主题建模
在文本挖掘中,我们经常收集一些文档集合,例如博客文章或新闻文章,我们希望将其分成组,以便我们可以分别理解它们。最近我们被客户要求撰写关于主题模型的研究报告,包括一些图形和统计输出。主题建模是对这些文档进行无监督分类的一种方法,类似于对数字数据进行聚类,即使我们不确定要查找什么,也可以找到分组。
相关视频:文本挖掘:主题模型(LDA)及R语言实现分析游记数据
文本挖掘:主题模型(LDA)及R语言实现分析游记数据
时长12:59
潜在狄利克雷分配(LDA)是拟合主题模型特别流行的方法。它将每个文档视为主题的混合体,并将每个主题看作是单词的混合体。这允许文档在内容方面相互“重叠”,而不是分离成离散的组,以反映自然语言的典型用法。
结合主题建模的文本分析流程图。topicmodels包采用Document-Term Matrix作为输入,并生成一个可以通过tidytext进行处理的模型,以便可以使用dplyr和ggplot2对其进行处理和可视化。
潜在狄利克雷分配
潜在Dirichlet分配是主题建模中最常用的算法之一。没有深入模型背后的数学,我们可以理解它是由两个原则指导的。
每个文档都是主题的混合体。我们设想每个文档可能包含来自几个主题的文字,并有一定的比例。例如,在双主题模型中,我们可以说“文档1是90%的主题A和10%的主题B,而文档2是30%的主题A和70%的主题B.”
每个主题都是词汇的混合。例如,我们可以想象一个新闻的两个主题模型,一个话题是“体育”,一个是“娱乐”。体育话题中最常见的词语可能是“篮球”,“足球”和“游泳“,而娱乐主题可以由诸如”电影“,”电视“和”演员“之类的词组成。重要的是,话题可以在话题之间共享; 像“奥运冠军”这样的词可能同时出现在两者中。
LDA是一种同时估计这两种情况的数学方法:查找与每个主题相关的单词集合,同时确定描述每个文档的主题分组。这个算法有很多现有的实现,我们将深入探讨其中的一个。
library(topicmodels)
data("AssociatedPress")
AssociatedPress
: term frequency (tf)我们可以使用LDA()topicmodels包中的函数设置k = 2来创建两个主题的LDA模型。
实际上几乎所有的主题模型都会使用更大的模型k,但我们很快就会看到,这种分析方法可以扩展到更多的主题。
此函数返回一个包含模型拟合完整细节的对象,例如单词如何与主题关联以及主题如何与文档关联。
# # 设置随机种子,使模型的输出是可重复的
ap_lda <- LDA(AssociatedPress,k =2,control =list(seed =1234))
ap_lda拟合模型是“简单部分”:分析的其余部分将涉及使用tidytext软件包中的函数来探索和解释模型。
单词主题概率
tidytext包提供了这种方法来提取每个主题的每个词的概率,称为β。
## # A tibble: 20,946 x 3
## topic term beta
## 1 1 aaron 1.69e-12
## 2 2 aaron 3.90e- 5
## 3 1 abandon 2.65e- 5
## 4 2 abandon 3.99e- 5
## 5 1 abandoned 1.39e- 4
## 6 2 abandoned 5.88e- 5
## 7 1 abandoning 2.45e-33
## 8 2 abandoning 2.34e- 5
## 9 1 abbott 2.13e- 6
## 10 2 abbott 2.97e- 5
## # ... with 20,936 more rows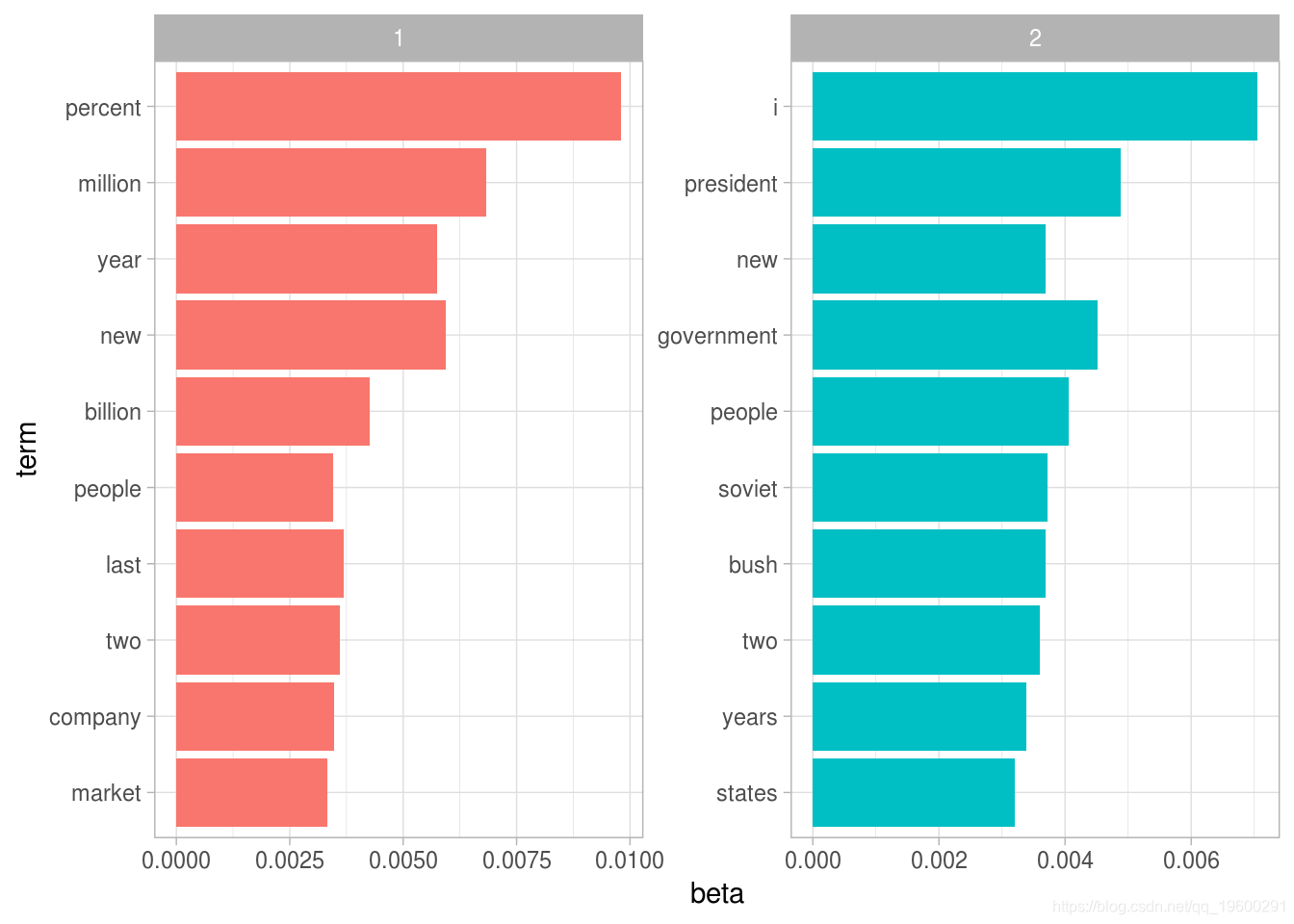
每个主题中最常见的词
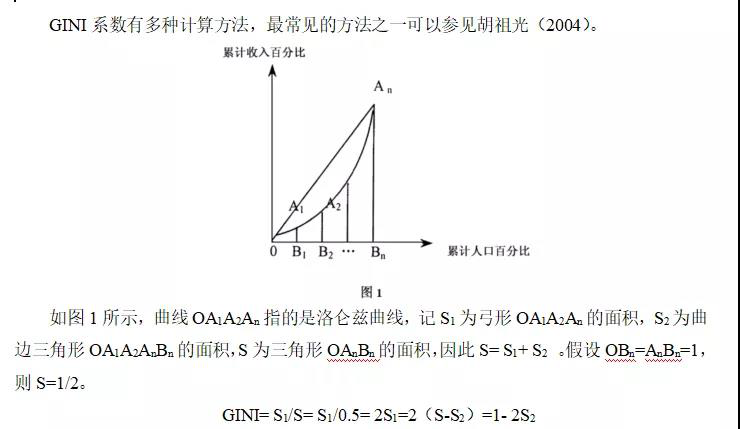
这种可视化让我们了解从文章中提取的两个主题。话题1中最常见的词语包括“百分比”,“百万”,“十亿”和“公司”,这表明它可能代表商业或财务新闻。话题2中最常见的包括“总统”,“政府”,表示这个话题代表政治新闻。关于每个主题中的单词的一个重要观察是,在这两个主题中,诸如“新”和“人”等一些词语是常见的。与“硬聚类”方法相反,这是话题建模的优势:自然语言中使用的话题可能存在一些重叠。
我们可以认为最大的区别是两个主题之间β差异最大的词。
## # A tibble: 198 x 4
## term topic1 topic2 log_ratio
##
## 1 administration 0.000431 0.00138 1.68
## 2 ago 0.00107 0.000842 -0.339
## 3 agreement 0.000671 0.00104 0.630
## 4 aid 0.0000476 0.00105 4.46
## 5 air 0.00214 0.000297 -2.85
## 6 american 0.00203 0.00168 -0.270
## 7 analysts 0.00109 0.000000578 -10.9
## 8 area 0.00137 0.000231 -2.57
## 9 army 0.000262 0.00105 2.00
## 10 asked 0.000189 0.00156 3.05
## # ... with 188 more rows图显示了这两个主题之间差异最大的词。

我们可以看到,话题2中更常见的词包括“民主”和“共和党”等政党等政治家的名字。主题1的特点是“日元”和“美元”等货币以及“指数”,“价格”和“利率”等金融术语。这有助于确认算法确定的两个主题是政治和财务新闻。
文档 - 主题概率
除了将每个主题评估为单词集合之外,LDA还将每个文档建模为混合主题。我们可以检查每个文档的每个主题概率,称为γ(“伽玛”) 。
## # A tibble: 4,492 x 3
## document topic gamma
## <int> <int> <dbl>
## 1 1 1 0.248
## 2 2 1 0.362
## 3 3 1 0.527
## 4 4 1 0.357
## 5 5 1 0.181
## 6 6 1 0.000588
## 7 7 1 0.773
## 8 8 1 0.00445
## 9 9 1 0.967
## 10 10 1 0.147
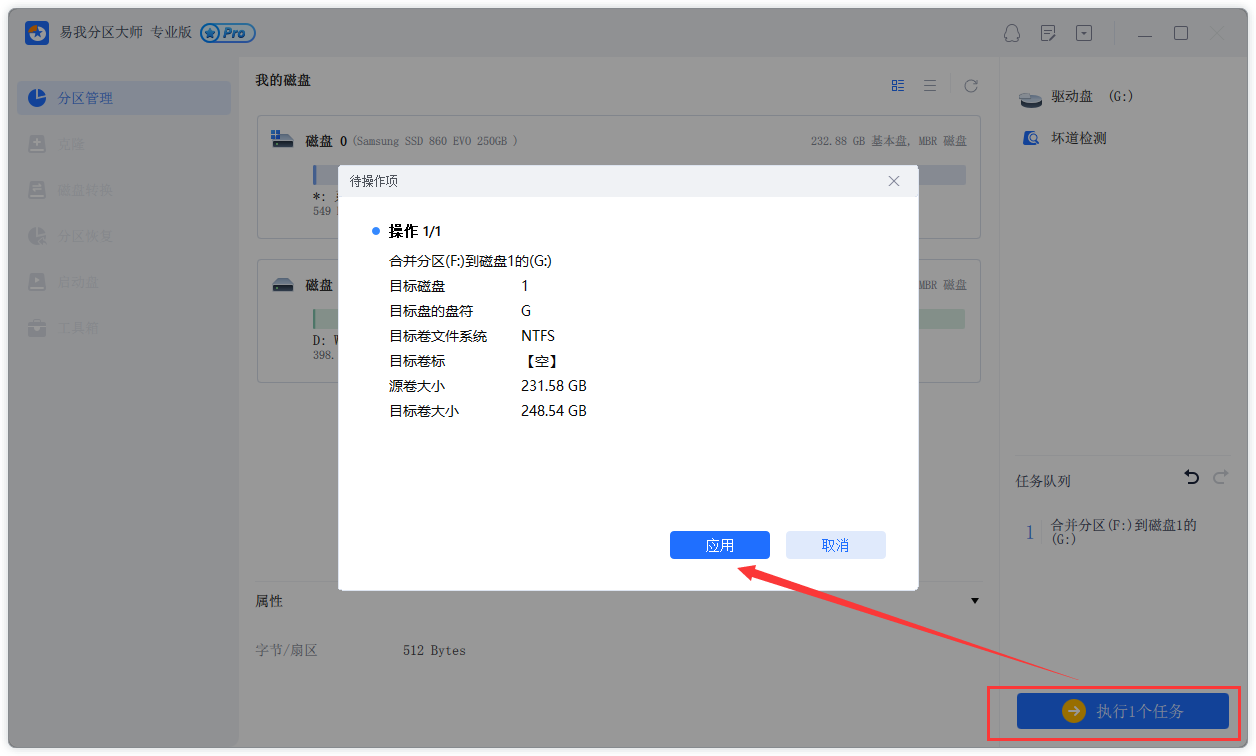
## # ... with 4,482 more rows这些值中的每一个都是该文档中从该主题生成的单词的估计比例。例如,该模型估计文档1中单词的大约24.8%是从主题1生成的。
我们可以看到,这些文档中的许多文档都是从两个主题中抽取出来的,但文档6几乎完全是从主题2中得出的,其中有一个主题1γ接近零。为了检查这个答案,我们可以检查该文档中最常见的词。
#> # A tibble: 287 x 3
#> document term count
#> <int> <chr> <dbl>
#> 1 6 noriega 16
#> 2 6 panama 12
#> 3 6 jackson 6
#> 4 6 powell 6
#> 5 6 administration 5
#> 6 6 economic 5
#> 7 6 general 5
#> 8 6 i 5
#> 9 6 panamanian 5
#> 10 6 american 4
#> # … with 277 more rows根据最常见的词汇,可以看出该算法将其分组到主题2(作为政治/国家新闻)是正确的。






![[附源码]Python计算机毕业设计DjangoON-FIT](https://img-blog.csdnimg.cn/1b3c6c6958d74ffda4293a1db02fe184.png)