来从标签平滑和知识蒸馏理解,先探讨一下hard label和soft label之间的关系,然后介绍一下如何用可靠的方法得到蕴含更多信息的soft label,其中主要包含标签平滑和知识蒸馏两种经典方法。
深度学习领域中,通常将数据标注为hard label,但事实上同一个数据包含不同类别的信息,直接标注为hard label会导致大量信息的损失,进而影响最终模型取得的效果。本文首先探讨一下hard label和soft label之间的关系,然后介绍一下如何用可靠的方法得到蕴含更多信息的soft label,其中主要包含Label Smoothing和Knowledge Distillation两种经典方法。
Hard Label vs Soft Label
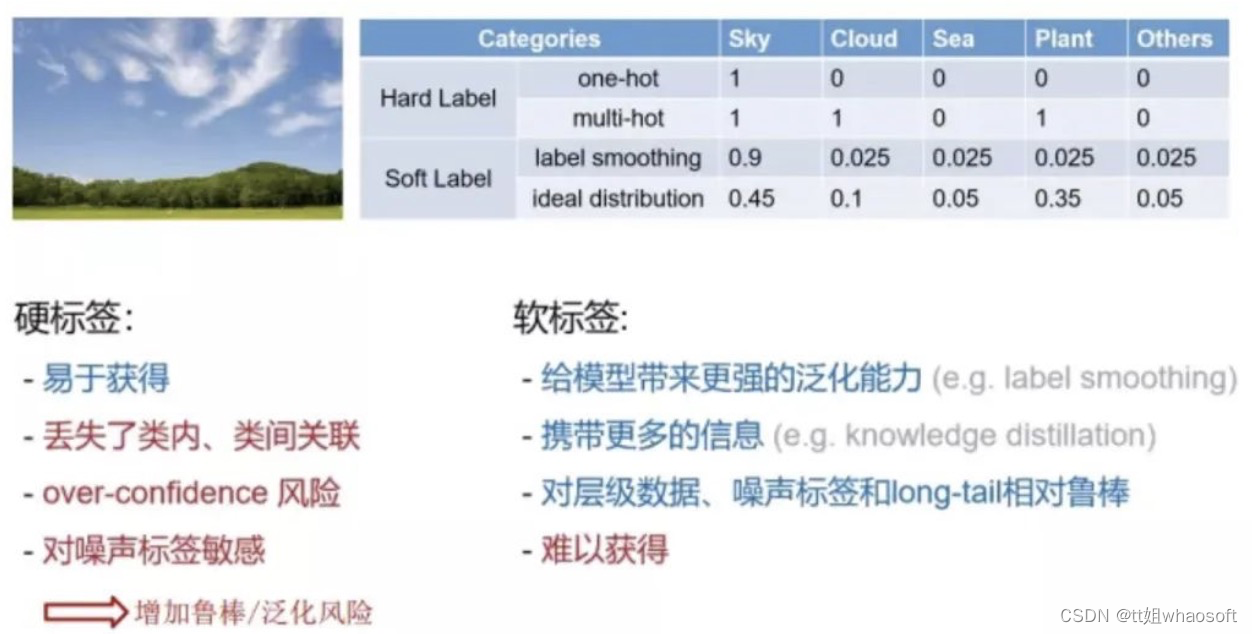
hard label更容易标注,但是会丢失类内、类间的关联,并且引入噪声。
soft label给模型带来更强的泛化能力,携带更多的信息,对噪声更加鲁棒,但是获取难度大。
Label Smoothing
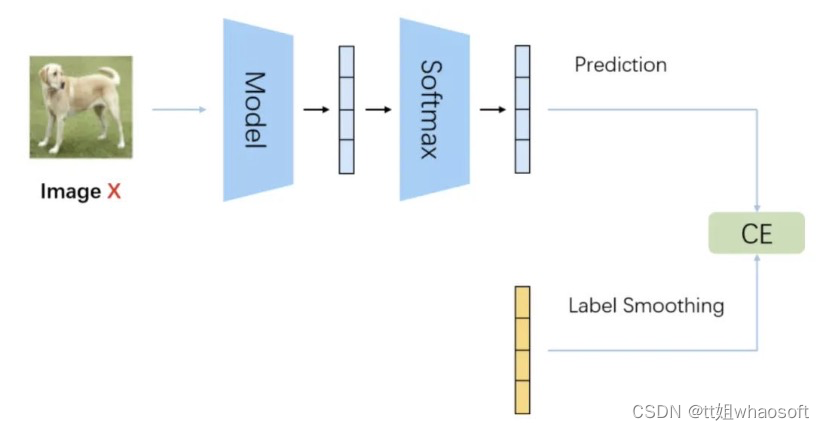 Softmax Cross Entropy不仅可以做分类任务(目标为one-hot label),还可以做回归任务(目标为soft label)。设网络输出的softmax prob为p,soft label为q,那Softmax Cross Entropy定义为:
Softmax Cross Entropy不仅可以做分类任务(目标为one-hot label),还可以做回归任务(目标为soft label)。设网络输出的softmax prob为p,soft label为q,那Softmax Cross Entropy定义为:
 InfoNCE可以拆分成两个部分,alignment和uniformity。
InfoNCE可以拆分成两个部分,alignment和uniformity。
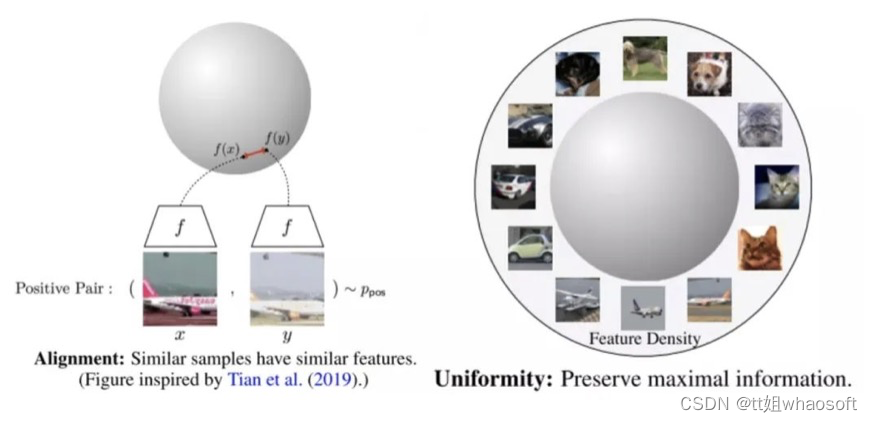 如上图所示,alignment部分只跟positive pair相关,希望positive pair的feature拉近,uniformity部分只跟negative pair相关,希望所有点的feature尽可能均匀分布在unit hypersphere上。
如上图所示,alignment部分只跟positive pair相关,希望positive pair的feature拉近,uniformity部分只跟negative pair相关,希望所有点的feature尽可能均匀分布在unit hypersphere上。
从softmax和InfoNCE损失函数上理解,把InoNCE公式的分母想象成soft label的所有位置相加,也就是最大值的那个位置可以看成是positive pair,其他位置都可以看成是negative pair,softmax的损失函数不是跟InfoNCE损失函数一模一样了吗,异曲同工!也就是说hard label可以认为只有positive pair,而soft label仍然保留negative pair。因此,soft label更容易避免退化解问题。 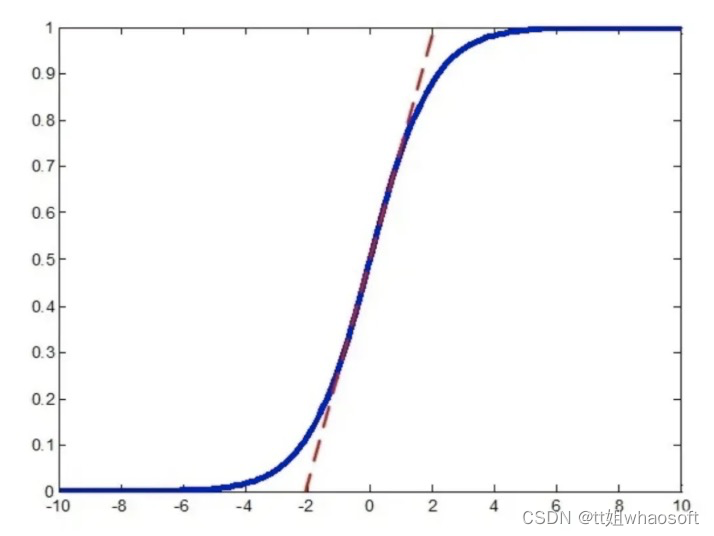
上图是sigmoid曲线。Softmax Cross Entropy 的loss曲线其实跟sigmoid类似,越靠近1的时候,loss曲线会越平缓,这里以sigmoid曲线图为例。
从softmax的损失函数曲线上理解,hard label监督下,由于softmax的作用,one-hot的最大值位置无限往1进行优化,但是永远不可能等于1,从上图可知优化到达一定程度时,优化效率就会很低,到达饱和区。而soft label可以保证优化过程始终处于优化效率最高的中间区域,避免进入饱和区。
Knowledge Distillation
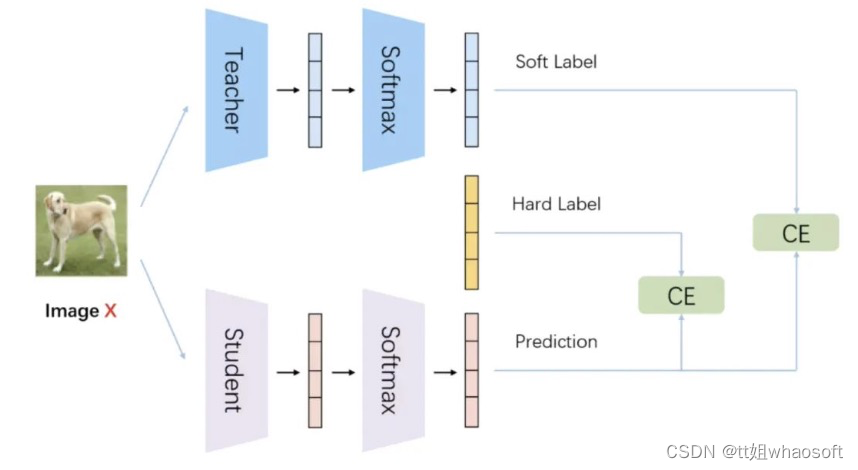
knowledge distillation相比于label smoothing,最主要的差别在于,知识蒸馏的soft label是通过网络推理得到的,而label smoothing的soft label是人为设置的。
原始训练模型的做法是让模型的softmax分布与真实标签进行匹配,而知识蒸馏方法是让student模型与teacher模型的softmax分布进行匹配。直观来看,后者比前者具有这样一个优势:经过训练后的原模型,其softmax分布包含有一定的知识——真实标签只能告诉我们,某个图像样本是一辆宝马,不是一辆垃圾车,也不是一颗萝卜;而经过训练的softmax可能会告诉我们,它最可能是一辆宝马,不大可能是一辆垃圾车,但绝不可能是一颗萝卜。
知识蒸馏得到的soft label相当于对数据集的有效信息进行了统计,保留了类间的关联信息,剔除部分无效的冗余信息。 相比于label smoothing,模型在数据集上训练得到的soft label更加可靠。
比较短哦 ~ whaosoft aiot http://143ai.com






![[附源码]Python计算机毕业设计DjangoON-FIT](https://img-blog.csdnimg.cn/1b3c6c6958d74ffda4293a1db02fe184.png)






![[U3D ShaderGraph] 全面学习ShaderGraph节点 | 第二课 | Input/Geometry](https://img-blog.csdnimg.cn/38fea60ef3a94038bd616c0ead25ffac.png)