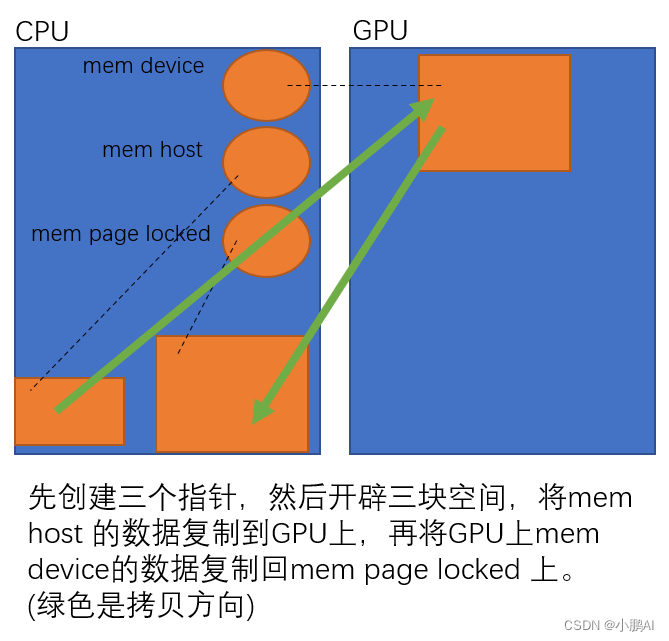
操作内存分配和数据复制过程概述
- 在gpu上开辟一块空间,并把地址记录在mem_device上
- 在cpu上开辟一块空间,并把地址记录在mem_host上,并修改了该地址所指区域的第二个值
- 把mem_host所指区域的数据都复制到mem_device的所指区域
- 在cpu上开辟一块空间,并把地址记录在mem_page_locked上
- 最后把mem_device所指区域的数据又复制回cpu上的mem_page_locked区域
内存模型
-
内存分为
- 主机内存:Host Memory,也就是CPU内存,内存 - 设备内存:Device Memory,也就是GPU内存,显存 - 设备内存又分为: - 全局内存(3):Global Memory - 寄存器内存(1):Register Memory - 纹理内存(2):Texture Memory - 共享内存(2):Shared Memory - 常量内存(2):Constant Memory - 本地内存(3):Local Memory - 只需要知道,谁距离计算芯片近,谁速度就越快,空间越小,价格越贵 - 清单的括号数字表示到计算芯片的距离 -
通过cudaMalloc分配GPU内存,分配到setDevice指定的当前设备上
-
通过cudaMallocHost分配page locked memory,即pinned memory,页锁定内存
- 页锁定内存是主机内存,CPU可以直接访问
- 页锁定内存也可以被GPU直接访问,使用DMA(Direct Memory Access)技术
- 注意这么做的性能会比较差,因为主机内存距离GPU太远,隔着PCIE等,不适合大量数据传输
- 页锁定内存是物理内存,过度使用会导致系统性能低下(导致虚拟内存等一系列技术变慢)
-
cudaMemcpy
- 如果host不是页锁定内存,则:
- Device To Host的过程,等价于
- pinned = cudaMallocHost
- copy Device to pinned
- copy pinned to Host
- free pinned
- Host To Device的过程,等价于
- pinned = cudaMallocHost
- copy Host to pinned
- copy pinned to Device
- free pinned
- Device To Host的过程,等价于
- 如果host是页锁定内存,则:
- Device To Host的过程,等价于
- copy Device to Host
- Host To Device的过程,等价于
- copy Host to Device
- Device To Host的过程,等价于
- 如果host不是页锁定内存,则:
- 建议先分配先释放
checkRuntime(cudaFreeHost(memory_page_locked));
delete [] memory_host;
checkRuntime(cudaFree(memory_device));
使用cuda API来分配内存的一般都有自己对应的释放内存方法;而使用new来分配的使用delete来释放
// CUDA运行时头文件
#include <cuda_runtime.h>
#include <stdio.h>
#include <string.h>
#define checkRuntime(op) __check_cuda_runtime((op), #op, __FILE__, __LINE__)
bool __check_cuda_runtime(cudaError_t code, const char* op, const char* file, int line){
if(code != cudaSuccess){
const char* err_name = cudaGetErrorName(code);
const char* err_message = cudaGetErrorString(code);
printf("runtime error %s:%d %s failed. \n code = %s, message = %s\n", file, line, op, err_name, err_message);
return false;
}
return true;
}
int main(){
int device_id = 0;
checkRuntime(cudaSetDevice(device_id));
float* memory_device = nullptr;
checkRuntime(cudaMalloc(&memory_device, 100 * sizeof(float))); // pointer to device
float* memory_host = new float[100];
memory_host[2] = 520.25;
checkRuntime(cudaMemcpy(memory_device, memory_host, sizeof(float) * 100, cudaMemcpyHostToDevice)); // 返回的地址是开辟的device地址,存放在memory_device
float* memory_page_locked = nullptr;
checkRuntime(cudaMallocHost(&memory_page_locked, 100 * sizeof(float))); // 返回的地址是被开辟的pin memory的地址,存放在memory_page_locked
checkRuntime(cudaMemcpy(memory_page_locked, memory_device, sizeof(float) * 100, cudaMemcpyDeviceToHost)); //
printf("%f\n", memory_page_locked[2]);
checkRuntime(cudaFreeHost(memory_page_locked));
delete [] memory_host;
checkRuntime(cudaFree(memory_device));
return 0;
}