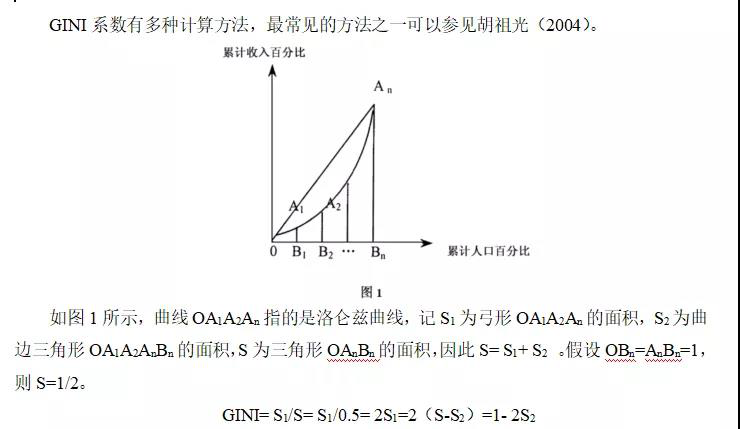
【问题】
I am trying to select top values in a column based on the variable/field in another column. it is a very large tab delimited file.
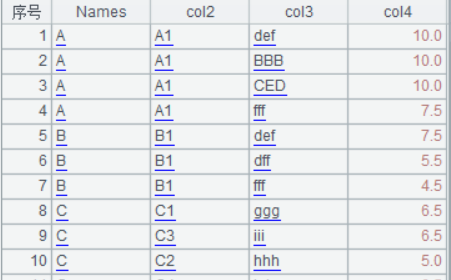
Input:
Names col2 col3 col4 A A1 def 10 A A1 BBB 10 A A1 CED 10 A A1 fff 7.5 B B1 def 7.5 B B1 dff 5.5 B B1 fff 4.5 C C1 ggg 6.5 C C3 iii 6.5 C C2 hhh 5.0 C C4 toi 6.5 D D1 xyz 10.0 D D2 ikj 7.5 D D3 abc 7.5 ...
Output
Names col2 col3 col4 A A1 def 10 A A1 BBB 10 A A1 CED 10 B B1 def 7.5 C C1 ggg 6.5 C C3 iii 6.5 C C4 toi 6.5 D D1 xyz 10.0
Basically, I want all the rows with values 10 and the top values for each of the names in column1. Any inputs to solve this by perl, awk or sed are well appreciated.
Thanks.
【回答】
分组后查询再合并是典型的结构化计算,用Shell实现会相对复杂,用SPL会方便些:
| A | |
| 1 | =file("file.txt").import@t() |
| 2 | =A1.group(Names) |
| 3 | =A2.((a=~.max(col4),~.select(col4==a|| col4==10))) |
| 4 | =A3.union() |
A1:读取文件file.txt中的内容。
A2:按Names分组。

A3:A2.(…)表示对A2中的每个成员依次计算,(a=~.max(col4),~.select(col4==a|| col4==10)) 表示依次计算括号内的表达式,并返回最后一个表达式的结果。其中a=~.max(col4)表示将每组数据中col4的最大值返回给变量a,~.select(col4==a|| col4==10)表示选择每组中clo4等于a或者10的记录,~.select(col4==a|| col4==10)就是括号运算符要返回的结果。
A4:合并A3。

SPL也可以命令行方式在unix/linux下执行。








![[附源码]Python计算机毕业设计DjangoON-FIT](https://img-blog.csdnimg.cn/1b3c6c6958d74ffda4293a1db02fe184.png)