前言
这里面结合手写数字识别的例子,讲解一下训练时候注意点
目录
- 训练问题
- 解决方案
- 参考代码
一 训练问题
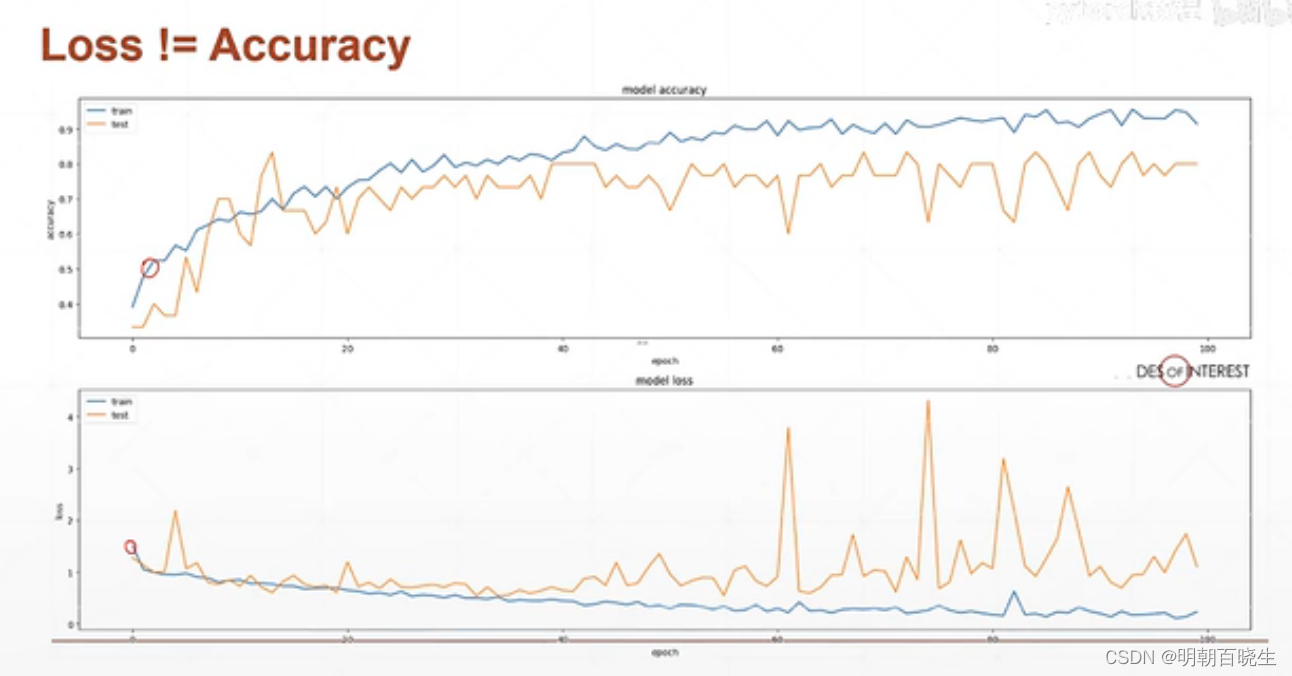
训练的时候,我们的数据集分为Train Data 和 validation Data。
随着训练的epoch次数增加,我们发现Train Data 上精度
先逐步增加,但是到一定阶段就会出现过拟合现象。
validation Data 上面不再稳定,反而出现下降的趋势,泛化能力变差.
二 解决方案
test once serveral batch(几个batch,验证一次)
test once per epoch(每一轮训练完后,验证一次)
test once serveral epoch(几轮训练后,验证一次)
当发现验证集acc到达一定精度,且下降后,停止训练
三 参考代码
# -*- coding: utf-8 -*-
"""
Created on Mon Apr 10 21:51:21 2023
@author: cxf
"""
import torch
import torch.nn.functional as F
def validation():
logits = torch.rand(6,10)
pred = F.softmax(logits, dim=1)
print(pred.shape)
pred_label= pred.argmax(dim=1)
print(pred_label)
label= torch.tensor([0,1,2,3,4,5])
N = label.shape[0]
correct = torch.eq(pred_label, label)
print(correct)
acc = correct.sum().float().item()/N
print("\n acc %f"%acc)
validation()import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
#超参数
batch_size=200
learning_rate=0.01
epochs=10
#获取训练数据
train_loader = torch.utils.data.DataLoader(
datasets.MNIST('../data', train=True, download=True, #train=True则得到的是训练集
transform=transforms.Compose([ #transform进行数据预处理
transforms.ToTensor(), #转成Tensor类型的数据
transforms.Normalize((0.1307,), (0.3081,)) #进行数据标准化(减去均值除以方差)
])),
batch_size=batch_size, shuffle=True) #按batch_size分出一个batch维度在最前面,shuffle=True打乱顺序
#获取测试数据
test_loader = torch.utils.data.DataLoader(
datasets.MNIST('../data', train=False, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=batch_size, shuffle=True)
class MLP(nn.Module):
def __init__(self):
super(MLP, self).__init__()
# 定义网络的每一层,nn.ReLU可以换成其他激活函数,比如nn.LeakyReLU()
self.model = nn.Sequential(
nn.Linear(784, 200),
nn.ReLU(inplace=True),
nn.Linear(200, 200),
nn.ReLU(inplace=True),
nn.Linear(200, 10),
nn.ReLU(inplace=True),
)
def forward(self, x):
x = self.model(x)
return x
device = torch.device('cuda:0') #使用第一张显卡
net = MLP().to(device)
# 定义sgd优化器,指明优化参数、学习率
# net.parameters()得到这个类所定义的网络的参数[[w1,b1,w2,b2,...]
optimizer = optim.SGD(net.parameters(), lr=learning_rate)
criteon = nn.CrossEntropyLoss().to(device)
for epoch in range(epochs):
for batch_idx, (data, target) in enumerate(train_loader):
data = data.view(-1, 28*28).to(device) # 将二维的图片数据摊平[样本数,784]
target = target.to(device)
logits = net(data) # 前向传播
loss = criteon(logits, target) # nn.CrossEntropyLoss()自带Softmax
optimizer.zero_grad() # 梯度信息清空
loss.backward() # 反向传播获取梯度
optimizer.step() # 优化器更新
if batch_idx % 100 == 0: # 每100个batch输出一次信息
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
test_loss = 0
correct = 0 # correct记录正确分类的样本数
for data, target in test_loader:
data = data.view(-1, 28 * 28).to(device)
target = target.to(device)
logits = net(data)
test_loss += criteon(logits, target).item() # 其实就是criteon(logits, target)的值,标量
pred = logits.data.max(dim=1)[1] # 也可以写成pred=logits.argmax(dim=1)
correct += pred.eq(target.data).sum()
test_loss /= len(test_loader.dataset)
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
参考:
课时53 MNIST测试实战_哔哩哔哩_bilibili
https://www.cnblogs.com/douzujun/p/13323078.html