,得到新的geom_feats维度为(Nprime,4),里面是真实空间的xyzb,然后用xyz的范围进行过滤一下。
第二步:拍平操作
得到维度为(Nprime,4)的geom_feats,这里说的也不准确,因为过滤了范围外的,第一维度就不再是Nprime,大家理解就行。然后根据BEV分辨率对geom_feats进行排序,geom_feats[:,0]*Y*Z*B+geom_feats[:,1]*Z*B+geom_feats[:,2]*B+geom_feats[:,3],然后argsort排序,对X以及geom_feats进行排序。X维度为(Nprime,C),对其进行cumsum操作,也叫前缀和操作,然后找到网格变化的节点,用当前变化节点减去前面的变化节点,就是中间这个网格的和,起到了一个sum_pooling操作,最后根据geom_feats的索引,把X放入到(B,C,Z,X,Y)里面,再把Z用unbind和cat操作压缩即可。
二、隐式转换的BEV感知
三、Reference
LSS(Lift,Splat,Shoot)-实现BEV感知的最佳利器 - 知乎 (zhihu.com)
![[element]element-ui框架下载](https://img-blog.csdnimg.cn/58820058cf68435d83d3b4c8f7d616c9.png)


![[STL]string的使用+模拟实现](https://img-blog.csdnimg.cn/3eff41e25455482daf49ed479a74b7e7.png)