目录标题
- 为什么会有文件系统
- 磁盘的物理结构
- 磁盘的存储结构
- 磁盘的逻辑结构
- 文件系统
为什么会有文件系统
在我们的云服务器上存在着很多的文件,但并不是所有的文件都是被打开的,操作系统得管理好已经被打开的文件,那么同样的道理在磁盘中没有被打开的文件也是要被静态的管理起来的,只有将没有被打开的文件管理好才能方便我们使用者能够随时随地的打开这些文件,那么本篇文章就要带着大家学习操作系统如何管理在磁盘中没有被打开的文件,我们把管理的方法称为文件系统。这就好比生活中的快递服务,快递公司即得管理好正在路途上运输的快递以便每个快递都能到达指定位置,又得管理好已经到达服务点的快递使得每个人来取快递的时候能够快速准确的找到指定的快递。
磁盘的物理结构
首先在现在的笔记本上已经很少磁盘了,为了提高笔记本的效率以及提高笔记本内部空间的利用率,现在笔记本都用硬盘来代替了磁盘,比如说我这台电脑里面的存储外设就硬盘:
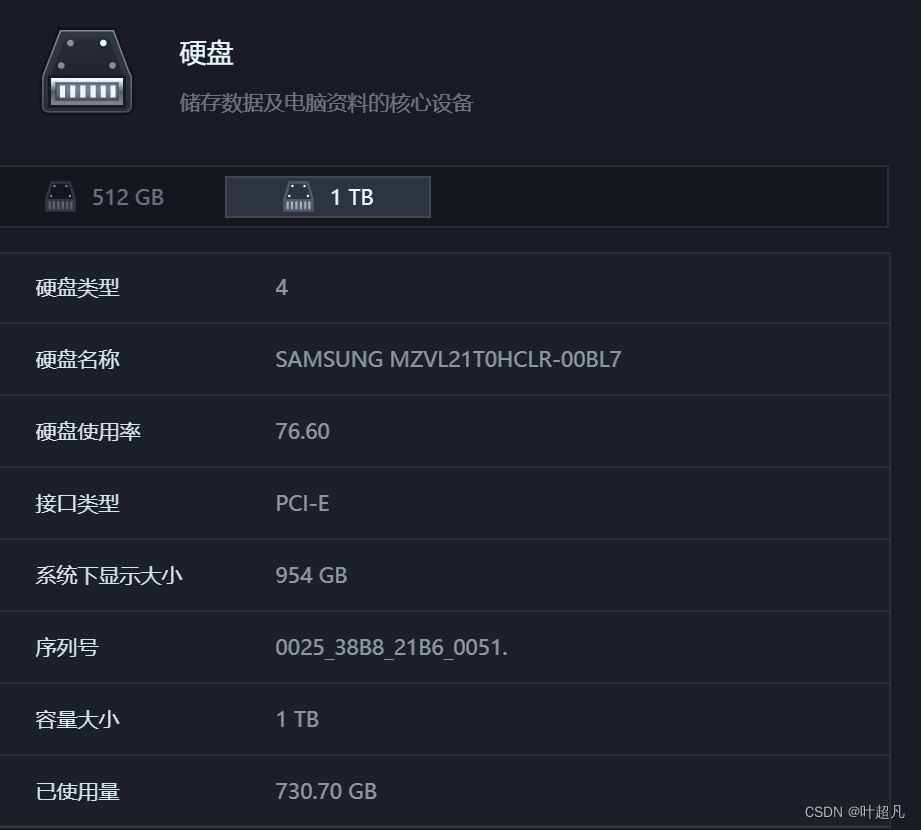
磁盘是我们计算机中的唯一的一个机械结构,机械结构加上外设就决定了磁盘的访问速度非常的慢,所以笔记本中淘汰了磁盘选择了硬盘来储存数据,但是在企业端磁盘依旧是存储的主流设备,我们来看看有关磁盘的图片

首先磁盘与我们小时候用到的光盘是有所区别的,光盘只有一面记录数据而磁盘两面都可以记录数据,我们把磁盘记录的数据的面称之为盘面,一张磁盘有两个盘面每个面都可以记录数据,并且每个盘面上都会有一个磁头,磁头不仅可以读取磁盘上的数据而且还不与盘面进行接触,因为磁盘得环境要求是非常高的在出厂之前得在无尘车间里面对磁盘进行封装来保证磁盘在运行的时候没有灰尘进而保证磁盘在运行的时候不被刮花以免数据丢失,所以磁头是不会与磁盘接触的,磁盘上有两个中心点每个中心点都是一个马达:

1号马达可以让磁盘绕着中心点快速旋转,2号马达可以让磁头绕着中心点做圆周运动,这样就可以让磁头读取到磁盘上每一个位置的数据,并且磁盘的旁边还有硬件电路,硬件电路上有磁盘专属的伺服系统

有了这两个东西我们就可以给磁盘发而进制指令使得磁盘可以定位寻找某个区域,然后从磁盘上面读取内容,磁盘并不是只有一个盘而是由多个盘组成的,比如说下面的图片:

所以磁盘要是有5个盘的话就会有10个盘面,每个盘面上都会有磁头所以5个盘就会有10个磁头来读取数据,如果一个盘面能记录4TB的内容的话那么5个盘就能记录40TB的内容,那么这就是磁盘的物理结构。
磁盘的存储结构
我们知道磁铁是分南北极的,所以我们可以将一个磁盘想象成由多个细小的磁铁组成,计算机上的数据都是0 1,而磁铁是有南北极的,并且磁铁的南北极是可以通过一些手段进行转换的,所以就可以用一小块磁铁的南极表示0,北极表示1,当计算机往磁盘中存储数据时实际上就是通过磁化技术改变一个个磁铁的南北极,读取数据时就是通过磁头来感知不同区域的磁铁南北极,然后将南北极转换成对应的0 1从而读取磁盘上的数据。磁盘有很多的盘片,每个盘片有两个面,那这里我们先来观察一个盘片的结构:
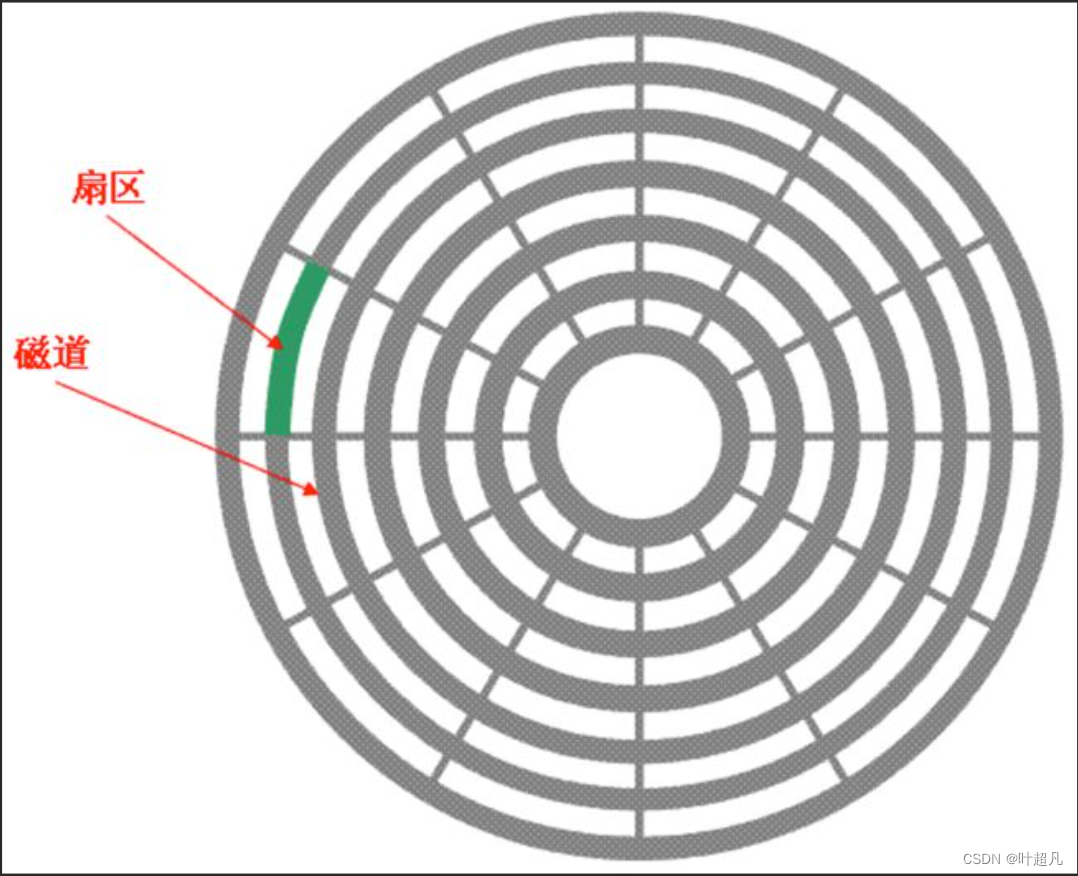 我们将一个盘片想象成由一堆连续的同心圆组成每个同心圆称之为磁道,所以一个盘片由多个磁道组成,每个磁道又会根据固定的角度分解成多个扇区,比如说上面的图片每个磁道就被分为了12个扇区,磁盘在查询地址的时候基本单位并不是bit也不是byte而是扇区,一个扇区的大小是512字节,虽然不同的磁道上的扇区长度不一样,但是这些扇区存储数据的大小都是一样的全部为512字节(当然现在的磁盘也有不一样的,这里就不考虑特殊情况),如果要查找的数据就在当前盘片上的话,那磁盘是如何找到数据对应的位置呢?方法很简单先旋转磁头找到数据所在的磁道,然后固定磁头旋转盘片找到数据所在的扇区即可。磁盘由多个盘片堆积组成每个盘片又有许多个磁道,所以不同盘片的相同半径的磁道就可以形成一个柱面:
我们将一个盘片想象成由一堆连续的同心圆组成每个同心圆称之为磁道,所以一个盘片由多个磁道组成,每个磁道又会根据固定的角度分解成多个扇区,比如说上面的图片每个磁道就被分为了12个扇区,磁盘在查询地址的时候基本单位并不是bit也不是byte而是扇区,一个扇区的大小是512字节,虽然不同的磁道上的扇区长度不一样,但是这些扇区存储数据的大小都是一样的全部为512字节(当然现在的磁盘也有不一样的,这里就不考虑特殊情况),如果要查找的数据就在当前盘片上的话,那磁盘是如何找到数据对应的位置呢?方法很简单先旋转磁头找到数据所在的磁道,然后固定磁头旋转盘片找到数据所在的扇区即可。磁盘由多个盘片堆积组成每个盘片又有许多个磁道,所以不同盘片的相同半径的磁道就可以形成一个柱面:
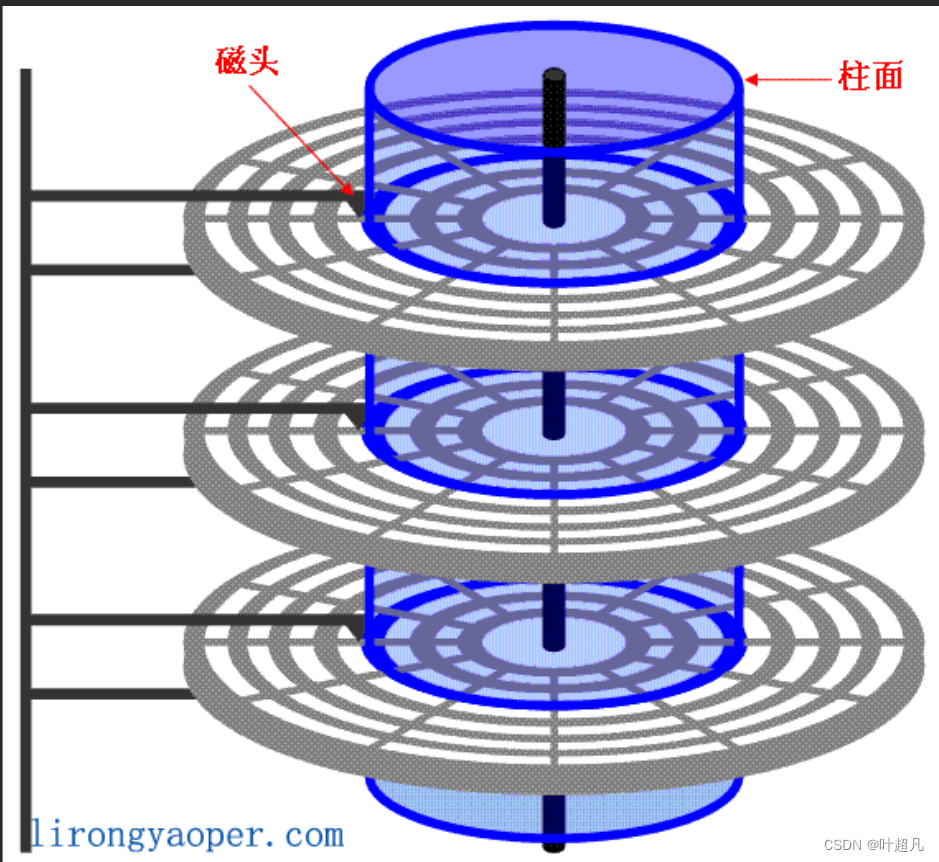
柱面就等价于磁道所以既可以说磁盘是由磁头+柱面+扇区组成,也可以说磁盘是由磁头+磁道+扇区组成。如果一个磁盘有三个盘片,那么这个磁盘就会有6个盘面6个磁头,并且磁头有一个特性就是所有磁头共进退也就是说6个磁头每个时刻所在水平位置都是一样的,所以磁盘要是想在多个盘片中查找数据的话得先旋转磁头确定数据在哪个柱面(磁道),然后在确定数据在哪个磁头(盘面),最后再旋转盘片确定数据在哪个扇区,我们把这种查找方法称为CHS定位法。
磁盘的逻辑结构
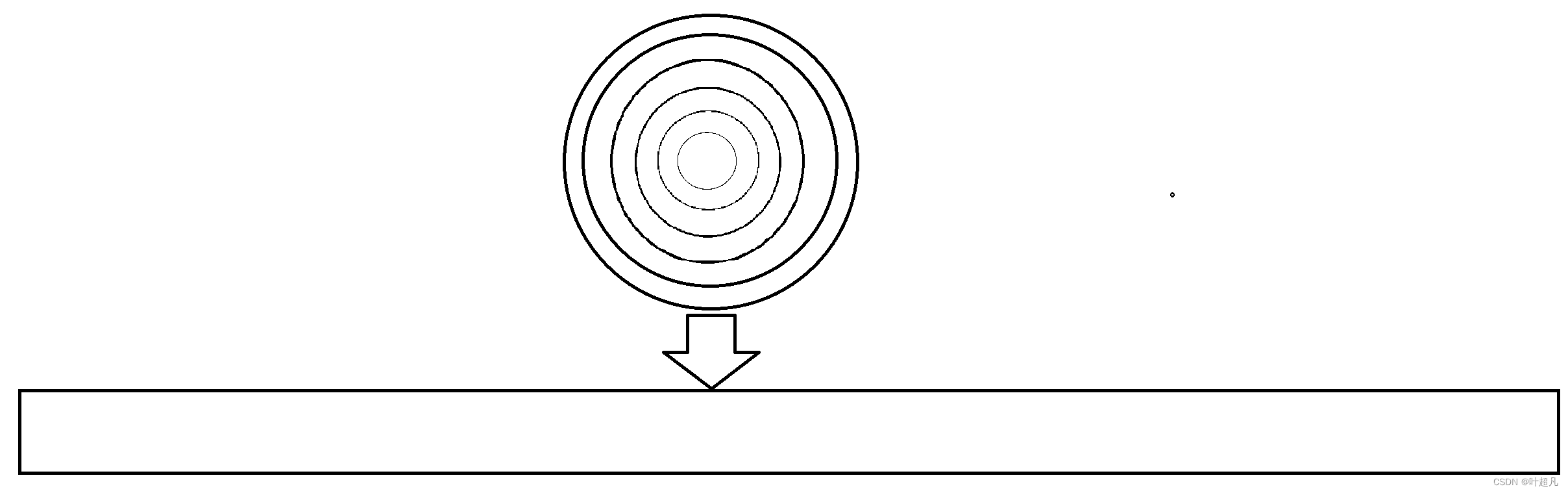
小时候大家应该都用过磁带,把磁带里面的黑色塑料拉出来可以拉成一条直线,这条直线的每个单位长度都会记载着数据,再将黑色塑料卷起来就会形成许多个同心圆,这些同心圆组合在一起就类似于上面的磁盘,比如说下面的图片

既然可以将磁盘中的黑色塑料拉成一条直线,那么也可以将磁盘想象成一条直线,直线上线性的记录着磁盘中的数据,磁盘上记录了500GB的空间,那么这个线性直线上也记录了500GB的空间
一个磁盘有两个盘片那么这个磁盘就有4个盘面,每个盘面都可以记录数据,所以我们将直线也分成4段,每段代表一个盘面的数据:

每个盘面又会有多个磁道,所以可以将上面的图片进行细分,比如说一个盘面上有三个磁道,那么图片就会变成下面这样:

每个磁道又是由多个扇区组成,所以这里可以继续往下细分:

这样每个小方格就是磁盘查找的基本单位,我们把整个磁盘从逻辑上就看成一个数组,数组的元素为512字节的扇区,所以对磁盘的管理就转换称为对数组的管理,那么这时在操作系统里面要是想查找一个扇区在哪的话是不是就只用知道这个扇区所对应的下标就可以了,在操作系统中磁盘的数据是线性排布的,那如何通过操作系统中的下标找到对应在磁盘上的数据呢?方法也很简单比如说一个磁盘有4个盘面,每个盘面有10个磁道,一个磁道上有100个扇区,如果数据在1123号扇区的话,就先将1123除以1000这样就可以知道数据在哪个盘面上这里计算的结果是1所以数据在1号盘面上,再将1123摸上1000等于123,再使用123除以100就可以知道数据在哪个磁道上,计算的结果是1所以数据在1号磁道上,再将123摸上100就可以得到23,所以操作系统中下标为1123号扇区在磁盘的1号盘面上的1号磁道的第23号扇区上,磁盘再根据 CHS定位法就可以访问到这个扇区上的数据。在操作系统中把上面等价出来的线性地址称之为LBA(Logical Block Address)也可以叫逻辑抽象地址,操作系统之所以要对磁盘进行逻辑抽象是因为便于管理这也是一个先描述再组织的过程,将磁盘描述称为一个数组对磁盘的管理就变为对数组的管理,其次是为了不让操作系统的代码和硬件强解耦,如果使用磁盘的CHS地址的话这个地址只能用于磁盘,如果将存储设备改成SSD硬盘的话这个CHS地址就又不合适了得再换一个新的地址准则,而使用逻辑抽象地址就不会出现这样的情况,对于任何的存储设备这个都使用。虽然磁盘访问的基本单位是一个扇区(512字节),但是对于计算机来说每次访问的数据依然是非常的少,而且磁盘属于外设计算的速度十分的慢每次访问数据的时候磁头也不是恰好就在指定的扇区,所以操作系统为了提高访问的效率就定制了多个扇区读取的方法:一次读取1KB或者2KB或者4KB大小的数据,多半还是4KB也就是八个扇区的数据,也就是说哪怕你只想读取或者修改磁盘上1bit大小的数据,操作系统也会将磁盘上4KB大小的数据加载进内存进行读取或者修改,如果有必要的话再写回磁盘,这就是局部性原理:当一个位置的数据被加载进内存时,那么这个位置旁边的数据也有很大的几率会被用到,如果提前将旁边的数据加载进内存的话有助于提高整机的效率。内存被划分成为一个个4KB大小的空间,我们把内存中的每个空间称之为页框。磁盘中的文件尤其是可执行文件都是按照4KB大小划分好的块,我们把磁盘中的每个块称之为页帧,所以当我们把磁盘中的程序加载进内存的时候本质上就是将页帧里面的内容加载进页框里面。
文件系统
假如一个磁盘有500GB的大小,那么要想写一个程序一口气管理这500个GB的话会十分的困难,就好比中国是一个面积十分大人口十分多的国家,如果不把国家进行划分而是直接管理的话会导致很多政策无法落实到位,很多百姓的生活无法顾及的到,所以将一个国家划分成为多个省份每个省份有对应的省长,每个省长会根据本省的特点来制定不同的政策,对于磁盘来说也是相同的道理,如果一口气管理500GB大小的空间的话会十分的困难,所以我们先将这500GB进行分区,分为5个100GB的空间或者2个100GB的空间和2个150GB大小的空间:
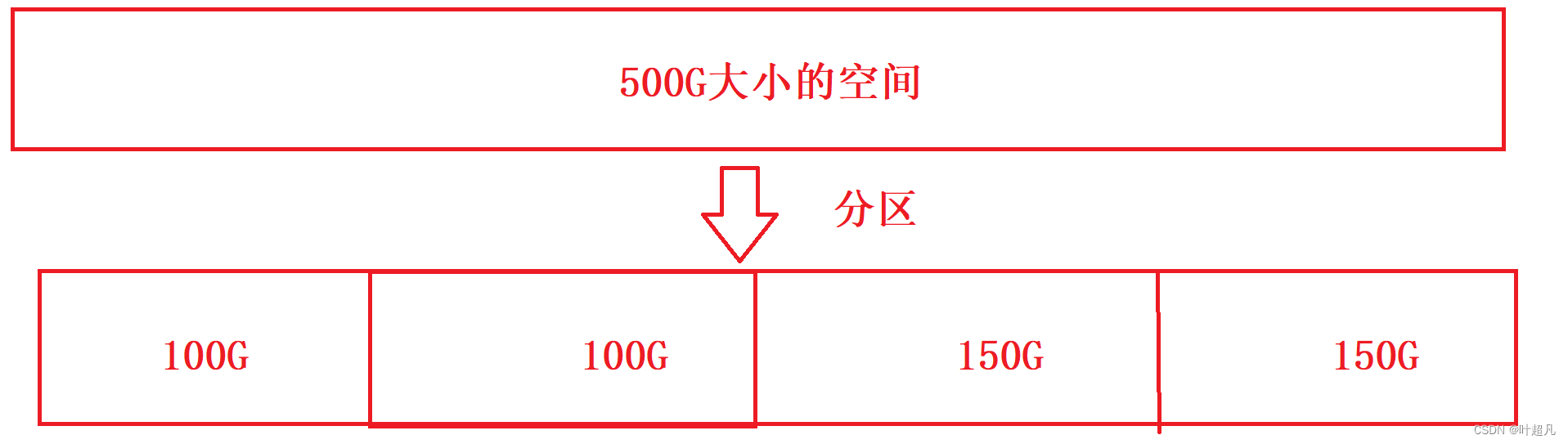
如果操作系统能将这100GB和150GB的空间管理好的话,那么操作系统就能管理好500GB大小的磁盘空间,但是100GB对于操作系统系统来说还是太大了,所以又会对100GB的空间进行分组,将一个100GB大小的空间分为20个5GB大小的空间:
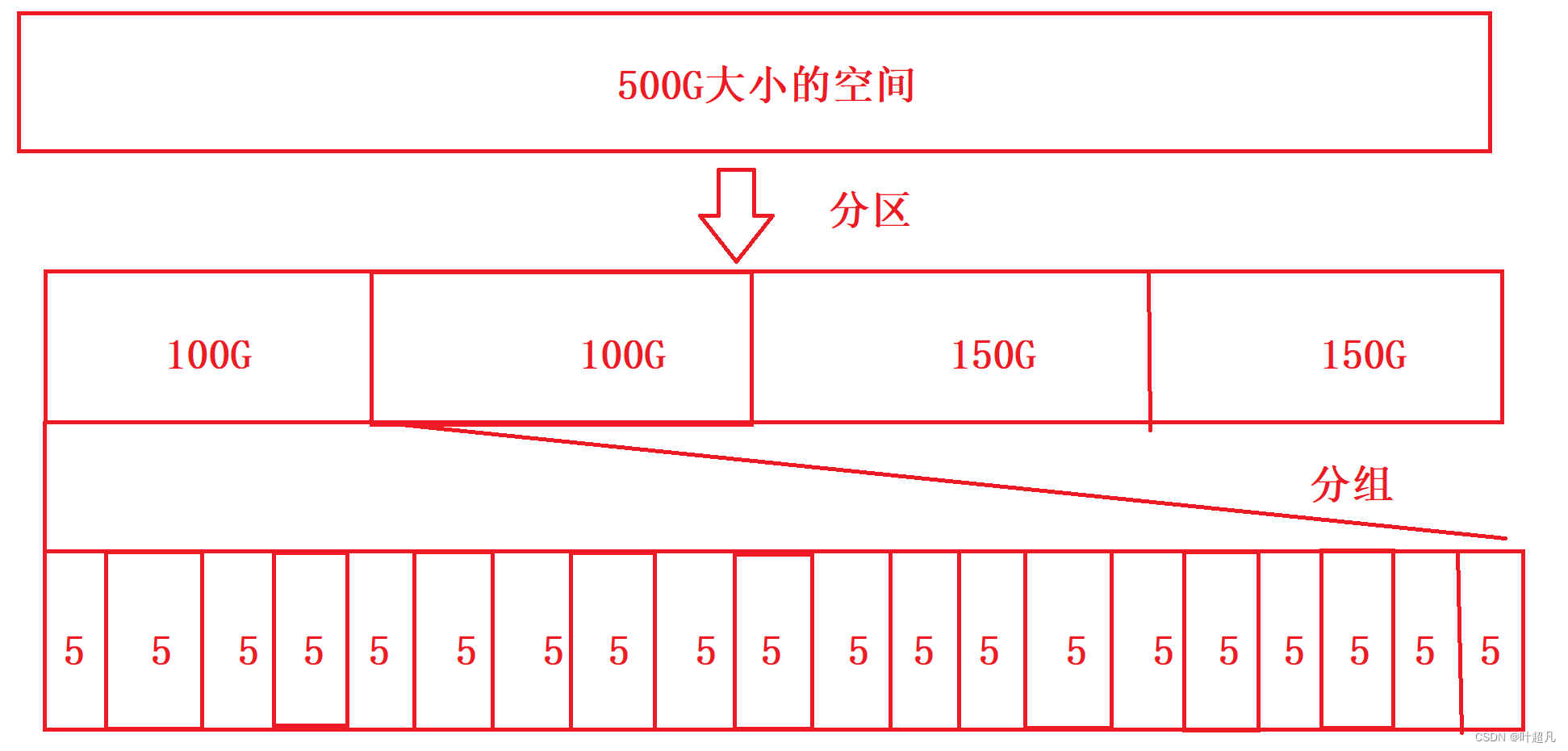
所以要想管理好500GB大小的空间就得管理好100GB和150GB大小的空间,要想管理好100GB和150GB的空间就得管理5GB大小的空间,只要管理5GB大小的空间那么整个磁盘的内容就都能管理好,这就是分而治之的方法将一件大事情不断地简化直到变成一个容易解决的小问题。操作系统采用下面的方法管理5GB的空间:
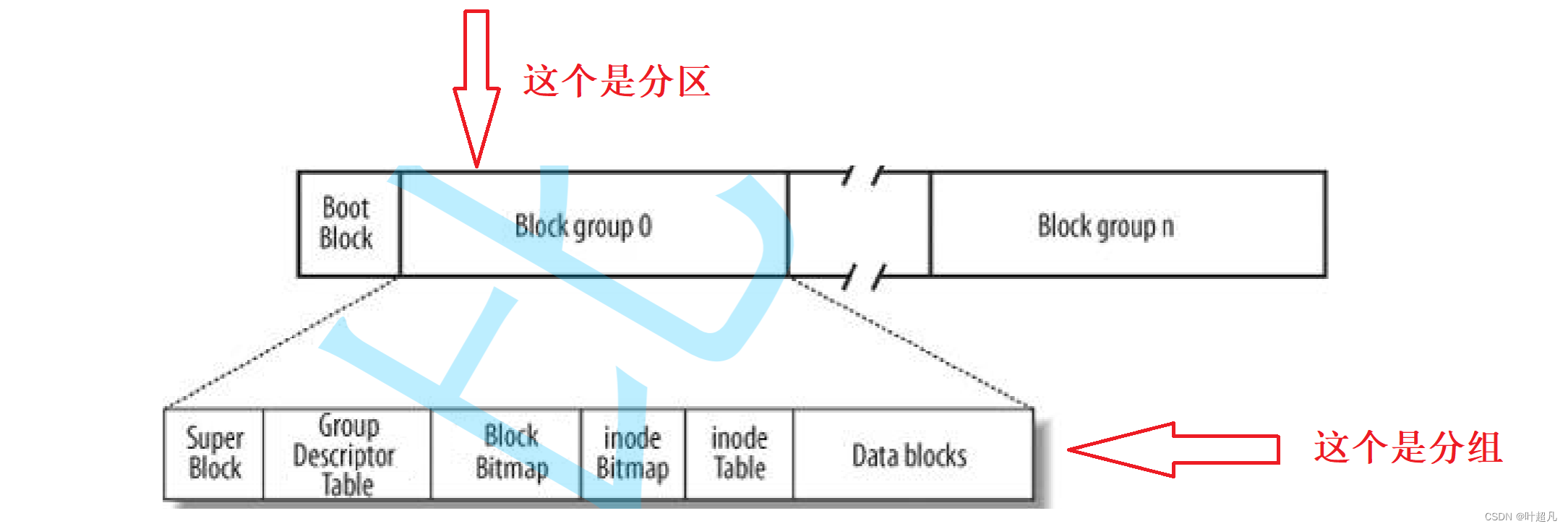
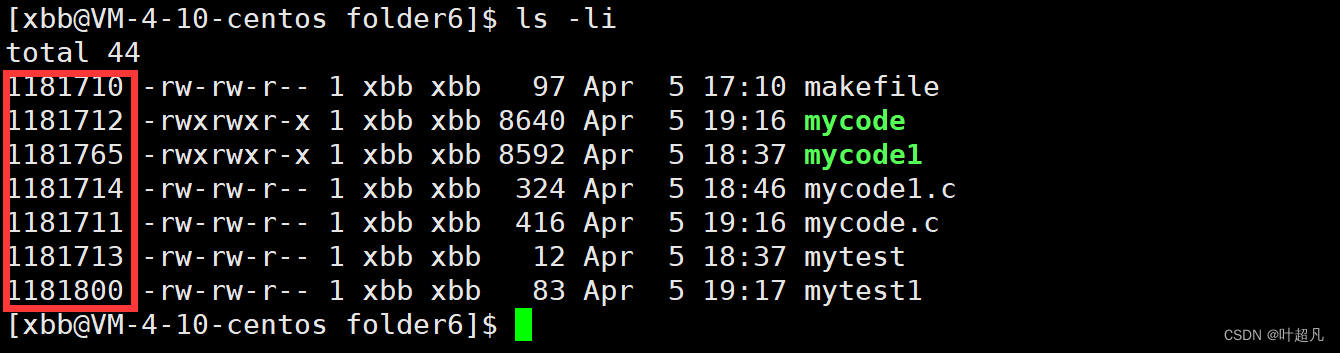
一个分区的最开始有个Boot Block,这个的区域的名字叫做启动块,这个东西的作用大家不用管用的地方太少了,分区完了之后就是分组,操作系统将每个组又分为好几个块首先是Super Block,这个块里面保存的是整个文件系统的信息比如说当前分区有多少个组,起始块号是多少,结束块号又是多少,每个组从哪里开始到哪里结束,每个组的空间使用率是多少等等都在这个super Block块里面,所以平时我们格式化某个分区时,实际上就是重新往这个分区的super block块里面写入信息,super block是按照一定的比例出现在不同的分组的第一位,也就是说有些组没有super block但是有些组有super block的信息,之所以这么做的原因就是方便备份,因为有时候会出一些问题导致一些数据被破坏,super block记录的是整个分区的信息,所以一旦他被破坏了就会导致很严重的后果,所以操作系统就会按照一定的比例在不同的分组里面都添加super block块这样一旦某个分组的super block块被破坏之后还能根据其他组的super block块进行修复,那么这就是第一个super block块的作用他保存整个文件系统的信息。文件=文件的内容+文件的属性,并且文件的内容和属性是分开存储的,在操作系统中用inode来存储文件的信息,并且inode的大小是固定的在大多数机器下inode都是128字节并且一个文件只会有一个inode,在inode里面记录了文件几乎所有的属性但是文件名不在inode里面存储,文件的内容存储在date block数据块里面,并且这个块的大小随着应用类型的变化而不断地发生变化。每个文件都会有一个属于自己的inode,如果分组里面有100个文件的话那么就会存在100个inode,所以inode为了区分彼此每个inode都会有一个属于自己的id,使用ls -li指令便可以查看每个文件对应的inode比如说下面的图片
每创建一个文件时操作系统就会给这个文件分配一个inode,我们不能创建无限个文件因为inode是有限的,因为每个分组里面会存在一个名为inode Table块,这个块里面保存了分组内部所有可用的inode,其中就包括已经使用的inode和没有使用的inode,每当我们创建一个文件时操作系统就会在这个块里面寻找一个没被使用的inode,找到之后就会将文件的所有属性保存到这个inode里面,如果这块里面有100个inode的话,那么这个块的大小就是12800字节,文件的属性会保存到inode table里面,那么文件的数据就会保存到Data blocks块里面并且是以数据块的方式进行保存也就是说一个文件可能会对应多个数据块而且每个数据块所保存的数据大小是4个字节。也就是说文件的属性会放到某一个inode里面,而文件的数据会放到Date block的某一个或多个数据块里面,所以当我们创建一个文件的时候会先inode块里面查找哪一个块没有被使用,找到之后将文件的属性填入对应的inode,然后再去data blocks里面找没有被使用的数据块,找到之后将文件的数据填入进去,所以不管是inode table还是data blocks,我们创建文件时都得需要一个功能就是查找功能,操作系统通过这个查找功能可以直到哪些inode没有被使用,哪些data blocks里面没有数据,所以为了实现这个功能在分组里面就有了一个inode Bitmap块,这个块里面就记录了inode对应的位图结构,比如说每一个分组里面存在8个inode,那么在inode Bitmap块里面就会存在8个比特位,每一个比特位就代表一个inode,如果一个inode被占用那么这个这个inode对应的比特位就会由0变成1,比如说第0 ,2个inode被占用了,那么这inode bitmap块里面的数据就会变成这样:0000 0101,而inode的大小是固定的,在磁盘中的存储也是连续的有规律的,所以我们可以根据inode的起始位置加上偏移量来找到指定的inode的数据,而inode bitmap里面记录了每一个inode是否被占用的情况,所以在创建文件时操作系统会先去在inode bitmap中会按顺序查找第几个inode没有被占用也就是查找inode btmap中的哪个比特位的值为0找到之后就将这个比特位所在的位置进行返回,然后操作系统根据这个位置再到inode table找到对应的inode最后将文件的属性填入进去,那么这就是inode bitmap块的功能。既然inode的查找是通过inode bitmap块里面的位图方式实现的,那么数据块的查找就是通过block bitmap快里面的位图结构实现的,如果data blocks里面有10000个数据块,那么block bitmap里面就会存在10000个比特位,根据两者的位置是一一对应的从而找到哪些数据块没有被占用。操作系统中的每个分组肯定会存在很多的信息比如说这个分组有多少个inode?有多少个数据块?inode的使用率是多少?数据块的使用率又是多少?等等属性和问题,这些属性当然可以通过临时计算来得到,但是计算还是太慢了会降低整体的效率,所以在分组里面就会存在一个Group Descriptor Table块简称GDT块组描述表,在这个块里面记录了分组的宏观属性信息。查找一个文件的时候,统一使用的是文件的inode编号,这个inode编号可以跨分组但是不可以跨分区,也就是说inode编号在不同的组中是不会出现相同的,但是在不同的分区里面可能会出现相同的inode编号,使用inode编号查找文件的属性很简单,先在inode bitmap中查找该inode编号是否存在,找到之后再看该inode是否被占用如果被占用的话就可以根据所在的位置在inode table中找到对应的属性,但是这里有个问题查找文件是通过inode编号查找的,但是通过上面的描述inode编号找文件的属性好像挺好找的,那如何通过inode编号来查找文件的数据呢?方法也很简单inode是一个结构体,这个结构体里面包含了文件的相关信息比如说inode的id,文件的权限mode,文件的拥有者uid,文件的所属组gid,文件的大小size等等,除了文件的属性在inode结构体里面还包含一个含有15个元素的数组,数组里面存放的就是数据块的编号,比如说下面的图片:
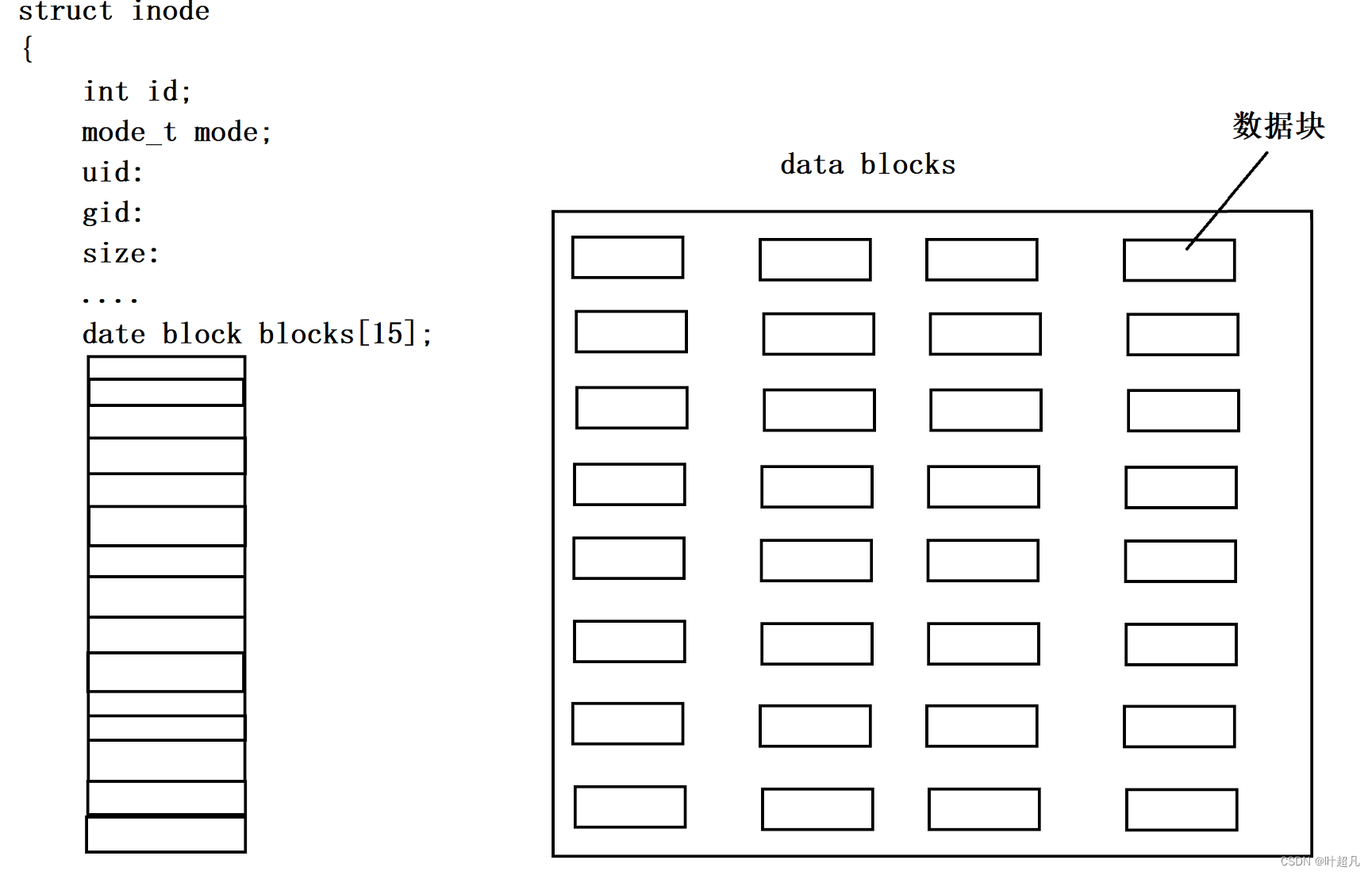
数组里面存放数据块的编号,我们可以通过这个编号找到数据块里面的内容,可是这里就存在一个问题,数组只有15个元素每个元素都指向一个数据块的话,那一个文件的大小最大不就只能是60KB了嘛,所以操作系统就采用了另外一个策略来解决这个问题,数组的最后三个元素指向的数据块并不记录文件的数据,而是记录该inode所对应的其他数据块的编号,其中下标为12的元素为一级索引,下标为13的元素为二级索引,下标为14的元素为三级索引,一级索引指向的数据数据块并不记录文件的数据而是其他数据块的编号,通过数据块里面的编号找到其他数据块,这些数据块里面装的才是文件的数据,二级索引表示的意思是当前元素指向的数据块里面装的是其他数据块的编号,这些编号所对应的文件里面装的也不是文件得数据还是该文件所对应得数据块的编号,这些编号再指向得数据块才存放文件的数据,三级索引也是同样的道理,一个数据块的大小是4KB能装很多编号所以一个data block blocks数组能够指向非常多的数据块,比如说下面的图片,黄色的方块表示当前数据块装的是文件的编码,而红色方块表示当前数据块装的是文件的属性,那么一级索引就是这样:

二级索引就是这样:
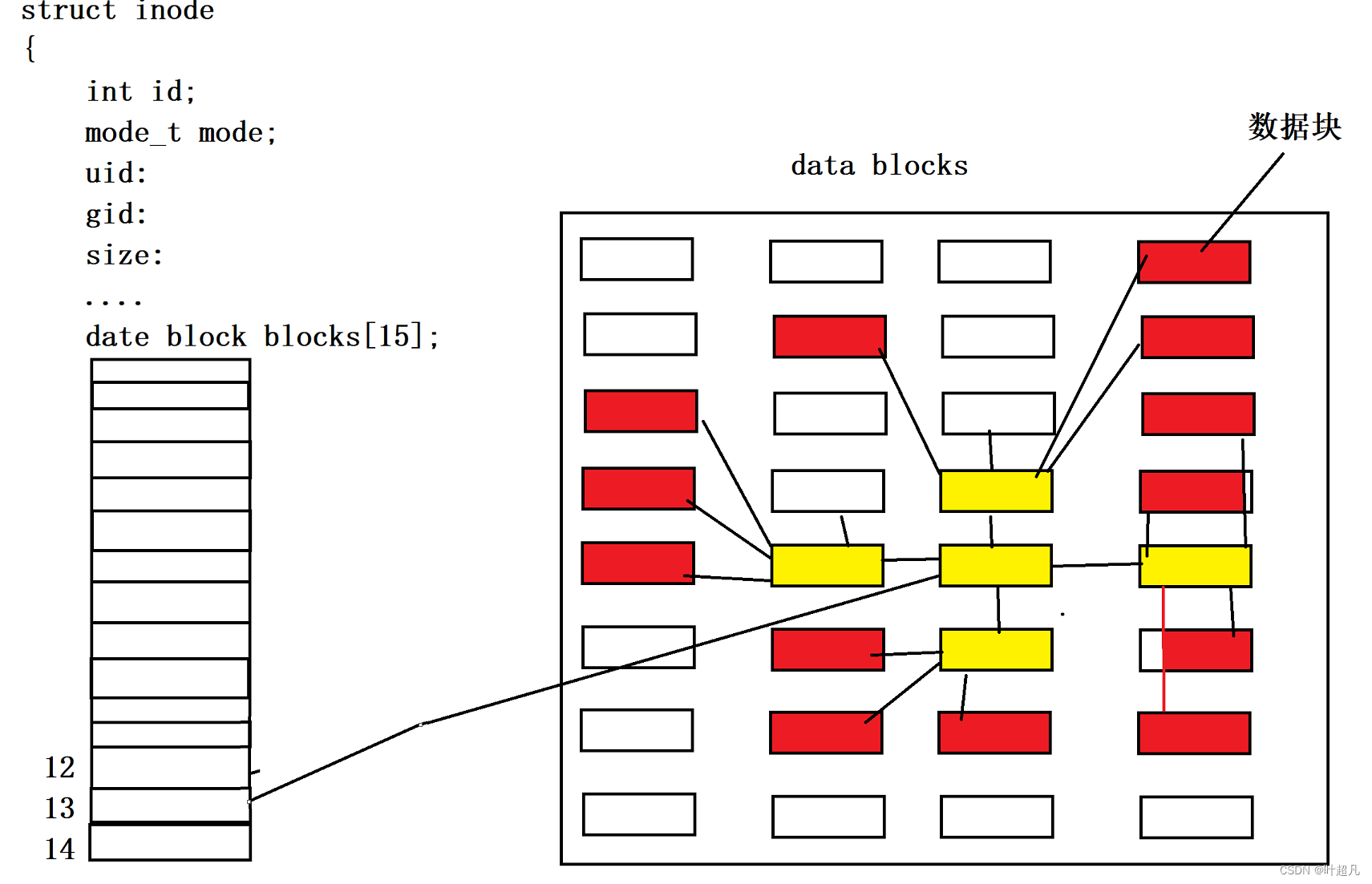
查找一个文件,创建一个文件都非常的复杂,但是删除一个文件却非常的简单,只用在inode bitmap中找到对应被删除文件的比特位,将该比特位由1改成0就可以了,无需将这个比特位对应的数据进行清空,因为之后创建文件时,新文件的数据会将原来的数据进行覆盖从另外一个方面达到清空数据的功能,所以大家要是一不小心删除某个文件的话还是可以恢复的,只用根据系统的日志找到被删除文件的indoe所对应的那个比特位将这个比特位由0改成1就可以恢复该文件。可是上面讲了这么多好像好事存在一个问题:我们平时在linux中操作文件啥的用的好像都是文件名啊我们从来都没使用inode啥的对吧,那操作系统是如何根据我们输入的文件来找到对应的inode的呢?这里我们就得聊聊目录,我们说linux下一切皆文件那文件夹是不是也是一个文件呢?我们平时用的所有文件和文件夹是不是一定在某个文件里面,每个文件都有自己的属性和数据,并且分组里面也会存在一个地方来存储这些数据和属性,那分组里面是不是也会有对应的地方来存储文件夹的属性和数据,而文件夹里面的数据就记录着该文件夹里面的文件名和inode的映射关系,平时我们使用文件名对文件进行操作,操作系统会先根据文件夹里面所记录的数据将你给的文件名转换为对应的inode然后再执行剩下的操作,知道这一点之后我们就能解决之前的问题,为什么一个人没有文件夹得写权限就无法在该文件夹里面创建其他文件或者文件夹呢?原因很简答创建文件或者文件夹本质上就是往文件夹得数据块里面写入内容,如果写权限就无法往数据块里面写入内容所有就无法创建文件或者文件夹,要想罗列文件夹里面的内容时就必须得有读权限,这是因为罗列文件夹的内容本质上就是查看文件夹的数据块里面的内容,而查看一个文件的数据块得有读权限所以没有读权限就无法罗列文件夹里面的内容,那么这就文件夹数据块的作用,以上就是本篇文章的内容希望大家能够理解。

![[架构之路-166]-《软考-系统分析师》-4-据通信与计算机网络-2- 网络体系结构、协议](https://img-blog.csdnimg.cn/17c46587ff584356afa083498a5834c3.png)



![[操作系统安全]SetUID与Capability权能](https://img-blog.csdnimg.cn/65b1e905104b42e7b745590deb6b2298.png)

![[FREERTOS]队列](https://img-blog.csdnimg.cn/485497e8a08b4cec84481370c10faab9.png)
