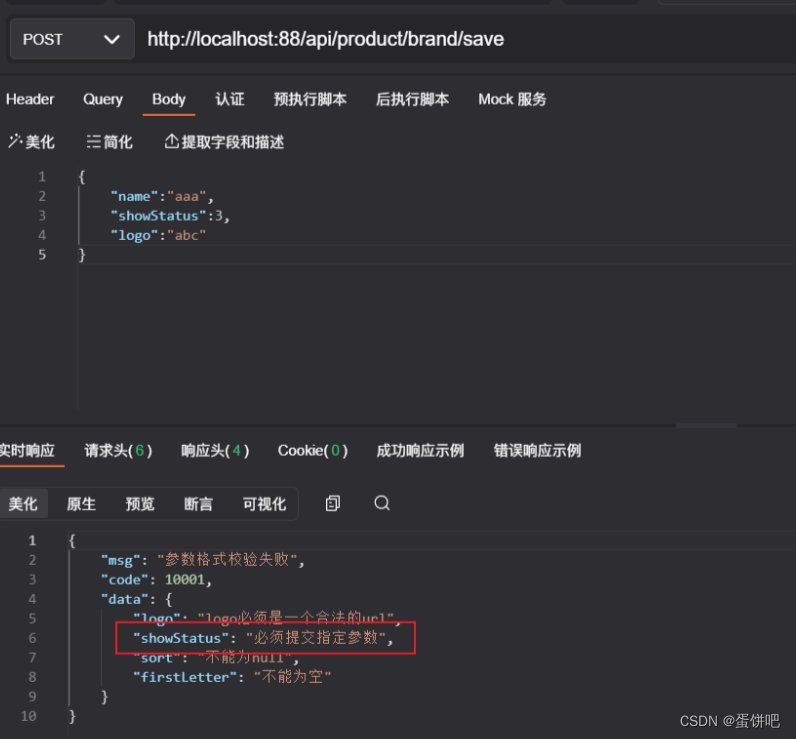
Watermark机制
Watermark机制,就是水印机制,也叫做水位线机制。就是专门用来解决流式环境下数据迟到问题的。
MonotonousWatermark(单调递增水印)
package day05;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
/**
* @desc: 需求:从socket获取数据,转换成水位传感器类,基于事件时间,每5秒生成一个滚动窗口,来计算传感器水位信息
* 定义类 WaterSensor
* String id --id
* Integer vc --value count
* Long ts --timestamp
* TODO 演示单调递增水印monotonousWatermark
*/
public class Demo01_MonotonousWatermark {
public static void main(String[] args) throws Exception {
//1.构建流式执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//2.数据输入
DataStreamSource<String> source = env.socketTextStream("node1", 9999);
//3.数据处理
// //3.1 把数据转换成WaterSensor对象
SingleOutputStreamOperator<WaterSensor> mapStream = source.map(new MapFunction<String, WaterSensor>() {
@Override
public WaterSensor map(String value) throws Exception {
//lines就是转换后的数组类型,数组的长度为3,分别表示:
// String id
// Integer vc
// Long ts
String[] lines = value.split(",");
return new WaterSensor(lines[0], Integer.parseInt(lines[1]), Long.parseLong(lines[2]));
}
});
// //3.2 分配watermark(演示常用的watermark水印)
SingleOutputStreamOperator<WaterSensor> watermarks = mapStream
//forMonotonousTimestamps:单调递增水印
.assignTimestampsAndWatermarks(WatermarkStrategy.<WaterSensor>forMonotonousTimestamps()
.withTimestampAssigner(new SerializableTimestampAssigner<WaterSensor>() {
@Override
public long extractTimestamp(WaterSensor element, long recordTimestamp) {
return element.getTs() * 1000L;
}
}));
// 3.3 基于id分组
SingleOutputStreamOperator<String> result = watermarks.keyBy(value -> value.getId())
// 3.4 指定5秒的滚动窗口
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
// 3.5 进行数据处理(统计次数)process方法。
/**
* 参数1:输入的数据类型
* 参数2:输出的数据类型
* 参数3:分组的数据类型
* 参数4:时间窗口
*/
.process(new ProcessWindowFunction<WaterSensor, String, String, TimeWindow>() {
/**
* process方法介绍:
* @param key 根据key来分组
* @param context 窗口计算的上下文对象(可以从上下文对象获取窗口的一些额外信息)
* @param elements 窗口内的数据
* @param out 收集窗口的计算结果
* @throws Exception 异常抛出
*/
@Override
public void process(String key, Context context, Iterable<WaterSensor> elements, Collector<String> out) throws Exception {
out.collect("分组的key为:" + key +
"\n窗口内的数据为:" + elements +
"\n窗口内的数据量为:" + elements.spliterator().estimateSize() +
"\n窗口为:[" + context.window().getStart() + "," + context.window().getEnd() + ")\n");
}
});
//4.数据输出
result.print();
//5.启动流式任务
env.execute();
}
/**
* 创建水位传感器类:WaterSensor
* @Data:可以用来构建getter和setter方法
* 构造器:Java中有无参和有参的构造器(构造方法)
* @AllArgsConstructor:有参构造
* @NoArgsConstructor:无参构造
*/
@Data
@AllArgsConstructor
@NoArgsConstructor
public static class WaterSensor {
//用户id
private String id;
//水位信息
private Integer vc;
//时间戳
private Long ts;
}
}
运行结果如下:
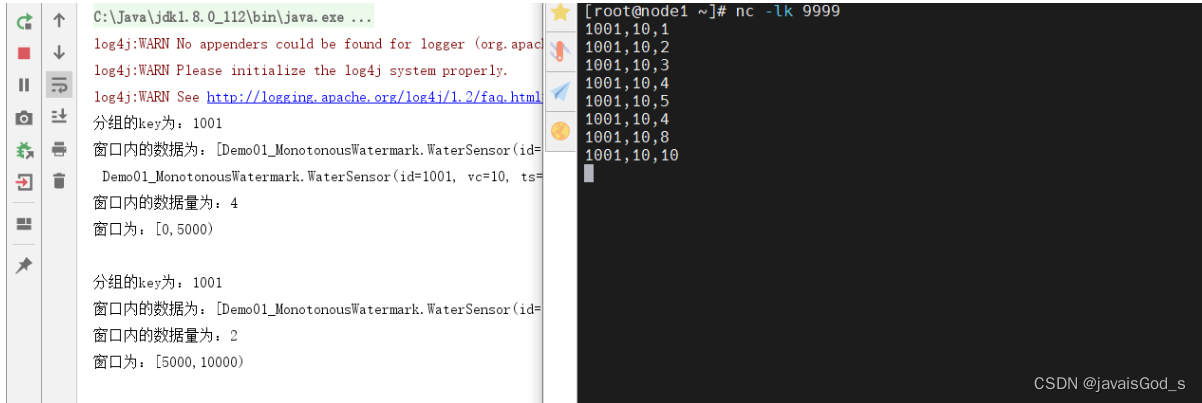
结论:
MonotonousWatermark(单调递增水印)会有数据丢失的情况。
BoundedOutofOrder(固定延迟水印)
package day05;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
import java.time.Duration;
/**
* @desc: 需求:从socket获取数据,转换成水位传感器类,基于事件时间,每5秒生成一个滚动窗口,来计算传感器水位信息
* * 定义类 WaterSensor
* * String id --id
* * Integer vc --value count
* * Long ts --timestamp
* todo 演示固定延迟水印
*/
public class Demo02_BoundedOutofOrderWatermark {
public static void main(String[] args) throws Exception {
//1.构建流式执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//2.数据输入
DataStreamSource<String> source = env.socketTextStream("node1", 9999);
//3.数据处理
//3.1 把输入数据转换成WaterSensor对象
SingleOutputStreamOperator<WaterSensor> mapStream = source.map(value -> {
String[] lines = value.split(",");
return new WaterSensor(lines[0], Integer.parseInt(lines[1]), Long.parseLong(lines[2]));
//返回时需要使用自定义的类WaterSensor,写法如下:Types.GENERIC(WaterSensor.class)
}).returns(Types.GENERIC(WaterSensor.class));
/**
* 3.2 给数据添加固定延迟水印
* WatermarkStrategy.forBoundedOutOfOrderness(Duration.ofSeconds(2))
* 如上代码,2秒的固定延迟,允许数据乱序2秒。(延迟2秒到达)
*/
SingleOutputStreamOperator<WaterSensor> watermarks = mapStream
.assignTimestampsAndWatermarks(WatermarkStrategy.<WaterSensor>forBoundedOutOfOrderness(Duration.ofSeconds(2))
.withTimestampAssigner(new SerializableTimestampAssigner<WaterSensor>() {
@Override
public long extractTimestamp(WaterSensor element, long recordTimestamp) {
return element.getTs() * 1000L;
}
}));
//3.3 把数据进行分组
SingleOutputStreamOperator<String> result = watermarks.keyBy(value -> value.getId())
//3.4 分配滚动事件时间窗口,并且制定窗口大小为5秒钟
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
/**
* 3.5 对窗口内的数据进行处理
* @param <IN> The type of the input value. 输入数据类型
* @param <OUT> The type of the output value. 输出数据类型
* @param <KEY> The type of the key. key的类型
* @param <W> The type of {@code Window} that this window function can be applied on.窗口
*/
.process(new ProcessWindowFunction<WaterSensor, String, String, TimeWindow>() {
/**
*
* @param s 分组的key
* @param context 上下文对象,可以从上下文对象中获取其他信息
* @param elements 窗口内的元素(数据)
* @param out out收集器,用于结果输出
* @throws Exception 异常
*/
@Override
public void process(String s, Context context, Iterable<WaterSensor> elements, Collector<String> out) throws Exception {
out.collect("分组的key为:" + s +
"\n窗口内的数据:" + elements +
"\n窗口内的数据量为:" + elements.spliterator().estimateSize() +
"\n窗口起始时间为:[" + context.window().getStart() + "," + context.window().getEnd() + ")\n");
}
});
//4.数据输出
result.print();
//5.启动流式任务
env.execute();
}
/**
* 创建水位传感器类:WaterSensor
* @Data:可以用来构建getter和setter方法
* 构造器:Java中有无参和有参的构造器(构造方法)
* @AllArgsConstructor:有参构造
* @NoArgsConstructor:无参构造
*/
@Data
@AllArgsConstructor
@NoArgsConstructor
public static class WaterSensor {
//用户id
private String id;
//水位信息
private Integer vc;
//时间戳
private Long ts;
}
}
运行结果如下:
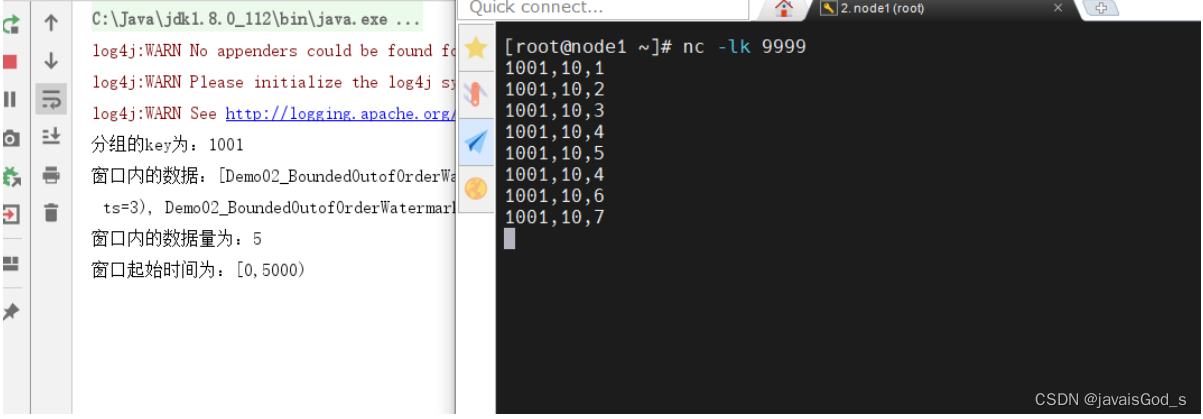
结论:
在固定延迟水印下,在一定范围内的数据迟到的情况下,可以正常统计。
AllowedLateness(在固定延迟水印下允许迟到)
package day05;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
import java.time.Duration;
/**
* @desc: 需求:从socket获取数据,转换成水位传感器类,基于事件时间,每5秒生成一个滚动窗口,来计算传感器水位信息
* * 定义类 WaterSensor
* * String id --id
* * Integer vc --value count
* * Long ts --timestamp
* todo 演示AllowedLateness
*/
public class Demo03_AllowedLateness {
public static void main(String[] args) throws Exception {
//1.构建流式执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//2.数据输入
DataStreamSource<String> source = env.socketTextStream("node1", 9999);
//3.数据处理
//3.1 把输入数据转换成WaterSensor对象
SingleOutputStreamOperator<WaterSensor> mapStream = source.map(value -> {
String[] lines = value.split(",");
return new WaterSensor(lines[0], Integer.parseInt(lines[1]), Long.parseLong(lines[2]));
//返回时需要使用自定义的类WaterSensor,写法如下:Types.GENERIC(WaterSensor.class)
}).returns(Types.GENERIC(WaterSensor.class));
/**
* 3.2 给数据添加固定延迟水印
* WatermarkStrategy.forBoundedOutOfOrderness(Duration.ofSeconds(2))
* 如上代码,2秒的固定延迟,允许数据乱序2秒。(延迟2秒到达)
*/
SingleOutputStreamOperator<WaterSensor> watermarks = mapStream
.assignTimestampsAndWatermarks(WatermarkStrategy.<WaterSensor>forBoundedOutOfOrderness(Duration.ofSeconds(2))
.withTimestampAssigner(new SerializableTimestampAssigner<WaterSensor>() {
@Override
public long extractTimestamp(WaterSensor element, long recordTimestamp) {
return element.getTs() * 1000L;
}
}));
//3.3 把数据进行分组
SingleOutputStreamOperator<String> result = watermarks.keyBy(value -> value.getId())
//3.4 分配滚动事件时间窗口,并且制定窗口大小为5秒钟
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
//allowedLateness,在固定延迟水印下,再允许你延迟的时间程度
.allowedLateness(Time.seconds(1))
/**
* 3.5 对窗口内的数据进行处理
* @param <IN> The type of the input value. 输入数据类型
* @param <OUT> The type of the output value. 输出数据类型
* @param <KEY> The type of the key. key的类型
* @param <W> The type of {@code Window} that this window function can be applied on.窗口
*/
.process(new ProcessWindowFunction<WaterSensor, String, String, TimeWindow>() {
/**
*
* @param s 分组的key
* @param context 上下文对象,可以从上下文对象中获取其他信息
* @param elements 窗口内的元素(数据)
* @param out out收集器,用于结果输出
* @throws Exception 异常
*/
@Override
public void process(String s, Context context, Iterable<WaterSensor> elements, Collector<String> out) throws Exception {
out.collect("分组的key为:" + s +
"\n窗口内的数据:" + elements +
"\n窗口内的数据量为:" + elements.spliterator().estimateSize() +
"\n窗口起始时间为:[" + context.window().getStart() + "," + context.window().getEnd() + ")\n");
}
});
//4.数据输出
result.print();
//5.启动流式任务
env.execute();
}
/**
* 创建水位传感器类:WaterSensor
* @Data:可以用来构建getter和setter方法
* 构造器:Java中有无参和有参的构造器(构造方法)
* @AllArgsConstructor:有参构造
* @NoArgsConstructor:无参构造
*/
@Data
@AllArgsConstructor
@NoArgsConstructor
public static class WaterSensor {
//用户id
private String id;
//水位信息
private Integer vc;
//时间戳
private Long ts;
}
}
运行结果如下:
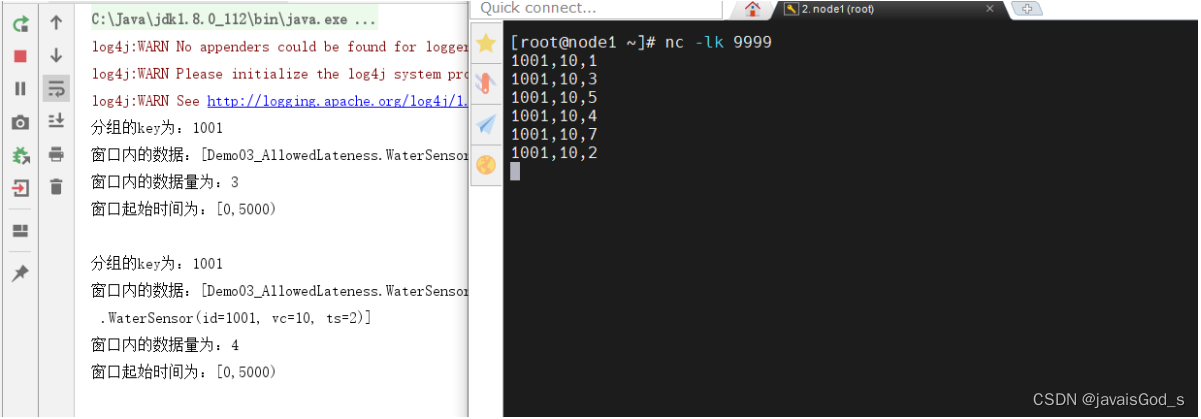
结论:
AllowedLateness,允许在固定延迟水印下,再次迟到的数据被捕获。
虽然Watermark会触发窗口计算,如果使用AllowedLateness,窗口就不会立刻销毁,
因此,数据的延迟时间在AllowedLateness的时间范围内,数据能够被正常处理。
窗口会在AllowedLateness设置的时间之后再销毁。
SideOutput(侧道输出)
package day05;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
import org.apache.flink.util.OutputTag;
import java.time.Duration;
/**
* @desc: 需求:从socket获取数据,转换成水位传感器类,基于事件时间,每5秒生成一个滚动窗口,来计算传感器水位信息
* * 定义类 WaterSensor
* * String id --id
* * Integer vc --value count
* * Long ts --timestamp
* todo 演示SideoutputTag(侧道输出)
*/
public class Demo04_SideOutputTag {
public static void main(String[] args) throws Exception {
//1.构建流式执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//2.数据输入
DataStreamSource<String> source = env.socketTextStream("node1", 9999);
//定义一个OutputTag对象,用于SideOutputLateData
OutputTag<WaterSensor> lateData = new OutputTag<>("lateData", Types.GENERIC(WaterSensor.class));
//3.数据处理
//3.1 把输入数据转换成WaterSensor对象
SingleOutputStreamOperator<WaterSensor> mapStream = source.map(value -> {
String[] lines = value.split(",");
return new WaterSensor(lines[0], Integer.parseInt(lines[1]), Long.parseLong(lines[2]));
//返回时需要使用自定义的类WaterSensor,写法如下:Types.GENERIC(WaterSensor.class)
}).returns(Types.GENERIC(WaterSensor.class));
/**
* 3.2 给数据添加固定延迟水印
* WatermarkStrategy.forBoundedOutOfOrderness(Duration.ofSeconds(2))
* 如上代码,2秒的固定延迟,允许数据乱序2秒。(延迟2秒到达)
*/
SingleOutputStreamOperator<WaterSensor> watermarks = mapStream
.assignTimestampsAndWatermarks(WatermarkStrategy.<WaterSensor>forBoundedOutOfOrderness(Duration.ofSeconds(2))
.withTimestampAssigner(new SerializableTimestampAssigner<WaterSensor>() {
@Override
public long extractTimestamp(WaterSensor element, long recordTimestamp) {
return element.getTs() * 1000L;
}
}));
//3.3 把数据进行分组
SingleOutputStreamOperator<String> result = watermarks.keyBy(value -> value.getId())
//3.4 分配滚动事件时间窗口,并且制定窗口大小为5秒钟
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
//allowedLateness,在固定延迟水印下,再允许你延迟的时间程度
.allowedLateness(Time.seconds(1))
//侧道输出:无论延迟多久的数据,都能够通过侧道输出来捕获
.sideOutputLateData(lateData)
/**
* 3.5 对窗口内的数据进行处理
* @param <IN> The type of the input value. 输入数据类型
* @param <OUT> The type of the output value. 输出数据类型
* @param <KEY> The type of the key. key的类型
* @param <W> The type of {@code Window} that this window function can be applied on.窗口
*/
.process(new ProcessWindowFunction<WaterSensor, String, String, TimeWindow>() {
/**
*
* @param s 分组的key
* @param context 上下文对象,可以从上下文对象中获取其他信息
* @param elements 窗口内的元素(数据)
* @param out out收集器,用于结果输出
* @throws Exception 异常
*/
@Override
public void process(String s, Context context, Iterable<WaterSensor> elements, Collector<String> out) throws Exception {
out.collect("分组的key为:" + s +
"\n窗口内的数据:" + elements +
"\n窗口内的数据量为:" + elements.spliterator().estimateSize() +
"\n窗口起始时间为:[" + context.window().getStart() + "," + context.window().getEnd() + ")\n");
}
});
//4.数据输出
result.print();
//获取迟到的数据,并且打印输出
result.getSideOutput(lateData).printToErr("超过AllowedLateness的数据:");
//5.启动流式任务
env.execute();
}
/**
* 创建水位传感器类:WaterSensor
* @Data:可以用来构建getter和setter方法
* 构造器:Java中有无参和有参的构造器(构造方法)
* @AllArgsConstructor:有参构造
* @NoArgsConstructor:无参构造
*/
@Data
@AllArgsConstructor
@NoArgsConstructor
public static class WaterSensor {
//用户id
private String id;
//水位信息
private Integer vc;
//时间戳
private Long ts;
}
}
运行结果如下:
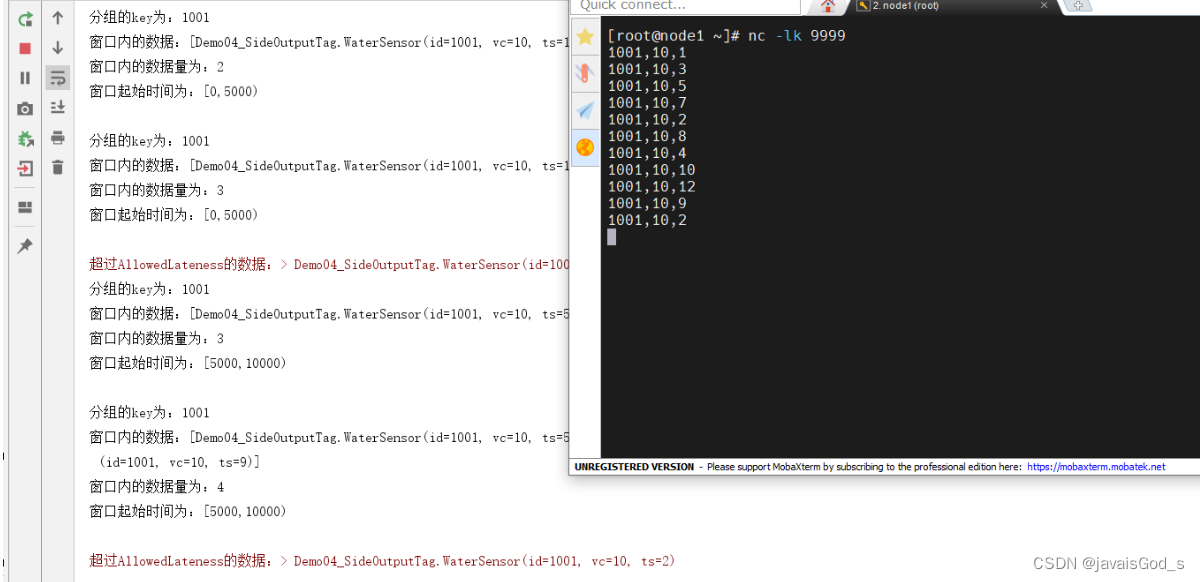
结论:
SideOutput侧道输出,可以允许数据在既超过了Watermark的时间,又超过了AllowedLateness的时间范围后,仍然被正常捕获。
也就是说,数据无论迟到多久,都不会丢失。
Checkpoint机制
Checkpoint机制,又叫容错机制,可以保证流式任务中,不会因为异常时等原因,造成任务异常退出。可以保证任务正常运行。
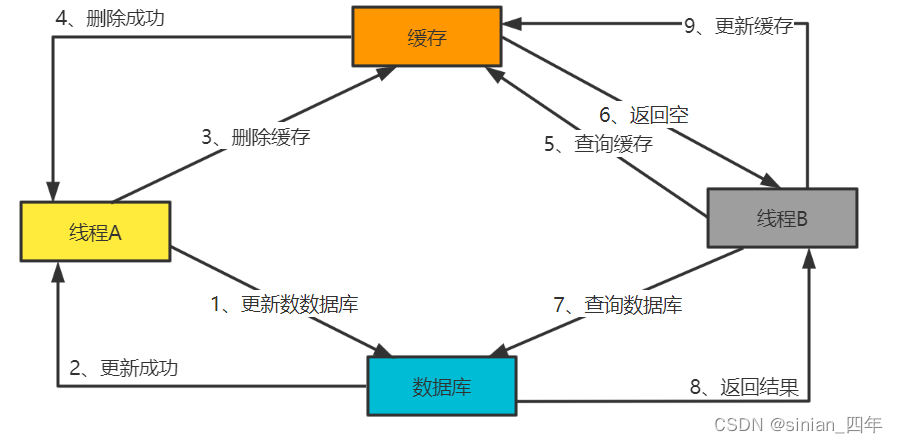
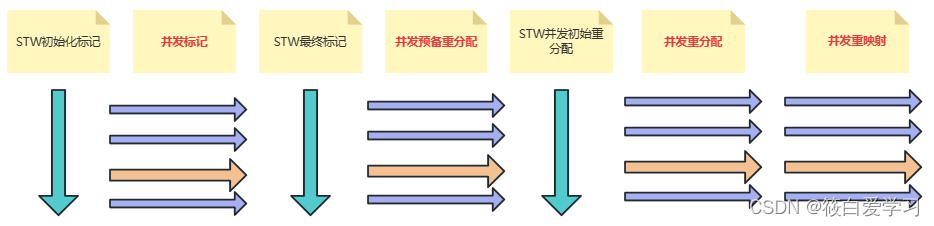
机制运行流程
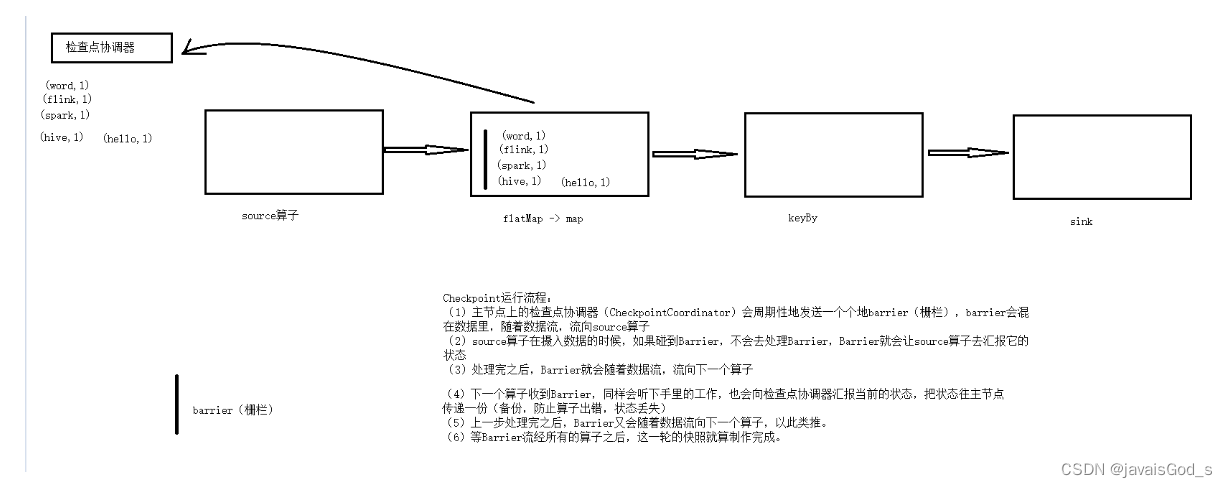
解释:
(1)主节点上的检查点协调器(CheckpointCoordinator)会周期性地发送一个个地Barrier(栅栏),Barrier会混在数据里,随着数据流,流向source算子
(2)source算子在摄入数据的时候,如果碰到Barrier栅栏,不会去处理,Barrier就会让算子去汇报当前的状态
(3)处理完之后,Barrier就会随着数据流,流向下一个算子
(4)下一个算子收到Barrier,同样会听下手里的工作,也会向检查点协调器汇报当前的状态,把状态往主节点传递一份(备份,防止算子出错,状态丢失) (5)上一步处理完之后,Barrier又会随着数据流向下一个算子,以此类推。 (6)等Barrier流经所有的算子之后,这一轮的快照就算制作完成。
状态后端
状态后端,StateBackend,就是Flink存储状态的介质。Flink提供了三种状态后端的存储方式:
-
MemoryStateBackend(内存)
内存,掉电易失。不安全。基本不用。
配置如下:
state.backend: hashmap
# 可选,当不指定 checkpoint 路径时,默认自动使用 JobManagerCheckpointStorage
state.checkpoint-storage: jobmanager
-
FsStateBackend(文件系统)
FsStateBackend,文件系统的状态后端,就是把状态保存在文件系统中,常用来保存状态的文件系统有HDFS。
配置如下:
state.backend: hashmap
state.checkpoints.dir: file:///checkpoint-dir/# 默认为FileSystemCheckpointStorage
state.checkpoint-storage: filesystem
-
RocksDBStateBackend(RocksDB数据库)
RocksDBStateBackend,把状态保存在RocksDB数据库中。
RocksDB,是一个小型文件系统的数据库。
配置如下:
state.backend: rocksdb
state.checkpoints.dir: file:///checkpoint-dir/# Optional, Flink will automatically default to FileSystemCheckpointStorage
# when a checkpoint directory is specified.
state.checkpoint-storage: filesystem
Flink的重启策略
Flink支持四种类型的重启策略:
-
none:没有重启。任务一旦遇到异常,就退出。
-
fixed-delay:固定延迟重启策略。也就是说,可以配置一个重启的次数。超过次数后,才会退出。
-
failure-rate:失败率重启策略。也就是说,任务的失败频率。超过该频率后才退出。在设定的频率之内,不会退出。
-
exponential-delay:指数延迟重启策略。也就是说,任务在失败后,下一次的延迟时间是随着指数增长的。
Checkpoint配置和重启策略的配置
execution.checkpointing.interval: 5000
#设置有且仅有一次模式 目前支持 EXACTLY_ONCE、AT_LEAST_ONCE
execution.checkpointing.mode: EXACTLY_ONCE
state.backend: hashmap
#设置checkpoint的存储方式
state.checkpoint-storage: filesystem
#设置checkpoint的存储位置
state.checkpoints.dir: hdfs://node1:8020/checkpoints
#设置savepoint的存储位置
state.savepoints.dir: hdfs://node1:8020/checkpoints
#设置checkpoint的超时时间 即一次checkpoint必须在该时间内完成 不然就丢弃
execution.checkpointing.timeout: 600000
#设置两次checkpoint之间的最小时间间隔
execution.checkpointing.min-pause: 500
#设置并发checkpoint的数目
execution.checkpointing.max-concurrent-checkpoints: 1
#开启checkpoints的外部持久化这里设置了清除job时保留checkpoint,默认值时保留一个 假如要保留3个
state.checkpoints.num-retained: 3
#默认情况下,checkpoint不是持久化的,只用于从故障中恢复作业。当程序被取消时,它们会被删除。但是你可以配置checkpoint被周期性持久化到外部,类似于savepoints。这些外部的checkpoints将它们的元数据输出到外#部持久化存储并且当作业失败时不会自动
清除。这样,如果你的工作失败了,你就会有一个checkpoint来恢复。
#ExternalizedCheckpointCleanup模式配置当你取消作业时外部checkpoint会产生什么行为:
#RETAIN_ON_CANCELLATION: 当作业被取消时,保留外部的checkpoint。注意,在此情况下,您必须手动清理checkpoint状态。
#DELETE_ON_CANCELLATION: 当作业被取消时,删除外部化的checkpoint。只有当作业失败时,检查点状态才可用。
execution.checkpointing.externalized-checkpoint-retention: RETAIN_ON_CANCELLATION
# 重启策略选一个
# 设置无重启策略
restart-strategy: none
# 设置固定延迟策略
restart-strategy: fixed-delay
# 尝试重启次数
restart-strategy.fixed-delay.attempts: 3
# 两次连续重启的间隔时间
restart-strategy.fixed-delay.delay: 3 s
# 设置失败率重启
restart-strategy: failure-rate
# 两次连续重启的间隔时间
restart-strategy.failure-rate.delay: 3 s
# 计算失败率的统计时间跨度
restart-strategy.failure-rate.failure-rate-interval: 1 min
# 计算失败率的统计时间内的最大失败次数
restart-strategy.failure-rate.max-failures-per-interval: 3
# 设置指数延迟重启
restart-strategy: exponential-delay
# 初次失败后重启时间间隔(初始值)
restart-strategy.exponential-delay.initial-backoff: 1 s
# 以后每次失败,重启时间间隔为上一次重启时间间隔乘以这个值
restart-strategy.exponential-delay.backoff-multiplier: 2
# 每次重启间隔时间的最大抖动值(加或减去该配置项范围内的一个随机数),防止大量作业在同一时刻重启
restart-strategy.exponential-delay.jitter-factor: 0.1
# 最大重启时间间隔,超过这个最大值后,重启时间间隔不再增大
restart-strategy.exponential-delay.max-backoff: 1 min
# 多长时间作业运行无失败后,重启间隔时间会重置为初始值(第一个配置项的值)
restart-strategy.exponential-delay.reset-backoff-threshold: 1 h