1.数据集介绍:
试验台如图所示,试验台左侧有电动机,中间有扭矩收集器,右侧有动力测试仪,控制电子设备在图中没有显示。SKF6203轴承使用16通道数据采集卡采集轴承的振动数据,并在驱动端部分(DE)、风扇端部分(FE)、基座端安装传感器。该实验在轴承内圈、滚动体、外圈上采用电火花加工方式制造故障,故障缺陷直径尺寸为0.1778mm、0.3556mm、0.5334mm(不同损伤程度)。分别在负载0HP、1HP、2HP、3HP下采集数据,采样频率为f=12.8khz。

CWRU滚动承轴实验平台
2.小波变换
在分析不稳定的时间信号时,在低频范围内需要一个更大的窗口来分析低频信号;而在高频区域,需要一个更窄的窗口来获取关于振幅的精确信息。但是,当快速傅里叶变换时,窗口函数的形状是固定的,当分析不连续信号时,信号在不同的时间内是离散的,因此快速傅里叶变换具有一定的局限性。基于小波变换很好地解决了这一限制,信号的范围是固定的,但可以通过信号的高频特征改变其窗口的长度和高度来适应信号的特征,确保频率分析的精度,确保频率分析的精度,频率的变化可以很好地满足实际工程需求。因此,本文件选择了一种基于小波变换的方法[42]。
小波的变换由两种类型组成:小波的离散变换(DWT)和小波的连续变换(CWT)。滚动轴承的振动信号属于实际的工程信号领域,更适合使用连续的小波变换进行分析。
连续小波变换尺度图(CWTS)
目前基于连续小波变换的故障诊断算法有一定的局限性。首先,大多数方法都是提取出小波变换系数中的几个特征值,进而通过对特征值的分类来进行故障诊断。这些方法对小波变换系数进行了降维处理,没有能够充分利用小波变换系数,可能导致重要故障特征的丢失。其次,这些算法中,故障特征的选择和提取大都是基于专家经验的,无法得到一个能在现场应用的通用的解决方案。
本文中,使用连续小波变换的滤波器组函数获得振动加速度信号的连续小波变换,并根据小波系数生成尺度(continuous wavelet transform scale,CWTS)图,再利用深度网络强大的图像识别能力,对由小波变换系数构成的CWTS图直接进行故障识别。CWTS图包含了连续小波变换的所有运算结果,没有进行数据降维,避免了故障信息的丢失,同时也不需要复杂的特征提取过程。
3.融合DE与FE两个传感器的图像
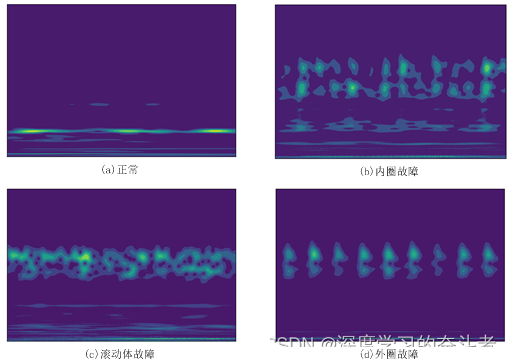
单通道小波时频图
在上图可以看出,正常状态的尺度图与其它三种故障状态的尺度图相互之间有明显特征区别,表明了本文所提的CWTS方法的的优越性。但是,只基于DE端传感器的振动信号,在变负载的诊断中容易受到干扰,出现结果不稳定等因素,多通道信息相对单通道,拥有更多的特征。当拥有更多的特征时,无论是传统机器学习方法,还是深度网络,都可以相应提高其识别准确率。所以,将DE端与FE端融合在一起,并通过本文的CWTS方法生成图像,如下图所示。在图中可以看出,双通道的小波尺度图像包含更多的特征。

4实验设定
采用二维卷积网络,为保持与一维卷积网络诊断结果的对比,同样主要有两个卷积层、两个池化层、一个拉直层和两个全连接层构成。但是,卷积核均采用二维卷积核,卷积层1和卷积层2均采用3*3尺寸,激活函数采用ReLU函数,池化层均采用二维最大池化方式,拉直层的主要作用是将最大池化层的输出结果变成符合全连接层输入的形状。全连接层1负责进一步映射特征与标签之间的关系,全连接层2的神经元个数与标签个数一样,并利用softmax函数输出预测标签概率。整个网络的主要参数如下表4-1所示。
表4-1 二维DCNN参数
| 网络类型 Network type | 层类型 Layer type | 核尺寸 Kernel size | 核/神经元 数量/个 | 步长 Step | 激活函数 |
| 二维CNN 网络 | 卷积层1 | 3*3 | 8 | 1 | Relu |
| 最大池化层1 | 2*2 | / | 2 | / | |
| 卷积层2 | 3*3 | 16 | 1 | Relu | |
| 最大池化层2 | 2*2 | / | 2 | / | |
| 拉直层 | / | / | / | Relu | |
| 全连接层1 | / | 64 | / | / | |
| 全连接层2 | / | 4 | / | Relu |
全连接网络(DNN)的设置
在全连接神经网络中,没有卷积层和池化层等结构,只有全连接层,并且相邻的全连接层的神经元是一一连接的,虽然避免了特征的过度损失,但是全连接网络参数过多,导致一般运算量极大,容易陷入局部最优解。整个网络的主要参数如下表4-2所示。
表4-2 全连接网络参数
| 网络类型 Network type | 层类型 Layer type | 神经元 数量/个 | 激活函数 |
| 全连接网络 | 全连接层1 | 32 | Relu |
| 拉直层 | / | Relu | |
| 全连接层2 | 64 | / | |
| 全连接层3 | 4 | Relu |
KNN分类
KNN算法在模式识别领域中,常用于解决分类问题。KNN算法,也被称为K临近算法,就是指的是每个样本都可以用它最接近的K个邻近值的特征来代表,这样就可以从高维降低到低维表示,降低特征维度。最后,KNN根据训练集中的K个最近邻中的多数标签对每个未标记的样本进行分类。因此,距离度量是KNN算法好坏的关键。在缺乏先验知识的情况下,大多数KNN分类器使用的是欧氏距离进行度量。
5.实验结果展示
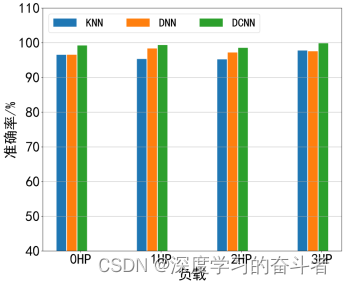
首先,实验的优化器使用Adam,epoch设定为100次,学习率设定为0.01,批量设定为64。为测试DCNN在单负载场景下对二维尺度图的特征提取能力,分别在4种不同负载下试验。为消除偶然误差,采用测试集10次实验结果的平均值评估网络性能。并使用DNN与KNN方法进行对比。基于二维图像的识别准确率如表4-3 所示,对应的柱状图如图4-4所示。
表4-3 基于二维图像的识别准确率
| 方法 | 识别准确率/% | |||
| 0HP | 1HP | 2HP | 3HP | |
| KNN | 97.54 | 95.34 | 95.23 | 96.78 |
| DNN | 97.52 | 98.36 | 97.21 | 97.57 |
| DCNN | 99.23 | 99.35 | 98.56 | 99.86 |
DCNN和DNN方法都是通过反向传播不断地减小真实标签与预测标签之间的损失差异,进而提高模型的识别准确率。所以,为更直观地观察DCNN和DNN的识别准确率和损失函数在迭代过程的变化,随机选择0HP负载数据集进行展示,如下图所示

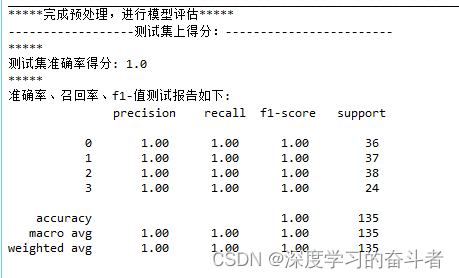
DCNN的F1报告:









![[FREERTOS] 任务的创建、删除、调度与状态](https://img-blog.csdnimg.cn/1c12348ac5f14c5aa53fceb3184c534d.png)