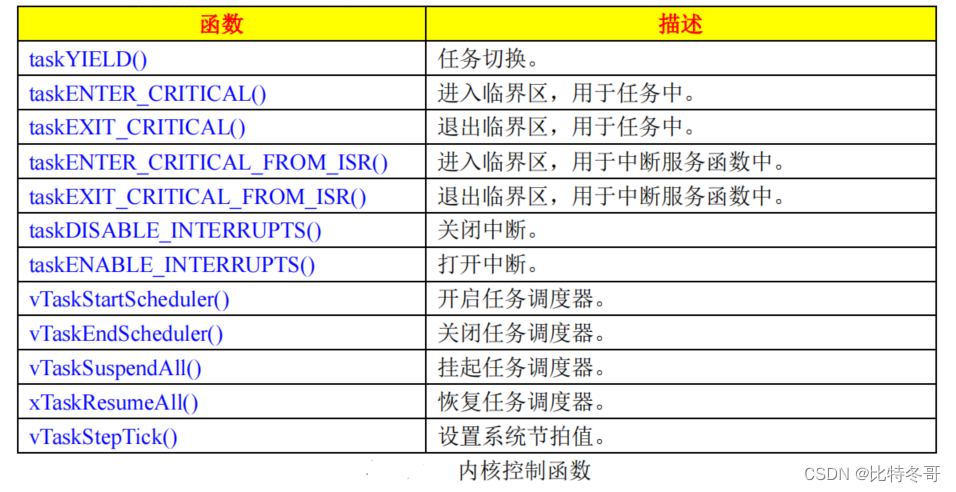
【论文阅读】3D-LaneNet
主要要做的事情就是 lane detection。这里提一下 BEV(Bird‘s Eye View) 感知算法,为了将 2D 图像映射到 3D 空间中,能够更准确的检测物体位置,需要 BEV 感知的结果。后续还会继续了解这方面内容。
文章提出的方法就是在图片上预测车道线。
这个方法应该是第一个非启发式的方法,是直接通过图像(单目深度估计)去学习的方法。而且它是一种基于 anchor 做匹配的方法。
首先基于”平地面假设“【假设1】,即假设当前的路面切平面为路面,可以更方便做映射。
在相机和地面的坐标(系)转换中,可以把相机的外参当作是三个——距离地面的垂直高度 H_cam,竖直和水平方向旋转角(pitch,roll)。
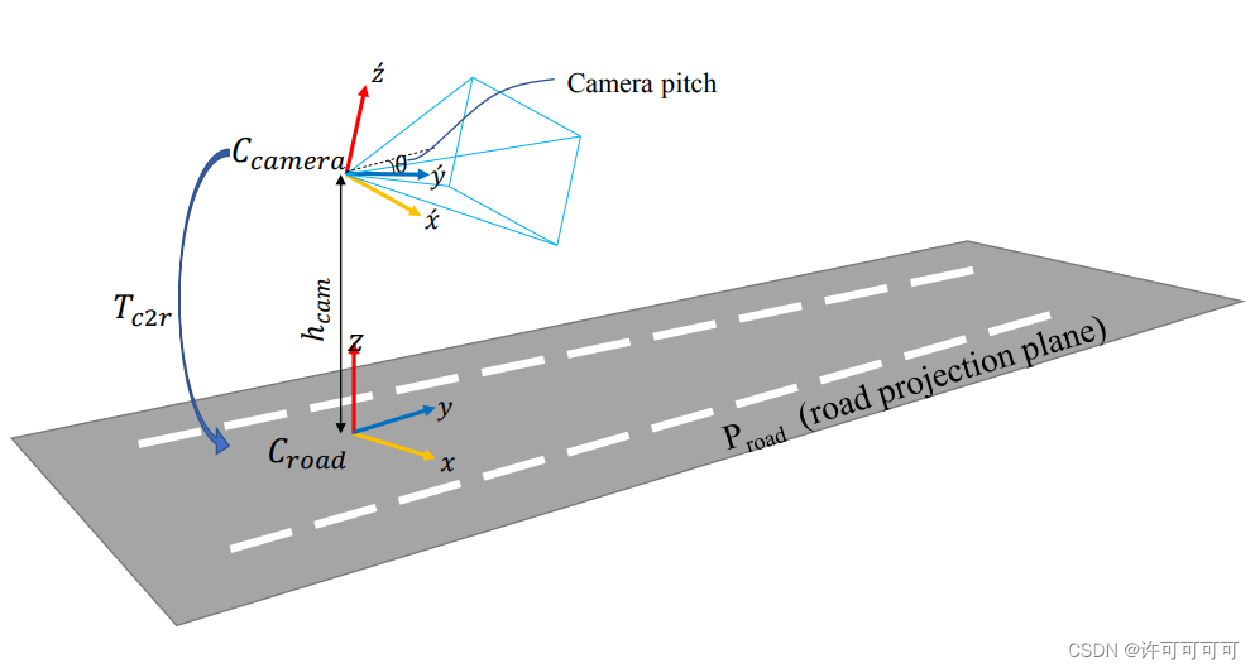
在这篇文章中,假设 roll 角的角度为零【假设2】,只用到了pitch角度。
已知相机高度 h 和 pitch 角度,可以求出相机坐标系 C_cam 向路面坐标系 C_road 的转换 T_c2r。这里用到的方法叫做 IPM(Inverse perspective mapping),逆透视变换。
看一下整体的网络框架:
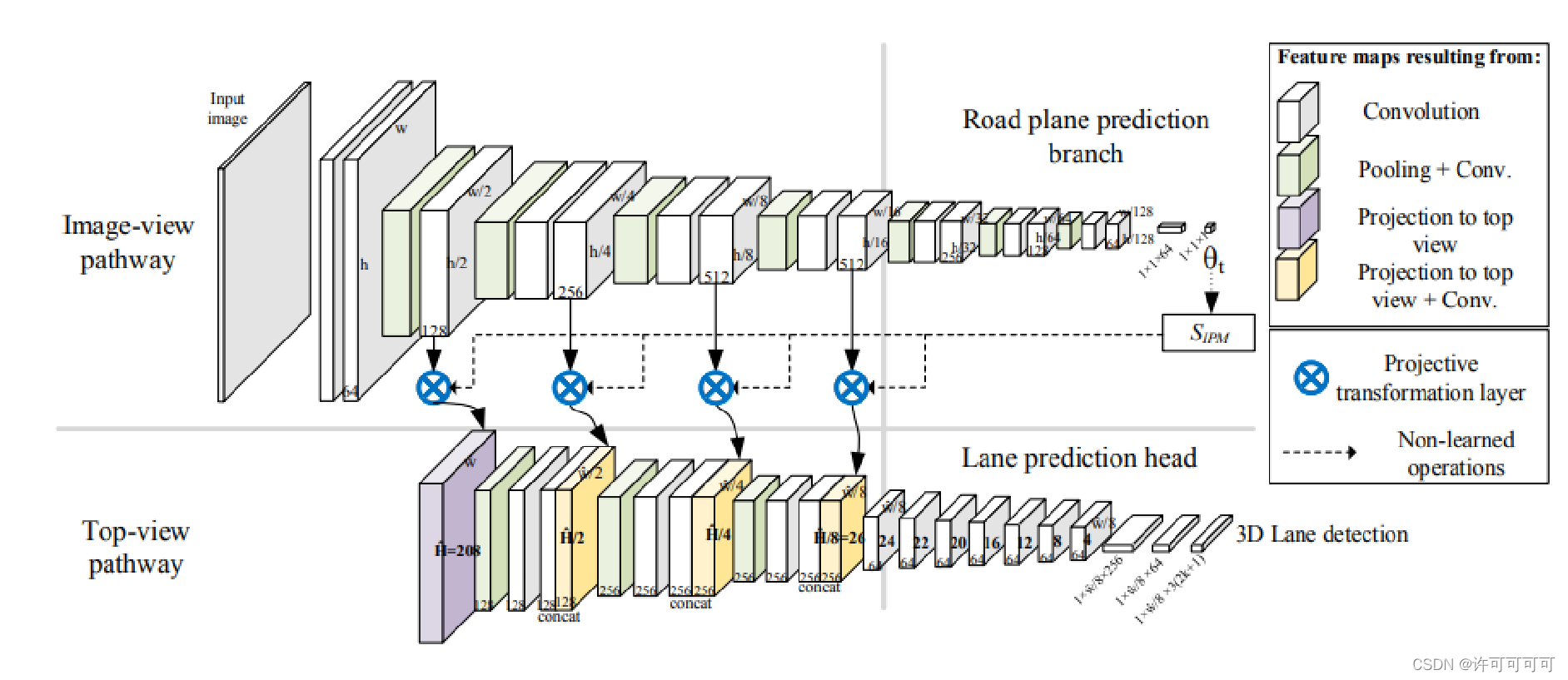
网络是双通道的结构。
-
image-view 通道,加入了 H_cam 和 pitch 去提取 image 特征,同时最后学习到 h 和 pitch 做逆透视变换。
-
top-view 通道,这个视图是虚拟的,用来提取 BEV 空间的特征,最后进行车道线的预测。
-
连接两个通道的是 Projective transformation layer,将 image feature map 通过 IPM 转换成 BEV 空间俯视图之后,通道数不变直接和 top-view feature map 做 concate。
然后文章还用了一种基于 anchor 的匹配的方法,作为检测子。
首先,因为 车道线是在 top-view 视图下预测的,沿 x 方向均匀划分一些anchors。anchor 和 gt(ground truth)车道线要进行匹配。在这里,我们要预测的车道线 gt 一共有两种,一种是 lane centerlines(车道中心线),另一种是 lane delimiter(车道边界线)。
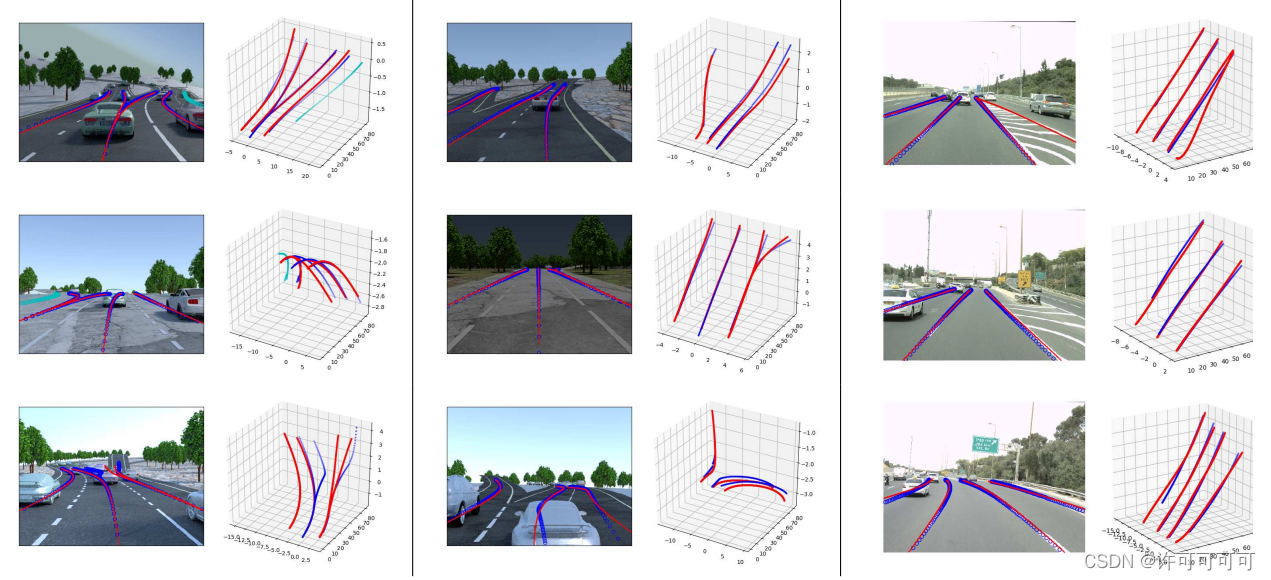
上图中,左边和中间两列是 centerlines 的预测,右边一列是 delimiter 的预测。
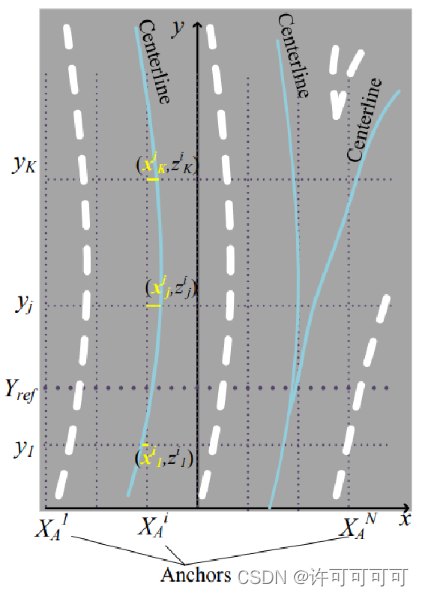
然后,对于 y 方向的 Y_ref,求出 gt 与 Y_ref 的交点,将每个 gt 归属于距其最近(交点的 x 方向距离最小)的anchor。使用非极大值抑制的方法。
这里假设 gt 与 Y_ref 是会有交点的【假设3】,这会导致过短的车道线无法被检测到。
对于每个anchor,记录它匹配到的 gt。delimiter 不会相交,但是centerlines 可能会。每个 anchor 最多会匹配到两个 centerlines (即当两条 centerlines 在 Y_ref 上相交时,如图右侧)。因此对每个 anchor 需要记录三个信息*(c1,c2,d)*,其中,匹配到的左边的 gt 作为 c1。
如下图所示:
最终车道线预测的输出维度是: 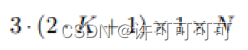
3 是指有三个预测的 type(c1,c2,d);每个anchor 有 K 个点,对于每个点,预测其*(x 横向偏移,z 深度)*;还有一个当前 gt 应该匹配到该 anchor 上的置信度 p^。anchors 的个数为 N。
最后,看一下损失函数的设计:
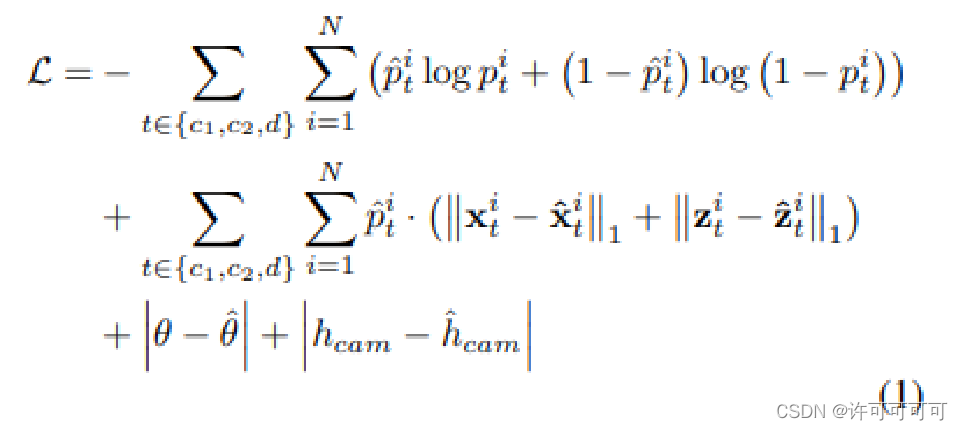
第一项是分类置信度的 CE 损失,第二项是横向偏移 x^ 和深度 z^ 的 L1 回归损失。后两项是 image-view 预测的相机外参 H_cam 和 pitch 角度的 L1 损失。
训练的流程就是线通过相机外参和已知的相机内参,包括像素和物理距离缩放尺度等计算出 C_road 坐标系,再将 gt 车道线转换到 C_road 的平面上。最后对其最近的 anchor 进行匹配。
总的来说,这篇文章提出的车道线检测的假设条件还是过于理想,泛化性能还有待进一步的提升。




![[Linux]环境变量](https://img-blog.csdnimg.cn/94dbb11cf7c642f39cd0254a90275532.png)