14天学习训练营导师课程:
杨鑫《Python 自学编程基础》
杨鑫《 Python 网络爬虫基础》
杨鑫《 Scrapy 爬虫框架实战和项目管理》
杨老师推荐自学Python的网站
w3schools
传送门
geeksforgeeks
传送门
realpython
传送门
学习之前读一读 来看看爬虫合不合法 传送门
立个小目标尽量做到一周输出 3篇 爬虫学习笔记哈
1.什么是爬虫
爬虫,即网络爬虫,又称网络蜘蛛(Web Spider),是一种按照一定规则,用来自动浏 览或抓取万维网数据的程序。可以把爬虫程序看成一个机器人,它的功能就是模拟人的行 为去访问各种站点,或者带回一些与站点相关的信息。它可以 24 小时不间断地做一些重复 性的工作,还可以自动提取一些数据。
但并不是只有 Python 才能编写爬虫 程序。其他的编程语言也可以用来编写爬虫程序,如 PHP 有 phpspider 爬虫框架,Java 有 WebMagic 爬虫框架,C#有 DotnetSpider 爬虫框架等等。
2.爬虫的应用场景
爬虫到底能干些什么呢?我们通过下面几个场景引入。
- 场景一:
大部分读者应该都有看网络小说的习惯,而去正版站点看小说一般是需要付费的,所 以衍生了很多盗版小说站点。这种盗版小说站点一般通过挂广告的形式来盈利,在浏览器 底部会嵌入各种类型的广告,用户单击这些广告会打开其对应的网址,盗版小说站点以此 获利。 这些盗版小说站点的广告一般都是误导读者打开它。比如,广告上有个 X 按钮,读者 通常以为单击 X 按钮可以关闭这个广告,殊不知是打开了广告,而且有些广告中含有不堪 入目的内容。想一想,在拥挤的地铁里,旁边的人看到你打开了这样的网页,会有多尴尬。 有没有办法既能看到小说又不用看这些烦人的广告呢?
答:通过爬虫可以解决这个问题,让爬虫只解析小说部分的内容并显示出来,甚至可 以把整本小说的内容解析完,保存到本地,以便离线阅读。
- 场景二:
有些读者有一种类似于强迫症的行为,比如,快递预计今天会到,每隔一段时间你就 会不由自主地输入单号看看快递到了没。有没有办法能摆脱这种频繁而又枯燥的工作 呢?
答:对于这种轮询(每隔一段时间查询一次)的任务,我们可以编写一个定时爬虫, 每隔一段时间自动去请求相应的站点,然后处理结果,判断其是否符合我们的预期,与人 工刷新相比,爬虫的频率更快、效率更高
- 场景三:
有一些站点,会通过签到或以做每日任务的形式来提高用户的活跃度,当坚持到一定 天数后会发放一些小奖励。比如,坚持十五天就能获得一个小礼物。因为忙碌或其他原因, 你中断了签到,使得之前的努力就都白费了。而且有些每日任务非常枯燥,但每天要为此 花上好几分钟。有没有办法把这种任务交给程序来做,然后坐享其成呢?
答:可以把这些任务交给爬虫。对于签到这种操作,通过抓包获取签到所需的接口、 参数和请求规则,接着让脚本每天定时执行即可。每日任务一般通过模拟单击的方式完成, 通过 Selenium 自动化框架来模拟。对于 App 签到,则可以通过 Appium 移动端自动化测试 框架来完成。
- 场景四:
如果你有志于从事 Python 开发相关的工作,想了解这个行业的一些情况,比如薪资、 年限和相关要求等,而你身边又没有从事相关工作的朋友,怎样才能获取到这些信息呢?
答:可以编写爬虫爬取一些招聘网站,比如拉勾、前程无忧这类站点,把 Python 岗位 相关的信息都抓取下来,然后通过数据分析基础三件套(NumPy、pandas、Matplotlib)进 行基本的数据分析,以此获取和这个行业相关的一些信息
3.爬虫由哪几部分组成
相信在看完爬虫应用的四个场景后,读者对爬虫能做什么有了大致了解,接下来我们 来了解爬虫由哪几部分组成。爬虫的三个组成部分如下图
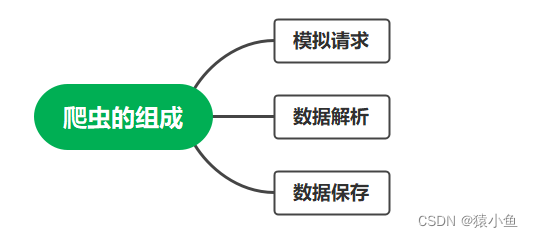
3.1 模拟请求
模拟请求就是如何把我们的爬虫伪装得像一个人一样去访问互联网站点。
-
最简单的站点,什么都不处理,只要发送请求,就会给出相应的结果。
-
稍微复杂一点的站点,会判断请求头中的 User-Agent 是否为浏览器请求,Host 字 段是否为正确的服务器域名,以及 Referer 字段的地址是否合法。
-
再复杂一点的站点,需要登录后才能访问。登录后会持有一个 Cookie 或 Session 会话,你需要带着这个东西才能执行一些请求,否则都会跳到登录页。
-
更复杂一点的站点,登录很复杂,需要五花八门的验证码、最简单的数字图片加 噪点、滑动验证码、点触验证码。除此之外,还有一些其他特立独行的验证方式, 如最经典的微博宫格验证码、极验验证码的行为验证等。
-
还有更复杂的站点,其链接和请求参数都是加密的,需要研究、破解加密规则才 能够模拟访问。
-
除此之外,还有一些反爬虫套路,如 限制 IP 访问频次、JavaScript 动态加 载数据等
在模拟请求之前,先要了解请求规则, 一般通过抓包工具来完成。
(1)对最简单的浏览器请求(以 Chrome 谷歌浏览器为例),在网页空白处右键单击并 选择检查,或者依次单击如图 所示的“更 多工具”→“开发者工具”。在 Windows 中打 开开发者工具的快捷键 F12。
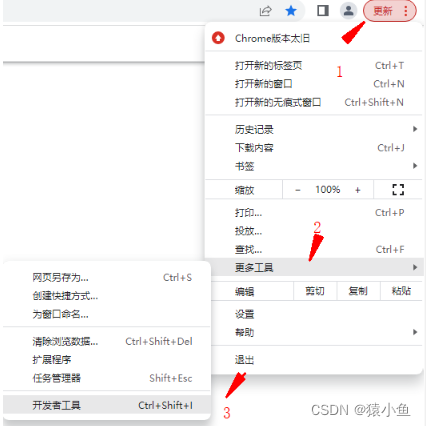
单击 Network 切换到抓包页面
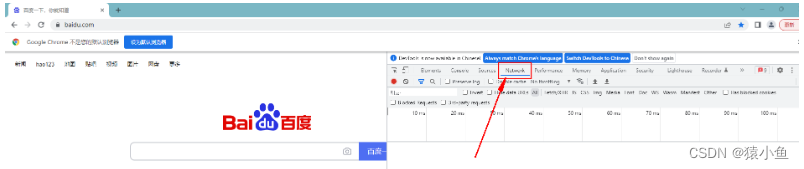
刷新当前页面或者去进行百度搜索,可以看到如下图所示的很多网络请求。单击对应的请求即可查看完整的 请求信息
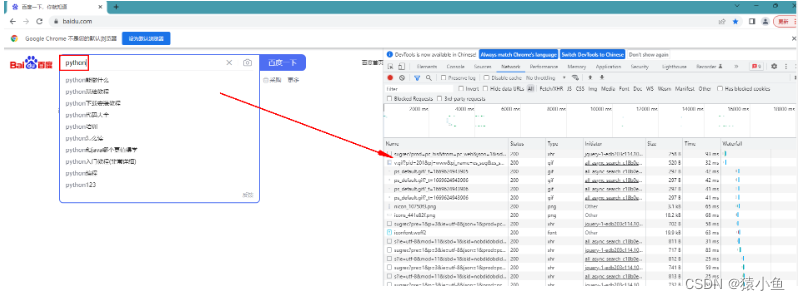
关于用 Chrome 抓包后面会详细介绍,这里先略过。
(2)稍微复杂一点的网站或 App 请求抓包,可以通过 Charles、Fidder、Wireshark 等工 具来实现,相关内容先收藏专栏等着看后面的学习笔记哈。
3.2 数据解析
数据解析是对模拟请求获得的不同类型的信息进行解析。
-
返回的结果是 HTML 或 XML,可利用 Beautiful Soup、Xpath、PyQuery 等模块解 析需要的节点数据。
-
返回的是JSON 字符串或其他字符串,可通过编写正则表达式提取所需信息。
-
返回的是加密后的数据,则需要解密后才能解析。
3.3 数据保存
数据保存是对解析后的数据进行保存。如果把采集到的数据放在内存里,一旦关 闭程序,数据就丢失了,因此我们需要把爬取到的数据保存到本地。
保存的形式有以 下几种:
- 保存为文本文件。一些文字类型的信息,如小说内容,可保存成 TXT 文件。
- 保存为图片、音视频等二进制文件。如一些多媒体资源可保存为这种格式。
- 保存到 Excel 表格中。其好处是直观,而且方便不了解编程的读者使用。
- 保存到数据库中。数据库又分为关系型数据库和非关系型数据库
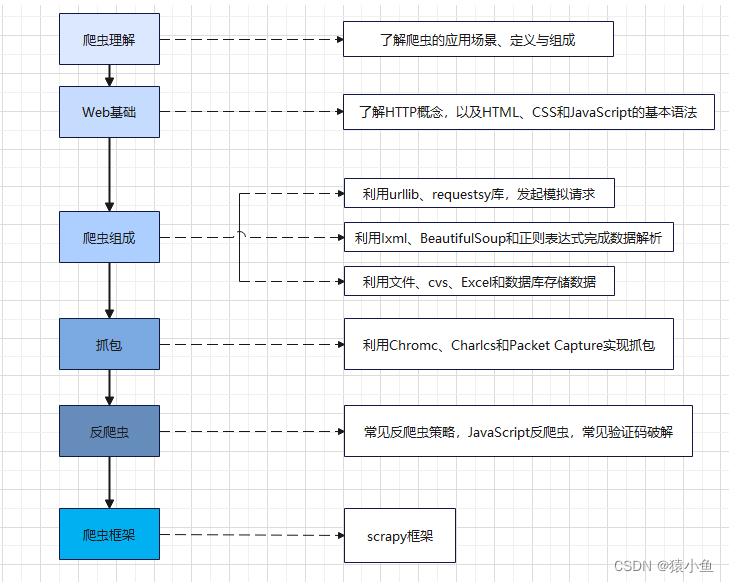
4.我的爬虫学习路线
![[附源码]SSM计算机毕业设计文章管理系统查重PPTJAVA](https://img-blog.csdnimg.cn/a519236f455340098be0904ada9ff5dd.png)

![[附源码]SSM计算机毕业设计鲜花销售管理系统JAVA](https://img-blog.csdnimg.cn/17c41ce230b743b993d1a1e349bd81a6.png)