文章目录
- 分布式数据库是如何演进的?
- 数据库+与分布式中间件有什么区别?
- 如何处理分布式事务,提供外部一致性?
- 如何处理分布式SQL?
- 如何实现分布式一致性?
- 数据库+更适合金融政企的未来
这些年大家都在谈分布式数据库,各大企业也纷纷开始做数据库的分布式改造。那么所谓的分布式数据库是什么?采用什么架构,优势在哪?为什么越来越多企业选择它?我们不妨一起来深入了解下。
分布式数据库是如何演进的?
回顾分布式数据库的演进历程,我们可以大致概括为三个发展阶段:应用分库分表做垂直拆分、分布式中间件、分布式数据库。每个阶段都呈现出了不同的特点:
应用分库分表做垂直拆分本质上是应用侧的改造,和数据库本身没有太大关系。
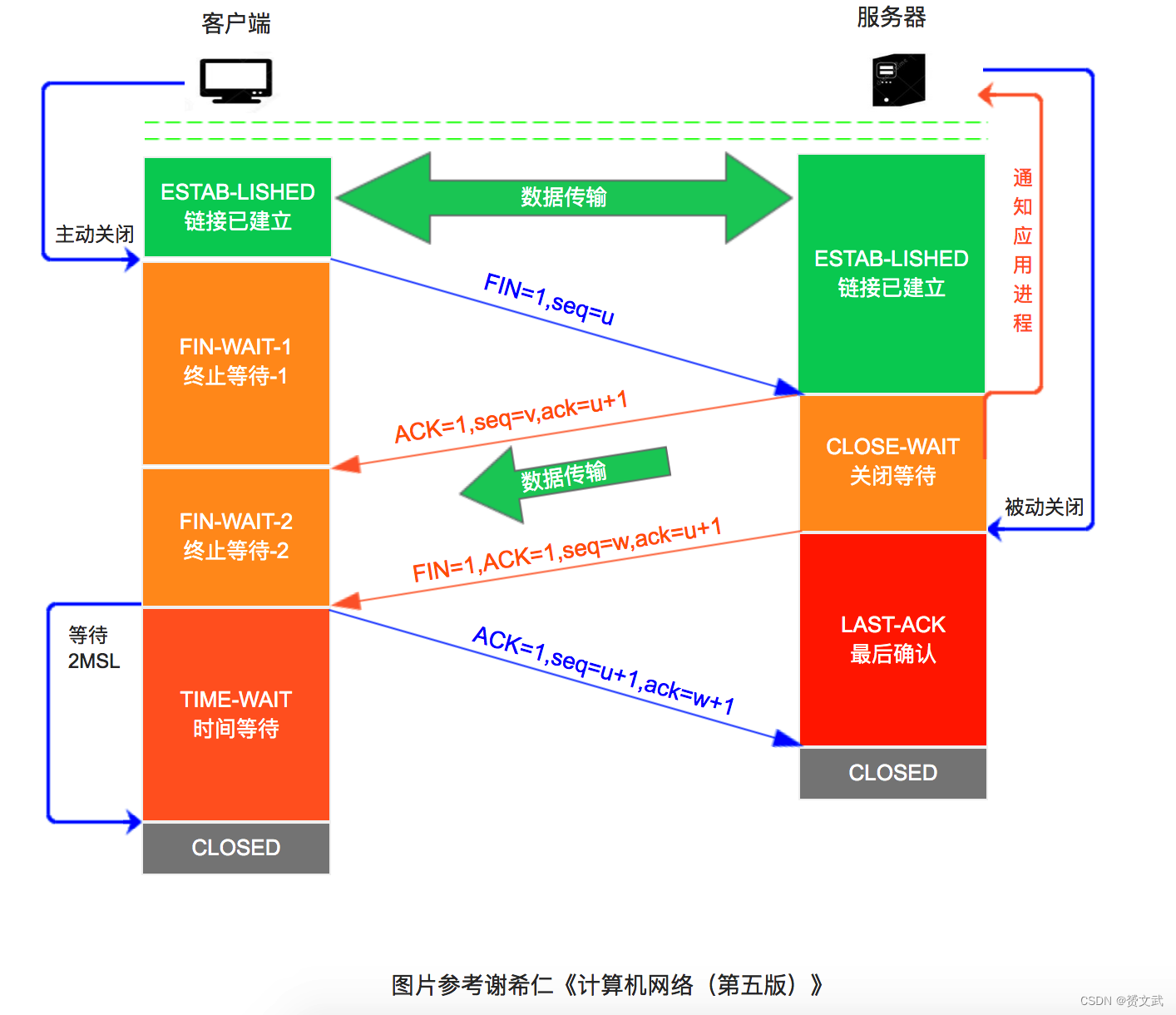
在分布式中间件阶段,分布式数据库本质上是由两部分组成的,上层是分布式中间件,底层再搭载开源MySQL或PG单机内核。这种方式因为使用了比较成熟的内核,所以生态友好、成本较低,比较容易实现,不过缺点也显而易见,比如功能降级、分布式事务处理能力较差,最重要的是,因为使用的是开源产品的内核,数据库会始终受制于开源代码修改、专利、发行方式等很多方面的风险,这种形式显然已经无法满足当前国内金融、政企客户的需求。
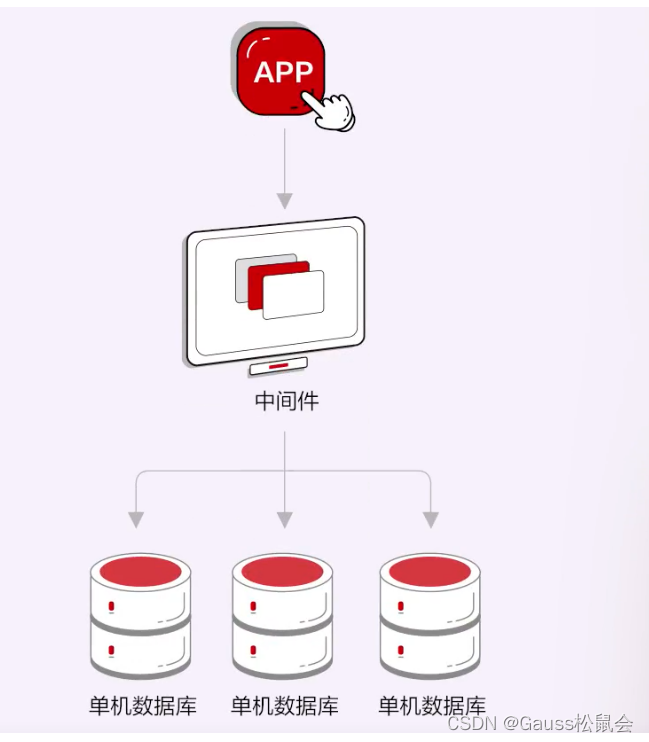
到了分布式数据库阶段,主要呈现出两种形态。一种是基于分布式存储实现的分布式数据库,这种形态先有分布式存储,再叠加数据库能力,我们习惯把它称为“分布式+”。
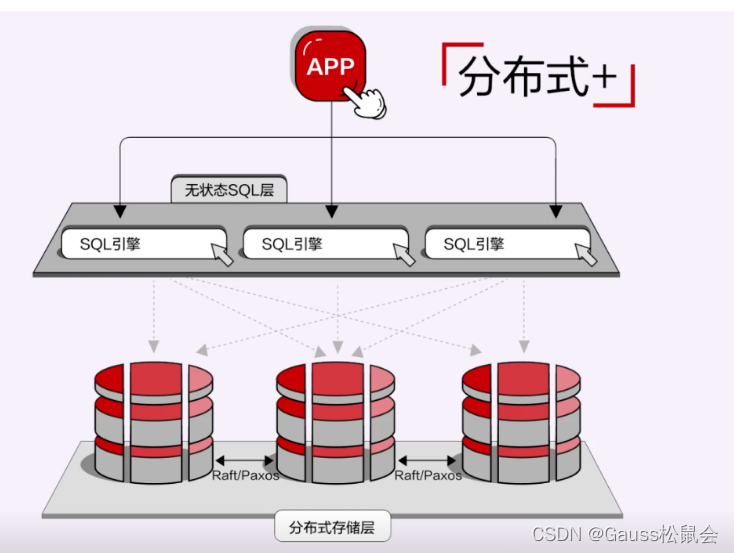
这种架构在分布式比较擅长的领域,更容易形成它的技术竞争力。什么是分布式擅长的领域呢?
比如说像扩展性、及时的扩展性,大规模运维的灵活性,比如扩缩容。在这方面,分布式+的天花板会更少,因为它一开始就是按照分布式存储来设计的。这里面有意思的一点是,这跟架构本身没有太大关系,我们看到,今年所有的在国内的分布式+的厂商都有一个共同特点,就是在整个存储引擎的设计上跟今天我们认知的,不管是MySQL还是PG,都不一样。它不是一个类似于B-TREE的这样一种结构,而通常是基于LSM-Tree存储引擎,数据写内存,然后批量写持久化的这样一种方式。
这是因为这些分布式+的厂商,他们的所有技术体系都来源于Google,而Google最早做的第一款产品就是分布式存储,叫Big Table,Big Table本身就是基于LSM-Tree的,这是一个历史传统。这就是为什么LSM-Tree跟分布式+本身没有必然关系,但是今天我们看到国内所有走分布式+路线的厂商,都使用的是LSM-Tree。
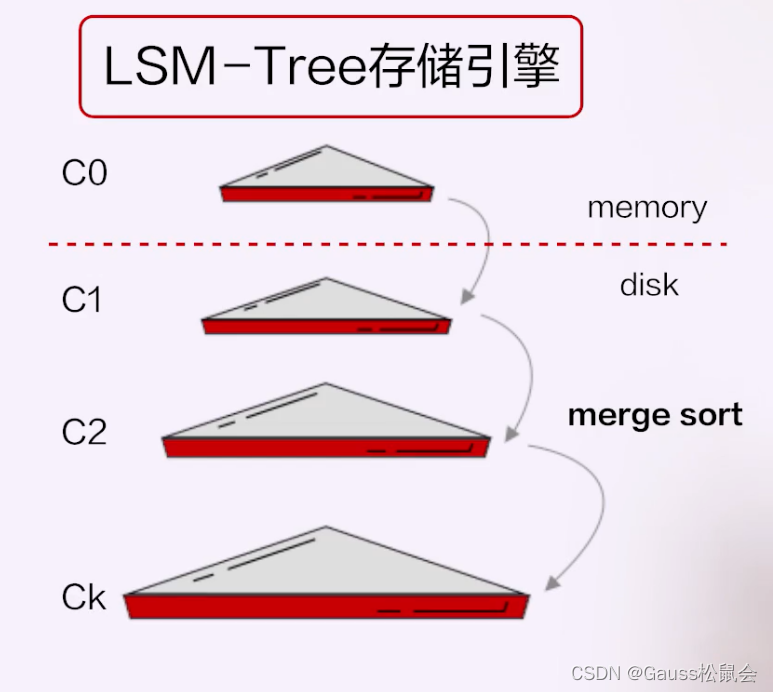
LSM-Tree有它的优点,比如主备之间的异构性有天生的优势,但也有一个非常大的缺点,就是对于场景的普遍适用性。它比较适合于写密集的场景,有大量写入插入,比如我的订单、流水化的订单,但不太适合状态类的业务,有大量的读和写,要去更新状态。而且它把随机写转为顺序写,在做compaction也就是内存和持久化存储数据合并时也会有空间放大和性能抖动问题,所以它整个场景的适用性比B-Tree要低。
这个阶段的另外一种形态,就是基于分布式数据库理论实现的原生分布式数据库,与“分布式+”正好相反,它是先有TP单机数据库引擎,再叠加分布式能力,我们一般称之为“数据库+”,华为云GaussDB分布式数据库就是这种形态的典型代表。
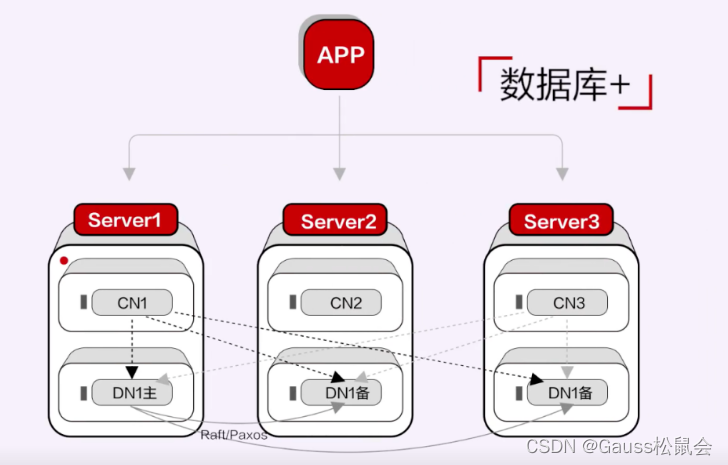
这种形态不存在空间放大和性能抖动的问题,而且更容易在数据库本身所擅长的领域发挥优势,比如说性能、复杂SQL处理能力、企业级能力。同时,因为金融政企客户在使用分布式技术之前,往往已经有分库分表、使用分布式中间件产品的经验,所以对这种架构的认可度更高,学习成本也相对较低,因此这种形态也是国内当前被采用较多的一种。
数据库+与分布式中间件有什么区别?
数据库+和分布式中间件,这两种形式从架构上来看是非常相似的,分布式中间件上面是一个代理层,下面有很多单机数据库。我们可以这么来看,就像是天平的两端,一端在0,一端在1,里面有三个非常大的差别。
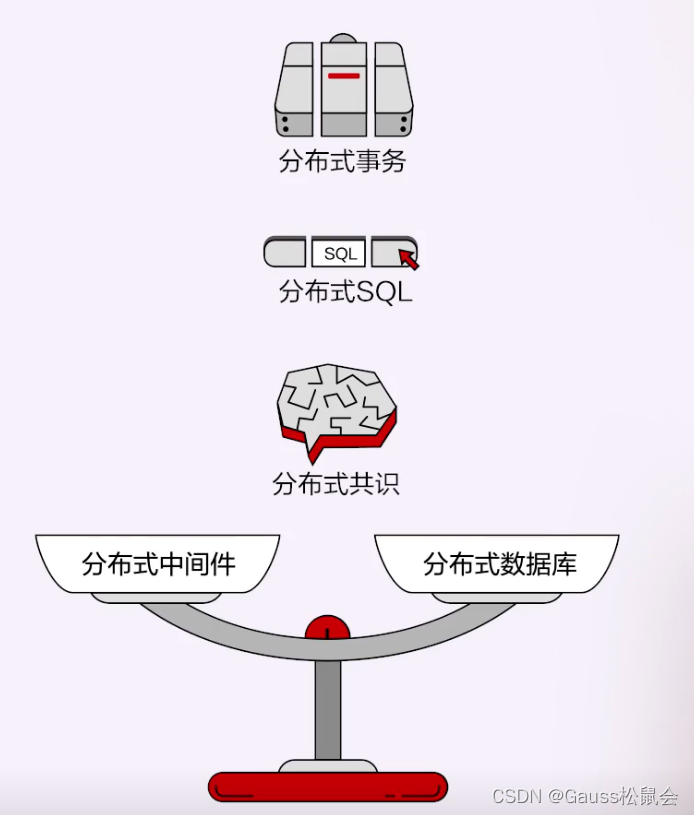
如何处理分布式事务,提供外部一致性?
分布式中间件通常是基于XA来实现数据一致性,但XA本身是不能实现外部一致性的,一般只支持最终一致性,而数据库+的分布式数据库可以基于内置全局授时来实现全局一致性读,从而支持外部一致性。
如何处理分布式SQL?
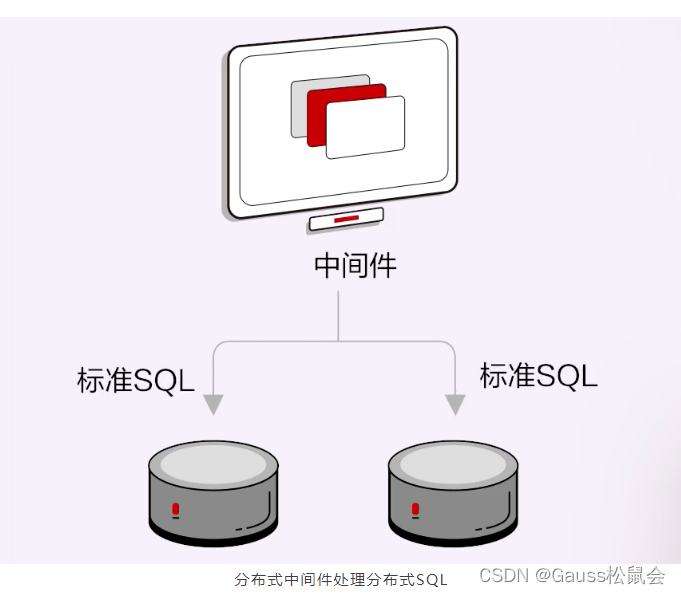
分布式中间件是把数据库作为黑盒,数据节点之间只能通过SQL的形式传递,是标准的SQL。
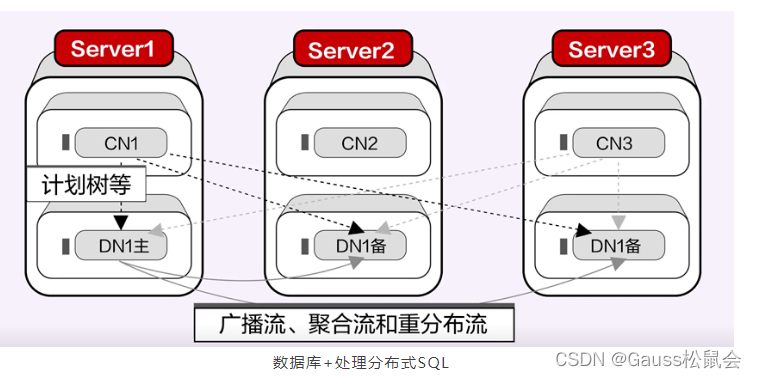
而数据库+的代理层和数据节点是一个数据库的不同部分,互相之间可以传递更加内部的东西,比如计划树,不同的数据节点之间也不需要代理节点,可以直接传递。
如何实现分布式一致性?
分布式中间件通常是基于传统主备架构,使用半同步、最大保护等模型来实现分布式一致性,不过这种形式下一致性和高可用是没有办法同时兼顾到的,而数据库+是基于原生分布式共识而打造,比如Quorum、Paxos,Raft,可以实现底层无损容灾,同时满足一致性和高可用性。
对于数据库厂商而言,如果以上三个问题全都做到了,那我们可以说它是分布式数据库,如果三者都无法做到,我们一般说它是分布式中间件,如果说只做到了其中的一部分,那就很难下定义究竟是分布式中间件还是分布式数据库,但可以从这三方面去衡量它的天平更倾向哪一边。
数据库+更适合金融政企的未来
出现三种不同的技术路线,本质上是团队的人员能力模型、特质和最初要解决的问题决定了最终走向哪条路线。技术没有绝对的好与坏,只有是不是合适。今天我们看到很多金融政企客户都在提分布式数据库,从0到1的突破可能是由于政策性的突破,因为国产化,但从1到N的突破,是需要产品本身竞争力的突破。
我们发现,在这个阶段,客户不再关心分布式,客户关心什么?关心的是数据库本身。不管叫什么技术,能不能满足需求,能不能提供足够的性能、足够的扩展性、足够的高可用,能不能支撑复杂的业务场景,我们的观点是,最终这个行业会回归到他的本源,分布式数据库的本源是数据库,不管叫分布式+还是数据库+,最终给客户的核心价值仍然是数据库。因此,数据库+更能匹配金融政企未来长期的发展。
GaussDB融合了华为在数据库领域15年多的战略投入,是基于分布式理论打造的行业领先的国产原生分布式关系型数据库,采用行业先进的全并行分布式架构,有应对海量并发事务处理与复杂查询混合负载的能力;还有同城跨AZ、两地三中心、数据0丢失等多种高可用方案,出色的金融级高可用商用能力全方面满足金融级监管要求。
现在,GaussDB已经在金融行业积累了非常丰富的实践经验,历经华为终端云、华为流程IT、全球TOP银行、运营商等各种严苛场景的考验,不仅成功助力邮储银行新一代个人业务分布式核心系统全面投产上线,为全行6.5亿个人客户、4万多个网点提供日均20亿笔、峰值6.7万笔/秒的交易处理能力,还通过一系列技术创新,轻松支撑华为流程IT ERP系统5倍业务压力下性能保持线性,实现业务效率的10倍提升,是企业数字化转型、核心数据上云、分布式改造的信赖之选。






![[FREERTOS] 任务的创建、删除、调度与状态](https://img-blog.csdnimg.cn/1c12348ac5f14c5aa53fceb3184c534d.png)
![浅谈[Linux搭建GitLab私有仓库,并内网穿透实现公网访问]](https://img-blog.csdnimg.cn/img_convert/4685d370be049c181d6cb66395d552c0.png)