目标:了解 LMM 背后的主要思想
▪️ Neural Machine Translation by Jointly Learning to Align and Translate
▪️ Attention Is All You Need
▪️ BERT
▪️ Improving Language Understanding by Generative Pre-Training
▪️ BART
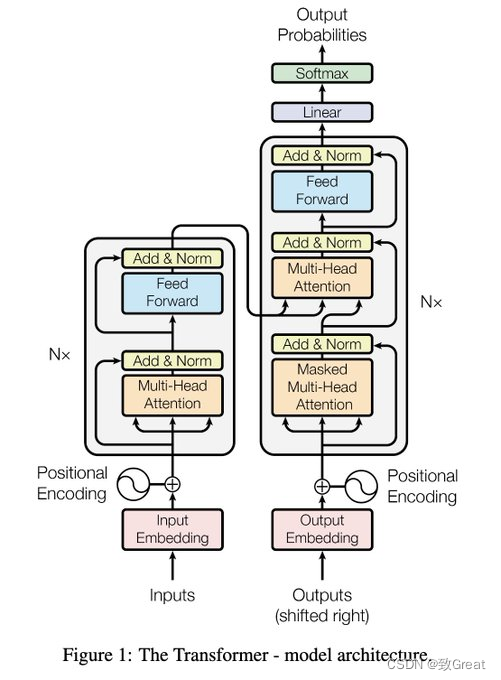
- Neural Machine Translation by Jointly Learning to Align and Translate

论文链接:https://arxiv.org/pdf/1409.0473.pdf
提出Encoder-Decoder的经典seq2seq结构,对文本生成,文本摘要、翻译等生成式人物起到重要影响
- Attention Is All You Need
论文链接:https://arxiv.org/pdf/1706.03762.pdf
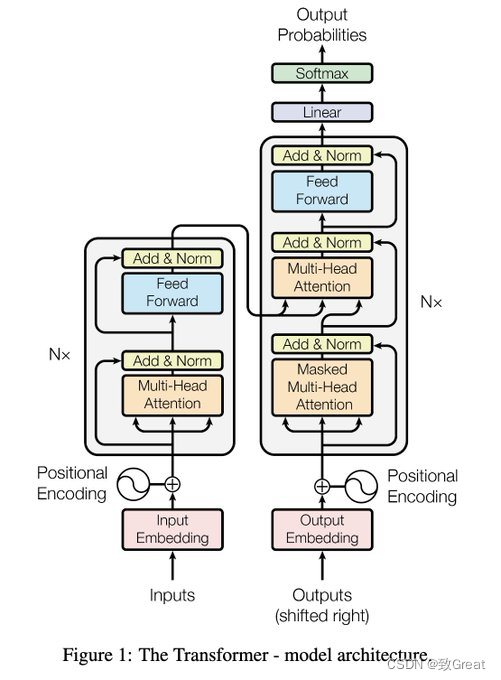
前两年火爆的论文:transformer
- BERT: Pre-training of Deep Bidirectional Transformers for Language

预训练模型经典之作
论文链接:https://arxiv.org/pdf/1810.04805.pdf
- Improving Language Understanding By Generative Pre-Training
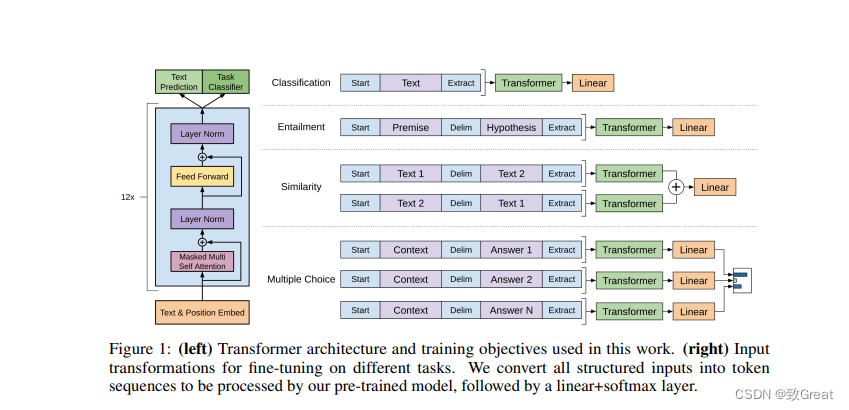
本论文探索一种基于半监督解决语言理解任务方法,使用无监督预训练和监督微调。目标是从大量未标注语料库学习一种普遍的表征,不要求目标任务与未标注语料库在相同领域。
论文链接:https://gwern.net/doc/www/s3-us-west-2.amazonaws.com/d73fdc5ffa8627bce44dcda2fc012da638ffb158.pdf
- BART: Denoising Sequence-to-Sequence Pre-training for NaturalLanguage Generation, Translation, and Comprehension
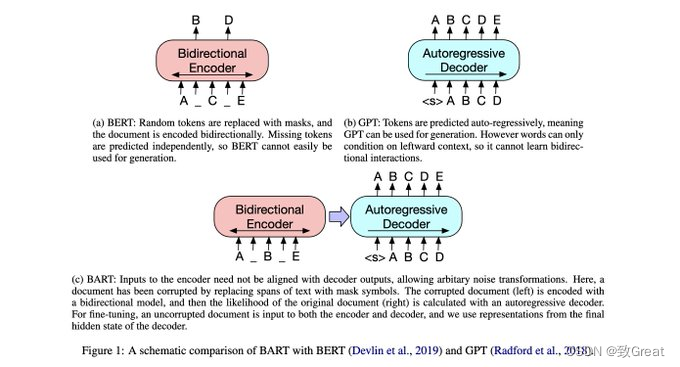
BART:Bidirectional and Auto-Regressive Transformers ,字面意思为双向自回归Transformer,依旧是基于Transformer改造出的模型。在GPT分走了Transformer的解码器部分,BERT分走了Transformer的编码器部分之后,BART终于将“老父亲”的所有“家产”一起打包带走。
论文链接:https://arxiv.org/pdf/1910.13461.pdf




![[Linux]环境变量](https://img-blog.csdnimg.cn/94dbb11cf7c642f39cd0254a90275532.png)