FFM模型
FFM(Field-aware Factorization Machine,领域感知因子分解机)是一种广泛应用于推荐系统和点击率预测(CTR)等任务的机器学习模型。
它是基于FM(Factorization Machine,因子分解机)的扩展,增加了领域感知特性,使模型在处理高度稀疏的特征组合时具有更强的表达能力。
因子分解机(FM)简介 FM是一种广义的线性模型,可以对特征向量的所有二阶组合进行建模。FM的主要优势是能够在高度稀疏的数据中捕捉到特征之间的交互作用,而且参数数量相对较少,计算复杂度较低。FM的数学表达形式如下:
FM(x) = w0 + ∑[wi * xi] + ∑∑[<vi, vj> * xi * xj]
其中,x是输入特征向量,w0是全局偏置,wi是一阶权重,vi和vj是特征向量的隐向量,<vi, vj>表示两个向量的内积。
领域感知因子分解机(FFM) FFM在FM的基础上引入了领域概念,将特征分成不同的领域,使模型能够学习不同领域之间的交互作用。FFM的数学表达形式如下:
FFM(x) = w0 + ∑[wi * xi] + ∑∑[<vi,fj, vj,fi> * xi * xj]
其中,fi和fj分别表示特征i和j所属的领域,vi,fj和vj,fi分别表示特征i在领域j的隐向量和特征j在领域i的隐向量。
FFM的优势相比于FM,FFM具有以下优势:
(1)更强的表达能力:FFM考虑了领域信息,使得模型能够捕捉到不同领域之间的交互作用,从而具有更强的表达能力。
(2)更好的泛化性能:FFM在高度稀疏的数据中具有更好的泛化性能,因为它能够学习到不同领域之间的潜在交互模式。
FFM的局限性尽管FFM具有较强的表达能力和泛化性能,但它也存在一些局限性:
(1)参数数量较多:FFM的参数数量是FM的K倍,其中K是领域数量。因此,FFM的参数数量可能会非常大,增加了模型的存储和计算需求。这可能导致训练和推理速度变慢,以及过拟合的风险增加。
(2)领域划分问题:FFM需要对特征进行领域划分,而合适的领域划分对模型性能有很大影响。如何选择合适的领域划分是一个挑战,可能需要根据具体应用场景和数据特性进行调整。
(3)高阶特征交互:FFM主要关注二阶特征交互,对于高阶特征交互的建模能力较弱。在某些场景下,高阶特征交互可能对预测结果产生重要影响,这时候FFM可能不是最佳选择。
FFM的应用场景 FFM主要应用于推荐系统和点击率预测(CTR)等任务,尤其是在特征稀疏且需要捕捉不同领域间特征交互的场景下表现优越。例如,在在线广告投放、电商商品推荐等领域,FFM都取得了较好的实际效果。
FFM的改进和拓展有许多针对FFM的改进和拓展方法,如:
(1)加入正则化:为了防止过拟合,可以在FFM的损失函数中加入L1或L2正则化项。
(2)采用梯度下降优化算法:FFM可以使用随机梯度下降(SGD)、Adagrad、Adam等优化算法进行训练,以提高模型训练速度和收敛性能。
(3)结合深度学习方法:将FFM与深度学习模型(如神经网络)相结合,以增强模型的非线性表达能力和高阶特征交互的建模能力。
总之,FFM作为一种领域感知的因子分解机,通过引入领域信息增强了模型在处理高度稀疏特征组合时的表达能力。然而,FFM也存在一定的局限性,如参数数量较多、领域划分问题等。在实际应用中,需要根据具体场景和数据特性选择合适的模型和方法。

编辑切换为居中
添加图片注释,不超过 140 字(可选)
在一个网站(发布者)上发布一条广告(广告主),我们可以通过观察某个用户(具有性别特征的用户)是否会点击这条广告来收集数据。在这个例子中,我们考虑了三个特征领域(字段):网站发布者(可选特征值包括ESPN、Vogue、NBC)、广告(可选特征值包括Nike、Adidas、Gucci)以及性别特征(可选特征值包括男性和女性)。通过这个例子,我们可以明显看出组合特征的重要性:例如,当在体育网站ESPN上发布Nike广告时,如果有100次展示,其中80次可能会被点击,而剩下的20次则不会。这表明组合特征(发布者为“ESPN”且广告主为“Nike”)是一个强大的二阶组合特征,有助于预测用户是否会点击广告。上图同时展示了一条用户点击记录告。
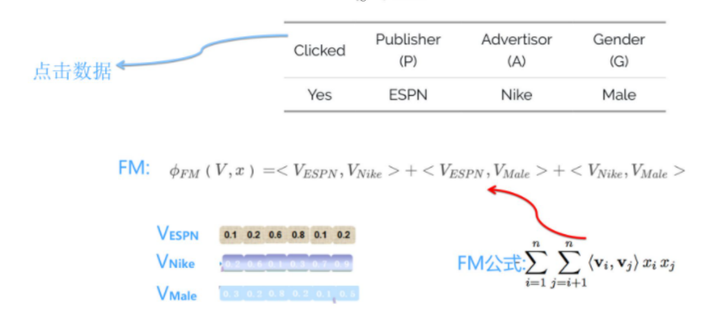
编辑切换为居中
添加图片注释,不超过 140 字(可选)
在FM模型中,为了进行二阶特征组合,我们会计算每个二阶组合特征的权重。这个权重是根据相应的两个特征的Embedding向量的内积来表示组合特征重要性的。训练FM模型后,每个特征将学到一个特征embedding向量。当我们需要预测用户是否会点击某条广告时,比如在上述例子中,我们会对三个特征进行两两组合。然后,根据这些组合特征的权重(由相应特征embedding的内积计算得出),我们可以对所有组合特征求和。最后,通过应用Sigmoid函数,我们便可以进行二分类预测,判断用户是否会点击广告。

编辑切换为居中
添加图片注释,不超过 140 字(可选)
在FM模型中,每个特征都会学到一个唯一的特征embedding向量。值得注意的是,这与FFM模型存在显著差异。为了便于理解FM模型并过渡到FFM模型,我们可以这样解释FM模型中某个特征的embedding:以Vespn特征为例,当它与其他特征域的某个特征进行二阶特征组合时,无论与哪个特征域的特征进行组合,Vespn特征都会反复使用相同的特征embedding来计算内积。因此,我们可以认为Vespn特征在与不同特征域的特征进行组合时,共享了同一个特征向量。
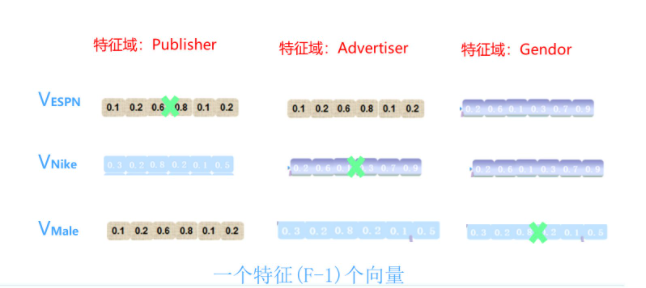
编辑切换为居中
添加图片注释,不超过 140 字(可选)
在FM模型中,每个特征在与其他特征域的特征进行组合求权重时确实共享了同一个特征向量。但是,如果我们想要更细致地描述特征组合,可以考虑为特征分配不同的embedding向量。例如,当Vespn特征与Nike(属于广告主特征域)组合时,使用一个特征embedding向量,而与Male(属于性别特征域)组合时,使用另一个特征embedding向量。这样的设计可以使特征组合描述更为精细。
也就是说,当Vespn特征与属于广告主特征域的特征组合时,使用一个特征embedding;与属于性别特征域的特征组合时,使用另一个特征embedding。这意味着,如果有F个特征域,那么每个特征将由FM模型的一个k维特征embedding扩展为(F-1)个k维特征embedding。之所以是F-1而不是F,是因为特征不会与自身组合,所以不需要考虑自身特征域。

编辑切换为居中
添加图片注释,不超过 140 字(可选)
在FFM模型中,上述过程的应用方式如下:由于这个例子包含三个特征域,因此Vespn具有两个特征embedding。当与Nike特征组合时,使用针对广告主特征域的embedding进行内积计算;
而与Male特征组合时,则使用针对性别特征域的embedding进行内积计算。同样地,Nike和Male这两个特征会根据组合特征所属的特征域的不同,采用不同的特征向量进行内积计算。
在进行两两特征组合方面,FFM和FM模型的做法是完全相同的。它们之间的区别在于每个特征对应的特征embedding数量。在FM模型中,每个特征只有一个共享的embedding向量;
而在FFM模型中,一个特征会有(F-1)个特征embedding向量,用于与不同特征域的特征进行组合。
假设模型具有n个特征,FM模型的参数量是n*k(暂时忽略一阶特征的参数),其中k是特征向量的大小。对于FFM模型,由于每个特征具有(F-1)个k维特征向量,因此模型参数量为(F-1)nk,即比FM模型的参数量扩充了F-1倍。这意味着,如果我们的任务包含100个特征域,FFM模型的参数量将是FM模型的大约100倍。这是相当惊人的,因为实际任务中,特征数量n通常很大,而特征域几十到上百也很常见。
另外,在我们之前介绍FM模型的部分中提到,FM模型可以通过公式改写,将原本看似n平方的计算复杂度降低至O(kn)。然而,FFM无法进行类似的改写,因此其计算复杂度为O(kn^2),在计算速度上明显比FM模型慢得多。因此,无论是从急剧膨胀的参数量还是变慢的计算速度角度来看,相较于FM模型,FFM模型显得更为笨重。
正因为FFM模型的参数量较大,在训练FFM模型时容易过拟合,需要采取如早停等防止过拟合的策略。根据经验,FFM模型的k值可以设置得较小,例如在几千万训练数据规模下,取8至10通常能达到较好效果。当然,k值的具体设定与训练数据规模有关。理论上,训练数据集越大,越不容易过拟合,k值可以设置得相对较大。
离线训练阶段与采用FFM模型的排序阶段相似,例如可以使用线上收集到的用户点击数据作为训练数据,线下训练一个完整的FFM模型。在召回阶段,我们实际上需要的是每个特征及其对应的训练好的(F-1)个embedding向量。这些向量可以存储好供以后使用。
在线预估阶段,我们利用与用户(User)相关的特征、广告(Item)相关的特征以及上下文特征(Context,如时间、地点、手机品牌等)来学习映射函数F。学习完这个函数后,当遇到一个新的Item时,我们将用户特征、广告特征以及用户在碰到这个广告时的上下文特征输入到函数F中,F函数会告诉我们用户是否对这个广告感兴趣。如果用户感兴趣,我们可以将该Item作为推荐结果推送给用户。
将特征域划分为三个子集:用户相关特征集合、广告相关特征集合以及上下文相关特征集合。用户历史行为特征,如用户过去点击广告的特征,可以视为描述用户兴趣的特征,将其纳入用户相关特征集合中。
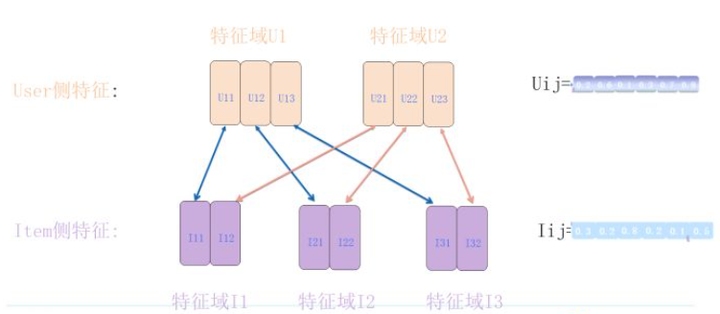
编辑切换为居中
添加图片注释,不超过 140 字(可选)
在这个例子中,我们使用五个特征域,分别是用户侧的两个特征域U1和U2,以及广告侧的三个特征域I1、I2和I3。当处理具体数据实例时,每个特征域下都会有一个相应的特征值。对于某个特定的特征值f1,根据FFM的计算原理,在离线训练阶段,它将学习到4个对应的embedding向量,这些向量将在f1与其他特征域中的特征进行特征组合时使用。
我们当前的任务是通过FFM模型来实现用户任意特征和广告任意特征的组合。
对于用户侧的两个特征,我们分别提取它们在和三个广告侧特征域组合时使用的embedding向量。例如,对于U1,我们将这三个特征embedding分别命名为U11、U12和U13。U11的两个下标数字表示:这是第一个用户侧特征域U1与第一个广告侧特征域I1组合时使用的特征embedding。U12则表示第一个用户侧特征域U1与第二个广告侧特征域I2组合时使用的特征embedding。如此处理后,每个用户侧的特征提取出三个特征向量,而每个广告侧的特征提取出两个特征向量,形成如图所示的结构。
根据FFM的计算规则,如果我们想计算用户侧和广告侧的两两特征组合,我们需要建立特征向量求内积时的对应关系,图中的箭头表示了这种对应关系。U和I特征向量下标编号具有规律性的对应关系,例如U12<-->I21、U23<-->I32等,即<Uij, Iji>。
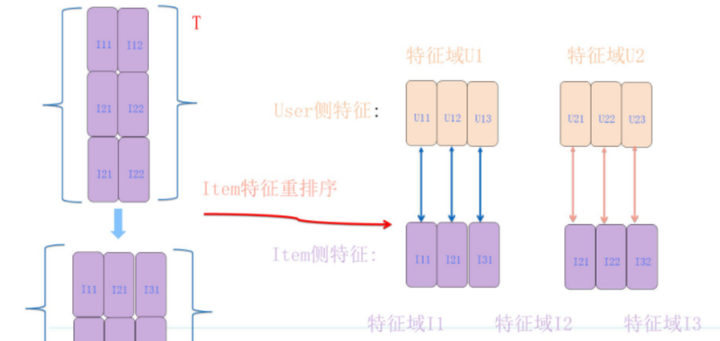
编辑切换为居中
添加图片注释,不超过 140 字(可选)
图中的特征向量之间的对应关系看起来有些复杂,那么是否可以让它们的对应关系更简洁明了呢?我们只需要对广告侧的特征向量重新排序即可。这个重排序过程可以看作是对原先顺序排列的广告侧特征向量矩阵执行了一个转置操作。这样,每个广告侧的特征向量就和需要求内积的对应用户侧特征向量形成了整齐的一一对齐效果。
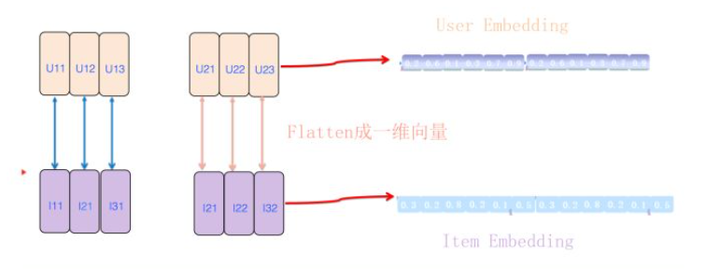
编辑切换为居中
添加图片注释,不超过 140 字(可选)
模型在召回阶段需要解决的问题是:如何根据FFM原理生成相应的用户侧embedding和广告侧embedding。前面两段讲述了根据FFM原理,特征向量应该如何对齐的过程。在向量对齐之后,我们如何生成两个embedding向量呢?方法很简单,只需将刚刚对齐的二维向量展平并顺序连接,就形成了展开的一维用户embedding和广告embedding。
接下来,我们可以将每个广告的embedding离线存储在Faiss中,而将用户embedding提前计算好并存放在内存数据库中。当用户登录或刷新页面时,我们可以在线根据用户的embedding向量,通过Faiss的快速查询功能,按内积值回溯并获取top K广告。返回的广告就是基于FFM模型计算得分最高的推荐结果。
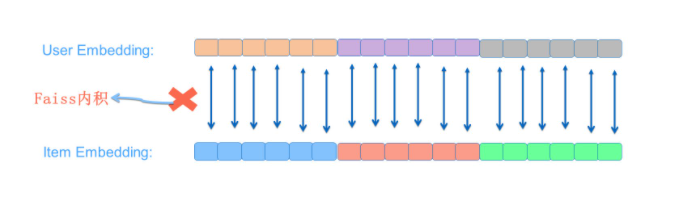
编辑切换为居中
添加图片注释,不超过 140 字(可选)
将拉长后的User Embedding和Item Embedding通过Faiss进行内积计算后得到的分数,是否等同于标准FFM计算结果呢?
两者显然是等价的。计算<U, I>内积的操作实际上是将两个长向量的对应位置数值相乘,然后求和。因此,拉长向量匹配版本和将子项分别求内积再求和的方法得到的数值是相同的。通过上图示例可以很容易地看出这一点。
从上述说明中,我们可以看出我们已经得到了一个基础版本的FFM召回模型。这个版本的召回模型仅考虑了用户特征和广告特征之间的组合,而其他因素尚未考虑。
在FFM中,embedding向量的长度可能会非常大。以实际任务为例,假设用户侧有50个特征域(M=50),广告侧有50个特征域(N=50),每个特征向量的大小k=10,可以推断出用户和广告的embedding长度为 25000(size=MNK=505010)。然而,对于Faiss来说,如果广告库较大,这样的速度显然无法满足需求。
为了减小embedding长度,可以尝试减小k值,例如将k设为2或4。如果仅使用FFM模型进行召回,这种策略是可行的。毕竟,在召回阶段,精确度要求不高,我们依靠第二个排序阶段来确保推荐结果的准确性,只要在召回阶段找到好的广告即可。然而,即使这样,embedding size仍然为 5000(50502),长度仍然较长。
另一种解决方案是减少特征域的数量,例如将M和N都设为10。这意味着用户和广告各有10个特征域,这样一来,embedding size降为200(10102),基本可以实用化了。虽然将FFM仅用于召回可能受到严重限制,但这样做是可行的。
前面的内容主要讨论了计算用户侧任意特征和广告侧任意特征之间的两两特征组合。
如果希望在召回阶段完整复现FFM模型,还需要考虑用户侧内部的两两特征组合以及广告侧内部的两两特征组合。

编辑切换为居中
添加图片注释,不超过 140 字(可选)
关于用户侧和广告侧内部的两两特征组合的计算方法,我们可以参考计算用户侧和广告侧特征组合的方法,或者遵循标准的FFM计算流程。总之,方法相当灵活。关键问题是:在计算出用户侧的内部特征两两组合得分Score(User_iUser_j)和Score(Item_iItem_j)后,如何将它们整合到那两个较长的用户embedding和广告embedding中?
一种做法是在用户的二阶项embedding后添加两位:一位表示用户侧内部特征组合得分,在对应的广告侧位置,增加一位,值设置为1。这样,在Faiss进行内积计算过程中,就会包含用户侧内部特征组合得分;类似地,广告侧也可以进行类似处理。这样,我们就将U和I的内部特征组合整合到了FFM召回模型中,FM模型同样可以采用这种方法。
理论上讲,如果仅使用FM/FFM模型进行召回,用户侧内部的特征组合对返回结果排序没有影响,因此可以不加入。广告侧内部特征之间的特征组合可能会对返回的广告排序结果产生影响,可以考虑引入这种方法,将其统一整合进来。但如果希望用FM/FFM模型一步完成“召回+Ranking”的两阶段模式,可以考虑完全复现FM/FFM模型,这样,应将双方的内部特征组合都纳入考虑。
FFM如何加入1阶项
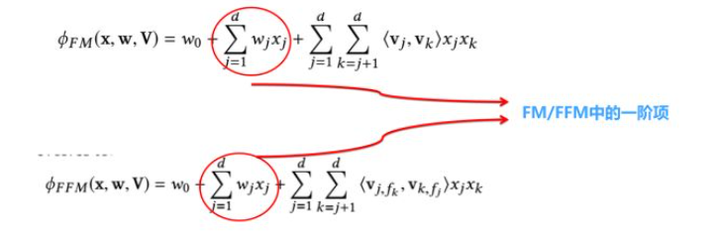
编辑切换为居中
添加图片注释,不超过 140 字(可选)
在标准的FM/FFM公式中,确实包含了一阶项,即线性回归(LR)模型。如果我们已经根据前述方法得到了用户侧和物品侧的二阶项embedding,现在想要将一阶项加入到FM/FFM召回模型中
方法一

编辑切换为居中
添加图片注释,不超过 140 字(可选)
在用户侧的嵌入向量中,我们可以增加两个额外的维度。
第一个维度表示用户特征域的特征对应的一阶项累加和。相应地,在广告侧的嵌入向量中,我们也需要在相应位置增加一个维度,并将其值设为1。这样,在使用Faiss计算内积时,用户侧的一阶项将被自然地纳入计算过程。同样的方法也可以用于加入广告侧的一阶项。
方法二
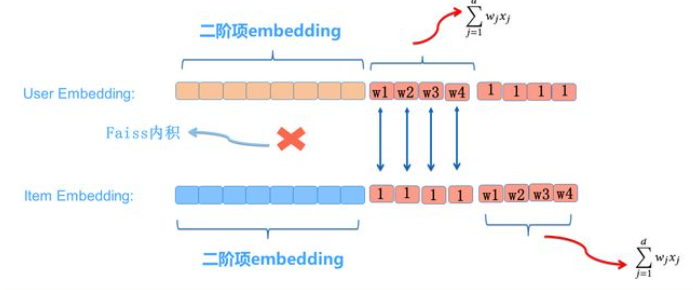
编辑切换为居中
添加图片注释,不超过 140 字(可选)
不直接计算用户侧和广告侧的一阶项求和,而是将用户侧和广告侧各自对应特征的一阶权重分别拼接到二阶项的嵌入向量之后。同时,在对应的广告侧或用户侧相应位置设置为1。这种方法同样可以在使用Faiss计算内积时,将一阶项纳入得分计算过程中。
在采用FM召回模型时,对于某些应用而言,一阶项对最终效果具有显著影响。因此,在使用FM/FFM进行召回时,需要考虑将一阶项纳入计算,这可能是由于个别一阶特征相对重要导致的。在Criteo数据集的实验结果中,我们发现对于FM模型,一阶项确实有价值。当去掉一阶项,仅保留二阶项时,AUC会降低大约1个绝对百分点。对于CTR预估来说,这个差距相当明显。然而,如果采用DeepFM模型,FM部分是否保留一阶项对最终结果影响不大,这表明DNN的隐层已经有效地吸收了一阶项的作用。
FFM加入上下文特征信息
在抽象的广告系统中,除了用户特征和广告特征外,还有一类重要特征,即用户行为发生的场景上下文特征(例如,何时、何地、使用何种设备进行刷新等)。然而,在逐步改进的FFM召回模型中,我们还未考虑这一部分特征。
场景上下文特征之所以被单独提及,是因为它具有独特的特点。部分上下文特征几乎是实时变化的,如刷新app的时间或对于地理位置敏感的应用(如美团、滴滴)中的用户所处地点。这种变化需要在召回阶段得到体现。因此,与用户特征这种可以离线计算并存储的特征不同,上下文特征具有较强的动态性,每次刷新时可能需要重新捕获当前特征值。
要将上下文特征纳入考虑并构建与标准FFM等效的召回模型,我们需要关注以下两个问题:
鉴于部分上下文特征可能是实时变化的且无法离线计算,如何将其实时融入前述FFM召回计算框架中?
我们需要考虑场景特征C与用户特征U之间的特征组合,以及C与广告特征I之间的特征组合。由于场景特征有时非常强烈,那么如何才能将这两组特征组合纳入考虑?
编辑切换为居中
添加图片注释,不超过 140 字(可选)
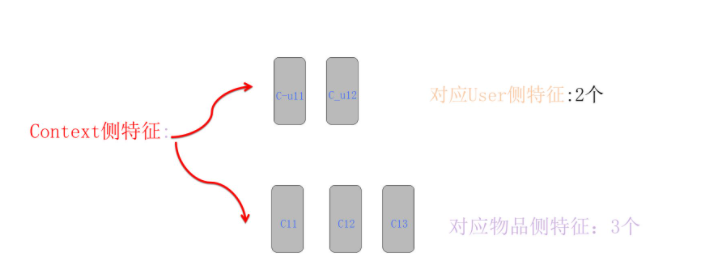
场景特征-根据用户和广告分拆特征
由于上下文特征的动态性,当给定用户UID时,我们可以在线查询某个上下文特征对应的(F-1)个embedding向量,其中F表示任务特征域的数量。这(F-1)个特征向量可以分为三组:第一组用于将上下文特征与用户特征域的特征进行特征组合,为两个;第二组用于将上下文特征与广告特征域的特征进行特征组合,为三个;第三组是用于上下文特征在自身内部进行特征组合,我们暂时忽略这一点,因为其处理方法与用户侧和广告侧求内部特征组合的方法相同。
为了简化说明,假设只有一个上下文特征,那么它将对应(6-1)= 5个embedding向量,其中2个用于与用户侧特征进行组合,3个用于与广告侧特征进行组合。我们将它们分成两组,如上图所示。
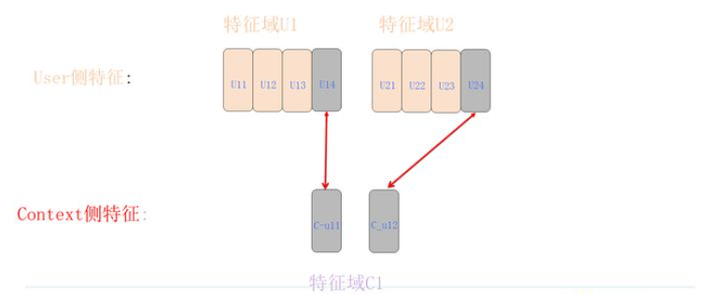
编辑切换为居中
添加图片注释,不超过 140 字(可选)
场景特征-用户特征组合
我们来讨论一下如何将上下文特征和用户侧特征进行特征组合。正如上图所示,这个过程实际上与之前提到的用户侧与广告侧的FFM特征组合过程相同。我们只需找到广告侧和上下文侧特征对应的嵌入向量,然后进行内积计算。关于这部分的具体内容,这里就不再赘述,请参考之前的讨论。由于这两类特征都可以在用户访问行为发生时获取,而且不依赖于与广告发生的关系,因此这个过程可以在用户侧在线计算完成。
计算出的内积数值表示用户特征和上下文特征的二阶特征组合得分,我们需要将其计算好并保存以备后用。
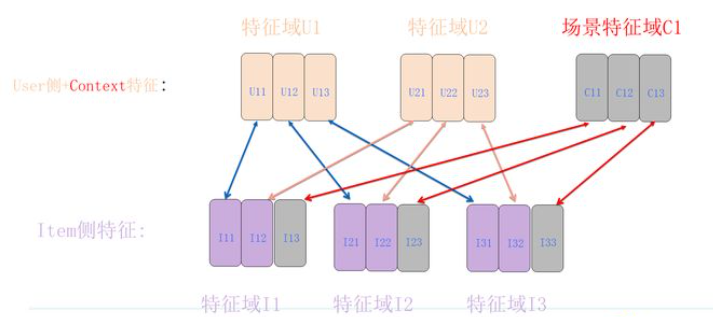
编辑切换为居中
添加图片注释,不超过 140 字(可选)
场景特征-广告特征组合
在计算上下文特征和广告侧特征的特征组合时,如上图所示,其实非常容易理解。就好像在进行用户侧特征与广告侧特征组合时,用户侧增加了一些新特征。尽管这些新增特征实际上属于上下文特征而非用户侧特征,但我们处理它们的方法仍然完全相同。这样一来,我们就可以将上下文特征融入到用户侧嵌入和广告侧嵌入中,从而成功解决了上下文特征与广告特征的组合问题。
FFM召回最终方案
利用用户侧嵌入(embedding)向量,我们可以通过Faiss使用内积方法获取Top K个广告。这种方法获取的广告同时考虑到了用户和广告的特征组合<U,I>,以及上下文和广告的特征组合<C,I>。假设返回的Top K个广告都带有内积得分Score1,再加上前一步的<U,C>得分Score,将两者相加对广告进行重排序(由于<U,C>与广告无关,实际上不影响广告排序,如果是召回阶段使用FM/FFM,则可以不考虑引入)。这样我们就得到了最终结果。这个最终结果在遵循FFM计算原则的基础上,考虑了U/I/C两两之间的特征组合。当然,我们可以将上述的一阶项以及<U,U>/<I,I>内部特征组合也整合到这个系统中。
因此,我们通过这种方式构建了一个完整的FFM召回模型。这个召回模型通过构造用户嵌入向量、上下文嵌入向量和物品嵌入向量,以及充分利用类似Faiss这种高效嵌入向量计算框架,构建了一个高效执行且与FFM计算完全等价的召回系统。
在前文中提到,按照这种方法进行FFM计算,生成的两个嵌入向量长度可能过长,从而影响Faiss的效率。下面提供提速方案:
降维: 使用降维技术,如PCA(主成分分析)或t-SNE,可以减少嵌入向量的维度,从而提高Faiss的计算效率。这种方法在保留主要特征的同时,降低了向量的长度和计算复杂度。
分层聚类: 对嵌入向量进行分层聚类,将相似的向量分组在一起。在检索阶段,我们可以先找到与查询向量最相似的簇,然后在该簇中找到最相似的向量。这样可以减少需要计算相似度的向量数量,从而提高检索速度。
近似最近邻搜索(Approximate Nearest Neighbor,ANN):对于高维空间中的最近邻搜索,可以使用近似最近邻算法,如Annoy、HNSW或BallTree等,它们在牺牲一定精度的前提下,可以大大加快搜索速度。
二值化嵌入向量:将嵌入向量二值化,使得每个元素只有0或1。这种表示方法可以大大降低存储和计算的复杂性,同时,我们可以使用汉明距离等快速计算方法来检索相似向量。
量化(Quantization):量化是一种有损压缩技术,它可以将嵌入向量中的实数值映射到一组有限的离散值,从而降低存储和计算成本。常见的量化方法包括标量量化(Scalar Quantization)和乘积量化(Product Quantization)等。
利用局部敏感哈希(Locality-Sensitive Hashing,LSH):LSH是一种哈希方法,它将相似的数据项映射到相同的哈希桶中。通过使用LSH,我们可以在较低的计算成本下找到近似的最近邻向量。
分布式计算:通过将计算任务分配到多个计算节点上进行处理,可以有效提高搜索速度。我们可以使用分布式计算框架(如Apache Spark或Dask等)将FFM召回模型部署在一个集群环境中,从而提高计算效率。
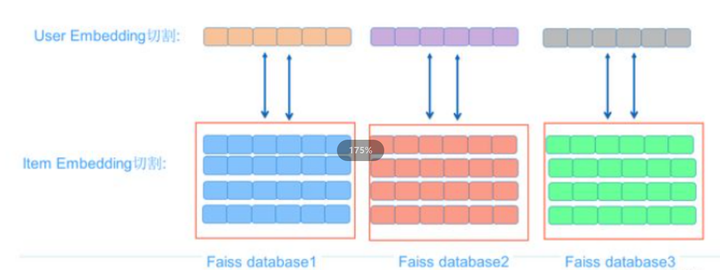
编辑切换为居中
添加图片注释,不超过 140 字(可选)
并行拉取提速策略
使用上述方法构建FFM召回模型时,可能会遇到用户和广告的embedding长度过长,导致Faiss提取速度减慢,从而使该方法因速度太慢而变得不切实际。为了加速这个过程,我们可以采用一种直接的方法:将过长的用户embedding分割成连续片段,同时将广告embedding也进行相应的分割。同一个物品的embedding片段可以分别存储在不同的Faiss数据库中。这样做的好处是,由于减少了embedding的长度,将大大提高Faiss的提取速度。
在返回结果时,我们需要合并针对每个用户embedding片段召回的物品子集。对于同一个广告,将各个片段的内积得分累加,便可以计算出该广告相对于用户的FFM最终得分。可以推断出,这种片段得分累加策略与直接计算长向量内积的结果是相同的。按照这个得分对返回的物品进行重新排序,我们就能得到最终的计算结果。这是一种典型的并行策略。
理论上,这个方案能够处理相当长的embedding匹配问题。然而,这个方案存在一个问题:它不能保证返回结果的最终排序与真实排序完全一致。这是因为可能存在某些综合总得分较高的广告没有被从任何一个Faiss子数据库中召回。例如,在某个物品的每个片段得分都不太高也不太低的情况下,就有可能发生这种漏召回的情况。
编辑切换为居中
添加图片注释,不超过 140 字(可选)
FM/FFM混合提速策略
在介绍FM召回模型的时候,可以看出,它的一个特别简洁的方式是把用户侧的特征embedding累加,以及广告侧的特征embedding累加,所以FM多出来的两个embedding长度,只跟k相关,跟特征数目没关系,无论多少特征,embedding size恒等于k。所以看着特别简洁,效率也高。
FM是否能够参照FM的思路,把一部分特征的embedding累加起来,通过这种方式来减小用户侧或广告侧的embedding大小呢?
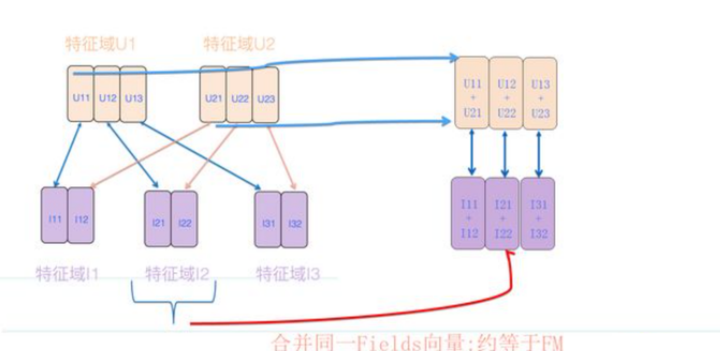
然而,如果我们不拘泥于FFM的计算原则,那么这个方法是可行的。参考上图,不同用户侧的特征,对应Fileds的向量直接累加;而在广告侧,同一个特征域的向量直接累加。这样可以保证用户embedding和广告embedding大小一致。例如,当用户侧和广告侧的embedding大小为M * K时,如M = 50,K = 10,那么长度为500,这样的长度可以保证计算速度。
参照上述做法,我们实际上做了这样一个事情:用户侧的特征仍然遵循FFM的计算原则,即每个特征针对其他不同特征域的组合采用不同的特征向量;但是,广告侧的特征向量因为同一个特征域的(F-1)个特征域合并成一个,这里采取了类似FM的特征embedding思路。因此,这个方法看起来像是处于FFM和FM模型之间的一种混合模型。其效果可能优于FM,但不如FFM,介于两者之间。
上述方法是基于合并广告侧同一个特征域的特征向量来实现的。我们也可以反过来,合并用户侧的同一个特征域的特征向量。这样,embedding大小将为N * K
FFM模型中每个v的维度k为128。用户侧有两个field,广告侧有三个field。整体用户侧的embedding大小为2 * 3 * 128 = 6 * k。
混合模式中,我们可以将用户侧的不同field进行累加。例如,用户侧的field1有3个v向量[1, 2, 3],field2也有3个v向量[1, 2, 3]。首先,我们将这两个field的相同位置的v向量相加,得到新的向量[2, 4, 6]。然后,我们将用户侧的两个field分别相加,得到一个长度为2 * k的向量[6, 6]。
对于广告侧,我们采用FM的方法。例如,广告侧的field1有2个v向量[1, 2],field2有2个v向量[1, 2],field3有2个v向量[1, 2]。接着,我们将三个field的相同位置的v向量相加,得到新的向量[3, 3, 3]。我们将广告侧的三个field分别相加,广告侧变成了一个长度为3 * k的向量[3, 6]。
通过这种混合模式,我们将原始的6 * k大小的用户侧embedding和3 * k大小的广告侧embedding分别缩减成了2 * k和3 * k大小的向量。这样的变化可以提高计算速度,但可能会影响模型的性能。这种方法实际上是介于FFM和FM之间的一种混合模型。
FM(Factorization Machine)模型中,我们可以通过将用户侧的所有特征相加来得到一个k维的embedding,同样地,我们也可以将广告侧的所有特征相加来得到一个k维的embedding。这样,对于用户侧的embedding(记作U)和广告侧的embedding(记作V),我们可以计算二者之间的点积作为相似度。
召回阶段,我们将用户侧的embedding U 和广告侧的embedding V 进行点积运算,得到一个表示相似度的标量值(即U·V)。基于这个相似度值,我们可以对广告进行排序,从而得到与用户相关性最高的广告列表。这种方法在FM模型中被用于评估用户和广告之间的相似度,从而实现召回和推荐。
在机器学习中,我们关注模型的偏差(bias)和方差(variance),因为它们与模型的泛化能力有关。我们希望找到一个偏差小、方差小的模型,这样模型在预测新数据时能够取得较好的效果。这里对不同情况进行解释:
偏差小,方差大:模型在训练集上拟合得很好,但在测试集上表现不佳。这种情况通常称为过拟合(overfitting),意味着模型过于复杂,捕捉了训练数据中的噪声,而没有很好地泛化到新数据。
偏差大,方差小:模型在训练集上拟合得不好,但在测试集上表现还可以。这种情况通常称为欠拟合(underfitting),意味着模型过于简单,没有捕捉到数据中的关键信息。
偏差大,方差大:这种模型在训练集和测试集上都表现不佳,通常被认为是不可用的。
当我们使用一个复杂的模型来处理非常少量的数据时,很容易出现过拟合现象。为了解决这个问题,我们可以采用正则化(regularization)等技术,以限制模型的复杂度。同时,我们还可以尝试收集更多的数据,以提高模型的泛化能力。
FFM是否可以将排序和召回一体化
我们已经讨论过如何使用FFM模型作为召回模型,但我们发现FFM模型的一个主要问题是其复杂性较高。这种复杂性主要体现在召回阶段的用户Embedding长度过长。假设用户侧有M个特征域,广告侧有N个特征域,单个特征的embedding向量大小为K,那么在不考虑上下文特征域的情况下,用户Embedding的尺寸将是M*N*K。这个长度很容易变得难以控制。
如果Embedding长度过长,单机版本的Faiss搜索速度将无法满足需求,这将导致整个方案变得不可行。然而,如果Embedding长度可以接受,并且Faiss的速度足够快,那么这个方案就有可能成功。因此,关键在于M、N和K的具体取值。
所以问题就变成了:在实际应用中,M(用户侧特征域数量)、N(广告侧特征域数量)和K(单个特征embedding向量大小)分别大约是多少?
以工业级的CTR数据集Criteo为例(包含4500万条数据,39个特征域,为了方便计算,我们假设有40个特征域)。首先考虑K,即单个特征向量的大小。在Criteo这种大规模数据集下,实验证明K=8时效果最佳。如果FFM模型仅用于召回阶段,后面还会接一个排序模型,也就是两阶段模式,此时可以将K设置得较小,如2到4,因为推荐的精确性还可以依赖排序模型来保证。然而,如果我们希望FFM模型同时完成召回和排序任务,那么K不能设置得太小,应为8,否则推荐效果会受到影响。
接下来讨论M和N。假设我们仍然使用Criteo数据集,它有40个特征域,我们再假设这些特征域在用户侧和广告侧平均分布,即:M=N=20。
因此,如果使用FFM模型来实现Criteo数据的召回模型,计算出的用户侧Embedding大小为:MNK=20*20*8=3200。如果使用单机版本的Faiss,搜索速度可能无法满足需求。然而,如果采用之前提到的将用户侧Embedding进行分布式切割的方法,例如将Embedding切成10份,速度应该可以接受,但这可能对推荐精度产生影响。
当然,我们还可以考虑采用前文提到的(FM+FFM)混合版本。在这种情况下,用户侧Embedding大小为MK或NK。对于Criteo数据集,这个长度将是160,对于Faiss来说,速度绝对不成问题,因此可以作为一体化模型。然而,预计这种方法的效果可能不如原版FFM模型。
此外,如果排序模型包含ID特征,FFM召回模型可能难以承担这一重任。
稀疏性问题:ID特征通常具有很高的稀疏性,例如用户ID和物品ID。在实际场景中,ID数量可能非常庞大,导致FFM模型的参数规模急剧增长。这将增加模型的计算复杂度和存储需求,从而降低模型训练和推荐的效率。
泛化能力:ID特征的稀疏性可能导致FFM模型在训练过程中无法充分学习到每个ID特征的有效信息。这使得FFM模型在面对新ID或冷启动问题时,泛化能力较弱,可能无法提供令人满意的推荐效果。
过拟合风险:由于ID特征的高度稀疏性,FFM模型可能更容易过拟合训练数据。过拟合可能导致模型在推荐过程中表现不佳,特别是对于那些在训练数据中很少出现或从未出现的ID。
要解决FFM召回模型在包含ID特征时的挑战,可以尝试以下策略:
特征工程:对ID特征进行预处理,将稀疏的ID特征转换为更容易处理的连续或离散特征。例如,可以将ID特征通过哈希(hashing)或embedding降维,以减少特征空间的大小并提高模型的泛化能力。
引入辅助信息:为ID特征引入额外的辅助信息,例如用户画像、物品类别等。这样可以帮助模型更好地理解ID特征背后的语义信息,从而提高泛化能力和推荐效果。
集成模型:可以将FFM模型与其他模型集成,以利用各自的优势并提高推荐性能。例如,可以将FFM模型与基于内容的推荐模型或协同过滤模型相结合,以提高推荐的准确性和覆盖率。
正则化和模型选择:在模型训练过程中引入正则化项,例如L1或L2正则化,以降低模型复杂度并减少过拟合的风险。此外,可以通过交叉验证等方法进行模型选择,以确定最佳的超参数配置。
使用深度学习模型:考虑使用深度学习模型,如深度神经网络(DNN)或卷积神经网络(CNN),来处理稀疏的ID特征。这些模型通常具有较强的特征提取能力,可以从稀疏的ID特征中提取有效信息,并在推荐任务中实现较好的泛化能力。
分层模型:将召回和排序任务分开处理,针对ID特征的挑战分别设计和优化模型。这样可以降低单个模型的复杂性,从而更好地应对ID特征带来的挑战。
通过上述实际例子,我们可以得出结论:能否使用FFM模型作为一体化广告模型实际上取决于任务的复杂度,也就是特征域的数量。显然,如果特征域数量较少,那么FFM模型是可行的;如果特征域数量较多,那么这种方法将不可行。除非你愿意采用embedding分段切割方式牺牲精度,或者采用(FM+FFM)混合版本,但这也可能会损失精度。
import tensorflow as tf
class Model:
def __init__(self, p, f, k, output_dim, feature2field):
# 初始化参数
self.p = p # 特征数量
self.f = f # 字段数量
self.k = k # 向量的维度
self.output_dim = output_dim # 输出层维度
self.feature2field = feature2field # 特征到字段的映射
def inference(self, x):
# 线性层
with tf.variable_scope('linear_layer'):
# 定义偏置项
b = tf.get_variable(name="bias", shape=[self.output_dim], initializer=tf.zeros_initializer())
# 定义权重矩阵
w1 = tf.get_variable(name="w1", shape=[self.p, self.output_dim], initializer=tf.truncated_normal_initializer(mean=0, stddev=0.01))
# 计算线性部分
self.linear_term = tf.add(tf.matmul(x, w1), b)
# Field-aware Interaction 层
with tf.variable_scope("field_aware_interaction_layer"):
# 定义权重矩阵
v = tf.get_variable(name="v", dtype=tf.float32, shape=[self.p, self.f, self.k], initializer=tf.truncated_normal_initializer(mean=0, stddev=0.01))
# 初始化交互项
self.field_aware_interaction_terms = tf.constant(0, dtype=tf.float32)
# 计算交互项
for i in range(self.p):
for j in range(i + 1, self.p):
# 对于每对特征,计算它们的交互项
self.field_aware_interaction_terms += tf.multiply(
tf.reduce_sum(tf.multiply(v[i, self.feature2field[j]], v[j, self.feature2field[i]])),
tf.multiply(x[:, i], x[:, j])
)
# 计算 logits
self.y_logits = tf.add(self.linear_term, self.field_aware_interaction_terms)
# 计算预测概率
self.y_prob = tf.nn.softmax(self.y_logits)
return self.y_prob
Field-aware Interaction 层是一种用于建模特征之间交互关系的方法。它源于 Field-aware Factorization Machines (FFM) 模型,这是一种广泛应用于推荐系统和点击率预测等领域的机器学习模型。
在许多实际问题中,特征之间的交互关系可能对预测目标有重要影响。Field-aware Interaction 层的目的是捕捉不同特征组合之间的交互信息,从而提高模型的预测性能。
与传统的 Factorization Machines (FM) 模型相比,FFM 在处理特征交互时引入了"field"的概念。在这里,"field"可以理解为一组相关的特征,例如用户信息和物品信息。通过将特征映射到不同的 field,FFM 可以为每对特征组合学习不同的隐向量表示。这使得模型能够更好地捕捉特征之间的复杂交互关系,从而提高预测性能。
Field-aware Interaction 层的主要思想是使用隐向量表示来建模特征之间的交互关系。对于每对特征 i 和 j,模型会学习两个隐向量表示:v[i, self.feature2field[j]] 和 v[j, self.feature2field[i]]。通过计算这两个隐向量的点积并乘以特征值,可以得到特征 i 和 j 之间的交互项。最后,将所有交互项相加,就可以得到 Field-aware Interaction 层的输出。
LightGBM+FFM
import numpy as np
import pandas as pd
import lightgbm as lgb
import xlearn as xl
from sklearn.metrics import log_loss
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
# 数据加载
def load_data():
data = pd.read_csv('sample_data.csv')
return data
# 特征工程
def feature_engineering(data):
categorical_features = ['cat1', 'cat2', 'cat3']
numerical_features = ['num1', 'num2', 'num3']
for col in categorical_features:
le = LabelEncoder()
data[col] = le.fit_transform(data[col])
return data, categorical_features, numerical_features
# GBDT训练
def train_gbdt(data, categorical_features, numerical_features):
X = data[numerical_features + categorical_features]
y = data['label']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
params = {
'task': 'train',
'boosting_type': 'gbdt',
'objective': 'binary',
'metric': 'binary_logloss',
'num_leaves': 31,
'learning_rate': 0.05,
'feature_fraction': 0.9,
'bagging_fraction': 0.8,
'bagging_freq': 5,
'verbose': 0
}
lgb_train = lgb.Dataset(X_train, y_train)
lgb_eval = lgb.Dataset(X_test, y_test, reference=lgb_train)
gbm = lgb.train(params,
lgb_train,
num_boost_round=100,
valid_sets=lgb_eval,
early_stopping_rounds=10)
leaf_indices_train = gbm.predict(X_train, pred_leaf=True)
leaf_indices_test = gbm.predict(X_test, pred_leaf=True)
return leaf_indices_train, leaf_indices_test, y_train, y_test
# FFM训练
def train_ffm(leaf_indices_train, leaf_indices_test, y_train, y_test):
ffm_train = pd.concat([pd.DataFrame(leaf_indices_train), y_train.reset_index(drop=True)], axis=1)
ffm_test = pd.concat([pd.DataFrame(leaf_indices_test), y_test.reset_index(drop=True)], axis=1)
ffm_train.to_csv('ffm_train.txt', sep='\t', index=False, header=False)
ffm_test.to_csv('ffm_test.txt', sep='\t', index=False, header=False)
ffm_model = xl.create_ffm()
ffm_model.setTrain('ffm_train.txt')
ffm_model.setValidate('ffm_test.txt')
param = {'task': 'binary', 'lr': 0.1, 'lambda': 0.0002, 'metric': 'logloss'}
ffm_model.fit(param, './model.out')
# FFM模型预测
ffm_model.setTest('ffm_test.txt')
ffm_model.setSigmoid()
ffm_model.predict('./model.out', 'ffm_output.txt')
# 读取FFM预测结果
with open('ffm_output.txt', 'r') as f:
ffm_preds = [float(line.strip()) for line in f.readlines()]
return np.array(ffm_preds)
# 计算logloss评估指标
def evaluate(y_true, y_preds):
loss = log_loss(y_true, y_preds)
return loss
if __name__ == '__main__':
# 加载数据
data = load_data()
# 特征工程
data, categorical_features, numerical_features = feature_engineering(data)
# GBDT训练
leaf_indices_train, leaf_indices_test, y_train, y_test = train_gbdt(data, categorical_features, numerical_features)
# FFM训练与预测
ffm_preds = train_ffm(leaf_indices_train, leaf_indices_test, y_train, y_test)
# 评估模型
logloss = evaluate(y_test, ffm_preds)
print('GBDT + FFM模型的logloss为:', logloss)
参考实验数据
https://maimai.cn/article/detail?fid=521052871&efid=0hRqgIAmhpuWtCUJpiZeQA
FTRL
import pandas as pd
from vowpalwabbit.sklearn_vw import VWClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import log_loss
from sklearn.preprocessing import LabelEncoder, MinMaxScaler
# 数据加载
def load_data():
data = pd.read_csv('sample_data.csv')
return data
# 特征工程
def feature_engineering(data):
categorical_features = ['cat1', 'cat2', 'cat3']
numerical_features = ['num1', 'num2', 'num3']
for col in categorical_features:
le = LabelEncoder()
data[col] = le.fit_transform(data[col])
for col in numerical_features:
scaler = MinMaxScaler()
data[col] = scaler.fit_transform(data[col].values.reshape(-1, 1))
return data, categorical_features, numerical_features
# 准备Vowpal Wabbit格式数据
def prepare_vw_data(data, categorical_features, numerical_features):
data['cat_features'] = data[categorical_features].apply(
lambda row: ' '.join([f"{col}:{row[col]}" for col in categorical_features]), axis=1)
data['num_features'] = data[numerical_features].apply(
lambda row: ' '.join([f"{col}:{row[col]}" for col in numerical_features]), axis=1)
vw_data = data['label'].astype(str) + ' |C ' + data['cat_features'] + ' |N ' + data['num_features']
return vw_data
# 训练FTRL模型
def train_ftrl(vw_train, vw_test, y_train, y_test):
model = VWClassifier(loss_function='logistic', link='logistic', ftrl=True)
model.fit(vw_train, y_train)
preds = model.predict_proba(vw_test)[:, 1]
return preds
# 计算logloss评估指标
def evaluate(y_true, y_preds):
loss = log_loss(y_true, y_preds)
return loss
if __name__ == '__main__':
# 加载数据
data = load_data()
# 特征工程
data, categorical_features, numerical_features = feature_engineering(data)
# 准备Vowpal Wabbit格式数据
vw_data = prepare_vw_data(data, categorical_features, numerical_features)
# 划分数据集
vw_train, vw_test, y_train, y_test = train_test_split(vw_data, data['label'], test_size=0.2, random_state=42)
# 训练FTRL模型
preds = train_ftrl(vw_train, vw_test, y_train, y_test)
# 评估模型
logloss = evaluate(y_test, preds)
print('FTRL模型的logloss为:', logloss)
DeepFM
import pandas as pd
import numpy as np
from sklearn.metrics import log_loss
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder, MinMaxScaler
from deepctr.models import DeepFM
from deepctr.feature_column import SparseFeat, DenseFeat, get_feature_names
# 数据加载
def load_data():
data = pd.read_csv('sample_data.csv')
return data
# 特征工程
def feature_engineering(data):
categorical_features = ['cat1', 'cat2', 'cat3']
numerical_features = ['num1', 'num2', 'num3']
for col in categorical_features:
le = LabelEncoder()
data[col] = le.fit_transform(data[col])
for col in numerical_features:
scaler = MinMaxScaler()
data[col] = scaler.fit_transform(data[col].values.reshape(-1, 1))
return data, categorical_features, numerical_features
# 构建DeepFM模型
def build_deepfm_model(data, categorical_features, numerical_features):
sparse_feature_columns = [SparseFeat(feat, vocabulary_size=data[feat].nunique(), embedding_dim=4)
for feat in categorical_features]
dense_feature_columns = [DenseFeat(feat, 1) for feat in numerical_features]
feature_names = get_feature_names(sparse_feature_columns + dense_feature_columns)
return DeepFM(sparse_feature_columns + dense_feature_columns, feature_names)
# 训练DeepFM模型
def train_deepfm(model, data, categorical_features, numerical_features):
X = data[categorical_features + numerical_features]
y = data['label']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['binary_crossentropy'])
model.fit(X_train, y_train, epochs=10, batch_size=256, validation_data=(X_test, y_test))
preds = model.predict(X_test)
return preds.flatten(), y_test
# 计算logloss评估指标
def evaluate(y_true, y_preds):
loss = log_loss(y_true, y_preds)
return loss
if __name__ == '__main__':
# 加载数据
data = load_data()
# 特征工程
data, categorical_features, numerical_features = feature_engineering(data)
# 构建DeepFM模型
model = build_deepfm_model(data, categorical_features, numerical_features)
# 训练DeepFM模型
preds, y_test = train_deepfm(model, data, categorical_features, numerical_features)
# 评估模型
logloss = evaluate(y_test, preds)
print('DeepFM模型的logloss为:', logloss)