Pytorch是机器学习里面常用的框架之一,我们在学习机器学习之前最好需要学习如何使用这个框架对我们将要使用的数据数据进行预处理操作。
如果我们想要学习好pytorch里面的方法,我们需要常去用一下dir()和help()函数,它们一个会帮我们查看某个包里面的内容,一个会帮我们返回某项功能的作用。
目录
数据导入
Dataset
Dataloader
数据预处理
Totensor
Normalize
Resize
Compose
RandomCrop
数据集下载
数据导入
下面我们来看看如何用Pytorch导入数据:
Pytorch导入数据的主要是两个类,它们分别是Dataset和Dataloader。而且他们都是位于torch.utils.data下面的模块。那为什么需要这两个模块呢?
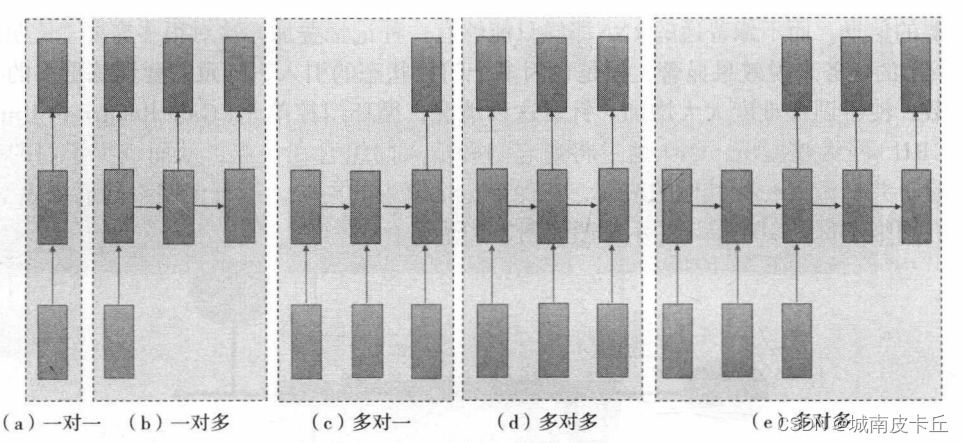
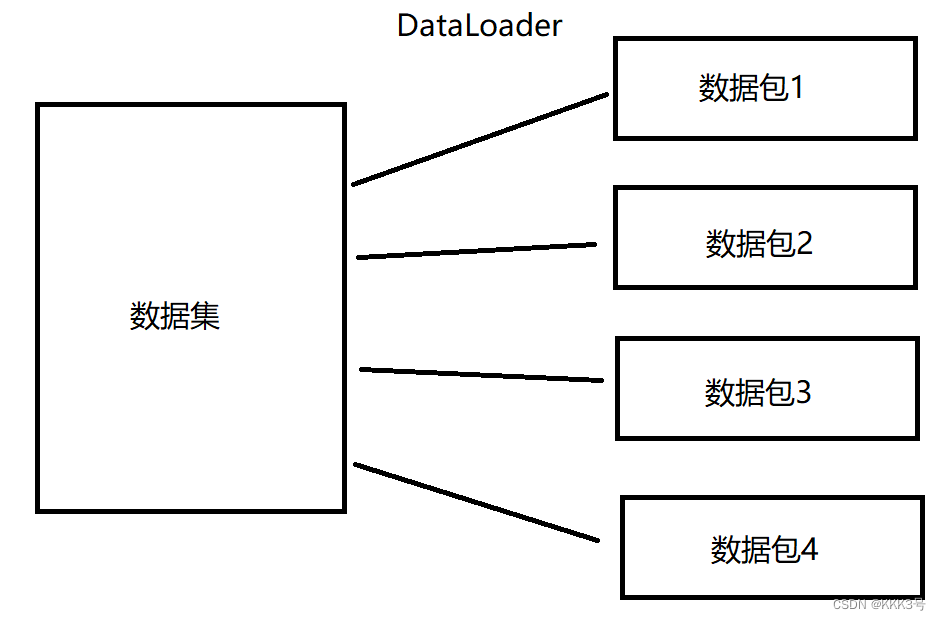
为了解决这个问题,我们需要知道数据是怎么导入到我们的模型的,而它们的作用如下图所示:
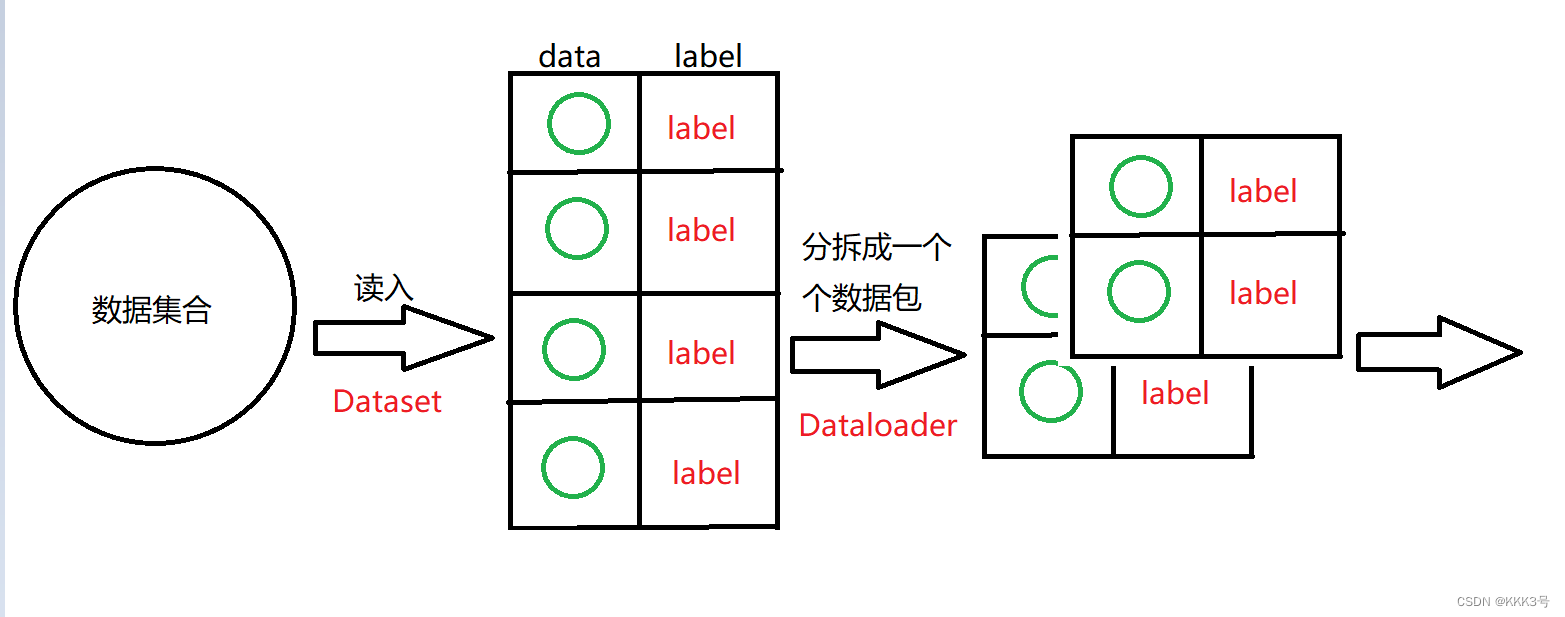
Dataset的作用是将数据从数据集中提取出来,然后为每一个数据贴上标签label
Dataloader的作用是将Dataset里面的数据按某个特定的大小分为一个个数据包,再提供给后面的网络。
Dataset
我们所有自己写的要读取数据集合的类都要继承自这个torch里面提供的父类Dataset。并且需要重写方法__getitem__。
下面我就按照小土堆的方法和他提供的数据集来记录读取一个数据集合的过程:
假如我有一个存满蚂蚁相片的文件夹,并且这个文件夹名字就是这些数据的标签。
我们首先要知道,我们要想获取这些数据集合,需要定位到该文件夹的位置。而要想获取一张图片,则需要定位到该图片的位置。我们决定将这些获取单张图片的路径的过程都写到__init__方法里面(它就类似于C++里面的构造函数,一调用这个类就会调研该方法)
import os
import torch
from torch.utils.data import Dataset
from PIL import Image
class Mydate(Dataset):
def __init__(self, Root_path, Image_Label):
self.root_path = Root_path
# 获取图片集文件夹路径
self.Image_Label = Image_Label
# 获取这些图片的标签,就是它们的文件夹名
self.image_set_name = os.listdir(self.root_path)
# 获取所有图片的名字
def __getitem__(self, item):
self.image_set_single_path = self.image_set_name[item]
# 获取单张图片的名字
self.image_set_path = os.path.join(self.root_path, self.image_set_single_path)
# 获取单张图片的完整路径
img = Image.open(self.image_set_path)
# 获取单张图片
label = self.Image_Label
# 获取单张图片对应的标签
return img, label
# 返回它们
MyDataset = Mydate('D:\\Python_Code\\Pytorch\\ants_data', 'ants_data')
img ,label = MyDataset[0]
img.show()首先我们写的初始化函数的主要目的是获取一个列表,其中os.listdir就是读取一个文件夹里面的所有文件名,这个列表里存储到是我们的图片数据的名称/路径,这一步可能已经会再一些H5文件里面封装好了。接下来就是重写__getitem__方法,这个方法是读取数据集里面的单个的单个数据。我们创建一个变量来存储单个图片的名字,并且将单个图片的名字传递过去,而单个图片就存储在之前的图片集里,所以我们需要取到下标为item的数据,这个过程就类似于一个for循环的重复获取过程。然后利用os里面的合并路径函数获取单个图片的路径,最后再返回单个图片和单个图片对应的标签即可。
Dataloader
Dataloader的功能是当我们将从Dataset来的数据集合发送过去时,它会负责将我们的数据集进行某种处理,例如划分,打乱等。
说到Dataloader是起到处理数据的作用,那就不得不来看它的几个参数的功能。首先我们需要知道对于数据的一些概念:
- 当我们称将对于Dataset而言的整个数据集反复训练了n遍,那么我们给对于Dataset而言的次数一个定义:epoch,那么epoch=n。
- 而假如Dataloader将来自Dataset的数据集又划分m个小数据集,那么我们称划分出来的小数据集的个数为Batch_size,而Batch_size=m。
接下来就可以来看Dataloader里面常用的几个参数了:
Dataset:这个是我们要给它的dataset对象
batch_size:这个就是设置每个小数据集里有多少个数据
shuffle:这个是设置每个epoch是否将数据打乱,True则为打乱
drop_last:这个设置当我们epoch/batch_size有余数时这个余数的保留问题,如果为True则舍弃
num_works:这个表示使用到的进程个数,默认0(主进程)
了解完各个参数之后,我们就需要具体来确定怎么用Pytorch来实现Dataloader了。首先就是不可避免的导包操作,我们需要从torch.utils.data这个工具箱里面拿出DataLoader这个工具。下面这里的data_train是一个数据集,我们可以理解为这个数据集是调用了基于上面Dataset而封装方法而得到的的多个数据集合。然后我们就可以将这个数据集传入到DataLoader这个工具里面,设置好一些Batch_size、shuffle、num_works和drop_last等这些参数。然后它就会返回给我们一个已经被划分好一块一块小包的数据包集合。
import torchvision
from torch.utils.data import DataLoader
tools = torchvision.transforms.Compose([torchvision.transforms.Resize([255,255])]
)
data_train = torchvision.datasets.MNIST('./dataset', transform=tools ,train=True, download=True)
data_loader = DataLoader(dataset=data_train, batch_size=5, shuffle=True, num_workers=0, drop_last=True)
数据预处理
在将数据导入之后,我们还需要将数据进行一定程度上的预处理,而我们常用于对数据进行预处理的工具包就是torchvision下面的transforms包。transforms包就类似于一个工具箱,我们需要经常使用到它里面的很多方法:如resize、totensor等对数据进行预处理。

然而值得注意的是,我们使用这里面的方法是不是直接将图片传递到transforms里面的方法,而是根据transforms里面的方法作为模板先创建出一个具体的工具。然后在使用这个我们创建出来的工具来对数据进行预处理。
Totensor
如我们要想将一张图片转换为Tensor数据类型,就需要下面的操作:
# 获取图片
img = Image.open("D:\\Python_Code\\Pytorch\\ants_data\\0013035.jpg")
# 实例化工具
tool = transforms.ToTensor()
# 获取Tensor
pic_tensor = tool(img)
print(pic_tensor)而我们在使用神经网络时如果有图片类型经常会需要将图片类型转换为Tensor的数据类型,不仅是因为Tensor数据类型可以抽象出图片的特征,还是因为它可以封装了很多神经网络有关的方法属性等。
Normalize
这个方法用于将我们得到的图片的Tensor里面的数据进行归一化处理,归一化处理的作用是将数据都限定在一个范围内(常用是[-1,1]),这样就能避免一些奇奇怪怪的数据对我们训练模型是带来的问题,并且能够在我们求梯度是加快速度。但是经过归一化处理出来的图片和我们平常的习惯的图片不同,我们要想转换回习惯人眼的图片需要进行反归一化。
下面是我们进行归一化的常用方式,以RGB格式为例:
# 获取图片
img = Image.open("D:\\Python_Code\\Pytorch\\ants_data\\0013035.jpg")
# 实例化工具
tool_Totensor = transforms.ToTensor()
# 获取Tensor
pic_tensor = tool_Totensor(img)
# 归一化工具实例化
tool_Norm = transforms.Normalize([0.5,0.5,0.5],[0.5,0.5,0.5])
# 传递参数,具体进行归一化
pic_ret = tool_Norm(pic_tensor)其中我们创建用于归一化的工具tool_Norm时,是直接将均值和标准差等参数传递给Normalize方法以创建适合的模板的。其中模板里面里面的第一个列表的三个数字是三个通道对应的的平均值,而第二个列表里面的三个数字是三个通道对应的标准差。
Resize
Resize是用于对图片数据进行大小调整的工具,因为我们可能数据集里面的图片都不是统一大小即像素点数量是不同的,如果我们想将大小进行统一处理可以使用这个工具。创建工具时需要向模板传入目标的图片大小,而且是以元组的形式。而且缩放后函数还是会返回一个图片。当Risize输入两个参数时,输出图片的高和宽的像素点数量会按照设定成我们设定的值。而只输入一个参数时,这个参数代表我们最短的边像素点数量。
# 获取图片
img = Image.open("D:\\Python_Code\\Pytorch\\ants_data\\0013035.jpg")
# 实例化工具,大小调整为960x960
tool_resize = transforms.Resize((960,960))
# 图片缩放
img_ret = tool_resize(img)
img_ret.show()Compose
Compose的作用是将多个我们制作出来的tramsforms工具合并成一个工具的工具,也就是多个功能封装成一个功能。制作Compose工具时需要我们输入一个列表,并且该列表里面的每一个参数就要是对应着一种transforms实例化工具。
# 获取图片
img = Image.open("D:\\Python_Code\\Pytorch\\ants_data\\0013035.jpg")
# 图片大小设置
tool_resize = transforms.Resize((512,512))
# 图片转化成Tensor
tool_tensor = transforms.ToTensor()
# 功能结合
Compose = transforms.Compose([tool_resize, tool_tensor])
ret = Compose(img)RandomCrop
这个工具用于对我们的图片进行随机剪切,例如我们有一张960x960大小的图片,那么我们可以设置随即剪切的大小为480x480,那么使用这个方法后就会随机在我们的图片基础上剪下一片480x480大小的区域返回。例如下面就是剪切的例子:
# 获取图片
img = Image.open("D:\\Python_Code\\Pytorch\\ants_data\\0013035.jpg")
# 图片随机剪切大小设置
tool_cut = transforms.RandomCrop([480,480])
# 图片剪切
ret = tool_cut(img)
# 图片展示
ret.show()数据集下载
前面我们说的很多都是关于单张图片的预处理,但是我们很少涉及到整个数据集的处理。其实Pytorch官网为我们提供了很多的数据集,我们打开torchvision — Torchvision master documentation这个网址,然后拖到下面即可看到很多的数据集:
而这些数据集下载我们需要使用到torchvision这个包。而我们下载就是直接调用torchvision下面的dataset下面的数据集的名字对应的方法,然后传入的参数常用到的有几个:
1、数据存储的位置,给定一个root地址;
2、这个数据集是否为训练所使用的数据集,true则为是;
3、是否下载,true则为是;
4、transforms的方法,传入写好的transforms方法;
import torchvision
tools = torchvision.transforms.Compose([torchvision.transforms.Resize([255,255])]
)
data_train = torchvision.datasets.MNIST('./dataset', transform=tools ,train=True, download=True)
img,label = data_train[0]参考资料:
https://blog.csdn.net/m0_57541899/article/details/122367407
https://blog.csdn.net/qq_40107571/article/details/126634899
https://blog.csdn.net/MrR1ght/article/details/116804409
https://blog.csdn.net/wuzhongqiang/article/details/105499476
https://www.bilibili.com/video/BV1hE411t7RN?p=7&vd_source=894e8817bba11b560ad040c21e7cfceb