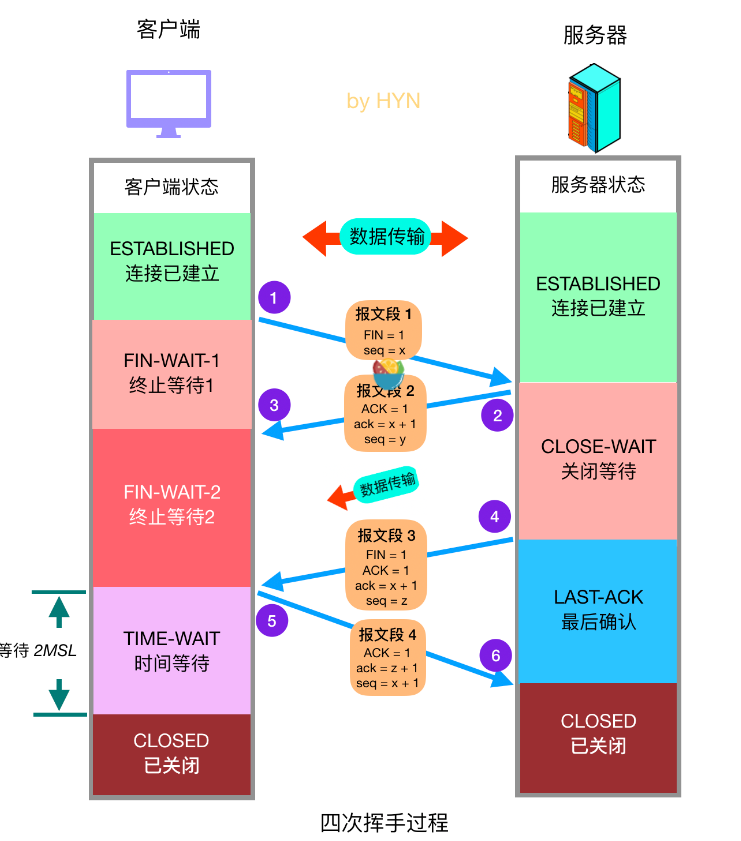
9.1.3 随机森林模型的代码实现
和决策树模型一样,随机森林模型既可以做分类分析,也可以做回归分析。
分别对应的模型为随机森林分类模型(RandomForestClassifier)及随机森林回归模型(RandomForestRegressor)。随机森林分类模型的基模型是分类决策树模型(详见5.1.2节),随机森林回归模型的基模型则是回归决策树模型(详见5.1.3节)。
# 随机森林分类模型简单代码演示如下所示:
from sklearn.ensemble import RandomForestClassifier
X = [[1, 2], [3, 4], [5, 6], [7, 8], [9, 10]]
y = [0, 0, 0, 1, 1]
model = RandomForestClassifier(n_estimators=10, random_state=123)
model.fit(X, y)
print(model.predict([[5, 5]]))
[0]
# 随机森林回归模型简单代码演示如下所示:
from sklearn.ensemble import RandomForestRegressor
X = [[1, 2], [3, 4], [5, 6], [7, 8], [9, 10]]
y = [1, 2, 3, 4, 5]
model = RandomForestRegressor(n_estimators=10, random_state=123)
model.fit(X, y)
print(model.predict([[5, 5]]))
[2.8]
9.2 量化金融 - 股票数据获取
9.2.1 股票基本数据获取
这里介绍一个免费的财经数据Python接口包:Tushare库,通过它我们能够免费地调用历史行情数据来进行分析。其官方地址为:http://tushare.org/
如果是想查看股价行情数据,可以访问相应网址:http://tushare.org/trading.html
1.Tushare库的基本介绍
推荐通过PIP安装法来安装Tushare库,以Windows系统为例,具体方法是:通过Win + R组合键调出运行框,输入cmd后回车,然后在弹出框中输入pip install tushare后按一下Enter回车键的方法来进行安装。如果在1.2.3节讲到的Jupyter Notebook编辑器中安装的话,只需要在代码框中输入!pip instll tushare(注意是英文格式下的!)然后运行该行代码框即可。
(1) 获得日线行情数据
import tushare as ts
df = ts.get_hist_data('000002', start='2018-01-01', end='2019-01-31')
df.head()
本接口即将停止更新,请尽快使用Pro版接口:https://tushare.pro/document/2
| open | high | close | low | volume | price_change | p_change | ma5 | ma10 | ma20 | v_ma5 | v_ma10 | v_ma20 | turnover | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| date |
注意,如果不写开始及结束日期,直接写ts.get_hist_data(‘000002’)会默认调取从当天往前3年的数据。此外,上面代码也可以简写成:
df = ts.get_hist_data('000002','2018-01-01', '2019-01-31')
df.head()
| open | high | close | low | volume | price_change | p_change | ma5 | ma10 | ma20 | v_ma5 | v_ma10 | v_ma20 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| date | |||||||||||||
| 2019-01-31 | 27.39 | 28.15 | 27.75 | 27.00 | 411857.59 | 0.54 | 1.99 | 26.800 | 26.153 | 25.641 | 426579.02 | 351523.31 | 320269.20 |
| 2019-01-30 | 26.70 | 27.82 | 27.21 | 26.63 | 592303.19 | 0.33 | 1.23 | 26.332 | 25.875 | 25.457 | 391193.72 | 334927.14 | 310794.00 |
| 2019-01-29 | 25.91 | 26.88 | 26.88 | 25.87 | 368071.62 | 0.82 | 3.15 | 25.952 | 25.696 | 25.292 | 302102.48 | 302443.43 | 293529.36 |
| 2019-01-28 | 26.20 | 26.62 | 26.06 | 25.86 | 308906.56 | -0.04 | -0.15 | 25.656 | 25.524 | 25.139 | 304355.52 | 302512.15 | 291266.32 |
| 2019-01-25 | 25.51 | 26.35 | 26.10 | 25.49 | 451756.16 | 0.69 | 2.71 | 25.574 | 25.420 | 25.008 | 293674.18 | 289949.63 | 293446.08 |
补充知识点:get_k_data()函数
因为get_hist_data()函数不仅获得了股票的基本价格信息,还获取了价格变化、均线价格等衍生变量,所以它最多也只能调取当天往前3年的数据,如果想调取超过3年的日线级别数据,得用ts.get_k_data()函数,它只获取股价的基本数据,代码如下:
df = ts.get_k_data('000002', start='2000-01-01', end='2019-01-31')
df.head()
| date | open | close | high | low | volume | code | |
|---|---|---|---|---|---|---|---|
| 0 | 2000-01-04 | 0.584 | 0.614 | 0.620 | 0.572 | 45747.08 | 000002 |
| 1 | 2000-01-05 | 0.617 | 0.599 | 0.623 | 0.596 | 46136.73 | 000002 |
| 2 | 2000-01-06 | 0.596 | 0.627 | 0.632 | 0.587 | 71920.31 | 000002 |
| 3 | 2000-01-07 | 0.631 | 0.655 | 0.656 | 0.624 | 136349.36 | 000002 |
| 4 | 2000-01-10 | 0.673 | 0.721 | 0.721 | 0.665 | 142424.86 | 000002 |
通过get_k_data()函数获取的数据没有像get_hist_data()函数那样将日期默认设为行索引,这里的日期还是作为一个普通的列(date列),如果想把这里的date列转为行索引,可以使用设置索引的set_index()函数,代码如下:
df = df.set_index('date') # 或者写成:df.set_index('date', inplace=True)
df.head()
| open | close | high | low | volume | code | |
|---|---|---|---|---|---|---|
| date | ||||||
| 2000-01-04 | 0.584 | 0.614 | 0.620 | 0.572 | 45747.08 | 000002 |
| 2000-01-05 | 0.617 | 0.599 | 0.623 | 0.596 | 46136.73 | 000002 |
| 2000-01-06 | 0.596 | 0.627 | 0.632 | 0.587 | 71920.31 | 000002 |
| 2000-01-07 | 0.631 | 0.655 | 0.656 | 0.624 | 136349.36 | 000002 |
| 2000-01-10 | 0.673 | 0.721 | 0.721 | 0.665 | 142424.86 | 000002 |
(2) 获得分钟级别的数据
通过设置ktype参数可以获得分钟级别的数据,代码如下:
df = ts.get_hist_data('000002', ktype='5')
df.head()
| open | high | close | low | volume | price_change | p_change | ma5 | ma10 | ma20 | v_ma5 | v_ma10 | v_ma20 | turnover | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| date | ||||||||||||||
| 2020-01-03 15:00:00 | 32.06 | 32.07 | 32.06 | 32.05 | 3920.32 | 0.00 | 0.00 | 32.122 | 32.113 | 32.0350 | 15322.7 | 17669.5 | 13041.0 | 0.00 |
| 2020-01-03 14:55:00 | 32.11 | 32.11 | 32.07 | 32.03 | 8377.52 | -0.04 | -0.12 | 32.136 | 32.103 | 32.0290 | 19359.3 | 17817.5 | 13428.9 | 0.01 |
| 2020-01-03 14:50:00 | 32.20 | 32.21 | 32.12 | 32.11 | 13402.00 | -0.08 | -0.25 | 32.154 | 32.093 | 32.0175 | 23136.3 | 17962.0 | 13959.7 | 0.01 |
| 2020-01-03 14:45:00 | 32.16 | 32.21 | 32.20 | 32.12 | 24470.90 | 0.04 | 0.12 | 32.160 | 32.078 | 32.0050 | 24442.3 | 17137.9 | 13903.3 | 0.03 |
| 2020-01-03 14:40:00 | 32.13 | 32.18 | 32.16 | 32.13 | 26443.00 | 0.03 | 0.09 | 32.132 | 32.056 | 31.9880 | 23976.3 | 15128.1 | 13491.1 | 0.03 |
(3) 获得实时行情数据
通过如下代码可以实时取得股票当前报价和成交信息:
df = ts.get_realtime_quotes('000002')
df
| name | open | pre_close | price | high | low | bid | ask | volume | amount | ... | a2_p | a3_v | a3_p | a4_v | a4_p | a5_v | a5_p | date | time | code | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 万 科A | 32.710 | 32.560 | 32.050 | 32.810 | 31.780 | 32.040 | 32.050 | 80553629 | 2584309903.290 | ... | 32.060 | 3005 | 32.070 | 119 | 32.080 | 344 | 32.090 | 2020-01-03 | 15:00:03 | 000002 |
1 rows × 33 columns
其运行结果就是当时的股价信息,如果收盘后运行的话获得的就是当日收盘价相关信息。如果觉得列数过多,可以通过DataFrame选取列的方法选取相应的列,代码如下:
df = df[['code','name','price','bid','ask','volume','amount','time']]
df
| code | name | price | bid | ask | volume | amount | time | |
|---|---|---|---|---|---|---|---|---|
| 0 | 000002 | 万 科A | 32.050 | 32.040 | 32.050 | 80553629 | 2584309903.290 | 15:00:03 |
如果想同时获得多个股票代码的实时数据,可以用如下代码:
df = ts.get_realtime_quotes(['000002','000980','000981'])
df
| name | open | pre_close | price | high | low | bid | ask | volume | amount | ... | a2_p | a3_v | a3_p | a4_v | a4_p | a5_v | a5_p | date | time | code | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 万 科A | 32.710 | 32.560 | 32.050 | 32.810 | 31.780 | 32.040 | 32.050 | 80553629 | 2584309903.290 | ... | 32.060 | 3005 | 32.070 | 119 | 32.080 | 344 | 32.090 | 2020-01-03 | 15:00:03 | 000002 |
| 1 | 众泰汽车 | 3.010 | 3.000 | 3.020 | 3.040 | 2.970 | 3.010 | 3.020 | 32495074 | 97566972.190 | ... | 3.030 | 4849 | 3.040 | 3840 | 3.050 | 2811 | 3.060 | 2020-01-03 | 15:00:03 | 000980 |
| 2 | ST银亿 | 1.870 | 1.890 | 1.810 | 1.920 | 1.800 | 1.810 | 1.820 | 40518670 | 74744476.400 | ... | 1.830 | 2939 | 1.840 | 4163 | 1.850 | 1449 | 1.860 | 2020-01-03 | 15:00:03 | 000981 |
3 rows × 33 columns
(4) 获得分笔数据
通过如下代码可以获得历史分笔数据,分笔数据也即每笔成交的信息:
df = ts.get_tick_data('000002', date='2018-12-12', src='tt')
df.head()
D:\Anaconda\Anaconda\lib\site-packages\tushare\stock\trading.py:182: FutureWarning: read_table is deprecated, use read_csv instead, passing sep='\t'.
skiprows=[0])
| time | price | change | volume | amount | type | |
|---|---|---|---|---|---|---|
| 0 | 09:25:04 | 26.31 | 0.34 | 6077 | 15988903 | 卖盘 |
| 1 | 09:30:00 | 26.33 | 0.02 | 197 | 518651 | 买盘 |
| 2 | 09:30:04 | 26.33 | 0.00 | 4623 | 12173863 | 卖盘 |
| 3 | 09:30:06 | 26.34 | 0.01 | 391 | 1030134 | 买盘 |
| 4 | 09:30:09 | 26.35 | 0.01 | 3289 | 8664911 | 买盘 |
(5) 获得指数信息
通过如下代码可以获得上证指数等指数信息:
df = ts.get_index()
df.head() # 目前的tushare获得的指数的列名有点错乱-2020-01-04备注
| code | name | change | open | preclose | close | high | low | volume | amount | |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 00上证指数 | 3089.0220 | 0.33 | 3085.1976 | 3083.7858 | 3093.8192 | 3074.5178 | 0.0 | 2.899917e+11 | 0.0 |
| 2 | 00A股指数 | 3236.7077 | 0.33 | 3232.6892 | 3231.1885 | 3241.7436 | 3221.4906 | 0.0 | 2.899041e+11 | 0.0 |
| 3 | 00B股指数 | 261.0510 | 0.00 | 261.1236 | 261.7619 | 261.7619 | 260.2429 | 0.0 | 8.764934e+07 | 0.0 |
| 8 | 00综合指数 | 3006.0295 | 0.39 | 2999.1744 | 3006.5318 | 3018.1699 | 2998.4266 | 0.0 | 6.499701e+10 | 0.0 |
| 9 | 0上证380 | 4885.0267 | 0.23 | 4881.7235 | 4879.5471 | 4890.8838 | 4858.4325 | 0.0 | 5.888844e+10 | 0.0 |
9.2.2 股票衍生变量生成
1.生成股票基本数据
这里首先通过上一节的get_k_data()函数获取从2015-01-01到2019-12-31的股票基本数据:
df = ts.get_k_data('000002',start='2015-01-01',end='2019-12-31')
df.head()
| date | open | close | high | low | volume | code | |
|---|---|---|---|---|---|---|---|
| 0 | 2015-01-05 | 12.436 | 12.885 | 13.214 | 12.289 | 6560835.0 | 000002 |
| 1 | 2015-01-06 | 12.617 | 12.410 | 12.954 | 12.142 | 3346346.0 | 000002 |
| 2 | 2015-01-07 | 12.324 | 12.298 | 12.531 | 12.099 | 2642051.0 | 000002 |
| 3 | 2015-01-08 | 12.375 | 11.745 | 12.419 | 11.632 | 2639394.0 | 000002 |
| 4 | 2015-01-09 | 11.701 | 11.624 | 12.289 | 11.485 | 3294584.0 | 000002 |
# 通过set_index()函数可以将日期列设置为行索引:
df = df.set_index('date')
df.head()
| open | close | high | low | volume | code | |
|---|---|---|---|---|---|---|
| date | ||||||
| 2015-01-05 | 12.436 | 12.885 | 13.214 | 12.289 | 6560835.0 | 000002 |
| 2015-01-06 | 12.617 | 12.410 | 12.954 | 12.142 | 3346346.0 | 000002 |
| 2015-01-07 | 12.324 | 12.298 | 12.531 | 12.099 | 2642051.0 | 000002 |
| 2015-01-08 | 12.375 | 11.745 | 12.419 | 11.632 | 2639394.0 | 000002 |
| 2015-01-09 | 11.701 | 11.624 | 12.289 | 11.485 | 3294584.0 | 000002 |
2.简单衍生变量的计算
通过如下代码我们可以先构造一些简单的衍生变量:
df['close-open'] = (df['close'] - df['open'])/df['open']
df['high-low'] = (df['high'] - df['low'])/df['low']
df['pre_close'] = df['close'].shift(1) # 该列所有往下移一行形成昨日收盘价
df['price_change'] = df['close']-df['pre_close']
df['p_change'] = (df['close']-df['pre_close'])/df['pre_close']*100
df.head()
| open | close | high | low | volume | code | close-open | high-low | pre_close | price_change | p_change | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| date | |||||||||||
| 2015-01-05 | 12.436 | 12.885 | 13.214 | 12.289 | 6560835.0 | 000002 | 0.036105 | 0.075271 | NaN | NaN | NaN |
| 2015-01-06 | 12.617 | 12.410 | 12.954 | 12.142 | 3346346.0 | 000002 | -0.016406 | 0.066875 | 12.885 | -0.475 | -3.686457 |
| 2015-01-07 | 12.324 | 12.298 | 12.531 | 12.099 | 2642051.0 | 000002 | -0.002110 | 0.035705 | 12.410 | -0.112 | -0.902498 |
| 2015-01-08 | 12.375 | 11.745 | 12.419 | 11.632 | 2639394.0 | 000002 | -0.050909 | 0.067658 | 12.298 | -0.553 | -4.496666 |
| 2015-01-09 | 11.701 | 11.624 | 12.289 | 11.485 | 3294584.0 | 000002 | -0.006581 | 0.070004 | 11.745 | -0.121 | -1.030226 |
3.移动平均线指标MA值
通过如下代码可以获得股价的5日移动平均值和10日移动平均值:
df['MA5'] = df['close'].rolling(5).mean()
df['MA10'] = df['close'].rolling(10).mean()
df.head(15) # head(15)表示展示前15行,因为要展示10行以上,才能看到MA10有值
| open | close | high | low | volume | code | close-open | high-low | pre_close | price_change | p_change | MA5 | MA10 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| date | |||||||||||||
| 2015-01-05 | 12.436 | 12.885 | 13.214 | 12.289 | 6560835.0 | 000002 | 0.036105 | 0.075271 | NaN | NaN | NaN | NaN | NaN |
| 2015-01-06 | 12.617 | 12.410 | 12.954 | 12.142 | 3346346.0 | 000002 | -0.016406 | 0.066875 | 12.885 | -0.475 | -3.686457 | NaN | NaN |
| 2015-01-07 | 12.324 | 12.298 | 12.531 | 12.099 | 2642051.0 | 000002 | -0.002110 | 0.035705 | 12.410 | -0.112 | -0.902498 | NaN | NaN |
| 2015-01-08 | 12.375 | 11.745 | 12.419 | 11.632 | 2639394.0 | 000002 | -0.050909 | 0.067658 | 12.298 | -0.553 | -4.496666 | NaN | NaN |
| 2015-01-09 | 11.701 | 11.624 | 12.289 | 11.485 | 3294584.0 | 000002 | -0.006581 | 0.070004 | 11.745 | -0.121 | -1.030226 | 12.1924 | NaN |
| 2015-01-12 | 11.511 | 11.338 | 11.511 | 11.019 | 2436341.0 | 000002 | -0.015029 | 0.044650 | 11.624 | -0.286 | -2.460427 | 11.8830 | NaN |
| 2015-01-13 | 11.278 | 11.295 | 11.563 | 11.209 | 1664610.0 | 000002 | 0.001507 | 0.031582 | 11.338 | -0.043 | -0.379256 | 11.6600 | NaN |
| 2015-01-14 | 11.295 | 11.321 | 11.494 | 11.122 | 1646818.0 | 000002 | 0.002302 | 0.033447 | 11.295 | 0.026 | 0.230190 | 11.4646 | NaN |
| 2015-01-15 | 11.347 | 11.900 | 11.952 | 11.235 | 2429686.0 | 000002 | 0.048735 | 0.063818 | 11.321 | 0.579 | 5.114389 | 11.4956 | NaN |
| 2015-01-16 | 11.900 | 11.684 | 11.900 | 11.572 | 2129475.0 | 000002 | -0.018151 | 0.028344 | 11.900 | -0.216 | -1.815126 | 11.5076 | 11.8500 |
| 2015-01-19 | 10.803 | 10.517 | 11.148 | 10.517 | 3603625.0 | 000002 | -0.026474 | 0.059998 | 11.684 | -1.167 | -9.988018 | 11.3434 | 11.6132 |
| 2015-01-20 | 10.543 | 10.673 | 10.889 | 10.422 | 2914688.0 | 000002 | 0.012330 | 0.044809 | 10.517 | 0.156 | 1.483313 | 11.2190 | 11.4395 |
| 2015-01-21 | 10.656 | 11.278 | 11.407 | 10.457 | 3555294.0 | 000002 | 0.058371 | 0.090848 | 10.673 | 0.605 | 5.668509 | 11.2104 | 11.3375 |
| 2015-01-22 | 11.252 | 11.736 | 11.796 | 11.166 | 3224727.0 | 000002 | 0.043015 | 0.056421 | 11.278 | 0.458 | 4.061004 | 11.1776 | 11.3366 |
| 2015-01-23 | 11.727 | 12.030 | 12.177 | 11.494 | 3310408.0 | 000002 | 0.025838 | 0.059422 | 11.736 | 0.294 | 2.505112 | 11.2468 | 11.3772 |
# 删除空值
df.dropna(inplace=True) # 删除空值行,也可以写成df = df.dropna()
df.head()
| open | close | high | low | volume | code | close-open | high-low | pre_close | price_change | p_change | MA5 | MA10 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| date | |||||||||||||
| 2015-01-16 | 11.900 | 11.684 | 11.900 | 11.572 | 2129475.0 | 000002 | -0.018151 | 0.028344 | 11.900 | -0.216 | -1.815126 | 11.5076 | 11.8500 |
| 2015-01-19 | 10.803 | 10.517 | 11.148 | 10.517 | 3603625.0 | 000002 | -0.026474 | 0.059998 | 11.684 | -1.167 | -9.988018 | 11.3434 | 11.6132 |
| 2015-01-20 | 10.543 | 10.673 | 10.889 | 10.422 | 2914688.0 | 000002 | 0.012330 | 0.044809 | 10.517 | 0.156 | 1.483313 | 11.2190 | 11.4395 |
| 2015-01-21 | 10.656 | 11.278 | 11.407 | 10.457 | 3555294.0 | 000002 | 0.058371 | 0.090848 | 10.673 | 0.605 | 5.668509 | 11.2104 | 11.3375 |
| 2015-01-22 | 11.252 | 11.736 | 11.796 | 11.166 | 3224727.0 | 000002 | 0.043015 | 0.056421 | 11.278 | 0.458 | 4.061004 | 11.1776 | 11.3366 |
4.股票衍生变量生成库:TA-Lib库的安装
下面要讲的衍生变量指标都是通过股票衍生变量生成库:TA-Lib库生成的,所以这里我们先讲解一下如何安装Ta-Lib库:
以Windows操作系统为例,如果你的系统是Windows的64位系统,直接使用pip install talib语句会报错,原因在于python pip源中TA-Lib是32位的,不能安装在64位系统平台上。
正确的方法是下载64位的安装包后本地安装,下载推荐使用加州大学的python扩展库,地址:https://www.lfd.uci.edu/~gohlke/pythonlibs/
进入网址后Ctrl + F键搜索“ta_lib”,如下图所示,
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FpvDHWnj-1681175692727)( https://uploader.shimo.im/f/rd7iXLJw6RMZPkbV.png!thumbnail)]
选择对应的文件TA_Lib-0.4.17-cp37-cp37m-win_amd64.whl(cp后的37表示的是Python3.7版本)下载到自己选择的文件夹,读者在下载时也要根据自己Python的版本进行下载。
如何查看自己Python的版本,可以通过Win + R键调出运行框,然后输入cmd,在弹出界面中输入python,然后按一下Enter回车键即可查看相关版本,如下图所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6KXw9yAF-1681175692728)( https://uploader.shimo.im/f/90luFuZqHt46OZko.png)]
下载完成后,在自己选择的文件夹中(例如笔者保存在的文件夹“E:\机器学习与大数据分析\随机森林”),如下图所示,在搜索框中输入cmd后按一下Enter回车键搜索:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Wp2cI7Zm-1681175692728)( https://uploader.shimo.im/f/EnabNoMQKT0tYdaz.png!thumbnail)]
在弹出框中输入如下内容,然后Enter回车键安装即可。
pip install TA_Lib-0.4.17-cp37-cp37m-win_amd64.whl
5.通过TA-Lib库生成相对强弱指标RSI值
import talib
df['RSI'] = talib.RSI(df['close'], timeperiod=12)
6.通过TA-Lib库生成动量指标MOM值
df['MOM'] = talib.MOM(df['close'], timeperiod=5)
7.通过TA-Lib库生成指数移动平均值EMA
df['EMA12'] = talib.EMA(df['close'], timeperiod=12) # 12日指数移动平均线
df['EMA26'] = talib.EMA(df['close'], timeperiod=26) # 26日指数移动平均线
8.通过TA-Lib库生成异同移动平均线MACD值
df['MACD'], df['MACDsignal'], df['MACDhist'] = talib.MACD(df['close'], fastperiod=12, slowperiod=26, signalperiod=9)
df.dropna(inplace=True) # 删除空行
df.tail() # 和head()相对,通过tail()函数可以查看后五行
| open | close | high | low | volume | code | close-open | high-low | pre_close | price_change | p_change | MA5 | MA10 | RSI | MOM | EMA12 | EMA26 | MACD | MACDsignal | MACDhist | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| date | ||||||||||||||||||||
| 2019-12-25 | 30.40 | 30.29 | 30.63 | 30.18 | 685037.0 | 000002 | -0.003618 | 0.014911 | 30.38 | -0.09 | -0.296248 | 30.878 | 30.075 | 63.075563 | -0.02 | 29.908556 | 28.973211 | 0.935345 | 0.772958 | 0.162387 |
| 2019-12-26 | 30.50 | 31.12 | 31.30 | 30.50 | 888790.0 | 000002 | 0.020328 | 0.026230 | 30.29 | 0.83 | 2.740178 | 30.896 | 30.387 | 68.890164 | 0.09 | 30.094932 | 29.132233 | 0.962699 | 0.810906 | 0.151793 |
| 2019-12-27 | 31.23 | 31.00 | 31.32 | 30.81 | 703096.0 | 000002 | -0.007365 | 0.016553 | 31.12 | -0.12 | -0.385604 | 30.760 | 30.672 | 67.220611 | -0.68 | 30.234173 | 29.270586 | 0.963587 | 0.841442 | 0.122145 |
| 2019-12-30 | 31.35 | 31.57 | 31.79 | 31.02 | 915751.0 | 000002 | 0.007018 | 0.024823 | 31.00 | 0.57 | 1.838710 | 30.872 | 30.884 | 70.877814 | 0.56 | 30.439685 | 29.440913 | 0.998772 | 0.872908 | 0.125864 |
| 2019-12-31 | 31.35 | 32.18 | 32.45 | 31.32 | 663497.0 | 000002 | 0.026475 | 0.036079 | 31.57 | 0.61 | 1.932214 | 31.232 | 31.057 | 74.233951 | 1.80 | 30.707426 | 29.643808 | 1.063618 | 0.911050 | 0.152567 |
补充内容:Talib库的一些验证
RSI指标的验证
import pandas as pd
import talib
data = pd.DataFrame()
data['close'] = [10, 12, 11, 13, 12, 14, 13]
data['RSI'] = talib.RSI(data['close'], timeperiod=6)
data
| close | RSI | |
|---|---|---|
| 0 | 10 | NaN |
| 1 | 12 | NaN |
| 2 | 11 | NaN |
| 3 | 13 | NaN |
| 4 | 12 | NaN |
| 5 | 14 | NaN |
| 6 | 13 | 66.666667 |
9.3 量化金融 - 股票涨跌预测模型搭建
9.3.1 多因子模型搭建
1.引入之后需要用到的库
import tushare as ts # 股票基本数据相关库
import numpy as np # 科学计算相关库
import pandas as pd # 科学计算相关库
import talib # 股票衍生变量数据相关库
import matplotlib.pyplot as plt # 引入绘图相关库
from sklearn.ensemble import RandomForestClassifier # 引入分类决策树模型
from sklearn.metrics import accuracy_score # 引入准确度评分函数
import warnings
warnings.filterwarnings("ignore") # 忽略警告信息,警告非报错,不影响代码执行
2.股票数据处理与衍生变量生成
我们这里将8.2节股票基本数据和股票衍生变量数据的相关代码汇总,方便之后的股票涨跌预测模型的搭建:
# 1.股票基本数据获取
df = ts.get_k_data('000002',start='2015-01-01',end='2019-12-31')
df = df.set_index('date') # 设置日期为索引
# 2.简单衍生变量构造
df['close-open'] = (df['close'] - df['open'])/df['open']
df['high-low'] = (df['high'] - df['low'])/df['low']
df['pre_close'] = df['close'].shift(1) # 该列所有往下移一行形成昨日收盘价
df['price_change'] = df['close']-df['pre_close']
df['p_change'] = (df['close']-df['pre_close'])/df['pre_close']*100
# 3.移动平均线相关数据构造
df['MA5'] = df['close'].rolling(5).mean()
df['MA10'] = df['close'].rolling(10).mean()
df.dropna(inplace=True) # 删除空值
# 4.通过Ta_lib库构造衍生变量
df['RSI'] = talib.RSI(df['close'], timeperiod=12) # 相对强弱指标
df['MOM'] = talib.MOM(df['close'], timeperiod=5) # 动量指标
df['EMA12'] = talib.EMA(df['close'], timeperiod=12) # 12日指数移动平均线
df['EMA26'] = talib.EMA(df['close'], timeperiod=26) # 26日指数移动平均线
df['MACD'], df['MACDsignal'], df['MACDhist'] = talib.MACD(df['close'], fastperiod=12, slowperiod=26, signalperiod=9) # MACD值
df.dropna(inplace=True) # 删除空值
本接口即将停止更新,请尽快使用Pro版接口:https://tushare.pro/document/2
# 查看此时的df后五行
df.tail()
| open | close | high | low | volume | code | close-open | high-low | pre_close | price_change | p_change | MA5 | MA10 | RSI | MOM | EMA12 | EMA26 | MACD | MACDsignal | MACDhist | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| date | ||||||||||||||||||||
| 2019-12-25 | 27.165 | 27.055 | 27.395 | 26.945 | 685037.0 | 000002 | -0.004049 | 0.016701 | 27.145 | -0.09 | -0.331553 | 27.643 | 26.840 | 63.081344 | -0.02 | 26.673555 | 25.737103 | 0.936452 | 0.774585 | 0.161867 |
| 2019-12-26 | 27.265 | 27.885 | 28.065 | 27.265 | 888790.0 | 000002 | 0.022740 | 0.029342 | 27.055 | 0.83 | 3.067825 | 27.661 | 27.152 | 68.895291 | 0.09 | 26.859932 | 25.896207 | 0.963725 | 0.812413 | 0.151311 |
| 2019-12-27 | 27.995 | 27.765 | 28.085 | 27.575 | 703096.0 | 000002 | -0.008216 | 0.018495 | 27.885 | -0.12 | -0.430339 | 27.525 | 27.437 | 67.225542 | -0.68 | 26.999173 | 26.034636 | 0.964537 | 0.842838 | 0.121699 |
| 2019-12-30 | 28.115 | 28.335 | 28.555 | 27.785 | 915751.0 | 000002 | 0.007825 | 0.027713 | 27.765 | 0.57 | 2.052944 | 27.637 | 27.649 | 70.882335 | 0.56 | 27.204685 | 26.205033 | 0.999651 | 0.874201 | 0.125451 |
| 2019-12-31 | 28.115 | 28.945 | 29.215 | 28.085 | 663497.0 | 000002 | 0.029522 | 0.040235 | 28.335 | 0.61 | 2.152815 | 27.997 | 27.822 | 74.238064 | 1.80 | 27.472426 | 26.407994 | 1.064432 | 0.912247 | 0.152185 |
3.特征变量和目标变量提取
X = df[['close', 'volume', 'close-open', 'MA5', 'MA10', 'high-low', 'RSI', 'MOM', 'EMA12', 'MACD', 'MACDsignal', 'MACDhist']]
y = np.where(df['price_change'].shift(-1)> 0, 1, -1)
首先强调最核心的一点:应该是今天的股价信息预测下一天的股价涨跌情况,所以y应该是下一天的股价变化情况。
其中Numpy库中的where()函数的使用方法如下所示:
np.where(判断条件,满足条件的赋值,不满足条件的赋值)
其中df[‘price_change’].shift(-1)则是利用shift()函数将price_change(股价变化)这一列往上移动一行,这样就获得了每一行对应的下一天股价涨跌情况。
因此这里的判断条件就是下一天股价是否大于0,如果下一天股价涨了的我们则y赋值为数字1,下一天股价跌了的,则y赋值为数字-1。这个下一天的股价涨跌情况就是我们根据当天股票基本数据以及衍生变量预测的内容。
3.训练集和测试集数据划分
接下来,我们要将原始数据集进行分割,我们要注意到一点,训练集与测试集的划分要按照时间序列划分,而不是像之前利用train_test_split()函数进行划分。原因在于股票价格的变化趋势具有时间性,如果我们随机划分,则会破坏时间性特征,因为我们是根据当天数据来预测下一天的股价涨跌情况,而不是任意一天的股票数据来预测下一天的股价涨跌情况。
因此,我们将前90%的数据作为训练集,后10%的数据作为测试集,代码如下:
X_length = X.shape[0] # shape属性获取X的行数和列数,shape[0]即表示行数
split = int(X_length * 0.9)
X_train, X_test = X[:split], X[split:]
y_train, y_test = y[:split], y[split:]
4.模型搭建
model = RandomForestClassifier(max_depth=3, n_estimators=10, min_samples_leaf=10, random_state=1)
model.fit(X_train, y_train)
RandomForestClassifier(max_depth=3, min_samples_leaf=10, n_estimators=10,random_state=1)</pre><b>In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. <br />On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.</b></div><div class="sk-container" hidden><div class="sk-item"><div class="sk-estimator sk-toggleable"><input class="sk-toggleable__control sk-hidden--visually" id="sk-estimator-id-1" type="checkbox" checked><label for="sk-estimator-id-1" class="sk-toggleable__label sk-toggleable__label-arrow">RandomForestClassifier</label><div class="sk-toggleable__content"><pre>RandomForestClassifier(max_depth=3, min_samples_leaf=10, n_estimators=10, random_state=1)</pre></div></div></div></div></div>
9.3.2 模型使用与评估
1.预测下一天的涨跌情况
y_pred = model.predict(X_test)
print(y_pred)
[-1 1 -1 1 1 1 1 1 1 1 1 1 1 1 1 1 -1 1 1 1 1 1 1 1
1 1 1 1 1 1 -1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 -1 -1 -1 1 1 1 1 1 1 1 1 1 1 1 1 -1 -1 -1
-1 -1 -1 -1 -1 -1 -1 -1 -1]
a = pd.DataFrame() # 创建一个空DataFrame
a['预测值'] = list(y_pred)
a['实际值'] = list(y_test)
a.head()
| 预测值 | 实际值 | |
|---|---|---|
| 0 | -1 | -1 |
| 1 | 1 | -1 |
| 2 | -1 | -1 |
| 3 | 1 | -1 |
| 4 | 1 | 1 |
# 查看预测概率
y_pred_proba = model.predict_proba(X_test)
y_pred_proba[0:5]
array([[0.53462409, 0.46537591],
[0.49852513, 0.50147487],
[0.53687766, 0.46312234],
[0.49733765, 0.50266235],
[0.49733765, 0.50266235]])
2.模型准确度评估
from sklearn.metrics import accuracy_score
score = accuracy_score(y_pred, y_test)
print(score)
0.5428571428571428
# 此外,我们还可以通过模型自带的score()函数记性打分,代码如下:
model.score(X_test, y_test)
0.5428571428571428
3.分析数据特征的重要性
model.feature_importances_
array([0.15132672, 0.09957677, 0.05021545, 0.06514831, 0.079073 ,
0.11447561, 0.04576496, 0.17559964, 0.04713332, 0.07061667,
0.08866083, 0.01240873])
# 通过如下代码可以更好的展示特征及其特征重要性:
features = X.columns
importances = model.feature_importances_
a = pd.DataFrame()
a['特征'] = features
a['特征重要性'] = importances
a = a.sort_values('特征重要性', ascending=False)
a
| 特征 | 特征重要性 | |
|---|---|---|
| 7 | MOM | 0.175600 |
| 0 | close | 0.151327 |
| 5 | high-low | 0.114476 |
| 1 | volume | 0.099577 |
| 10 | MACDsignal | 0.088661 |
| 4 | MA10 | 0.079073 |
| 9 | MACD | 0.070617 |
| 3 | MA5 | 0.065148 |
| 2 | close-open | 0.050215 |
| 8 | EMA12 | 0.047133 |
| 6 | RSI | 0.045765 |
| 11 | MACDhist | 0.012409 |
9.3.3 参数调优
from sklearn.model_selection import GridSearchCV # 网格搜索合适的超参数
# 指定分类器中参数的范围
parameters = {'n_estimators':[5, 10, 20], 'max_depth':[2, 3, 4, 5], 'min_samples_leaf':[5, 10, 20, 30]}
new_model = RandomForestClassifier(random_state=1) # 构建分类器
grid_search = GridSearchCV(new_model, parameters, cv=6, scoring='accuracy') # cv=6表示交叉验证6次,scoring='roc_auc'表示以ROC曲线的AUC评分作为模型评价准则, 默认为'accuracy', 即按准确度评分
grid_search.fit(X_train, y_train) # 传入数据
grid_search.best_params_ # 输出参数的最优值
{'max_depth': 2, 'min_samples_leaf': 20, 'n_estimators': 10}
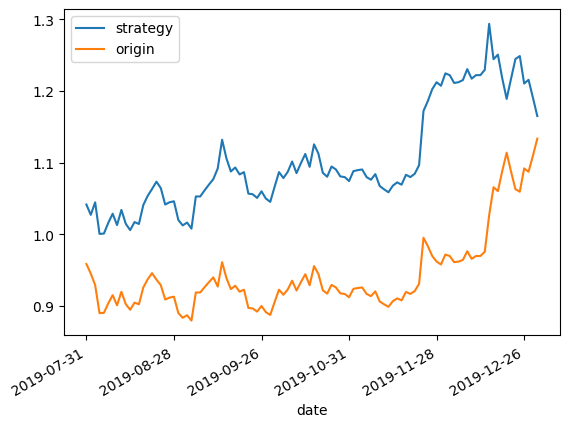
9.3.4 收益回测曲线绘制
X_test['prediction'] = model.predict(X_test)
X_test['p_change'] = (X_test['close'] - X_test['close'].shift(1)) / X_test['close'].shift(1)
X_test['origin'] = (X_test['p_change'] + 1).cumprod()
X_test['strategy'] = (X_test['prediction'].shift(1) * X_test['p_change'] + 1).cumprod()
X_test[['strategy', 'origin']].tail()
| strategy | origin | |
|---|---|---|
| date | ||
| 2019-12-25 | 1.248484 | 1.059319 |
| 2019-12-26 | 1.210183 | 1.091817 |
| 2019-12-27 | 1.215391 | 1.087118 |
| 2019-12-30 | 1.190439 | 1.109436 |
| 2019-12-31 | 1.164811 | 1.133320 |
# 通过如下代码将收益情况删除空值后可视化,并设置X轴刻度自动倾斜:
X_test[['strategy', 'origin']].dropna().plot()
plt.gcf().autofmt_xdate()
plt.show()