使用支持向量机的基于异常的入侵检测系统
- 使用支持向量机的基于异常的入侵检测系统
- 学习目标:
- 学习内容:
- 1.⼀种智能⼊侵检测系统
- 第⼀阶段
- 第⼆阶段:分类
- 总结
- 2.使用支持向量机的基于异常的入侵检测系统
- 1.预处理入侵数据集
- 2.基于信息增益的特征排名
- 3.分类器优化
- 4.使用 RBF-SVM 的检测模型
- 总结
- 参考论文
申明: 未经许可,禁止以任何形式转载,若要引用,请标注链接地址。 全文共计3685字,阅读大概需要3分钟
更多学习内容, 欢迎关注我的个人公众号:不懂开发的程序猿
使用支持向量机的基于异常的入侵检测系统
学习目标:
-
1.An intelligent intrusion detection system(⼀种智能⼊侵检测系统)
-
2.Anomaly-Based Intrusion Detection System Using Support Vector Machine(使用支持向量机的基于异常的入侵检测系统)
学习内容:
1.⼀种智能⼊侵检测系统
(An intelligent intrusion detection system)
第一阶段,IDS 使⽤ K-Means 检测攻击,
第⼆阶段,使⽤监督学习对此类攻击进行分类并消除误报的数量。
数据集:KDD
数据预处理⽅法:
-
⾸先,计算特征值的⽅差以测量该数据集中特征之间的分布。⽬标是将低方差的过滤掉。
-
其次,我们计算并去除了相关特征以避免过拟合。当之间的相关系数两个特征接近于1,那么删除密切相关的特征有助于从模型中消除偏差。
-
第三,使⽤最⼩⼆乘回归误差(LSQE)最⼩化特征相似性和减小最⼤化维度
-
第四,等式
e ( x , y ) = v a r ( x ) ∗ ( 1 − r e l a t i o n ( x , y ) 2 ) e(x,y)=var(x) * (1 - relation(x,y)^2) e(x,y)=var(x)∗(1−relation(x,y)2)
基本上衡量了关系在两个特征 x 和 y 之间。如果这些特征具有线性关系则 e(x, y) 将为 0,如果它们没有那么 e(x, y) 将等于 var(x)。
- 最后,最⼤信息压缩指数(MICI)也⽤于分析特征关系
λ 2 ( x , y ) = m i n ( e i g v ( Σ ) ) λ_2(x,y)=min(eigv(Σ)) λ2(x,y)=min(eigv(Σ))
当 MICI 为 0 时,那么特征具有线性关系。
特征数从 41 减少到 30
第⼀阶段
使⽤ K-Means 模型对数据进行聚类和检测攻击,是简单地检测是否有攻击,可以承受误报攻击,完成这个分类,建⽴了两个低簇间相似性和良好的簇内相似性,将 n 个观测值处理成 2 个簇,查看预处理的数据特征并将它们放置成簇。分成两个集群(攻击和正常)
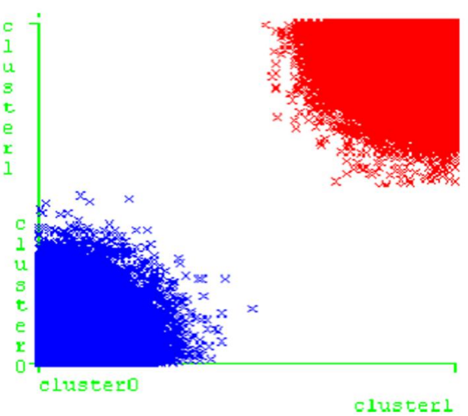
第⼆阶段:分类
在这个阶段,⽬标是降低误报率并提⾼准确性
J48 是⼀种基于决策树的算法,⽤于对数据进行分类,该算法利⽤信息熵构建决策树,基于C4.5决策树,。在构建树时,J48 会根据信息增益选择属性,熵值计算公式:
E
n
t
r
o
p
y
=
Σ
i
c
−
p
i
∗
l
o
g
2
(
p
i
)
Entropy=Σ^c_i - p_i * log_2(p_i)
Entropy=Σic−pi∗log2(pi)
计算信息增益率。增益基本上是先验熵(T)和所选分⽀的熵(X)之差。
增
益
(
T
,
X
)
=
熵
(
T
)
−
熵
(
X
)
增益(T,X)=熵(T)-熵(X)
增益(T,X)=熵(T)−熵(X)
计算每个候选属性的增益后,根据信息增益最⾼的属性对数据进行拆分。⼀旦攻击信息增益最多的特征落⼊错误的分⽀,J48 的性能就不会很好。
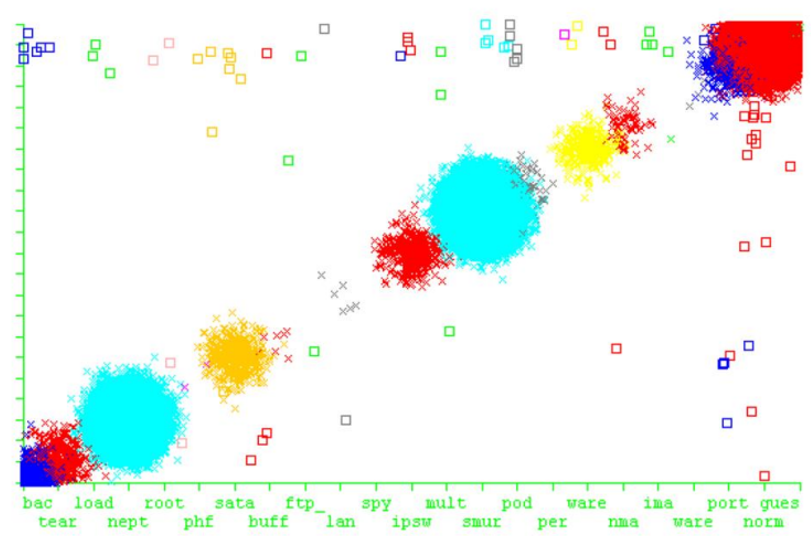
总结
优点:J48 是⼀种容易实现和可视化的算法。由于它基于C4.5,所以它在具有两个以上类别的离散数据中表现良好,计算要求低
在查看训练计算要求时,通常 J48 需要更多的时间和内存来进行训练,如果⽆法正确配置 J48 决策树,输出⼀个复杂的树,它的性能很差并且需要很⾼的计算能力
2.使用支持向量机的基于异常的入侵检测系统
(Anomaly-Based Intrusion Detection System Using Support Vector Machine)
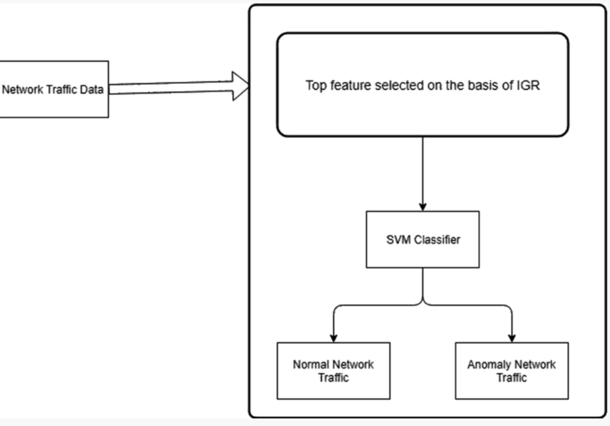
1.预处理入侵数据集
本实验使用 NSL-KDD 数据集进行评估,共有 41 个特征,其中 34 个是数字的,7 个是符号的,因为 SVM 分类器不能使用其基本形式的数据集特征。因此,我们需要将符号数据转换为数字形式,并借助 min–max scalar(在 python 中)将其放入固定范围(-1, 1),最后将其映射为正常或异常。
2.基于信息增益的特征排名
特征排名是通过使用过滤器信息增益比来完成的,当特征对应于特定类时,熵的值较小。当特征对应多个类时,熵值更大。具有高信息增益值的特征被认为是对会话数据进行分类最重要的,信息增益比 (IGR) 是一个定量值,用于根据数据集中这些特征的值对特征进行优先级排序。
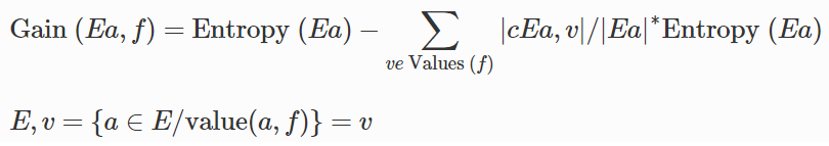
3.分类器优化
在基本分类中,我们使用以直线作为超平面的线性 SVM,但并非总是如此。为了减少误报的数量,我们需要一个非线性内核—径向基函数(Radial Basis Function)
RBF 用于超平面取决于最近点的地方,旨在减少误报的数量。它的值取决于两个主要因素,C——也称为惩罚因子,较高的C值具有较高的复杂性,较低的C值具有较低的复杂性。Gamma 是核系数。高 gamma 值对超平面上较远的点的影响更大,而低 gamma 值对更近的点的影响更大
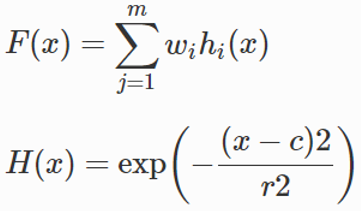
其中r是标准偏差,x – c是从给定点到现有点中心的距离
4.使用 RBF-SVM 的检测模型
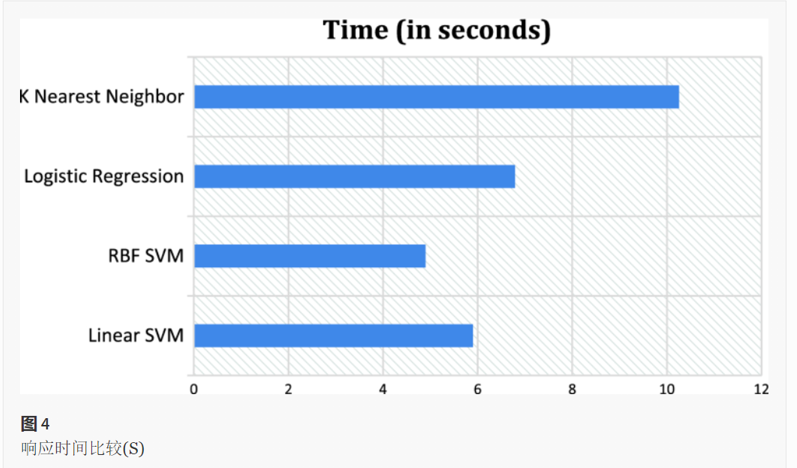
总结
这2篇可以结合起来考虑一下,数据预处理部分计算特征值的⽅差过滤部分数据再计算Gini指数熵进行特征排序,分类器部分对常规的线性超平面的SVM优化,用RBF-SVM来做。
参考论文
[1] Bendale S, Prasad J. Preliminary study of Software Defined Network on COVID-19 pandemic use cases[J]. Available at SSRN 3612815, 2020.
[2] Ajaeiya G A, Adalian N, Elhajj I H, et al. Flow-based intrusion detection system for SDN[C]//2017 IEEE Symposium on Computers and Communications (ISCC). IEEE, 2017: 787-793.
[3] Le D H, Tran H A. A novel Machine Learning-based Network Intrusion Detection System for Software-Defined Network[C]//2020 7th NAFOSTED Conference on Information and Computer Science (NICS). IEEE, 2020: 25-30.
[4] Kaja N, Shaout A, Ma D. An intelligent intrusion detection system[J]. Applied Intelligence, 2019, 49(9): 3235-3247.
[5] Kevric J, Jukic S, Subasi A. An effective combining classifier approach using tree algorithms for network intrusion detection[J]. Neural Computing and Applications, 2017, 28(1): 1051-1058.
[6] Saleh, A.I., Talaat, F.M. & Labib, L.M. A hybrid intrusion detection system (HIDS) based on prioritized k-nearest neighbors and optimized SVM classifiers. Artif Intell Rev 51, 403–443 (2019). https://doi.org/10.1007/s10462-017-9567-1
–end–