用pr设计的图片,当封面不错

单例模式
单例对象的类必须保证只有一个实例存在
饿汉式单例
饿汉式在类创建的同时就已经创建好一个静态的对象供系统使用,以后不再改变,所以天生是线程安全的
//饿汉式单例类.
public class Singleton {
//构造器私有化
private Singleton() {}
//static修饰 在类初始化时,已经自行实例化
private static final Singleton single = new Singleton();
//静态工厂方法
public static Singleton getInstance() {
return single;
}
}
- 优点:保证线程绝对安全
- 缺点:所有对象类加载的时候就实例化,系统初始化就会导致大量的内存浪费
懒汉式单例
//懒汉式单例类
public class Singleton {
//构造器私有化
private Singleton() {}
private static Singleton single = null;
//静态工厂方法
public static Singleton getInstance() {
if(single==null){
//在第一次调用的时候实例化自己
single=new Singleton();
}
return single;
}
}优点:解决了饿汉式单例可能带来的内存浪费问题,节省内存
缺点:线程不安全的问题
在多线程环境下,我们就要考虑到线程的安全问题:即是否有不同的线程分别new一个对象实例,导致不同线程创建的class类的实例不是同一个。
线程安全懒汉式
可以直接在方法加synchronized,但是不推荐。会导致资源浪费
//懒汉式-线程安全
public class Singleton {
//构造器私有化
private Singleton() {
}
private static volatile Singleton single = null;
//静态工厂方法
public static synchronized Singleton getInstance() {
if (single != null) {
return single;
}
single = new Singleton()
return single;
}
}懒汉式双重锁
双重锁检查:方法检查判定两次,并使用锁,所以形象称为双重检查锁定模式。
1.首先判断变量是否被初始化,没有被初始化,再去获取锁。
2.获取锁之后,再次判断变量是否被初始化。第二次判断目的在于有可能其他线程获取过锁,已经初始化改变量。第二次检查还未通过,才会真正初始化变量。
用 volatile定义的变量,将会保证对所有线程的可见性。禁止指令重排序优化。
//懒汉式-线程安全
public class Singleton {
//构造器私有化
private Singleton() {
}
private static volatile Singleton single = null;
//静态工厂方法
public static Singleton getInstance() {
if (single != null) {
return single;
}
synchronized (Singleton.class) {
if (single == null) {
//在第一次调用的时候实例化自己
single = new Singleton();
}
}
return single;
}
}
工厂模式
准备工作
public interface Phone { //规范:每个手机都只能玩游戏 void play(); }oppo手机
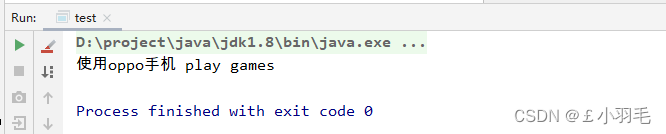
public class OPPO implements Phone{ @Override public void play() { System.out.println("使用oppo手机 play games"); } }vivo手机
public class VIVO implements Phone{ @Override public void play() { System.out.println("使用vivo手机 play games"); } }小米手机
public class XiaoMi implements Phone { @Override public void play() { System.out.println("使用xiaomi手机 play games"); } }
简单工厂模式
简单工厂模式:创建一个工厂类根据传入的参数决定创建出哪一种产品的实例
//简单工厂模式
public class PhoneFactory {
public static Phone getPhone(String phone) {
//通过给工厂传入不同的参数,拿到不一样的手机
if (phone.equals("oppo")) {
return new OPPO();
} else if (phone.equals("vivo")) {
return new VIVO();
} else if (phone.equals("xiaomi")) {
return new XiaoMi();
} else {
return null;
}
}
}测试:
public static void main(String[] args) { Phone phone = PhoneFactory.getPhone("xiaomi"); phone.play(); }

工厂方法模式
此时每一种品牌都有自己的工厂制作自己品牌的手机。定义一个工厂接口基类,
public interface PhoneFactory {
//定义创建产品的抽象方法
Phone makePhone();
}oppo工厂
//oppo工厂 public class OPPOFactory implements PhoneFactory { @Override public Phone makePhone() { return new OPPO(); } }vivo工厂
//vivo工厂 public class VIVOFactory implements PhoneFactory{ @Override public Phone makePhone() { return new VIVO(); } }小米工厂
//小米工厂 public class XiaoMiFactory implements PhoneFactory { @Override public Phone makePhone() { return null; } }
测试
public static void main(String[] args) { OPPOFactory oppoFactory = new OPPOFactory(); Phone phone = oppoFactory.makePhone(); phone.play(); }
看的出来,我们新增了很多个工厂类,那么工厂方法模式好在哪里呢?
符合 开闭原则,在新增产品的时候不需要改动已经存在的代码,利于程序的扩展。而简单工厂模式在添加新的产品时,不得不修改工厂方法,扩展性不好。
工厂方法模式缺点:就是在新增产品的时候需要新增产品类和工厂类(成对增加)。
抽象工厂模式
与工厂方法模式相比,抽象工厂模式中的工厂不再只是创建一种具体的产品(比如上面,我们的小米工厂就只是去创建小米手机)。
抽象工厂模式的工厂创建一组产品。这一组产品式一系列相关相互依赖对象。比如小米工厂创建的小米手机、小米手环、小米电视、小米充电宝、小米电脑....
简单整一个统一的电视接口
public interface TV { void watchTV(); }小米电视
public class XiaoMITV implements TV { @Override public void watchTV() { System.out.println("使用小米电视 watch TV"); } }
抽象工厂Factory基类.。为了方便我就只写了俩个创建手机和创建电视。
//抽象工厂Factory基类
public interface Factory {
Phone createPhone();
TV createTV();
}具体各个品牌的工厂类如下:为了方便我就只写了小米工厂手机和创建电视。
//小米工厂
public class XiaoMiFactory implements Factory {
@Override
public Phone createPhone() {
return new XiaoMi();
}
@Override
public TV createTV() {
return new XiaoMITV();
}
}测试
public static void main(String[] args) { Factory factory = new XiaoMiFactory(); Phone phone = factory.createPhone(); phone.play(); TV tv = factory.createTV(); tv.watchTV(); }
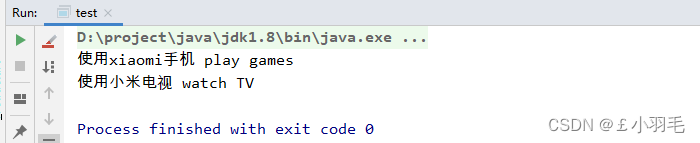
抽象工厂模式优势:将具有一定共性的产品集合封装在一起。。更符合业务场景
原型模式
原型模式:用⼀个已经创建的实例作为原型,通过复制该原型对象来创建⼀个和原型相同的新对象。避免了重新执行构造过程步骤,当直接创建对象的代价比较大时,则采用这种模式
因为Java对原型模式的支持,所以原型模式在Java是很容易实现的一件事情。
浅拷贝
浅拷贝的整个过程就是,创建一个新的对象,然后新对象的每个值都是由原对象的值,通过 = 进行赋值;
- 基本数据类型是值赋值
- 非基本的就是引用赋值
Java 中的 Object 类提供了浅克隆的 clone() ⽅法,具体原型类只要实现 Cloneable 接⼝就可实现对象的浅克隆,这⾥的 Cloneable 接⼝就是抽象原型类。
//对于实现了Cloneable接口的对象,可以调用Object#clone()来进行属性的拷贝
public interface Cloneable {
}地址类
@Data @NoArgsConstructor @AllArgsConstructor public class Address { private String province;//省 private String city;//市 private String area;//区 }用户类
@Data @NoArgsConstructor @AllArgsConstructor public class User implements Cloneable { private Integer userId; private String name; private String password; private Address address;//引用类型 //浅拷贝 @Override protected Object clone() throws CloneNotSupportedException { //浅拷贝是使用默认的 clone()方法来实现 User user = (User) super.clone(); return user; } }
测试类-测试浅拷贝
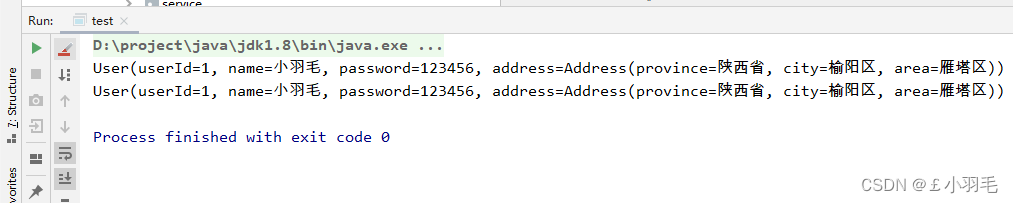
public static void main(String[] args) throws CloneNotSupportedException { Address address = new Address("陕西省", "西安市", "雁塔区"); User user = new User(1, "小羽毛", "123456", address); //克隆user对象 User clone = (User)user.clone(); //修改克隆后的对象,会影响到原来的对象的属性 Address addressClone = clone.getAddress(); addressClone.setCity("榆林市"); addressClone.setCity("榆阳区"); //输出结果 System.out.println(user); System.out.println(clone); }
深拷贝
通过序列化克隆对象(推荐使用)
深拷贝,就是要创建一个全新的对象,新的对象内部所有的成员也都是全新的,只是初始化的值已经由被拷贝的对象确定了而已
浅拷贝实现Cloneable,重写,深拷贝是通过实现Serializable读取二进制流。
地址类
@Data @NoArgsConstructor @AllArgsConstructor public class Address implements Serializable, Cloneable { private String province;//省 private String city;//市 private String area;//区 //因为该类的属性,都是 String , 因此这里使用默认的 clone 完成即可 @Override protected Object clone() throws CloneNotSupportedException { return super.clone(); } }用户类
22-04-23 西安 javaSE(14)文件流、缓冲流、转换流、对象流、标准流、关闭IO资源的封装类IOUtils(纳命来)_ioutils关闭_£小羽毛的博客-CSDN博客
@Data @NoArgsConstructor @AllArgsConstructor public class User implements Serializable, Cloneable { private Integer userId; private String name; private String password; private Address address;//引用类型 //深拷贝 - 通过对象的序列化实现 (推荐) @Override protected Object clone() throws CloneNotSupportedException { try{ //创建一个 32 字节 ( 默认大小 ) 的缓冲区 ByteArrayOutputStream bos = new ByteArrayOutputStream(); ObjectOutputStream oos = new ObjectOutputStream(bos); oos.writeObject(this); ByteArrayInputStream bis = new ByteArrayInputStream(bos.toByteArray()); ObjectInputStream ois = new ObjectInputStream(bis); User clone = (User)ois.readObject(); return clone; }catch (Exception e){ e.printStackTrace(); return null; } } }Java 字节数组输出流 (
ByteArrayOutputStream) 在内存中创建一个字节数组缓冲区,所有发送到输出流的数据保存在该字节数组缓冲区中//创建一个新分配的字节数组。数组的大小和当前输出流的大小,内容是当前输出流的拷贝 public byte[] toByteArray()ByteArrayInputStream和ByteArrayOutputStream两个流对象都操作的数组,并没有使用系统资源,所以不用进行 close 关闭
测试类-测试深拷贝
public static void main(String[] args) throws CloneNotSupportedException { Address address = new Address("陕西省", "西安市", "雁塔区"); User user = new User(1, "小羽毛", "123456", address); //克隆user对象 User clone = (User)user.clone(); //修改克隆后的对象,会影响到原来的对象的属性 Address addressClone = clone.getAddress(); addressClone.setCity("榆林市"); addressClone.setCity("榆阳区"); //输出结果 System.out.println(user); System.out.println(clone); }

序列化拷贝
通过序列化然后将对象写入流再写出流的方式来对对象进行克隆。注意俩点
1.原型对象也不需要实现Cloneable接口,而是需要实现Serializable接口,使得对象支持序列化。
2.不需要把每一个级联对象的clone()方法都实现
User和Address都实现Serializable接口
@Data @NoArgsConstructor @AllArgsConstructor public class Address implements Serializable { private String province;//省 private String city;//市 private String area;//区 }@Data @NoArgsConstructor @AllArgsConstructor public class User implements Serializable { private Integer userId; private String name; private String password; private Address address;//引用类型 //深拷贝 - 通过对象的序列化实现 protected Object cloneUser() { try { //创建一个 32 字节 ( 默认大小 ) 的缓冲区 ByteArrayOutputStream bos = new ByteArrayOutputStream(); ObjectOutputStream oos = new ObjectOutputStream(bos); oos.writeObject(this); ByteArrayInputStream bis = new ByteArrayInputStream(bos.toByteArray()); ObjectInputStream ois = new ObjectInputStream(bis); User clone = (User) ois.readObject(); return clone; } catch (Exception e) { e.printStackTrace(); return null; } } }
测试:只改动了 User clone = (User)user.cloneUser();
public static void main(String[] args) throws CloneNotSupportedException Address address = new Address("陕西省", "西安市", "雁塔区"); User user = new User(1, "小羽毛", "123456", address); //克隆user对象 User clone = (User)user.cloneUser(); //修改克隆后的对象,会影响到原来的对象的属性 Address addressClone = clone.getAddress(); addressClone.setCity("榆林市"); addressClone.setCity("榆阳区"); //输出结果 System.out.println(user); System.out.println(clone); }