一、Linux下面的I/O模型
Linux下面一共有五种可以使用的I/O模型,如下:
1)阻塞式I/O
2)非阻塞式I/O
3)I/O多路复用(select与epoll)
4)信号驱动式I/O
5)异步I/O
下面重点介绍前三种I/O模型
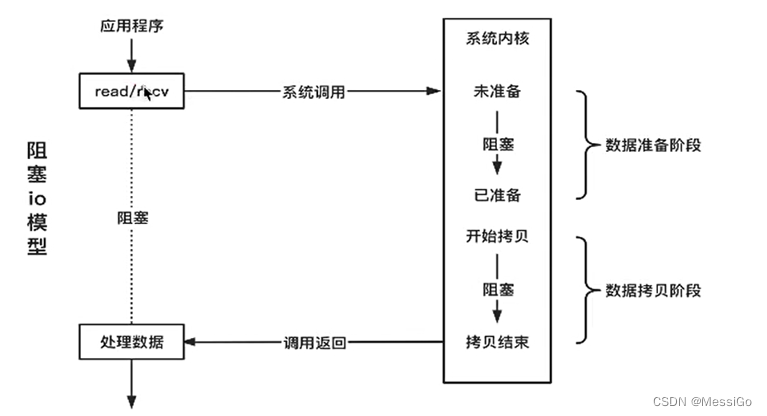
1、阻塞式I/O
对一个网络套接字上的read操作,第一步通常涉及等待数据从网络中到达。当等待的数据到达时,它被复制到内核的某个缓冲区。第二步就是把数据从内核缓冲区拷贝到进程缓冲区。默认情况下所有的套接字都是阻塞的,如下:
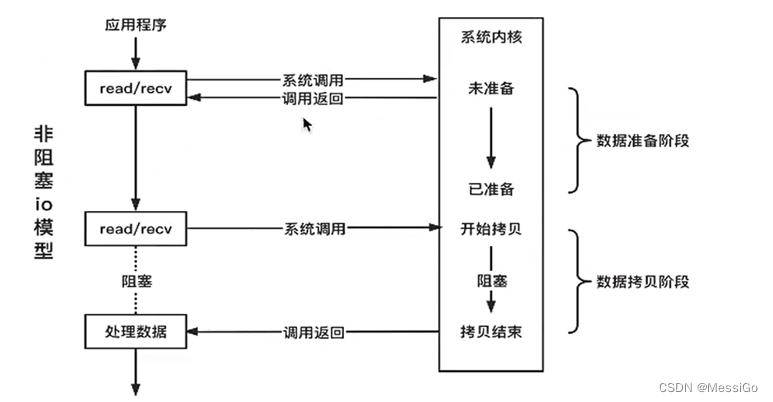
2、非阻塞I/O
套接字默认是阻塞的,可以设置成非阻塞。当把一个套接字设置成非阻塞时,是在通知内核:当所请求的I/O操作非得把线程置于休眠状态才能完成时,不要把线程置于休眠状态(即:如果数据没有准备好不要阻塞当前线程),而是返回一个错误码EAGIN。这样 read/write 的时候,如果数据没准备好,返回 EAGAIN 的错误即可,不会卡住线程,从而整个系统就运转起来了。当一个应用程序对一个非阻塞文件描述符循环调用read操作时,称之为轮询。应用程序持续轮询内核,以看某个操作是否就绪,这样做的缺点是浪费大量CPU时间。下面是非阻塞的I/O模型,如下:
关键问题
问:阻塞具体阻塞在什么地方?
答:阻塞在网络线程
问:由什么来决定I/O是阻塞或非阻塞的?
答:由套接字来决定I/O是阻塞还是非阻塞的
问:阻塞与非阻塞的具体差异点?
答:I/O函数在数据未到达时是否立即返回,如果立即返回则是非阻塞I/O,否则就是阻塞I/O
3、I/O多路复用
有了I/O复用模型,可以使用select/poll/epoll等系统调用,应用阻塞在这几个系统调用上面而不是直接阻塞在I/O调用上。如下:
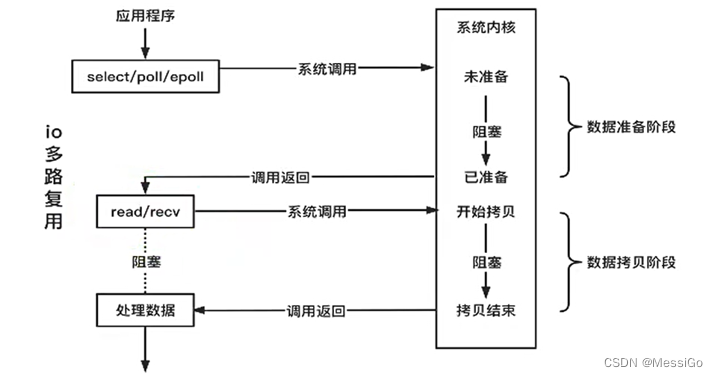
注意:epoll是作用在数据等待阶段
4、同步I/O与异步I/O对比
1)同步I/O操作:导致请求线程阻塞,直到I/O操作完成
2)异步I/O操作:不导致请求线程阻塞
阻塞I/O模型、非阻塞I/O模型、I/O复用模型和信号驱动式I/O模型都是同步I/O模型,以为其中真正的I/O操作将导致线程阻塞。只有异步I/O模型与POSIX定义的异步I/O相匹配。
二、I/O多路复用
1、传统的网络模型
传统的网络模型是基于阻塞I/O模型 + 多线程在实现服务端,如下:
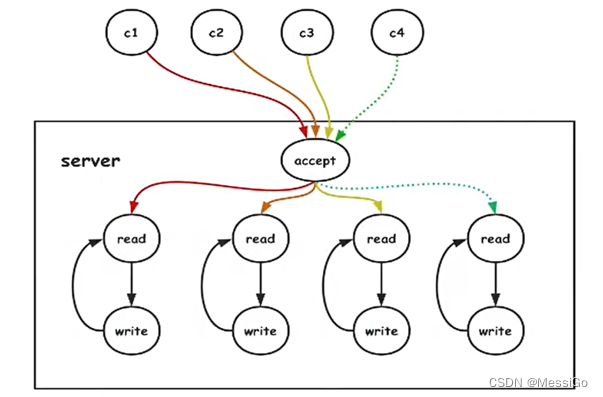
优点:处理及时,响应速度快
缺点:线程利用率低,并且线程的数量是有限的
问:为什么传统的网络模型线程利用率低?
传统的网络模型是基于阻塞I/O来实现的,如果没有数据到来线程会一直阻塞在read操作,导致线程资源浪费。如果把阻塞I/O换成非阻塞I/O,此时没有数据到来,调用完read直接返回,浪费CPU资源一直检测是否有数据可读(类似于在一个死循环里面调用read操作)
2,I/O多路复用模型
2.1、什么是I/O多路复用?
1)I/O多路:多个网络连接(或多个fd句柄)
2)复用:服务端使用一个线程来处理所有客户端的I/O请求。select,poll,epoll都是IO多路复用的机制。I/O多路复用就是通过一种机制,一个进程可以监视多个描述符(socket),一旦某个描述符就绪(一般是读就绪或者写就绪),能够通知程序进行相应的读写操作。I/O 多路复用是一种同步IO模型,事件就绪后自己负责进行读写,也就是说这个读写过程是阻塞的。
注意:高并发的核心解决方案是1个线程处理所有连接的“等待消息准备好”
2.2、为什么要使用I/O多路复用机制?
I/O多路复用指的是这样一个过程:
1)拿到了一堆文件描述符
2)调用某个系统函数告诉内核:“这个函数你先不要返回,你替我监视着这些描述符,当这堆文件描述符中有可以进行I/O读写操作的时候你再返回”
3)当调用的这个函数返回后就能知道哪些文件描述符可以进行I/O操作